
TL; DR
- Para alcançar alta observabilidade de contêineres e microsserviços, revistas e métricas primárias não são suficientes.
- Para uma recuperação mais rápida e maior tolerância a falhas, os aplicativos devem aplicar o Princípio de Alta Observabilidade (HOP).
- No nível do aplicativo, a NRA exige: registro adequado, monitoramento cuidadoso, verificações de integridade e rastreamento de desempenho / transição.
- Use as verificações readinessProbe e livenessProbe Kubernetes como um elemento HOP .
O que é um modelo de verificação de saúde?
Ao projetar um aplicativo de missão crítica e altamente disponível, é muito importante pensar em tolerância a falhas. Um aplicativo é considerado tolerante a falhas se for restaurado rapidamente após uma falha. Um aplicativo em nuvem típico usa uma arquitetura de microsserviço - quando cada componente é colocado em um contêiner separado. E para garantir que o aplicativo no k8s seja altamente acessível, quando você cria um cluster, precisa seguir certos padrões. Entre eles está o Health Check Template. Ele determina como o aplicativo relata o k8s sobre seu desempenho. Não são apenas informações sobre se o pod funciona, mas também sobre como ele aceita solicitações e responde a elas. Quanto mais o Kubernetes souber sobre o desempenho de um pod, mais decisões inteligentes serão tomadas sobre o roteamento de tráfego e o balanceamento de carga. Assim, o princípio da alta observabilidade do aplicativo em tempo hábil para responder às solicitações.
O princípio da alta observabilidade (ARN)
O princípio da alta observabilidade é um dos princípios do design de aplicativos em contêiner . Na arquitetura de microsserviço, os serviços não se importam com o processamento da solicitação (e com razão), mas é importante como obter respostas dos serviços recebidos. Por exemplo, para autenticar um usuário, um contêiner envia outra solicitação HTTP, aguardando uma resposta em um formato específico - isso é tudo. O PythonJS também pode manipular a solicitação e o Python Flask pode responder. Os contêineres um para o outro são como caixas pretas com conteúdo oculto. No entanto, o princípio da NRA exige que cada serviço divulgue vários pontos de extremidade da API, mostrando o quão eficiente é, assim como seu estado de prontidão e tolerância a falhas. O Kubernetes pede que essas métricas pensem nas próximas etapas para roteamento e balanceamento de carga.
