Poucos hosters oferecem tarifas VDS com uma alta velocidade de clock do processador, embora pareça que tudo é simples: inseri o i9 mais poderoso no servidor, configure o faturamento e pronto.
Quando preparamos as tarifas de alta CPU, descobrimos que:
- servidores i9 consomem toneladas de eletricidade
- pegar um equilíbrio e fazer uma tarifa lucrativa em hardware de alta qualidade não é fácil
- Os data centers preferem não mexer com isso
Nós dizemos como lidamos com isso e lançamos o Hi CPU.

Por que preciso de uma CPU alta
Preparamos a tarifa perfeita para o Bitrix. Porque
Claro, por causa do dinheiro.
 De acordo com o CMS iTrack
De acordo com o CMS iTrack , metade de todos os sites criados no CMS são WordPress e apenas 11,68% dos sites usam Bitrix. No entanto, de
acordo com a classificação da CMS Magazine , existem duas vezes mais sites comerciais usando Bitrix que WordPress. A maioria dos sites no WordPress - blogs, sites pessoais e outros cartões de visita.
Milhares de empresas russas usam o Bitrix, pronto para pagar por VDS de alta qualidade. E muitos precisam de soluções Hi-CPU que não são suficientes no mercado: na maioria das vezes, os hosters oferecem tarifas com uma frequência de processador de 2-3 gigahertz - adequado para tarefas diárias, mas para o processamento em alta velocidade de muitos pequenos, não é mais suficiente. Especialmente se o hoster não se esforçar com o excesso de tempo do processador.
Portanto, a maneira certa de se tornar uma hospedagem Bitrix de qualidade era fazer uma tarifa lucrativa de alta CPU e se tornar um parceiro de destaque - para obter a
classificação dos hosts recomendados , que é o próprio Bitrix.
Preparação: Teste Inicial
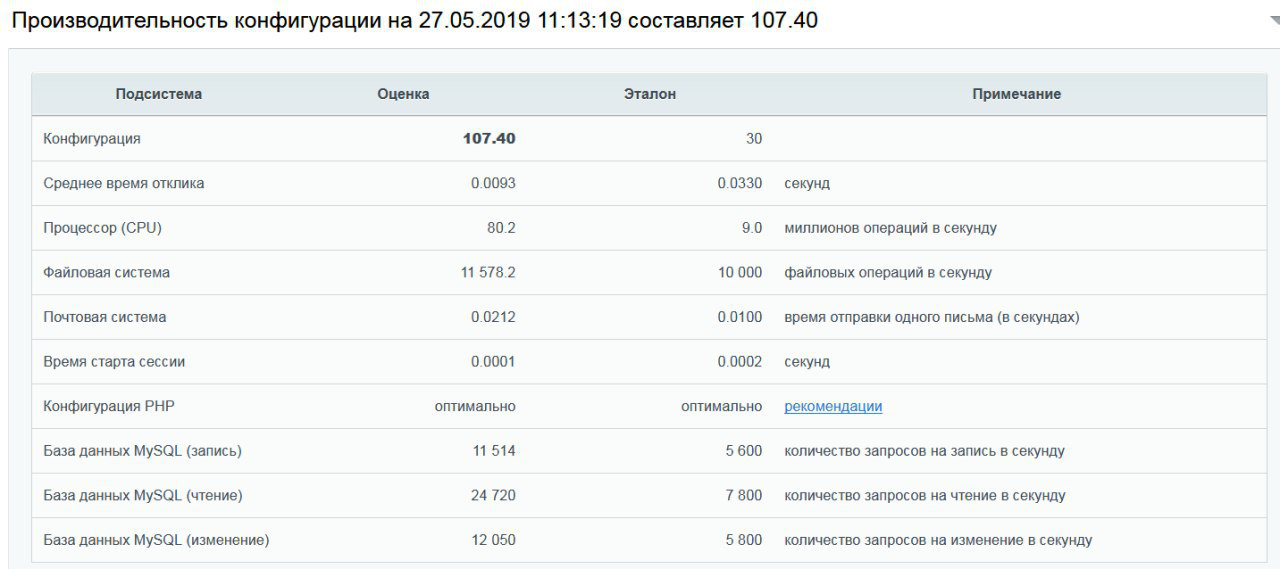
Para começar, verificamos quantos papagaios Bitrix a montagem produz a uma taxa padrão. Processador - Intel Scalable Xeon Silver 4116. Recebeu 107 papagaios.
