Em aplicativos móveis, a função de pesquisa é muito popular. E se isso puder ser negligenciado em produtos pequenos, em aplicativos que fornecem acesso a uma grande quantidade de informações, você não pode ficar sem uma pesquisa. Hoje vou lhe dizer como implementar corretamente essa função em programas para Android.

Abordagens para a implementação da pesquisa em um aplicativo móvel
- Pesquisar como um filtro de dados
Geralmente, parece uma barra de pesquisa acima de alguma lista. Ou seja, apenas filtramos os dados concluídos. - Pesquisa de servidor
Nesse caso, fornecemos toda a implementação ao servidor, e o aplicativo atua como um thin client, do qual é necessário apenas mostrar os dados da forma correta. - Pesquisa Integrada
- o aplicativo contém uma grande quantidade de dados de vários tipos;
- o aplicativo funciona offline;
- A pesquisa é necessária como um único ponto de acesso às seções / conteúdo do aplicativo.
Neste último caso, a pesquisa de texto completo incorporada ao SQLite vem em socorro. Com ele, é possível encontrar rapidamente correspondências em uma grande quantidade de informações, o que nos permite fazer várias consultas em tabelas diferentes sem sacrificar o desempenho.
Considere a implementação dessa pesquisa usando um exemplo específico.
Preparação de dados
Digamos que precisamos implementar um aplicativo que mostre uma lista de filmes do
themoviedb.org . Para simplificar (para não ficar online), pegue uma lista de filmes e forme um arquivo JSON, coloque-o em ativos e preencha nosso banco de dados localmente.
Estrutura de arquivo JSON de exemplo:
[ { "id": 278, "title": " ", "overview": " ..." }, { "id": 238, "title": " ", "overview": " , ..." }, { "id": 424, "title": " ", "overview": " ..." } ]
Preenchimento de banco de dados
O SQLite usa tabelas virtuais para implementar a pesquisa de texto completo. Externamente, eles se parecem com tabelas SQLite regulares, mas qualquer acesso a elas faz algum trabalho nos bastidores.
As tabelas virtuais nos permitem acelerar a pesquisa. Mas, além das vantagens, elas também têm desvantagens:
- Você não pode criar um gatilho em uma tabela virtual;
- Você não pode executar os comandos ALTER TABLE e ADD COLUMN para uma tabela virtual;
- cada coluna na tabela virtual é indexada, o que significa que os recursos podem ser desperdiçados em colunas de indexação que não devem estar envolvidas na pesquisa.
Para resolver o último problema, você pode usar tabelas adicionais que conterão parte das informações e armazenar links para elementos de uma tabela regular em uma tabela virtual.
Criar uma tabela é um pouco diferente do padrão, temos as palavras-chave
VIRTUAL e
fts4 :
CREATE VIRTUAL TABLE movies USING fts4(id, title, overview);
Comentando a versão fts5Já foi adicionado ao SQLite. Esta versão é mais produtiva, mais precisa e contém muitos novos recursos. Mas, devido à grande fragmentação do Android, não podemos usar o fts5 (disponível com API24) em todos os dispositivos. Você pode escrever lógicas diferentes para diferentes versões do sistema operacional, mas isso complicará seriamente o desenvolvimento e o suporte. Decidimos seguir o caminho mais fácil e usar o fts4, que é suportado na maioria dos dispositivos.