Um aplicativo em nuvem bem projetado registra seus principais eventos usando os fluxos de E / S STDERR e STDOUT padrão. Em seguida, um serviço auxiliar, por exemplo, batida de arquivo, logstash ou fluente, é executado, entregando os logs em um sistema de monitoramento centralizado (como Prometheus) e no sistema de coleta de logs (ELK software suite). O diagrama abaixo mostra como o aplicativo em nuvem funciona de acordo com o Modelo de Verificação de Saúde e o Princípio da Alta Observabilidade.
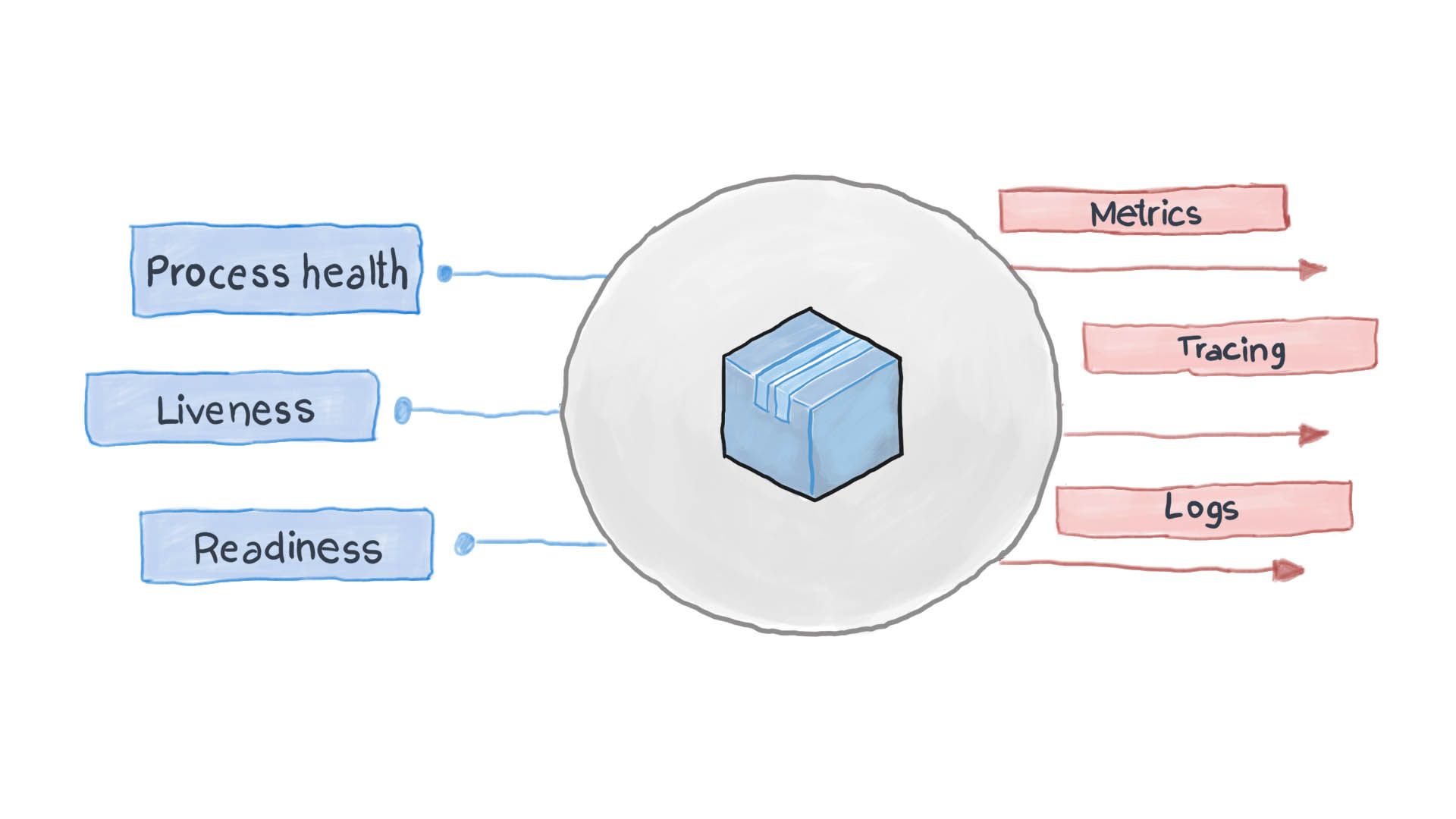
Como aplicar o Health Check Pattern no Kubernetes?
Pronto para uso, o k8s monitora o status dos pods usando um dos controladores ( Implantações , ReplicaSets , DaemonSets , StatefulSets , etc., etc.). Depois de descobrir que o pod caiu por algum motivo, o controlador tenta reiniciá-lo ou movê-lo para outro nó. No entanto, o pod pode relatar que está em funcionamento, enquanto ele próprio não está funcionando. Aqui está um exemplo: seu aplicativo usa o Apache como servidor da Web, você instalou o componente em vários pods do cluster. Como a biblioteca não foi configurada corretamente, todas as solicitações para o aplicativo respondem com o código 500 (erro interno do servidor). Ao verificar a entrega, a verificação do status dos pods fornece um resultado bem-sucedido, no entanto, os clientes consideram o contrário. Descrevemos essa situação indesejável da seguinte forma:
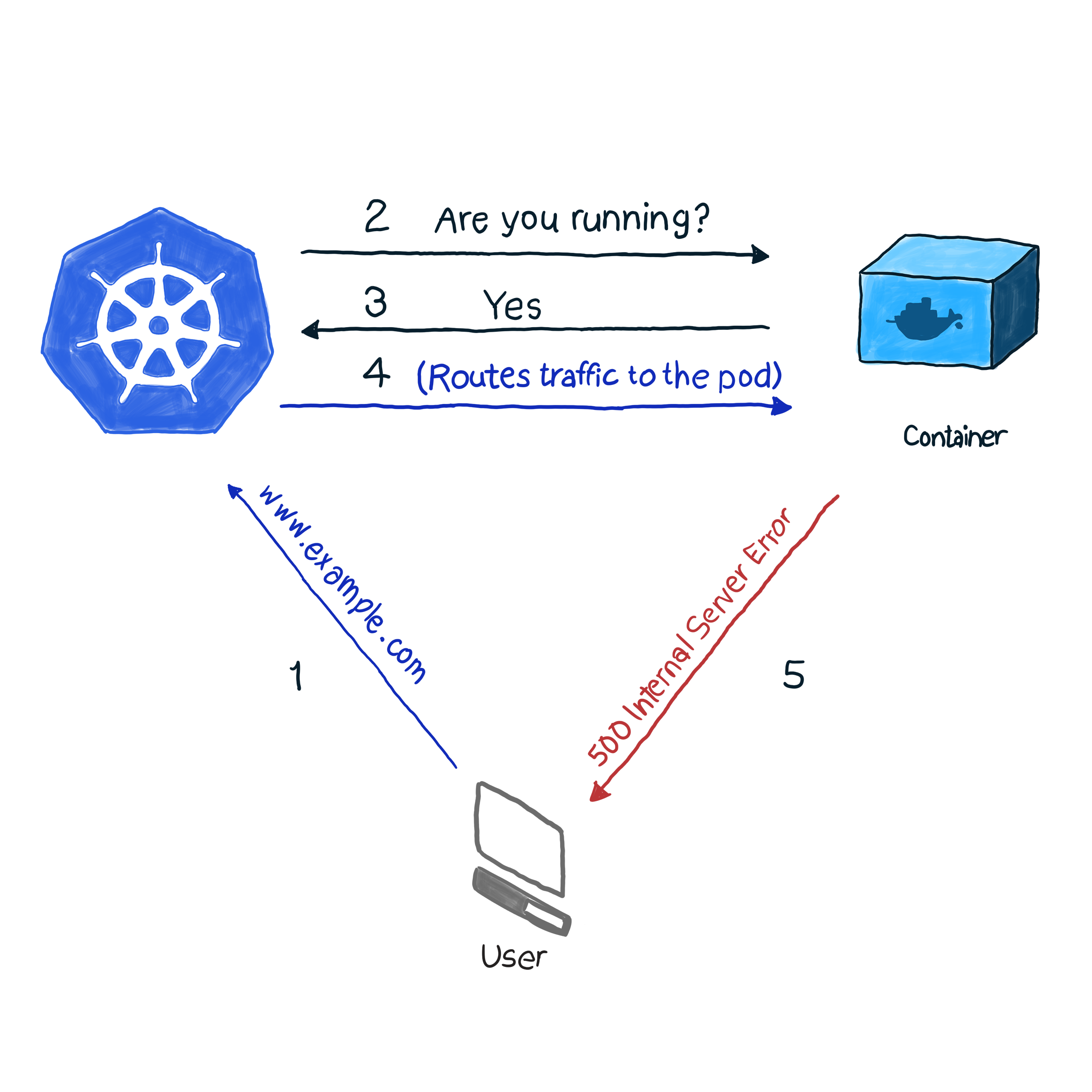
No nosso exemplo, o k8s executa uma verificação de saúde . Nesse tipo de verificação, o kubelet verifica constantemente o status do processo no contêiner. Depois que ele entender que o processo subiu, ele o reiniciará. Se o erro for eliminado simplesmente reiniciando o aplicativo e o programa for projetado para desligar quando houver algum erro, para seguir a NRA e o Modelo de Verificação de Integridade, uma verificação de integridade do processo é suficiente. É uma pena que nem todos os erros sejam eliminados ao reiniciar. Nesse caso, o k8s oferece duas maneiras mais profundas de solucionar problemas de um pod : livenessProbe e readinessProbe .