 Um conjunto semelhante está disponível hoje, a partir de 2 rublos por dia .
Um conjunto semelhante está disponível hoje, a partir de 2 rublos por dia .O Intel Scalable Xeon Silver 4116 faz um bom trabalho com tarefas típicas do VDS, mas para o Bitrix você precisa de algo mais poderoso, especialmente se o objetivo é chegar ao topo da classificação.

Encontrar ferro poderoso para papagaios
A primeira coisa a fazer é levar o processador com uma frequência mais alta: é a frequência do processador que cresce principalmente papagaios.
Inicialmente, foi considerada a montagem automática baseada no Intel Core i9-9900K S1151. Alguns colegas fazem exatamente isso e há ainda mais papagaios saindo deles do que nos processadores de servidor. No entanto, como mencionamos, os i9s e conjuntos de ponta baseados neles consomem tanta energia que precisariam aumentar o preço ou falir nas contas de eletricidade. Sim, e o data center não estava entusiasmado: ele exigiu organizar refrigeração adicional de racks e engenheiros para configurar e manter a auto-montagem (e refrigeração adicional de engenheiros).
Dados os riscos, a falta de garantia e o preenchimento geral da área de trabalho, a montagem automática acabou sendo mais um problema do que um benefício.
Fomos procurar o melhor que os fornecedores oficiais ofereceram. Além do desempenho e da eficiência energética, analisamos o espaço ocupado no rack: você deve pagar pela manutenção de cada unidade, isso também aumenta o custo da tarifa.
A melhor opção parecia encontrar o MicroCloud em 3U. De fato, são 12 servidores em um, o que permite 4 vezes economizar espaço em rack com o mesmo desempenho. Os servidores foram escolhidos em novembro de 2018 e, em seguida, não havia tantas soluções na 3U, a escolha caiu quase imediatamente no
Supermicro SuperServer 5039MS-H12TRF .
 Consiste em doze nós separados
Consiste em doze nós separados Cada nó é essencialmente um servidor separado. Temos uma montagem diferente da da figura, mas o princípio é o mesmo.
Cada nó é essencialmente um servidor separado. Temos uma montagem diferente da da figura, mas o princípio é o mesmo.O coração escolheu o Intel Xeon E3-1270 v6. Confiamos na experiência: já usamos esse processador na plataforma Dell R330 para outros projetos altamente carregados. O E3-1270 nunca falhou, o preço e a qualidade nos convieram.
Para começar, eles compraram apenas um Microcloud: custa cerca de 20 mil dólares e não havia muito dinheiro grátis. É para melhor: soluções novas, mais eficazes e baratas estão constantemente aparecendo no mercado. Quando o dinheiro apareceu no novo servidor, analisamos o mercado novamente.
Primeiro problema de instalação
O primeiro MicroCloud foi entregue uma semana após o pedido. Já no data center, descobriu-se que não cabe em um rack. Queríamos colocá-lo nos servidores 1U, mas os trilhos no rack estão localizados para que o Microcloud não entre. Para colocá-lo, você teria que organizar um tempo de inatividade para outros servidores e deslizar as guias.
Decidimos adiar o lançamento e colocar o Microcloud em um novo rack. Essa acabou sendo a solução ideal: o consumo de energia e a dissipação de calor do MicroCloud diferem dos servidores comuns. E equipamentos de rede com características próprias.
 O MicroClouds agora vive em um rack separado
O MicroClouds agora vive em um rack separadoO MicroCloud planejava instalar placas de rede de dez gigabits para dispersar adequadamente a migração de contêineres VDS. Já fizemos esse truque com servidores 1U, mas com o MicroCloud tudo se tornou mais complicado.
Placas de rede de dez gigabits para servidores MicroCloud eram uma raridade. Pedimos o MicroLP AOM-CTGS-i2TM de baixo perfil, esperamos alguns meses e recebemos a resposta: “Desculpe, o fabricante raramente encontra esses pedidos. Os cartões estarão prontos em seis meses. Eu tive que abandonar a idéia: enquanto houver cartões de gigabit padrão suficientes, mas no futuro tentaremos novamente comprar cartões de dez gigabits.
