O artigo anterior analisou a arquitetura de uma rede virtualizada, underlay overlay, o caminho do pacote entre VMs e muito mais.
Roman Gorge foi inspirado por ela e decidiu escrever um problema de revisão sobre virtualização em geral.
Neste artigo, abordaremos (ou tentaremos abordar) as perguntas: como a virtualização das funções de rede realmente ocorre, como o back-end dos principais produtos para iniciar e gerenciar VMs é implementado e como a comutação virtual funciona (ponte OVS e Linux).
O tópico da virtualização é amplo e profundo, é impossível explicar todos os detalhes do trabalho do hypervisor (e não é necessário). Nós nos limitaremos ao conjunto mínimo de conhecimentos necessário para entender a operação de qualquer solução virtualizada, não necessariamente a Telco.

Conteúdo
- Introdução e uma breve história da virtualização
- Tipos de recursos virtuais - computação, armazenamento, rede
- Comutação virtual
- Ferramentas de virtualização - libvirt, virsh e mais
- Conclusão
Introdução e uma breve história da virtualização
A história das modernas tecnologias de virtualização data de 1999, quando a jovem empresa VMware lançou um produto chamado VMware Workstation. Este era um produto de virtualização para aplicativos de desktop / cliente. A virtualização do servidor veio um pouco mais tarde na forma do produto ESX Server, que depois evoluiu para o ESXi (ou seja, integrado) - este é o mesmo produto que é usado universalmente na TI e na Telco como um hipervisor de aplicativo para servidor.
No lado Opensource, dois grandes projetos trouxeram virtualização para o Linux:
- KVM (Máquina Virtual Baseada em Kernel) é um módulo do kernel do Linux que permite que o kernel funcione como um hypervisor (cria a infraestrutura necessária para iniciar e gerenciar VMs). Foi adicionado na versão 2.6.20 do kernel em 2007.
- QEMU (Quick Emulator) - emula diretamente o hardware de uma máquina virtual (CPU, disco, RAM, qualquer coisa, incluindo uma porta USB) e é usado em conjunto com o KVM para obter um desempenho quase "nativo".
De fato, no momento, toda a funcionalidade do KVM está disponível no QEMU, mas isso não é importante, pois a maioria dos usuários de virtualização Linux não usa diretamente o KVM / QEMU, mas os acessa por pelo menos um nível de abstração, mas mais tarde.
Hoje, o VMware ESXi e o Linux QEMU / KVM são os dois principais hipervisores que dominam o mercado. Eles também são representantes de dois tipos diferentes de hipervisores:
- Tipo 1 - o hipervisor é executado diretamente no hardware (bare-metal). Este é VMware ESXi, Linux KVM, Hyper-V
- Tipo 2 - o hypervisor é iniciado dentro do SO Host (sistema operacional). Esta é a VMware Workstation ou Oracle VirtualBox.
Uma discussão sobre o que é melhor e o que é pior está além do escopo deste artigo.

Os produtores de ferro também tiveram que fazer sua parte para garantir um desempenho aceitável.
Talvez o mais importante e mais usado seja o Intel VT (Virtualization Technology) - um conjunto de extensões desenvolvido pela Intel para seus processadores x86 que são usados para a operação efetiva do hipervisor (e, em alguns casos, são necessários, por exemplo, o KVM não funcionará sem o VT ativado -x e sem ele, o hipervisor é forçado a se envolver em emulação puramente de software, sem aceleração de hardware).
Duas dessas extensões são mais conhecidas - VT-x e VT-d. O primeiro é importante para melhorar o desempenho da CPU durante a virtualização, pois fornece suporte de hardware para algumas de suas funções (com o código VT-x 99,9% de SO convidado é executado diretamente no processador físico, produzindo saídas para emulação apenas nos casos mais necessários), o segundo é para conectar dispositivos físicos diretamente para uma máquina virtual (para funções virtuais de encaminhamento (VF) SRIOV, por exemplo, o VT-d
deve estar ativado ).
O próximo conceito importante é a diferença entre virtualização completa e para-virtualização.
A virtualização completa é boa, pois permite executar qualquer sistema operacional em qualquer processador; no entanto, é extremamente ineficiente e absolutamente inadequado para sistemas altamente carregados.
Para-virtualização, em resumo, é quando o SO convidado entende que está sendo executado em um ambiente virtual e coopera com o hipervisor para obter maior eficiência. Ou seja, a interface guest-hypervisor é exibida.
A grande maioria dos sistemas operacionais usados hoje tem suporte para para-virtualização - no kernel do Linux, isso apareceu desde a versão 2.6.20 do kernel.
Para que uma máquina virtual funcione, não são necessários apenas um processador virtual (vCPU) e memória virtual (RAM); também é necessária a emulação de dispositivos PCI. Na verdade, é necessário um conjunto de drivers para gerenciar interfaces de rede virtual, discos e assim por diante.
No hypervisor KVM do Linux, essa tarefa foi resolvida implementando o
virtio , uma estrutura para desenvolver e usar dispositivos de E / S virtualizados.
O Virtio é um nível adicional de abstração, que permite emular vários dispositivos de E / S em um hypervisor para-virtualizado, fornecendo uma interface unificada e padronizada para o lado da máquina virtual. Isso permite reutilizar o código do driver virtio para vários dispositivos inerentes. Virtio consiste em:
- Driver front-end - o que há na máquina virtual
- Driver de backend - o que há no hypervisor
- Driver de transporte - o que conecta o back-end e o front-end
Essa modularidade permite alterar as tecnologias usadas no hipervisor sem afetar os drivers na máquina virtual (esse momento é muito importante para as tecnologias de aceleração de rede e soluções em nuvem em geral, mas mais sobre isso posteriormente).
Ou seja, existe uma conexão convidado-hipervisor quando o SO convidado "sabe" que está sendo executado em um ambiente virtual.
Se você alguma vez escreveu uma pergunta na RFP ou respondeu a uma pergunta na RFP "O virtio é suportado no seu produto?" Era apenas para dar suporte ao driver virtio do front-end.
Tipos de recursos virtuais - computação, armazenamento, rede
Em que consiste uma máquina virtual?
Existem três tipos principais de recursos virtuais:
- computação - processador e RAM
- storage - disco do sistema da máquina virtual e armazenamento em bloco
- rede - placas de rede e dispositivos de entrada / saída
Computar
CPU
Teoricamente, o QEMU é capaz de emular qualquer tipo de processador e seus sinalizadores e funcionalidades correspondentes; na prática, eles usam o modelo de host e desativam os sinalizadores no sentido horário antes de transferi-los para o SO convidado, ou usam o modelo nomeado e ativam / desativam sinalizadores no sentido horário.
Por padrão, o QEMU emulará um processador que o SO convidado reconhecerá como CPU virtual do QEMU. Esse não é o tipo mais ideal de processador, especialmente se um aplicativo em execução em uma máquina virtual usa sinalizadores de CPU para seu trabalho.
Saiba mais sobre os diferentes modelos de CPU no QEMU .
O QEMU / KVM também permite controlar a topologia do processador, o número de threads, o tamanho do cache, vincular a vCPU ao núcleo físico e muito mais.
Se isso é necessário para uma máquina virtual ou não, depende do tipo de aplicativo em execução no SO convidado. Por exemplo, é um fato bem conhecido que, para aplicativos que processam pacotes com alto PPS, é importante fazer a
fixação da CPU , ou seja, para não permitir que o processador físico seja transferido para outras máquinas virtuais.
Memória
O próximo na fila é a RAM. Do ponto de vista do Host OS, uma máquina virtual lançada usando QEMU / KVM não é diferente de nenhum outro processo em execução no espaço do usuário do sistema operacional. Assim, o processo de alocação de memória para uma máquina virtual é realizado pelas mesmas chamadas no SO do kernel, como se você tivesse lançado, por exemplo, um navegador Chrome.
Antes de continuar a história da RAM em máquinas virtuais, você precisa discernir e explicar o termo NUMA - Acesso não uniforme à memória.
A arquitetura dos servidores físicos modernos envolve a presença de dois ou mais processadores (CPU) e associados a ela (RAM). Um monte de processador + memória é chamado de nó ou nó. A comunicação entre vários nós NUMA é realizada através de um barramento especial - QPI (QuickPath Interconnect)
O nó NUMA local é alocado - quando o processo em execução no sistema operacional usa o processador e a RAM localizados no mesmo nó NUMA e o nó NUMA remoto - quando o processo em execução no sistema operacional usa o processador e a RAM localizados em diferentes nós da NUMA, isto é, para a interação do processador e da memória, é necessária a transferência de dados através do barramento QPI.
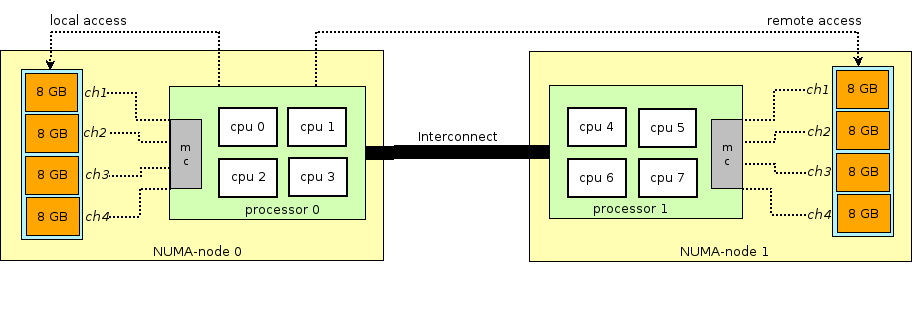
Do ponto de vista da máquina virtual, a memória já estava alocada para ela no momento do seu lançamento, mas, na realidade, não é assim, e o Host OS do kernel aloca novas seções de memória para o processo QEMU / KVM, pois o aplicativo no SO convidado solicita memória adicional (embora também possa haver uma exceção se você especificar diretamente QEMU / KVM para alocar toda a memória para a máquina virtual diretamente na inicialização).
A memória é alocada não byte a byte, mas com um determinado tamanho -
página . O tamanho da página é configurável e, teoricamente, pode ser qualquer, mas, na prática, o tamanho é de 4kB (padrão), 2MB e 1GB. Os dois últimos tamanhos são chamados de
HugePages e geralmente são usados para alocar memória para máquinas virtuais que consomem
muita memória. O motivo para usar o HugePages no processo de encontrar uma correspondência entre o endereço virtual da página e a memória física no
Translation Lookaside Buffer (
TLB ), que por sua vez é limitado e armazena informações apenas sobre as últimas páginas usadas. Se não houver informações sobre a página desejada no TLB, ocorrerá um processo chamado
miss TLB e você precisará usar o processador Host OS para encontrar a célula de memória física correspondente à página desejada.
Esse processo é ineficiente e lento, portanto, menos páginas de tamanho maior são usadas.
O QEMU / KVM também permite emular várias topologias NUMA para SO convidado, recuperar memória para uma máquina virtual apenas de um SO Host de nó NUMA específico e assim por diante. A prática mais comum é levar a memória para uma máquina virtual de um nó NUMA local para os processadores alocados à máquina virtual. O motivo é o desejo de evitar carga desnecessária no barramento
QPI que conecta os soquetes da CPU do servidor físico (é claro, isso é lógico se o servidor tiver 2 ou mais soquetes).
Armazenamento
Como você sabe, a RAM é chamada de memória operacional porque seu conteúdo desaparece quando a energia é desligada ou o sistema operacional é reiniciado. Para armazenar informações, você precisa de um dispositivo de armazenamento persistente (ROM) ou
armazenamento persistente .
Existem dois tipos principais de armazenamento persistente:
- Armazenamento em bloco - um bloco de espaço em disco que pode ser usado para instalar o sistema de arquivos e criar partições. Se for grosseiro, você poderá considerá-lo um disco comum.
- Armazenamento de objetos - as informações podem ser salvas apenas como um objeto (arquivo), acessível via HTTP / HTTPS. Exemplos típicos de armazenamento de objetos são o AWS S3 ou o Dropbox.
A máquina virtual precisa de
armazenamento persistente ; no entanto, como fazer isso se a máquina virtual "viver" na RAM do sistema operacional host? Em resumo, qualquer chamada do SO convidado para o controlador de disco virtual é interceptada pelo QEMU / KVM e transformada em um registro no disco físico do SO host. Esse método é ineficiente e, portanto, aqui, assim como para dispositivos de rede, o driver virtio é usado em vez de emular totalmente um dispositivo IDE ou iSCSI. Leia mais sobre isso
aqui . Assim, a máquina virtual acessa seu disco virtual através de um driver virtio e, em seguida, o QEMU / KVM faz com que as informações transferidas sejam gravadas no disco físico. É importante entender que, no host OS, um back-end de disco pode ser implementado como uma prateleira CEPH, NFS ou iSCSI.
A maneira mais fácil de emular o armazenamento persistente é usar o arquivo em algum diretório do Host OS como espaço em disco de uma máquina virtual. O QEMU / KVM suporta muitos formatos diferentes desse tipo de arquivo - raw, vdi, vmdk e outros. No entanto, o formato mais utilizado é o
qcow2 (versão 2 do QEMU copy-on-write). Em geral, qcow2 é um arquivo estruturado de uma certa maneira, sem qualquer sistema operacional. Um grande número de máquinas virtuais é distribuído na forma de qcow2-images (images) e é uma cópia do disco do sistema de uma máquina virtual, compactada no formato qcow2. Isso tem várias vantagens - a codificação qcow2 ocupa muito menos espaço do que uma cópia não processada de um disco de bytes em bytes, o QEMU / KVM pode redimensionar um arquivo qcow2, o que significa que é possível alterar o tamanho do disco de uma máquina virtual, a criptografia AES qcow2 também é suportada (isso faz sentido, pois a imagem de uma máquina virtual pode conter propriedade intelectual).
Além disso, quando a máquina virtual é iniciada, o QEMU / KVM usa o arquivo qcow2 como um disco do sistema (eu omito o processo de carregar a máquina virtual aqui, embora isso também seja uma tarefa interessante), e a máquina virtual tem a capacidade de ler / gravar dados no arquivo qcow2 via virtio motorista. Assim, o processo de captura de imagens de máquinas virtuais funciona, pois a qualquer momento o arquivo qcow2 contém uma cópia completa do disco do sistema da máquina virtual e a imagem pode ser usada para backup, transferência para outro host e muito mais.
Em geral, esse arquivo qcow2 será definido no SO convidado como um
dispositivo / dev / vda , e o SO convidado particionará o espaço em disco em partições e instalará o sistema de arquivos. Da mesma forma, os seguintes arquivos qcow2 conectados pelo QEMU / KVM como
dispositivos / dev / vdX podem ser usados como
armazenamento em
bloco em uma máquina virtual para armazenar informações (é exatamente assim que o componente Openstack Cinder funciona).
Rede
Os últimos da nossa lista de recursos virtuais são placas de rede e dispositivos de E / S. Uma máquina virtual, como um host físico, precisa de um
barramento PCI / PCIe para conectar dispositivos de E / S. O QEMU / KVM pode emular diferentes tipos de chipsets - q35 ou i440fx (o primeiro suporta PCIe, o segundo suporta PCI herdado), bem como várias topologias PCI, por exemplo, criam barramentos PCI separados (barramento expansor PCI) para os nós NUMA Guest OS.
Após criar o barramento PCI / PCIe, você deve conectar um dispositivo de E / S a ele. Em geral, pode ser qualquer coisa, de uma placa de rede a uma GPU física. E, é claro, uma placa de rede, totalmente virtualizada (interface e1000 totalmente virtualizada, por exemplo) e para-virtualizada (virtio, por exemplo) ou uma NIC física. A última opção é usada para máquinas virtuais de plano de dados em que você precisa obter taxas de pacotes com taxa de linha - roteadores, firewalls etc.
Existem duas abordagens principais aqui -
passagem de PCI e
SR-IOV . A principal diferença entre eles é que, para o PCI-PT, o driver é usado apenas dentro do SO convidado, e para o SRIOV, o driver SO host (para criar
VF - Funções Virtuais ) e o driver SO convidado são usados para controlar o SR-IOV VF.
Juniper escreveu excelentes detalhes sobre PCI-PT e SRIOV.

Para esclarecimento, vale ressaltar que a passagem do PCI e o SR-IOV são tecnologias complementares. O SR-IOV está dividindo uma função física em funções virtuais. Isso é feito no nível do sistema operacional host. Ao mesmo tempo, o Host OS vê as funções virtuais como outro dispositivo PCI / PCIe. O que ele faz a seguir com eles não é importante.
E o PCI-PT é um mecanismo para encaminhar qualquer dispositivo PCI do sistema operacional host no sistema operacional convidado, incluindo a função virtual criada pelo dispositivo SR-IOV
Assim, examinamos os principais tipos de recursos virtuais e o próximo passo é entender como a máquina virtual se comunica com o mundo externo por meio de uma rede.
Comutação virtual
Se houver uma máquina virtual e houver uma interface virtual nela, é óbvio que surge o problema de transferir um pacote de uma VM para outra. Nos hipervisores baseados em Linux (KVM, por exemplo), esse problema pode ser resolvido usando a ponte Linux; no entanto, o projeto
Open vSwitch (OVS) ganhou ampla aceitação.
Existem várias funcionalidades principais que permitiram que o OVS se espalhasse amplamente e se tornasse o método de troca de pacotes primário de fato usado em muitas plataformas de computação em nuvem (como Openstack) e soluções virtualizadas.
- Transferência de estado da rede - ao migrar uma VM entre hipervisores, surge a tarefa de transferir ACLs, QoSs, tabelas de encaminhamento L2 / L3 e muito mais. E o OVS pode fazer isso.
- Implementação do mecanismo de transferência de pacotes (caminho de dados) no kernel e no espaço do usuário
- Arquitetura CUPS (separação de controle / plano de usuário) - permite transferir a funcionalidade do processamento de pacotes para um chipset especializado (o chipset Broadcom e Marvell, por exemplo, pode fazer isso), controlando-o através do OVS do plano de controle.
- Suporte para métodos de controle remoto de tráfego - protocolo OpenFlow (oi, SDN).
A arquitetura OVS à primeira vista parece bastante assustadora, mas é apenas à primeira vista.
