Oi Pela manchete, você já entendeu sobre o que vou falar. Haverá muito hardcore:
discutiremos Java, C, C ++, assembler, um pouco de Linux, um pouco do kernel do sistema operacional. Também analisaremos um caso prático, para que o artigo seja dividido em três partes grandes (bastante volumosas).
No primeiro, tentaremos extrair tudo dos criadores de perfil existentes.
Na segunda parte, criaremos nosso próprio pequeno gerador de perfil e na terceira veremos como criar um perfil do que não é habitual, porque as ferramentas existentes não são muito adequadas para isso. Se você está pronto para seguir esse caminho - estou esperando por você :)
Conteúdo
Tempo e meios de compreensão - profiler
Do ponto de vista cotidiano, 1 segundo é muito pequeno. Mas sabemos que 1 segundo é um bilhão inteiro de nanossegundos. E deixe levar cerca de 4 ciclos do processador em apenas 1 nanossegundo. Em 1 segundo, muitas coisas são feitas no computador que podem melhorar ou piorar nossas vidas.
Suponha que estamos desenvolvendo um aplicativo que por si só é crítico o suficiente para acelerar, e para alguns fragmentos de código isso geralmente é crítico. Essas partes são executadas, digamos, centenas de microssegundos - com rapidez suficiente, mas elas [
seções do código ] afetam diretamente o sucesso do nosso aplicativo e a quantidade de dinheiro ganho ou perdido. Por exemplo
ao enviar ordens para concluir transações de câmbio, um atraso de 100 microssegundos pode custar à troca 1 milhão de rublos ou mais em cada transação, completada por um, não dois, ou mesmo cem.
E a
tarefa foi definida para mim: por um lado, você precisa enviar todos os pedidos ao mesmo tempo e, por outro lado, enviá-los para que a variação entre o primeiro e o último seja mínima. Ou seja, era necessário criar um perfil de uma função que envia pedidos para a central. Uma tarefa típica, exceto por uma pequena nuance: o tempo de execução característico dessa função é
significativamente menor que 100 μs .
Vamos pensar em como traçamos esses 100 μs para entender o que está acontecendo lá dentro.
O que considerar ao escolher esta ferramenta?
- A seção de código que nos interessa raramente é executada, ou seja, 100 microssegundos são executados em algum lugar uma vez por segundo. E isso está na bancada de testes e ainda menos na produção.
- Será difícil isolar esse trecho de código em uma marca de microbench, porque afeta uma parte significativa do projeto e até mesmo a entrada / saída da rede.
- E, finalmente, o mais importante, quero que o perfil resultante corresponda ao comportamento que estará em nossos servidores de produção.
Como levamos em conta todas essas nuances e definimos corretamente o método de interesse?
Conceitualmente, todos os criadores de perfil podem ser divididos em dois grupos de
instrumentadores ou
amostragem . Vamos considerar cada grupo separadamente.
Os criadores de perfil de ferramentas contribuem com bastante sobrecarga porque modificam nosso bytecode e inserem um registro de temporização nele. Daí a principal desvantagem de tais criadores de perfil: eles podem afetar significativamente o código executável. Como resultado, será difícil dizer o quanto o perfil resultante corresponde ao comportamento nos servidores de produção: algumas otimizações podem funcionar de maneira diferente, outras acontecem e outras não. Talvez, em outras escalas de tempo - segundos, minutos, horas - tenhamos dados representativos. Porém, em uma escala de 100 μs, a otimização acionada ou com falha pode levar o perfil a não ser representativo. Então, vamos dar uma olhada em outro grupo de criadores de perfil.
Os criadores de perfil de amostragem contribuem para sobrecarga mínima ou moderada. Essas ferramentas não afetam diretamente o código executável e seu uso requer um pouco mais de atenção de você. Portanto, vamos nos concentrar nos criadores de perfil de amostragem. Vamos ver quais dados e de que forma receberemos deles.
Como funcionam os criadores de perfil de amostragem?
Para entender como um criador de perfil de amostra funciona, considere o exemplo a seguir - o método
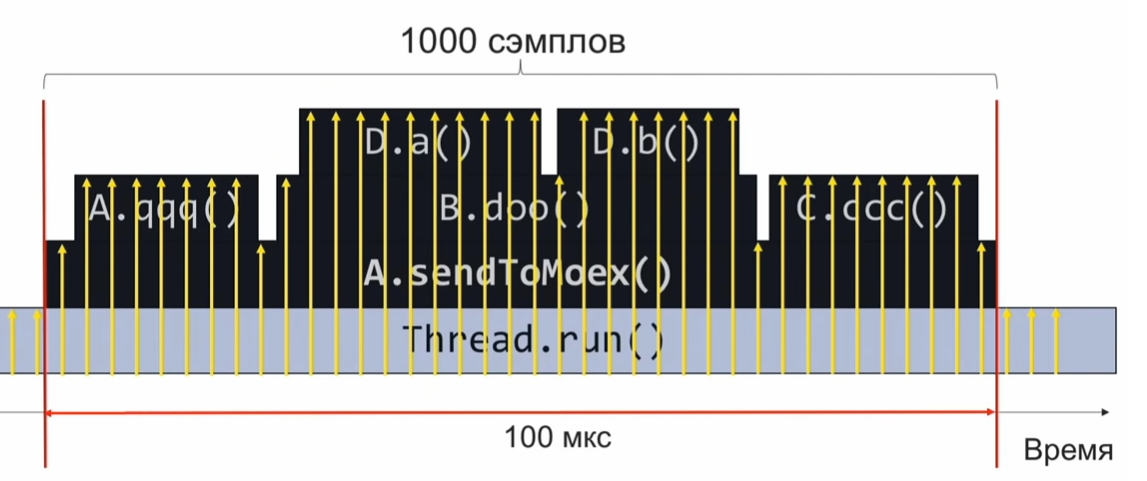
sendToMoex chama vários outros métodos. Nós olhamos:
void sendToMoex() { a.qqq(); b.doo(); c.ccc() } void doo() { da(); db(); }
Se monitorarmos o estado da pilha de chamadas no momento da execução desta seção do programa e a registrarmos periodicamente, receberemos informações aproximadamente da seguinte forma:

Este é um conjunto de pilhas de chamadas. Supondo que as amostras sejam distribuídas igualmente, o número de pilhas idênticas indica o tempo de execução relativo do método que está no topo da pilha.
Neste exemplo, o método Da foi executado tanto quanto o método C.ccc, e isso é 2 vezes mais que o método Db. No entanto, a suposição de que a distribuição de amostras é uniforme pode não estar completamente correta e, portanto, a estimativa do tempo de execução estará incorreta.
Quantas vezes precisamos provar?
Suponha que queremos coletar 1000 amostras em 100 microssegundos para entender o que foi reproduzido por dentro. Em seguida, calculamos com uma proporção simples que, se precisarmos fazer 1000 amostras em 100 μs, serão 10 milhões de amostras em 1 segundo ou 10.000.000 de amostras / s.
Se fizermos uma amostragem nessa velocidade, em uma execução do código, coletaremos 1000 amostras, agregamos e entenderemos o que funcionou rápida ou lentamente. Depois disso, analisaremos o desempenho e ajustaremos o código.
No entanto, uma frequência de 10 milhões de amostras por segundo é muito. E se falharmos em atingir tal velocidade de criação de perfil desde o início? Suponha que coletamos para 10 µs apenas 10 amostras, e não 1000. Nesse caso, precisamos aguardar a próxima execução do código de perfil, que ocorrerá após 1 segundo (afinal, o código de perfil é executado uma vez por segundo). Então, vamos coletar mais 10 amostras. Como eles são distribuídos igualmente conosco, eles podem ser combinados em um conjunto comum. Basta esperar até que o código de perfil seja executado 1000/10 = 100 vezes, e coletaremos as 1000 amostras necessárias (10 amostras cada uma das 100 vezes).
Escolha um profiler
Armado com esse conhecimento teórico, vamos à prática.