Um pouco de hickporno: é assim que o MicroCloud's é montadoPersonalização e aplicação de modelos no Bitrix
Inicialmente, construímos um modelo com um viés para o Bitrix, mas também uma conveniência para o restante do CMS: por exemplo, adicionamos uma configuração não padrão para o Vesta com uma opção de versão do PHP. Toda a configuração e otimização foram feitas no esquema apache + mod_fcgi. Os parâmetros foram selecionados para fornecer o melhor resultado médio para todas as tarifas.
O desempenho do Bitrix depende diretamente da velocidade do clock do processador. Em média, a frequência do processador para tarifas de alta CPU era 40-50% maior que a dos processadores que atendem a tarifas regulares. Os resultados da medição se correlacionaram: pelo menos 30% mais desempenho com uma carga alta no servidor, cerca de 60% - em "bom tempo".
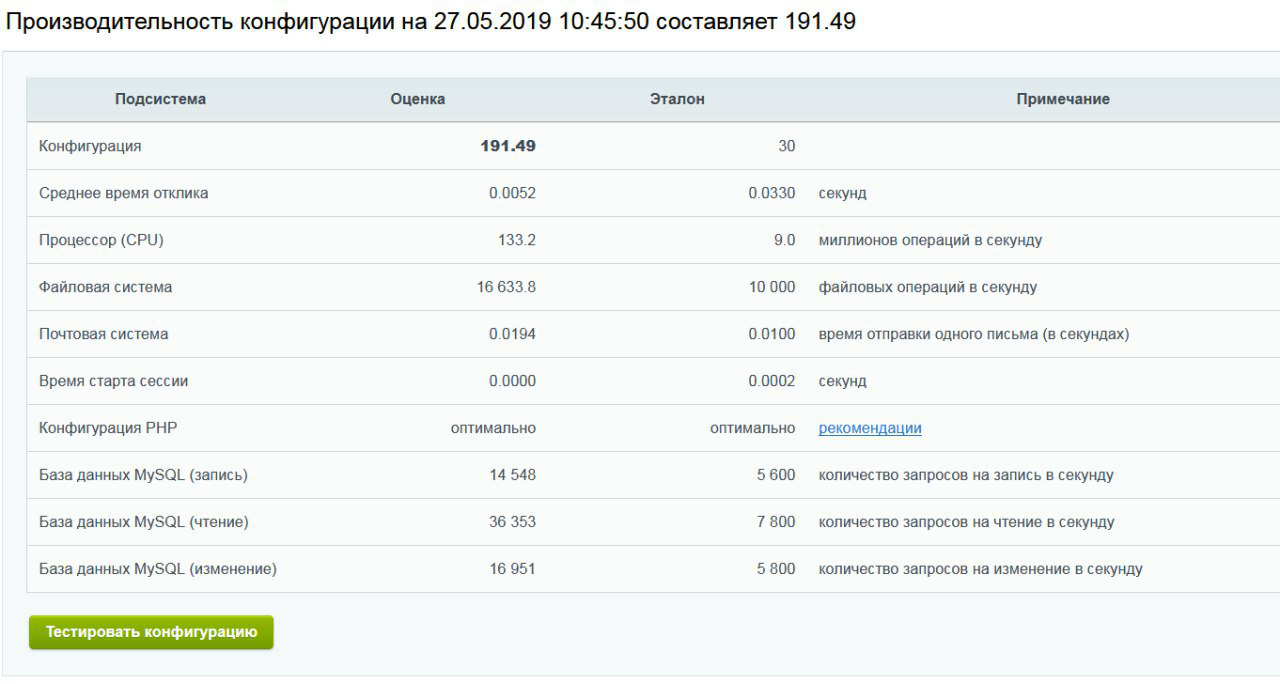
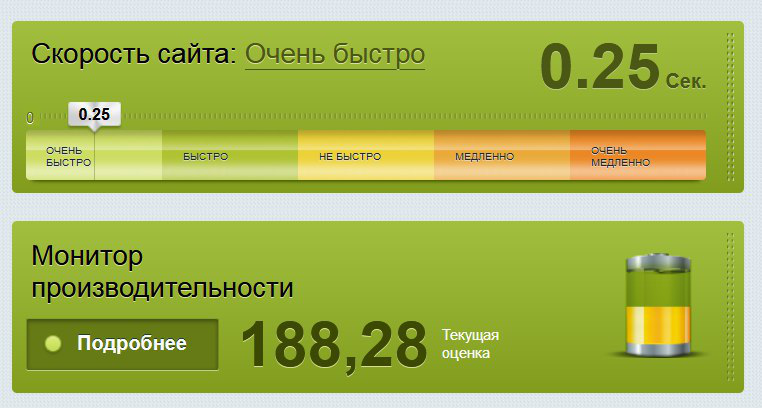 Conseguimos esses números a uma tarifa que custa 26,6 rublos por dia
Conseguimos esses números a uma tarifa que custa 26,6 rublos por diaQuando tudo foi depurado, registramos no site parceiros Bitrix e preenchemos um aplicativo ao qual anexamos dados do VDS com um modelo otimizado para o Bitrix.
Guerra pelo primeiro lugar no ranking
Os resultados do desempenho foram confirmados, mas a classificação final foi menor do que esperávamos: a classificação leva em consideração não apenas o desempenho, mas também o custo absoluto da tarifa e a disponibilidade do período de teste.

E abandonamos conscientemente a luta pelo primeiro lugar no ranking por duas razões.
Preço e bom senso
Outras empresas de hospedagem enviaram aplicativos com tarifas mais baratas, com menos RAM, espaço no SSD e tráfego do que o nosso. Enviamos uma solicitação com uma tarifa mais cara, mas mais adequada para a operação normal do Bitrix.
Por que recusou um período de teste gratuito
A falta de um período de teste gratuito não nos permitiu chegar à primeira linha da classificação, mas tínhamos um motivo sério para recusá-lo. Porque Porque somos orientados a serviços.
Ao criar a VDSina, contamos com a conveniência: o registro deve ocorrer em tempo real, sem captcha (temos azia dela), verificação dos dados do passaporte e confirmação do número de telefone. Entrei no correio, reabasteço a balança em 30 rublos e o VDS se desdobra em 60 segundos - para nós, isso é uma questão de princípio.
Hospedagens complicam o registro para lidar com golpistas que exploram minas no período de teste gratuito, criando centenas de contas gratuitas.
Com esse esquema de lidar com carregadores solitários, os clientes normais sofrem e, basicamente, não queremos carregá-los com o nosso problema em geral.
Para poder testar a hospedagem, fizemos o faturamento diário e um pagamento mínimo de 30 rublos - praticamente não custa nada para os clientes que realmente procuram um VDS conveniente para trabalhar.
Até agora, nossos clientes estão satisfeitos com essa situação, e nós também.
Testes de desempenho de nossas CPUs Hi


Detalhes do testeBYTE UNIX VDS regular
===================================================== =================
Benchmarks do BYTE UNIX (Versão 5.1.3)
Sistema: v148399.hosted-by-vdsina.ru: GNU / Linux
OS: GNU / Linux - 3.10.0-957.5.1.el7.x86_64 - # 1 SMP Fri Feb 1 14:54:57 UTC 2019
Máquina: x86_64 (x86_64)
Idioma: en_US.utf8 (charmap = "UTF-8", agrupe = "UTF-8")
CPU 0: Processador KVM comum (4394.9 bogomips)
x86-64, MMX, Endereço físico ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
CPU 1: Processador KVM comum (4394.9 bogomips)
x86-64, MMX, Endereço físico ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
10:42:54 até 21 min, 1 usuário, média de carga: 0,07, 0,21, 0,21; nível de execução 3
- Benchmark Run: Wed Sep 11 2019 10:42:54 - 11:10:59
2 CPUs no sistema; executando 1 cópia paralela de testes
Dhrystone 2 usando variáveis de registro 26770638,9 lps (10,0 s, 7 amostras)
Pedra de amolar de dupla precisão 4222,7 MWIPS (9,8 s, 7 amostras)
Taxa de transferência de Execução 1763,2 lps (30,0 s, 2 amostras)
File Copy 1024 bufsize 2000 maxblocks 226998,4 KBps (30,0 s, 2 amostras)
File Copy 256 bufsize 500 maxblocks 60299.3 KBps (30.0 s, 2 amostras)
