1. Introdução
Alguns anos atrás, decidimos que era hora de oferecer suporte ao código SIMD no .NET . Introduzimos o namespace System.Numerics com os tipos Vector2 , Vector3 , Vector4 e Vector<T> . Esses tipos representam uma API de uso geral para criar, acessar e manipular instruções vetoriais sempre que possível. Eles também fornecem compatibilidade de software para os casos em que o hardware não suporta instruções adequadas. Isso permitiu, com refatoração mínima, vetorizar vários algoritmos. Seja como for, a generalidade dessa abordagem dificulta a aplicação para obter todas as vantagens de todas as instruções vetoriais disponíveis, em hardware moderno. Além disso, o hardware moderno fornece várias instruções especializadas, não vetoriais, que podem melhorar significativamente o desempenho. Neste artigo, falarei sobre como contornamos essas limitações no .NET Core 3.0.

Nota: Ainda não existe um termo estabelecido para a tradução Intrisics . No final do artigo, há um voto para a opção de tradução. Se escolhermos uma boa opção, mudaremos o artigo
Quais são as funções incorporadas
No .NET Core 3.0, adicionamos novas funcionalidades chamadas funções internas específicas do hardware (WF remoto). Essa funcionalidade fornece acesso a muitas instruções específicas de hardware que não podem ser simplesmente representadas por mecanismos de uso geral. Eles diferem das instruções SIMD existentes por não terem uma finalidade geral (os novos WFs não são multiplataforma e sua arquitetura não fornece compatibilidade de software). Em vez disso, eles fornecem diretamente funcionalidade específica de plataforma e hardware para desenvolvedores .NET. As funções SIMD existentes, por exemplo, multiplataforma, oferecem compatibilidade de software e são um pouco abstraídas do hardware subjacente. Essa abstração pode ser cara, além disso, pode impedir a divulgação de algumas funcionalidades (quando, por exemplo, a funcionalidade não existe ou é difícil de emular em todas as plataformas de destino).
Novas funções internas e tipos suportados estão localizados no System.Runtime.Intrinsics . Para o .NET Core 3.0, no momento, há um System.Runtime.Intrinsics.X86 . Estamos trabalhando no suporte de funções internas para outras plataformas, como System.Runtime.Intrinsics.Arm .
Em espaços de nome específicos da plataforma, os WFs são agrupados em classes que representam grupos de instruções de hardware integradas de maneira lógica (geralmente chamadas de arquitetura de conjunto de instruções (ISA)). Cada classe fornece uma propriedade IsSupported indica se o hardware no qual o código está executando suporta este conjunto de instruções. Além disso, cada uma dessas classes contém um conjunto de métodos mapeados para um conjunto correspondente de instruções. Às vezes, há uma subclasse adicional que corresponde a uma parte do mesmo conjunto de instruções, que pode ser limitada (suportada) por hardware específico. Por exemplo, a classe Lzcnt fornece acesso a instruções para contar zeros à esquerda . Ele tem uma subclasse chamada X64 , que contém o formato dessas instruções usadas apenas em máquinas com arquitetura de 64 bits.
Algumas dessas classes são naturalmente de natureza hierárquica. Por exemplo, se Lzcnt.X64.IsSupported retornar true, Lzcnt.IsSupported também deverá retornar true, pois essa é uma subclasse explícita. Ou, por exemplo, se Sse2.IsSupported retornar true, Sse.IsSupported deverá retornar true, porque o Sse2 herda explicitamente do Sse . No entanto, vale ressaltar que a semelhança dos nomes de classe não é um indicador de que eles pertencem à mesma hierarquia de herança. Por exemplo, o Bmi2 não Bmi2 herdado do Bmi1 , portanto, os valores retornados pelo IsSupported para esses dois conjuntos de instruções serão diferentes. O princípio fundamental no desenvolvimento dessas classes foi a apresentação explícita das especificações ISA. O SSE2 requer suporte para o SSE1, portanto, as classes que os representam são relacionadas por herança. Ao mesmo tempo, o IMC2 não requer suporte para o IMC1, portanto, não usamos herança. A seguir, é apresentado um exemplo da API acima.
namespace System.Runtime.Intrinsics.X86 { public abstract class Sse { public static bool IsSupported { get; } public static Vector128<float> Add(Vector128<float> left, Vector128<float> right); // Additional APIs public abstract class X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<float> value); // Additional APIs } } public abstract class Sse2 : Sse { public static new bool IsSupported { get; } public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right); // Additional APIs public new abstract class X64 : Sse.X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<double> value); // Additional APIs } } }
Você pode ver mais no código-fonte nos seguintes links source.dot.net ou dotnet / coreclr no GitHub
IsSupported verificações IsSupported processadas pelo compilador JIT como constantes de tempo de execução (quando a otimização está ativada); portanto, você não precisa de compilação cruzada para suportar vários ISAs, plataformas ou arquiteturas. Em vez disso, basta escrever o código usando expressões if , como resultado das ramificações de código não utilizadas (ou seja, aquelas ramificações que não são alcançáveis devido ao valor da variável na instrução condicional) serão descartadas quando o código nativo for gerado.
É importante que a verificação do IsSupported correspondente anteceda o uso dos comandos de hardware embutidos. Se não houver essa verificação, o código que usa comandos específicos da plataforma em execução nas plataformas / arquiteturas onde esses comandos não são suportados lançará uma exceção de tempo de execução PlatformNotSupportedException .
Quais benefícios eles oferecem?
Obviamente, funções internas específicas de hardware não são para todos, mas podem ser usadas para melhorar o desempenho em operações carregadas com cálculos. CoreFX ML.NET CoreFX e ML.NET usam esses métodos para acelerar operações como copiar na memória, pesquisar o índice de um elemento em uma matriz ou string, redimensionar uma imagem ou trabalhar com vetores / matrizes / tensores. A vetorização manual de algum código que acabou sendo um gargalo também pode ser mais simples do que parece. A vetorização do código, de fato, é executar várias operações por vez, em geral, usando instruções SIMD (um fluxo de instruções, fluxo de dados múltiplo).
Antes de decidir vetorizar algum código, é necessário executar a criação de perfil para garantir que esse código seja realmente parte do "hot spot" (e, portanto, sua otimização dará um aumento significativo no desempenho). Também é importante realizar a criação de perfil em cada estágio da vetorização, pois a vetorização de nem todo o código leva ao aumento da produtividade.
Vetorização de um algoritmo simples
Para ilustrar o uso de funções internas, adotamos o algoritmo para somar todos os elementos de uma matriz ou intervalo. Esse tipo de código é um candidato ideal para vetorização, porque a cada iteração, a mesma operação trivial é executada.
