
Existem muitos artigos com um título semelhante, então tentarei evitar tópicos comuns. Espero que até um desenvolvedor muito experiente encontre algo útil aqui. Este artigo considerará apenas mecanismos e abordagens de otimização simples que permitirão sua aplicação com o mínimo de esforço. E essas alterações não aumentarão a entropia do seu código. O artigo não prestará atenção ao que e quando otimizar; este artigo é mais sobre a abordagem para escrever código em geral.
1. ToArray vs ToList
public IEnumerable<string> GetItems() { return _storage.Items.Where(...).ToList(); }
Concordo, um código muito típico para projetos industriais. Mas o que há de errado com ele? A interface IEnumerable retorna uma coleção que você pode "revisar"; essa interface não implica que possamos adicionar / remover elementos. Portanto, não há necessidade de finalizar a expressão LINQ convertendo para uma Lista (ToList). Nesse caso, é preferível transmitir para Array (ToArray). Como List é um wrapper sobre Array e todos os recursos adicionais fornecidos por esse wrapper, cortamos a interface. Uma matriz consome menos memória e o acesso aos seus valores é mais rápido. Por conseguinte, por que pagar mais. Por um lado, essa otimização não é significativa, como se diz "otimização em correspondências", mas isso não é totalmente verdade. O fato é que em um aplicativo típico no qual os serviços retornam modelos para a camada de apresentação, pode haver uma infinidade de chamadas ToList. No exemplo descrito acima, a interface IEnumerable é introduzida apenas para fins ilustrativos. Essa abordagem é relevante para todos os casos em que você precisa retornar uma coleção que não será alterada posteriormente.
Prevejo um comentário de que Matriz e Lista não funcionarão de maneira equivalente no caso de acesso multiencadeado à coleção. É mesmo. Mas se você, como desenvolvedor, estiver considerando a possibilidade de acesso multiencadeado a uma coleção com a possibilidade de alterá-la, com um alto grau de probabilidade, nem a Matriz nem a Lista serão adequadas.
2. O parâmetro "caminho do arquivo" nem sempre é a melhor opção para o seu método
Ao desenvolver uma API, evite assinaturas de método que recebem um caminho de arquivo como entrada (para processamento posterior pelo seu método). Em vez disso, forneça a capacidade de transmitir uma matriz de bytes para a entrada ou,
como último recurso, Stream. O fato é que, com o tempo, seu método pode ser aplicado não apenas a um arquivo do disco, mas também a um arquivo transferido pela rede, a um arquivo de um arquivo morto, a um arquivo de um banco de dados, a um arquivo cujo conteúdo é gerado dinamicamente na memória etc. Fornecendo um método com o parâmetro de entrada "caminho do arquivo", você obriga o usuário da sua API a salvar os dados em disco antes de lê-los novamente. Essa operação sem sentido afeta criticamente o desempenho. Uma unidade é uma coisa extremamente lenta. Por conveniência, você pode fornecer um método com um parâmetro de entrada "caminho para um arquivo", mas sempre use um método público sobrecarregado com uma matriz de bytes ou fluxo na entrada. Há um "marcador" que pode ajudar a encontrar operações extras de gravação / leitura de disco, tente encontrar em seu projeto usando métodos padrão:
Path.GetTempPath() e
Path.GetRandomFileName() (do System.IO). Com um alto grau de probabilidade, você encontrará uma solução alternativa para o problema acima ou similar.
Um leitor atento e experiente perceberá que, em alguns casos, gravar em disco pode, pelo contrário, melhorar o desempenho, por exemplo, se estivermos lidando com arquivos muito grandes. Isso é verdade, deve ser levado em consideração, mas presumo que essa seja uma situação muito rara com uma implementação específica.
3. Evite usar threads como parâmetros e o resultado de retorno de seus métodos
Qual é o problema aqui ... quando obtemos um fluxo de alguma "caixa preta", devemos ter em mente seu estado. I.e. O fluxo está aberto? Onde está o marcador de leitura / gravação? Seu estado pode mudar independentemente do nosso código? Se um fluxo é declarado como uma classe base de fluxo, nem sequer temos informações sobre quais operações estão disponíveis. Tudo isso é resolvido com verificações adicionais, código e custos adicionais. Além disso, deparei-me repetidamente com uma situação em que, ao receber o Stream de algum método "obscuro", o desenvolvedor preferia jogar com segurança e "transferir" dados dele para um novo MemoryStream local completamente controlado. Embora o fluxo de origem possa ser bastante seguro. Talvez até isso já estivesse gentilmente preparado para a leitura do MemoryStream. Às vezes, pode chegar ao ponto do absurdo - dentro de um método, uma matriz de bytes é colocada em um MemoryStream, então esse MemoryStream é retornado como resultado de um método declarado como um fluxo base. Lá fora, esse fluxo se transforma em um novo MemoryStream e, em seguida, ToArray () retorna uma matriz de bytes, que originalmente tínhamos. Mais precisamente, será sua próxima cópia. A ironia é que, dentro e fora do nosso método, o código está completamente correto. Na minha opinião, este exemplo não está fora de minha cabeça, mas foi encontrado em algum lugar no código comercial.
Como resultado, se você tiver a capacidade de enviar / receber dados "limpos", não use fluxos para isso - não crie traps para aqueles que os usarão. Se seu aplicativo já tiver fluxos de transferência / retorno, analise seu uso com base no exposto acima.
4. Herança de enums
Essa otimização é comum, todo mundo sabe, até os alunos. Mas, pela minha experiência, é extremamente raramente usado. Portanto, por padrão, o enum herda de int. No entanto, ele pode ser herdado do byte, que contém 256 valores (ou 8 valores "sinalizáveis"). Que quase sempre cobre a funcionalidade do enum "intermediário". Uma alteração mínima no código e todos os valores da sua enum ocupam menos memória para sempre. Abaixo está uma ilustração de uma referência para preencher uma coleção com valores de enumeração herdados de int e byte.
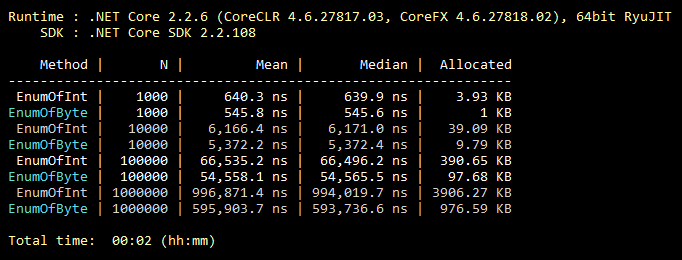
Código de referência public class CollectEnums { [Params(1000, 10000, 100000, 1000000)] public int N; [Benchmark] public EnumFromInt[] EnumOfInt() { EnumFromInt[] results = new EnumFromInt[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromInt.Value1; } return results; } [Benchmark] public EnumFromByte[] EnumOfByte() { EnumFromByte[] results = new EnumFromByte[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromByte.Value1; } return results; } } public enum EnumFromInt { Value1, Value2 } public enum EnumFromByte: byte { Value1, Value2 }
5. Mais algumas palavras sobre as classes Matriz e Lista
Seguindo a lógica, a iteração em uma matriz é sempre mais eficiente do que a iteração em uma "planilha", pois uma "planilha" é um invólucro em uma matriz. Além disso, seguindo a lógica, "for" é sempre mais rápido que "foreach", pois o "foreach" executa muitas das ações exigidas pela implementação da interface IEnumerable. Tudo é lógico aqui, mas errado! Vamos dar uma olhada nos resultados do benchmark:

Código de referência public class IterationBenchmark { private List<int> _list; private int[] _array; [Params(100000, 10000000)] public int N; [GlobalSetup] public void Setup() { const int MIN = 1; const int MAX = 10; Random rnd = new Random(); _list = Enumerable.Repeat(0, N).Select(i => rnd.Next(MIN, MAX)).ToList(); _array = _list.ToArray(); } [Benchmark] public int ForList() { int total = 0; for (int i = 0; i < _list.Count; i++) { total += _list[i]; } return total; } [Benchmark] public int ForeachList() { int total = 0; foreach (int i in _list) { total += i; } return total; } [Benchmark] public int ForeachArray() { int total = 0; foreach (int i in _array) { total += i; } return total; } [Benchmark] public int ForArray() { int total = 0; for (int i = 0; i < _array.Length; i++) { total += _array[i]; } return total; } }
O fato é que, para iterar sobre uma matriz, "foreach" não usa uma implementação IEnumerable. Nesse caso em particular, a iteração mais otimizada por índice é executada, sem verificar fora dos limites da matriz, pois a construção "foreach" não opera com índices, portanto, o desenvolvedor não tem a opção de "bagunçar" o código. Essa é a exceção à regra. Portanto, se em alguma seção crítica do código você substituiu o uso de "foreach" por "for" por uma questão de otimização, você deu um tiro no pé. Observe que isso é relevante
apenas para matrizes . Existem várias ramificações no StackOverflow em que esse recurso é discutido.
6. A pesquisa em uma tabela de hash sempre se justifica?
Todo mundo sabe que tabelas de hash são muito eficazes para pesquisar. Mas eles costumam esquecer que o preço de uma pesquisa rápida é uma adição lenta à tabela de hash. O que se segue disso? Para que o uso da tabela de hash seja justificado, é necessário que o número de elementos da tabela de hash seja pelo menos 8 (aproximadamente). E para que o número de operações de pesquisa fosse pelo menos uma ordem de magnitude maior que o número de operações de adição. Caso contrário, use uma coleção mais simples. A qualidade da função hash fará seus próprios ajustes na eficiência, mas o significado disso não será alterado. Na minha prática, houve um caso em que o maior gargalo no código carregado estava chamando o método Dictionary.Add (). A chave era uma corda regular, de comprimento curto. Lembrando disso e se tornou um gatilho para escrever este parágrafo. Para ilustrar, um exemplo de código muito ruim:
private static int GetNumber(string numberStr) { Dictionary<string, int> dictionary = new Dictionary<string, int> { {"One", 1}, {"Two", 2}, {"Three", 3} }; dictionary.TryGetValue(numberStr, out int result); return result; }
Talvez algo semelhante ocorra no seu projeto?
7. Métodos de incorporação
O código é dividido em métodos com mais freqüência por 2 razões. Garanta a reutilização e decomposição do código quando uma tarefa estiver dividida em várias subtarefas. É mais fácil para uma pessoa. O embutimento é o processo inverso de decomposição, ou seja, o código do método está incorporado no local em que o método deve ser chamado e, como resultado, economizamos na pilha de chamadas e na passagem de parâmetros. Eu não recomendo empurrar tudo em um único método. Mas esses métodos que poderíamos teoricamente "inline" podem ser marcados com o atributo correspondente:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
Este atributo informará ao sistema que esse método pode ser incorporado. Isso não significa que o método marcado com este atributo seja necessariamente interno. Por exemplo, não é possível incorporar métodos recursivos ou virtuais. Também é importante notar que o mecanismo de incorporação é extremamente "delicado". Existem muitas outras razões pelas quais o sistema se recusará a incorporar seu método. No entanto, a equipe da Microsoft que trabalha no .NET Core está usando ativamente esse atributo. O código fonte do .NET Core tem muitos exemplos de seu uso.