O preenchimento não é diferente do habitual:
fun populate(context: Context) { val movies: MutableList<Movie> = mutableListOf() context.assets.open("movies.json").use { val typeToken = object : TypeToken<List<Movie>>() {}.type movies.addAll(Gson().fromJson(InputStreamReader(it), typeToken)) } try { writableDatabase.beginTransaction() movies.forEach { movie -> val values = ContentValues().apply { put("id", movie.id) put("title", movie.title) put("overview", movie.overview) } writableDatabase.insert("movies", null, values) } writableDatabase.setTransactionSuccessful() } finally { writableDatabase.endTransaction() } }
Versão básica
Ao executar a consulta, a palavra-chave
MATCH é usada em vez de
LIKE :
fun firstSearch(searchString: String): List<Movie> { val query = "SELECT * FROM movies WHERE movies MATCH '$searchString'" val cursor = readableDatabase.rawQuery(query, null) val result = mutableListOf<Movie>() cursor?.use { if (!cursor.moveToFirst()) return result while (!cursor.isAfterLast) { val id = cursor.getInt("id") val title = cursor.getString("title") val overview = cursor.getString("overview") result.add(Movie(id, title, overview)) cursor.moveToNext() } } return result }
Para implementar o processamento de entrada de texto na interface, usaremos o
RxJava :
RxTextView.afterTextChangeEvents(findViewById(R.id.editText)) .debounce(500, TimeUnit.MILLISECONDS) .map { it.editable().toString() } .filter { it.isNotEmpty() && it.length > 2 } .map(dbHelper::firstSearch) .subscribeOn(Schedulers.computation()) .observeOn(AndroidSchedulers.mainThread()) .subscribe(movieAdapter::updateMovies)
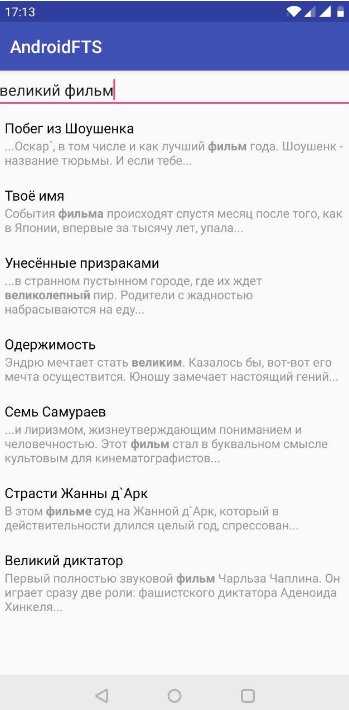
O resultado é uma opção de pesquisa básica. No primeiro elemento, a palavra desejada foi encontrada na descrição e no segundo elemento, tanto no título quanto na descrição. Obviamente, desta forma, não está totalmente claro o que encontramos. Vamos consertar.
Adicionar acentos
Para melhorar a obviedade da pesquisa, usaremos a função auxiliar
SNIPPET . É usado para exibir um fragmento de texto formatado no qual uma correspondência é encontrada.
snippet(movies, '<b>', '</b>', '...', 1, 15)
- filmes - nome da tabela;
- <b & gt e </b> - esses argumentos são usados para destacar uma seção do texto que foi pesquisada;
- ... - para a concepção do texto, se o resultado for um valor incompleto;
- 1 - número da coluna da tabela na qual serão alocados trechos de texto;
- 15 é um número aproximado de palavras incluídas no valor de texto retornado.
O código é idêntico ao primeiro, sem contar a solicitação:
SELECT id, snippet(movies, '<b>', '</b>', '...', 1, 15) title, snippet(movies, '<b>', '</b>', '...', 2, 15) overview FROM movies WHERE movies MATCH ''
Tentamos novamente:
Acabou mais claramente do que na versão anterior. Mas este não é o fim. Vamos tornar nossa pesquisa mais "completa". Usaremos a análise lexical e destacaremos as partes significativas de nossa consulta de pesquisa.
Melhoria de acabamento
O SQLite possui tokens internos que permitem executar análises lexicais e transformar a consulta de pesquisa original. Se, ao criar a tabela, não especificamos um tokenizador específico, então “simples” será selecionado. De fato, ele apenas converte nossos dados para minúsculas e descarta caracteres ilegíveis. Não nos convém.
Para uma melhoria qualitativa na pesquisa, precisamos usar o
stemming - o processo de encontrar a base da palavra para uma determinada palavra-fonte.
O SQLite possui um tokenizer interno adicional que usa o algoritmo Porter Stemmer. Esse algoritmo aplica sequencialmente várias regras, destacando partes significativas de uma palavra cortando finais e sufixos. Por exemplo, ao procurar por "chaves", podemos obter uma pesquisa onde as palavras "chave", "chaves" e "chave" estão contidas. Vou deixar um link para uma descrição detalhada do algoritmo no final.
Infelizmente, o tokenizer embutido no SQLite funciona apenas em inglês; portanto, para o idioma russo, você precisa escrever sua própria implementação ou usar desenvolvimentos prontos. Tomaremos a implementação finalizada no site
algoritmist.ru .
Transformamos nossa consulta de pesquisa no formulário necessário:
- Remova caracteres extras.
- Divida a frase em palavras.
- Pule a haste.
- Colete em uma consulta de pesquisa.
Algoritmo de Porter object Porter { private val PERFECTIVEGROUND = Pattern.compile("((|||||)|((<=[])(||)))$") private val REFLEXIVE = Pattern.compile("([])$") private val ADJECTIVE = Pattern.compile("(|||||||||||||||||||||||||)$") private val PARTICIPLE = Pattern.compile("((||)|((?<=[])(||||)))$") private val VERB = Pattern.compile("((||||||||||||||||||||||||||||)|((?<=[])(||||||||||||||||)))$") private val NOUN = Pattern.compile("(|||||||||||||||||||||||||||||||||||)$") private val RVRE = Pattern.compile("^(.*?[])(.*)$") private val DERIVATIONAL = Pattern.compile(".*[^]+[].*?$") private val DER = Pattern.compile("?$") private val SUPERLATIVE = Pattern.compile("(|)$") private val I = Pattern.compile("$") private val P = Pattern.compile("$") private val NN = Pattern.compile("$") fun stem(words: String): String { var word = words word = word.toLowerCase() word = word.replace('', '') val m = RVRE.matcher(word) if (m.matches()) { val pre = m.group(1) var rv = m.group(2) var temp = PERFECTIVEGROUND.matcher(rv).replaceFirst("") if (temp == rv) { rv = REFLEXIVE.matcher(rv).replaceFirst("") temp = ADJECTIVE.matcher(rv).replaceFirst("") if (temp != rv) { rv = temp rv = PARTICIPLE.matcher(rv).replaceFirst("") } else { temp = VERB.matcher(rv).replaceFirst("") if (temp == rv) { rv = NOUN.matcher(rv).replaceFirst("") } else { rv = temp } } } else { rv = temp } rv = I.matcher(rv).replaceFirst("") if (DERIVATIONAL.matcher(rv).matches()) { rv = DER.matcher(rv).replaceFirst("") } temp = P.matcher(rv).replaceFirst("") if (temp == rv) { rv = SUPERLATIVE.matcher(rv).replaceFirst("") rv = NN.matcher(rv).replaceFirst("") } else { rv = temp } word = pre + rv } return word } }
Algoritmo em que dividimos a frase em palavras val words = searchString .replace("\"(\\[\"]|.*)?\"".toRegex(), " ") .split("[^\\p{Alpha}]+".toRegex()) .filter { it.isNotBlank() } .map(Porter::stem) .filter { it.length > 2 } .joinToString(separator = " OR ", transform = { "$it*" })
Após essa conversão, a frase "pátios e fantasmas" se parece com "quintal
* OU fantasma
* ".
O símbolo "
* " significa que a pesquisa será realizada pela ocorrência de uma determinada palavra em outras palavras. O operador "
OU " significa que serão mostrados resultados que contêm pelo menos uma palavra da frase de pesquisa. Nós olhamos:
Sumário
A pesquisa de texto completo não é tão complicada quanto parece à primeira vista. Analisamos um exemplo específico que você pode implementar rápida e facilmente em seu projeto. Se você precisar de algo mais complicado, consulte a documentação, pois há uma e está muito bem escrita.
Referências: