Continuação da tradução de um pequeno livro:
"Entendendo os Message Brokers",
autor: Jakub Korab, editor: O'Reilly Media, Inc., data de publicação: junho de 2017, ISBN: 9781492049296.
Tradução concluída: tele.gg/middle_javaParte anterior:
Compreendendo os Message Brokers. Aprendendo a mecânica das mensagens através do ActiveMQ e Kafka. Capítulo 2. ActiveMQCAPÍTULO 3
Kafka
O Kafka foi desenvolvido no LinkedIn para contornar algumas das limitações dos agentes de mensagens tradicionais e evitar a necessidade de configurar vários agentes de mensagens para diferentes interações ponto a ponto, conforme descrito no livro "Escala vertical e horizontal" na página 28 deste livro. O LinkedIn se baseou fortemente na absorção unidirecional de grandes quantidades de dados, como cliques em páginas e logs de acesso, permitindo que vários sistemas usassem esses dados. am, sem afetar o desempenho de outros produtores ou konsyumerov. De fato, a razão pela qual Kafka existe é obter a arquitetura de mensagens que o Universal Data Pipeline descreve.
Dado esse objetivo final, outros requisitos surgiram naturalmente. Kafka deve:
- Seja extremamente rápido
- Forneça maior rendimento de mensagens
- Suporte aos modelos Publisher-Subscriber e Point-to-Point
- Não diminua a velocidade com a adição de consumidores. Por exemplo, o desempenho das filas e dos tópicos no ActiveMQ se deteriora à medida que o número de consumidores no destino aumenta.
- Seja escalável horizontalmente; se uma única mensagem persistente puder fazer isso apenas na velocidade máxima do disco, para aumentar o desempenho, faz sentido ir além dos limites de uma instância do broker
- Delinear o acesso ao armazenamento e recuperação de mensagens
Para conseguir tudo isso, Kafka adotou uma arquitetura que redefiniu as funções e responsabilidades de clientes e intermediários de mensagens. O modelo JMS é muito focado no broker, onde ele é responsável pela distribuição de mensagens, e os clientes precisam apenas se preocupar em enviar e receber mensagens. Kafka, por outro lado, é orientado ao cliente, com o cliente assumindo muitas das funções de um corretor tradicional, como a distribuição justa de mensagens relevantes entre os consumidores, em troca de receber um corretor extremamente rápido e escalável. Para as pessoas que trabalham com sistemas de mensagens tradicionais, trabalhar com Kafka requer uma mudança fundamental de atitude.
Essa direção de engenharia levou à criação de uma infraestrutura de mensagens que pode aumentar a taxa de transferência em muitas ordens de magnitude em comparação com um corretor convencional. Como veremos, essa abordagem está cheia de compromissos, o que significa que o Kafka não é adequado para certos tipos de cargas e software instalado.
Modelo de destino unificado
Para cumprir os requisitos descritos acima, Kafka combinou a assinatura de publicação e as mensagens ponto a ponto em um tipo de destinatário -
tópico . Isso é confuso para as pessoas que trabalham com sistemas de mensagens, onde a palavra "tópico" se refere a um mecanismo de transmissão do qual (a partir do tópico) a leitura não é confiável (não é durável). Os tópicos Kafka devem ser considerados um tipo de destino híbrido, conforme definido na introdução deste livro.
No restante deste capítulo, a menos que especifique explicitamente o contrário, o termo tópico se referirá ao tópico Kafka.
Para entender completamente como os tópicos se comportam e quais garantias eles fornecem, primeiro precisamos considerar como eles são implementados no Kafka.
Cada tópico no Kafka tem seu próprio diário.Os produtores que enviam mensagens para Kafka anexam-se a esta revista, e os consumidores lêem a revista usando indicadores que avançam constantemente. Kafka exclui periodicamente as partes mais antigas do diário, independentemente de as mensagens nessas partes terem sido lidas ou não. Uma parte central do design da Kafka é que o broker não se importa se as mensagens são lidas ou não - essa é a responsabilidade do cliente.
Os termos "diário" e "índice" não são encontrados na documentação do Kafka . Esses termos conhecidos são usados aqui para ajudar a entender.
Esse modelo é completamente diferente do ActiveMQ, em que as mensagens de todas as filas são armazenadas em um diário e o broker marca as mensagens como excluídas após serem lidas.
Vamos agora um pouco mais fundo e examinar a revista de tópicos com mais detalhes.
A Revista Kafka consiste em várias partições (
Figura 3-1 ). O Kafka garante pedidos rigorosos em todas as partições. Isso significa que as mensagens gravadas na partição em uma determinada ordem serão lidas na mesma ordem. Cada partição é implementada como um arquivo de log contínuo (log) que contém um
subconjunto de todas as mensagens enviadas ao tópico por seus produtores. O tópico criado contém uma partição por padrão. O particionamento é a ideia central de Kafka para dimensionamento horizontal.
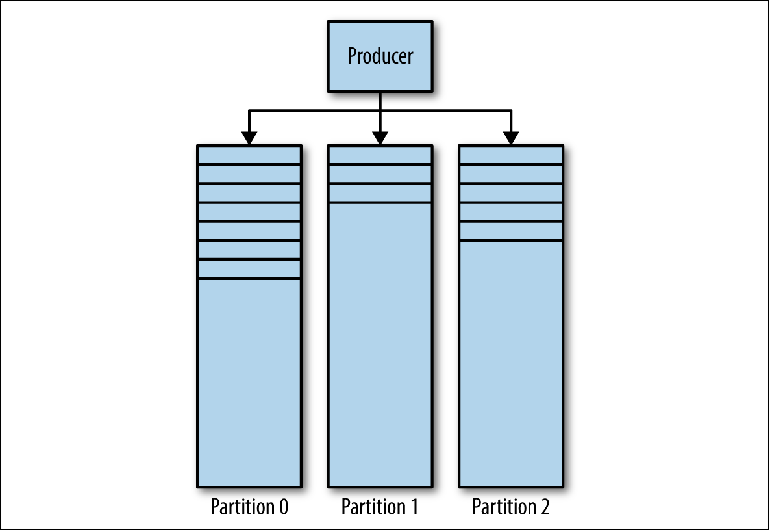 Figura 3-1. Divisórias Kafka
Figura 3-1. Divisórias KafkaQuando o produtor envia uma mensagem para o tópico Kafka, ele decide para qual partição enviar a mensagem. Consideraremos isso com mais detalhes posteriormente.
Lendo mensagens
Um cliente que deseja ler mensagens controla um ponteiro nomeado chamado
grupo de consumidores , que indica o
deslocamento de uma mensagem em uma partição. Um deslocamento é uma posição com um número crescente que começa em 0 no início da partição. Esse grupo de consumidores, referido na API por meio de um identificador definido pelo usuário group_id, corresponde a um
único consumidor ou sistema lógico .
A maioria dos sistemas de mensagens lê dados do destinatário através de várias instâncias e threads para processar mensagens em paralelo. Assim, geralmente haverá muitos casos de consumidores que compartilham o mesmo grupo de consumidores.
O problema de leitura pode ser representado da seguinte maneira:
- O tópico possui várias partições
- Vários grupos de consumidores podem usar o tópico ao mesmo tempo.
- Um grupo de consumidores pode ter várias instâncias separadas.
Esse é um problema não trivial de muitos para muitos. Para entender como o Kafka lida com os relacionamentos entre grupos de consumidores, instâncias de consumidores e partições, vamos dar uma olhada em uma série de scripts de leitura cada vez mais complexos.
Consumidores e grupos de consumidores
Vamos considerar um tópico de partição única como ponto de partida (
Figura 3-2 ).
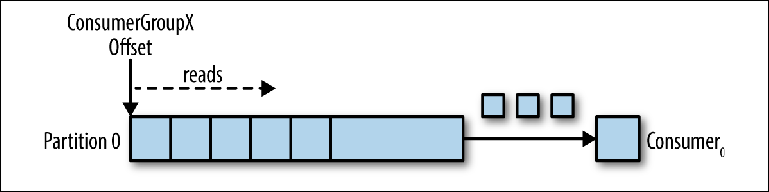 Figura 3-2. O consumidor lê da partição
Figura 3-2. O consumidor lê da partiçãoQuando uma instância do consumidor é conectada com seu próprio group_id nesse tópico, é designada uma partição para leitura e um deslocamento nessa partição. A posição desse deslocamento é configurada no cliente como um ponteiro para a posição mais recente (a mensagem mais recente) ou a posição mais antiga (a mensagem mais antiga). O consumidor solicita (pesquisas) mensagens do tópico, o que leva à leitura sequencial do diário.
A posição de deslocamento é confirmada regularmente de volta ao Kafka e salva como mensagens no tópico interno
_consumer_offsets . As mensagens de leitura ainda não são excluídas, ao contrário de um broker regular, e o cliente pode retroceder o deslocamento para processar novamente as mensagens já exibidas.
Quando um segundo consumidor lógico é conectado usando outro group_id, ele controla um segundo ponteiro que é independente do primeiro (
Figura 3-3 ). Assim, o tópico Kafka atua como uma fila na qual há um consumidor e, como um tópico regular, como assinante-publicador (pub-sub), ao qual vários consumidores estão inscritos, com a vantagem adicional de que todas as mensagens são salvas e podem ser processadas várias vezes.
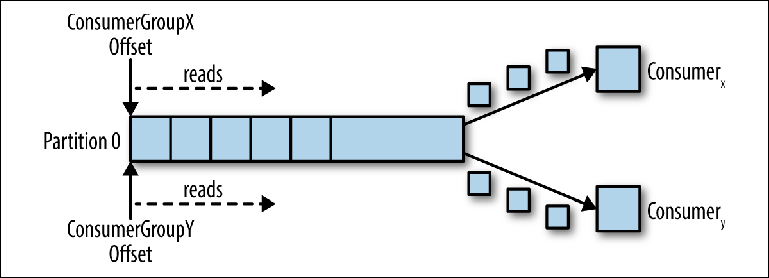 Figura 3-3. Dois consumidores em diferentes grupos de consumidores lêem da mesma partição
Figura 3-3. Dois consumidores em diferentes grupos de consumidores lêem da mesma partiçãoConsumidores no grupo de consumidores
Quando uma instância do consumidor lê dados da partição, controla completamente o ponteiro e processa as mensagens, conforme descrito na seção anterior.
Se várias instâncias dos consumidores foram conectadas com o mesmo group_id ao tópico com uma partição, a instância que foi conectada por último terá controle sobre o ponteiro e a partir de então receberá todas as mensagens (
Figura 3-4 ).
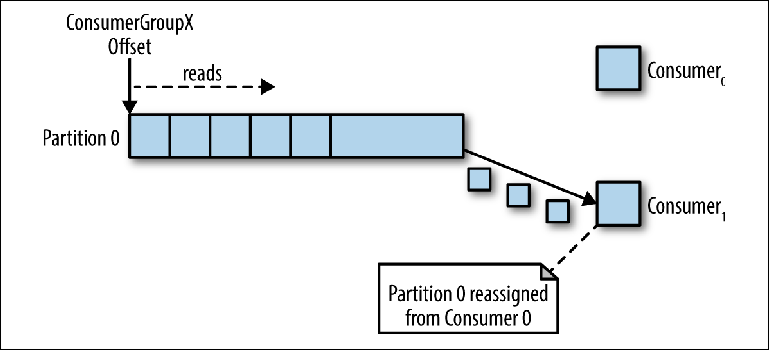 Figura 3-4. Dois consumidores no mesmo grupo de consumidores lêem da mesma partição
Figura 3-4. Dois consumidores no mesmo grupo de consumidores lêem da mesma partiçãoEsse modo de processamento, no qual o número de instâncias de consumidores excede o número de partições, pode ser considerado como um tipo de consumidor de monopólio. Isso pode ser útil se você precisar do cluster "ativo-passivo" (ou "quente e quente") de suas instâncias de consumidores, embora a operação paralela de vários consumidores ("ativo-ativo" ou "quente e quente") seja muito mais típica do que os consumidores no modo de espera.
Esse comportamento de distribuição de mensagens, descrito acima, pode ser surpreendente em comparação com o comportamento de uma fila JMS comum. Nesse modelo, as mensagens enviadas para a fila serão distribuídas igualmente entre os dois consumidores.
Na maioria das vezes, quando criamos várias instâncias de compiladores, fazemos isso para processamento paralelo de mensagens, ou para aumentar a velocidade da leitura ou para aumentar a estabilidade do processo de leitura. Como apenas uma instância de um consumidor pode ler dados de uma partição, como isso é alcançado no Kafka?
Uma maneira de fazer isso é usar uma instância do consumidor para ler todas as mensagens e enviá-las ao conjunto de encadeamentos. Embora essa abordagem aumente a taxa de transferência de processamento, aumenta a complexidade da lógica dos consumidores e não faz nada para aumentar a estabilidade do sistema de leitura. Se uma instância do consumidor desligar devido a uma falha de energia ou evento semelhante, a revisão será interrompida.
A maneira canônica de resolver esse problema no Kafka é usar mais partições.
Particionamento
Partições são o principal mecanismo para paralelizar a leitura e o dimensionamento do tópico além da largura de banda de uma instância do broker. Para entender melhor isso, vejamos uma situação em que há um tópico com duas partições e um consumidor assina esse tópico (
Figura 3-5 ).
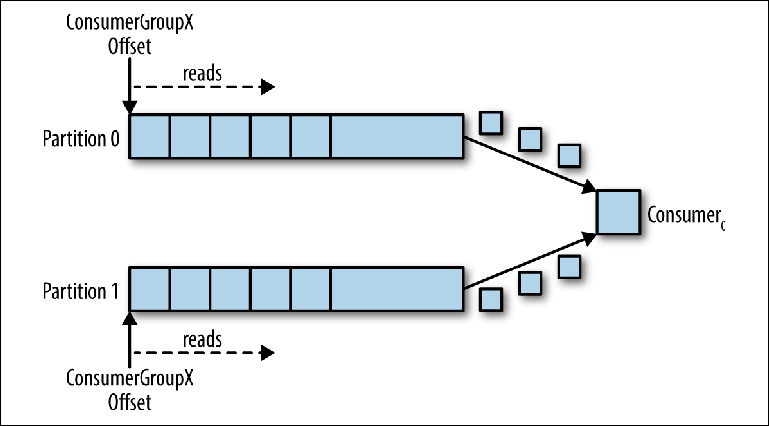 Figura 3-5. Um consumidor lê de várias partições
Figura 3-5. Um consumidor lê de várias partiçõesNesse cenário, o consultor tem controle sobre os ponteiros correspondentes ao seu group_id em ambas as partições, e a leitura das mensagens de ambas as partições é iniciada.
Quando um compurador adicional é adicionado a este tópico para o mesmo group_id, o Kafka reatribui (realoca) uma das partições da primeira para a segunda. Depois disso, cada instância do consumidor será subtraída de uma partição do tópico (
Figura 3-6 ).
Para garantir que as mensagens sejam processadas em paralelo em 20 threads, você precisará de pelo menos 20 partições. Se houver menos partições, você ainda terá consumidores com os quais não trabalhar, conforme descrito anteriormente na discussão de monitores exclusivos.
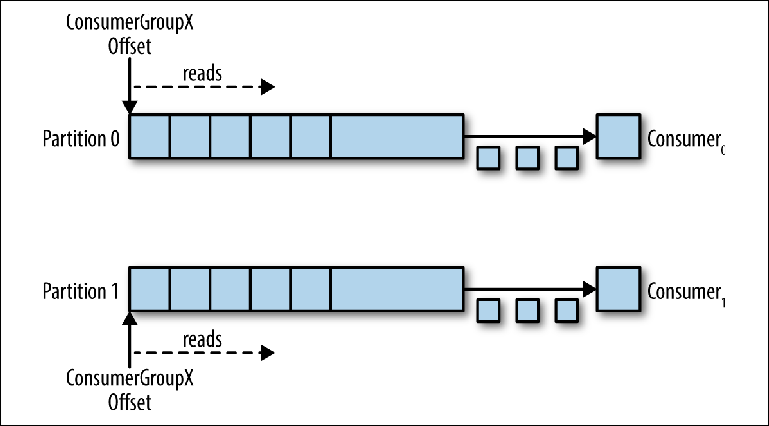 Figura 3-6. Dois consumidores no mesmo grupo de consumidores lêem partições diferentes
Figura 3-6. Dois consumidores no mesmo grupo de consumidores lêem partições diferentesEsse esquema reduz significativamente a complexidade do broker Kafka em comparação com a distribuição de mensagens necessária para suportar a fila JMS. Não há necessidade de cuidar dos seguintes pontos:
- Qual consumidor deve receber a próxima mensagem com base na distribuição round-robin, capacidade atual do buffer de pré-busca ou mensagens anteriores (como nos grupos de mensagens JMS).
- Quais mensagens foram enviadas para quais consumidores e se eles devem ser reenviados em caso de falha.
Tudo o que o corretor Kafka deve fazer é enviar consistentemente mensagens ao consultor quando este solicitar.
No entanto, os requisitos para paralelizar a revisão e reenviar mensagens sem êxito não desaparecem - a responsabilidade por eles simplesmente passa do intermediário para o cliente. Isso significa que eles devem ser incluídos no seu código.
Enviando mensagens
A responsabilidade de decidir para qual partição enviar a mensagem é o produtor da mensagem. Para entender o mecanismo pelo qual isso é feito, você primeiro precisa considerar o que exatamente estamos enviando.
Enquanto no JMS usamos uma estrutura de mensagens com metadados (cabeçalhos e propriedades) e um corpo contendo uma carga, no Kafka a mensagem é
um par de valores-chave . A carga útil da mensagem é enviada como um valor. Uma chave, por outro lado, é usada principalmente para particionar e deve conter uma
chave específica da lógica de negócios para colocar as mensagens relacionadas na mesma partição.
No capítulo 2, discutimos o cenário de apostas on-line, quando eventos relacionados devem ser processados em ordem por um único consumidor:
- A conta do usuário está configurada.
- O dinheiro é creditado na conta.
- É feita uma aposta que retira dinheiro da conta.
Se cada evento for uma mensagem enviada ao tópico, nesse caso, o identificador da conta será a chave natural.
Quando uma mensagem é enviada usando a API do Kafka Producer, ela é passada para a função de partição, que, dada a mensagem e o estado atual do cluster Kafka, retorna o identificador da partição para a qual a mensagem deve ser enviada. Esse recurso é implementado em Java através da interface do Partitioner.
Essa interface é a seguinte:
interface Partitioner { int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); }
A implementação do Particionador usa o algoritmo de hash de uso geral padrão sobre a chave ou round-robin se a chave não for especificada para determinar a partição. Esse valor padrão funciona bem na maioria dos casos. No entanto, no futuro você vai querer escrever o seu.
Escrevendo sua própria estratégia de particionamento
Vejamos um exemplo quando você deseja enviar metadados junto com a carga útil da mensagem. A carga útil em nosso exemplo é uma instrução para fazer um depósito em uma conta de jogo. Uma instrução é algo que gostaríamos de garantir para não modificar durante a transmissão, e queremos ter certeza de que apenas um sistema superior confiável pode iniciar essa instrução. Nesse caso, os sistemas de envio e recebimento concordam com o uso da assinatura para autenticar a mensagem.
Em um JMS regular, simplesmente definimos a propriedade de assinatura da mensagem e a adicionamos à mensagem. No entanto, Kafka não nos fornece um mecanismo para transmitir metadados - apenas a chave e o valor.
Como o valor é a carga útil de uma transferência bancária (carga útil de transferência bancária), cuja integridade queremos manter, não temos escolha a não ser determinar a estrutura de dados para uso na chave. Supondo que precisamos de um identificador de conta para particionar, como todas as mensagens relacionadas à conta devem ser processadas em ordem, criaremos a seguinte estrutura JSON:
{ "signature": "541661622185851c248b41bf0cea7ad0", "accountId": "10007865234" }
Como o valor da assinatura varia de acordo com a carga, a estratégia padrão de hash da interface do Partitioner não agrupará mensagens relacionadas de maneira confiável. Portanto, precisaremos escrever nossa própria estratégia, que analisará essa chave e compartilhará o valor de accountId.
O Kafka inclui somas de verificação para detectar corrupção de mensagens no repositório e possui um conjunto completo de recursos de segurança. Mesmo assim, às vezes aparecem requisitos específicos do setor, como o acima.
A estratégia de particionamento do usuário deve garantir que todas as mensagens relacionadas terminem na mesma partição. Embora isso pareça simples, o requisito pode ser complicado devido à importância de solicitar mensagens relacionadas e à correção do número de partições no tópico.
O número de partições no tópico pode mudar ao longo do tempo, pois elas podem ser adicionadas se o tráfego ultrapassar as expectativas iniciais. Assim, as chaves de mensagem podem ser associadas à partição para a qual foram originalmente enviadas, implicando uma parte do estado que deve ser distribuída entre as instâncias do produtor.
Outro fator a considerar é a distribuição uniforme de mensagens entre partições. Como regra, as chaves não são distribuídas igualmente entre as mensagens e as funções de hash não garantem uma distribuição justa de mensagens para um pequeno conjunto de chaves.
É importante observar que, não importa como você decida dividir as mensagens, talvez o próprio separador precise ser reutilizado.
Considere o requisito para replicação de dados entre clusters Kafka em diferentes localizações geográficas. Para esse fim, o Kafka vem com uma ferramenta de linha de comando chamada MirrorMaker, usada para ler mensagens de um cluster e transferi-las para outro.
O MirrorMaker deve entender as chaves do tópico replicado para manter a ordem relativa entre as mensagens durante a replicação entre clusters, pois o número de partições para esse tópico pode não coincidir em dois clusters.
Estratégias de particionamento personalizadas são relativamente raras, pois hashes padrão ou rodízio funcionam com êxito na maioria dos cenários. No entanto, se você precisar de garantias estritas de pedido ou extrair metadados das cargas, o particionamento é algo que você deve examinar mais de perto.
Os benefícios de escalabilidade e desempenho da Kafka vêm da transferência de algumas das responsabilidades de um corretor tradicional para um cliente. Nesse caso, é tomada uma decisão sobre a distribuição de mensagens potencialmente relacionadas entre vários consumidores que trabalham em paralelo.
Os corretores JMS também devem lidar com esses requisitos. Curiosamente, o mecanismo para enviar mensagens relacionadas para a mesma conta implementada por meio dos Grupos de Mensagens JMS (um tipo de estratégia de balanceamento de SLB) também requer que o remetente marque as mensagens como relacionadas. No caso do JMS, o broker é responsável por enviar esse grupo de mensagens relacionadas a um dos muitos clientes e transferir a propriedade do grupo se o cliente cair.
Acordo de Produtor
Particionar não é a única coisa a considerar ao enviar mensagens. Vejamos os métodos send () da classe Producer na API Java:
Future < RecordMetadata > send(ProducerRecord < K, V > record); Future < RecordMetadata > send(ProducerRecord < K, V > record, Callback callback);
Deve-se notar imediatamente que ambos os métodos retornam Future, o que indica que a operação de envio não é executada imediatamente. Como resultado, verifica-se que a mensagem (ProducerRecord) é gravada no buffer de envio para cada partição ativa e transmitida ao broker no fluxo em segundo plano na biblioteca do cliente Kafka. Embora isso torne o trabalho incrivelmente rápido, significa que um aplicativo inexperiente pode perder mensagens se o processo for interrompido.