Tome o
Async-profiler. Uma ótima ferramenta (usa a chamada de máquina virtual AsyncGetCallTrace) que coleta a pilha de chamadas até a instrução do código de bytes da máquina virtual Java. A taxa de amostragem nativa do criador de perfis de assinaturas é de
1000 amostras por segundo .
Resolveremos uma proporção simples: 10.000.000 amostras / s - 1 segundo, 1000 amostras / s - X segundos.
Concluímos que na frequência de amostragem padrão do async-profiler, a criação de perfil levará cerca de 3 horas. Faz muito tempo. Idealmente, quero montar o perfil o mais rápido possível, na velocidade superluminal.
Vamos tentar fazer overclock do
Async-profiler . Para fazer isso, no leia-me, encontramos o sinalizador
-i , que define o intervalo de amostragem. Vamos tentar definir o sinalizador
-i1 (1 nanossegundo) ou
-i0 em geral, para que o criador de perfil seja
-i0 sem parar. Eu tenho uma frequência de cerca de 2,5 mil amostras por segundo. Nesse caso, a duração total da criação de perfil será de aproximadamente 1 hora. Claro, não 3 horas, mas também não muito rápido. Parece que, para atingir as velocidades de criação de perfil necessárias, é necessário fazer algo qualitativamente diferente, para atingir um novo nível.
Para obter frequências significativamente mais altas, você terá que abandonar a chamada AsyncGetCallTrace e usar o
perf , o criador de perfil Linux em tempo integral encontrado em todas as distribuições Linux. No entanto, o perf não sabe nada sobre Java, e ainda precisamos treiná-lo para trabalhar com Java. Enquanto isso, vamos tentar executar o perf desta maneira assustadora:
$ perf record –F 10000 -p PID -g -- sleep 1 [ perf record: Woken up 1 times to write data ] [ perf record: .. 0.215 MB perf.data (4032 samples) ]
Mais sobre notação- registro perf significa que queremos gravar um perfil.
- O sinalizador
-F e o argumento 10.000 são a taxa de amostragem. - O sinalizador
-p indica que queremos criar um perfil apenas do PID específico do nosso processo Java. - O sinalizador
-g é responsável por coletar pilhas de chamadas. - Finalmente, com o sono 1, limitamos a entrada do perfil a 1 segundo.
Por que precisamos coletar pilhas de chamadas? Nós perfilamos tudo em uma linha e, a partir dos dados coletados, extraímos a parte que nos interessa (o método responsável pela formação e envio de pedidos). O marcador que a amostra coletada pertence aos dados nos quais estamos interessados é a presença do quadro de pilha da
chamada do método
sendToMoex .
Aprenda perf para criar um perfil de aplicativo Java.
Executamos o comando perf record ..., esperamos 1 segundo e executamos o script perf para ver o que foi perfilado? E veremos algo não muito claro:
$ perf script java 8079 2008793.746571: 3745505 cycles:uppp: 7fa1e88b53f8 [unknown] (/tmp/perf-11038.map) java 8079 2008793.747565: 3728336 cycles:uppp: 7fa1e88b5372 [unknown] (/tmp/perf-11038.map) java 8079 2008793.748613: 3731147 cycles:uppp: 7fa1e88b53ef [unknown] (/tmp/perf-11038.map)
Parece ser endereços, mas não há nomes de métodos Java. Portanto, você precisa ensinar o perf para combinar esses endereços com os nomes dos métodos.
No mundo de C e C ++, as chamadas informações de depuração são usadas para corresponder endereços e nomes de funções. Uma correspondência é armazenada em uma seção especial do arquivo executável: um método está nesses endereços, outro método está em outros endereços. O Perf obtém essas informações e faz um mapeamento.
Obviamente, o compilador JIT da máquina virtual não gera informações de depuração nesse formato. Ainda temos outra maneira - escrever dados sobre a correspondência de endereços e nomes de métodos em um arquivo perf-map especial, que o perf tratará como um complemento às informações de depuração lidas. Esse arquivo perf-map deve estar na pasta tmp e ter a seguinte estrutura de dados:
A primeira coluna é o endereço do início do código do método, a segunda é o seu comprimento, a terceira coluna é o nome do método.
