Na Internet, os captchas ainda permanecem relevantes, que como opção oferecem ouvir o texto da imagem clicando no botão correspondente. Se alguém estiver familiarizado com a imagem abaixo e / ou estiver interessado em como contorná-la usando um sistema de reconhecimento de som offline, é recomendável lê-la.
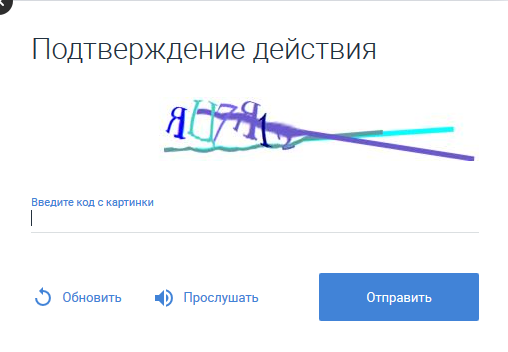
Não atormentaremos as intrigas de especialistas na área de reconhecimento de fala, afirmando imediatamente que nenhum sistema de reconhecimento de voz proprietário para os fins declarados foi desenvolvido. O artigo usa o bom e velho Pocketsphinx, mas com um certo grau de personalização.
Preparação
"Você entra no escritório de concorrentes que têm controle de voz em computadores, grita" Sudo Era menos Eref Home "e foge." Dos comentários.
Assim, o captcha se oferece para ouvir a si mesmo clicando no botão apropriado. Se você salvar o arquivo de som resultante, poderá descobrir como é um pequeno pedaço de áudio em .mp3. Ao mesmo tempo, os captchas são oferecidos com dublagem em voz feminina ou masculina. O "desenho" dos mesmos sons feitos por um homem e uma mulher é diferente:
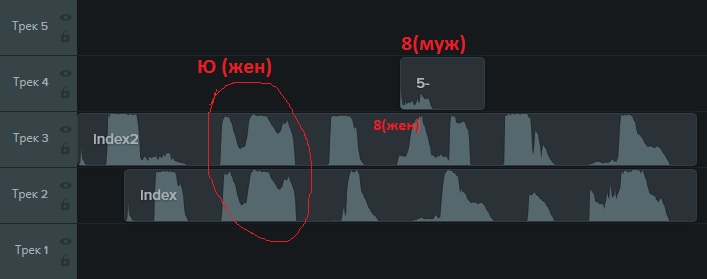
Eles soam letras (e russo) e números.
À primeira vista, tudo é triste. Mas há um ponto positivo em que os sons para as mesmas letras coincidem.
Até agora, esse conhecimento não ajuda muito. Como colocar tudo no pacote Sphinx?
Instale o Pocketsphinx, um modelo de som russo
* Há
um artigo em Habré onde o som é alimentado para o google tradutor online através do redirecionamento da saída de som. E isso poderia terminar este post, se tudo isso funcionasse neste caso.
Instalar o próprio Pocketsphinx no Windows (e também no Linux) não é muito complicado - faça o
download , instale.
Como, por padrão, o pocketsphinx vem com um idioma inglês, modelos acústicos, dicionário, você precisará do mesmo para o idioma russo.
Faça o download da versão em russo -
link .
Após descompactar o modelo russo na estrutura do arquivo, você pode tentar o arquivo .wav de teste decoder-text.wav com o seguinte código python:
import os from pocketsphinx import AudioFile, get_model_path, get_data_path
O conteúdo do arquivo de áudio deve ser exibido na linha: "Ilya Ilf Evgeny Petrov Golden Calf".
Se não der resultado (como na minha situação), você precisará converter decoder-test.wav para outro formato de áudio.
Você precisará do ffmpeg para isso.
Ffmpeg
Depois de baixar o utilitário ffmpeg, coloque decoder-test.wav em C: \ python3 \ ffmpeg \ bin.
Em seguida, converta a linha de comandos:
ffmpeg -i decoder-test.wav -ar 16000 decoder-test-.wav
Em seguida, corrija o link para o arquivo de áudio de origem no código python:
'audio_file': os.path.join(data_path, 'C://python3//decoder-test-.wav'),
Agora, depois de elaborar o código:

É verdade que você precisa esperar até a segunda vinda, o código funciona muito lentamente - cerca de 20 segundos.
Nós convertemos o captcha de áudio pelo mesmo princípio de mp3 para wav e alimentamos o áudio do captcha. Dê uma olhada no código:

Algum tipo de ignorância, mas há um resultado. Teria sido muito pior se nada tivesse sido revelado. Tal como acontece com uma voz feminina:

Vamos ver como melhorar o resultado e, ao mesmo tempo, acelerá-lo.
Vocabulário
Você precisará do seu próprio dicionário. Nesse caso, ele consistirá em todas as letras do alfabeto russo (exceto b, s, b) e números.
Todos os caracteres devem ser colocados em um arquivo de texto sem formatação, um em cada linha na codificação UTF-8.
Agora você precisa converter o dicionário.
Você precisará instalar o perl (é necessário que o conversor funcione).
Em seguida, faça o download do projeto para converter o
ru4sphinx .
E converta o dicionário criado anteriormente:
C:\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt.
A saída é um dicionário para o trabalho:

A extensão do dicionário deve ser renomeada do formato .txt para .dic e o próprio arquivo deve ser colocado em um local acessível.
No código python, indicaremos a localização do dicionário comentando o antigo dicionário:
Execute o programa e veja o resultado:

Melhor, mas com a mesma lentidão, e nem todas as letras são identificadas corretamente.
Crie seu próprio modelo
Isso aumentará significativamente a velocidade do trabalho e um pouco de precisão no resultado.
Vamos percorrer um pouco as
instruções .
Siga o
link e faça o upload do nosso dicionário, criado anteriormente no formato .txt (não .dic!) Para o site:
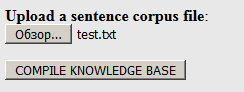
Clique em "Compilar ...". Na saída, você pode fazer o download do pacote resultante no arquivo .tgz (ele contém todos os arquivos necessários):
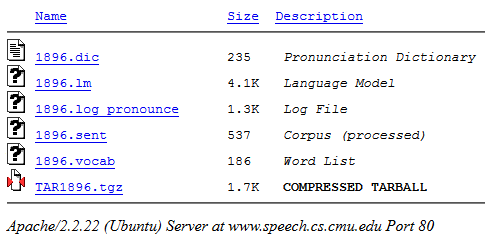
Em seguida, pegamos um arquivo com a extensão .lm (nosso modelo) do arquivo morto.
Vamos corrigir o script de reconhecimento de python substituindo o modelo por um novo:
Tentamos:

Funciona muito mais rápido - menos de um segundo, além disso, todas as letras são definidas.
Mas aqui é necessária uma pequena observação.
Nem todos os caracteres são reconhecidos corretamente e, se em vez da letra correta, um caractere diferente for exibido, você poderá corrigir manualmente o dicionário .dic criado anteriormente, correspondendo à correspondência da letra.
Por exemplo, em vez da letra a, exibe e. É necessário pegar uma linha do dicionário e:
rye
transfira (excluindo o antigo), alterando a letra:
ryMas como a letra "a" já está no dicionário, é necessário adicionar "(2)" (ou 3,4) à letra, em geral, um número de série, dependendo de quantos sons já estão no dicionário:
a(2) ryNão é necessário reconverter o dicionário. De uma maneira tão simples, você pode "captar" fonemas de todas as letras, quase.
Cherchez la femme
Trabalho de modelo e vocabulário, mas não com uma voz feminina. Se a voz do captcha é feminina, não obtemos nada na saída. Isso é bom e ruim ao mesmo tempo. Primeiro sobre o bem.
Se você não reconheceu nada ao iniciar o programa, significa que estamos lidando com uma voz feminina, para que você possa filtrar captchas "femininos".
Mas o que fazer com eles?
Aqui você precisa trabalhar com a conversão.
Por exemplo, com um captcha "masculino", a frequência era 16000 e para um "captcha" feminino 24000:
ffmpeg -i acap(3).mp3 -ar 24000 acap(3)2.wav

Todos os sons são definidos (em cada linha pelo som), mas sua correspondência é fraca.
É melhor criar um dicionário separado para o modelo feminino e depois editá-lo.
No entanto, isso é para auto-estudo.
Links úteis:
1.home-smart-home.ru/raspberry-pi-pocketsphinx-offlajn-raspoznavanie-rechi-i-upravlenie-golosom2.https: //itnan.ru/post.php? C = 1 & p = 351376
3.
ru.wikipedia.org/wiki/Cherchez_la_femmeArquivos:
1.
O programa .
2.
O modelo3. O
modelo russo .
4.
Dicionário .
5.
Teste o captcha .
6.
ffmpeg .
7.
Um pacote de captcha .