Oi Habr.
Este artigo é uma continuação lógica do ranking dos artigos da
Best Habr para 2018 . E, embora o ano ainda não tenha terminado, mas como você sabe, no verão houve mudanças nas regras, consequentemente, ficou interessante ver se isso afetava alguma coisa.

Além das estatísticas em si, será fornecida uma classificação atualizada dos artigos, bem como alguns códigos-fonte para quem estiver interessado em como isso funciona.
Para aqueles que estão interessados no que aconteceu, continuaram sob o corte. Quem estiver interessado em uma análise mais detalhada das seções do site também poderá ver a
próxima parte .
Dados de origem
Esta classificação não é oficial e não tenho dados internos. Como é fácil ver, tendo consultado a barra de endereços do navegador, todos os artigos em Habré têm numeração de ponta a ponta. A seguir, é uma questão técnica, apenas lemos todos os artigos seguidos em um ciclo (em um thread e com pausas para não carregar o servidor). Os próprios valores foram obtidos por um simples analisador em Python (o código-fonte está
aqui ) e armazenados em um arquivo csv aproximadamente deste tipo:
2019-08-11T22:36Z,https://habr.com/ru/post/463197/,"Blazor + MVVM = Silverlight , ",votes:11,votesplus:17,votesmin:6,bookmarks:40,views:5300,comments:73
2019-08-11T05:26Z,https://habr.com/ru/news/t/463199/," NASA ",votes:15,votesplus:15,votesmin:0,bookmarks:2,views:1700,comments:7Processamento
Para análise, usaremos Python, Pandas e Matplotlib. Aqueles que não estão interessados em estatística, podem pular esta parte e ir imediatamente aos artigos.
Primeiro, você precisa carregar o conjunto de dados na memória e selecionar os dados para o ano desejado.
import pandas as pd import datetime import matplotlib.dates as mdates from matplotlib.ticker import FormatStrFormatter from pandas.plotting import register_matplotlib_converters df = pd.read_csv("habr.csv", sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ') df['datetime'] = dates year = 2019 df = df[(df['datetime'] >= pd.Timestamp(datetime.date(year, 1, 1))) & (df['datetime'] < pd.Timestamp(datetime.date(year+1, 1, 1)))] print(df.shape)
Acontece que, para este ano (embora ainda não tenha terminado), no momento da redação, 12715 artigos foram publicados. Para comparação, em todo o ano de 2018 - 15904. Em geral, muito - isso é cerca de 43 artigos por dia (e isso é apenas com uma classificação positiva, quantos artigos são baixados negativos ou excluídos, é possível adivinhar ou descobrir as omissões entre os identificadores).
Selecione os campos necessários no conjunto de dados. Como métricas, usaremos o número de visualizações, comentários, valores de classificação e o número de favoritos adicionados.
def to_float(s):
Agora, os dados foram adicionados ao conjunto de dados e podemos usá-los. Agrupe os dados por dia e calcule os valores médios.
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.median().reset_index() grouped['counts'] = days_count['counts'] counts_per_day = grouped['counts'].values counts_per_day_avg = grouped['counts'].rolling(window=20).mean() view_per_day = grouped['views'].values view_per_day_avg = grouped['views'].rolling(window=20).mean() votes_per_day = grouped['votes'].values votes_per_day_avg = grouped['votes'].rolling(window=20).mean() bookmarks_per_day = grouped['bookmarks'].values bookmarks_per_day_avg = grouped['bookmarks'].rolling(window=20).mean()
Agora, a parte divertida, podemos ver os gráficos.
Vamos ver o número de publicações sobre Habré em 2019.
import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = (16, 8) fig, ax = plt.subplots() plt.bar(year_days, counts_per_day, label='Articles/day') plt.plot(year_days, counts_per_day_avg, 'g-', label='Articles avg/day') plt.xticks(rotation=45) ax.xaxis.set_major_formatter(mdates.DateFormatter("%d-%m-%Y")) ax.xaxis.set_major_locator(mdates.MonthLocator(interval=1)) plt.legend(loc='best') plt.tight_layout() plt.show()
O resultado é interessante. Como você pode ver, Habr ligeiramente "salsicha" durante o ano. Eu não sei o motivo.

Para comparação, 2018 parece um pouco mais suave:

Em geral, não vi nenhuma redução drástica no número de artigos publicados em 2019 no gráfico. Além disso, pelo contrário, parece ter crescido um pouco desde o verão.
Mas os dois gráficos a seguir me deprimem um pouco mais.
Média de visualizações por artigo:

Classificação média por artigo:
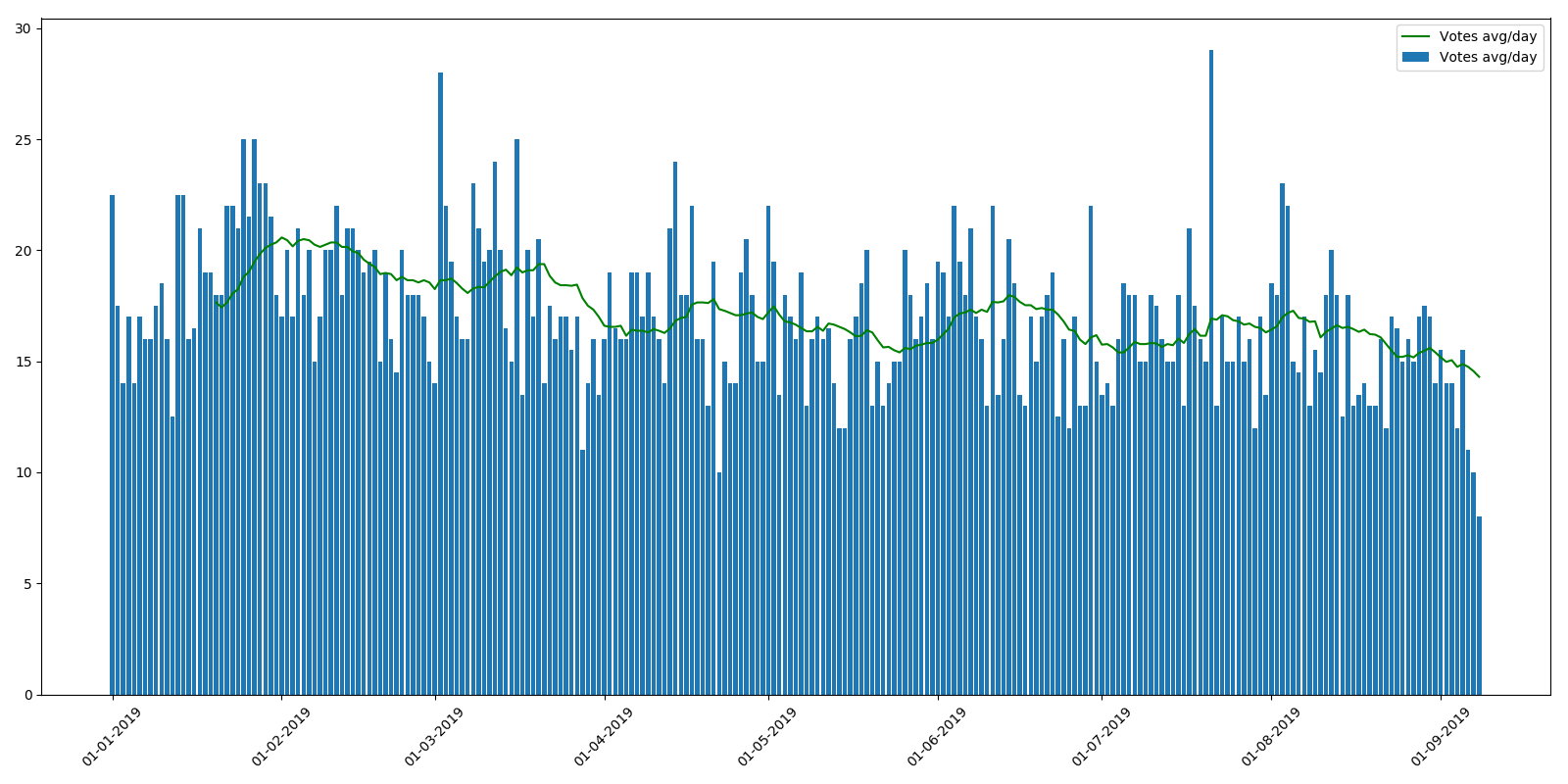
Como você pode ver, o número médio de visualizações durante o ano é ligeiramente reduzido. Isso pode ser explicado pelo fato de que novos artigos ainda não foram indexados pelos mecanismos de pesquisa e não são encontrados com tanta frequência. Mas a diminuição na classificação média por artigo é mais incompreensível. A sensação é de que os leitores simplesmente não têm tempo para navegar por tantos artigos ou não prestam atenção às classificações. Do ponto de vista do programa de recompensa dos autores, essa tendência é muito desagradável.
