Há quase um ano, uso o serviço Yandex Music e tudo me convém. Mas há uma página interessante neste serviço - a história. Ele armazena todas as faixas que foram ouvidas em ordem cronológica. E, é claro, eu queria fazer o download e analisar o que ouvia lá o tempo todo.

Primeiras tentativas
Começando a lidar com esta página, encontrei imediatamente um problema. O serviço não baixa todas as faixas de uma só vez, mas apenas à medida que você rola. Eu não queria fazer o download do sniffer e entender o tráfego, e não tinha habilidades nesse assunto naquele momento. Portanto, decidi ir mais simplesmente emulando o navegador usando selênio.
O roteiro foi escrito. Mas ele trabalhou muito instável e por um longo tempo. Mas ele conseguiu carregar a história. Após uma análise simples, deixei o script sem modificações, até que, depois de algum tempo, não quis mais baixar a história. Na esperança do melhor, eu o lancei. E, claro, ele deu um erro. Então percebi que era hora de fazer tudo humanamente.
Opção de trabalho
Para a análise do tráfego, escolhi o Fiddler por conta de uma interface mais poderosa para o tráfego http, diferente do wireshark. Executando o sniffer, esperava ver pedidos de API com um token. Mas não. Nosso objetivo era music.yandex.ru/handlers/library.jsx . E as solicitações exigiam autorização total no site. Vamos começar com ela.
Entrar
Nada complicado aqui. Vamos para passport.yandex.ru/auth , localizamos os parâmetros para as solicitações e fazemos duas solicitações de autorização.
auth_page = self.get('/auth').text csrf_token, process_uuid = self.find_auth_data(auth_page) auth_login = self.post( '/registration-validations/auth/multi_step/start', data={'csrf_token': csrf_token, 'process_uuid': process_uuid, 'login': self.login} ).json() auth_password = self.post( '/registration-validations/auth/multi_step/commit_password', data={'csrf_token': csrf_token, 'track_id': auth_login['track_id'], 'password': self.password} ).json()
E assim fizemos o login.
Histórico de downloads
Em seguida, vá para music.yandex.ru/user/<user>/history , onde também selecionamos alguns parâmetros que são úteis para nós ao receber informações sobre as faixas. Agora você pode baixar a história. music.yandex.ru/handlers/library.jsx das music.yandex.ru/handlers/library.jsx em music.yandex.ru/handlers/library.jsx com os parâmetros {'owner': <user>, 'filter': 'history', 'likeFilter': 'favorite', 'lang': 'ru', 'external-domain': 'music.yandex.ru', 'overembed': 'false', 'ncrnd': '0.9546193023464256'} . Eu estava interessado no parâmetro ncrnd aqui. Ao fazer solicitações, o Yandex sempre atribui valores diferentes a esse parâmetro, mas tudo funciona com o mesmo. De volta, obtemos o histórico na forma de faixas de identificação e informações detalhadas sobre as dez principais faixas. A partir das informações detalhadas da faixa, você pode salvar muitos dados interessantes para análise posterior. Por exemplo, ano de lançamento, duração da faixa e gênero. Informações sobre o restante das faixas são obtidas em music.yandex.ru/handlers/track-entries.jsx . Guardamos todo esse negócio em csv e passamos para a análise.
Análise
Para análise, usamos ferramentas padrão na forma de pandas e matplotlib.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('statistics.csv') df.head(3)
Altere None do python para NaN e jogue-o fora.
df = df.replace('None', pd.np.nan).dropna()
Vamos começar com um simples. Vamos ver o tempo que passamos ouvindo todas as faixas
duration_sec = df['duration_sec'].astype('int64').sum() ss = duration_sec % 60 m = duration_sec // 60 mm = m % 60 h = m // 60 hh = h % 60 f'{h // 24} {hh}:{mm}:{ss}'
'15 15:30:14'
Mas aqui você pode discutir sobre a precisão dessa figura, porque não está claro qual parte da faixa você precisa ouvir, Yandex a adicionou à história.
Agora vamos ver a distribuição das faixas por ano de lançamento.
plt.rcParams['figure.figsize'] = [15, 5] plt.hist(df['year'].sort_values(), bins=len(df['year'].unique())) plt.xticks(rotation='vertical') plt.show()
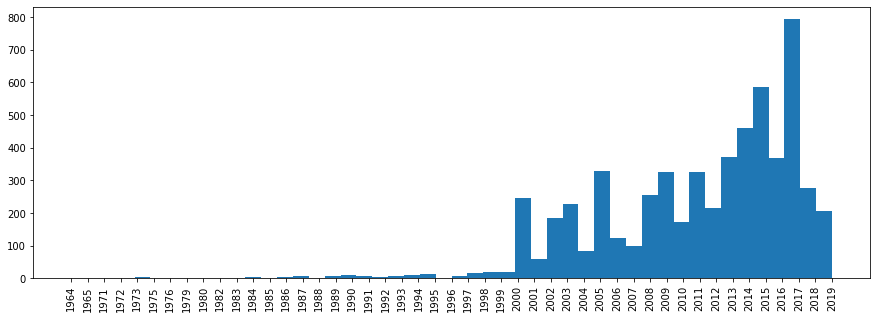
Aqui, o mesmo não é tão simples, pois as diversas coleções de "Best Hits" terão um ano posterior.
Outras estatísticas serão baseadas em um princípio muito semelhante. Vou dar um exemplo das faixas mais ouvidas
df.groupby(['track_id', 'artist','track'])['track_id'].count().sort_values(ascending=False).head()
e faixas mais tocadas do artista
artist_name = 'Coldplay' df.groupby([ 'artist_id', 'track_id', 'artist', 'track' ])['artist_id'].count().sort_values(ascending=False)[:,:,artist_name].head(5)
O código completo pode ser encontrado aqui.