Eu sempre estava interessado em como distribuir melhor os livros na minha biblioteca eletrônica. Como resultado, cheguei a essa opção com o cálculo automático do número de páginas e outros itens. Peço a todos os interessados em gato.
Parte 1. Dropbox
Todos os livros que tenho estão na caixa de depósito. Existem quatro categorias nas quais eu dividi tudo: Livro didático, Referência, Artístico, Não artístico. Mas não adiciono livros de referência ao tablet.
A maioria dos livros é .epub, o restante é .pdf. Ou seja, a solução final deve, de alguma forma, cobrir as duas opções.
Os caminhos para os livros são mais ou menos assim:
///// / .epub
Se o livro for ficção, a categoria (ou seja, "Design" no caso acima) será removida.
Eu decidi não me incomodar com a API do dropbox, felizmente eu tenho o aplicativo deles que sincroniza a pasta. Ou seja, o plano é o seguinte: pegue livros de uma pasta, execute cada livro através de um contador de palavras, adicione-o ao Noção.
Parte 2. Adicione uma linha
A tabela em si deve se parecer com isso. ATENÇÃO: os nomes das colunas são melhores em letras latinas.
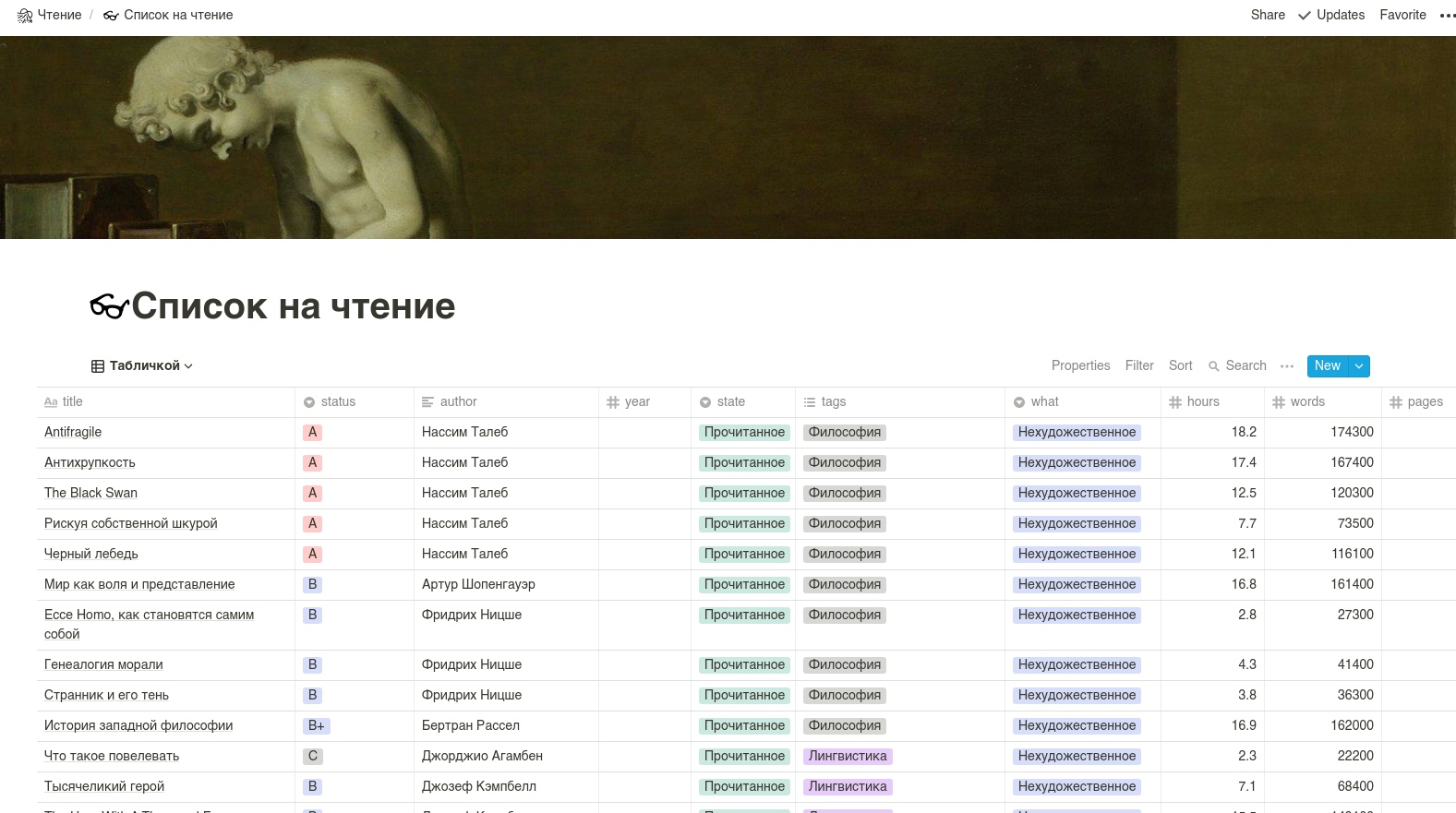
Usaremos a API não oficial da Noção, porque a oficial ainda não foi entregue.

Vá para Noção, pressione Ctrl + Shift + J, vá para Aplicativo -> Cookies, copie o token_v2 e chame-o de TOKEN. Então vamos para a página que precisamos com a placa da biblioteca e copiamos o link. Ligue para NOTION.
Em seguida, escrevemos o código para se conectar ao Noção.
database = client.get_collection_view(NOTION) current_rows = database.default_query().execute()
Em seguida, vamos escrever uma função para adicionar uma linha ao rótulo.
def add_row(path, file, words_count, pages_count, hours): row = database.collection.add_row() row.title = file tags = path.split("/") if len(tags) >= 1: row.what = tags[0] if len(tags) >= 2: row.state = tags[1] if len(tags) >= 3: if tags[0] == "": row.author = tags[2] elif tags[0] == "": row.tags = tags[2] elif tags[0] == "": row.tags = tags[2] if len(tags) >= 4: row.author = tags[3] row.hours = hours row.pages = pages_count row.words = words_count
O que está acontecendo aqui. Pegamos e adicionamos uma nova linha à tabela na primeira linha. Em seguida, dividimos nosso caminho por "/" e obtemos as tags. Tags - em termos de "Artístico", "Design", quem é o autor e assim por diante. Em seguida, definimos todos os campos necessários do prato.
Parte 3. Contando palavras, relógios e outras delícias
Esta é uma tarefa mais complicada. Como lembramos, temos dois formatos: epab e pdf. Se tudo estiver claro com o epab - provavelmente existem palavras, o que acontece com o pdf não é tão simples: ele pode simplesmente consistir em imagens coladas.
Portanto, a função para contar palavras em pdf ficará assim: pegamos o número de páginas e multiplicamos por uma certa constante (número médio de palavras por página).
Aqui está:
def get_words_count(pages_number): return pages_number * WORDS_PER_PAGE
Esta é a WORDS_PER_PAGE para a página A4, aproximadamente 300.
Agora vamos escrever uma função para contar as páginas. Vamos usar o PyPDF2 .
def get_pdf_pages_number(path, filename): pdf = PdfFileReader(open(os.path.join(path, filename), 'rb')) return pdf.getNumPages()
Em seguida, escreveremos um pouco sobre a contagem de páginas no epaba. Usamos epub_converter . Aqui pegamos um livro, convertemos em linhas e, para cada linha, contamos palavras.
def get_epub_pages_number(path, filename): book = open_book(os.path.join(path, filename)) lines = convert_epub_to_lines(book) words_count = 0 for line in lines: words_count += len(line.split(" ")) return round(words_count / WORDS_PER_PAGE)
Agora vamos fazer a contagem do tempo. Pegamos nosso número favorito de palavras e dividimos pela sua velocidade de leitura.
def get_reading_time(words_count): return round(((words_count / WORDS_PER_MINUTE) / 60) * 10) / 10
Parte 4. Conectando todas as peças
Precisamos percorrer todos os caminhos possíveis em nossa pasta de livros. Verifique se já existe um livro no Noção: se houver, não precisamos mais criar uma linha.
Então precisamos determinar o tipo de arquivo, dependendo disso, conte o número de palavras. Adicione um livro no final.
Aqui está o código que obtemos:
for root, subdirs, files in os.walk(BOOKS_DIR): if len(files) > 0 and check_for_excusion(root): for file in files: array = file.split(".") filetype = file.split(".")[len(array) - 1] filename = file.replace("." + filetype, "") local_root = root.replace(BOOKS_DIR, "") print("Dir: {}, file: {}".format(local_root, file)) if not check_for_existence(filename): print("Dir: {}, file: {}".format(local_root, file)) if filetype == "pdf": count = get_pdf_pages_number(root, file) else: count = get_epub_pages_number(root, file) words_count = get_words_count(count) hours = get_reading_time(words_count) print("Pages: {}, Words: {}, Hours: {}".format(count, words_count, hours)) add_row(local_root, filename, words_count, count, hours)
E a função para verificar se o livro foi adicionado é assim:
def check_for_existence(filename): for row in current_rows: if row.title in filename: return True elif filename in row.title: return True return False
Conclusão
Obrigado a todos que leram este artigo. Espero que ela ajude você a ler mais :)