Recentemente, deparei-me
com um conjunto de dados
Kaggle com dados de 45 mil filmes do Full MovieLens Dataset. Os dados continham não apenas informações sobre os atores, a equipe, o enredo etc., mas também as classificações apresentadas pelos usuários dos filmes para filmes (26 milhões de classificações de 270 mil usuários).
Uma tarefa padrão para esses dados é um sistema de recomendação. Mas, por alguma razão, ocorreu-me
prever a classificação de um filme com base nas informações disponíveis antes de seu lançamento . Eu não sou um conhecedor de cinema e, portanto, geralmente me concentro em críticas, escolhendo o que ver nas notícias. Mas os revisores também são um tanto tendenciosos - eles assistem a muito mais filmes diferentes do que o espectador comum. Portanto, parecia interessante prever como o filme seria apreciado pelo público em geral.
Portanto, o conjunto de dados contém as seguintes informações:
- Informações sobre o filme: tempo de lançamento, orçamento, idioma, empresa e país de origem, etc. Bem como a classificação média (e vamos prever)
- Palavras-chave (tags) sobre o gráfico
- Nomes dos atores e equipe
- Na verdade classificações (estimativas)
O código usado no artigo (python) está disponível no
github .
Pré-filtragem de dados
A matriz completa contém dados sobre mais de 45 mil filmes, mas como a tarefa é prever a classificação, é necessário garantir que as classificações de um filme específico sejam objetivas. Por exemplo, no fato de muitas pessoas gostarem disso.
A maioria dos filmes tem muito poucas classificações:

A propósito, o filme com o maior número de classificações (14075) me surpreendeu - este é
“Inception” . Mas os próximos três - "O Cavaleiro das Trevas", "Avatar" e "Vingadores" parecem bastante lógicos.
Espera-se que o número de classificações e o orçamento do filme estejam interconectados (orçamento mais baixo - classificações mais baixas). Portanto, a remoção de filmes com um pequeno número de classificações torna o modelo tendencioso em direção a filmes mais caros:
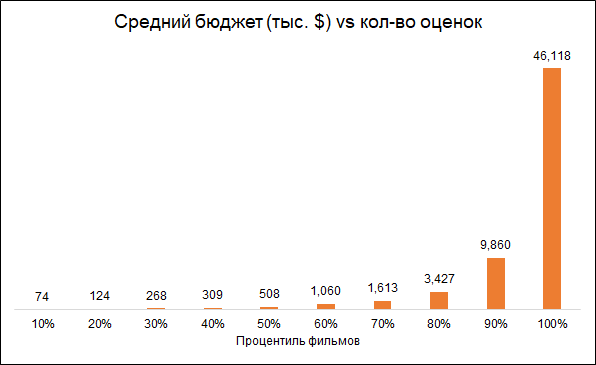
Partimos para filmes de análise com mais de 50 classificações.
Além disso, removeremos os filmes lançados antes do início do serviço de classificação (1996). Aqui, o problema é que os filmes modernos são classificados em média piores que os filmes antigos, simplesmente porque entre os filmes antigos, eles assistem e avaliam os melhores, e entre os filmes modernos, isso é tudo.
Como resultado, a matriz final contém cerca de 6 mil filmes.
Recursos Usados
Usaremos vários grupos de recursos:
- Metadados do filme : se o filme pertence à "coleção" (série de filmes), país de lançamento, empresa de fabricação, idioma do filme, orçamento, gênero, ano e mês de lançamento do filme, sua duração
- Palavras-chave: para cada filme, há uma lista de tags que descrevem seu enredo. Como existem muitas palavras, elas foram processadas da seguinte forma: agrupadas em grupos de similaridade (por exemplo, acidente e acidente de carro), com base nesses grupos e em palavras individuais, uma análise de PCA foi feita e os componentes mais importantes foram selecionados a partir de seus resultados. Isso reduziu a dimensão do espaço do recurso.
- Méritos anteriores dos atores que estrelaram o filme. Para cada ator, foi formada uma lista de filmes nos quais ele estrelou anteriormente e a classificação desses filmes foi calculada. Assim, para cada filme foi formado um indicador que agrega o sucesso dos filmes em que os atores estrelaram anteriormente.
- Oscars. Se os atores, diretor, produtor, roteirista ou cinegrafista já participaram do filme, que foi indicado ou recebeu um Oscar de melhor filme, direção ou roteiro, isso foi levado em consideração no modelo. Além disso, se os atores foram indicados ou vencedores do Oscar de Melhor Ator Coadjuvante ou Papel Coadjuvante, isso também foi levado em consideração. Informações sobre o Oscar recebido da Wikipedia.
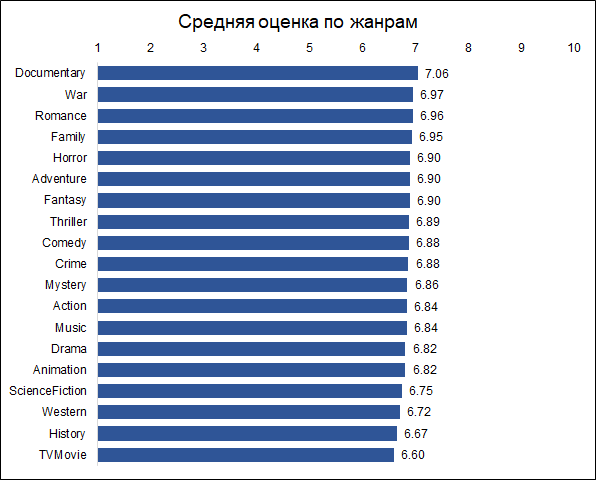
Algumas estatísticas interessantes
Os documentários recebem as classificações mais altas. Esse é um bom motivo para observar que filmes diferentes são avaliados por pessoas diferentes e, se os documentários foram classificados por fãs de ação, os resultados podem ser diferentes. Ou seja, as estimativas são tendenciosas devido às preferências iniciais do público. Mas para a nossa tarefa isso não é importante, pois queremos prever uma avaliação não condicional objetiva (como se cada espectador assistisse a todos os filmes), a saber, a que será dada ao filme pelo público.
A propósito, é interessante que os filmes históricos sejam classificados muito mais baixos que os documentários.
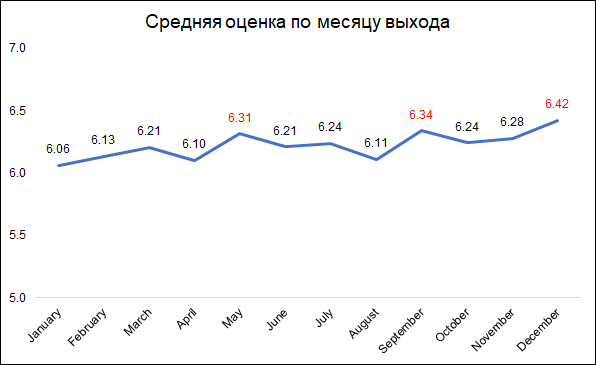
 As classificações mais altas são dadas aos filmes lançados em dezembro, setembro e maio.
As classificações mais altas são dadas aos filmes lançados em dezembro, setembro e maio.Provavelmente, isso pode ser explicado da seguinte maneira:
- em dezembro, as empresas lançam os melhores filmes para coletar bilheteria durante as férias de Natal
- em setembro, serão lançados filmes que participarão da luta pelo Oscar
- Maio é o tempo de lançamento dos blockbusters de verão.
