
Bem-vindo ao próximo artigo de uma
série de quebra-cabeças que perguntei nas entrevistas do Google antes de serem banidos após o vazamento. Desde então, parei de trabalhar como engenheiro de software no Google e passei para o cargo de gerente de desenvolvimento no Reddit, mas ainda tenho alguns ótimos tópicos. Até o momento, examinamos
a programação dinâmica ,
elevando as matrizes ao poder e à
sinonímia das consultas . Desta vez, uma pergunta completamente nova.
Mas primeiro, dois pontos. Primeiro, o trabalho no Reddit foi incrível. Nos últimos oito meses, construí e liderei a nova equipe de Relevância dos anúncios e montei um novo escritório de desenvolvimento em Nova York. Por mais divertido que seja, infelizmente, descobri que até recentemente não havia tempo ou energia sobrando para um blog. Receio ter abandonado um pouco esta série. Desculpe pelo atraso.
Em segundo lugar, se você seguiu os artigos, depois da última edição, talvez pensasse que eu começaria a procurar nas opções sinônimas das consultas. Embora eu queira voltar a isso em algum momento, devo admitir que perdi o devido interesse por esse problema devido a uma mudança de trabalho e, até agora, decidi adiá-lo. No entanto, mantenha contato! Eu me devo, e pretendo devolvê-lo. Só um pouco mais tarde ...
Isenção de responsabilidade rápida: Embora entrevistar candidatos seja um dos meus deveres profissionais, este blog apresenta minhas observações pessoais, histórias pessoais e opiniões pessoais. Não aceite isso para nenhuma declaração oficial do Google, Alphabet, Reddit ou qualquer outra pessoa ou organização.Procure uma nova pergunta
Em um
artigo anterior, descrevi uma das minhas perguntas favoritas que usei por muito tempo, antes do vazamento inevitável. As perguntas anteriores eram fascinantes do ponto de vista teórico, mas eu queria escolher um problema um pouco mais relevante para o Google como empresa. Quando essa pergunta foi banida, eu queria encontrar uma substituição levando em conta a nova restrição: para tornar a pergunta
mais simples .
Agora, isso pode parecer um pouco surpreendente, dado o infame processo de entrevista no Google. Mas naquela época um problema mais simples fazia sentido. Meu raciocínio consistia em duas partes. A primeira é pragmática: os candidatos geralmente não lidavam muito bem com as perguntas anteriores, apesar de inúmeras sugestões e simplificações, e nem sempre eu tinha certeza do motivo. A segunda teoria: o processo de entrevista deve dividir os candidatos nas categorias “vale a pena contratar” e “não vale a pena contratar”, e fiquei curioso para saber se isso poderia ser um pouco mais fácil com a pergunta.
Antes de esclarecer esses dois pontos, quero destacar o que eles
não significam. "Nem sempre sei por que uma pessoa tem problemas" não significa a inutilidade das perguntas e que eu queria simplificar a entrevista por esse motivo. Mesmo a pergunta mais difícil, muitos lidaram bem. Quero dizer, quando os candidatos tinham problemas, era difícil para mim entender o que estavam perdendo.
Boas entrevistas dão uma visão ampla dos pontos fortes e fracos do candidato. Não basta que o comitê de contratação simplesmente diga que "falhou": o comitê determina se o candidato possui as qualidades específicas da empresa que está procurando. Da mesma forma, as palavras “ele é legal” não ajudam o comitê a decidir sobre um candidato forte em algumas áreas, mas duvidoso em outras. Descobri que questões mais complexas freqüentemente separam os candidatos nessas duas categorias. Sob esse prisma, "nem sempre tenho certeza do porquê de uma pessoa ter problemas" significa que "a incapacidade de avançar nessa questão não é, por si só, um retrato das habilidades desse candidato".
A classificação dos candidatos como “vale a pena contratar” e “não vale a pena contratar”
não significa que o processo de entrevista deva separar candidatos estúpidos de espertos. Não me lembro de um único candidato que não fosse inteligente, talentoso e motivado. Muitos vieram de excelentes universidades e o restante estava claramente extremamente motivado. Passar por entrevistas telefônicas já é uma boa peneira, e até recusar nesta fase não é um sinal de falta de habilidade.
No entanto, lembro-me de muitos que não estavam preparados o suficiente para a entrevista ou trabalharam muito devagar, ou exigiram muita supervisão para resolver o problema, ou se comunicaram de uma maneira pouco clara, ou não conseguiram traduzir suas idéias em código, ou mantiveram uma posição que simplesmente não levaria seu sucesso a longo prazo etc. A definição de “vale a pena contratar” é vaga e varia de acordo com a empresa, e o processo de entrevista é determinar se cada candidato atende aos requisitos de uma empresa em particular.
Eu li muitos comentários no reddit reclamando de perguntas de entrevistas excessivamente complexas. Fiquei curioso para saber se ainda era possível fazer uma recomendação digna / indigna para uma tarefa mais simples. Suspeitei que isso daria um sinal útil sem gritar desnecessariamente os nervos do candidato. Vou falar sobre minhas conclusões no final do artigo ...
Com esses pensamentos, eu estava procurando uma nova pergunta. Em um mundo ideal, essa é uma pergunta bastante simples para ser resolvida em 45 minutos, mas com perguntas adicionais para que os candidatos mais poderosos mostrem suas habilidades. A implementação também deve ser compacta, porque muitos candidatos ainda escrevem no quadro. Uma grande vantagem se o tópico estiver de alguma forma relacionado aos produtos do Google.
Finalmente, decidi por uma pergunta que algum maravilhoso pesquisador descreveu cuidadosamente e inseriu em nosso banco de dados de perguntas. Agora, consultei ex-colegas e certifiquei-me de que a pergunta ainda seja proibida, para que você definitivamente não seja perguntado na entrevista. Apresento da forma que me parece mais eficaz, com um pedido de desculpas ao autor original.
Pergunta
Fale sobre como medir distâncias.
A mão é uma unidade de medida de dez polegadas comumente usada em países de língua inglesa para medir a altura dos cavalos.
Um ano-luz é outra unidade de medida igual à distância que uma partícula (ou onda?) De luz viaja em um determinado número de segundos, aproximadamente igual a um ano terrestre. À primeira vista, eles têm pouco em comum um com o outro, exceto pelo fato de serem usados para medir a distância. Mas acontece que o Google pode convertê-los facilmente:

Isso pode parecer óbvio: no final, os dois medem a distância, então fica claro que há uma transformação. Mas se você pensar bem, é um pouco estranho: como eles calcularam essa taxa de conversão? Claramente, ninguém contou realmente o número de mãos em um ano-luz. Na verdade, você não precisa levar isso diretamente. Você pode simplesmente usar conversões conhecidas:
- 1 mão = 4 polegadas
- 4 polegadas = 0.33333 pés
- 0.33333 ft = 6.3125e - 5 milhas
- 6.3125e - 5 milhas = 1.0737e - 17 anos-luz
O objetivo da tarefa é desenvolver um sistema que realize essa transformação. Em particular:
Na entrada, você tem uma lista de fatores de conversão (formatados no idioma escolhido) na forma de um conjunto de unidades de medida iniciais, unidades e fatores finais, por exemplo:
ft 12
jardas para pés 0.3333333
etc.
Portanto, ORIGIN * MULTIPLIER = DESTINATION. Desenvolva um algoritmo que use dois valores de unidade arbitrários e retorne o fator de conversão entre eles.
A discussão
Eu gosto desse problema porque ele tem uma resposta intuitiva e óbvia: basta converter de uma unidade para outra e depois para a próxima, até encontrar o alvo! Não me lembro de um único candidato que se deparou com esse problema e ficou completamente intrigado em como resolvê-lo. Isso se encaixa bem com a exigência de um problema "mais simples", uma vez que os anteriores normalmente exigiam um longo estudo e reflexão antes que pelo menos uma abordagem básica da solução fosse encontrada.
No entanto, muitos candidatos não conseguiram perceber sua intuição como uma solução funcional, sem sugestões óbvias. Uma das vantagens desta pergunta é que ela testa a capacidade do candidato de formular o problema (para fazer o enquadramento), de modo a se prestar à análise e codificação. Como veremos, há uma extensão muito interessante aqui que requer um novo salto conceitual.
Por contexto, o enquadramento é o ato de traduzir um problema com uma solução não óbvia em um problema equivalente, onde a solução é deduzida de maneira natural. Se isso soa completamente abstrato e inexpugnável, me desculpe, mas é. Vou explicar o que quero dizer quando apresentar a solução inicial para esse problema. A primeira parte da solução será um exercício de desenvolvimento e aplicação de conhecimento algorítmico. A segunda parte será um exercício de manipulação desse conhecimento para chegar a uma otimização nova e não óbvia.
Parte 0. Intuição
Antes de aprofundar, vamos explorar completamente a solução "óbvia". A maioria das conversões necessárias é simples e direta. Qualquer americano que viajou para fora dos Estados Unidos sabe que a maior parte do mundo usa a unidade misteriosa "quilômetro" para medir distâncias. Para converter, basta multiplicar o número de milhas por cerca de 1,6.
Nós encontramos essas coisas na maior parte de nossas vidas. Para a maioria das unidades, já existe uma conversão pré-calculada, portanto, basta analisá-la na tabela correspondente. Mas se não houver conversão direta (por exemplo, de mãos para anos-luz), faz sentido criar um caminho de conversão, conforme indicado acima:
- 1 mão = 4 polegadas
- 4 polegadas = 0.33333 pés
- 0.33333 ft = 6.3125e - 5 milhas
- 6.3125e - 5 milhas = 1.0737e - 17 anos-luz
Era muito simples, eu apenas tive essa transformação usando minha imaginação e uma tabela de transformação padrão! No entanto, algumas perguntas permanecem. Existe um caminho mais curto? Qual é a precisão do coeficiente? A conversão é sempre possível? É possível automatizá-lo? Infelizmente, aqui a abordagem ingênua se desmorona.
Parte 1. Decisão ingênua
É bom que o problema tenha uma solução intuitiva, mas, de fato, essa simplicidade é um obstáculo para resolvê-lo. Não há nada mais difícil do que tentar entender de uma nova maneira o que você já entende - principalmente porque você sabe menos do que pensa. Para ilustrar, imagine que você veio para uma entrevista - e você tem esse método intuitivo em sua cabeça. Mas isso não permite resolver uma série de problemas importantes.
Por exemplo, e se
não houver conversão ? A abordagem óbvia não diz nada, é realmente possível converter de uma unidade para outra. Se eles me derem mil taxas de conversão, será muito difícil determinar se é possível em princípio. Se me pedem para fazer uma conversão entre unidades desconhecidas (ou inventadas) de um
ponteiro e um
jab , não faço ideia por onde começar. Como uma abordagem intuitiva ajuda aqui?
Devo admitir que este é um tipo de cenário artificial, mas também existe um cenário mais realista. Você vê que minha declaração do problema inclui apenas unidades de distância. Isso é feito de propósito. E se eu pedir ao sistema para converter de polegadas para quilogramas? Você e eu sabemos que isso não é possível porque eles medem tipos diferentes, mas a entrada não diz nada sobre o “tipo” que cada unidade mede.
É aqui que uma formulação cuidadosa da questão permite que candidatos fortes se provem.
Antes de desenvolver o algoritmo, eles pensam nos casos extremos do sistema. E essa afirmação do problema propositadamente lhes dá a oportunidade de me perguntar se traduziremos unidades diferentes. Este não é um problema tão grande se ocorrer em um estágio inicial, mas é sempre um bom sinal quando alguém me pergunta com antecedência: "O que o programa deve retornar se a conversão não for possível?" Colocar a pergunta dessa maneira me dá uma idéia das habilidades do candidato antes que ele escreva pelo menos uma linha de código.
Visualização de gráficoObviamente, a abordagem ingênua não é adequada, por isso precisamos pensar em como fazer essa conversão? A resposta é considerar as unidades como um gráfico. Este é o primeiro salto de entendimento necessário para resolver esse problema.
Em particular, imagine que cada unidade seja um nó em um gráfico e haja uma aresta do nó
A para o nó
B se
A puder ser convertido em
B :
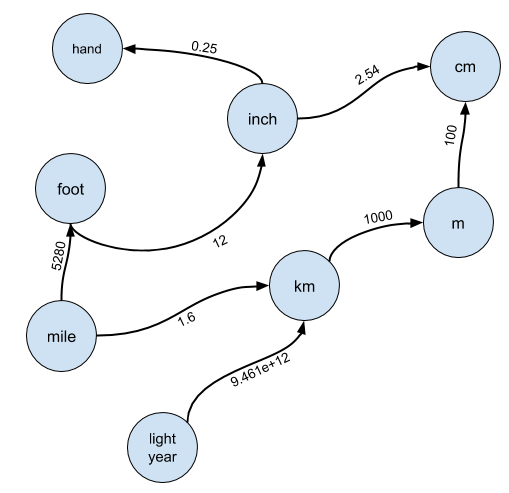
As arestas são rotuladas com uma taxa de conversão pela qual você deve multiplicar
A para obter
BEu quase sempre esperava que o candidato apresentasse esse tipo de estrutura e raramente dava dicas sérias a ele. Posso perdoar o candidato que não percebe a solução para o problema de usar conjuntos disjuntos ou não está muito familiarizado com a álgebra linear para encontrar uma solução que reduza a aumentar novamente o poder da matriz de adjacência, mas os gráficos são ensinados em qualquer currículo ou curso de programação. Se o candidato não tiver o conhecimento adequado, este é um sinal de "não contratação".
EnfimUma representação gráfica reduz a solução para o problema clássico de pesquisa gráfica. Em particular, dois algoritmos são úteis aqui: pesquisa ampla (BFS) e pesquisa profunda (DFS). Ao pesquisar em largura, examinamos os nós de acordo com a distância da origem:
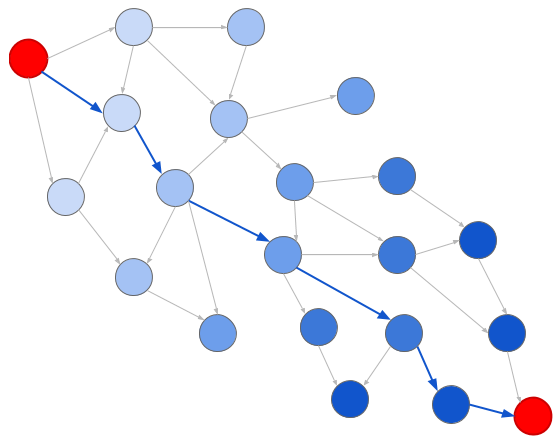 Azuis mais escuros significam gerações posteriores
Azuis mais escuros significam gerações posterioresE, ao pesquisar em profundidade, examinamos os nós na ordem em que eles ocorrem:
 Azuis mais escuros também significam gerações posteriores. Observe que na verdade não visitamos todos os sites
Azuis mais escuros também significam gerações posteriores. Observe que na verdade não visitamos todos os sitesQualquer um dos algoritmos determina facilmente se há uma conversão de uma unidade para outra; basta apenas pesquisar no gráfico. Começamos a partir da unidade de origem e procuramos até encontrar a unidade de destino. Se você não encontrar o seu destino (como se estivesse tentando converter polegadas em quilogramas), sabemos que não há como.
Mas espere, algo está faltando. Não queremos procurar uma maneira, queremos encontrar uma taxa de conversão! É aqui que o candidato deve saltar: acontece que você pode modificar qualquer algoritmo de pesquisa para calcular a taxa de conversão, simplesmente salvando o estado adicional à medida que avança. É aí que as ilustrações não fazem mais sentido, então vamos nos aprofundar no código.
Primeiro, você precisa determinar a estrutura de dados do gráfico, portanto, usamos isso:
class RateGraph(object): def __init__(self, rates): 'Initialize the graph from an iterable of (start, end, rate) tuples.' self.graph = {} for orig, dest, rate in rates: self.add_conversion(orig, dest, rate) def add_conversion(self, orig, dest, rate): 'Insert a conversion into the graph.' if orig not in self.graph: self.graph[orig] = {} self.graph[orig][dest] = rate def get_neighbors(self, node): 'Returns an iterable of the nodes neighboring the given node.' if node not in self.graph: return None return self.graph[node].items() def get_nodes(self): 'Returns an iterable of all the nodes in the graph.' return self.graph.keys()
Então vamos começar no DFS. Existem várias maneiras de implementá-lo, mas de longe o mais comum é uma solução recursiva. Vamos começar com isso:
from collections import deque def __dfs_helper(rate_graph, node, end, rate_from_origin, visited): if node == end: return rate_from_origin visited.add(node) for unit, rate in rate_graph.get_neighbors(node): if unit not in visited: rate = __dfs_helper(rate_graph, unit, end, rate_from_origin * rate, visited) if rate is not None: return rate return None def dfs(rate_graph, node, end): return __dfs_helper(rate_graph, node, end, 1.0, set())
Em poucas palavras, esse algoritmo começa com um nó, itera sobre seus vizinhos e visita-os imediatamente, fazendo uma chamada recursiva à função. Cada chamada de função na pilha salva o estado de sua própria iteração, portanto, quando uma visita recursiva é retornada, seu pai imediatamente continua a iteração. Evitamos visitar o mesmo site novamente, mantendo um conjunto de sites visitados em todas as chamadas. Também calculamos o coeficiente atribuindo um fator de conversão entre cada nó e a fonte. Assim, quando encontramos o nó / bloco de destino, já criamos o coeficiente de conversão a partir do nó de origem e podemos simplesmente devolvê-lo.
Esta é uma ótima implementação, mas sofre de duas falhas principais. Em primeiro lugar, é recursivo. Se o caminho desejado consistir em mais de mil saltos, sairemos voando com uma falha. Obviamente, isso é improvável, mas se há algo inaceitável para um serviço de longo prazo, é um fracasso. Em segundo lugar, mesmo se concluirmos com êxito, a resposta tem algumas propriedades indesejáveis.
Na verdade, eu já dei uma dica no início do post. Você já reparou como o Google mostra a taxa de conversão de
1.0739e-17 , mas meu cálculo manual fornece
1.0737e-17 ? Acontece que todas essas multiplicações de ponto flutuante já fazem pensar em espalhar o erro. Existem muitas nuances para este artigo, mas a conclusão é que você precisa minimizar a multiplicação de ponto flutuante para evitar erros que se acumulam e causam problemas.
DFS é um ótimo algoritmo de pesquisa. Se existir uma solução, ela a encontrará. Mas ele não possui uma propriedade-chave: ele não encontra necessariamente o caminho mais curto. Isso é importante para nós, porque um caminho mais curto significa menos saltos e menos erros devido às multiplicações de ponto flutuante. Para resolver o problema, recorremos ao BFS.
Parte 2. Solução BFS
Nesta fase, se um candidato implementa com êxito uma solução DFS recursiva e a interrompe, geralmente dou pelo menos uma recomendação fraca sobre a contratação desse candidato. Ele entendeu o problema, escolheu o enquadramento apropriado e implementou uma solução de trabalho. Esta é uma decisão ingênua, por isso não insisto em contratá-lo, mas se ele lidou bem com outras entrevistas, não recomendarei recusar.
Vale a pena repetir: em caso de dúvida, escreva uma solução ingênua! Mesmo que não seja completamente ideal, a presença de código no quadro já é uma conquista, e muitas vezes a solução certa pode ser encontrada em sua base. Vou dizer de forma diferente: nunca trabalhe por nada. Provavelmente, você pensou em uma solução ingênua, mas não quis oferecê-la, porque sabe que ela não é ótima. Se você está pronto para encontrar a melhor solução no momento, tudo bem, mas se não, registre o progresso feito antes de passar para coisas mais complexas.
A partir de agora, vamos falar sobre as melhorias no algoritmo. As principais desvantagens de uma solução DFS recursiva são que são recursivas e não minimizam o número de multiplicações. Como veremos em breve, o BFS minimiza o número de multiplicações e também é muito difícil implementá-lo recursivamente. Infelizmente, teremos que abandonar a solução recursiva do DFA, porque para melhorá-la, precisaremos reescrever completamente o código.
Sem mais delongas, apresento uma abordagem iterativa baseada no BFS:
from collections import deque def bfs(rate_graph, start, end): to_visit = deque() to_visit.appendleft( (start, 1.0) ) visited = set() while to_visit: node, rate_from_origin = to_visit.pop() if node == end: return rate_from_origin visited.add(node) for unit, rate in rate_graph.get_neighbors(node): if unit not in visited: to_visit.appendleft((unit, rate_from_origin * rate)) return None
Essa implementação é funcionalmente muito diferente da anterior, mas se você observar de perto, faz a mesma coisa, com uma alteração significativa: enquanto o DFS recursivo salva o estado da rota adicional na pilha de chamadas, implementando efetivamente a pilha LIFO, a solução iterativa a armazena na fila FIFO
Isso implica na propriedade “caminho mais curto / menor número de multiplicações”. Visitamos nós na ordem em que eles ocorrem e, dessa maneira, obtemos gerações de nós. O primeiro nó insere seus vizinhos e, em seguida, os visitamos em ordem, mantendo os vizinhos o tempo todo e assim por diante. A propriedade de caminho mais curto decorre do fato de os nós serem visitados na ordem de sua distância da origem. Portanto, quando encontramos um destino, sabemos que não há geração anterior que possa levar a ele.
Neste momento, estamos
quase terminando. Primeiro, você precisa responder a algumas perguntas, e elas são forçadas a retornar à formulação original do problema.
Primeiro, a coisa mais trivial a fazer se a unidade original não existir? Ou seja, não podemos encontrar o nó com o nome fornecido. Na prática, você precisa fazer alguma normalização das seqüências de caracteres para que a libra, a libra e a libra aponte para o mesmo nó "libra" (ou alguma outra representação canônica), mas isso está além do escopo de nossa pergunta.
Em segundo lugar, e se não houver conversão entre as duas unidades? Lembre-se de que, nos dados iniciais, existem apenas conversões entre unidades e isso não indica se é possível obter outro de uma unidade específica. Isso se resume ao fato de que transformações e caminhos são diretamente equivalentes; portanto, se não houver caminho entre dois nós, não haverá transformação. Na prática, você acaba com ilhas de unidades não relacionadas: uma para distâncias, uma para pesos, uma para moedas etc.
Por fim, se você observar atentamente o gráfico acima, verifica-se que não é possível converter entre mãos e anos-luz com esta solução. A direção das conexões entre os nós significa que não há como passar da mão aos anos-luz. No entanto, isso é bastante fácil de corrigir, porque as transformações podem ser revertidas. Podemos alterar nosso código de inicialização do gráfico da seguinte maneira:
def add_conversion(self, orig, dest, rate): 'Insert a conversion into the graph. Note we insert its inverse also.' if orig not in self.graph: self.graph[orig] = {} self.graph[orig][dest] = rate if dest not in self.graph: self.graph[dest] = {} self.graph[dest][orig] = 1.0 / rate
Parte 3. Avaliação
Feito! Se o candidato chegou a esse ponto, provavelmente o recomendarei para contratar. Se você estudou ciência da computação ou fez um curso de algoritmos, pode perguntar: “Isso é realmente suficiente para obter uma entrevista com esse cara?”, Ao qual responderei: “Essencialmente, sim”.
Antes de decidir que a pergunta é simples demais, vejamos o que um candidato deve fazer para chegar a esse ponto:
- Compreenda a pergunta
- Construir uma rede de transformações na forma de um gráfico
- Entenda que os coeficientes podem ser comparados com as arestas do gráfico
- Veja a possibilidade de usar algoritmos de pesquisa para conseguir isso.
- Escolha seu algoritmo favorito e altere-o para rastrear probabilidades
- Se ele implementou o DFS como uma solução ingênua, reconheça suas fraquezas.
- Implementar BFS
- Para voltar atrás e estudar casos extremos:
- E se nos perguntarem sobre um nó que não existe?
- E se o fator de conversão não existir?
- Reconhecer que transformações inversas são possíveis e provavelmente necessárias
Esta pergunta é mais fácil do que as anteriores, mas também é difícil. Como em todas as perguntas anteriores, o candidato deve dar um salto mental de uma pergunta formulada abstratamente para um algoritmo ou estrutura de dados que abra o caminho para uma solução. A única coisa é que o algoritmo final é menos avançado do que em outras questões. Fora deste material algorítmico, os mesmos requisitos se aplicam, especialmente com relação a casos extremos e correção.
"Mas espere!" Você pode perguntar. - O Google não é obcecado pela complexidade do tempo de execução? Você nem perguntou sobre a complexidade temporal ou espacial desse problema. Oh bem! Você também pode perguntar: “Espere um minuto, você deu a classificação“ altamente recomendável para contratar ”? Como conseguir isso? Muito boas perguntas, ambas. Isso nos leva à nossa rodada final de bônus extra ...
Parte 4. É possível fazer melhor?
Neste ponto, gostaria de felicitar o candidato com uma boa resposta e deixar claro que tudo o mais é apenas um bônus. Quando a pressão desaparece, podemos começar a criar.
Então, qual é a dificuldade de executar o BFS? Na pior das hipóteses, devemos considerar cada nó e borda individual, o que fornece complexidade linear
O(N+E) . Isso está além da mesma complexidade da construção do gráfico
O(N+E) . Para um mecanismo de pesquisa, isso provavelmente é bom: mil unidades de medida são suficientes para a maioria dos aplicativos razoáveis, e fazer uma pesquisa na memória para cada consulta não é uma sobrecarga.
No entanto, pode-se fazer melhor. Para motivar, considere como esse código é inserido na string de pesquisa. Conversões de algumas unidades não padrão são um pouco mais comuns, portanto, as calcularemos novamente. Cada vez que uma pesquisa é realizada, valores intermediários são calculados e assim por diante.
Muitas vezes, é sugerido simplesmente armazenar em cache os resultados do cálculo. Sempre que uma conversão de unidade é calculada, sempre podemos adicionar uma margem entre as duas conversões. Como bônus, obtemos a transformação inversa e de graça! Você terminou?
De fato, isso nos dará um tempo de pesquisa assintoticamente constante, mas custará o armazenamento de arestas adicionais. Na verdade, isso se torna bastante caro: com o tempo, procuraremos um gráfico completo, pois todos os pares de transformações são gradualmente calculados e armazenados. O número de arestas possíveis no gráfico é metade do quadrado do número de nós; portanto, para mil nós, precisamos de meio milhão de arestas. Para dez mil nós, cerca de cinquenta milhões, etc.
Indo além do escopo do mecanismo de pesquisa, para um gráfico de um milhão de nós, lutamos por meio trilhão de arestas. Esse valor é simplesmente irracional para armazenar, além de gastarmos tempo inserindo arestas no gráfico. Nós devemos fazer melhor.
Felizmente, existe uma maneira de obter tempo constante para buscar coeficientes, sem crescimento quadrático do espaço. De fato, quase tudo o que precisamos está bem debaixo do nosso nariz.
Parte 4. Tempo constante
Portanto, o cache total está realmente próximo da solução ideal. Nesta abordagem, (em última análise), obtemos arestas entre todos os nós, ou seja, nossa transformação é reduzida para encontrar uma aresta. Mas é realmente necessário armazenar conversões de cada nó para cada nó? E se apenas salvarmos os fatores de conversão de
um nó para todos os outros?
Dê uma outra olhada na solução BFS:
from collections import deque def bfs(rate_graph, start, end): to_visit = deque() to_visit.appendleft( (start, 1.0) ) visited = set() while to_visit: node, rate_from_origin = to_visit.pop() if node == end: return rate_from_origin visited.add(node) for unit, rate in rate_graph.get_neighbors(node): if unit not in visited: to_visit.appendleft((unit, rate_from_origin * rate)) return None
Vamos ver o que acontece aqui: começamos a partir do nó de origem e, para cada nó que encontramos, calculamos o coeficiente de conversão da fonte para esse nó. Então, assim que chegamos ao destino, retornamos o coeficiente entre os pontos inicial e final e descartamos os coeficientes intermediários.
Essas taxas intermediárias são fundamentais. Mas e se nós não os jogarmos fora? E se nós os escrevermos? Todas as pesquisas mais complexas e incompreensíveis tornam-se simples: para encontrar a proporção de A para B, primeiro encontre a proporção de X para B, depois divida-a pela proporção de X para A e pronto! Visualmente, fica assim:
 Observe que entre dois nós não mais que duas arestas
Observe que entre dois nós não mais que duas arestasAcontece que, para calcular esta tabela, quase não precisamos alterar a solução BFS:
from collections import deque def make_conversions(graph): def conversions_bfs(rate_graph, start, conversions): to_visit = deque() to_visit.appendleft( (start, 1.0) ) while to_visit: node, rate_from_origin = to_visit.pop() conversions[node] = (start, rate_from_origin) for unit, rate in rate_graph.get_neighbors(node): if unit not in conversions: to_visit.append((unit, rate_from_origin * rate)) return conversions conversions = {} for node in graph.get_nodes(): if node not in conversions: conversions_bfs(graph, node, conversions) return conversions
A estrutura de transformação é representada por um dicionário da unidade A em dois valores: a raiz do componente associado da unidade A e o coeficiente de conversão entre a unidade raiz e a unidade A. Como inserimos uma unidade nesse dicionário a cada visita, podemos usar o espaço de chave desse dicionário como um conjunto de visitas em vez de usar um conjunto dedicado de visitas. Observe que não temos um nó final e, em vez disso, iteramos pelos nós até terminarmos.
Fora desse BFS, há uma função auxiliar que itera sobre os nós em um gráfico. Sempre que encontra um nó fora do dicionário de tradução, inicia o BFS a partir desse nó.
Assim, temos a garantia de recolher todos os nós em seus componentes relacionados.Quando você precisa encontrar o relacionamento entre as unidades, simplesmente usamos a estrutura de transformação que acabamos de calcular: def convert(conversions, start, end): 'Given a conversion structure, performs a constant-time conversion' try: start_root, start_rate = conversions[start] end_root, end_rate = conversions[end] except KeyError: return None if start_root != end_root: return None return end_rate / start_rate
A situação “não existe tal unidade” é tratada ouvindo uma exceção ao acessar a estrutura de transformações. A situação “não existem tais transformações” é tratada comparando as raízes de duas quantidades: se elas têm raízes diferentes, são detectadas por meio de duas chamadas BFS diferentes, ou seja, elas estão em dois componentes conectados diferentes e, portanto, não há caminho entre elas. Finalmente, realizamos a conversão.Lá vai você! A solução atual possui complexidade de pré-processamentoO(V+E)(não é pior que as soluções anteriores), mas ela também pesquisa com tempo constante. Teoricamente, dobramos os requisitos de espaço, mas na maioria das vezes não precisamos mais do gráfico original, portanto podemos excluí-lo e usar apenas este. Além disso, a complexidade espacial é na verdade menor que o gráfico original: requer O(V+E)porque precisa armazenar todas as arestas e vértices, e essa estrutura exige apenas O(V)porque não precisamos mais de arestas.Resultados
Se você foi tão longe, lembre-se de que uma das perguntas era inicialmente verificar se um problema mais simples ainda poderia ser útil na escolha de candidatos dignos e se poderia dar uma imagem melhor das habilidades. Gostaria de dar uma resposta científica definitiva, mas só tenho histórias de experiência pessoal. No entanto, notei alguns resultados positivos.Se dividirmos a solução desse problema em quatro obstáculos (discussão do enquadramento, escolha do algoritmo, implementação, discussão da execução por um tempo constante), no final da entrevista quase todos os candidatos alcançaram a “escolha do algoritmo”. Como eu suspeitava, a discussão sobre o enquadramento era um bom filtro: os candidatos exibiam imediatamente um gráfico ou não podiam chegar a ele de forma alguma, apesar das dicas significativas.Este é um sinal útil imediatamente. Eu posso entender quando uma pessoa não conhece estruturas de dados avançadas ou obscuras, porque, para sermos honestos, você raramente precisa implementar conjuntos disjuntos. Mas os gráficos são uma estrutura de dados fundamental e são ensinados como parte de quase qualquer curso introdutório sobre esse tópico. Se o candidato se esforçar para entendê-los ou não puder aplicá-los facilmente, provavelmente será difícil para ele ter sucesso no Google (pelo menos no meu tempo lá, não sei como hoje).Por outro lado, a escolha do algoritmo não foi uma fonte de sinal particularmente útil. As pessoas que passaram pelo estágio de enquadramento geralmente acessavam o algoritmo sem problemas. Suspeito que isso se deva ao fato de que os algoritmos de pesquisa quase sempre são ensinados junto com os próprios gráficos; portanto, se alguém está familiarizado com um, então conhece o outro.A implementação não foi fácil. Muitas pessoas não tiveram problemas com a implementação recursiva do DFS, mas, como mencionei acima, essa implementação não é adequada para produção. Para minha surpresa, as implementações iterativas do BFS e DFS não parecem muito familiares para as pessoas e, mesmo depois de dicas óbvias, elas frequentemente flutuam no assunto.Na minha opinião, qualquer pessoa que passou pela fase de implementação já me recebeu a recomendação "Contratar", e a discussão do lead time constante é simplesmente um bônus. Embora tenhamos analisado a solução em detalhes no artigo, na prática, uma discussão oral em vez de escrever código é geralmente mais produtiva. Muito poucos candidatos poderiam tomar uma decisão imediatamente. Muitas vezes tive que dar pistas substanciais e mesmo assim muitas pessoas não o encontraram. Isso é normal: como esperado, é difícil obter uma classificação altamente recomendada.Mas espere, isso não é tudo!
Basicamente, examinamos todo o problema, mas se você estiver interessado em estudá-lo mais, existem várias extensões nas quais não vou mergulhar. Deixo os seguintes exercícios para o leitor:Primeiro, o aquecimento: na solução pelo tempo constante que expus, escolhi arbitrariamente o nó raiz de cada componente conectado. Em particular, eu uso o primeiro nó componente que encontramos. Isso não é ideal, porque para todos os valores conhecidos escolhemos algum nó, embora outro possa estar mais próximo do centro, com caminhos mais curtos para todos os outros nós. Sua tarefa é substituir essa opção arbitrária por uma que minimize o número de multiplicações necessárias e minimize a propagação do erro de ponto flutuante.Em segundo lugar, em todos os argumentos, assumiu-se que todos os caminhos iguais no gráfico são iguais inicialmente, o que nem sempre é o caso. Uma das opções interessantes para esse problema é a conversão de moedas: os nós são moedas e as bordas de A a B e vice-versa são os preços de oferta / demanda de cada par de moedas. Podemos reformular a questão da conversão de unidades como uma questão de arbitragem de moeda: implemente um algoritmo que, dado o gráfico de conversão de moeda, calcule um ciclo no gráfico que dará ao trader mais dinheiro do que o valor inicial. Não inclua nenhuma taxa de transação.Finalmente, uma verdadeira jóia: algumas unidades são expressas como uma combinação de diferentes unidades base. Por exemplo, um watt é definido no sistema SI como kg • m² / s³. A tarefa final é expandir esse sistema para suportar a conversão entre essas unidades, levando em consideração apenas as definições das unidades básicas de SI.Se você tiver alguma dúvida, não hesite em entrar em contato comigo no reddit .Conclusão
Quando comecei a fazer essa tarefa nas entrevistas, esperava que fosse um pouco mais fácil do que as anteriores. O experimento teve grande êxito: se o candidato viu a solução imediatamente, ele geralmente lidava com a tarefa rapidamente, então tínhamos muito tempo para conversar sobre uma solução avançada com tempo constante. As pessoas que experimentavam dificuldades, via de regra, tropeçavam em outros lugares além do salto conceitual algorítmico: o candidato não conseguia formular completamente o problema de maneira apropriada ou esboçou uma boa solução, mas não conseguiu traduzi-lo em código funcional. Não importa onde ou quando eles tenham dificuldades, descobri que poderia obter informações significativas sobre os pontos fortes e fracos dos candidatos.Espero que você tenha achado este artigo útil. Entendo que pode não haver tantas aventuras com algoritmos quanto em alguns artigos anteriores. Nas entrevistas dos desenvolvedores, é costume discutir bastante os algoritmos. Mas a verdade é que surgem dificuldades significativas ao usar até um método simples e bem conhecido. Todo o código está no repositório desta série de artigos .