Geralmente, quando alguém fala sobre OSM, um dos serviços da Web aparece na sua cabeça ou um aplicativo como o Maps.me com base em
dados do OSM. De fato, o projeto OSM é principalmente de dados, todo o resto é essencialmente um caso especial de uso. Os serviços geralmente fornecem apenas uma parte das informações extraídas de acordo com suas regras.
Inicialmente, o OSM é uma coleção de pontos, links entre pontos e tags para eles. As fontes da comunidade têm dois formatos. Inicialmente, o
XML era usado como uma maneira prioritária de distribuição de dados, mas o arquivo Planet.osm, na forma descompactada, já excedeu os terabytes, e não vejo razão para usá-lo para informações relativamente volumosas.
O PBF tem uma grande vantagem - é binário e o arquivo earth inteiro tem um tamanho de cerca de 50 GB (XML compactado cerca de 80 GB).
Será sobre a importação de dados OSM do formato "nativo" usando a ferramenta Osmose.
Também precisamos do PostgreSql com a extensão Postgis, na qual importaremos dados do OSM.
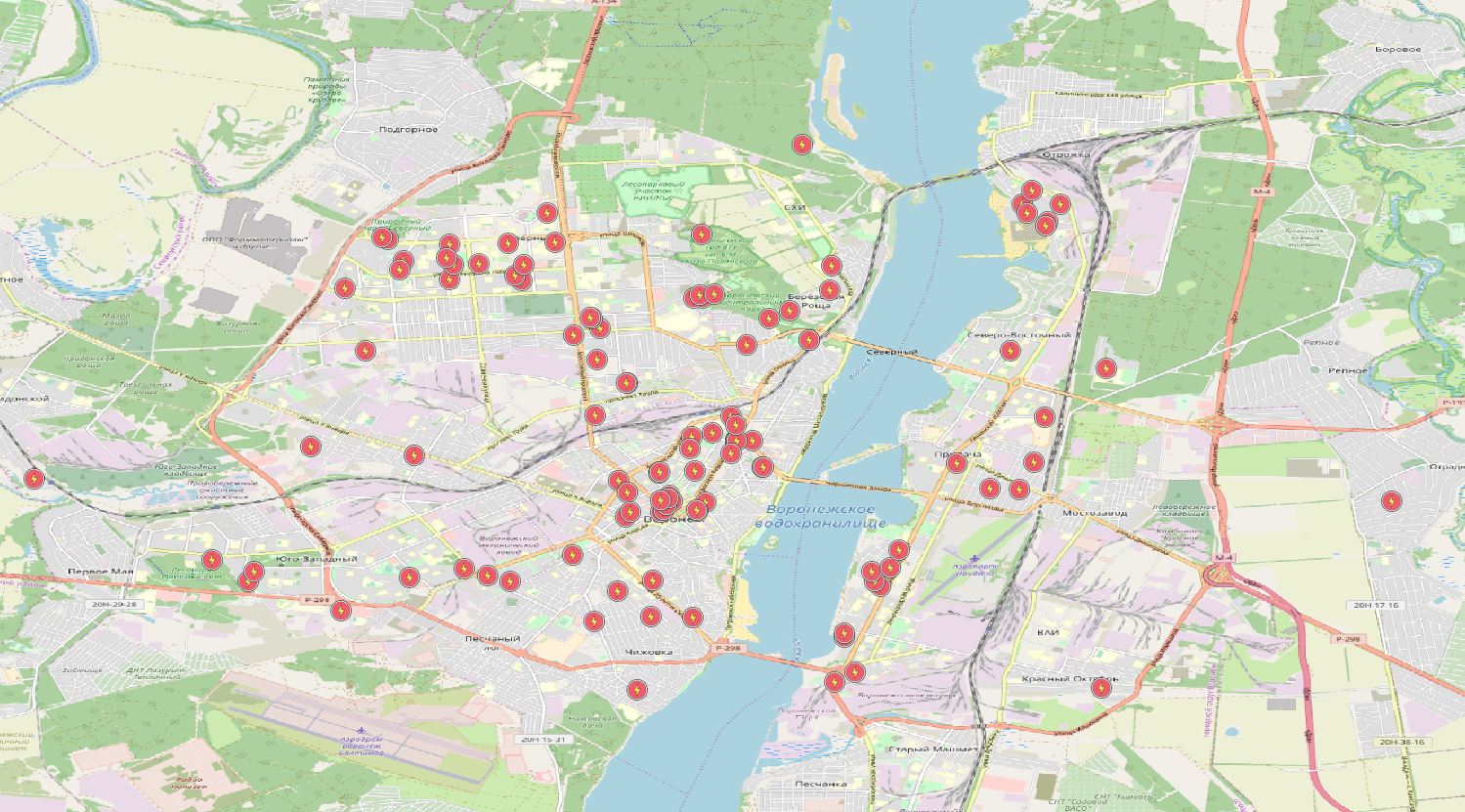
Como resultado, é possível obter informações sobre objetos
com as tags listadas aqui em seus bancos de dados
.
Preparação de DB.
Primeiro, crie um banco de dados no Postgresql, o nome realmente não importa.
psql -c "CREATE DATABASE map;"
Em seguida, adicione as extensões necessárias para trabalhos futuros.
psql -d map -c "CREATE EXTENSION postgis; CREATE EXTENSION hstore; "
A extensão do Postgis "conecta" ao banco de dados o módulo real para trabalhar com dados geográficos (lembro que você deve instalar o próprio Postgis). A extensão hstore foi projetada para funcionar com conjuntos de chaves / valores, como muita informação estará contida nas tags OSM.
Faça o download da
osmose . Em resumo, é um software para uma ampla variedade de operações com dados OSM. Há uma boa documentação sobre como trabalhar com a linha de comando. Fontes em Java. Abaixo usaremos a linha de comando. Também usei o Osmosis como uma biblioteca Java, o código-fonte (disponível no GitHub) me pareceu suficientemente claro e a API foi fácil de usar.
Agora estamos preparando o banco de dados para importação. As tabelas e funções necessárias podem ser criadas usando scripts localizados na pasta osmose / script. Além do script principal, executaremos o código SQL que criará um campo para armazenar a geometria das linhas. Isso se deve ao fato de que os dados OSM são mais provavelmente representados como conexões pontuais do que como um conjunto de formas geométricas.
psql -d map -fc:\osmosis\script\pgsnapshot_schema_0.6.sql psql -d map -fc:\osmosis\script\pgsnapshot_schema_0.6_linestring.sql
Importar dados do OSM para um banco de dados
Bem, agora quase tudo está pronto. Você pode até executar a importação. É necessário decidir o que tomaremos como fonte. Ou seja, você precisa escolher o formato e a fonte. Inicialmente, a comunidade OSM usou (e usa) o formato XML. Mas, como a quantidade de dados está aumentando e aumentando, o formato do texto está sendo gradualmente reduzido. Usar PBF é um pouco mais conveniente. A fonte central
planet.openstreetmap.org contém dados para o mundo inteiro. Com um arquivo, você pode baixar toda a base de conhecimento do projeto, que já excedeu 40 gigabytes em formato binário. Nesses casos, quando eu queria cortar alguns dados de lá, geralmente deixava o laptop trabalhando a noite toda, fornecendo mais de 100 GB de espaço livre no SSD para arquivos temporários.
No nosso caso, podemos começar usando envios de membros da comunidade. Existem recursos que possibilitam o download de dados apenas para uma região específica. Por exemplo,
download.geofabrik.de . Pegue a região de Voronezh. Lá está incluído em um arquivo contendo dados para todo o distrito federal central. Você pode fazer o download do central-fed-district-latest.osm.pbf e, em seguida, recortar a “peça” desejada em um arquivo ou filtro separado por coordenadas ao importar para o banco de dados. Eu sugeriria a primeira opção:
c:\osmosis\bin\osmosis.bat --read-pbf file="c:\downloads\central-fed-district-latest.osm.pbf" --bounding-box top=52.059564 left=37.92290 bottom=49.612297 right=43.225858 --write-pbf file="c:\map\voronezh.osm.pbf"
Tudo é simples aqui. Lemos o arquivo PBF, filtramos os resultados da leitura pelo retângulo de coordenadas e escrevemos os resultados após a filtragem no arquivo de saída. Você pode filtrar por coordenadas com mais precisão usando não um retângulo, mas um polígono cujas coordenadas estão em um arquivo separado.
O arquivo resultante voronezh.osm.pbf é então importado para o banco de dados. Para conectar, crie um arquivo de propriedades com parâmetros de acesso ao banco de dados:
host=localhost database=map user=pguser password=pgpassword dbType=postgresql
Bem, a importação em si:
c:\osmosis\bin\osmosis.bat --read-pbf c:\map\voronezh.osm.pbf --write-pgsql authFile=c:\map\databaseinfo.properties
Dados Importados
Agora você já pode começar a estudar o que temos no banco de dados. O primeiro pensamento é que há um conjunto de figuras, mas isso não é inteiramente verdade. Como eu disse, o elemento principal é o ponto. Tudo o resto é criado através da criação de links (relacionamentos) entre pontos. Ainda não nos aprofundaremos, especialmente porque as mãos já estão ansiosas para criar sua própria tabela "plana" com alguns dados. Bem, para linhas e pontos, tudo está pronto, você só precisa criar uma tabela com os campos necessários e inserir as entradas necessárias. E que campos temos? Aqui para ajudar o wiki. Por exemplo,
use o par de chave / valor power = line . Escolha uma lista de campos que usaremos, por exemplo: nome, voltagem, operador, cabos. Acontece que queremos selecionar as linhas que necessariamente possuem a propriedade power = line, juntamente com o nome dos campos, tensão, operador, cabos. Crie uma tabela:
CREATE TABLE power_lines ( name varchar, voltage varchar, operator varchar, cables varchar, geom geometry )
E a própria solicitação para preencher nossa nova tabela:
INSERT INTO power_lines SELECT ways.tags -> 'name' as name, ways.tags -> 'voltage' as voltage, ways.tags -> 'operator' as operator, ways.tags -> 'cables' as cables, ways.linestring as geom FROM ways WHERE ways.tags -> 'power' IN ( 'line' )
Feito, temos uma mesa com linhas de energia, onde algumas linhas têm alguns campos preenchidos! Bem, a tabela é certamente interessante, mas visualizar os dados para visualizar a geometria também seria bom. A maneira mais rápida de fazer isso é com o QGIS, exceto que esse GIS poderoso deve ser instalado primeiro. Já adicionamos uma camada Postgis, usamos qualquer mapa como substrato (você pode usar o plugin OpenLayers). Configurado, veja:

Viva! Mesmo muito parecido com a verdade, pensei, olhando pela janela as linhas de energia.
