
Os aplicativos Deep Learning mudaram muitas coisas. Alguns que dão esperança para um futuro melhor e outros que levantam suspeitas. No entanto, para os desenvolvedores, o crescimento de aplicativos de aprendizado profundo os deixou mais perplexos quanto à escolha do melhor dentre tantas estruturas de aprendizado profundo existentes.
O TensorFlow é uma das estruturas de aprendizado profundo que vem à mente. É sem dúvida a estrutura de aprendizado profundo mais popular do mercado. Nada justifica a afirmação melhor do que o fato de o Tensorflow ser usado por empresas como Uber, Nvidia, Gmail, entre outras grandes corporações, para o desenvolvimento de aplicativos avançados de aprendizado profundo.
Mas, no momento, estou em uma busca para descobrir se realmente é a melhor estrutura de aprendizado profundo. Ou talvez descubra o que o torna o melhor de todas as outras estruturas em que compete.
Aqui está tudo sobre o TensorFlow 2.0
A maioria dos desenvolvedores e cientistas de dados prefere usar o Python com o TensorFlow. O TensorFlow funciona não apenas no Windows, Linux e Mac, mas também nos sistemas operacionais iOS e Android.
TF usa um gráfico de computação estática para operações. Isso significa que os desenvolvedores primeiro definem o gráfico, executam todos os cálculos, fazem alterações na arquitetura, se necessário, e depois treinam novamente o modelo. Em geral, muitos conceitos de aprendizado de máquina e aprendizado profundo podem ser resolvidos usando matrizes multidimensionais. É isso que o Tensorflow 2.0 faz que ajuda a descrever relacionamentos lineares entre objetos geométricos. O tensor é uma unidade primitiva onde podemos aplicar operações de matriz com facilidade e eficácia.
import tensorflow as TF const1 = TF.constant([[05,04,03], [05,04,03]]); const2 = TF.constant([[01,02,00], [01,02,00]]); result = TF.subtract(const1, const2); print(result)
A saída do código acima será assim: TF.Tensor([[04 02 03] [04 02 03]])
Como você pode ver, dei aqui duas constantes e subtraí um valor do outro e obtive um objeto Tensor subtraindo dois valores. Além disso, com o Tensorflow 2.0, não há necessidade de criar sessões antes de executar o código.
Uma coisa a saber antes de trabalhar com o TensorFlow 2.0 é que você precisará codificar muito e também não precisará executar operações aritméticas com o TensorFlow. É mais sobre pesquisa profunda, construção de preditores de IA, classificadores, modelos generativos, redes neurais e assim por diante. Certamente, o TF ajuda com o último, mas tarefas importantes, como definir a arquitetura da rede neural, definir um volume para dados de saída e entrada, tudo precisa ser feito com cuidadoso pensamento humano.
A maneira mais rápida de treinar esses modelos de IA é a unidade de processamento tensorial (TPUs) introduzida pelo Google em 2016. A TPU lida com a questão do treinamento em redes neurais de várias maneiras.
Quantização - É uma ferramenta poderosa que usa um número inteiro de 8 bits para calcular uma previsão de rede neural. Por exemplo, ao aplicar a quantização a um modelo de reconhecimento de imagem como o Inception v3, você o compactará cerca de um quarto do tamanho original de 91 MB a 23 MB.
Processamento paralelo - O processamento paralelo na unidade multiplicadora Matrix é uma maneira bem conhecida de melhorar o desempenho de grandes operações matriciais através do processamento vetorial. Máquinas com suporte ao processamento vetorial podem processar até centenas e milhares de elementos de operações em um único ciclo de clock.
CISC - TPU trabalha em um design CISC que se concentra na implementação de instruções de alto nível que executam tarefas de alto nível, como multiplicar e adicionar várias vezes, etc. A TPU usa os seguintes recursos para executar tarefas complexas:
- Unidade multiplicadora de matriz (MXU): 65.536 unidades de multiplicar e adicionar de 8 bits para operações de matriz.
- Buffer unificado (UB): 24 MB de SRAM que funcionam como registradores.
- Unidade de Ativação (AU): Funções de ativação com fio.
Matriz sistólica - A matriz sistólica é baseada na nova arquitetura do MXU, também chamada de coração do TPU. O MXU leu o valor uma vez, mas o utiliza para muitas operações diferentes sem armazená-lo novamente em um registro. Ele reutiliza a entrada muitas vezes para produzir a saída. Essa matriz é chamada sistólica porque os dados fluem através do chip em ondas da mesma maneira que nosso coração bombeia sangue. Melhora a flexibilidade operacional na codificação e oferece uma taxa de densidade de operação muito maior.
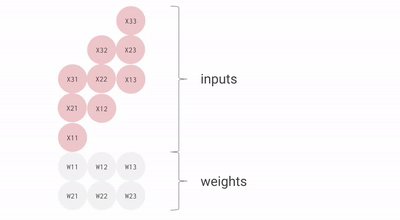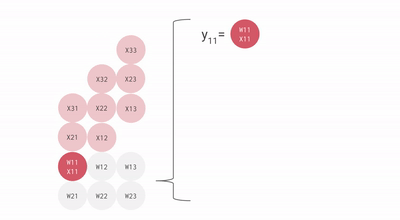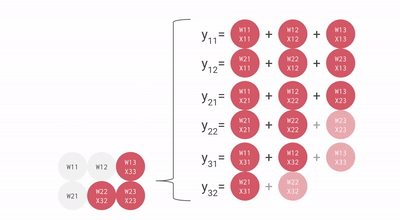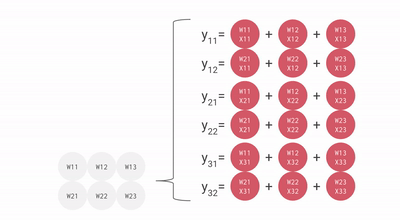
Como você pode ver, todos esses pontos importantes do TPU ajudam a analisar e manipular os dados de maneira eficaz. Além disso, ele fornece conjuntos de dados TensorFlow que os desenvolvedores podem usar para treinar algumas das soluções de IA personalizadas e para trabalhos de pesquisa adicionais.
Também de acordo com a atualização mais recente, a Cerebras Systems (uma nova empresa de inteligência artificial) revela o maior chip semicondutor baseado no modelo TPU. Nesse chip, você pode encontrar o maior processador já criado, projetado para processar, treinar e manipular os aplicativos de IA. O chip gigante é igual ao tamanho de um iPad e comporta 1,2 trilhões de transistores.Uma das maiores vantagens do TensorFlow em relação a outras estruturas de aprendizado profundo é em termos de escalabilidade. Diferentemente de outras estruturas, como o PyTorch, o TensorFlow foi desenvolvido para inferência em larga escala e treinamento distribuído. No entanto, também pode ser usado para experimentar novos modelos e otimização de aprendizado de máquina. Essa flexibilidade também permite que os desenvolvedores implantem modelos de aprendizado profundo em mais de uma única CPU / GPU com o TensorFlow.
Compatibilidade entre plataformas
O TensorFlow 2.0 é compatível com todas as principais plataformas de sistemas operacionais, como Windows, Linux, macOS, iOS e Android. Além disso, o Keras também pode ser usado com o TensorFlow como uma interface.
Escalabilidade de hardware
O TensorFlow 2.0 pode ser implantado em uma ampla variedade de máquinas de hardware, desde dispositivos celulares a computadores em larga escala com configurações complexas. Ele pode ser implantado em uma gama de máquinas de hardware, como dispositivos celulares e computadores com configurações complexas. Ele pode incorporar diferentes APIs para arquiteturas de aprendizado profundo em escala, como CNN ou RNN.
Visualização
A estrutura do TensorFlow baseia-se na computação gráfica e fornece uma ferramenta de visualização útil para fins de treinamento. Essa ferramenta de visualização, chamada TensorBoard, permite que os desenvolvedores visualizem a construção de uma rede neural, o que facilita a visualização e a solução de problemas.
Depuração
O Tensorflow permite que os usuários executem as subpartes de um gráfico para a introdução e recuperação de dados discretos no limite, fornecendo um método de depuração limpo.
Capacidade dinâmica de gráficos para fácil implantação
O TensorFlow usa um recurso chamado "Execução ansiosa" que facilita a capacidade de gráficos dinâmicos para facilitar a implantação. Ele permite salvar o gráfico como um buffer de protocolo que pode ser implantado em algo diferente das infraestruturas de relação python, por exemplo, Java.
Por que o TensorFlow continuará crescendo?
O TensorFlow possui a taxa de crescimento mais rápida dentre todas as outras estruturas de aprendizado profundo existentes hoje. Possui a maior atividade do GitHub entre todos os outros repositórios na seção de aprendizado profundo e o maior número de partidas também.
Na pesquisa anual do desenvolvedor do Stack Overflow 2019, o TensorFlow foi votado como a estrutura de aprendizado profundo mais popular, a segunda estrutura mais popular, o Torch / PyTorch estava muito longe.
Essas estatísticas são suficientes para provar o domínio do TensorFlow. Mas por quanto tempo ele vai sustentar esse crescimento? acabaria excedendo sua popularidade atual? Com a introdução e ótima recepção do TensorFlow 2.0, o último parece possível.