Um exemplo de implementação de um algoritmo desse tipo pode ser da seguinte maneira:
public int Sum(ReadOnlySpan<int> source) { int result = 0; for (int i = 0; i < source.Length; i++) { result += source[i]; } return result; }
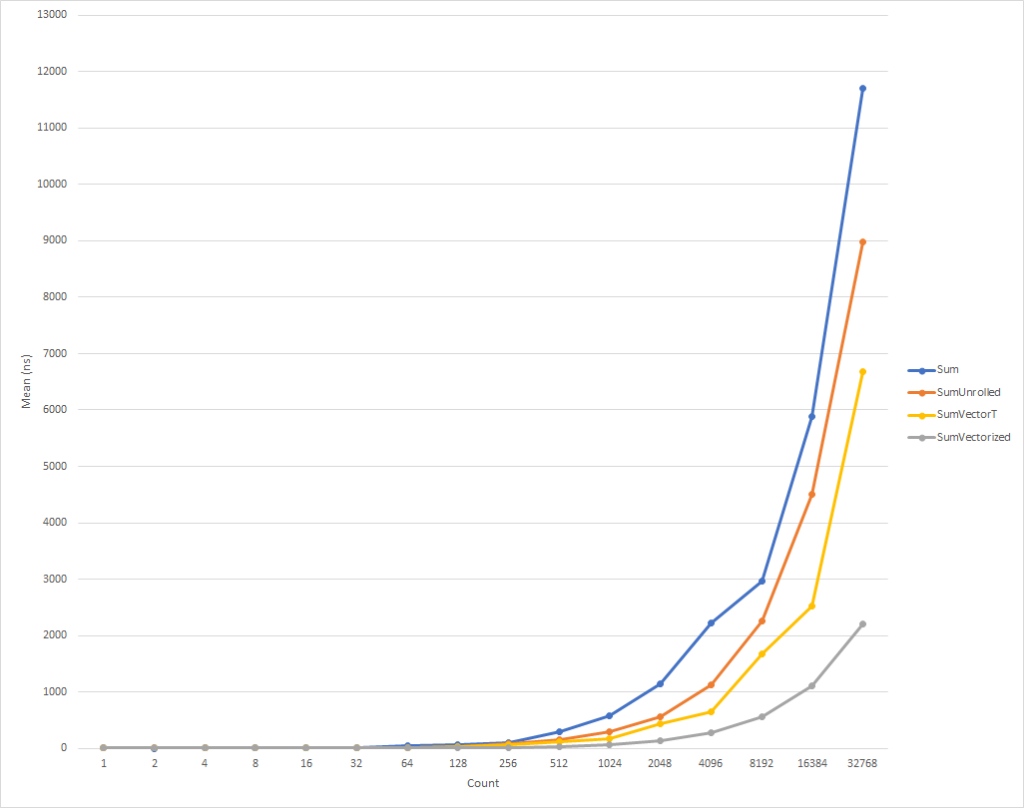
Esse código é bastante simples e direto, mas ao mesmo tempo lento o suficiente para grandes dados de entrada, como faz apenas uma operação trivial por iteração.
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362 AMD Ryzen 7 1800X, 1 CPU, 16 logical and 8 physical cores .NET Core SDK=3.0.100-preview9-013775 [Host] : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT [AttachedDebugger] DefaultJob : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT
Aumente a produtividade através de ciclos de implantação
Os processadores modernos têm várias opções para melhorar o desempenho do código. Para aplicativos de encadeamento único, uma dessas opções é executar várias operações primitivas em um único ciclo do processador.
A maioria dos processadores modernos pode executar quatro operações adicionais em um ciclo de clock (em condições ideais), como resultado, com o "layout" correto do código, às vezes você pode melhorar o desempenho, mesmo em uma implementação de thread único.
Embora o JIT possa executar o desenrolamento de loop por conta própria, o JIT é conservador ao tomar esse tipo de decisão, devido ao tamanho do código gerado. Portanto, pode ser vantajoso implantar um loop, no código, manualmente.
Você pode expandir o loop no código acima da seguinte maneira:
public unsafe int SumUnrolled(ReadOnlySpan<int> source) { int result = 0; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); // Pin source so we can elide the bounds checks fixed (int* pSource = source) { while (i < lastBlockIndex) { result += pSource[i + 0]; result += pSource[i + 1]; result += pSource[i + 2]; result += pSource[i + 3]; i += 4; } while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
Esse código é um pouco mais complicado, mas faz melhor uso dos recursos de hardware.
Para loops realmente pequenos, esse código é um pouco mais lento. Mas essa tendência já está mudando para dados de entrada de oito elementos, após os quais a velocidade de execução começa a aumentar (o tempo de execução do código otimizado, para 32 mil elementos, é 26% menor que o tempo da versão original). Vale ressaltar que essa otimização nem sempre aumenta a produtividade. Por exemplo, ao trabalhar com coleções com elementos do tipo float versão "implantada" do algoritmo tem quase a mesma velocidade que a original. Portanto, é muito importante realizar a criação de perfil.

Aumente a produtividade através da vetorização de loop
Seja como for, mas ainda podemos otimizar ligeiramente esse código. As instruções SIMD são outra opção fornecida pelos processadores modernos para melhorar o desempenho. Usando uma única instrução, eles permitem executar várias operações em um único ciclo de relógio. Isso pode ser melhor do que o desdobramento direto do loop, porque, de fato, é feito o mesmo, mas com uma quantidade menor de código gerado.
Para esclarecer, cada operação de adição, em um ciclo implantado, leva 4 bytes. Portanto, precisamos de 16 bytes para 4 operações de adição na forma expandida. Ao mesmo tempo, a instrução de adição SIMD também realiza 4 operações de adição, mas leva apenas 4 bytes. Isso significa que temos menos instruções para a CPU. Além disso, no caso de uma instrução SIMD, a CPU pode fazer suposições e executar otimizações, mas isso está além do escopo deste artigo. O que é ainda melhor é que os processadores modernos podem executar mais de uma instrução SIMD por vez, ou seja, em alguns casos, você pode aplicar uma estratégia mista, ao mesmo tempo em que executa uma varredura e vetorização de ciclo parcial.
Em geral, você precisa começar observando a classe de uso geral Vector<T> para suas tarefas. Ele, como os novos WFs , incorporará instruções SIMD, mas, ao mesmo tempo, dada a versatilidade dessa classe, ele pode reduzir o número de codificação "manual".
O código pode ficar assim:
public int SumVectorT(ReadOnlySpan<int> source) { int result = 0; Vector<int> vresult = Vector<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % Vector<int>.Count); while (i < lastBlockIndex) { vresult += new Vector<int>(source.Slice(i)); i += Vector<int>.Count; } for (int n = 0; n < Vector<int>.Count; n++) { result += vresult[n]; } while (i < source.Length) { result += source[i]; i += 1; } return result; }
Esse código funciona mais rápido, mas somos forçados a nos referir a cada elemento separadamente ao calcular o valor final. Além disso, o Vector<T> não possui um tamanho definido com precisão e pode variar, dependendo do equipamento no qual o código está sendo executado. as funções internas específicas do hardware fornecem funcionalidade adicional que pode melhorar um pouco esse código e torná-lo um pouco mais rápido (ao custo de complexidade adicional de código e requisitos de manutenção).

OBSERVAÇÃO Para este artigo, fiz com força o tamanho do Vector<T> igual a 16 bytes usando o parâmetro de configuração interno ( COMPlus_SIMD16ByteOnly=1 ). Esse ajuste normalizou os resultados ao comparar SumVectorT com SumVectorizedSse e nos permitiu manter o código simples. Em particular, evitou gravar um salto condicional if (Avx2.IsSupported) { } . Esse código é quase idêntico ao do Sse2 , mas lida com o Vector256<T> (32 bytes) e processa ainda mais elementos em uma iteração do loop.
Assim, usando as novas funções internas , o código pode ser reescrito da seguinte maneira:
public int SumVectorized(ReadOnlySpan<int> source) { if (Sse2.IsSupported) { return SumVectorizedSse2(source); } else { return SumVectorT(source); } } public unsafe int SumVectorizedSse2(ReadOnlySpan<int> source) { int result; fixed (int* pSource = source) { Vector128<int> vresult = Vector128<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); while (i < lastBlockIndex) { vresult = Sse2.Add(vresult, Sse2.LoadVector128(pSource + i)); i += 4; } if (Ssse3.IsSupported) { vresult = Ssse3.HorizontalAdd(vresult, vresult); vresult = Ssse3.HorizontalAdd(vresult, vresult); } else { vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0x4E)); vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0xB1)); } result = vresult.ToScalar(); while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
Esse código, novamente, é um pouco mais complicado, mas é significativamente mais rápido para todos, exceto os menores conjuntos de entradas. Para 32 mil elementos, esse código executa 75% mais rápido que o ciclo expandido e 81% mais rápido que o código-fonte do exemplo.