8. Capacidade Estimada
Eu (e espero que a maioria dos desenvolvedores também) tenha desenvolvido um reflexo: Inicializei a coleção - pensei se é possível definir o Capacity para ela. No entanto, o número exato de elementos de coleção nem sempre é conhecido antecipadamente. Mas esse não é um motivo para ignorar esse parâmetro. Por exemplo, se, falando sobre quantos itens haverá em sua coleção, você assume um "par de milhares" embaçado, esta é uma ocasião para definir a Capacidade como 1000. Uma pequena teoria, por exemplo, para Lista por padrão, Capacidade = 16, para que apenas alcançar 1000, o sistema fará 1008 (16 + 32 + 64 + 128 + 256 + 512) cópias extras dos elementos e criará 7 matrizes temporárias para serem tratadas na próxima chamada do GC. I.e. todo esse trabalho será desperdiçado. Além disso, como Capacidade, ninguém proíbe usar a fórmula. Se o tamanho da sua coleção for estimado em um terço da outra coleção, você poderá definir Capacity igual a otherCollection.Count / 3. Ao definir o Capacity, é bom entender o alcance do tamanho possível da coleção e a proximidade com que seu valor é distribuído. Sempre há uma chance de dano, mas se usada corretamente, uma capacidade estimada lhe dará uma boa vitória.
9. Sempre especifique seu código.
Use ativamente (à primeira vista, opcional) palavras-chave do C #, como: estático, const, somente leitura, lacrado, abstrato etc. Naturalmente, onde eles fazem sentido. E aqui está a performance? O fato é que, quanto mais detalhado você descreve seu sistema para o compilador, mais otimizado é o código que ele pode gerar. Um leitor atento e experiente pode perceber que, por exemplo, a palavra-chave selada não afeta o desempenho. Agora isso é verdade, mas nas versões futuras tudo pode mudar. Dê uma chance ao compilador e à máquina virtual! Receba um bônus, identificando muitos erros de uso indevido do seu código na fase de compilação. Regra geral: quanto mais claramente o sistema for descrito, mais otimizado será o resultado. Aparentemente, com as pessoas também.
A história real confirma essa regra, mas se você ler a preguiça, poderá pularUma noite, enquanto envolvido em seu
projeto de hobby , ele se propôs a aumentar o desempenho de uma seção de código acima de um determinado nível. Mas este site era curto e havia poucas opções para o que fazer com ele. Eu encontrei na documentação que, começando com a versão C # 7.2, a palavra-chave “readonly” pode ser usada para estruturas. E no meu caso, estruturas imutáveis foram usadas, adicionando uma única palavra "somente leitura" e consegui o que queria, mesmo com uma margem! O sistema, sabendo que minhas estruturas não devem ser alteradas, conseguiu gerar um código melhor para o meu caso.
10. Se possível, use uma versão do .NET para todos os projetos de solução
Você deve se esforçar para garantir que todos os assemblies no seu aplicativo pertençam à mesma versão do .NET. Isso se aplica aos pacotes NuGet (editados em packages.config / json) e aos seus próprios assemblies (editados nas propriedades do projeto). Isso economizará RAM e acelera o início "frio", pois na memória do seu aplicativo não haverá cópias das mesmas bibliotecas para diferentes versões do .NET. Vale ressaltar que nem sempre, versões diferentes do .NET geram cópias na memória. Mas suponha que um aplicativo criado na mesma versão do .NET seja sempre melhor. Além disso, isso elimina vários problemas em potencial que estão fora do escopo deste artigo. A consolidação de versões de todos os pacotes NuGet usados também contribuirá para melhorar o desempenho do seu aplicativo.
Algumas ferramentas úteis
O ILSpy é uma ferramenta gratuita que permite exibir o código-fonte do assembly restaurado. Se eu tiver uma pergunta sobre qual mecanismo .NET é mais eficiente, primeiro abro o ILSpy (e não o Google ou o StackOverflow) e já vejo como ele é implementado. Por exemplo, para descobrir o que é melhor usado em termos de desempenho para o recebimento de dados via HTTP, a classe HttpWebRequest ou WebClient, basta ver sua implementação por meio do ILSpy. Nesse caso específico, o WebClient é um invólucro do HttpWebRequest, respectivamente, a resposta é óbvia. Os códigos-fonte .NET não valem medo, são escritos pelos mesmos programadores comuns.
BenchmarkDotNet é uma biblioteca gratuita de benchmarks. Existe um StopWatch simples e intuitivo (do System.Diagnostics). Mas às vezes não é suficiente. Como, de uma maneira boa, é necessário levar em consideração não um único resultado, mas a média de várias comparações, é melhor comparar sua mediana para minimizar a influência do sistema operacional. Além disso, você precisa levar em consideração a "partida a frio" e a quantidade de memória alocada. Para testes tão complexos, foi criado o BenchmarkDotNet. É essa biblioteca que os desenvolvedores do .NET Core usam em testes oficiais. A biblioteca é fácil de usar, mas se seus autores lerem repentinamente este post, dê uma oportunidade mais conveniente de influenciar a estrutura da tabela de resultados.
Os U2U Consult Performance Analyzers são um plug-in gratuito para o Visual Studio que fornece dicas sobre como melhorar o código em termos de desempenho. 100% dependem dos conselhos deste analisador não vale a pena. Desde que me deparei com uma situação em que um conselho me surpreendeu um pouco e, depois de uma análise detalhada, ele realmente se mostrou errado. Infelizmente, este exemplo está perdido, então tome uma palavra. No entanto, se você usá-lo cuidadosamente, é uma ferramenta muito útil. Por exemplo, ele sugerirá que, em vez de
myStr.Replace("*", "-") mais eficiente usar
myStr.Replace('*', '-') . E as duas expressões Where no LINQ são melhor combinadas em uma. Tudo isso é "otimização em correspondências", mas são fáceis de aplicar e não levam a um aumento no código / complexidade.
Em conclusão
Se cada décima pessoa que ler o artigo aplicar as abordagens acima em seu projeto atual (ou uma parte crítica dele) e também aderir a essas abordagens no futuro, então juntos podemos salvar toda a floresta! Forest ??? I.e. os recursos poupados dos sistemas de computador, na forma de eletricidade obtida da queima de madeira, permanecerão sem uso. Nesse caso, a “floresta” é apenas algum tipo de equivalente. Provavelmente saiu uma conclusão estranha, mas espero que você seja inspirado pelo pensamento.
Atualização PS baseada em comentários
A vantagem do ToArray sobre o ToList é relevante para o .NET Core. Mas se você usar o antigo .NET Framework, provavelmente será preferível o ToList. O problema é que, no .NET Framework, a chamada ToArray em si é significativamente mais lenta que a chamada ToList. E essas perdas podem não ser compensadas por acessos mais rápidos a elementos e menos armazenamento em matriz. Em geral, esse problema acabou sendo mais complicado, pois diferentes classes que implementam IEnumerable podem ter diferentes implementações de ToArray e ToList, com diferentes níveis de eficiência.
Se a enumeração herdada do byte for usada como membro de uma classe (estrutura) e não separadamente, talvez não haja economia de memória. Devido ao alinhamento da memória ocupada de todos os membros da classe (estrutura). Este ponto está ausente no artigo. No entanto, o ganho potencial é melhor do que a sua ausência, pois além da memória ocupada, também são utilizados enum's. Portanto, o parágrafo 4 ainda é relevante, mas com esta importante reserva.
Agradeço ao
KvanTTT e à
epetrukhin pelos comentários construtivos sobre essas questões.
Além disso, como
Taritsyn observou, a otimização no estágio de compilação JIT para a palavra-chave “selada” ainda existe. Mas isso apenas confirma todas as teses do parágrafo 9.
Parece que todos os comentários construtivos foram levados em consideração. Estou muito satisfeito com esses comentários. Como eu, como autor, recebi um feedback e também aprendi algo novo para mim.