Como sempre, existe uma maneira de tornar a operação de envio mais confiável devido ao desempenho. O tamanho desse buffer pode ser definido como 0 e o encadeamento do aplicativo de envio será forçado a esperar até que a mensagem seja enviada ao broker, da seguinte maneira:
RecordMetadata metadata = producer.send(record).get();
Mais uma vez sobre a leitura de mensagens
A leitura de mensagens tem dificuldades adicionais que precisam ser consideradas. Diferente da API JMS, que pode iniciar um ouvinte de mensagem em resposta a uma mensagem, a interface
Consumer Kafka é pesquisada apenas. Vamos dar uma olhada no método
poll () usado para esta finalidade:
ConsumerRecords < K, V > poll(long timeout);
O valor de retorno do método é uma estrutura de contêiner que contém vários objetos
ConsumerRecord de potencialmente várias partições.
Um ConsumerRecord em si é um objeto detentor de um par de valores-chave com metadados associados, como a partição da qual é derivada.
Conforme discutido no Capítulo 2, devemos lembrar constantemente o que acontece com as mensagens depois que elas são processadas com ou sem êxito, por exemplo, se o cliente não puder processar a mensagem ou se interromper o trabalho. No JMS, isso foi tratado através do modo de reconhecimento. O broker excluirá a mensagem processada com êxito ou entregará novamente a mensagem bruta ou invertida (desde que as transações tenham sido usadas).
Kafka funciona de uma maneira completamente diferente. As mensagens não são excluídas no broker após a revisão, e a responsabilidade pelo que acontece após a falha está no próprio código.
Como já dissemos, um grupo de consumidores está associado a um deslocamento na revista. A posição do log associada a esse viés corresponde à próxima mensagem que será emitida em resposta a
poll () . Crucial na leitura é o momento em que esse deslocamento aumenta.
Retornando ao modelo de leitura discutido anteriormente, o processamento de mensagens consiste em três estágios:
- Recupere uma mensagem para ler.
- Processe a mensagem.
- Confirme a mensagem.
O Kafka Consumer Advisor vem com a
opção de configuração
enable.auto.commit . Essa é uma configuração padrão comumente usada, como é geralmente o caso das configurações que contêm a palavra "automático".
Antes do Kafka 0.10, o cliente que usava esse parâmetro enviava o deslocamento da última mensagem lida na próxima chamada
poll () após o processamento. Isso significava que todas as mensagens que já foram buscadas poderiam ser processadas novamente se o cliente já as tivesse processado, mas foram destruídas inesperadamente antes de chamar
poll () . Como o broker não mantém nenhum status com relação a quantas vezes a mensagem foi lida, o próximo consumidor que recupera essa mensagem não saberá que algo ruim aconteceu. Esse comportamento foi pseudo-transacional. O deslocamento foi confirmado apenas no caso de processamento bem-sucedido da mensagem, mas se o cliente interrompido, o broker enviou novamente a mesma mensagem para outro cliente. Esse comportamento foi consistente com a garantia de entrega "
pelo menos uma vez ".
No Kafka 0.10, o código do cliente foi alterado de forma que o commit começou a ser iniciado periodicamente pela biblioteca do cliente, de acordo com a configuração
auto.commit.interval.ms . Esse comportamento está em algum lugar entre os modos JMS AUTO_ACKNOWLEDGE e DUPS_OK_ACKNOWLEDGE. Ao usar a confirmação automática, as mensagens podem ser confirmadas independentemente de terem sido realmente processadas - isso pode acontecer no caso de um consumidor lento. Se o computador foi interrompido, as mensagens foram recuperadas pelo computador seguinte, iniciando em uma posição segura, o que poderia levar a uma mensagem pulando. Nesse caso, Kafka não perdeu mensagens, o código de leitura simplesmente não as processou.
Esse modo tem as mesmas perspectivas da versão 0.9: as mensagens podem ser processadas, mas no caso de uma falha, o deslocamento pode não ser fechado, o que pode levar a uma duplicação da entrega. Quanto mais mensagens você recuperar ao fazer
poll () , maior será esse problema.
Conforme discutido na seção "Subtraindo mensagens da fila" no
Capítulo 2 , não existe entrega de mensagens únicas no sistema de mensagens, dados os modos de falha.
No Kafka, existem duas maneiras de corrigir (confirmar) um deslocamento (deslocamento): automática e manualmente. Nos dois casos, as mensagens podem ser processadas várias vezes, caso a mensagem tenha sido processada, mas falhou antes de ser confirmada. Também não é possível processar a mensagem se a confirmação ocorreu em segundo plano e seu código foi concluído antes de iniciar o processamento (possivelmente no Kafka 0.9 e versões anteriores).
Você pode controlar o processo de confirmar compensações manualmente na API do Kafka
Consumer , definindo
enable.auto.commit como false e chamando explicitamente um dos seguintes métodos:
void commitSync(); void commitAsync();
Se você deseja processar a mensagem “pelo menos uma vez”, confirme o deslocamento manualmente usando
commitSync () executando este comando imediatamente após o processamento das mensagens.
Esses métodos não permitem que mensagens reconhecidas sejam processadas antes de serem processadas, mas não fazem nada para eliminar a possível duplicação de processamento, criando ao mesmo tempo a aparência de transacionalidade. Kafka não tem transações. O cliente não tem a oportunidade de fazer o seguinte:
- Reverter automaticamente uma mensagem de reversão. Os próprios consumidores devem lidar com exceções decorrentes de cargas problemáticas e desconexões de back-end, pois não podem confiar no broker para entregar novamente as mensagens.
- Envie mensagens para vários tópicos em uma operação atômica. Como veremos em breve, o controle sobre vários tópicos e partições pode estar localizado em máquinas diferentes no cluster Kafka, que não coordenam as transações durante o envio. No momento da redação deste artigo, algum trabalho foi feito para tornar isso possível com o KIP-98.
- Associe a leitura de uma mensagem de um tópico ao envio de outra mensagem para outro tópico. Novamente, a arquitetura do Kafka depende de muitas máquinas independentes funcionando como um barramento e nenhuma tentativa é feita para ocultá-lo. Por exemplo, não há componentes de API que permitam que o Consumidor e o Produtor sejam vinculados em uma transação. No JMS, isso é fornecido pelo objeto Session a partir do qual MessageProducers e MessageConsumers são criados.
Se não podemos confiar nas transações, como podemos fornecer semânticas mais próximas das fornecidas pelos sistemas de mensagens tradicionais?
Se houver a possibilidade de o deslocamento do consumidor aumentar antes que a mensagem tenha sido processada, por exemplo, durante a falha do cliente, o cliente não terá como saber se o grupo de clientes perdeu a mensagem ao receber uma partição. Assim, uma estratégia é rebobinar o deslocamento para a posição anterior. A API do Kafka Consumer Advisor fornece os seguintes métodos para isso:
void seek(TopicPartition partition, long offset); void seekToBeginning(Collection < TopicPartition > partitions);
O método
seek () pode ser usado com o método
offsetsForTimes (Map <TopicPartition, Long> timestampsToSearch) para retroceder para um estado em qualquer ponto específico do passado.
Implicitamente, o uso dessa abordagem significa que é muito provável que algumas mensagens processadas anteriormente sejam lidas e processadas novamente. Para evitar isso, podemos usar a leitura idempotente, conforme descrito no Capítulo 4, para rastrear mensagens visualizadas anteriormente e eliminar duplicatas.
Como alternativa, o código do seu consumidor pode ser simples se a perda ou duplicação de mensagens for permitida. Quando analisamos os cenários de uso nos quais o Kafka geralmente é usado, por exemplo, processando eventos de log, métricas, rastreamento de cliques etc., entendemos que é improvável que a perda de mensagens individuais tenha um impacto significativo nos aplicativos vizinhos. Nesses casos, os valores padrão são aceitáveis. Por outro lado, se seu aplicativo precisar transferir pagamentos, você deverá cuidar cuidadosamente de cada mensagem individual. Tudo se resume ao contexto.
Observações pessoais mostram que, com o aumento da intensidade da mensagem, o valor de cada mensagem individual diminui. As mensagens de alto volume tendem a se tornar valiosas quando exibidas de forma agregada.
Alta disponibilidade
A abordagem de alta disponibilidade de Kafka é muito diferente do ActiveMQ. O Kafka é desenvolvido com base em clusters escaláveis horizontalmente, nos quais todas as instâncias do broker recebem e distribuem mensagens simultaneamente.
O cluster Kafka consiste em várias instâncias do broker em execução em servidores diferentes. O Kafka foi projetado para funcionar em um hardware independente convencional, em que cada nó tem seu próprio armazenamento dedicado. O uso do SAN (Network Attached Storage) não é recomendado porque vários nós de computação podem competir por intervalos de tempo de armazenamento e criar conflitos.
Kafka é um sistema
constantemente ativo. Muitos usuários grandes do Kafka nunca extinguem seus clusters e o software sempre fornece atualizações por meio de uma reinicialização consistente. Isso é obtido garantindo a compatibilidade com a versão anterior para mensagens e interações entre os intermediários.
Os
intermediários estão conectados a um
cluster de servidores
ZooKeeper , que atua como um determinado registro de configuração e é usado para coordenar as funções de cada intermediário. O ZooKeeper em si é um sistema distribuído que fornece alta disponibilidade através da replicação de informações, estabelecendo um
quorum .
No caso base, o tópico é criado no cluster Kafka com as seguintes propriedades:
- O número de partições. Como discutido anteriormente, o valor exato usado aqui depende do nível desejado de leitura simultânea.
- O coeficiente de replicação (fator) determina quantas instâncias do broker no cluster devem conter os logs para esta partição.
Usando o ZooKeepers para coordenação, Kafka está tentando distribuir de forma justa novas partições entre os intermediários no cluster. Isso é feito por uma instância, que atua como o Controller.
