No processo de trabalho no próximo projeto, a equipe discutiu sobre o uso do formato XML ou SQL no Liquibase. Naturalmente, muitos artigos já foram escritos sobre o Liquibase, mas como sempre, quero adicionar minhas observações. O artigo apresentará um pequeno tutorial sobre a criação de um aplicativo simples com um banco de dados e considerará a diferença de meta-informações para esses tipos.
Liquibase é uma biblioteca independente de banco de dados para rastrear, gerenciar e aplicar alterações no esquema do banco de dados. Para fazer alterações no banco de dados, um arquivo de migração (* changeset *) é criado, conectado ao arquivo principal (* changeLog *), que controla as versões e gerencia todas as alterações.
Os formatos XML ,
YAML ,
JSON e
SQL são usados para descrever a estrutura e as alterações do banco de dados.
O conceito básico de migração de banco de dados é o seguinte:
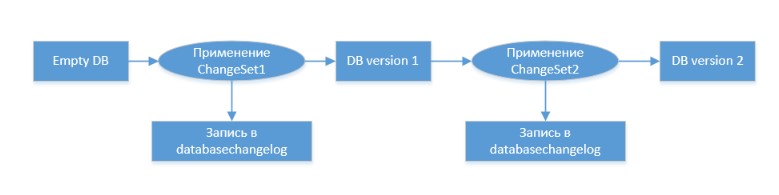
Mais informações sobre o Liquibase podem ser encontradas
aqui ou
aqui . Espero que o quadro geral seja claro, então vamos continuar criando o projeto.
O projeto de teste usa
- Java 8
- Bota de mola
- Maven
- H2
- bem liquibase em si
Criação e Dependências do Projeto
O uso do Spring-boot não é condicional aqui, você pode fazer apenas um plugin do maven para rolar scripts. Então, vamos começar.
1. Crie um projeto maven no IDE e adicione as seguintes dependências ao arquivo pom:
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.liquibase</groupId> <artifactId>liquibase-core</artifactId> <version>3.6.3</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> </dependencies>
2. Na pasta resources, crie o arquivo application.yml e adicione as seguintes linhas:
spring: liquibase: change-log: classpath:/db/changelog/db.changelog-master.yaml datasource: url: jdbc:h2:mem:test; platform: h2 username: sa password: driverClassName: org.h2.Driver h2: console: enabled: true
Linha Liquibase: change-log: classpath: /db/changelog/db.changelog-master.yaml - informa onde o arquivo de script liquibase está localizado.
3. Na pasta resources ao longo do caminho db.changelog-master, crie os seguintes arquivos:
- xmlSchema.xml - altera o script no formato xml
- sqlSchema.sql - script de alterações no formato sql
- data.xml - adicione dados à tabela
- db.changelog-master.yml - lista de alterações
4. Adicionando dados aos arquivos:
Para o teste, você precisa criar dois t não relacionados
tabelas e o conjunto mínimo de dados.
No arquivo sqlSchema.sql, adicionamos a conhecida sintaxe sql a todos:
O uso do sql como um changeet é orientado por scripts fáceis. Nos arquivos, todos entendem o sql usual.
Um comentário é usado para separar o conjunto de alterações:
--changeset TestUsers_sql: 1 com o número da mudança e o sobrenome
(os parâmetros podem ser encontrados
aqui .)
No arquivo xmlSchema.sql, adicione o DSL que o liquibase fornece: <?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd"> <changeSet id="Create table test_xml_table" author="TestUsers_xml"> <createTable tableName="test_xml_table"> <column name="name" type="character varying"> <constraints primaryKey="true" nullable="false"/> </column> <column name="description" type="character varying"/> </createTable> </changeSet> <changeSet id="Create table test_xml_table_2" author="TestUsers_xml"> <createTable tableName="test_xml_table_2"> <column name="name" type="character varying"> <constraints primaryKey="true" nullable="false"/> </column> <column name="description" type="character varying"/> </createTable> </changeSet> </databaseChangeLog>
Esse formato para descrever a criação de tabelas é universal para diferentes bancos de dados. Assim como o slogan do Java:
"É escrito uma vez, funciona em qualquer lugar" . O Liquibase usa a descrição xml e a compila em código sql específico, dependendo do banco de dados selecionado. O que é muito conveniente para parâmetros gerais.
Cada operação é executada em um changeSet separado, indicando o ID e o nome do autor. Eu acho que a linguagem usada no xml é muito fácil de entender e nem precisa ser explicada.
5. Carregue os dados em nossas placas, isso não é necessário, mas como as placas foram feitas, você precisa colocar algo nelas. Nós preenchemos o arquivo data.xml com os seguintes dados:
<?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd"> <changeSet id="insert data to test_xml_table" author="TestUsers"> <insert tableName="test_xml_table"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_xml_table_2" author="TestUsers"> <insert tableName="test_xml_table_2"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_sql_table" author="TestUsers"> <insert tableName="test_sql_table"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_sql_table_2" author="TestUsers"> <insert tableName="test_sql_table_2"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> </databaseChangeLog>
Arquivos para tabelas rolantes são criados, dados para tabelas são criados. É hora de combinar tudo isso em uma ordem comum e iniciar nosso aplicativo.
Adicione nossos arquivos sql e xml ao arquivo db.changelog-master.yml:
databaseChangeLog: - include: # schema file: db/changelog/xmlSchema.xml - include: file: db/changelog/sqlSchema.sql # data - include: file: db/changelog/data.xml
E agora que temos tudo criado. Basta executar nosso aplicativo. Você pode usar a linha de comando ou o plugin para iniciar, mas criaremos apenas o método principal e executaremos nosso SpringApplication.
Ver metadados
Agora que executamos nossos dois scripts para criar e preencher as tabelas, podemos olhar para a tabela databaseChangeLog e ver o que rolou.

O resultado do rolamento xml:
- No campo de identificação dos arquivos xml, aparece um cabeçalho que o desenvolvedor aponta para changeSet, cada changeSet individual é uma linha separada no banco de dados com um título e uma descrição.
- O autor de cada alteração é indicado.
Resultado do rolo quadrado:
- Não há informações detalhadas sobre changeSet no campo id de arquivos sql.
- O autor de cada alteração não é indicado.
Outra conclusão importante para o uso de xml é a reversão. Comandos como criar tabela, alterar tabela, adicionar coluna têm reversão automática ao usar xml. Para arquivos sql, cada reversão deve ser gravada manualmente.
Conclusão
Todo mundo escolhe para si o que usar. Mas nossa escolha caiu no lado xml. Meta-informações detalhadas e fácil transição para outros bancos de dados superaram as escalas do formato sql favorito de todos.