E polígonos?
A situação com pontos é quase a mesma, exceto que você precisa usar a tabela de nós. O KDPV apenas contém
dados sobre subestações . E os polígonos? Os polígonos também consistem em linhas (fechadas). Parece que você pode simplesmente fechar as linhas e apreciar o resultado, mas não funciona dessa maneira. Existem muitas armadilhas. Os polígonos podem consistir em várias linhas fechadas.
Por exemplo, uma ilha pode estar em um lago. Portanto, temos um "buraco" no aterro. Eu também tive que aprender sobre o significado da palavra "exclave" (para minha vergonha, eu sabia apenas sobre o "enclave"). Os polígonos também são agrupados. Por exemplo, uma floresta pode consistir em várias "peças". Que devemos representar como um objeto. Para completar, precisamos cortar polígonos abertos se alguns dados estiverem fora do mapa. Resolvi esses e outros problemas no script SQL, que coloquei na prateleira com segurança depois que funcionou. O projeto
osmose-multypolygon foi encontrado no GitHub. Relutantemente, decidi que usar esta solução é uma opção melhor do que o meu conjunto de scripts escritos no meu joelho em alguns dias. Fazemos o que é dito no README, a saber, executamos a lista de scripts e temos a tabela multipolígonos, que é preenchida com as instruções de assemble.sql. Depois de preenchermos a tabela com polígonos, você pode criar o que queremos obter. Vamos escolher o
território dos parques ?
Nós olhamos para o wiki e escrevemos um script:
CREATE TABLE parks ( name varchar, geom geometry ); INSERT INTO parks SELECT m.tags -> 'name' as name, m.geom FROM multipolygons m WHERE m.tags -> 'leisure' IN ( 'park' )
Agora visualizamos:
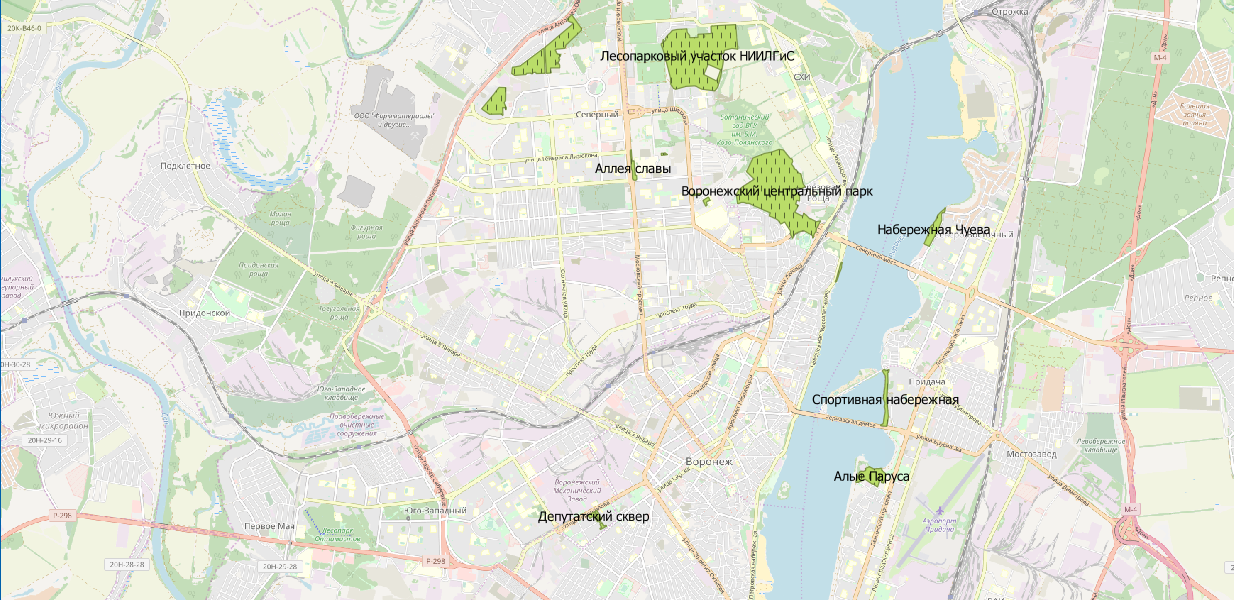
Bem, para ser sincero, aqui você pode discutir sobre a relevância dos dados. Mas este é um tópico para outra discussão.