Portanto, precisamos gerar um arquivo semelhante. Obviamente, não conseguiremos fazer isso manualmente (como sabemos em que endereço o compilador JIT colocará o código); portanto, usaremos o script create-java-perf-map.sh do projeto perf-map-agent, passando o PID do nosso processo Java . O arquivo está pronto, verifique seu conteúdo, execute o perf-script novamente.
$ perf script java 8080 1895245.867498: cycles:uppp: 7fb2dd10f527 Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868176: 2127960 cycles:uppp: 7fb2dd10f57f Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868737: 1959990 cycles:uppp: 7fb2dd10f627 Loop3.doRecursiveCall (/tmp/perf-8079.map)
Voila! Vemos os nomes dos métodos java! O que aconteceu: ensinamos o perf profiler, que não sabe nada sobre Java, a criar um perfil de um aplicativo Java comum e ver os métodos hot java desse aplicativo!
No entanto, para analisar o desempenho da parte do programa que estamos interrogando, não temos pilha de chamadas suficiente para filtrar os dados de interesse de todas as amostras coletadas.
Como obter uma pilha de chamadas?Agora você precisa fazer outra coisa com perf ou uma máquina virtual para obter pilhas de chamadas. Para entender o que precisa ser feito, vamos dar um passo atrás e ver como a pilha geralmente funciona. Imagine que temos três funções f1, f2, f3. Além disso, f1 chama f2 e f2 chama f3.
void f1() { f2(); } void f2() { f3(); } void f3() { ... }
No momento em que a função
f3 executada, vamos ver em que estado a pilha está. Vemos o registro
rsp , que aponta para o topo da pilha. Também sabemos que a pilha possui o endereço do quadro anterior. E como posso obter uma pilha de chamadas?
Se, de alguma forma, pudéssemos obter o endereço dessa área, poderíamos imaginar a pilha como uma lista simplesmente conectada e entender a sequência de chamadas que nos levaram ao ponto de execução atual.
Do que precisamos para isso? Precisamos de um registro rbp extra que aponte para a área amarela. Acontece que o registro rbp permite que o perf obtenha a pilha de chamadas, entenda a sequência que nos levou ao ponto atual. Eu recomendo a leitura desses detalhes na
interface binária do aplicativo System V. Ele descreve como os métodos são chamados no Linux.

Nós entendemos qual é o nosso problema. Precisamos forçar a máquina virtual a usar o registro rbp para sua finalidade original - como um ponteiro para o início do quadro da pilha. É assim que o compilador JIT deve usar o registro rbp. Há um sinalizador PreserveFramePointer na máquina virtual para isso. Quando passamos esse sinalizador para a máquina virtual, a máquina virtual começará a usar o registro rbp para sua finalidade tradicional. E então o Perf pode girar a pilha. E temos uma pilha de chamadas real no perfil. A bandeira foi contribuída pelo notório Brendan Gregg em apenas JDK8u60.
Iniciamos a máquina virtual com uma nova bandeira. Execute
create-java-perf-map , em seguida,
perf record e
perf script . Agora podemos criar um perfil preciso com pilhas de chamadas:
$ perf script java 18657 1901247.601878: 979583 cycles:uppp: 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7f285d007b10 Interpreter (...) 7f285d0004e7 call_stub (...) 67d0db [unknown] (... libjvm.so) ... 708c start_thread (... libpthread-2.26.so)
Ensinamos o perf profiler, incluído na maioria das distribuições Linux, a trabalhar com aplicativos Java. Portanto, agora podemos ver não apenas as seções importantes do código, mas também a sequência de chamadas que levaram ao ponto ativo atual. Uma grande conquista, já que o perf profiler não sabe nada sobre java. Acabamos de ensinar a tudo isso!
Aumentar a taxa de amostragem de perf
Vamos tentar fazer um overclock do perf para 10 milhões de amostras por segundo. Agora temos uma frequência significativamente menor.
