
Hoje, na quarta-feira,
será realizada a próxima versão do Kubernetes - 1.16. De acordo com a tradição desenvolvida para o nosso blog, pela décima data de aniversário, estamos falando das mudanças mais significativas na nova versão.
As informações usadas para preparar este material são extraídas da
tabela de rastreamento de aprimoramentos do Kubernetes ,
CHANGELOG-1.16 e questões relacionadas, solicitações de recebimento e propostas de aprimoramento do Kubernetes (KEP). Então vamos lá ..
Nós
Um número verdadeiramente grande de inovações notáveis (no status da versão alfa) é apresentado ao lado dos nós dos clusters K8s (Kubelet).
Primeiramente,
são apresentados os chamados
" recipientes efêmeros " ( recipientes efêmeros ) , projetados para simplificar o processo de depuração em pods . O novo mecanismo permite executar contêineres especiais que iniciam no espaço de nomes dos pods existentes e permanecem por um curto período de tempo. Seu objetivo é interagir com outros pods e contêineres para resolver problemas e depuração. Para esse recurso, um novo comando
kubectl debug é
kubectl debug , o que é semelhante em essência ao
kubectl exec : somente em vez de iniciar o processo no contêiner (como no caso do
exec ), ele inicia o contêiner no pod. Por exemplo, esse comando conectará um novo contêiner ao pod:
kubectl debug -c debug-shell --image=debian target-pod -- bash
Detalhes sobre recipientes efêmeros (e exemplos de seu uso) podem ser encontrados no
KEP correspondente . A implementação atual (no K8s 1.16) é a versão alfa e um dos critérios para sua transferência para a versão beta é “testar a API de recipientes efêmeros por pelo menos 2 lançamentos [Kubernetes]”.
NB : Em essência, e até o nome do recurso se parece com o plugin kubectl-debug já existente, sobre o qual já escrevemos . Supõe-se que, com o advento dos contêineres efêmeros, o desenvolvimento de um plug-in externo separado será interrompido.Outra inovação, o
PodOverhead foi projetada para fornecer um
mecanismo para calcular os custos indiretos dos pods , que podem variar bastante, dependendo do tempo de execução usado. Como exemplo, os autores
deste KEP citam Kata Containers, que exigem o lançamento do kernel convidado, do agente kata, do sistema init etc. Quando a sobrecarga se torna tão grande, não pode ser ignorada, o que significa que é necessária uma maneira de levar em consideração outras cotas, planejamento etc. Para implementá-
PodSpec , o campo
Overhead *ResourceList foi adicionado ao
PodSpec (comparado com os dados no
RuntimeClass , se um for usado).
Outra inovação notável é o
Node Topology Manager , projetado para unificar a abordagem para ajustar a alocação de recursos de hardware para vários componentes no Kubernetes. Essa iniciativa é causada pela crescente demanda de vários sistemas modernos (da área de telecomunicações, aprendizado de máquina, serviços financeiros etc.) para computação paralela de alto desempenho e minimização de atrasos na execução das operações, para os quais eles usam os recursos avançados de aceleração de CPU e hardware. Essas otimizações no Kubernetes foram alcançadas até agora graças a componentes díspares (gerenciador de CPU, gerenciador de dispositivos, CNI), e agora eles adicionarão uma única interface interna que unifica a abordagem e simplifica a conexão de novos componentes semelhantes - os chamados reconhecimento de topologia - no lado do Kubelet. Os detalhes estão no
KEP correspondente .
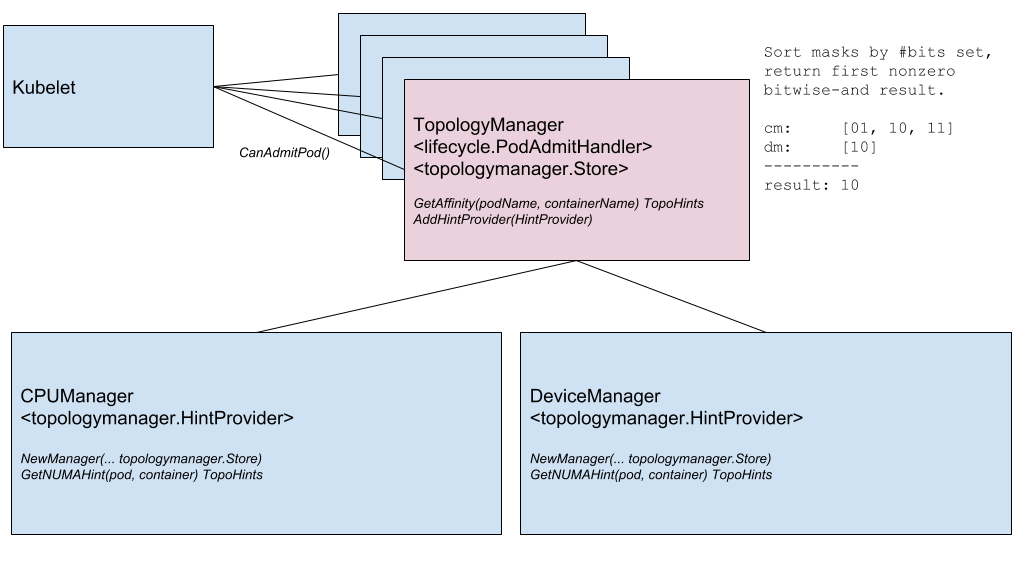 Diagrama do componente do Gerenciador de Topologia
Diagrama do componente do Gerenciador de TopologiaO próximo recurso é
verificar contêineres durante a inicialização ( probe de inicialização ) . Como você sabe, para contêineres que são executados por um longo período de tempo, é difícil obter o status atual: eles são "mortos" antes do início real da operação ou terminam em um conflito por um longo tempo. Uma nova verificação (ativada através do portão de recurso chamado
StartupProbeEnabled ) cancela - ou melhor,
StartupProbeEnabled - a ação de outras verificações até o momento em que o pod termina seu lançamento. Por esse motivo, o recurso foi originalmente chamado
de adiamento da sonda de animação de inicialização por pod . Para pods que demoram muito tempo para iniciar, você pode pesquisar o estado em intervalos de tempo relativamente curtos.
Além disso, imediatamente no status beta, é adicionada uma melhoria para o RuntimeClass, adicionando suporte para "clusters heterogêneos". Com o
RuntimeClass Scheduling, agora não é necessário que cada nó tenha suporte para cada RuntimeClass: para pods, você pode escolher RuntimeClass sem pensar na topologia do cluster. Anteriormente, para conseguir isso - para que os pods aparecessem nos nós com suporte para tudo o que eles precisavam - eles tinham que atribuir regras apropriadas ao NodeSelector e tolerâncias.
O KEP fala sobre exemplos de uso e, é claro, detalhes de implementação.
Rede
Dois recursos de rede significativos que apareceram pela primeira vez (na versão alfa) no Kubernetes 1.16 são:
- Suporte para uma pilha de rede dupla - IPv4 / IPv6 - e seu "entendimento" correspondente no nível de pods, nós, serviços. Inclui a interação de IPv4 para IPv4 e IPv6 para IPv6 entre pods, de pods para serviços externos, implementações de referência (na estrutura dos plug-ins Bridge CNI, PTP CNI e IPAM Host-Local), bem como o reverso Compatível com clusters Kubernetes que funcionam apenas em IPv4 ou IPv6. Os detalhes da implementação estão no KEP .
Um exemplo da saída de dois tipos de endereços IP (IPv4 e IPv6) na lista de pods:
kube-master
- A nova API do Endpoint é a API EndpointSlice . Ele resolve os problemas da API do Endpoint existente com desempenho / escalabilidade que afeta vários componentes no plano de controle (apiserver, etcd, endpoints-controller, kube-proxy). A nova API será adicionada ao grupo da API de descoberta e poderá atender dezenas de milhares de pontos de extremidade de back-end em cada serviço em um cluster que consiste em mil nós. Para fazer isso, cada Serviço é mapeado para N objetos
EndpointSlice , cada um dos quais, por padrão, não possui mais de 100 pontos de extremidade (o valor é configurável). A API EndpointSlice também fornecerá oportunidades para seu desenvolvimento futuro: suporte a vários endereços IP para cada pod, novos estados para terminais (não apenas Ready e NotReady ), subconjunto dinâmico para terminais.
O
finalizador apresentado no último release chamado
service.kubernetes.io/load-balancer-cleanup e anexado a cada serviço com o tipo
LoadBalancer avançou para a versão beta. No momento da remoção de um serviço desse tipo, impede a exclusão real do recurso até que a "limpeza" de todos os recursos correspondentes do balanceador seja concluída.
API Machinery
O verdadeiro "marco de estabilização" é fixo na área do servidor da API do Kubernetes e a interação com ele. Em muitos aspectos, isso ocorreu devido à
transferência para o status estável de CustomResourceDefinitions (CRD) que
não precisava de uma apresentação especial , que tinha status beta desde o distante Kubernetes 1.7 (e junho de 2017!). A mesma estabilização chegou aos recursos relacionados a eles:
- "Sub-recursos" com
/status e /scale para CustomResources; - conversão de versão para CRD, com base em um webhook externo;
- recentemente introduzido (no K8s 1.15) valores padrão (padrão) e exclusão automática de campos (remoção) de CustomResources;
- a possibilidade de usar o esquema OpenAPI v3 para criar e publicar documentação do OpenAPI usada para validar recursos CRD no lado do servidor.
Outro mecanismo que há muito tempo é conhecido pelos administradores do Kubernetes: o
webhook de admissão - também está no status beta há muito tempo (desde o K8s 1.9) e agora foi declarado estável.
Dois outros recursos chegaram à versão beta:
aplicar do lado do servidor e
assistir aos favoritos .
E a única inovação significativa na versão alfa foi a
rejeição do SelfLink - um URI especial que representa o objeto especificado e faz parte do
ObjectMeta e do
ListMeta (ou seja, parte de qualquer objeto no Kubernetes). Por que recusar? A motivação “simples”
parece a ausência de razões reais (intransponíveis) para que esse campo continue a existir. Razões mais formais são otimizar o desempenho (remover um campo desnecessário) e simplificar o trabalho do genérico-apiserver, que é forçado a processar esse campo de uma maneira especial (este é o único campo definido antes do serialização do objeto). A verdadeira "obsolescência" (na versão beta) do
SelfLink acontecerá com a versão 1.20 do Kubernetes e a versão final - 1.21.
Armazenamento de dados