LivenessProbe
Durante o livenessProbe , o kubelet executa três tipos de verificações: não apenas descobre se o pod funciona, mas se está pronto para receber e responder adequadamente às solicitações:
- Defina uma solicitação HTTP para pod. A resposta deve conter um código de resposta HTTP no intervalo de 200 a 399. Portanto, os códigos 5xx e 4xx indicam que o pod tem problemas, mesmo se o processo estiver em execução.
- Para verificar pods com serviços não HTTP (por exemplo, servidor de correio Postfix), é necessário estabelecer uma conexão TCP.
- Execução de um comando arbitrário para o pod (internamente). A verificação será considerada bem-sucedida se o código de saída do comando for 0.
Um exemplo de como isso funciona. A definição do pod a seguir contém um aplicativo NodeJS que fornece um erro de 500 para solicitações HTTP.Para garantir que o contêiner reinicie após receber esse erro, usamos o parâmetro livenessProbe:
apiVersion: v1 kind: Pod metadata: name: node500 spec: containers: - image: magalix/node500 name: node500 ports: - containerPort: 3000 protocol: TCP livenessProbe: httpGet: path: / port: 3000 initialDelaySeconds: 5
Isso não é diferente de qualquer outra definição de .spec.containers.livenessProbe , mas adicionamos um objeto .spec.containers.livenessProbe . O parâmetro httpGet aceita o caminho para o qual a solicitação HTTP GET é enviada (no nosso exemplo, isso é / , mas em cenários de batalha também pode haver algo como /api/v1/status ). Ainda o livenessProbe aceita o parâmetro initialDelaySeconds , que instrui a operação de validação a aguardar um número especificado de segundos. O atraso é necessário porque o contêiner precisa de tempo para iniciar e, quando reiniciar, ficará indisponível por um tempo.
Para aplicar essa configuração a um cluster, use:
kubectl apply -f pod.yaml
Após alguns segundos, você pode verificar o conteúdo do pod com o seguinte comando:
kubectl describe pods node500
Encontre o seguinte no final da saída.
Como você pode ver, o livenessProbe iniciou uma solicitação HTTP GET, o contêiner gerou um erro 500 (que foi programado para) e o kubelet o reiniciou.
Se você estiver interessado em como o aplicativo NideJS foi programado, aqui estão os app.js e Dockerfile que foram usados:
app.js
var http = require('http'); var server = http.createServer(function(req, res) { res.writeHead(500, { "Content-type": "text/plain" }); res.end("We have run into an error\n"); }); server.listen(3000, function() { console.log('Server is running at 3000') })
Dockerfile
FROM node COPY app.js / EXPOSE 3000 ENTRYPOINT [ "node","/app.js" ]
É importante prestar atenção a isso: livenessProbe reiniciará o contêiner apenas em caso de falha. Se a reinicialização não corrigir o erro que interfere na operação do contêiner, o kubelet não poderá tomar medidas para eliminar o mau funcionamento.
readinessProbe
O readinessProbe funciona de maneira semelhante ao livenessProbes (solicitações GET, comunicações TCP e execução de comandos), com exceção das ações de solução de problemas. O contêiner no qual a falha é registrada não é reiniciado, mas é isolado do tráfego recebido. Imagine que um dos contêineres faça muita computação ou esteja sob carga pesada, o que aumenta o tempo de resposta para solicitações. No caso de livenessProbe, uma verificação de disponibilidade de resposta é acionada (através do parâmetro timeoutSeconds check), após o qual o kubelet reinicia o contêiner. Quando iniciado, o contêiner começa a executar tarefas com muitos recursos e é reiniciado novamente. Isso pode ser crítico para aplicativos que se preocupam com a velocidade de resposta. Por exemplo, um carro no caminho aguarda uma resposta do servidor, a resposta está atrasada - e o carro trava.
Vamos escrever uma definição readinessProbe que defina o tempo de resposta para uma solicitação GET para não mais de dois segundos, e o aplicativo responderá a uma solicitação GET em 5 segundos. O arquivo pod.yaml deve ficar assim:
apiVersion: v1 kind: Pod metadata: name: nodedelayed spec: containers: - image: afakharany/node_delayed name: nodedelayed ports: - containerPort: 3000 protocol: TCP readinessProbe: httpGet: path: / port: 3000 timeoutSeconds: 2
Expanda o pod com o kubectl:
kubectl apply -f pod.yaml
Aguarde alguns segundos e veja como o readinessProbe funcionou:
kubectl describe pods nodedelayed
No final da conclusão, você pode ver que alguns dos eventos são semelhantes a isso .
Como você pode ver, o kubectl não reiniciou o pod quando o tempo de varredura excedeu 2 segundos. Em vez disso, ele cancelou o pedido. As conexões de entrada são redirecionadas para outros pods em funcionamento.
Nota: agora que a carga extra foi removida do pod, o kubectl envia solicitações novamente: as respostas à solicitação GET não são mais atrasadas.
Para comparação: a seguir está o arquivo app.js modificado:
var http = require('http'); var server = http.createServer(function(req, res) { const sleep = (milliseconds) => { return new Promise(resolve => setTimeout(resolve, milliseconds)) } sleep(5000).then(() => { res.writeHead(200, { "Content-type": "text/plain" }); res.end("Hello\n"); }) }); server.listen(3000, function() { console.log('Server is running at 3000') })
TL; DR
Antes do advento dos aplicativos baseados na nuvem, os logs eram os principais meios de monitorar e verificar o status dos aplicativos. No entanto, não havia meios de executar nenhuma etapa de solução de problemas. Os logs são úteis hoje, devem ser coletados e enviados ao sistema de montagem de logs para análise de situações de emergência e tomada de decisão. [ tudo isso poderia ser feito sem aplicativos em nuvem usando o monit, por exemplo, mas com o k8s ficou muito mais fácil :) - ed. ]
Hoje, as correções precisam ser feitas quase em tempo real, para que os aplicativos não sejam mais caixas pretas. Não, eles devem mostrar os pontos de extremidade que permitem aos sistemas de monitoramento solicitar e coletar dados valiosos sobre o status dos processos, para que possam responder instantaneamente, se necessário. Isso é chamado de Modelo de Design de Verificação de Saúde, que segue o Princípio da Alta Observabilidade (NRA).
O Kubernetes, por padrão, oferece 2 tipos de verificações de saúde: readinessProbe e livenessProbe. Ambos usam os mesmos tipos de verificações (solicitações HTTP GET, comunicações TCP e execução de comandos). Eles diferem em quais decisões são tomadas em resposta a problemas nos pods. livenessProbe reinicia o contêiner na esperança de que o erro não ocorra novamente e o prontidãoProbe isola o pod do tráfego de entrada até que a causa do problema seja resolvida.
O design adequado do aplicativo deve incluir os dois tipos de validação e a coleta de dados suficientes, especialmente quando uma exceção é criada. Ele também deve mostrar os pontos de extremidade da API necessários que transmitem métricas importantes do status de integridade ao sistema de monitoramento (também chamado de Prometheus).