Neste artigo, coletaremos um painel para análise de tráfego de SEO. Descarregaremos os dados através de scripts python e de arquivos .csv.
O que vamos descarregar?
Para analisar a dinâmica das posições das frases de pesquisa, você precisará descarregar do
Yandex.Webmaster e do
Google Search Console . Para avaliar a "utilidade" de bombear a posição da frase de pesquisa, os dados de frequência serão úteis. Eles podem ser obtidos no
Yandex.Direct e no
Google Ads . Bem, para analisar o comportamento do lado técnico do site, usaremos o
Page Speed Insider .
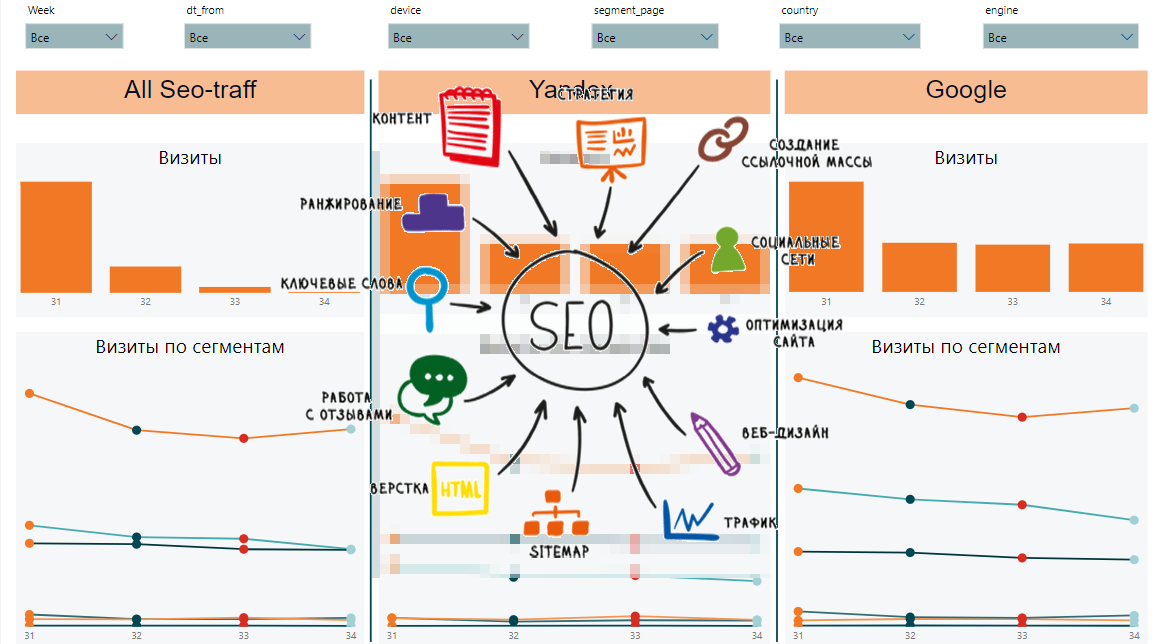 Dinâmica de tráfego SEO
Dinâmica de tráfego SEOConsole de pesquisa do Google
Para interagir com a API, usaremos a biblioteca
searchconsole . O github descreve em detalhes como obter os tokens necessários para o login. O procedimento para carregar e carregar dados no banco de dados MS SQL será o seguinte:
def google_reports():
Yandex.Webmaster
Infelizmente, o webmaster pode carregar apenas 500 frases de pesquisa. Carregar cortes por país, tipo de dispositivo etc. ele também não pode. Devido a essas restrições, além de enviar posições para 500 palavras do Webmaster, enviaremos dados do Yandex.Metrica para as páginas de destino. Para quem não possui muitas frases de busca, basta 500 palavras. Se o seu núcleo semântico de acordo com o Yandex for amplo o suficiente, você precisará descarregar posições de outras fontes ou escrever seu analisador de posição.
def yandex_reports(): token = "..."
Page Speed Insider
Permite avaliar a velocidade de download do conteúdo do site. Se o site começou a carregar mais lentamente, isso pode reduzir significativamente a posição do site nos resultados da pesquisa.
Anúncios do Google e Yandex Direct
Para estimar a frequência das consultas de pesquisa, descarregamos a frequência do nosso núcleo de SEO.
 Previsão de orçamento Yandex
Previsão de orçamento Yandex Planejador de palavras-chave do Google
Planejador de palavras-chave do GoogleMétrica Yandex
Carregue dados sobre visualizações e visitas para páginas de login do tráfego de SEO.
token = token headers = {"Authorization": "OAuth " + token} now = datetime.now() fr = (now - timedelta(days = 9)).strftime("%Y-%m-%d") to = (now - timedelta(days = 3)).strftime("%Y-%m-%d") res = requests.get("https://api-metrika.yandex.net/stat/v1/data/?ids=ids&metrics=ym:s:pageviews,ym:s:visits&dimensions=ym:s:startURL,ym:s:lastsignSearchEngine,ym:s:regionCountry,ym:s:deviceCategory&date1={0}&date2={1}&group=all&filters=ym:s:lastsignTrafficSource=='organic'&limit=50000".format(fr,to), headers=headers) a = json.loads(res.text) re = pd.DataFrame(columns=['page', 'device', 'view', 'dt_from', 'dt_to', 'engine', 'visits', 'country', 'pageviews']) for i in a['data']: temp={} temp['page'] = i['dimensions'][0]['name'] temp['engine'] = i['dimensions'][1]['name'] temp['country'] = i['dimensions'][2]['name'] temp['device'] = i['dimensions'][3]['name'] temp['view'] = i['metrics'][0] temp['visits'] = i['metrics'][1] temp['pageviews'] = i['metrics'][0] temp['dt_from'] = fr temp['dt_to'] = to re=re.append(temp, ignore_index=True) to_sql_server(re, 'yandex_pages')
Aquisição de dados no Power BI
Vamos ver o que conseguimos descarregar:
- google_positions e yandex_positions
- google_frequency e yandex_frequency
- google_speed e yandex_speed
- yandex_metrika
A partir desses dados, poderemos coletar dinâmicas por semana, por segmento, dados gerais por segmentos e solicitações, dinâmica e dados gerais por páginas e velocidade de carregamento de conteúdo. É assim que o relatório final pode ser:

Por um lado, existem muitos sinais diferentes e é difícil entender quais são as tendências gerais. Por outro lado, cada placa exibe dados importantes sobre posições, impressões, cliques, CTR, velocidade de carregamento da página.
Artigos do ciclo: