Habr, olá.
Este post é uma breve visão geral dos algoritmos gerais de aprendizado de máquina. Cada um é acompanhado por uma breve descrição, guias e links úteis.
Método do componente principal (PCA) / SVD
Este é um dos algoritmos básicos de aprendizado de máquina. Permite reduzir a dimensionalidade dos dados, perdendo a menor quantidade de informações. É usado em muitos campos, como reconhecimento de objetos, visão computacional, compactação de dados, etc. O cálculo dos componentes principais se reduz ao cálculo dos vetores próprios e valores próprios da matriz de covariância dos dados de origem ou à decomposição singular da matriz de dados.
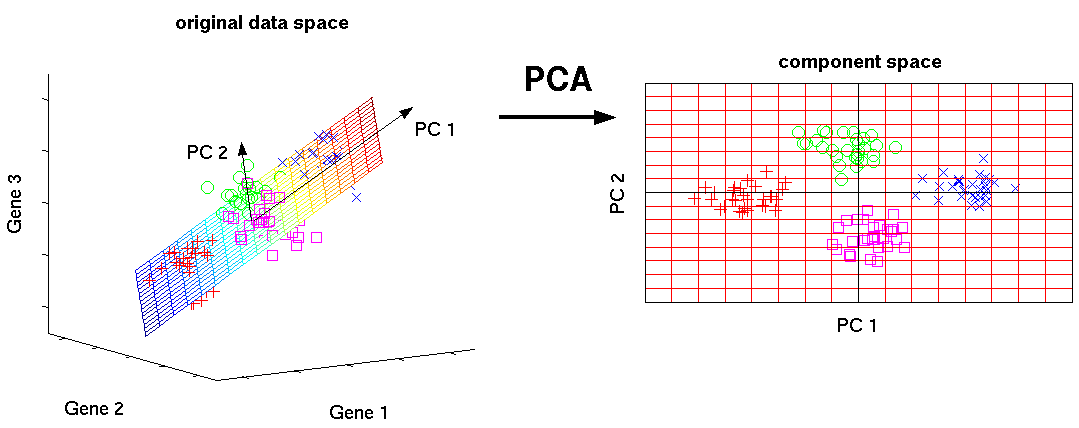
SVD é uma maneira de calcular componentes encomendados.
Links úteis:
Guia Introdutório:
Método dos mínimos quadrados
O método dos mínimos quadrados é um método matemático usado para resolver vários problemas, com base na minimização da soma dos quadrados dos desvios de algumas funções das variáveis desejadas. Pode ser usado para "resolver" sistemas de equações sobredeterminados (quando o número de equações excede o número de incógnitas), para encontrar uma solução no caso de sistemas de equações não-lineares comuns (não redefinidos) e também para aproximar os valores pontuais de uma função.
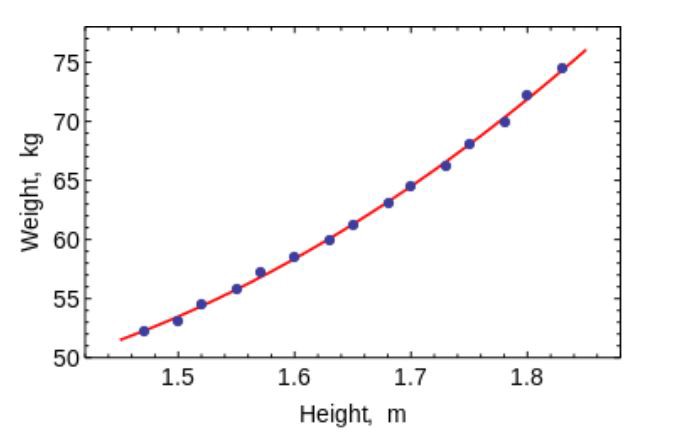
Use este algoritmo para ajustar curvas / regressões simples.
Links úteis:
Guia Introdutório:
Regressão linear limitada
O método dos mínimos quadrados pode confundir outliers, campos falsos etc. São necessárias restrições para reduzir a variação da linha que colocamos no conjunto de dados. A solução correta é ajustar um modelo de regressão linear que garanta que os pesos não se comportem "mal". Os modelos podem ter a norma L1 (LASSO) ou L2 (Regressão de Ridge) ou ambos (regressão elástica).
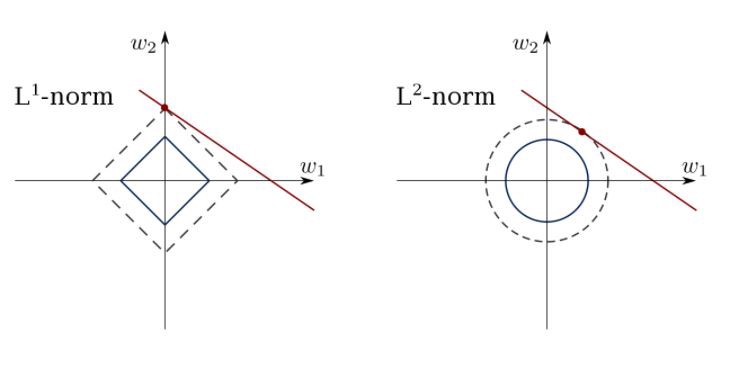
Use esse algoritmo para corresponder às linhas de regressão restritas, evitando a substituição.
Link útil:
Guias introdutórios:
Método K-means
O algoritmo de cluster não controlado favorito de todos. Dado um conjunto de dados na forma de vetores, podemos criar grupos de pontos com base nas distâncias entre eles. Esse é um dos algoritmos de aprendizado de máquina que move sequencialmente os centros dos clusters e, em seguida, agrupa os pontos com cada centro do cluster. A entrada é o número de clusters a serem criados e o número de iterações.
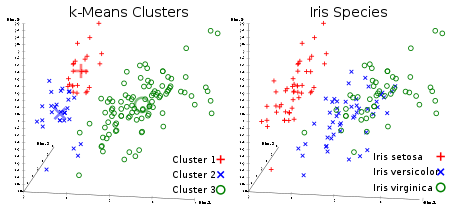
Link útil:
Guias introdutórios:
Regressão logística
A regressão logística é limitada pela regressão linear com não linearidade (principalmente usando a função sigmóide ou tanh) após a aplicação de pesos; portanto, a limitação de saída é próxima das classes +/- (que é 1 e 0 no caso de um sigmóide). As funções de perda de entropia cruzada são otimizadas usando o método de descida de gradiente.
Nota para iniciantes: a regressão logística é usada para classificação, não para regressão. Em geral, é semelhante a uma rede neural de camada única. Treinado usando técnicas de otimização, como descida de gradiente ou L-BFGS. Os desenvolvedores de PNL costumam usá-lo, chamando de "classificação máxima de entropia".

Use o LR para treinar classificadores simples, mas muito "fortes".
Link útil:
Guia Introdutório:
SVM (método de vetor de suporte)
SVM é um modelo linear, como regressão linear / logística. A diferença é que ele possui uma função de perda baseada em margem. Você pode otimizar a função de perda usando métodos de otimização como L-BFGS ou SGD.

Uma coisa única que o SVM pode fazer é aprender os classificadores de classe.
O SVM pode ser usado para treinar classificadores (mesmo regressores).
Link útil:
Guias introdutórios:
Redes neurais de distribuição direta
Basicamente, esses são classificadores multiníveis de regressão logística. Muitas camadas de pesos são separadas por não linearidades (sigmóide, tanh, relu + softmax e novo selu legal). Eles também são chamados de perceptrons multicamadas. Os FFNNs podem ser usados para classificação e "treinamento sem professores" como codificadores automáticos.

O FFNN pode ser usado para treinar o classificador ou extrair funções como codificadores automáticos.
Links úteis:
Guias introdutórios:
Redes neurais convolucionais
Quase todas as conquistas modernas no campo de aprendizado de máquina foram alcançadas usando redes neurais convolucionais. Eles são usados para classificar imagens, detectar objetos ou até segmentar imagens. Inventado por Jan Lekun no início dos anos 90, as redes possuem camadas convolucionais que atuam como extratores hierárquicos de objetos. Você pode usá-los para trabalhar com texto (e até para trabalhar com gráficos).
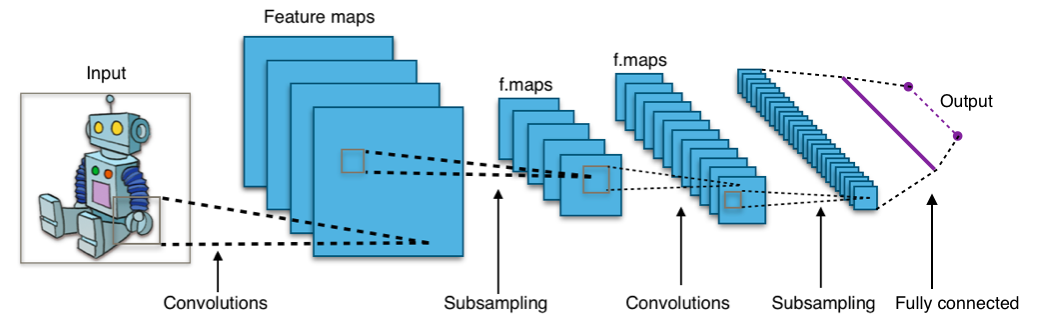
Links úteis:
Guias introdutórios:
Redes Neurais Recorrentes (RNNs)
As RNNs modelam sequências aplicando o mesmo conjunto de pesos recursivamente ao estado do agregador no tempo te entrada no tempo t. RNNs puros raramente são usados agora, mas seus equivalentes, como LSTM e GRU, são os mais avançados na maioria das tarefas de modelagem de sequência. LSTM, que é usado em vez de uma camada densa simples em RNN puro.

Use RNN para qualquer tarefa de classificação de texto, tradução automática, modelagem de idiomas.
Links úteis:
Guias introdutórios:
Campos aleatórios condicionais (CRFs)
Eles são usados para modelagem de sequência, como RNNs, e podem ser usados em combinação com RNNs. Eles também podem ser usados em outras tarefas de previsão estruturada, por exemplo, na segmentação de imagens. O CRF modela cada elemento da sequência (digamos, uma frase), para que os vizinhos influenciem o rótulo do componente na sequência, e nem todos os rótulos que são independentes um do outro.
Use o CRF para vincular seqüências (em texto, imagem, série temporal, DNA etc.).
Link útil:
Guias introdutórios:
Árvores de decisão e florestas aleatórias
Um dos algoritmos de aprendizado de máquina mais comuns. Usado em estatística e análise de dados para modelos de previsão. A estrutura é "folhas" e "galhos". Os atributos dos quais a função objetivo depende são registrados nas "ramificações" da árvore de decisão, os valores da função objetivo são escritos nas "folhas" e os atributos que distinguem os casos são registrados nos nós restantes.
Para classificar um novo caso, você precisa descer a árvore até a folha e emitir o valor correspondente. O objetivo é criar um modelo que preveja o valor da variável de destino com base em várias variáveis de entrada.
Links úteis:
Guias introdutórios:
Você aprenderá mais informações sobre aprendizado de máquina e ciência de dados assinando minha conta no
Habré e no canal Telegram
Neuron . Não pule artigos futuros.
Todo conhecimento!