Você notou que escrevemos alguns cheques IsSupported . O primeiro verifica se o hardware atual suporta o conjunto necessário de funções internas ; caso contrário, a otimização é realizada por meio de uma combinação de varredura e Vector<T> . A última opção será selecionada para plataformas como ARM / ARM64 que não suportam o conjunto de instruções necessário ou se o conjunto foi desativado para a plataforma. O segundo teste IsSupported , no método SumVectorizedSse2 , é usado para otimização adicional se o hardware suportar o Ssse3 instruções Ssse3 .
Caso contrário, a maior parte da lógica é essencialmente a mesma do loop expandido. Vector128<T> é um tipo de 128 bits que contém os elementos Vector128<T>.Count . Nesse caso, o uint , que é de 32 bits, pode ter 4 elementos (128/32), foi assim que lançamos o loop.
Conclusão
As novas funções integradas oferecem a oportunidade de aproveitar a funcionalidade específica de hardware da máquina na qual você executa o código. Existem aproximadamente 1.500 APIs para X86 e X64 distribuídas em 15 conjuntos; há muitas para descrever em um artigo. Ao criar um perfil do código para identificar gargalos, é possível determinar a parte do código que se beneficia da vetorização e observar um aumento de desempenho bastante bom. Existem muitos cenários em que a vetorização pode ser aplicada e o desdobramento do loop é apenas o começo.
Qualquer pessoa que queira ver mais exemplos pode procurar o uso de funções internas na estrutura (consulte dotnet e aspnet ) ou em outros artigos da comunidade. E embora os WFs atuais sejam vastos, ainda há muitas funcionalidades que precisam ser introduzidas. Se você tem a funcionalidade que deseja apresentar, sinta-se à vontade para registrar sua solicitação de API via dotnet / corefx no GitHub . O processo de revisão da API é descrito aqui e há um bom exemplo de um modelo de solicitação de API especificado na etapa 1.
Agradecimentos especiais
Gostaria de expressar uma gratidão especial aos membros da nossa comunidade Fei Peng (@fiigii) e Jacek Blaszczynski (@ 4creators) por sua ajuda na implementação do WF , bem como a todos os membros da comunidade por comentários valiosos sobre o desenvolvimento, implementação e facilidade de uso dessa funcionalidade.
Posfácio à tradução
Eu gosto de observar o desenvolvimento da plataforma .NET e, em particular, a linguagem C #. Vindo do mundo do C ++, e tendo pouca experiência em desenvolvimento em Delphi e Java, fiquei muito confortável em começar a escrever programas em C #. Em 2006, essa linguagem de programação (a própria linguagem) me pareceu mais concisa e prática do que Java no mundo da coleta de lixo gerenciada e da plataforma cruzada. Portanto, minha escolha caiu em C # e não me arrependi. O primeiro estágio na evolução de uma língua foi simplesmente sua aparência. Em 2006, o C # absorveu o melhor da época nas melhores linguagens e plataformas: C ++ / Java / Delphi. Em 2010, o F # tornou-se público. Era uma plataforma experimental para estudar o paradigma funcional com o objetivo de introduzi-lo no mundo do .NET. O resultado dos experimentos foi o próximo estágio na evolução do C # - a expansão de suas capacidades para o FP, através da introdução de funções anônimas, expressões lambda e, finalmente, LINQ. Essa extensão da linguagem fez do C # a linguagem de propósito geral mais avançada, do meu ponto de vista. O próximo passo evolutivo foi relacionado ao apoio à simultaneidade e assincronia. Tarefa / Tarefa <T>, todo o conceito de TPL, o desenvolvimento de LINQ - PLINQ e, finalmente, assíncrono / aguardam. , - , .NET C# — . Span<T> Memory<T>, ValueTask/ValueTask<T>, IAsyncDispose, ref readonly struct in, foreach, IO.Streams. GC . , — . , .NET C#, , . ( ) .