O CQM é uma aparência diferente no aprendizado profundo para otimizar as pesquisas em idiomas naturais
Breve descrição: A Malha Quântica Calibrada (CQM) é o próximo passo da RNN / LSTM (Redes Neurais Recorrentes) / Memória de longo prazo (LSTM). Existe um novo algoritmo chamado Calibrated Quantum Mesh (CQM), que promete aumentar a precisão das pesquisas em linguagem natural sem o uso de dados de treinamento rotulados.
Foi criado um algoritmo de pesquisa de linguagem natural (NLS) e compreensão de linguagem natural (NLU) completamente novo, que não só ultrapassa os algoritmos tradicionais RNN / LSTM ou CNN, mas também é auto-aprendizado e não requer dados marcados para treinamento.
Parece bom demais para ser verdade, mas os resultados iniciais são impressionantes. CQM - desenvolvido por Praful Krishna e sua equipe em Coseer (San Francisco).
Embora a empresa ainda seja pequena, eles trabalham com várias empresas da Fortune 500 e começaram a realizar conferências técnicas.
É aqui que eles esperam provar a si mesmos:
Precisão: De acordo com Krishna, o NLS médio funciona em um chatbot menos sério, como regra, tem uma precisão de apenas cerca de 70%.
As aplicações iniciais da Coseer alcançaram uma precisão de mais de 95% ao retornar as informações relevantes corretas. Palavras-chave não são necessárias.
Os dados de treinamento rotulados não são necessários: todos sabemos que os dados de treinamento rotulados são uma despesa financeira e de tempo que limita a precisão de nossos bots de bate-papo.
Há alguns anos, M.D. Anderson abandonou seu experimento caro e de anos com o IBM Watson para oncologia por causa da precisão.
O que reteve a precisão foi a necessidade de pesquisadores de câncer muito experientes anotarem documentos no recinto. Eles deveriam ter feito isso em vez de fazer suas pesquisas.
Velocidade de implementação: a Coseer diz que, sem dados de treinamento, a maioria das implantações pode ser lançada dentro de 4-12 semanas. Isso é muito menor do que quando o usuário começa a usar um sistema pré-treinado, cuja operação começa com o carregamento preliminar de documentos marcados.
Além disso, ao contrário dos grandes fornecedores atuais que usam algoritmos tradicionais de aprendizado profundo, a Coseer prefere implantá-los em uma nuvem segura e privada para garantir a segurança dos dados.
Todas as “evidências” usadas para chegar a qualquer conclusão são armazenadas em um diário que pode ser usado para demonstrar transparência e conformidade com as regras de segurança de dados, como o GDPR.
Como isso funciona
Coseer fala sobre os três princípios que definem o CQM:
1. Palavras (variáveis) têm significados diferentes.
Considere a palavra "forno", que pode ser um substantivo ou um verbo. Por exemplo, "verso", que pode significar "poema" ou o verbo "verso vento" - essas são as palavras homônimos.
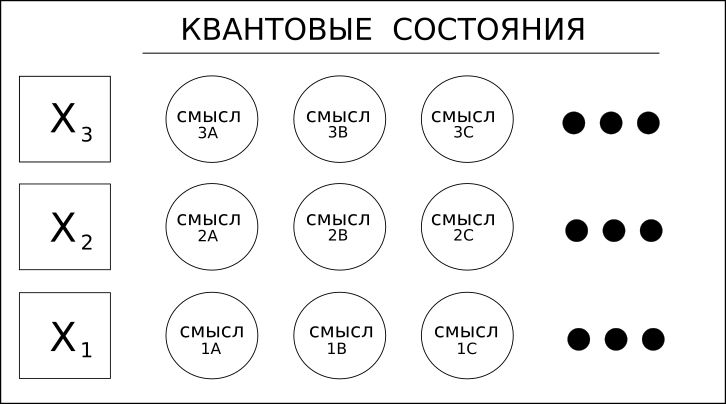
As soluções de aprendizado profundo, incluindo RNN / LSTM ou até CNN para texto, podem apenas olhar para frente ou para trás para determinar o "contexto" de uma palavra e, assim, determinar seu significado.
Coseer leva em consideração todos os possíveis significados da palavra e aplica probabilidade estatística a cada um deles com base em todo o documento ou corpus.
O uso do termo "quantum" neste caso refere-se apenas à possibilidade de múltiplos valores, e não a uma superposição mais exótica da computação quântica.
2. Tudo está interconectado em uma grade de valores:
Extrair de todas as palavras disponíveis (variáveis) todos os seus relacionamentos possíveis é o segundo princípio.
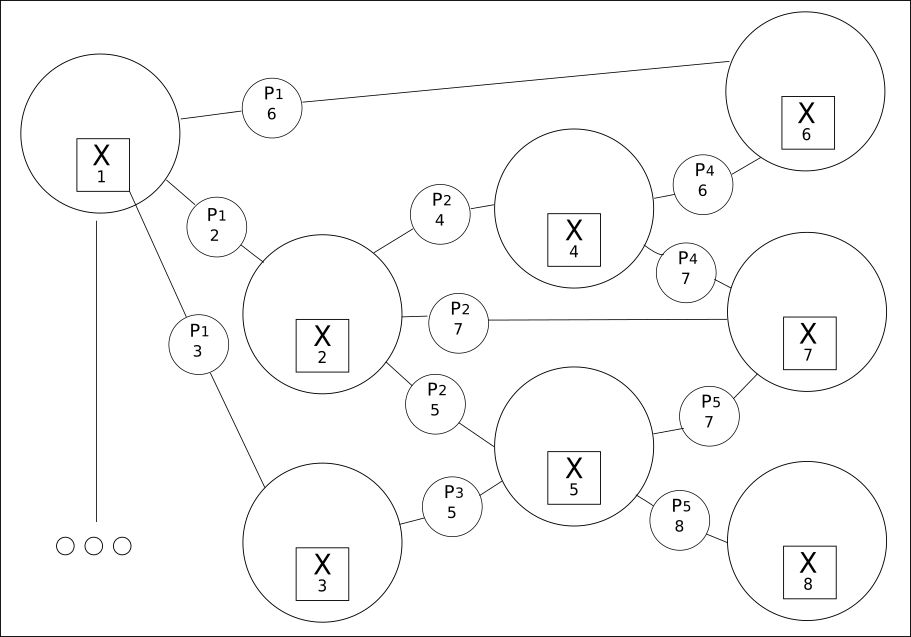
O CQM cria uma grade de valores possíveis, entre os quais um valor real será encontrado. O uso dessa abordagem revela uma relação muito mais ampla entre frases anteriores ou subsequentes do que o tradicional Deep Learning pode fornecer.
Embora o número de palavras possa ser limitado, seus relacionamentos podem estar na casa das centenas de milhares.
3. Todas as informações disponíveis são usadas seqüencialmente para combinar a grade em um único valor. Esse processo de calibração identifica rapidamente palavras ou conceitos ausentes e fornece treinamento muito rápido e preciso.
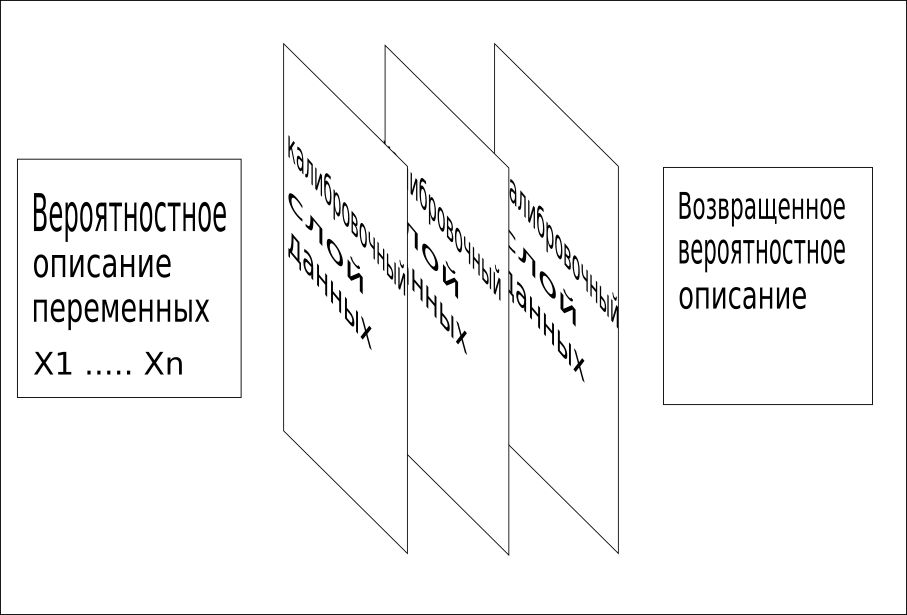
Os modelos CQM usam dados de treinamento, dados de contexto, dados de referência e outros fatos conhecidos sobre o problema para identificar essas camadas de dados de calibração.
Infelizmente, Coseer publicou muito pouco em domínio público para explicar os aspectos técnicos do algoritmo.
Qualquer avanço na eliminação de dados marcados durante o treinamento deve ser bem-vindo e, é claro, melhorar a precisão levará ao fato de que clientes muito mais satisfeitos usarão seu bot de bate-papo.