O principal trabalho no campo de armazenamento, como nas versões anteriores, é observado no campo de
suporte CSI . As principais mudanças aqui são:
- pela primeira vez (na versão alfa) , o suporte para plug-ins CSI para nós de trabalho do Windows apareceu : a maneira atual de trabalhar com repositórios substituirá os plug-ins in-tree no núcleo Kubernetes e plug-ins FlexVolume da Microsoft baseados em Powershell;
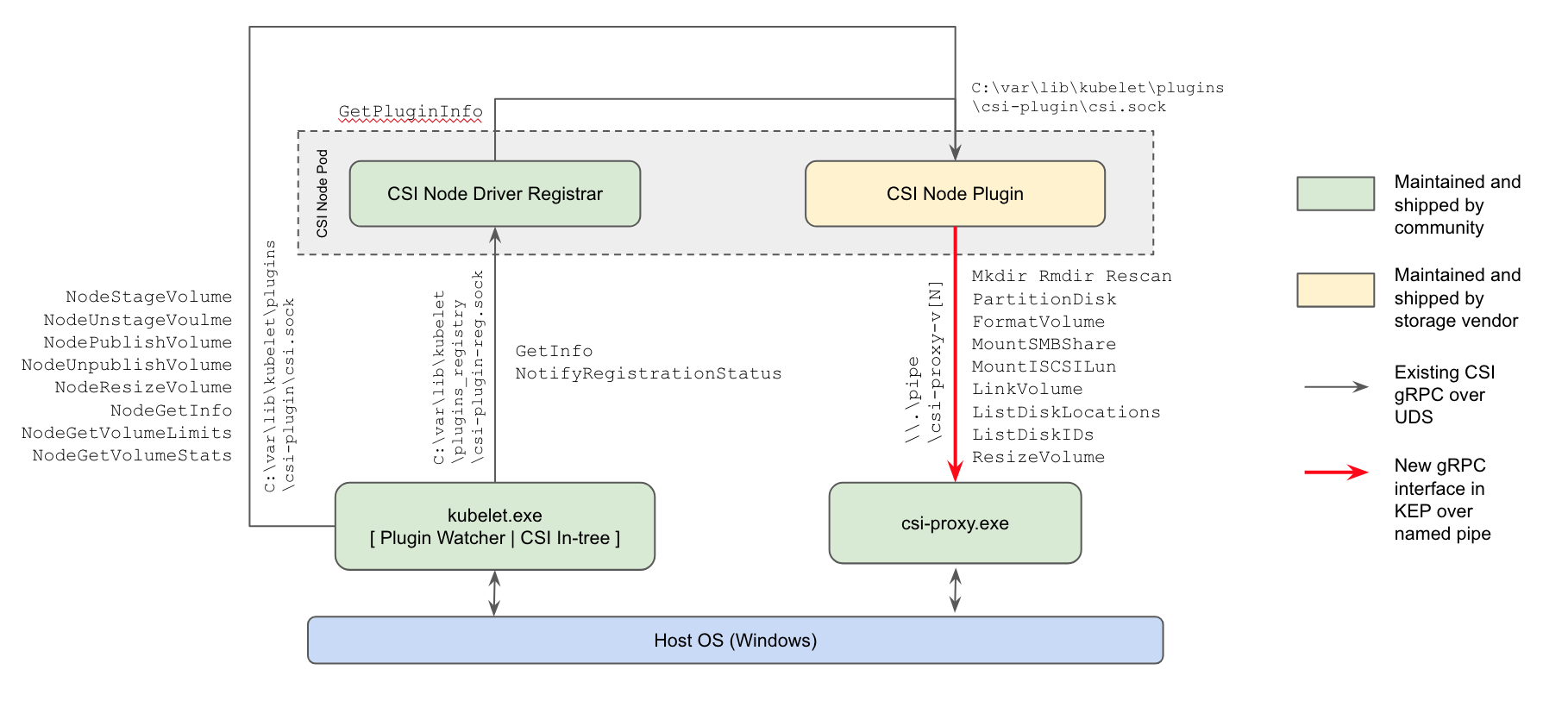
Esquema de implementação do plug-in do Windows CSI do Kubernetes
- a capacidade de redimensionar volumes CSI , introduzida no K8s 1.12, cresceu para uma versão beta;
- a possibilidade de usar o CSI para criar volumes efêmeros locais ( CSI Inline Volume Support ) atingiu um "aumento" semelhante (de alfa para beta).
A
função para clonar volumes que apareceu na versão anterior do Kubernetes (usando PVCs existentes como um
DataSource para criar novos PVCs) agora também recebeu status beta.
Planejador
Duas mudanças notáveis no planejamento (ambas na versão alfa):
EvenPodsSpreading é a capacidade de usar EvenPodsSpreading para "distribuir de forma justa" cargas em vez de unidades lógicas de aplicativo (como Deployment e ReplicaSet) e ajustar essa distribuição (como um requisito estrito ou uma condição moderada, ou seja, prioridade). O recurso expandirá os recursos de distribuição existentes dos pods planejados, agora limitados pelas PodAntiAffinity e PodAntiAffinity , fornecendo aos administradores um controle mais PodAntiAffinity sobre esse assunto, o que significa melhor acessibilidade e consumo otimizado de recursos. Os detalhes estão no KEP .- O uso da política BestFit na função de prioridade RequestedToCapacityRatio durante o agendamento de pods, que permite que o empacotamento em lixeira (“empacotamento em contêineres”) seja usado para recursos principais (processador, memória) e estendidos (como GPU). Veja KEP para mais detalhes.

Programação de pod: antes de usar a política de melhor ajuste (diretamente através do planejador padrão) e usá-la (via extensor do planejador)
Além disso,
é apresentada a oportunidade de criar seus próprios plug-ins para o planejador fora da árvore de desenvolvimento principal do Kubernetes (fora da árvore).
Outras mudanças
Também na versão Kubernetes 1.16, você pode observar a
iniciativa de colocar as métricas existentes em ordem completa ou mais precisamente, de acordo com os
requisitos oficiais para a instrumentação do K8s. Eles basicamente contam com a
documentação relevante do
Prometheus . As inconsistências foram formadas por vários motivos (por exemplo, algumas métricas foram simplesmente criadas antes que as instruções atuais aparecessem), e os desenvolvedores decidiram que era hora de trazer tudo para um único padrão ", de acordo com o restante do ecossistema de Prometheus". A implementação atual desta iniciativa tem o status da versão alfa, que aumentará gradualmente nas versões futuras do Kubernetes para beta (1.17) e estável (1.18).
Além disso, as seguintes alterações podem ser observadas:
- Desenvolvimento do suporte do Windows com o advento do utilitário Kubeadm para este SO (versão alfa), a possibilidade de
RunAsUserName para contêineres do Windows (versão alfa), aprimoramento do suporte da Conta de Serviço Gerenciada de Grupo (gMSA) para a versão beta, montagem / conexão de volumes vSphere. - Mecanismo de compactação de dados reprojetado nas respostas da API . Anteriormente, um filtro HTTP era usado para esses propósitos, o que impunha várias restrições que impediam sua inclusão por padrão. Agora a "compactação transparente de solicitações" funciona: os clientes que enviam
Accept-Encoding: gzip no cabeçalho recebem uma resposta compactada no GZIP se seu tamanho exceder 128 Kb. O Clients on Go suporta automaticamente a compactação (envie o cabeçalho desejado), para que eles notem imediatamente uma diminuição no tráfego. (Para outros idiomas, pequenas modificações podem ser necessárias.) - Tornou-se possível escalar o HPA de / para zero pods com base em métricas externas . Se o dimensionamento for baseado em objetos / métricas externas, quando as cargas de trabalho estiverem ociosas, você poderá escalar automaticamente para 0 réplicas para economizar recursos. Esse recurso deve ser especialmente útil nos casos em que os trabalhadores solicitam recursos da GPU e o número de tipos diferentes de trabalhadores ociosos excede o número de GPUs disponíveis.
- Um novo cliente -
k8s.io/client-go/metadata.Client - para acesso "generalizado" a objetos. Ele foi projetado para obter facilmente metadados (isto é, a subseção de metadata ) dos recursos do cluster e executar operações com eles a partir da categoria de coleta de lixo e cotas. - Agora o Kubernetes pode ser criado sem provedores de nuvem desatualizados ("embutidos" na árvore) (versão alfa).
- A capacidade experimental (versão alfa) de aplicar patches de customização durante as operações
init , join e upgrade foi adicionada ao utilitário kubeadm. Para detalhes sobre como usar o --experimental-kustomize , consulte KEP . - O novo terminal para o apiserver é
readyz , que permite exportar informações de prontidão. O servidor da API também possui um sinalizador --maximum-startup-sequence-duration , que permite ajustar suas reinicializações. - Dois recursos para o Azure são declarados estáveis: Suporte para zonas de disponibilidade e grupo de recursos cruzados (RG). Além disso, o Azure adicionou:
- A AWS oferece suporte ao EBS no Windows e chamadas API API EC2 otimizadas
DescribeInstances . - O Kubeadm agora migra sua configuração CoreDNS por conta própria ao atualizar para o CoreDNS.
- Os binários etcd na imagem correspondente do Docker são executáveis em todo o mundo, o que permite executar essa imagem sem a necessidade de privilégios de root. Além disso, a imagem de migração etcd abandonou o suporte para a versão etcd2.
- O Cluster Autoscaler 1.16.0 passou a usar o distroless como imagem de base, melhorou o desempenho e adicionou novos provedores de nuvem (DigitalOcean, Magnum, Packet).
- Atualizações no software usado / dependente: Vá para 1.12.9, etcd 3.3.15, CoreDNS 1.6.2.
PS
Leia também em nosso blog: