No
primeiro artigo da série, promovi ativamente a ideia de que o desenvolvimento de código para Redd é secundário e o projeto principal é primário. O Redd é uma ferramenta auxiliar; portanto, gastar muito tempo com isso é errado. Ou seja, o desenvolvimento deve ocorrer rapidamente. Mas isso não significa que os programas resultantes não devam ser ótimos. Na verdade, se eles não forem otimizados, apenas a potência do equipamento não será suficiente para implementar o sistema de teste desejado. Portanto, o processo, como eu disse, deve ser rápido e fácil, mas o desenvolvedor deve sempre ter em mente alguns princípios de otimização.
Livros grossos foram publicados sobre otimização. Alguns desses livros são úteis, outros já estão desatualizados, pois os princípios descritos neles há muito migraram para o estágio de otimização automática ao criar código ... Mas há algumas coisas que não têm valor no desenvolvimento de programas comuns para processadores comuns, portanto, livros típicos geralmente não descrevem . Vamos agora começar a considerá-los.
1. Introdução
Até agora, escrevi sobre o princípio de "um problema - um artigo". E os artigos foram obtidos no formato de palestras, afetando vários tópicos ao mesmo tempo, unidos por um problema comum. Mas alguns leitores disseram que esses artigos não podiam ser lidos de uma só vez. Portanto, agora tentaremos falar sobre apenas um tópico em um artigo. Também é mais fácil escrever assim. Vamos ver, de repente será mais conveniente para todos.
Além disso, delicie os misteriosos invasores. Se um artigo é publicado pela manhã, o primeiro sinal negativo chega depois de um período de tempo em que é impossível ler o texto inteiro. Alguém faz isso puramente por princípio, poupando apenas tópicos sobre UDB e balalaica. Se a publicação não foi pela manhã, mas pela tarde, ele lança um sinal de menos com atraso. O segundo menos chega durante o dia (e esse amigo, aliás, também poupou tópicos sobre o UDB e a balalaica). Haverá mais artigos no novo formato, o que significa que haverá momentos mais agradáveis para esse casal (embora, pessoalmente, para mim, como autor, fique triste e ofensivo por suas ações).
Artigos anteriores da série:
- Desenvolvimento do “firmware” mais simples para FPGAs instalados no Redd e depuração usando o teste de memória como exemplo.
- Desenvolvimento do “firmware” mais simples para FPGAs instalados em Redd. Parte 2. Código do programa.
- Desenvolvimento de núcleo próprio para incorporação em um sistema de processador baseado em FPGA.
- Desenvolvimento de programas para o processador central Redd no exemplo de acesso ao FPGA.
- As primeiras experiências usando o protocolo de streaming no exemplo da comunicação da CPU e do processador no FPGA do Redd.
- Merry Quartusel, ou como o processador ganhou vida.
Comportamento misterioso de um sistema típico
Vamos fazer o sistema de processador mais simples, incluindo um relógio, um processador Nios II / f, um controlador SDRAM e uma porta de saída. É assim que este sistema é espartano no Platform Designer
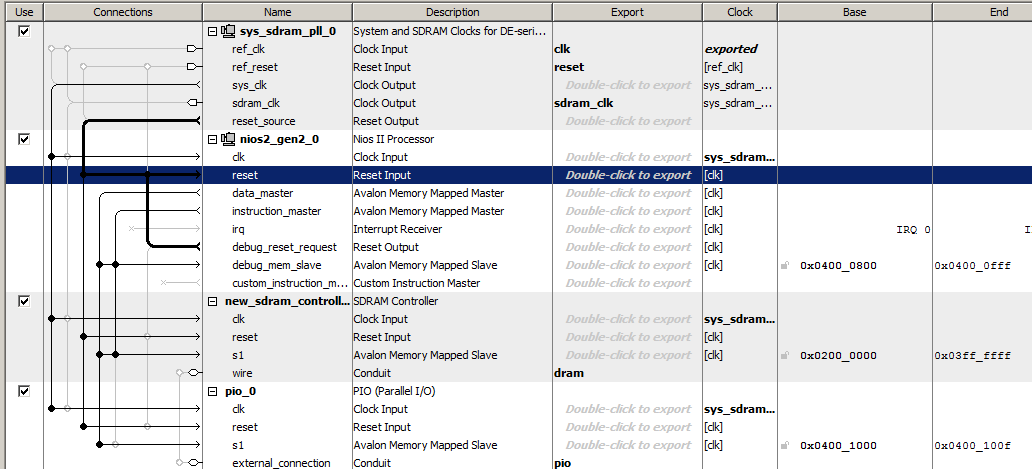
O código do programa conterá apenas uma função, cujo corpo parece um tanto estranho, pois contém muitas linhas repetidas, mas isso será útil para nós.
O código está oculto porque é muito apertado.extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction() { while (1) { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } } int main() { MagicFunction(); /* Event loop never exits. */ while (1); return 0; }
Coloque um ponto de interrupção na última das linhas:
IOWR (PIO_0_BASE,0,0);
no
MagicFunction e execute o programa. O que conseguimos na saída do porto? Impulsos muito irregulares:
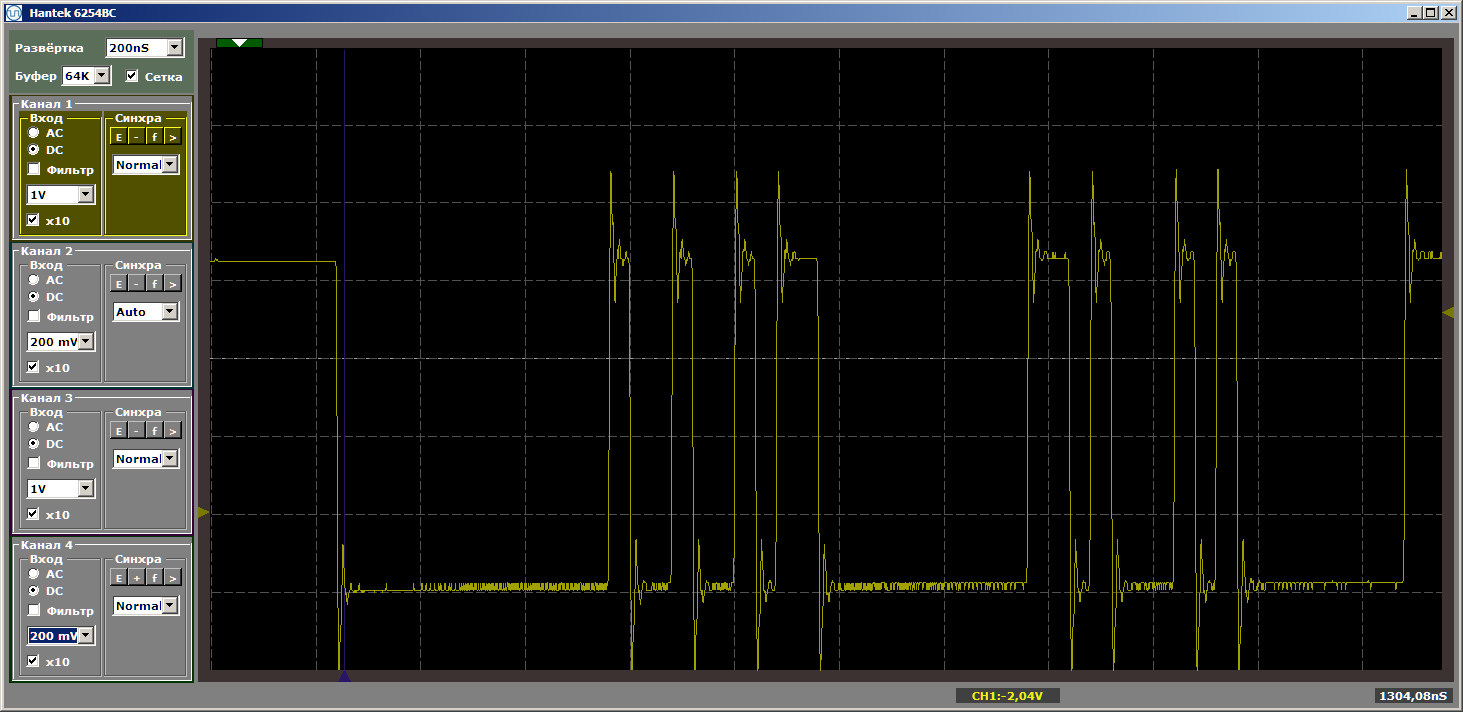
O horror Bem sim. No entanto, clique no botão "iniciar" novamente para concluir outra iteração do loop. E agora, na saída, vemos um belo meandro suave:
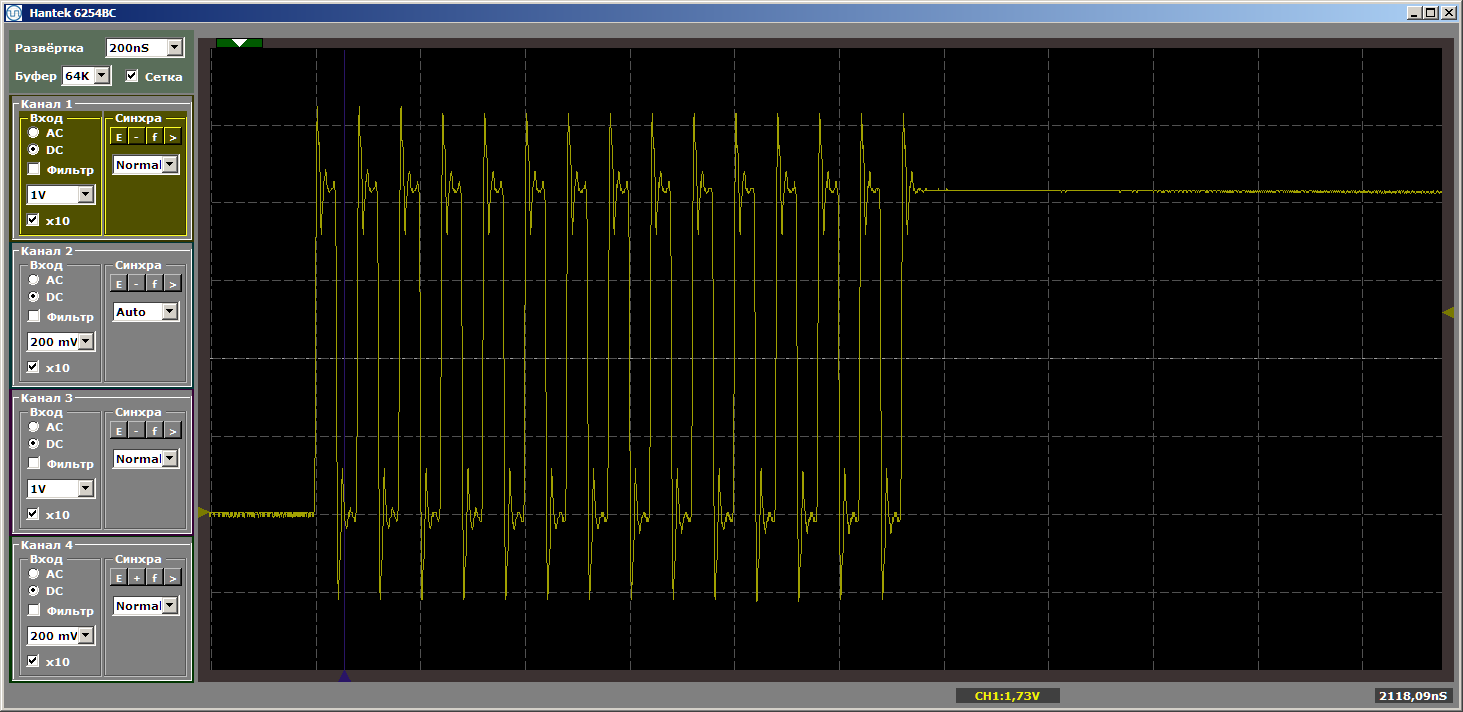
Outra iteração. E mais um ... Meandro estável. Removemos o ponto de interrupção e assistimos ao trabalho em dinâmica - não há mais interrupções desse tipo. Existem infinitas explosões de pulsos.
Por que arrancamos impulsos na primeira passagem? Um acidente? Não. Paramos a depuração e a iniciamos novamente. E novamente temos impulsos rasgados. As lacunas sempre surgem na entrada do programa.
A pista está no cache
Na verdade, a solução para esse comportamento está no cache. Nosso programa é armazenado em SDRAM. A busca do código da SDRAM não é rápida. É necessário dar um comando de leitura, é necessário dar um endereço, e o endereço consiste em duas partes. Você tem que esperar um pouco. Somente então o microcircuito fornecerá os dados. Para evitar tais atrasos todas as vezes, o microcircuito pode emitir não um, mas várias palavras consecutivas. Não consideraremos os horários hoje, adiaremos para os seguintes artigos.
Bem, no lado do núcleo do processador, um cache foi criado por padrão. Aqui estão suas configurações:
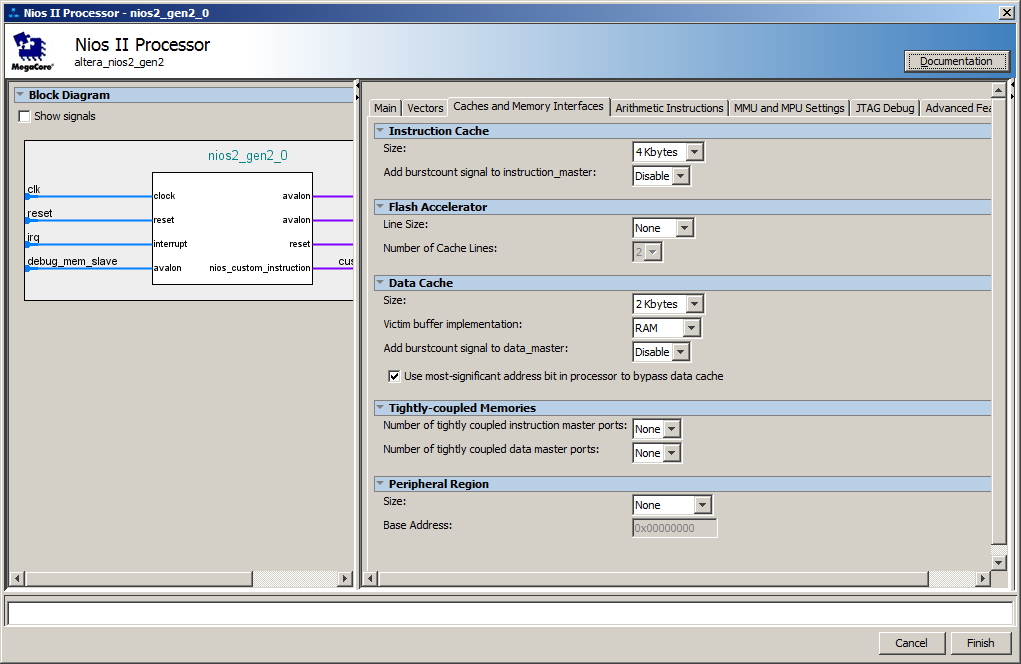
Na verdade, ocorrem atrasos no momento em que o carregamento em lote de instruções do SDRAM para o cache está em andamento. Nas próximas iterações, o código já está no cache, portanto, o carregamento não é mais necessário.
O oscilograma mostra uma média de 8 entradas por porta (uma unidade é gravada 4 vezes e zero é gravada 4 vezes) por operação de carregamento. Um comando - um comando assembler, que pode ser encontrado escolhendo o item de menu Janela-> Mostrar Visualização-> Outro:
e depois Depurar-> Desmontagem:
Aqui estão nossas strings e o código de montagem correspondente:
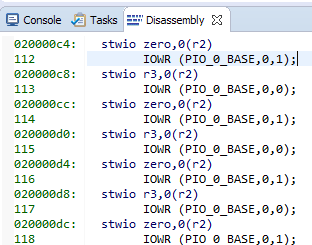
8 equipes de 4 bytes cada. Obtemos 32 bytes por linha de cache ... Examinamos nosso arquivo de ajuda favorito C: \ Work \ CachePlay \ software \ CachePlay_bsp \ system.he vemos:
#define ALT_CPU_ICACHE_LINE_SIZE 32 #define ALT_CPU_ICACHE_LINE_SIZE_LOG2 5
Os dados praticamente calculados coincidiram com a teoria. Além disso, a partir da documentação, segue-se que o tamanho da string não pode ser alterado. É sempre igual a trinta e dois bytes.
Um pouco mais complicado experimento
Vamos tentar provocar um cache para reiniciar durante o trabalho estabelecido. Vamos mudar um pouco o programa de teste. Nós criamos duas funções e as chamamos da função
main () , colocando um loop nela. Não vou definir um ponto de interrupção. A propósito, se você tornar as funções completamente idênticas, o otimizador perceberá isso e removerá uma delas, portanto, pelo menos uma linha, mas elas devem diferir ... Isso é o que escrevi no começo: os otimizadores são muito inteligentes agora.
Código do programa de teste modificado. extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); } int main() { while (1) { MagicFunction1(); MagicFunction2(); } /* Event loop never exits. */ while (1); return 0; }
Temos um resultado bastante bonito, já filmado no modo estabelecido do programa.
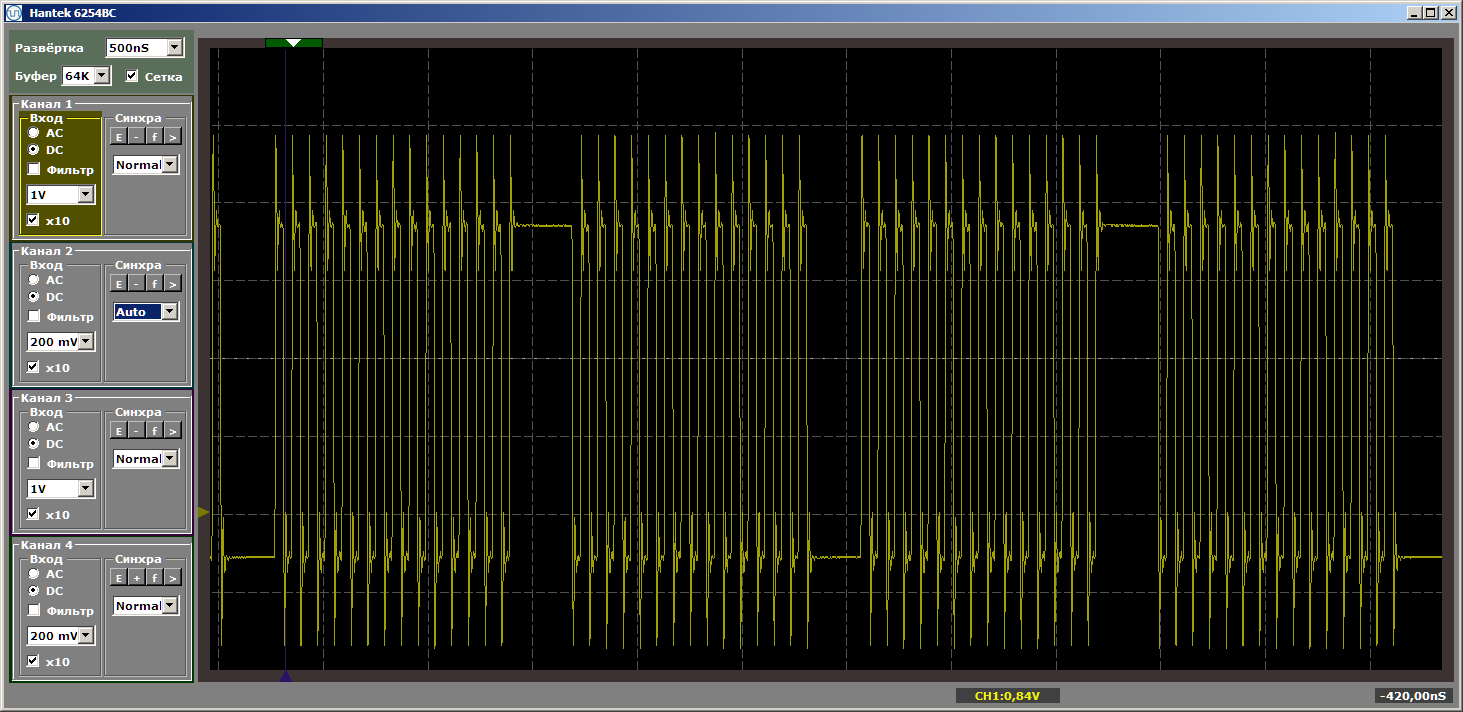
E agora colocaremos uma nova função entre esse par de funções, e não vamos chamá-lo, será apenas colocado entre eles na memória. Agora vou tentar fazer com que ocupe mais espaço ... O tamanho do cache é de 4 kilobytes, então o tornamos igual a quatro kilobytes ... Basta inserir 1024 NOPs, cada um com 4 bytes de tamanho. Mostrarei o final da primeira função, a nova função e o início da segunda, para que fique claro como o programa muda:
... IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } #define Nops4 __asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop"); #define Nops16 Nops4 Nops4 Nops4 Nops4 #define Nops64 Nops16 Nops16 Nops16 Nops16 #define Nops256 Nops64 Nops64 Nops64 Nops64 #define Nops1024 Nops256 Nops256 Nops256 Nops256 volatile void FuncBetween() { Nops1024 } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
A lógica do programa não mudou, mas quando executada agora, temos pulsos rasgados
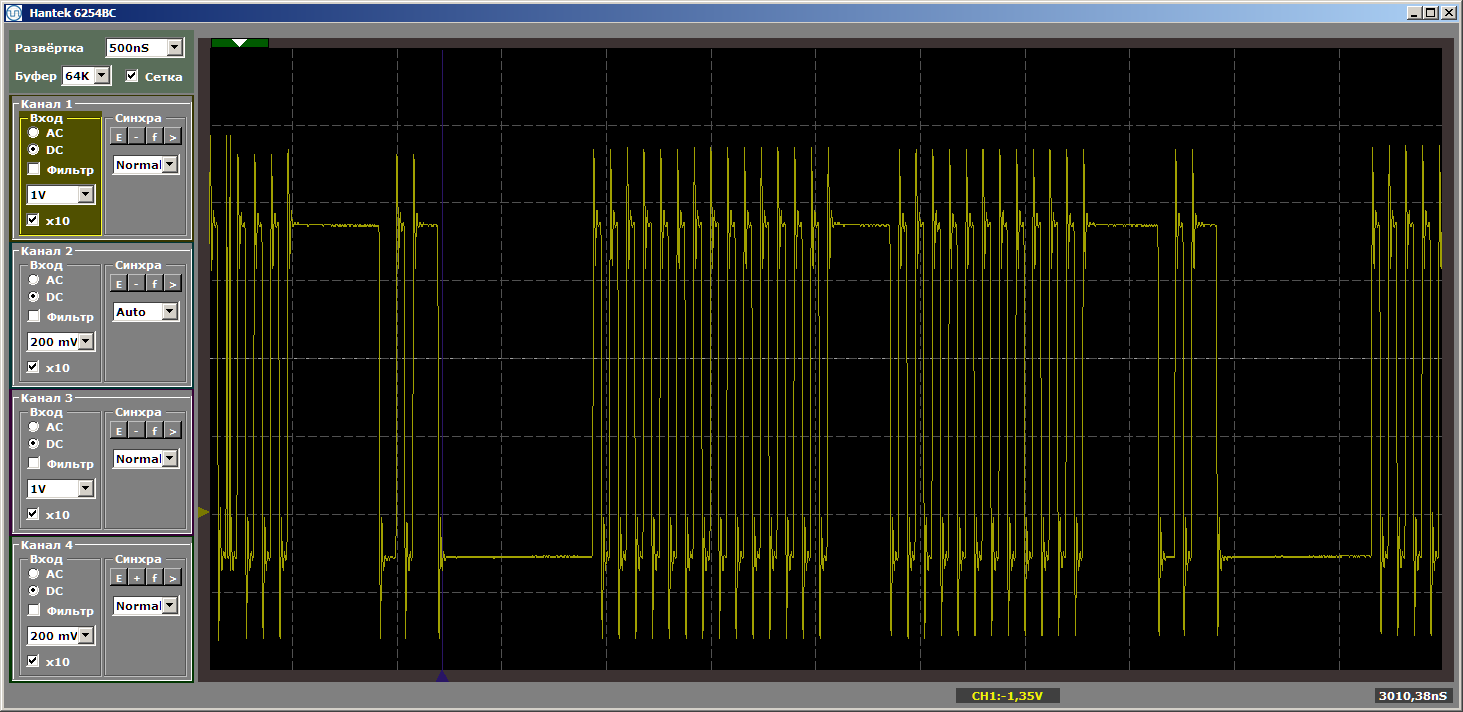
Farei uma pergunta ingênua: voamos para fora do cache e agora, à medida que a lacuna aumenta, sempre haverá carregamento? Nem um pouco! Altere o tamanho da função "ruim", tornando-a igual a, digamos, cinco kilobytes. Cinco a mais do que quatro, ainda estamos voando? Ou não? Substitua a inserção por esta:
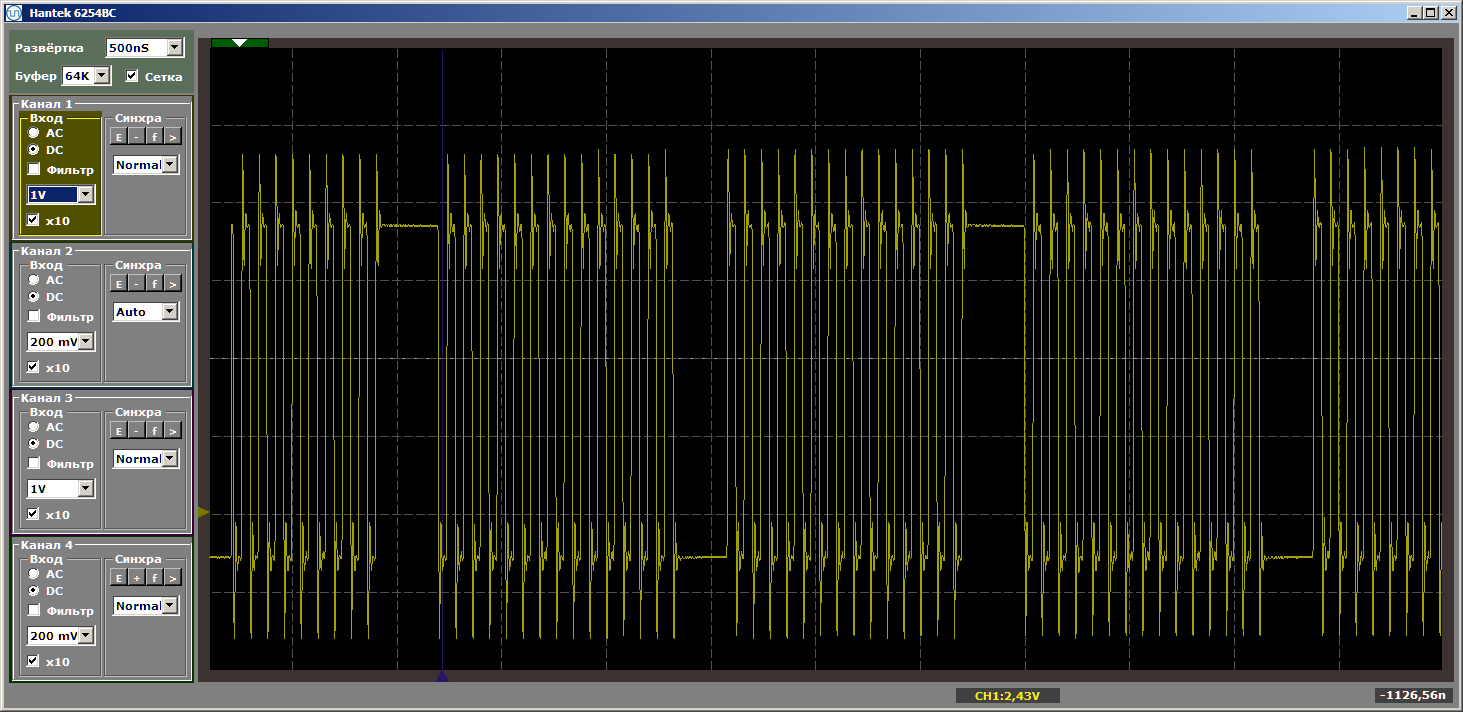
volatile void FuncBetween() { Nops1024 Nops256 }
E novamente temos a beleza:
Então, o que determina a necessidade de carregar código no cache? Podemos prever algo ou cada vez que precisamos olhar para o fato? Vamos nos aprofundar na teoria, com a qual o
Guia de Referência do Processador Nios II nos ajuda.
Pouco de teoria
É assim que o campo de endereço se divide no processador:
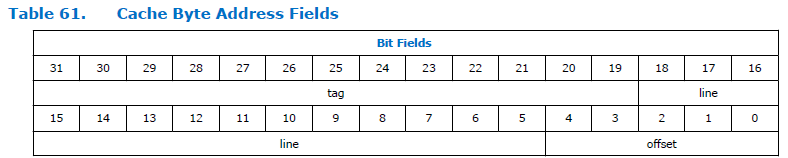
Como você pode ver, o endereço está dividido em três partes. Etiqueta, linha e deslocamento. A dimensão do campo de deslocamento é constante para o processador Nios II e é sempre cinco bits, ou seja, pode endereçar 32 bytes. A dimensão do campo "linha" depende do tamanho do cache especificado ao configurar o processador. Na figura acima, é bastante grande. Não sei por que o documento tem uma dimensão tão grande. Temos um tamanho de cache de 4 kilobytes, o que significa que a profundidade e o deslocamento total de bits são 12 bits. 5 bits leva um deslocamento, para uma linha permanece 12-5 = 7 bits.
Temos uma determinada tabela de 128 linhas, cada uma com 32 bytes de comprimento. Vou dar, digamos, as 6 primeiras linhas:
E então nos voltamos para o endereço 0x123
004 . Se você descartar a parte “não importante”, o par “linha + deslocamento” é 0x004. Este é o intervalo de zero linhas. Os dados serão carregados nesta linha. E o trabalho adicional com dados do intervalo 0x123
000 a 0x123
01F funcionará no cache. Sob quais condições a string será sobrecarregada? Ao acessar qualquer outro endereço que termine no intervalo de 0x000 a 0x01F. Bem, isto é, se voltarmos para o endereço 0xABC
204 , tudo permanecerá no lugar, porque o intervalo de endereços inferiores não se sobrepõe ao nosso. E 0xABC
804 não vai estragar nada. Porém, ao executar o código a partir do endereço 0xABC
004, isso resultará no carregamento de novos conteúdos na linha de cache. E a transição para o endereço 0x123
004 já levará novamente a uma sobrecarga. Se você pular constantemente entre 0xABC
004 e 0x123
004 , a sobrecarga ocorrerá continuamente.
Vamos tentar descrever isso na forma de uma imagem. Suponha que tenhamos apenas 8 linhas no cache; é mais conveniente colori-las em cores diferentes. Tornarei o tamanho da linha 0x10, é mais conveniente pintar os endereços na imagem (lembre-se de que no Nios II real o tamanho da linha é sempre 0x20 bytes). A memória bate em páginas condicionais com o mesmo tamanho das linhas de cache. A página vermelha da memória sempre irá para a linha vermelha do cache, da laranja para a laranja e assim por diante. Assim, o conteúdo antigo será descarregado.

Bem, na verdade, o comportamento do programa durante o experimento agora está claro. Quando as funções foram separadas estritamente por 4 kilobytes, elas atingiram páginas de cores semelhantes. Portanto, o código
while (1) { MagicFunction1(); MagicFunction2(); }
levou ao carregamento do cache por uma questão e depois por outra função. E quando o espaçamento não era de 4, mas de 5 kilobytes, as funções eram espaçadas em blocos de cores diferentes. Não houve conflito, tudo funcionou sem demora.
Conclusões
Quando li muitos anos atrás, há linhas de núcleos Cortex A, Cortex R e Cortex M projetados para coisas produtivas, para trabalhar em tempo real e para trabalhar em sistemas baratos, respectivamente, no começo eu não entendi, mas qual é a diferença . Não, sistemas baratos são compreensíveis, mas os dois primeiros são quais são as diferenças? No entanto, depois de jogar o núcleo do Cortex A9 disponível no FPGA Cyclone V SoC, senti todas as desvantagens do cache ao trabalhar com ferro. Existem muitos caches no núcleo do Cortex A ... E a previsibilidade do comportamento do sistema é quase zero. Mas o cache melhora o desempenho. Às vezes, é melhor que tudo funcione não previsivelmente preciso, mas mais rápido do que previsivelmente lento. Isso é especialmente verdadeiro para a computação ou, por exemplo, a exibição de gráficos.
Mas o principal problema não é que as coisas descritas no artigo surjam, mas que o comportamento do sistema mudará de montagem para montagem, pois ninguém sabe o que aborda a função que ocorrerá após adicionar ou remover o código. Há 15 anos, no projeto do emulador de console de jogos da Sega para um decodificador de televisão a cabo, tivemos que criar um pré-processador inteiro que, após cada edição, movesse as funções que emulavam os comandos do assembler da Motorola no núcleo SPARC-8, para que o tempo de execução fosse sempre o mesmo (não devido ao cache, caso contrário, tudo nadou muito).
Mas quando precisamos de previsibilidade? Obviamente, durante a formação de diagramas de tempo programaticamente (lembre-se de que, em geral, nos FPGAs, é possível confiar isso também ao equipamento, mas existem alguns detalhes com desenvolvimento rápido). Mas, ao trabalhar com algoritmos computacionais, isso não é tão importante. A menos que o algoritmo seja complexo, você precisa ter certeza de que as seções críticas não causam sobrecarga constante de cache. Na maioria dos casos, o cache não cria problemas e a produtividade aumenta.
No próximo artigo, veremos como prever funções críticas na memória não armazenável em cache, que sempre é executada na velocidade máxima, e discutir as vantagens implícitas dos FPGAs em relação aos sistemas padrão decorrentes das tecnologias usadas neste processo.
