Oi Habr.
Na
parte anterior , a participação de Habr foi analisada pelos principais parâmetros - o número de artigos, suas opiniões e classificações. No entanto, a questão da popularidade das seções do site não foi considerada. Tornou-se interessante examinar isso com mais detalhes e encontrar os hubs mais populares e menos populares. Por fim, examinarei o “efeito geektimes” com mais detalhes e, no final, os leitores receberão uma nova seleção dos melhores artigos sobre as novas classificações.
Quem se importa com o que aconteceu, continuou sob o corte.
Recordo mais uma vez que estatísticas e classificações não são oficiais, não tenho nenhuma informação privilegiada. Também não é garantido que não me enganei em algum lugar ou que não perdi nada. Mas ainda assim, acho que ficou interessante. Começaremos com o código primeiro, para quem isso é irrelevante, as primeiras seções podem ser ignoradas.
Coleta de dados
Na primeira versão do analisador, apenas o número de visualizações, comentários e a classificação dos artigos foram levados em consideração. Isso já é bom, mas não permite que você faça consultas mais complexas. É hora de analisar as seções temáticas do site. Isso permitirá estudos interessantes, por exemplo, para ver como a popularidade da seção "C ++" mudou ao longo de vários anos.
O analisador de artigos foi aprimorado, agora retorna os hubs aos quais o artigo pertence, assim como o apelido do autor e sua classificação (aqui você também pode fazer muitas coisas interessantes, mas isso mais tarde). Os dados são salvos em um arquivo csv aproximadamente do seguinte tipo:
2018-12-18T12:43Z,https://habr.com/ru/post/433550/," Slack — , , ",votes:7,votesplus:8,votesmin:1,bookmarks:32, views:8300,comments:10,user:ReDisque,karma:5,subscribers:2,hubs:productpm+soft ...
Obtenha uma lista dos principais hubs temáticos do site.
def get_as_str(link: str) -> Str: try: r = requests.get(link) return Str(r.text) except Exception as e: return Str("") def get_hubs(): hubs = [] for p in range(1, 12): page_html = get_as_str("https://habr.com/ru/hubs/page%d/" % p)
A função find_between e a classe Str destacam uma linha entre duas tags, usei-as
anteriormente . Os hubs temáticos estão marcados com "*", para facilitar o destaque, você também pode descomentar as linhas correspondentes para obter seções de outras categorias.
Na saída da função get_hubs, obtemos uma lista bastante impressionante, que salvamos como um dicionário. Eu cito especialmente a lista inteira para que seu volume possa ser estimado.
hubs_profile = {'infosecurity', 'programming', 'webdev', 'python', 'sys_admin', 'it-infrastructure', 'devops', 'javascript', 'open_source', 'network_technologies', 'gamedev', 'cpp', 'machine_learning', 'pm', 'hr_management', 'linux', 'analysis_design', 'ui', 'net', 'hi', 'maths', 'mobile_dev', 'productpm', 'win_dev', 'it_testing', 'dev_management', 'algorithms', 'go', 'php', 'csharp', 'nix', 'data_visualization', 'web_testing', 's_admin', 'crazydev', 'data_mining', 'bigdata', 'c', 'java', 'usability', 'instant_messaging', 'gtd', 'system_programming', 'ios_dev', 'oop', 'nginx', 'kubernetes', 'sql', '3d_graphics', 'css', 'geo', 'image_processing', 'controllers', 'game_design', 'html5', 'community_management', 'electronics', 'android_dev', 'crypto', 'netdev', 'cisconetworks', 'db_admins', 'funcprog', 'wireless', 'dwh', 'linux_dev', 'assembler', 'reactjs', 'sales', 'microservices', 'search_technologies', 'compilers', 'virtualization', 'client_side_optimization', 'distributed_systems', 'api', 'media_management', 'complete_code', 'typescript', 'postgresql', 'rust', 'agile', 'refactoring', 'parallel_programming', 'mssql', 'game_promotion', 'robo_dev', 'reverse-engineering', 'web_analytics', 'unity', 'symfony', 'build_automation', 'swift', 'raspberrypi', 'web_design', 'kotlin', 'debug', 'pay_system', 'apps_design', 'git', 'shells', 'laravel', 'mobile_testing', 'openstreetmap', 'lua', 'vs', 'yii', 'sport_programming', 'service_desk', 'itstandarts', 'nodejs', 'data_warehouse', 'ctf', 'erp', 'video', 'mobileanalytics', 'ipv6', 'virus', 'crm', 'backup', 'mesh_networking', 'cad_cam', 'patents', 'cloud_computing', 'growthhacking', 'iot_dev', 'server_side_optimization', 'latex', 'natural_language_processing', 'scala', 'unreal_engine', 'mongodb', 'delphi', 'industrial_control_system', 'r', 'fpga', 'oracle', 'arduino', 'magento', 'ruby', 'nosql', 'flutter', 'xml', 'apache', 'sveltejs', 'devmail', 'ecommerce_development', 'opendata', 'Hadoop', 'yandex_api', 'game_monetization', 'ror', 'graph_design', 'scada', 'mobile_monetization', 'sqlite', 'accessibility', 'saas', 'helpdesk', 'matlab', 'julia', 'aws', 'data_recovery', 'erlang', 'angular', 'osx_dev', 'dns', 'dart', 'vector_graphics', 'asp', 'domains', 'cvs', 'asterisk', 'iis', 'it_monetization', 'localization', 'objectivec', 'IPFS', 'jquery', 'lisp', 'arvrdev', 'powershell', 'd', 'conversion', 'animation', 'webgl', 'wordpress', 'elm', 'qt_software', 'google_api', 'groovy_grails', 'Sailfish_dev', 'Atlassian', 'desktop_environment', 'game_testing', 'mysql', 'ecm', 'cms', 'Xamarin', 'haskell', 'prototyping', 'sw', 'django', 'gradle', 'billing', 'tdd', 'openshift', 'canvas', 'map_api', 'vuejs', 'data_compression', 'tizen_dev', 'iptv', 'mono', 'labview', 'perl', 'AJAX', 'ms_access', 'gpgpu', 'infolust', 'microformats', 'facebook_api', 'vba', 'twitter_api', 'twisted', 'phalcon', 'joomla', 'action_script', 'flex', 'gtk', 'meteorjs', 'iconoskaz', 'cobol', 'cocoa', 'fortran', 'uml', 'codeigniter', 'prolog', 'mercurial', 'drupal', 'wp_dev', 'smallbasic', 'webassembly', 'cubrid', 'fido', 'bada_dev', 'cgi', 'extjs', 'zend_framework', 'typography', 'UEFI', 'geo_systems', 'vim', 'creative_commons', 'modx', 'derbyjs', 'xcode', 'greasemonkey', 'i2p', 'flash_platform', 'coffeescript', 'fsharp', 'clojure', 'puppet', 'forth', 'processing_lang', 'firebird', 'javame_dev', 'cakephp', 'google_cloud_vision_api', 'kohanaphp', 'elixirphoenix', 'eclipse', 'xslt', 'smalltalk', 'googlecloud', 'gae', 'mootools', 'emacs', 'flask', 'gwt', 'web_monetization', 'circuit-design', 'office365dev', 'haxe', 'doctrine', 'typo3', 'regex', 'solidity', 'brainfuck', 'sphinx', 'san', 'vk_api', 'ecommerce'}
Para comparação, as seções dos geeks parecem mais modestas:
hubs_gt = {'popular_science', 'history', 'soft', 'lifehacks', 'health', 'finance', 'artificial_intelligence', 'itcompanies', 'DIY', 'energy', 'transport', 'gadgets', 'social_networks', 'space', 'futurenow', 'it_bigraphy', 'antikvariat', 'games', 'hardware', 'learning_languages', 'urban', 'brain', 'internet_of_things', 'easyelectronics', 'cellular', 'physics', 'cryptocurrency', 'interviews', 'biotech', 'network_hardware', 'autogadgets', 'lasers', 'sound', 'home_automation', 'smartphones', 'statistics', 'robot', 'cpu', 'video_tech', 'Ecology', 'presentation', 'desktops', 'wearable_electronics', 'quantum', 'notebooks', 'cyberpunk', 'Peripheral', 'demoscene', 'copyright', 'astronomy', 'arvr', 'medgadgets', '3d-printers', 'Chemistry', 'storages', 'sci-fi', 'logic_games', 'office', 'tablets', 'displays', 'video_conferencing', 'videocards', 'photo', 'multicopters', 'supercomputers', 'telemedicine', 'cybersport', 'nano', 'crowdsourcing', 'infographics'}
Da mesma forma, os hubs restantes foram salvos. Agora é fácil escrever uma função que retorne o resultado, o artigo refere-se a tempos de geek ou a um hub de perfis.
def is_geektimes(hubs: List) -> bool: return len(set(hubs) & hubs_gt) > 0 def is_geektimes_only(hubs: List) -> bool: return is_geektimes(hubs) is True and is_profile(hubs) is False def is_profile(hubs: List) -> bool: return len(set(hubs) & hubs_profile) > 0
Funções semelhantes foram feitas para outras seções (“desenvolvimento”, “administração” etc.).
Processamento
É hora de começar a análise. Carregamos o conjunto de dados e processamos os dados dos hubs.
def to_list(s: str) -> List[str]:
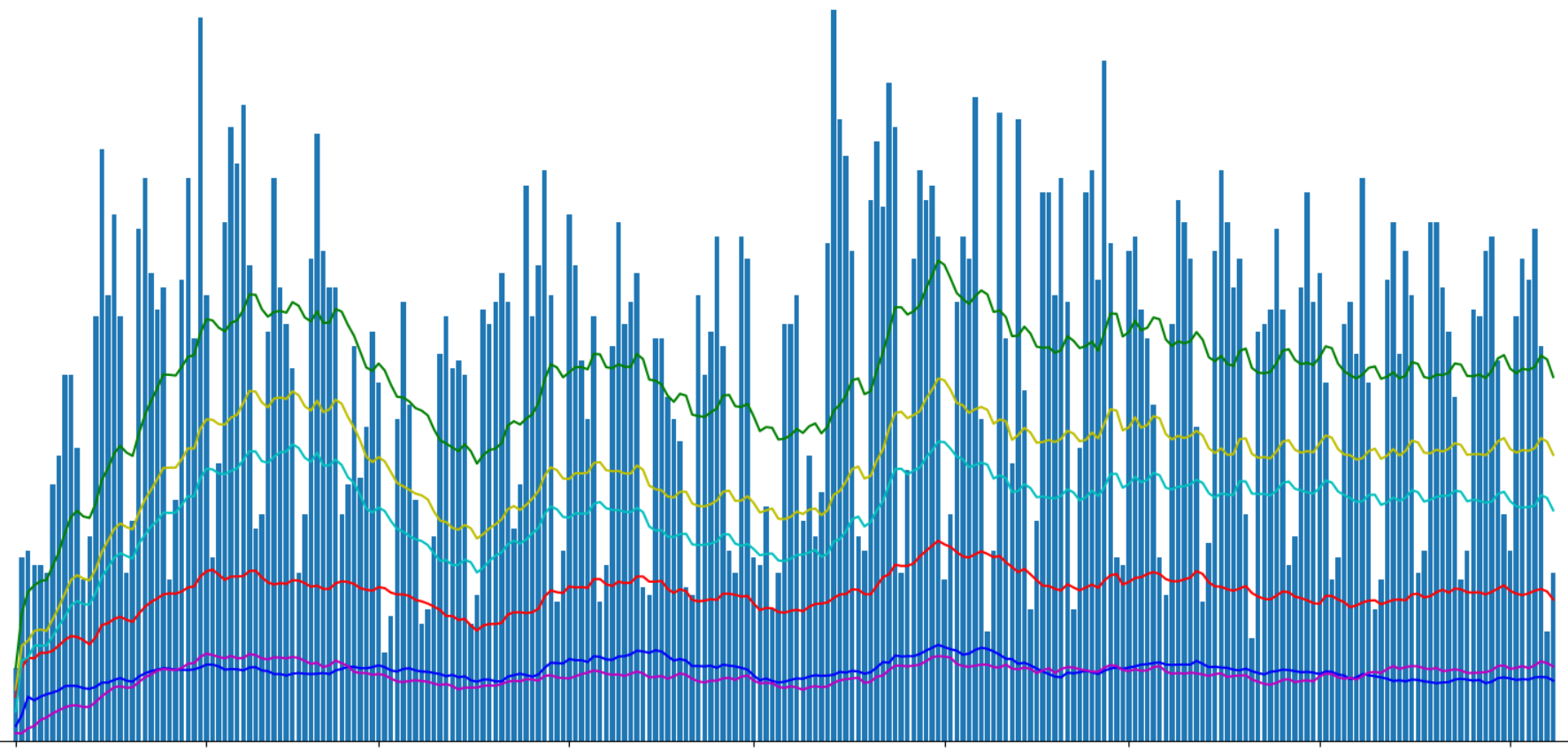
Agora podemos agrupar os dados por dia e exibir o número de publicações por diferentes hubs.
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.sum().reset_index() profile_per_day_avg = grouped['is_profile'].rolling(window=20, min_periods=1).mean() geektimes_per_day_avg = grouped['is_geektimes'].rolling(window=20, min_periods=1).mean() geektimesonly_per_day_avg = grouped['is_geektimes_only'].rolling(window=20, min_periods=1).mean() admin_per_day_avg = grouped['is_admin'].rolling(window=20, min_periods=1).mean() develop_per_day_avg = grouped['is_develop'].rolling(window=20, min_periods=1).mean()
Exiba o número de artigos publicados usando o Matplotlib:

Dividi os artigos “geektimes” e “geektimes only” no gráfico, porque um artigo pode pertencer às duas seções simultaneamente (por exemplo, “DIY” + “microcontroladores” + “C ++”). Com a designação “perfil”, destaquei os artigos de perfil do site, embora seja possível que o termo inglês profile não esteja totalmente correto para isso.
Na parte anterior, perguntamos sobre o "efeito geektimes" associado à mudança nas regras para pagamento de artigos por geektimes a partir deste verão. Derivamos artigos separados para os geeks:
df_gt = df[(df['is_geektimes_only'] == True)] group_gt = df_gt.groupby(['date']) days_count_gt = group_gt.size().reset_index(name='counts') grouped = group_gt.sum().reset_index() year_days_gt = days_count_gt['date'].values view_gt_per_day_avg = grouped['views'].rolling(window=20, min_periods=1).mean()
O resultado é interessante. A proporção aproximada de visualizações de artigos geektimes em relação ao total em torno de 1: 5. Mas se o número total de visualizações flutuasse visivelmente, a visualização de artigos "divertidos" era mantida aproximadamente no mesmo nível.

Você também pode observar que o número total de visualizações de artigos na seção "geektimes" depois de alterar as regras ainda caiu, mas "a olho nu", não mais que 5% dos valores totais.
É interessante ver o número médio de visualizações por artigo:

Para artigos "divertidos", é cerca de 40% acima da média. Provavelmente isso não é surpreendente. O fracasso no início de abril não está claro para mim, talvez tenha sido, ou seja algum tipo de erro de análise, ou talvez um dos geeks dos autores tenha saído de férias;).
A propósito, no gráfico há mais dois picos perceptíveis no número de visualizações de artigos - feriados de Ano Novo e Maio.
Hubs
Vamos seguir para a análise prometida dos hubs. Exibiremos os 20 principais hubs pelo número de visualizações:
hubs_info = [] for hub_name in hubs_all: mask = df['hubs'].apply(lambda x: hub_name in x) df_hub = df[mask] count, views = df_hub.shape[0], df_hub['views'].sum() hubs_info.append((hub_name, count, views))
Resultado:

Surpreendentemente, o hub de "Segurança da informação" acabou sendo o mais popular em termos de visualização, também "Programação" e "Ciência popular" estão entre os 5 principais líderes.
O antítopo toma Gtk e cacau.

Vou lhe contar um segredo, os principais hubs também podem ser vistos
aqui , embora o número de visualizações não seja mostrado lá.
Classificação
E, finalmente, a classificação prometida. Usando os dados da análise de hubs, podemos exibir os artigos mais populares nos hubs mais populares para este ano de 2019.
Segurança da informação- Como eu não trabalhei por um ano no Sberbank 304000 visualizações, 599 comentários, classificação + 457,0 / -14,0
- As lâmpadas inteligentes lançadas no lixo são uma fonte valiosa de informações pessoais 232.000 visualizações, 147 comentários, classificação + 75,0 / -11,0
- Fraudadores e EDS - tudo é muito ruim 176.000 visualizações, 778 comentários, classificação + 356.0 / -0.0
- Como Megafon dormiu em assinaturas móveis 166.000 visualizações, 676 comentários, classificação + 624,0 / -2,0
- Ao invadir a VK, a autenticação de dois fatores não salvará 148.000 visualizações, 332 comentários, classificação + 124,0 / -17,0
- Como o navegador ajuda o camarada Major 132.000 visualizações, 321 comentários, classificação + 246.0 / -19.0
- O maior despejo da história: 2,7 bilhões de contas, das quais 773 milhões de 123.000 visualizações únicas , 154 comentários, classificação + 86,0 / -5,0
- Querida, matamos a Internet 121.000 visualizações, 933 comentários, classificação + 392.0 / -83.0
- 'Conteúdo para celular' de graça, sem SMS e registros. Detalhes de fraude da Megafon 114.000 visualizações, 478 comentários, classificação + 488.0 / -8.0
- Port scanner na conta pessoal da Rostelecom 111.000 visualizações, 194 comentários, classificação + 300.0 / -8.0
Programação- Sobre um homem 167.000 visualizações, 249 comentários, classificação + 239,0 / -33,0
- Quanto mais rápido você esquecer OOP, melhor para você e seus programas 129.000 visualizações, 1271 comentários, classificação + 131,0 / -63,0
- Por que os desenvolvedores seniores não conseguem um emprego 119.000 visualizações, 901 comentários, classificação + 151,0 / -14,0
- Os idosos não pertencem aqui? Programamos após 35.000 visualizações, 649 comentários, classificação + 222,0 / -16,0
- Novas linguagens de programação eliminam imperceptivelmente nossa conexão com a realidade 106.000 visualizações, 764 comentários, classificação + 164.0 / -52.0
- O que aprendi com minha experiência amarga (mais de 30 anos em desenvolvimento de software) 101.000 visualizações, 128 comentários, classificação + 178,0 / -9,0
- As linguagens de programação mais raras e mais caras 82900 visualizações, 119 comentários, avaliação + 38,0 / -10,0
- Curso de palestras em JavaScript e Node.js nas visualizações KPI 80300, 14 comentários, classificação + 34,0 / -2,0
- Termos de TI no exemplo do processo de cultivo de batatas 78000 visualizações, 86 comentários, classificação + 84,0 / -14,0
- 256 linhas de C ++ simples: escrevendo um traçador de raios do zero em poucas horas 77600 visualizações, 124 comentários, avaliação + 241,0 / -0,0
Ciência popular- O que o designer fumava: uma arma de fogo incomum 236.000 visualizações, 123 comentários, avaliação + 119,0 / -9,0
- Cientistas descobriram o vertebrado vivo mais antigo da Terra 234.000 visualizações, 212 comentários, classificação + 82.0 / -14.0
- A série 'Chernobyl': assista e pense 173.000 visualizações, 803 comentários, classificação + 164.0 / -25.0
- Um adolescente de 12 anos conduziu uma reação de fusão nuclear em seu laboratório doméstico 145.000 visualizações, 280 comentários, classificação + 126.0 / -29.0
- The Tale of the Rose Alloy and the Fallen Krenka 134.000 visualizações, 244 comentários, classificação + 217,0 / -1,0
- Aumente isso! Aumento moderno na resolução 134000 visualizações, 235 comentários, classificação + 377,0 / -1,0
- O software para o Boeing-737 Max foi escrito por terceirizados que ganhavam US $ 9 por hora ; 126.000 visualizações; 560 comentários; classificação + 153,0 / -6,0
- Não fique nervoso, não se apresse, não interrompa: a história de uma tragédia 121.000 visualizações, 384 comentários, classificação + 242.0 / -4.0
- Os matemáticos encontraram a maneira perfeita de multiplicar números 108.000 visualizações, 222 comentários, classificação + 173,0 / -10,0
- Novas linguagens de programação eliminam imperceptivelmente nossa conexão com a realidade 106.000 visualizações, 764 comentários, classificação + 164.0 / -52.0
Carreira profissional- Como eu não trabalhei por um ano no Sberbank 304000 visualizações, 599 comentários, classificação + 457,0 / -14,0
- Eu estrago a vida dos desenvolvedores com meus comentários de código e desculpe-me 187.000 visualizações, 21 comentários, classificação + 37,0 / -3,0
- Development King 179.000 visualizações, 668 comentários, avaliação + 315.0 / -60.0
- Sobre um homem 167.000 visualizações, 249 comentários, classificação + 239,0 / -33,0
- Aposentado em 22.158.000 visualizações, 927 comentários, classificação + 259,0 / -100,0
- Como substituir uma lâmpada no local de trabalho para que você não seja demitido? 139000 visualizações, 762 comentários, avaliação + 200,0 / -20,0
- Innovation in Russian 128.000 visualizações, 612 comentários, classificação + 480,0 / -33,0
- Por que os desenvolvedores seniores não conseguem um emprego 119.000 visualizações, 901 comentários, classificação + 151,0 / -14,0
- Funcionários 'queimados': existe uma saída? 117000 visualizações, 398 comentários, avaliação + 210,0 / -14,0
- Os idosos não pertencem aqui? Programamos após 35.000 visualizações, 649 comentários, classificação + 222,0 / -16,0
Legislação em TI- Fraudadores e EDS - tudo é muito ruim 176.000 visualizações, 778 comentários, classificação + 356.0 / -0.0
- Como Megafon dormiu em assinaturas móveis 166.000 visualizações, 676 comentários, classificação + 624,0 / -2,0
- Innovation in Russian 128.000 visualizações, 612 comentários, classificação + 480,0 / -33,0
- 'Conteúdo para celular' de graça, sem SMS e registros. Detalhes de fraude da Megafon 114.000 visualizações, 478 comentários, classificação + 488.0 / -8.0
- Enquanto as autoridades do Cazaquistão tentam encobrir seu fracasso com a introdução do certificado, 111.000 visualizações, 77 comentários, classificação + 122.0 / -14.0
- Como o Protonmail é bloqueado na Rússia 102000 visualizações, 398 comentários, classificação + 418,0 / -7,0
- A lei sobre o isolamento do Runet foi adotada pela Duma do Estado em três leituras, 88.200 visualizações, 878 comentários, classificação + 73,0 / -18,0
- Como programador, o banco escolheu e leu o contrato 87.200 visualizações, 611 comentários, classificação + 166,0 / -9,0
- O Ministério das Comunicações e Meios de Comunicação de Massa aprovou o projeto de lei sobre isolamento do Runet 83600 visualizações, 364 comentários, classificação + 79,0 / -9,0
- Uma resposta detalhada ao comentário, bem como um pouco sobre a vida dos provedores na Federação Russa, 74700 visualizações, 389 comentários, classificação + 290,0 / -1,0
Desenvolvimento Web- Os idosos não pertencem aqui? Programamos após 35.000 visualizações, 649 comentários, classificação + 222,0 / -16,0
- Como criar sites em 2019 110.000 visualizações, 278 comentários, classificação + 233,0 / -11,0
- Learning Docker, Part 1: Basics 91300 visualizações, 24 comentários, avaliação + 52,0 / -10,0
- Curso de palestras em JavaScript e Node.js nas visualizações KPI 80300, 14 comentários, classificação + 34,0 / -2,0
- Estagiário Vasya e suas histórias sobre idempotency API 68900 visualizações, 160 comentários, avaliação + 216.0 / -3.0
- O entendimento de junções está quebrado. Definitivamente, essa não é a interseção de círculos, honestamente 65.900 visualizações, 223 comentários, classificação + 138,0 / -41,0
- Por que você não precisa gastar seu tempo criando sites temáticos de nicho 62700 visualizações, 243 comentários, classificação + 179,0 / -13,0
- Criamos uma aplicação web moderna do zero 62200 visualizações, 122 comentários, avaliação + 56,0 / -8,0
- Um dia sombrio para Vue.js 60.800 visualizações, 133 comentários, avaliação + 77,0 / -6,0
- Por que o desenvolvimento web moderno é tão complicado? Parte 1.577.700 visualizações, 319 comentários, classificação + 101,0 / -6,0
GTKE, finalmente, para não ofender ninguém, darei a classificação do hub menos visitado "gtk". Nele,
um artigo foi publicado ao longo do ano, e também “automaticamente” ocupa a primeira linha da classificação.
Conclusão
Não haverá conclusão. Gostam de ler para todos.