
Problemas no ambiente de trabalho são sempre um desastre. Isso acontece quando você vai para casa, e o motivo sempre parece estúpido. Recentemente, ficamos sem memória nos nós do cluster Kubernetes, embora o nó tenha se recuperado imediatamente, sem interrupções visíveis. Hoje falaremos sobre este caso, sobre quais danos sofremos e como pretendemos evitar um problema semelhante no futuro.
Caso um
Sábado, 15 de junho de 2019 17:12
Blue Matador (sim, nós nos monitoramos!) Gera um alerta: um evento em um dos nós no cluster de produção Kubernetes - SystemOOM.
17:16
O Blue Matador gera um aviso: O EBS Burst Balance está baixo no volume raiz do nó - aquele em que o evento SystemOOM ocorreu. Embora um aviso sobre o Burst Balance tenha surgido após uma notificação sobre o SystemOOM, dados reais do CloudWatch mostram que o Burst Balance atingiu um nível mínimo às 17:02. O motivo do atraso é que as métricas do EBS estão constantemente 10 a 15 minutos atrasadas e nosso sistema não captura todos os eventos em tempo real.
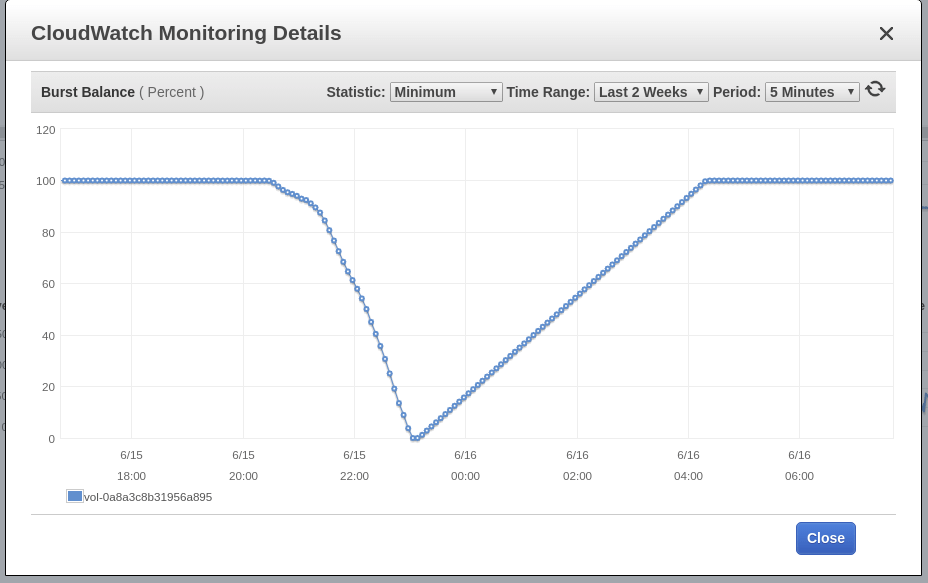
17:18
Agora eu vi um alerta e um aviso. Eu corro rapidamente os pods do kubectl get para ver o dano que sofremos e fico surpreso ao descobrir que os pods do aplicativo morreram exatamente 0. Eu executo os nós principais do kubectl , mas essa verificação também mostra que o nó suspeito tem um problema de memória; É verdade que ele já se recuperou e usa aproximadamente 60% de sua memória. São 17h e a cerveja artesanal já está esquentando. Depois de me certificar de que o nó estava operacional e que nenhum pod estava danificado, decidi que ocorreu um acidente. Se alguma coisa, eu vou descobrir na segunda-feira.
Aqui está nossa correspondência com a estação de serviço em Slack naquela noite:

Caso dois
Sábado, 16 de junho de 2019 18:02
O Blue Matador gera um alerta: o evento já está em outro nó, também SystemOOM. Deve ter sido que a estação de serviço naquele momento estava apenas olhando para a tela do smartphone, porque me escreveu e me levou a aceitar o evento imediatamente, eu mesmo não consigo ligar o computador (é hora de reinstalar o Windows novamente?). E, novamente, tudo parece normal. Nem um único pod é eliminado e o nó dificilmente consome 70% da memória.
18:06
O Blue Matador gera um aviso novamente: EBS Burst Balance. A segunda vez em um dia, o que significa que não posso liberar esse problema nos freios. Com o CloudWatch inalterado, o Burst Balance desviou-se da norma 2 horas ou mais antes do problema ser identificado.
18:11
Vou ao Datalog e olho os dados sobre o consumo de memória. Vejo isso logo antes do evento SystemOOM, o nó suspeito realmente consumiu muita memória. A trilha leva às nossas vagens fluentes e sumológicas.

Você pode ver claramente um desvio acentuado no consumo de memória, aproximadamente ao mesmo tempo em que os eventos do SystemOOM ocorreram. Minha conclusão: foram esses pods que consumiram toda a memória e, quando o SystemOOM aconteceu, o Kubernetes percebeu que esses pods poderiam ser eliminados e reiniciados para retornar a memória necessária sem afetar meus outros pods. Muito bem, Kubernetes!
Então, por que não vi isso no sábado quando descobri quais pods foram reiniciados? O fato é que eu corro vagens fluentes e sumológicas em um espaço para nome separado e com pressa não pensei em investigá-lo.
Conclusão 1: Ao procurar pods reiniciados, verifique todos os namespaces.
Depois de receber esses dados, calculei que no dia seguinte a memória em outros nós não terminaria. No entanto, fui em frente e reiniciei todos os pods sumológicos para que eles começassem a trabalhar com baixo consumo de memória. Na manhã seguinte, planejo explicar como integrar o trabalho sobre o problema em um plano para a semana e não carregar muito no domingo à noite.
23:00
Eu assisti a próxima série de "Black Mirror" (a propósito, gostei de Miley) e decidi ver como o cluster estava indo. O consumo de memória é normal, portanto, fique à vontade para deixar tudo como está para a noite.
Fix
Na segunda-feira, arrumei tempo para esse problema. Não dói caçar com ela todas as noites. O que eu sei no momento:
- Recipientes fluidos-sumológicos devoravam uma tonelada de memória;
- O evento SystemOOM é precedido por alta atividade de disco, mas não sei qual.
A princípio, pensei que os recipientes fluológicos-sumológicos são aceitos para comer memória com um repentino fluxo de toras. No entanto, após verificar o Sumologic, vi que os logs eram usados de maneira estável e, ao mesmo tempo em que havia problemas, não havia aumento nesses logs.
Um pouco pesquisando, encontrei esta tarefa no github , que sugere ajustar algumas configurações do Ruby - para reduzir o consumo de memória. Decidi tentar, adicionar uma variável de ambiente à especificação do pod e executá-la:
env: - name: RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR value: "0.9"
Examinando o manifesto fluente-sumológico, notei que não definia solicitações e restrições de recursos. Estou começando a suspeitar que a correção RUBY_GCP_HEAP fará algum tipo de milagre, então agora faz sentido definir limites de consumo de memória. Mesmo que eu não corrija o problema de memória, será pelo menos possível limitar seu consumo a esse conjunto de pods. Usando os principais pods do kubectl | grep fluentd-sumologic , já sei quantos recursos solicitar:
resources: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "250m"
Conclusão 2: defina limites de recursos, especialmente para aplicativos de terceiros.
Verificação de execução
Após alguns dias, confirmo que o método acima funciona. O consumo de memória foi estável e - sem problemas com qualquer componente do Kubernetes, EC2 e EBS. Agora está claro o quão importante é determinar solicitações e restrições de recursos para todos os pods que eu corro, e aqui está o que precisa ser feito: aplique uma combinação de limites e cotas de recursos padrão .
O último mistério não resolvido é o EBS Burst Balance, que coincidiu com o evento SystemOOM. Eu sei que quando há pouca memória, o sistema operacional usa o espaço de troca para não ficar completamente sem memória. Mas eu não nasci ontem e sei que o Kubernetes nem será iniciado nos servidores em que o arquivo de paginação está ativado. Apenas querendo ter certeza, entrei nos meus nós via SSH - para verificar se o arquivo de paginação estava ativado; Usei tanto a memória livre quanto a da área de troca. O arquivo não foi ativado.
E como a troca não está funcionando, tenho mais pistas sobre o que causou o crescimento dos fluxos de E / S, e é por isso que o nó quase ficou sem memória, não. Na verdade, tenho um palpite: o próprio pod fluente-sumológico estava escrevendo uma tonelada de mensagens de log nesse momento, possivelmente até uma mensagem de log relacionada à configuração do Ruby GC. Também é possível que existam outras fontes de Kubernetes ou mensagens de diário que se tornem excessivamente produtivas quando a memória se esgote, e eu as classifiquei enquanto configurava fluentemente. Infelizmente, não tenho mais acesso aos arquivos de log gravados imediatamente antes do mau funcionamento e agora não posso me aprofundar mais.
Conclusão 3: Enquanto houver uma oportunidade, vá mais fundo ao analisar as causas principais, qualquer que seja o problema.
Conclusão
E embora eu não tenha chegado à raiz das causas, tenho certeza de que elas não são necessárias para evitar as mesmas falhas no futuro. Tempo é dinheiro, mas estou ocupado há muito tempo e depois disso também escrevi este post para você. E como usamos o Blue Matador , essas avarias são tratadas com grande detalhe, por isso me permito liberar algo no freio, sem me distrair do projeto principal.