Em tempo
de execução
para cada partição do tópico, o Controlador atribui ao intermediário as funções de
líder (líder, mestre, líder) e
seguidores (seguidores, escravos, subordinados). O corretor, atuando como líder dessa partição, é responsável por receber todas as mensagens enviadas a ele pelos produtores e distribuir mensagens aos consumidores. Ao enviar mensagens para uma partição de tópico, elas são replicadas para todos os nós do intermediário que atuam como seguidores dessa partição. Cada nó que contém os logs da partição é chamado de
réplica . Um corretor pode atuar como líder em algumas partições e como seguidor em outras.
Um seguidor que contém todas as mensagens armazenadas pelo líder é chamado de
réplica sincronizada (uma réplica em estado sincronizado, réplica sincronizada). Se o intermediário que atua como líder da partição for desconectado, qualquer intermediário que esteja no estado atualizado ou sincronizado para esta partição poderá assumir a função de líder. Este é um design incrivelmente sustentável.
Parte da configuração do produtor é o parâmetro
acks , que determina quantas réplicas devem confirmar o recebimento de uma mensagem antes que o fluxo do aplicativo continue enviando: 0, 1 ou todos. Se o valor estiver definido como
todos , quando a mensagem for recebida, o líder enviará uma confirmação de volta ao produtor assim que receber a confirmação das várias réplicas (incluindo ele mesmo) definidas pela
configuração do tópico
min.insync.replicas (por padrão 1). Se a mensagem não puder ser replicada com êxito, o produtor lançará uma exceção para o aplicativo (
NotEnoughReplicas ou
NotEnoughReplicasAfterAppend ).
Em uma configuração típica, um tópico é criado com um coeficiente de replicação 3 (1 líder, 2 seguidores para cada partição) e o parâmetro min.insync.replicas é definido como 2. Nesse caso, o cluster permitirá que um dos intermediários que gerenciam a partição seja desconectado. sem afetar os aplicativos clientes.Isso nos leva de volta ao compromisso já familiar entre desempenho e confiabilidade. A replicação ocorre devido ao tempo de espera adicional para agradecimentos (agradecimentos) dos seguidores. Embora, como é executado em paralelo, a replicação de pelo menos três nós tenha o mesmo desempenho que dois (ignorando o aumento no uso da largura de banda da rede).Usando esse esquema de replicação, o Kafka evita inteligentemente a necessidade de gravar fisicamente cada mensagem no disco usando a operação sync () . Cada mensagem enviada pelo produtor será gravada no log da partição, mas, conforme discutido no Capítulo 2, a gravação no arquivo é inicialmente executada no buffer do sistema operacional. Se essa mensagem for replicada para outra instância do Kafka e estiver em sua memória, a perda de um líder não significa que a mensagem foi perdida - uma réplica sincronizada pode assumir isso sozinha.Desativar a operação sync ()significa que Kafka pode receber mensagens na velocidade com que pode gravá-las na memória. Por outro lado, quanto mais você evitar a descarga da memória no disco, melhor. Por esse motivo, não é incomum os corretores Kafka alocarem 64 GB ou mais de memória. Esse uso de memória significa que uma instância do Kafka pode funcionar facilmente em velocidades milhares de vezes mais rápidas que um broker de mensagens tradicional.O Kafka também pode ser configurado para usar sync ()para pacotes de mensagens. Como tudo no Kafka é orientado a pacotes, ele realmente funciona muito bem para muitos casos de uso e é uma ferramenta útil para usuários que exigem garantias muito fortes. A maior parte do desempenho puro de Kafka está relacionada às mensagens enviadas ao broker como pacotes e ao fato de que essas mensagens são lidas do broker em blocos sucessivos usando operações de cópia zero (operações que não executam a tarefa de copiar dados de uma área de memória para outro). O último é um grande ganho em termos de desempenho e recursos e só é possível através do uso da estrutura de dados de log subjacente que define o esquema de partição.Em um cluster Kafka, é possível um desempenho muito mais alto do que ao usar um único broker Kafka, pois as partições de tópicos podem ser dimensionadas horizontalmente em muitas máquinas separadas.Sumário
Neste capítulo, examinamos como a arquitetura Kafka reinterpreta o relacionamento entre clientes e corretores para fornecer um pipeline de mensagens incrivelmente robusto, com largura de banda muitas vezes maior que um corretor de mensagens comum. Discutimos a funcionalidade usada para atingir esse objetivo e revisamos brevemente a arquitetura dos aplicativos que fornecem essa funcionalidade. No próximo capítulo, discutiremos problemas comuns que os aplicativos de mensagens precisam resolver e discutir estratégias para resolvê-los. Concluímos o capítulo descrevendo como falar sobre tecnologias de mensagens em geral, para que você possa avaliar a adequação deles para seus casos de uso.Tradução concluída: tele.gg/middle_javaContinua ...