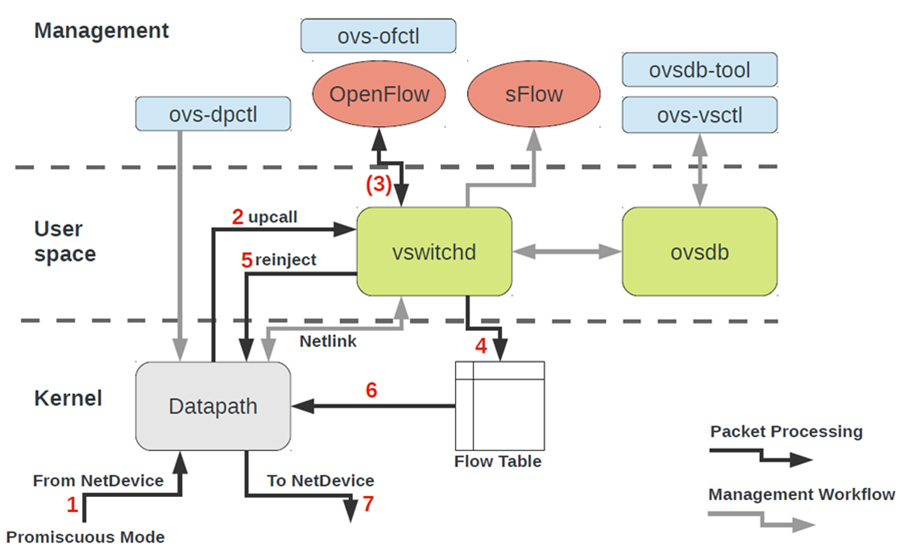
Para trabalhar com o OVS, você precisa entender o seguinte:
- Datapath - pacotes são processados aqui. A analogia é o tecido de um interruptor de ferro. O Datapath inclui pacotes de recebimento, processamento de cabeçalhos, correspondências correspondentes na tabela de fluxo, que já está programada no Datapath. Se o OVS for executado no kernel, ele será implementado como um módulo do kernel. Se o OVS for executado no espaço do usuário, esse é um processo no Linux do espaço do usuário.
- vswitchd e ovsdb são daemons no espaço do usuário, que implementa diretamente a funcionalidade do comutador, armazena a configuração, define o fluxo para o caminho de dados e o programa.
- Kit de ferramentas de configuração e solução de problemas do OVS - ovs-vsctl, ovs-dpctl, ovs-ofctl, ovs-appctl . Tudo o que é necessário para registrar a configuração da porta no ovsdb, registrar para qual fluxo deve ser alternado, coletar estatísticas e assim por diante. Boas pessoas escreveram um artigo sobre isso.
Como o dispositivo de rede de uma máquina virtual acaba no OVS?Para resolver esse problema, precisamos interconectar de alguma forma a interface virtual localizada no espaço do usuário do sistema operacional com o caminho de dados OVS localizado no kernel.
No sistema operacional Linux, os pacotes são transferidos entre os processos do kernel e do espaço do usuário por meio de duas interfaces especiais.
Ambas as interfaces usam a gravação / leitura de um pacote para / de um arquivo especial para transferir pacotes do processo de espaço do usuário para o kernel e vice-versa - descritor de arquivo (FD) (esse é um dos motivos para um desempenho ruim de comutação virtual se o caminho de dados OVS estiver no kernel - cada pacote precisa escrever / ler o FD)- TUN (túnel) - um dispositivo que funciona no modo L3 e permite gravar / ler apenas pacotes IP de / para o FD.
- TAP (toque na rede) - o mesmo que a interface tun + pode executar operações com quadros Ethernet, ou seja, trabalhar no modo L2.
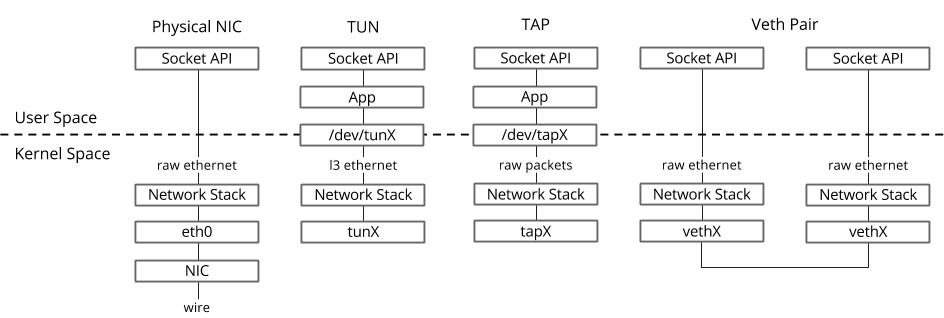
Host OS TAP-
ip link ifconfig — «» virtio, «» kernel Host OS. , TAP- MAC- virtio- .
TAP- OVS
ovs-vsctl — , OVS TAP-, file descriptor.
, .. OVS bridge, , OVS, .
, , , OVS bridge TAP- ovs-vsctl. .
OVS bridges, , Openstack Neutron, namespace multi-tenancy.
OVS bridges?—
veth pair . Veth pair , — , «» , «» . Veth pair OVS bridges Linux bridges. veth pair namespace Linux OS, veth pair namespace .
— libvirt, virsh
, , KVM-.
, 90 :
- libvirt
- virsh CLI
- virt-install
, CLI-, , , qemu_system_x86_64 virt manager, . Cloud-, Openstack, , libvirt.
libvirt
libvirt — open-source , . QEMU/KVM, ESXi, LXC .
— XML- API. libvirt ,
, , .
, libvirt - .
, libvirt.

libvirt — Host OS — Ubuntu, CentOS RHEL, , , libvirt . (apt, yum ).
libvirt Linux bridge virbr0 .
Ubuntu Server, , ifconfig Linux bridge virbr0 — libvirtd
Essa ponte do Linux não será conectada a nenhuma interface física; no entanto, pode ser usada para comunicar máquinas virtuais em um único hipervisor. O Libvirt certamente pode ser usado junto com o OVS, no entanto, para isso, o usuário deve criar pontes OVS de forma independente usando os comandos OVS apropriados.Qualquer recurso virtual necessário para criar uma máquina virtual (computação, rede, armazenamento) é representado como um objeto na libvirt. Um conjunto de arquivos XML diferentes é responsável pelo processo de descrição e criação desses objetos.Não faz muito sentido descrever o processo de criação de redes virtuais e armazenamentos virtuais em detalhes, pois esse aplicativo está bem descrito na documentação da libvirt:A própria máquina virtual com todos os dispositivos PCI conectados é chamada de domínio na terminologia libvirt. Este também é um objeto dentro da libvirt , que é descrito por um arquivo XML separado.Este arquivo XML é, estritamente falando, uma máquina virtual com todos os recursos virtuais - RAM, processador, dispositivos de rede, discos e muito mais. Geralmente, esse arquivo XML é chamado libvirt XML ou dump XML.É improvável que haja uma pessoa que entenda todos os parâmetros do libvirt XML, no entanto, isso não é necessário quando houver documentação., libvirt XML Ubuntu Desktop Guest OS — 40-50 . libvirt XML (NUMA-, CPU-, CPU pinning ), libvirt XML . , , libvirt XML.
virsh CLI
O utilitário virsh é uma linha de comando "nativa" para gerenciar a libvirt. Seu principal objetivo é gerenciar objetos libvirt descritos como arquivos XML. Exemplos típicos são iniciar, parar, definir, destruir e assim por diante. Ou seja, o ciclo de vida dos objetos - gerenciamento do ciclo de vida.Uma descrição de todos os comandos e sinalizadores virsh também está disponível na documentação da libvirt .virt-install
Outro utilitário usado para interagir com libvirt. Uma das principais vantagens é que você não precisa lidar com o formato XML, mas convém com os sinalizadores disponíveis no virsh-install. O segundo ponto importante é o mar de exemplos e informações na Web.Portanto, não importa qual utilitário você use, em última análise, será a libvirt que controlará o hipervisor; portanto, é importante entender a arquitetura e os princípios de sua operação.
Conclusão
Neste artigo, examinamos o conjunto mínimo de conhecimento teórico necessário para trabalhar com máquinas virtuais. Intencionalmente, não dei exemplos práticos e conclusões dos comandos, pois esses exemplos podem ser encontrados na Web e quantos você quiser, e não me propus a tarefa de escrever um “guia passo a passo”. Se você estiver interessado em um tópico ou tecnologia específica, deixe seus comentários e escreva perguntas.
Links úteis
Obrigado
- Alexander Shalimov , meu colega e especialista no desenvolvimento de redes virtuais. Para comentários e edições.
- Yevgeny Yakovlev, meu colega e especialista na área de virtualização, para comentários e correções.