Para automatizar todas as tarefas que acabamos de executar, você pode usar o script
perf-java-record-stack do projeto perf-map-agent. Ele tem uma caneta maravilhosa - a variável de ambiente
perf_record-freq , com a qual você pode definir a frequência de amostragem. Primeiro, vamos definir 100 mil amostras por segundo e tentar executar. Uma mensagem terrível aparece no console informando que excedeu a frequência de amostragem máxima permitida:
$ PERF_RECORD_FREQ=100000 ./bin/perf-java-record-stack PID ... Maximum frequency rate (30000) reached. Please use -F freq option with lower value or consider tweaking /proc/sys/kernel/perf_event_max_sample_rate. ...
No meu caso, o limite foi de 30 mil amostras por segundo. O Perf diz imediatamente qual argumento do kernel precisa ser corrigido, o que faremos usando echo sudo tee no arquivo desejado ou diretamente através do
sysctl . Então:
$ echo '1000000' | sudo tee /proc/sys/kernel/perf_event_max_sample_rate
ou mais:
$ sudo sysctl kernel.perf_event_max_sample_rate=1000000
Agora, estamos dizendo ao kernel que o limite superior da frequência agora é de 1 milhão de amostras por segundo. Iniciamos o criador de perfil novamente e indicamos a frequência de 200 mil amostras por segundo. O criador de perfil funcionará por 15 segundos e fornecerá 1 milhão de amostras. Tudo parece estar bem. Pelo menos nenhuma mensagem de erro formidável. Mas que frequência nós realmente recebemos? Acontece que apenas 70 mil amostras por segundo. O que deu errado?
Vamos ver a saída do
dmesg :
[84430.412898] perf: interrupt took too long (1783 > 200), lowering kernel.perf_event_max_sample_rate to 89700 ... [84431.618452] perf: interrupt took too long (2229 > 2228), lowering kernel.perf_event_max_sample_rate to 71700
Esta é a saída do kernel do Linux. Ele percebeu que amostramos com muita frequência e leva muito tempo, portanto o kernel diminui a frequência. Acontece que precisamos desaparafusar outro identificador no kernel - ele é chamado
kernel.perf_cpu_time_max_percent e controla a quantidade de tempo que o kernel pode gastar em interrupções do perf.
Pediremos uma frequência de amostragem de 200 mil amostras por segundo. E após 15 segundos, obtemos 3 milhões de amostras - 200 mil amostras por segundo.
$ PERF_RECORD_FREQ=200000 ./bin/perf-java-record-stack PID Recording events for 15 seconds ... ... [ perf record: Captured ... (2.961.252 samples) ]
Agora vamos ver o perfil. Execute o
perf script :
$ perf script ... java ... native_write_msr (/.../vmlinux) java ... Loop2.main (/tmp/perf-29621.map) java ... native_write_msr (/.../vmlinux) ...
Vemos funções estranhas e o módulo executável vmlinux - o kernel do Linux. Definitivamente, este não é o nosso código. O que aconteceu? A frequência acabou sendo tão alta que o código do kernel começou a cair nas amostras. Ou seja, quanto maior aumentarmos a frequência, mais haverá amostras que não estão relacionadas ao nosso código, mas ao kernel do Linux.
Beco sem saída.
Usamos (explicitamente) eventos de PMU / PEBS de hardware
Então decidi tentar usar a tecnologia de hardware PMU / PEBS - Performance Monitoring Unit, Precise Event Based Sampling. Ele permite que você receba notificações de que um evento ocorreu um determinado número de vezes. Isso é chamado de "período". Por exemplo, podemos receber notificações sobre a execução pelo processador de cada 20ª instrução. Vejamos um exemplo. Deixe a instrução xor ser executada agora e o contador da PMU obter o valor 18; depois vem a instrução mov - o contador é 19; e a próxima instrução,
adicione% r14,% r13 , a PMU será exibida como "quente".