A propósito, esse não foi o caso em 2018 e o cronograma é mais ou menos uniforme.
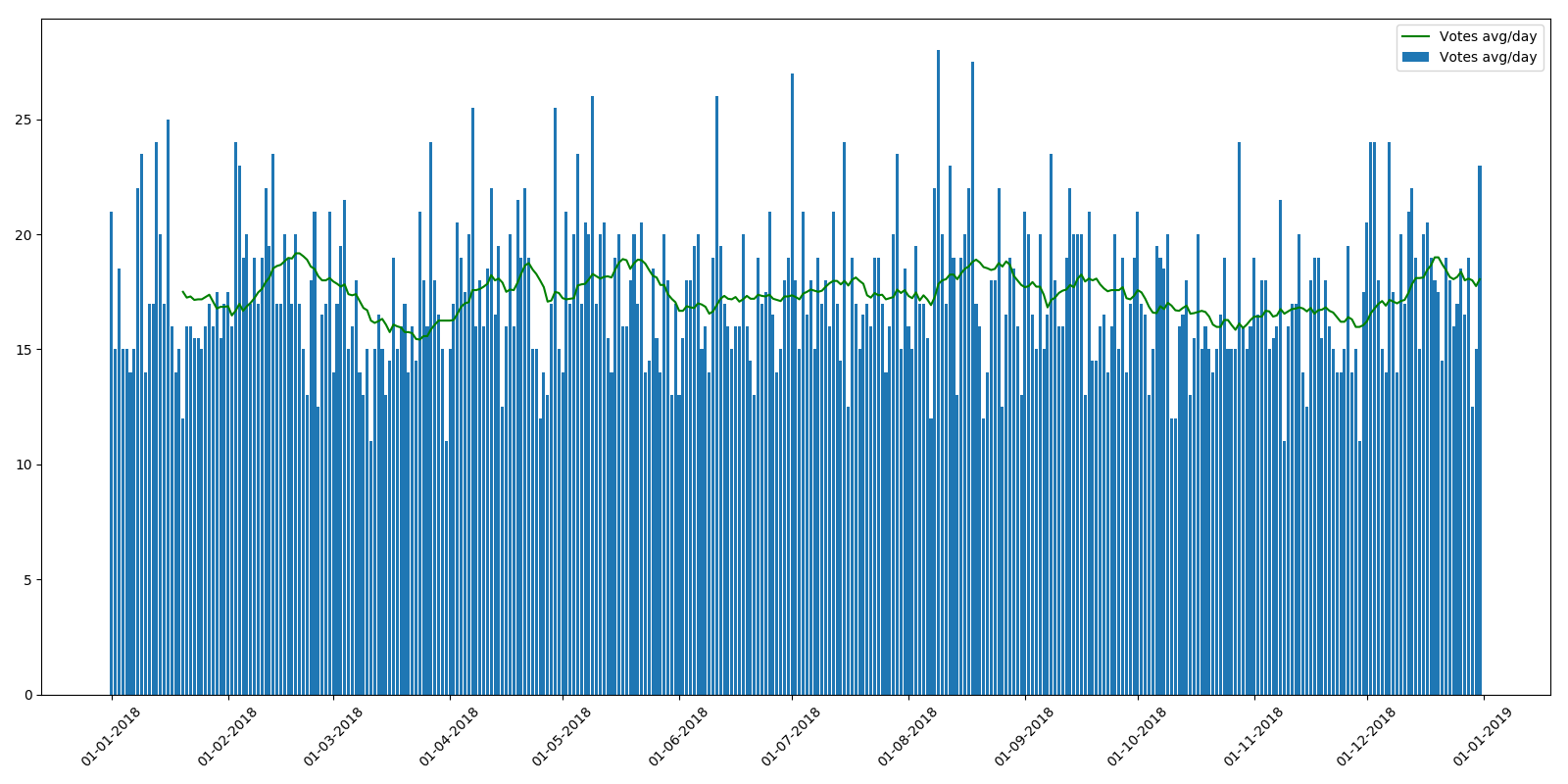
Em geral, os proprietários de recursos têm algo em que pensar.
Mas não vamos falar sobre coisas tristes. Em geral, podemos dizer que Habr "sobreviveu" ao verão muda com bastante sucesso e o número de artigos no site não diminuiu.
Classificação
Agora, na verdade, a classificação. Parabéns para quem o acertou. Deixe-me lembrá-lo mais uma vez de que a classificação não é oficial, talvez eu tenha perdido alguma coisa, e se algum artigo definitivamente estiver aqui, mas não estiver escrito, eu a adicionarei manualmente. Como classificação, uso métricas calculadas que, ao que me parece, se mostraram bastante interessantes.
Artigos mais vistos- Mentiras de LED de proporções sem precedentes 241.000 visualizações, 569 comentários, classificação + 364.0 / -1.0
- 'Artigo sobre boquete': cientistas processaram 109 horas de sexo oral para desenvolver uma IA que suga um membro 236.000 visualizações, 361 comentários, classificação + 240,0 / -68,0
- O que o designer fumava: uma arma de fogo incomum 235.000 visualizações, 123 comentários, avaliação + 119,0 / -9,0
- Como eu não trabalhei por um ano no Sberbank 233.000 visualizações, 580 comentários, classificação + 449.0 / -14.0
- Cientistas descobriram o vertebrado vivo mais antigo da Terra 221000 visualizações, 211 comentários, classificação + 82,0 / -14,0
- Lâmpadas inteligentes jogadas no lixo são uma fonte valiosa de informações pessoais 219.000 visualizações, 147 comentários, classificação + 73,0 / -11,0
- Development King 178.000 visualizações, 668 comentários, avaliação + 315.0 / -60.0
- Fraudadores e EDS - tudo está muito ruim 175.000 visualizações, 778 comentários, classificação + 356.0 / -0.0
- A série 'Chernobyl': assista e pense 172.000 visualizações, 803 comentários, classificação + 164.0 / -25.0
- O pior controle de volume de som da interface do usuário 166.000 visualizações, 176 comentários, classificação + 292,0 / -30,0
- Um resumo honesto de um programador 165.000 visualizações, 283 comentários, classificação + 410.0 / -40.0
- Eu estrago a vida dos desenvolvedores com meus comentários de código e desculpe-me 164.000 visualizações, 12 comentários, avaliação + 33.0 / -3.0
- Como Megafon dormiu em assinaturas móveis 162.000 visualizações, 676 comentários, classificação + 624.0 / -2.0
- Revolta no Picaba. Os usuários acessam o Reddit em massa 160.000 visualizações, 484 comentários, classificação + 215,0 / -41,0
- Pilhas AAA baratas e caras 159.000 visualizações, 382 comentários, classificação + 363,0 / -6,0
- Aposentado em 22.156.000 visualizações, 922 comentários, classificação + 259,0 / -100,0
- Homem sem smartphone 152000 visualizações, 736 comentários, classificação + 173,0 / -25,0
- Quer LEDs eternos? Descubra ferros e arquivos de solda. Ou iluminação caseira caseira 149.000 visualizações, 262 comentários, classificação + 94,0 / -6,0
- O que você não precisa fazer se seu telefone for roubado 144.000 visualizações, 638 comentários, classificação + 259,0 / -27,0
- 1 de fevereiro de 2019, seu site pode parar de funcionar 143.000 visualizações, 162 comentários, classificação + 89,0 / -8,0
Artigos principais sobre a proporção de classificações e visualizações- Fraqueza, parte 2: o prazo de votação para publicações e outras mudanças é 14000 visualizações, classificação + 238,0 / -3,0
- Bastante fantasioso 'Começo' de Euclides no TeX-e 10.800 visualizações, classificação + 136,0 / -0,0
- Recompensa do usuário aos autores de Habr 26400 visualizações, classificação + 320,0 / -0,0
- Enviando mensagens de impressão incorreta nas publicações 18.900 visualizações, classificação + 179,0 / -2,0
- Olá mundo! Or Habr em inglês, v1.0 21.000 visualizações, classificação + 178.0 / -2.0
- Vida nas partículas 34.000 visualizações, classificação + 267,0 / -2,0
- Civilization of Springs, 5/5 25800 visualizações, classificação + 201,0 / -1,0
- Jogamos Tetris na tela eletromecânica 16300 visualizações, classificação + 124,0 / -0,0
- Recriar fontes de uma tela CRT 13.400 visualizações, classificação + 101,0 / -0,0
- O modelo matemático do jogo é Dobble 14600 visualizações, classificação + 110.0 / -0.0
- Uma mensagem importante sobre convites no perfil é 18300 visualizações, classificação + 137,0 / -8,0
- Enfraquecer as porcas nas regras Habr 48300 visualizações, classificação + 338,0 / -13,0
- Comparação de codecs mágicos de rua. Revelamos os segredos de 21.700 visualizações, classificação + 144,0 / -0,0
- Analisador inteligente para números gravados em palavras 20.500 visualizações, classificação + 136,0 / -1,0
- Modelos genéricos e de metaprogramação: Go, Rust, Swift, D e outras 17000 visualizações, classificação + 110,0 / -2,0
- Crio uma base de conhecimento global sobre baterias 22.200 visualizações, classificação + 139,0 / -0,0
- Como escrevi e publiquei um livro sobre a Universidade Estatal de Moscou, ou 12 erros críticos, 21.600 visualizações, classificação + 134,0 / -0,0
- Sobre kote, esposa, dois filhos, a idéia ... e não apenas. Uma história com uma continuação de 43.000 visualizações, classificação + 269,0 / -8,0
- Vídeo computado em 755 megapixels: plenoptics ontem, hoje e amanhã 41.500 visualizações, classificação + 244,0 / -0,0
- A densidade de plotagem no varejo 27.500 visualizações, classificação + 160,0 / -1,0
Artigos principais sobre a proporção de comentários e visualizações- O Github começou a bloquear repositórios de usuários da Criméia, Cuba, Irã, Coréia do Norte e Síria 44.500 visualizações, 1.309 comentários, classificação + 115,0 / -6,0
- Ucraniano lições 60400 visualizações, 1672 comentários, avaliação + 285,0 / -41,0
- Enfraquecer as nozes nas regras Habr 48300 visualizações, 1285 comentários, avaliação + 338,0 / -13,0
- A manifestação contra o isolamento do Runet 50.900 visualizações, 923 comentários, classificação + 204,0 / -32,0
- Como montar duas rodas para trabalhar 47100 visualizações, 781 comentários, classificação + 113,0 / -10,0
- Acidente de avião em Sheremetyevo: analogias históricas 82.400 visualizações, 1211 comentários, avaliação + 147,0 / -11,0
- Os engenheiros salvam as pessoas perdidas na floresta, mas a floresta ainda não se rendeu 28.900 visualizações, 423 comentários, classificação + 132,0 / -1,0
- Comute contra o isolamento do Runet 63.300 visualizações, 820 comentários, classificação + 182,0 / -20,0
- Como a proteção das crianças contra a informação é organizada - e a história encantadora sobre sua origem (18+) 65.400 visualizações, 811 comentários, classificação + 175,0 / -2,0
- Olá mundo! Or Habr em inglês, v1.0 21.000 visualizações, 249 comentários, classificação + 178.0 / -2.0
- Como comprar batatas corretamente, se você é daltônico 51.800 visualizações, 607 comentários, avaliação + 135.0 / -3.0
- Como é ser um mantenedor de software livre 22.900 visualizações, 259 comentários, avaliação + 129.0 / -3.0
- Fraqueza, parte 2: período de votação para publicações e outras mudanças 14000 visualizações, 158 comentários, classificação + 238,0 / -3,0
- Produção piloto de eletrônicos por um preço mínimo de 34.200 visualizações, 382 comentários, classificação + 165.0 / -3.0
- Como equipamos o Megaphone 39800 visualizações, 405 comentários, classificação + 140,0 / -6,0
- Guerras nucleares do passado distante? 83.400 visualizações, 843 comentários, avaliação + 133,0 / -5,0
- Olá mundo! Ou Habr de língua inglesa, v1.0 60.300 visualizações, 591 comentários, classificação + 268,0 / -7,0
- Space as a vaga memory 43200 visualizações, 402 comentários, avaliação + 190.0 / -7.0
- Recompensa do usuário aos autores de Habr 26.400 visualizações, 245 comentários, classificação + 320,0 / -0,0
- Os princípios do mercado livre no entendimento dos Estados Unidos 56.300 visualizações, 502 comentários, classificação + 160,0 / -44,0
Artigos mais controversos- State and T-killers 752 comentários, avaliação + 83,0 / -80,0, 15100 visualizações
- Esses caras tóxicos: envenenam projetos 120 comentários, avaliação + 67.0 / -51.0, 50.300 visualizações
- Por que você ensina ao Go 70 comentários, avaliação + 76.0 / -57.0, 23100 visualizações
- Eu li 80 currículos, tenho perguntas 635 comentários, classificação + 135,0 / -94,0, 90700 visualizações
- Por que é realmente impossível ser vegetariano 940 comentários, avaliação + 76.0 / -52.0, 51.600 visualizações
- Programação funcional: um brinquedo maluco que mata a produtividade do trabalho. Parte 1 394 comentários, avaliação + 100,0 / -68,0, 54000 visualizações
- Escrevemos o código mais útil em nossa vida, mas jogamos no lixo. Together with us 259 comentários, avaliação + 101,0 / -63,0, 62900 visualizações
- Recurso na Apple 96 comentários, avaliação + 90,0 / -52,0, 39,300 visualizações
- Por que o Windows não dirige em 2019 ou CHYDNT? 881 comentários, avaliação + 123,0 / -70,0, 75.000 visualizações
- Não sou real 246 comentários, avaliação + 105,0 / -59,0, 63900 visualizações
- Cinco tendências assustadoras do desenvolvimento moderno 262 comentários, avaliação + 95,0 / -52,0, 77400 visualizações
- Quanto mais rápido você esquecer OOP, melhor para você e seus programas 1271 comentários, avaliação + 131,0 / -63,0, 128000 visualizações
- Um ano ao volante de um veículo elétrico 1098 comentários, avaliação + 131,0 / -58,0, 71800 visualizações
- Vou parar de chutar bem para lançar 179 comentários, classificação + 147,0 / -62,0, 34.400 visualizações
- Catch me if you 215 comentários, avaliação + 141.0 / -58.0, 65.400 visualizações
- Aposentado em 22.922 comentários, classificação + 259,0 / -100,0, 156.000 visualizações
- Resposta do psiquiatra ao artigo 'Doente e saudável' 272 comentários, avaliação + 154,0 / -55,0, 43.400 visualizações
- Novas linguagens de programação eliminam imperceptivelmente nossa conexão com a realidade 764 comentários, classificação + 164,0 / -52,0, 106.000 visualizações
- Alcoolismo no último estágio 597 comentários, avaliação + 208,0 / -60,0, 123.000 visualizações
- 'Artigo sobre boquete': cientistas processaram 109 horas de sexo oral para desenvolver uma IA que suga um membro 361 comentários, avaliação + 240,0 / -68,0, 236.000 visualizações
Artigos mais votados- Como Megafon dormiu em assinaturas móveis , 676 comentários, classificação + 624,0 / -2,0, 162.000 visualizações
- 'Conteúdo para celular' de graça, sem SMS e registros. Detalhes de fraude de megafone , 474 comentários, avaliação + 488.0 / -8.0, 112.000 visualizações
- Inovações em russo , 612 comentários, classificação + 480,0 / -33,0, 127.000 visualizações
- Como eu não trabalhei por um ano no Sberbank , 580 comentários, classificação + 449,0 / -14,0, 233.000 visualizações
- Como o Protonmail é bloqueado na Rússia , 398 comentários, avaliação + 418,0 / -7,0, 102.000 visualizações
- 10 anos em TI com diagnóstico de esquizofrenia, dicas de sobrevivência , 281 comentários, classificação + 403,0 / -8,0, 122.000 visualizações
- Um resumo honesto de um programador , 283 comentários, avaliação + 410,0 / -40,0, 165.000 visualizações
- Quando 'a' não é igual a 'a'. Na sequência de um hack , 64 comentários, avaliação + 374,0 / -5,0, 74.600 visualizações
- Aumente isso! Aumento da resolução moderna , 214 comentários, classificação + 366,0 / -1,0, 104000 visualizações
- Mentiras de LED de proporções sem precedentes , 569 comentários, classificação + 364,0 / -1,0, 241.000 visualizações
- Pilhas AAA baratas e caras , 382 comentários, avaliação + 363,0 / -6,0, 159.000 visualizações
- Fraudadores e EDS - tudo está muito ruim , 778 comentários, avaliação + 356,0 / -0,0, 175000 visualizações
- Japão: um país de bom senso que, em alguns lugares, é irracional para nós , 483 comentários, classificação + 365,0 / -12,0, 138.000 visualizações
- Fraqueza nas regras Habr , 1285 comentários, classificação + 338,0 / -13,0, 48300 visualizações
- Recompensa do usuário aos autores de Habr , 245 comentários, classificação + 320,0 / -0,0, 26.400 visualizações
- Como eu peguei um hacker , 273 comentários, classificação + 305,0 / -6,0, 110.000 visualizações
- Mitos da física popular moderna , 556 comentários, classificação + 304,0 / -6,0, 99.600 visualizações
- Agora, bons desenvolvedores são medidos por visualizações e assinantes - e isso é ruim , 486 comentários, classificação + 324,0 / -26,0, 74800 visualizações
- Sobreviva a uma colisão frontal e por que a amnésia não é o que você pensa , 165 comentários, classificação + 297.0 / -4.0, 61800 visualizações
- Port scanner na conta pessoal da Rostelecom , 194 comentários, classificação + 300,0 / -8,0, 111.000 visualizações
Top Bookmark Artigos- 42 Operadores de pesquisa avançada do Google (lista completa) 47.100 visualizações, 917 favoritos
- Como se tornar um desenvolvedor Java em 1,5 anos 88.500 visualizações, 894 favoritos
- Sampler. Utilitário de console para visualizar o resultado de qualquer comando do shell 58.400 visualizações, 801 favoritos
- HBO, obrigado por me lembrar ... 'Kit de primeiros socorros em Chernobyl' de um farmacêutico bielorrusso 88.500 visualizações, 797 favoritos
- Dicas práticas, exemplos e túneis SSH 40.000 visualizações, 787 favoritos
- 256 linhas de C ++ simples: escrevendo um traçador de raios do zero em poucas horas 60.000 visualizações, 745 marcadores
- Programação assíncrona (curso completo) 36.700 visualizações, 690 favoritos
- Funcionários 'queimados': existe uma saída? 116.000 visualizações, 688 favoritos
- Uma ampla visão geral das entrevistas em Python. Dicas e Truques 28.400 visualizações, 687 favoritos
- 15 livros de aprendizado de máquina para iniciantes 18.700 visualizações, 670 favoritos
- Curso de palestras sobre JavaScript e Node.js no KPI 52500 visualizações, 656 favoritos
- Como escrevo notas de matemática no LaTeX no Vim 58100 visualizações, 652 favoritos
- O que aprendi com minha experiência amarga (mais de 30 anos em desenvolvimento de software) 100.000 visualizações, 651 favoritos
- Uma seleção de slides úteis de Julia Evans 41.000 visualizações, 587 favoritos
- Cabeçalhos HTTP para desenvolvedor responsável 33.600 visualizações, 566 favoritos
- N + 7 livros úteis 42.700 visualizações, 563 favoritos
- Hacking CAN bus automático. Painel virtual 60.700 visualizações, 562 favoritos
- Mudança cuidadosa para a Holanda com sua esposa e hipoteca. Parte 1: procura de emprego 76200 visualizações, 555 favoritos
- TCP vs UDP ou o futuro dos protocolos de rede 50.300 visualizações, 538 marcadores
- Melhores distribuições Linux para computadores mais antigos 66.000 visualizações, 523 favoritos
Relação de Favoritos de Topo por Vista- 15 livros de aprendizado de máquina para iniciantes 670 favoritos, 18.700 visualizações
- Música para seus projetos: 12 recursos temáticos com faixas licenciadas sob Creative Commons 477 favoritos, 18.100 visualizações
- Uma ampla visão geral das entrevistas em Python. Dicas e Truques 687 favoritos, 28.400 visualizações
- Uma seleção de conjuntos de dados para aprendizado de máquina 455 indicadores, 19.000 visualizações
- Gerador de masmorra com base em nós do gráfico 304 indicadores, 12,700 visualizações
- Uma explicação simples dos algoritmos de pesquisa de caminho e marcadores A * 316, 13.500 visualizações
- Ferramentas da Web ou por onde começar um pentester? 421 favoritos, 18800 visualizações
- Learning Docker, Parte 2: Termos e conceitos 341 favoritos, 15,600 visualizações
- Explorando o Docker, parte 3: arquivos do Dockerfile 297 favoritos, 13.800 visualizações
- Ferramentas para analisar e depurar aplicativos .NET 244 favoritos, 11.600 visualizações
- Como depurar variáveis de ambiente nos favoritos do Linux 322, 15.900 visualizações
- Como dar os primeiros passos na robótica? 224 favoritos, 11.200 visualizações
- Labirintos: classificação, geração, busca de soluções 318 favoritos, 16.000 visualizações
- Dicas práticas, exemplos e túneis Marcadores SSH 787, 40.000 visualizações
- Palestra Curso 'Fundamentos do processamento de sinais digitais' 418 favoritos, 21,400 visualizações
- 42 Operadores de pesquisa avançada do Google (lista completa) 917 favoritos, 47.100 visualizações
- Shaders de jogos 3D para iniciantes 239 favoritos, 12,400 visualizações
- Aponte os bloqueios PKH de desvio em um roteador com o OpenWrt usando indicadores WireGuard e DNSCrypt 302, 15.700 visualizações
- Desenvolvendo a habilidade de usar o agrupamento e a visualização de dados nos indicadores do Python 192, 10.000 visualizações
- Outro Github 2: aprendizado de máquina, conjuntos de dados e Jupyter Notebooks 265 favoritos, 13.900 visualizações
Artigos mais comentados- Aulas de ucraniano 1672 comentários, 60,400 visualizações
- Foguete 9M729. Algumas palavras sobre o “violador” do Tratado INF 1371 comentários, 83.000 visualizações
- O Github começou a bloquear repositórios de usuários da Criméia, Cuba, Irã, Coréia do Norte e Síria 1.309 comentários, 44.500 visualizações
- Nozes enfraquecidas em regras de Habr 1285 comentários, 48300 visualizações
- Quanto mais rápido você esquecer OOP, melhor para você e seus programas 1271 comentários, 128000 visualizações
- Acidente de avião em Sheremetyevo: analogias históricas 1211 comentários, 82.400 visualizações
- Como a geração Y se transformou em uma geração esgotada? 1122 comentários, 81.500 visualizações
- Carro elétrico não é para mim 1116 comentários, 50.700 visualizações
- 1098 , 71800
- 1021 , 27500
- 999 , 62100
- 997 , 7700
- 940 , 51600
- , 933 , 120000
- 923 , 50900
- 22 922 , 156000
- Escolhendo um carro para um especialista em TI ou dicas para bules a partir de um bule 914 comentários, 43.400 visualizações
- Por que os desenvolvedores seniores não conseguem um emprego 901 comentários, 119.000 visualizações
- O plano retornou à economia 892 comentários, 27.800 visualizações
- Teleportador da cidade pessoal 889 comentários, 40.800 visualizações
E, finalmente, o último anti-stop pelo número de antipatias- Aposentado em 22.922 comentários, classificação + 259,0 / -100,0
- Eu li 80 currículos, tenho perguntas , 635 comentários, classificação + 135,0 / -94,0
- Querida, matamos a Internet , 933 comentários, classificação + 392,0 / -83,0
- State and T-killers , 752 comentários, classificação + 83,0 / -80,0
- Windows 2019 , ? , 881 , +123.0/-70.0
- : , . 1 , 394 , +100.0/-68.0
- ' ': 109 , , , 361 , +240.0/-68.0
- , . , 259 , +101.0/-63.0
- , , 1271 , +131.0/-63.0
- - , 179 , +147.0/-62.0
- , 668 , +315.0/-60.0
- , 597 , +208.0/-60.0
- , 246 , +105.0/-59.0
- , , 215 , +141.0/-58.0
- , 1098 , +131.0/-58.0
- Go , 70 , +76.0/-57.0
- '-' , 272 , +154.0/-55.0
- Apple , 96 , +90.0/-52.0
- , 764 , +164.0/-52.0
- Cinco tendências assustadoras do desenvolvimento moderno , 262 comentários, classificação + 95,0 / -52,0
Uff. Tenho algumas amostras mais interessantes, mas não vou aborrecer os leitores.Conclusão
Ao criar a classificação, chamei a atenção para dois pontos que pareciam interessantes.Em primeiro lugar, afinal, 60% dos principais são artigos do gênero geektimes. Se haverá menos deles no próximo ano e como o Habr ficará sem artigos sobre cerveja, espaço, remédios e assim por diante - eu não sei. Os leitores definitivamente perderão algo. Vamos ver
Em segundo lugar, o topo dos favoritos acabou sendo inesperadamente de alta qualidade. Isso é psicologicamente compreensível, os leitores podem não prestar atenção à classificação e, se um artigo for necessário , eles o adicionarão aos favoritos. E aqui está apenas a maior concentração de artigos úteis e sérios. Penso que os proprietários do site devem considerar de alguma forma a relação entre o número de favoritos e o programa de incentivos, se quiserem aumentar essa categoria específica de artigos aqui no Habré.Algo assim.
Espero que tenha sido informativo.A lista de artigos é longa, mas provavelmente é a melhor. Gostam de ler para todos.