Saudação, Khabrovites! Parabéns a todos no dia do programador e compartilhem a tradução do artigo, que foi especialmente preparado para os alunos do curso "High Load Architect" . "Fragmento. Ou não caco. Sem tentar. "
"Fragmento. Ou não caco. Sem tentar. "
- YodaHoje vamos mergulhar na separação de dados entre vários servidores MySQL. Concluímos o sharding no início de 2012, e esse sistema ainda é usado para armazenar nossos dados básicos.
Antes de discutirmos como compartilhar dados, vamos conhecê-los melhor. Prepare uma luz agradável, pegue morangos no chocolate, lembre-se de citações de Star Trek ...
O Pinterest é um mecanismo de pesquisa para tudo o que lhe interessa. Em termos de dados, o Pinterest é o maior gráfico de interesses humanos em todo o mundo. Ele contém mais de 50 bilhões de pinos que foram salvos pelos usuários em mais de um bilhão de placas. As pessoas mantêm alguns alfinetes para si e, como outros alfinetes, assinam outros alfinetes, placas e interesses, visualizam o feed doméstico de todos os alfinetes, placas e interesses aos quais estão inscritos. Ótimo! Agora vamos torná-lo escalável!
Crescimento doloroso
Em 2011, começamos a ganhar impulso. Segundo algumas
estimativas , crescemos mais rápido do que qualquer startup conhecida na época. Por volta de setembro de 2011, todos os componentes de nossa infraestrutura foram sobrecarregados. Tínhamos várias tecnologias NoSQL à nossa disposição e todas falharam catastroficamente. Também tínhamos muitos escravos do MySQL, que costumávamos ler, o que causava muitos erros extraordinários, principalmente quando o cache era feito. Nós reconstruímos todo o nosso modelo de armazenamento. Para trabalhar com eficiência, abordamos cuidadosamente o desenvolvimento de requisitos.
Exigências
- Todo o sistema deve ser muito estável, fácil de usar e dimensionar do tamanho de uma caixa pequena ao tamanho da lua à medida que o local cresce.
- Todo o conteúdo gerado pelo pinner deve estar disponível no site a qualquer momento.
- O sistema deve suportar a solicitação de N pinos na placa em uma ordem determinística (por exemplo, na ordem inversa do horário de criação ou na ordem especificada pelo usuário). O mesmo vale para pinners, pinos, etc.
- Para simplificar, você deve se esforçar para atualizar de todas as maneiras possíveis. Para obter a consistência necessária, serão necessários brinquedos adicionais, como um diário de transações distribuídas. É divertido e (não muito) fácil!
Filosofia da Arquitetura e Notas
Como queremos que esses dados abranjam vários bancos de dados, não podemos usar apenas uma junção, chaves estrangeiras e índices para coletar todos os dados, embora possam ser usados para subconsultas que não abrangem o banco de dados.
Também precisávamos manter o balanceamento de carga nos dados. Decidimos que a movimentação de dados, elemento por elemento, tornaria o sistema desnecessariamente complexo e causaria muitos erros. Se precisássemos mover dados, era melhor mover o nó virtual inteiro para outro nó físico.
Para que nossa implementação entre rapidamente em circulação, precisávamos da solução mais simples e conveniente e de nós muito estáveis em nossa plataforma de dados distribuídos.
Todos os dados tiveram que ser replicados na máquina escrava para criar um backup, com alta disponibilidade e despejo no S3 para o MapReduce. Interagimos com o mestre apenas na produção. Na produção, você não desejará escrever ou ler em escravo. Escravo lag, e isso causa bugs estranhos. Se o sharding for feito, não há sentido em interagir com um escravo na produção.
Finalmente, precisamos de uma boa maneira de gerar identificadores exclusivos universais (UUIDs) para todos os nossos objetos.
Como fizemos sharding
O que íamos criar, tinha que atender aos requisitos, trabalhar de forma estável, em geral, ser viável e sustentável. É por isso que escolhemos a
tecnologia MySQL já bastante madura como a tecnologia subjacente. É intencionalmente cauteloso com as novas tecnologias para o dimensionamento automático do MongoDB, Cassandra e Membase, porque elas estavam longe o suficiente da maturidade (e, no nosso caso, quebraram de maneira impressionante!).
Além disso: eu ainda recomendo startups para evitar coisas bizarras - tente usar o MySQL. Confie em mim. Eu posso provar isso com cicatrizes.
MySQL - a tecnologia é comprovada, estável e simples - ela funciona. Além de usá-lo, ele é popular em outras empresas com escalas ainda mais impressionantes. O MySQL atende totalmente a nossa necessidade de otimizar consultas de dados, selecionar intervalos de dados específicos e transações no nível de linha. De fato, em seu arsenal, há muito mais oportunidades, mas todos nós não precisamos delas. Mas o MySQL é uma solução "in a box", então os dados tiveram que ser fragmentados. Aqui está a nossa solução:
Começamos com oito servidores EC2, uma instância do MySQL em cada:
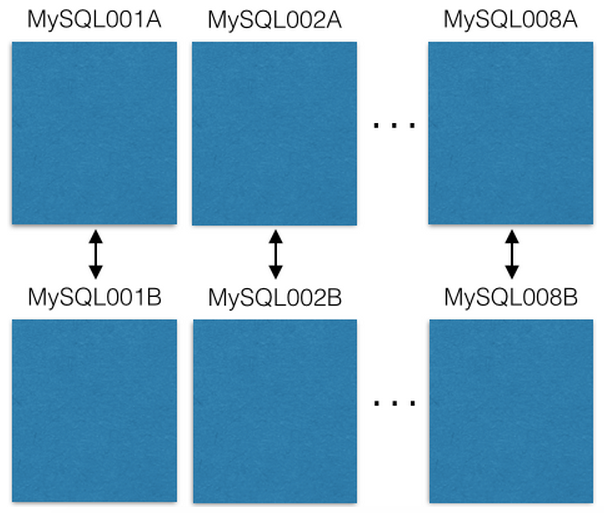
Cada servidor mestre do MySQL é replicado para o host de backup no caso de uma falha primária. Nossos servidores de produção apenas lêem ou gravam no master. Eu recomendo que você faça também. Isso simplifica e evita erros com atrasos na replicação.
Cada entidade do MySQL possui muitos bancos de dados:

Observe que cada banco de dados é nomeado exclusivamente: db00000, db00001 a dbNNNNN. Cada banco de dados é um fragmento de nossos dados. Tomamos uma decisão arquitetural, com base na qual apenas parte dos dados cai no fragmento e nunca vai além desse fragmento. No entanto, você pode obter mais capacidade movendo shards para outras máquinas (falaremos sobre isso mais adiante).
Trabalhamos com uma tabela de configuração que indica quais máquinas possuem shards:
[{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”}, {“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”}, ... {“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}]
Essa configuração muda apenas quando precisamos mover shards ou substituir o host. Se o
master morre, podemos usar o
slave existente e depois pegar um novo. A configuração está localizada no
ZooKeeper e, quando atualizada, é enviada para serviços que atendem ao shard do MySQL.
Cada shard possui o mesmo conjunto de tabelas:
pins ,
boards ,
users_has_pins ,
users_likes_pins ,
pin_liked_by_user etc. Vou falar sobre isso um pouco mais tarde.
Como distribuímos dados para esses fragmentos?
Criamos um ID de 64 bits que contém o ID do fragmento, o tipo de dados contido nele e o local em que esses dados estão na tabela (ID local). O ID do shard consiste em 16 bits, o ID do tipo é 10 bits e o ID local é 36 bits. Os matemáticos avançados perceberão que existem apenas 62 bits. Minha experiência anterior como desenvolvedor de compiladores e placas de circuito me ensinou que os bits de backup valem seu peso em ouro. Portanto, temos dois desses bits (definidos como zero).
ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)
Vamos pegar este pino:
https://www.pinterest.com/pin/241294492511762325/ , vamos analisar seu ID 241294492511762325:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429 Type ID = (241294492511762325 >> 36) & 0x3FF = 1 Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
Assim, o objeto pin vive no fragmento 3429. Seu tipo é "1" (ou seja, "Pino") e está na linha 7075733 na tabela de pinos. Por exemplo, vamos imaginar que esse fragmento está no MySQL012A. Podemos chegar a ele da seguinte maneira:
conn = MySQLdb.connect(host=”MySQL012A”) conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
Existem dois tipos de dados: objetos e mapeamentos. Os objetos contêm partes, como dados de pinos.
Tabelas de Objetos
As tabelas de objetos, como Pins, usuários, quadros e comentários, têm um ID (ID local, com uma chave primária que aumenta automaticamente) e um blob que contém JSON com todos os dados do objeto.
CREATE TABLE pins ( local_id INT PRIMARY KEY AUTO_INCREMENT, data TEXT, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB;
Por exemplo, os objetos pin são assim:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}
Para criar um novo pino, coletamos todos os dados e criamos um blob JSON. Em seguida, selecionamos o ID do shard (preferimos escolher o mesmo ID do shard no quadro em que ele está colocado, mas isso não é necessário). Para o tipo de pino 1. Nós nos conectamos a esse banco de dados e inserimos JSON na tabela de pinos. O MySQL retornará um ID local aumentado automaticamente. Agora temos um fragmento, um tipo e um novo ID local, para que possamos compilar um identificador completo de 64 bits!
Para editar o pino, lemos-modificamos-escrevemos JSON usando a
transação MySQL :
> BEGIN > SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE [Modify the json blob] > UPDATE db03429.pins SET blob='<modified blob>' WHERE local_id=7075733 > COMMIT
Para remover um alfinete, você pode excluir sua linha no MySQL. No entanto, é melhor adicionar o campo
"ativo" no JSON e configurá-lo como
"falso" , além de filtrar os resultados no lado do cliente.
Tabelas de mapeamento
A tabela de mapeamento vincula um objeto a outro, por exemplo, uma placa com pinos. A tabela MySQL para mapeamentos contém três colunas: 64 bits para o ID "from", 64 bits para o ID "where" e o ID da sequência. Nesta tripla (de onde, onde, sequência), existem chaves de índice e elas estão no fragmento do identificador "de".
CREATE TABLE board_has_pins ( board_id INT, pin_id INT, sequence INT, INDEX(board_id, pin_id, sequence) ) ENGINE=InnoDB;
As tabelas de mapeamento são unidirecionais, por exemplo, como a tabela
board_has_pins . Se você precisar da direção oposta, precisará de uma tabela separada
pin_owned_by_board . O ID da sequência define a sequência (nossos IDs não podem ser comparados entre os shards, porque os novos IDs locais são diferentes). Normalmente, inserimos novos pinos em uma nova placa com um ID de sequência igual ao tempo no unix (registro de data e hora unix). Qualquer número pode estar na sequência, mas o tempo unix é uma boa maneira de armazenar novos materiais sequencialmente, pois esse indicador aumenta monotonamente. Você pode dar uma olhada nos dados na tabela de mapeamento:
SELECT pin_id FROM board_has_pins WHERE board_id=241294561224164665 ORDER BY sequence LIMIT 50 OFFSET 150
Isso fornecerá mais de 50 pinos_id, que você poderá usar para procurar objetos de pinos.
O que acabamos de fazer é uma junção da camada de aplicação (board_id -> pin_id -> pin objects). Uma das propriedades surpreendentes das conexões no nível do aplicativo é que você pode armazenar em cache a imagem separadamente do objeto. Armazenamos pin_id no cache do objeto pin no cluster memcache, no entanto, salvamos board_id em pin_id no cluster redis. Isso nos permite escolher a tecnologia certa que melhor se adequa ao objeto em cache.
Aumentar capacidade
Existem três maneiras principais de aumentar a capacidade em nosso sistema. A maneira mais fácil de atualizar a máquina (para aumentar o espaço, colocar discos rígidos mais rápidos, mais RAM).
A próxima maneira de aumentar a capacidade é abrir novos intervalos. Inicialmente, criamos um total de 4096 shards, apesar do ID do shard consistir em 16 bits (um total de 64k shards). Novos objetos só podem ser criados nesses primeiros 4k shards. Em algum momento, decidimos criar novos servidores MySQL com shards de 4096 a 8191 e começamos a preenchê-los.
A última maneira de aumentar a capacidade é transferir alguns fragmentos para novas máquinas. Se queremos aumentar a capacidade do MySQL001A (com shards de 0 a 511), criamos um novo par mestre-mestre com os seguintes nomes máximos possíveis (por exemplo, MySQL009A e B) e iniciamos a replicação do MySQL001A.
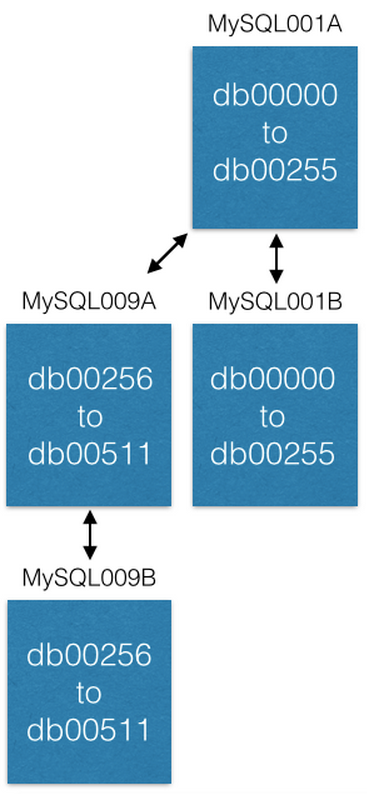
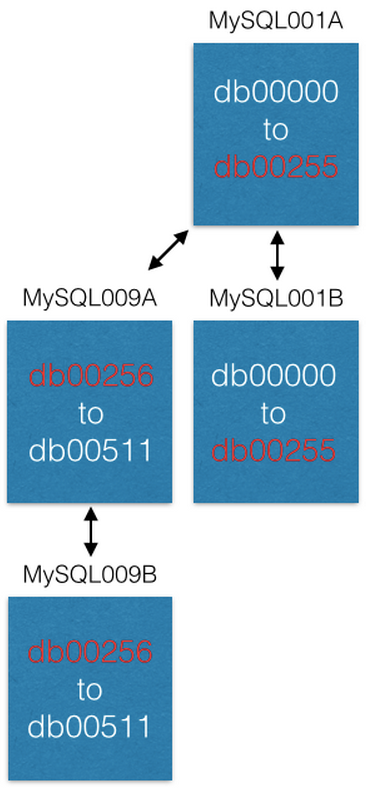
Assim que a replicação é concluída, alteramos nossa configuração para que no MySQL001A existam apenas shards de 0 a 255 e no MySQL009A de 256 a 511. Agora, cada servidor deve processar apenas metade dos shards processados anteriormente.
Alguns recursos interessantes
Aqueles que já possuíam sistemas para gerar novos
UUIDs entenderão que neste sistema os obtemos sem nenhum custo! Quando você cria um novo objeto e o insere na tabela de objetos, ele retorna um novo identificador local. Esse ID local, combinado com o ID do shard e o ID do tipo, fornece um UUID.
Aqueles de vocês que executaram ALTERs para adicionar mais colunas às tabelas MySQL sabem que eles podem trabalhar extremamente devagar e se tornar um grande problema. Nossa abordagem não requer nenhuma alteração no nível do MySQL. No Pinterest, provavelmente fizemos apenas um ALTER nos últimos três anos. Para adicionar novos campos aos objetos, diga aos seus serviços que existem vários novos campos no esquema JSON. Você pode alterar o valor padrão para que, ao desserializar o JSON de um objeto sem um novo campo, obtenha o valor padrão. Se você precisar de uma tabela de mapeamento, crie uma nova tabela de mapeamento e comece a preenchê-la sempre que desejar. E quando terminar, você pode enviar!
Fragmento de modificação
É quase como um
esquadrão de mods , apenas completamente diferente.
Alguns objetos precisam ser encontrados sem um ID. Por exemplo, se um usuário efetuar login com uma conta do Facebook, precisamos mapear do ID do Facebook para o Pinterest. Para nós, os IDs do Facebook são apenas bits, então os armazenamos em um sistema de fragmentos separado chamado mod shard.
Outros exemplos incluem endereços IP, nome de usuário e endereço de email.
O Mod Shard é muito semelhante ao sistema de sharding descrito na seção anterior, com a única diferença: você pode procurar dados usando dados de entrada arbitrários. Essa entrada é dividida em hash e modificada de acordo com o número total de shards no sistema. Como resultado, um fragmento será obtido no qual os dados estarão ou já estão localizados. Por exemplo:
shard = md5(“1.2.3.4") % 4096
Nesse caso, o shard será igual a 1524. Processamos o arquivo de configuração correspondente ao ID do shard:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”}, {“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”}, {“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”}, …]
Portanto, para encontrar dados no endereço IP 1.2.3.4, precisamos fazer o seguinte:
conn = MySQLdb.connect(host=”msdb003a”) conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)
Você está perdendo algumas boas propriedades do ID do shard, como localidade espacial. Você terá que começar com todos os shards criados no início e criar a chave você mesmo (ela não será gerada automaticamente). É sempre melhor representar objetos no seu sistema com IDs imutáveis. Portanto, você não precisa atualizar muitos links quando, por exemplo, o usuário altera seu "nome de usuário".
Últimos pensamentos
Este sistema produz produção no Pinterest há 3,5 anos e provavelmente permanecerá lá para sempre. A implementação foi relativamente simples, mas foi difícil colocá-lo em operação e mover todos os dados de máquinas antigas. Se você encontrar um problema ao criar um novo shard, considere criar um cluster de máquinas de processamento de dados em segundo plano (dica: use
pyres ) para mover seus dados com scripts de bancos de dados antigos para o novo shard. Eu garanto que alguns dados serão perdidos, não importa o quanto você tente (é tudo gremlins, eu juro), então repita a transferência de dados várias vezes até que a quantidade de novas informações no fragmento se torne muito pequena ou não seja.
Todo esforço foi feito para esse sistema. Mas não fornece atomicidade, isolamento ou coerência de forma alguma. Uau! Isso parece ruim! Mas não se preocupe. Certamente, você se sentirá excelente sem eles. Você sempre pode criar essas camadas com outros processos / sistemas, se necessário, mas, por padrão e sem nenhum custo, já obtém bastante: capacidade de trabalho. Confiabilidade alcançada através da simplicidade e até funciona rápido!
Mas e a tolerância a falhas? Criamos um serviço para manutenção de shards do MySQL, salvamos a tabela de configuração de shard no ZooKeeper. Quando o servidor mestre falha, aumentamos a máquina escrava e, em seguida, aumentamos a máquina que a substituirá (sempre atualizada). Não usamos o processamento automático de falhas até hoje.