File Copy 4096 bufsize 8000 maxblocks 702987,3 KBps (30,0 s, 2 amostras)
Rendimento do tubo 315773,1 lps (10,0 s, 7 amostras)
Comutação de contexto baseada em tubo 85613,2 lps (10,0 s, 7 amostras)
Criação de processo 5140,5 lps (30,0 s, 2 amostras)
Scripts do shell (1 simultâneo) 3570,0 lpm (60,0 s, 2 amostras)
Scripts de shell (8 simultâneos) 730,3 lpm (60,1 s, 2 amostras)
Despesas gerais de chamada do sistema 293013,8 lps (10,0 s, 7 amostras)
Benchmarks do sistema Índice Valores ÍNDICE DE RESULTADOS DA LINHA DE BASE
Dhrystone 2 usando variáveis de registro 116700.0 26770638.9 2294.0
Pedra de amolar de precisão dupla 55.0 4222.7 767.8
Rendimento de execução 43.0 1763.2 410.1
Cópia de arquivo 1024 bufsize 2000 maxblocks 3960.0 226998.4 573,2
Cópia de arquivo 256 tamanho do bloco 500 maxblocks 1655.0 60299.3 364.3
Cópia de arquivo 4096 bufsize 8000 maxblocks 5800.0 702987.3 1212.0
Rendimento do tubo 12440.0 315773.1 253,8
Comutação de contexto baseada em tubo 4000.0 85613.2 214.0
Criação de processo 126,0 5140,5 408,0
Scripts de shell (1 simultâneo) 42,4 3570,0 842,0
Scripts de shell (8 simultâneos) 6,0 730,3 1217,2
Despesas gerais de chamadas do sistema 15000.0 293013.8 195,3
========
Índice de benchmarks do sistema Pontuação 552,6
- Benchmark Run: Wed Sep 11 2019 11:10:59 - 11:39:17
2 CPUs no sistema; executando 2 cópias paralelas de testes
Dhrystone 2 usando variáveis de registro 50497275,9 lps (10,0 s, 7 amostras)
Pedra de amolar de dupla precisão 8233,3 MWIPS (9,8 s, 7 amostras)
Rendimento de execução 3435,3 lps (29,8 s, 2 amostras)
File Copy 1024 bufsize 2000 maxblocks 386580,4 KBps (30,0 s, 2 amostras)
File Copy 256 bufsize 500 maxblocks 102199.5 KBps (30.0 s, 2 amostras)
File Copy 4096 bufsize 8000 maxblocks 1187846,7 KBps (30,0 s, 2 amostras)
Rendimento do tubo 614216,9 lps (10,0 s, 7 amostras)
Comutação de contexto baseada em tubo 168877,2 lps (10,0 s, 7 amostras)
Criação de processo 11055,3 lps (30,0 s, 2 amostras)
Scripts de shell (1 simultâneo) 5620,2 lpm (60,0 s, 2 amostras)
Scripts de shell (8 simultâneos) 804,7 lpm (60,1 s, 2 amostras)
Despesas gerais de chamada do sistema 561793,2 lps (10,0 s, 7 amostras)
Benchmarks do sistema Índice Valores ÍNDICE DE RESULTADOS DA LINHA DE BASE
Dhrystone 2 usando variáveis de registro 116700.0 50497275.9 4327,1
Pedra de amolar de dupla precisão 55.0 8233.3 1497.0
Rendimento de Execução 43,0 3435,3 798,9
Cópia de arquivo 1024 bufsize 2000 maxblocks 3960.0 386580.4 976.2
Cópia de arquivo 256 tamanho do bloco 500 maxblocks 1655,0 102199,5 617,5
Cópia de arquivo 4096 bufsize 8000 maxblocks 5800.0 1187846.7 2048.0
Rendimento da tubulação 12440.0 614216.9 493,7
Comutação de contexto baseada em tubo 4000.0 168877.2 422.2
Criação de processo 126,0 11055,3 877,4
Scripts de shell (1 simultâneo) 42,4 5620,2 1325,5
Scripts de shell (8 simultâneos) 6,0 804,7 1341,2
Despesas gerais de chamadas do sistema 15000.0 561793.2 374,5
========
Índice de desempenho do sistema 979,3
BYTE UNIX VDS antigo de alta CPU
===================================================== =================
Benchmarks do BYTE UNIX (Versão 5.1.3)
Sistema: v148401.hosted-by-vdsina.ru: GNU / Linux
OS: GNU / Linux - 3.10.0-957.5.1.el7.x86_64 - # 1 SMP Fri Feb 1 14:54:57 UTC 2019
Máquina: x86_64 (x86_64)
Idioma: en_US.utf8 (charmap = "UTF-8", agrupe = "UTF-8")
CPU 0: Processador KVM comum (6624.1 bogomips)
x86-64, MMX, Endereço físico ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
CPU 1: Processador KVM comum (6624.1 bogomips)
x86-64, MMX, Endereço físico ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
14:01:52 até 3:40, 1 usuário, média de carga: 0,00, 0,07, 0,07; nível de execução 3
- Benchmark Run: Wed Sep 11 2019 14:01:52 - 14:30:53
2 CPUs no sistema; executando 1 cópia paralela de testes
Dhrystone 2 usando variáveis de registro 41165945.1 lps (10,0 s, 7 amostras)
Pedra de amolar de dupla precisão 3454,8 MWIPS (15,4 s, 7 amostras)
Taxa de transferência de execução 2102,9 lps (29,6 s, 2 amostras)
File Copy 1024 bufsize 2000 maxblocks 323989.0 KBps (30.0 s, 2 amostras)
File Copy 256 bufsize 500 maxblocks 88536.1 KBps (30.0 s, 2 amostras)
File Copy 4096 bufsize 8000 maxblocks 1090490,9 KBps (30,0 s, 2 amostras)
Rendimento do tubo 456730,9 lps (10,0 s, 7 amostras)
Comutação de contexto baseada em tubo 126170,4 lps (10,0 s, 7 amostras)
Criação de processo 6282,5 lps (30,0 s, 2 amostras)
Scripts de shell (1 simultâneo) 5172,3 lpm (60,0 s, 2 amostras)
Scripts de shell (8 simultâneos) 1122,8 lpm (60,0 s, 2 amostras)
Despesas gerais de chamada do sistema 426422,9 lps (10,0 s, 7 amostras)
Benchmarks do sistema Índice Valores ÍNDICE DE RESULTADOS DA LINHA DE BASE
Dhrystone 2 usando variáveis de registro 116700.0 41165945.1 3527.5
Pedra de amolar de dupla precisão 55,0 3454,8 628,1
Rendimento de Execução 43,0 2102,9 489,1
Cópia de arquivo 1024 bufsize 2000 maxblocks 3960.0 323989.0 818.2
Cópia de arquivo 256 tamanho do bloco 500 maxblocks 1655.0 88536.1 535.0
Cópia de arquivo 4096 bufsize 8000 maxblocks 5800.0 1090490.9 1880.2
Rendimento da tubulação 12440.0 456730.9 367.1
Comutação de contexto baseada em tubo 4000.0 126170.4 315.4
Criação de processo 126,0 6282,5 498,6
Scripts de shell (1 simultâneo) 42,4 5172,3 1219,9
Scripts de shell (8 simultâneos) 6,0 1122,8 1871,4
Despesas gerais de chamadas do sistema 15000.0 426422.9 284.3
========
Índice de benchmarks do sistema Pontuação 753.4
- Benchmark Run: Wed Sep 11 2019 14:30:53 - 15:00:04
2 CPUs no sistema; executando 2 cópias paralelas de testes
Dhrystone 2 usando variáveis de registro 73510146,2 lps (10,0 s, 7 amostras)
Pedra de amolar de dupla precisão 6546,6 MWIPS (16,2 s, 7 amostras)
Taxa de transferência de execução 5306,0 lps (30,0 s, 2 amostras)
File Copy 1024 bufsize 2000 maxblocks 580128,9 KBps (30,0 s, 2 amostras)
File Copy 256 bufsize 500 maxblocks 149810.9 KBps (30.0 s, 2 amostras)
File Copy 4096 bufsize 8000 maxblocks 1896766,5 KBps (30,0 s, 2 amostras)
Rendimento do tubo 891359,8 lps (10,0 s, 7 amostras)
Comutação de contexto baseada em tubo 245363,7 lps (10,0 s, 7 amostras)
Criação de processo 17811,2 lps (30,0 s, 2 amostras)
Scripts de shell (1 simultâneo) 8446,7 lpm (60,0 s, 2 amostras)
Scripts de shell (8 simultâneos) 1147,3 lpm (60,0 s, 2 amostras)
Despesas gerais de chamada do sistema 831002,3 lps (10,0 s, 7 amostras)
Benchmarks do sistema Índice Valores ÍNDICE DE RESULTADOS DA LINHA DE BASE
Dhrystone 2 usando variáveis de registro 116700.0 73510146.2 6299.1
Pedra de amolar de dupla precisão 55,0 6546,6 1190,3
Rendimento de Execução 43,0 5306,0 1234,0
Cópia de arquivo 1024 bufsize 2000 maxblocks 3960.0 580128.9 1465.0
Cópia de arquivo 256 tamanho do bloco 500 maxblocks 1655.0 149810.9 905.2
Cópia de arquivo 4096 bufsize 8000 maxblocks 5800.0 1896766.5 3270.3
Vazão do tubo 12440.0 891359.8 716,5
Comutação de contexto baseada em tubo 4000.0 245363.7 613.4
Criação de processo 126,0 17811,2 1413,6
Scripts de shell (1 simultâneo) 42,4 8446,7 1992.1
Scripts de shell (8 simultâneos) 6,0 1147,3 1912,1
Despesas gerais de chamadas do sistema 15000.0 831002.3 554,0
========
Pontuação do índice de benchmarks do sistema 1391,3
BYTE UNIX Hi-CPU VDS
===================================================== =================
Benchmarks do BYTE UNIX (Versão 5.1.3)
Sistema: v148401.hosted-by-vdsina.ru: GNU / Linux
OS: GNU / Linux - 3.10.0-957.5.1.el7.x86_64 - # 1 SMP Fri Feb 1 14:54:57 UTC 2019
Máquina: x86_64 (x86_64)
Idioma: en_US.utf8 (charmap = "UTF-8", agrupe = "UTF-8")
CPU 0: Processador KVM comum (6624.1 bogomips)
x86-64, MMX, Endereço físico ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
CPU 1: Processador KVM comum (6624.1 bogomips)
x86-64, MMX, Endereço físico ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
10:42:58 até 21 min, 1 usuário, média de carga: 0,03, 0,07, 0,06; nível de execução 3
- Benchmark Run: Wed Sep 11 2019 10:42:58 - 11:12:20
2 CPUs no sistema; executando 1 cópia paralela de testes
Dhrystone 2 usando variáveis de registro 50496763,2 lps (10,0 s, 7 amostras)
Whetstone de precisão dupla 3290,3 MWIPS (18,2 s, 7 amostras)
Rendimento de execução 3416,6 lps (30,0 s, 2 amostras)
File Copy 1024 bufsize 2000 maxblocks 419298,9 KBps (30,0 s, 2 amostras)
File Copy 256 bufsize 500 maxblocks 105903.4 KBps (30.0 s, 2 amostras)
File Copy 4096 bufsize 8000 maxblocks 1417343,7 KBps (30,0 s, 2 amostras)
Rendimento da tubulação 539629,9 lps (10,0 s, 7 amostras)
Comutação de contexto baseada em tubo 152917,5 lps (10,0 s, 7 amostras)
Criação de processo 10424,5 lps (30,0 s, 2 amostras)
Scripts de shell (1 simultâneo) 7237,0 lpm (60,0 s, 2 amostras)
Scripts do shell (8 simultâneos) 1502,7 lpm (60,0 s, 2 amostras)
Despesas gerais de chamada do sistema 495647,5 lps (10,0 s, 7 amostras)
Benchmarks do sistema Índice Valores ÍNDICE DE RESULTADOS DA LINHA DE BASE
Dhrystone 2 usando variáveis de registro 116700.0 50496763.2 4327,1
Pedra de amolar de dupla precisão 55.0 3290.3 598.2
Rendimento de Execução 43,0 3416,6 794,6
Cópia de arquivo 1024 bufsize 2000 maxblocks 3960.0 419298.9 1058.8
Cópia de arquivo 256 tamanho do bloco 500 maxblocks 1655,0 105903,4 639,9
Cópia de arquivo 4096 bufsize 8000 maxblocks 5800.0 1417343.7 2443.7
Rendimento do tubo 12440.0 539629.9 433,8
Comutação de contexto baseada em tubo 4000.0 152917.5 382.3
Criação de processo 126,0 10424,5 827,3
Scripts de shell (1 simultâneo) 42,4 7237,0 1706,8
Scripts de shell (8 simultâneos) 6,0 1502,7 2504,5
Despesas gerais de chamadas do sistema 15000.0 495647.5 330.4
========
Pontuação do índice de benchmarks do sistema 966,0
- Benchmark Run: Wed Sep 11 2019 11:12:20 - 11:41:45
2 CPUs no sistema; executando 2 cópias paralelas de testes
Dhrystone 2 usando variáveis de registro 101242206,9 lps (10,0 s, 7 amostras)
Pedra de amolar de dupla precisão 6543,9 MWIPS (18,3 s, 7 amostras)
Rendimento de execução 7095,4 lps (30,0 s, 2 amostras)
File Copy 1024 bufsize 2000 maxblocks 793174,9 KBps (30,0 s, 2 amostras)
File Copy 256 bufsize 500 maxblocks 203939,8 KBps (30,0 s, 2 amostras)
File Copy 4096 bufsize 8000 maxblocks 2721785,9 KBps (30,0 s, 2 amostras)
Rendimento do tubo 1072159,2 lps (10,0 s, 7 amostras)
Comutação de contexto baseada em tubo 307924,6 lps (10,0 s, 7 amostras)
Criação de processo 23097,3 lps (30,0 s, 2 amostras)
Scripts de shell (1 simultâneo) 11354,9 lpm (60,0 s, 2 amostras)
Scripts de shell (8 simultâneos) 1585,1 lpm (60,1 s, 2 amostras)
Despesas gerais de chamada do sistema 979658,1 lps (10,0 s, 7 amostras)
Benchmarks do sistema Índice Valores ÍNDICE DE RESULTADOS DA LINHA DE BASE
Dhrystone 2 usando variáveis de registro 116700.0 101242206.9 8675.4
Pedra de amolar de precisão dupla 55.0 6543.9 1189.8
Rendimento de Execução 43,0 7095,4 1650,1
Cópia de arquivo 1024 bufsize 2000 maxblocks 3960.0 793174.9 2003.0
Cópia de arquivo 256 tamanho do bloco 500 maxblocks 1655.0 203939.8 1232.3
Cópia de arquivo 4096 bufsize 8000 maxblocks 5800.0 2721785.9 4692.7
Rendimento da tubulação 12440.0 1072159.2 861,9
Comutação de contexto baseada em tubo 4000.0 307924.6 769,8
Criação de processo 126.0 23097.3 1833.1
Scripts de shell (1 simultâneo) 42,4 11354,9 2678,1
Scripts de shell (8 simultâneos) 6,0 1585,1 2641,9
Despesas gerais de chamadas do sistema 15000.0 979658.1 653.1
========
Pontuação do índice de benchmarks do sistema 1793,6
Planos futuros
Recentemente, o quarto servidor chegou até nós. Desta vez, o Supermicro MicroCloud com 12 x Xeon E-2136, 48 x DDR4 16Gb e 12 x 1TB NVME P4510.
Em média, o desempenho do novo MicroCloud é 8 a 10% superior ao dos irmãos de rack
O novo MicroCloud já foi comissionado e agora estamos planejando expandir o Hi-CPU para a Holanda e outros países. Temos servidores para tarifas regulares em dois data centers holandeses, mas quando surge a dúvida sobre algo mais complicado que um servidor de 1U, é preciso passar por nove rodadas de coordenação.
Mas isso é outra história.

Inscreva-se no nosso desenvolvedor do Instagram