 A classificação do filme depende pouco do orçamento
A classificação do filme depende pouco do orçamento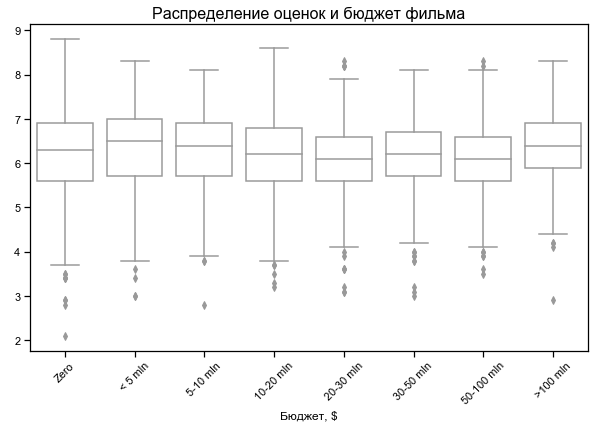
Orçamento zero para alguns filmes - provavelmente sem dados
Filmes mais curtos e mais longos com melhor classificação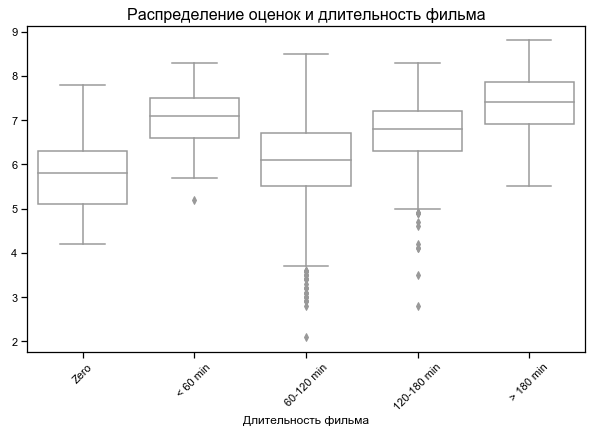
Para alguns filmes, a duração zero é indicada - provavelmente nenhum dado
Resultados em diferentes conjuntos de recursos
Nossa tarefa - prever a classificação - a tarefa de regressão. Testaremos três modelos - regressão linear (como linha de base), SVM e XGB. Como uma métrica de qualidade, escolhemos o RMSE. O gráfico abaixo mostra os valores RMSE no conjunto de validação para diferentes modelos e diferentes conjuntos de recursos (eu queria entender se valia a pena mexer com palavras-chave e Oscars). Todos os modelos são construídos com hiperparâmetros básicos.
Como você pode ver, o XGB tem o melhor resultado com um conjunto completo de recursos (metadados do filme + palavras-chave + Oscars).
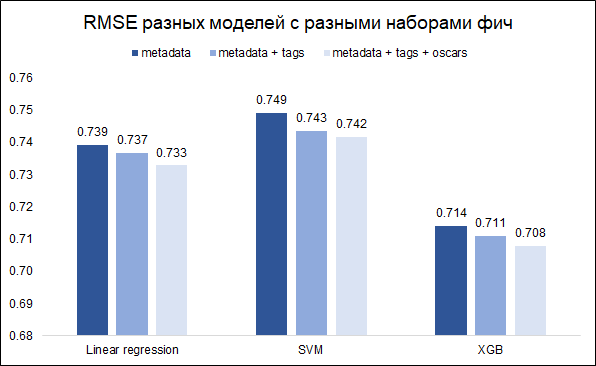
Ajustando os hiperparâmetros, foi possível reduzir o RMSE de 0,708 para 0,706
Análise de erros e comentários finais
Assumimos que erros inferiores a 5% são pequenos (cerca de um terço) e erros superiores a 20% são grandes (cerca de 10%). Em outros casos (um pouco mais da metade), consideraremos a média do erro.
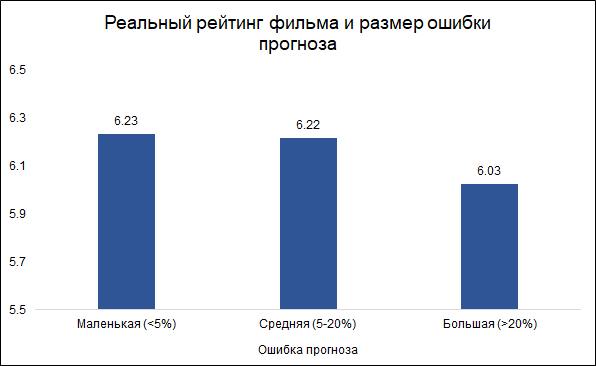
Curiosamente, o tamanho do erro e a classificação do filme estão relacionados:
é menos provável que o
modelo cometa erros em bons filmes e mais frequentemente em erros. Parece lógico: bons filmes, como qualquer outro trabalho, são feitos por pessoas mais experientes e profissionais. Sobre o filme de Tarantino com a participação de Brad Pitt, você pode dizer com antecedência que provavelmente será bom. Ao mesmo tempo, um filme de baixo orçamento com atores pouco conhecidos pode ser bom e ruim, e é difícil julgar sem vê-lo.
Aqui estão os recursos mais importantes do modelo (as variáveis PCA se referem às palavras-chave processadas que descrevem o enredo do filme):

Dois desses filmes pertencem ao Oscar, que foi previamente indicado por membros da equipe (diretor, produtor, roteirista, cinegrafista) ou filmes nos quais os atores estrelaram. Como mencionado acima, o erro de previsão está associado à avaliação do filme e, nesse sentido, indicações anteriores para o Oscar podem ser um bom delimitador para o modelo. De fato, os filmes que têm pelo menos uma indicação ao Oscar (entre atores ou equipes) têm um erro médio de previsão de 8,3%, e os que não têm essas indicações - 9,8%. Entre os 10 principais recursos usados no modelo, são as indicações ao Oscar que dão a melhor conexão com o tamanho do erro.
Portanto, surgiu a idéia de construir dois modelos separados: um para filmes em que os atores ou a equipe foram indicados ao Oscar e o segundo ao restante. A ideia era que isso pudesse reduzir o erro geral. No entanto, o experimento falhou: o modelo geral deu RMSE 0,706, e dois separados deram 0,715.
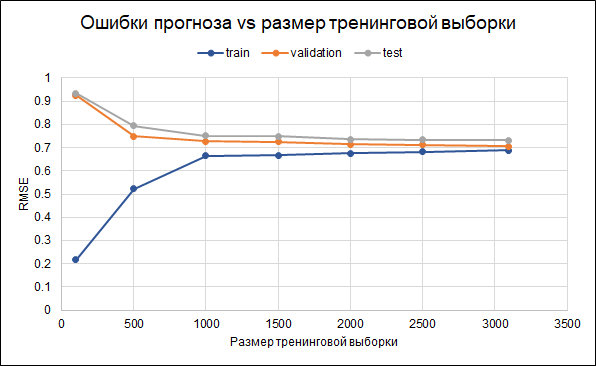
Portanto, deixaremos o modelo original. Os resultados de sua precisão são os seguintes: RMSE na amostra de treinamento - 0,688, na amostra de validação - 0,706 e na amostra de teste - 0,732.
Ou seja, há algum ajuste excessivo. Os parâmetros de regularização já foram definidos no próprio modelo. Outra maneira de reduzir o overfitting poderia ser coletar mais dados. Para entender se isso ajudará, construiremos um gráfico de erros para diferentes tamanhos da amostra de treinamento - de 100 ao máximo de 3.000 disponíveis.O gráfico mostra que a partir de cerca de 2,5 mil pontos no conjunto de treinamento, erros na alteração do conjunto de treinamento, validação e teste pequeno, ou seja, um aumento na amostra não terá um efeito significativo.
 O que mais você pode tentar refinar o modelo:
O que mais você pode tentar refinar o modelo:- Inicialmente, os filmes são selecionados de forma diferente (limite diferente no número de votos, limites adicionais em outras variáveis)
- Nem todas as classificações são usadas para calcular a classificação - é possível selecionar usuários mais ativos ou remover aqueles que dão apenas classificações ruins
- Experimente maneiras diferentes de substituir dados ausentes
Curiosamente, o filme "Batman e Robin" de 1997 teve o maior erro de previsão (7 pontos de previsão em vez de 4,2 reais). O filme com Arnold Schwarzenegger, George Clooney e Uma Thurman recebeu
11 indicações (e uma vitória) para o Golden Raspberry Award, liderou a
lista dos 50 piores filmes da história do Empire Newsreel e levou ao
cancelamento da sequência e ao reinício de toda a série . Bem, aqui o modelo, talvez, foi enganado como um homem :)