Para os mais atentos
Um leitor corrosivo pode perguntar: "Por que o oscilograma foi rasgado insuficientemente ao inserir quatro kilobytes de código?" Tudo é simples. Se você inserir exatamente 4 kilobytes, obteremos os seguintes endereços para colocar funções na memória:
MagicFunction1(): 0200006c: movhi r2,1024 02000070: movi r4,1 02000074: addi r2,r2,4096 02000078: stwio r4,0(r2) 92 IOWR (PIO_0_BASE,0,0); 0200007c: mov r3,zero 02000080: stwio r3,0(r2) 93 IOWR (PIO_0_BASE,0,1); ... 120 IOWR (PIO_0_BASE,0,0); 020000f0: stwio r3,0(r2) 020000f4: ret 131 Nops1024 FuncBetween(): 020000f8: nop 020000fc: nop 02000100: nop 02000104: nop ... 020010ec: nop 020010f0: nop 020010f4: nop 020010f8: ret 135 IOWR (PIO_0_BASE,0,0); MagicFunction2(): 020010fc: movhi r2,1024 02001100: mov r4,zero 02001104: addi r2,r2,4096
Para uma forma de onda perfeitamente ruim, é necessário inserir NOPs para que 4 kilobytes sejam o volume e o comprimento da função
MagicFunction1 () . Não importa o que você vá para uma bela foto! Mude a inserção para isto:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
Repetidamente, presto atenção que o inserto não recebe controle. Simplesmente altera a posição das funções na memória, uma em relação à outra. Com esta inserção, obtemos o horror terrível desejado:
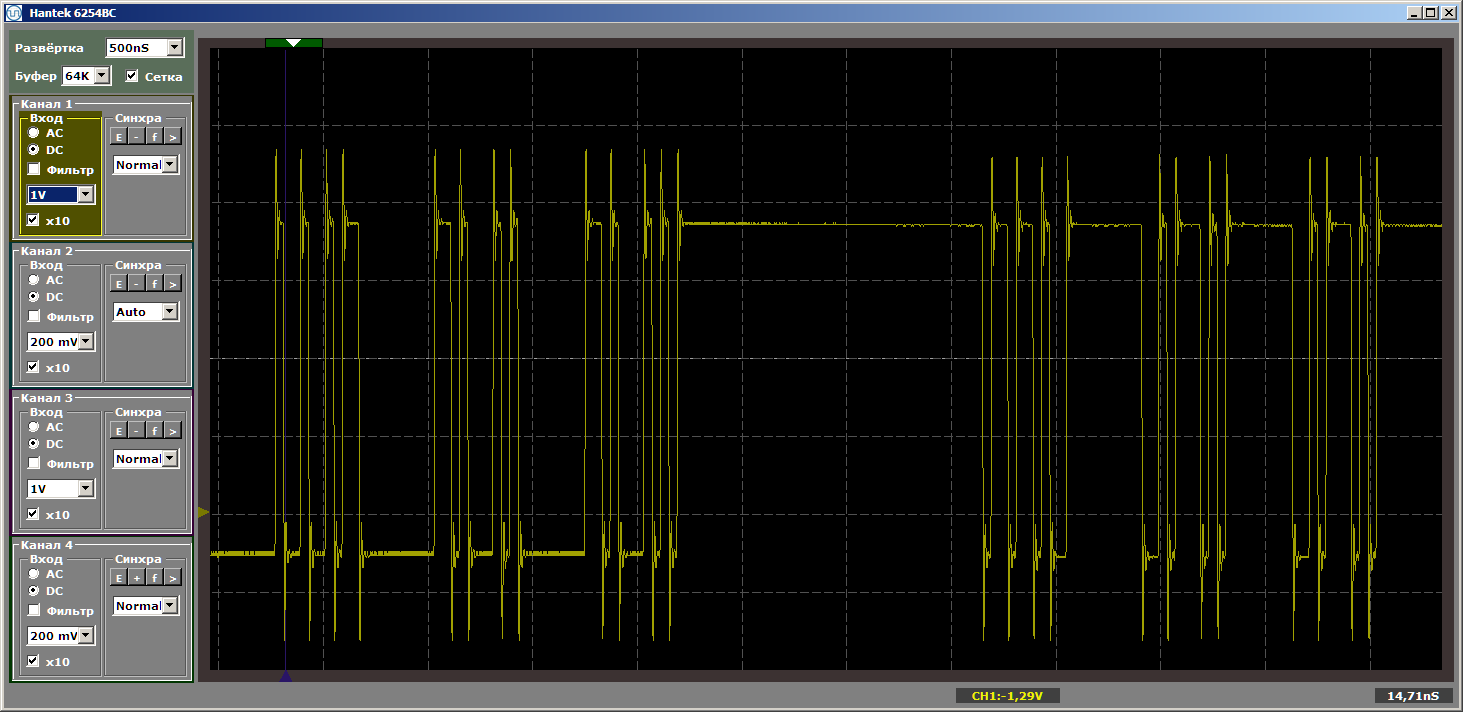
Pareceu-me que esses detalhes inseridos no texto principal distraíam todos do texto principal, então eu os coloquei em um postscript.