Em seguida, um novo ciclo começa:
inc é executado - a PMU é redefinida para 1. Mais algumas iterações do ciclo passam. No final, paramos na instrução
mov , a PMU tira 19. A próxima instrução add e novamente a marcamos como quente. Veja a lista:
mov aaa, bbbb xor %rdx, %rdx L_START: mov $0x0(%rbx, %rdx),%r14 add %r14, %r13 ; (PMU "") cmp %rdx,100000000 jne L_START
Não percebe as esquisitices? Um ciclo de cinco instruções, mas cada vez que marcamos a mesma instrução como quente. Obviamente, isso não é verdade: todas as instruções são "quentes". Eles também gastam tempo e marcamos apenas um. O fato é que, entre o período e o contador do número de instruções na iteração, temos um fator comum 4. Acontece que a cada quarta iteração, marcaremos a mesma instrução como "quente". Para evitar esse comportamento, você precisa escolher um número como um período no qual a probabilidade de um divisor comum entre o número de iterações no loop e o próprio contador é minimizada. Idealmente, o período deve ser primo, ou seja, compartilhe somente consigo mesmo e com a unidade. Para o exemplo acima: você deve escolher um período igual a 23. Em seguida, marcamos uniformemente todas as instruções deste ciclo como "quentes".
A tecnologia PMU / PEBS é suportada em sua forma moderna desde pelo menos 2009, ou seja, está disponível em praticamente qualquer computador. Para aplicá-lo explicitamente, vamos modificar o script
perf-java-record-stack . Substitua o sinalizador
-F por
-e , que especifica explicitamente o uso de PMU / PEBS.
... sudo perf record -F $PERF_RECORD_FREQ ... ...
Transformando o script:
... sudo perf record -e cycles –c 10007 ... ...
Você já sabe quais propriedades um período deve ter - precisamos de um número primo. Para o nosso caso, será o período 10007.
Eles lançaram o script perf-java-record-stack modificado e obtiveram 4,5 milhões de amostras em 15 segundos - quase 300 mil amostras por segundo, uma amostra a cada 3 microssegundos. Ou seja, para uma execução de nosso código de perfil, por 100 μs, coletaremos 33 amostras. Nessa frequência, o tempo total de coleta de perfis é de apenas 30 segundos. Nem beba uma xícara de café! Na realidade, tudo é um pouco mais complicado. O que acontece se nosso código começar a ser executado não uma vez por segundo, mas uma vez a cada 5 segundos? Em seguida, a duração do perfil aumentará para 2,5 minutos, o que também é um resultado decente.
Assim, em 30 segundos você pode obter um perfil que cubra completamente todas as nossas necessidades de pesquisa. Vitória
Mas a sensação de algum truque sujo não me deixou. Vamos voltar à situação em que nosso código é executado a cada 5 segundos. A criação de perfil levará 150 segundos, durante os quais coletaremos cerca de 45 milhões de amostras. Desses, precisamos apenas de 1000, ou seja, 0,002% dos dados coletados. Todo o resto é lixo, o que atrasa o trabalho de outras ferramentas e aumenta a sobrecarga. Sim, o problema está resolvido, mas na testa, força suja e contundente.
E naquela noite, quando obtive um perfil tão detalhado com a ajuda do perf, tive um sonho. Eu estava voltando para casa do trabalho e pensando, mas seria bom se o ferro fosse capaz de montar o perfil em si e até a precisão das microestruturas e microssegundos, e analisaríamos apenas os resultados. Meu sonho se tornará realidade? O que você acha?
Breve resumo:
- Para criar um perfil de um aplicativo Java usando perf, você precisa gerar um arquivo com informações sobre símbolos usando scripts do projeto perf-map-agent
- Para coletar informações não apenas sobre seções importantes do código, mas também sobre pilhas, você precisa executar uma máquina virtual com o sinalizador -XX: + PreserveFramePointer
- Se você deseja aumentar a frequência de amostragem, preste atenção no sysctl'i e no kernel.perf_cpu_time_max_percent e no kernel.perf_event_max_sample_rate.
- Se amostras do kernel que não estão relacionadas ao aplicativo começaram a entrar no perfil, pense em especificar explicitamente o período da PMU / PEBS.
Este artigo (e suas partes subseqüentes) é uma transcrição do relatório, adaptada em forma de texto. Se você deseja não apenas ler, mas também ouvir sobre criação de perfil, uma
referência à apresentação.