
Com o advento dos telefones celulares com câmeras de alta qualidade, começamos a fazer mais e mais fotos e vídeos de momentos brilhantes e memoráveis em nossas vidas. Muitos de nós têm arquivos de fotos que se estendem por décadas e compreendem milhares de fotos, o que as torna cada vez mais difíceis de navegar. Lembre-se de quanto tempo levou para encontrar uma imagem de interesse apenas alguns anos atrás.
Um dos objetivos do Mail.ru Cloud é fornecer os meios mais acessíveis para acessar e pesquisar seus próprios arquivos de foto e vídeo. Para esse fim, nós da Equipe Mail.ru da Computer Vision criamos e implementamos sistemas para processamento inteligente de imagens: pesquisa por objeto, cena, rosto etc. Outra tecnologia espetacular é o reconhecimento de referência. Hoje, vou contar como fizemos disso uma realidade usando o Deep Learning.
Imagine a situação: você volta de suas férias com um monte de fotos. Conversando com seus amigos, você é solicitado a mostrar uma foto de um lugar que vale a pena ver, como palácio, castelo, pirâmide, templo, lago, cachoeira, montanha e assim por diante. Você corre para rolar a pasta da galeria tentando encontrar uma que seja realmente boa. Provavelmente, está perdido entre centenas de imagens e você diz que o mostrará mais tarde.
Resolvemos esse problema agrupando fotos de usuários em álbuns. Isso permitirá que você encontre as fotos necessárias em apenas alguns cliques. Agora, temos álbuns compilados por rosto, objeto e cena, e também por ponto de referência.
As fotos com pontos de referência são essenciais porque geralmente capturam os destaques de nossas vidas (viagens, por exemplo). Podem ser fotos com alguma arquitetura ou região selvagem em segundo plano. É por isso que procuramos localizar essas imagens e torná-las prontamente disponíveis para os usuários.
Peculiaridades do reconhecimento de marcos
Há uma nuance aqui: não se ensina apenas um modelo e faz com que ele reconheça pontos de referência imediatamente - há vários desafios.
Primeiro, não podemos dizer claramente o que realmente é um “marco”. Não podemos dizer por que um edifício é um marco, enquanto outro ao lado não é. Não é um conceito formalizado, o que torna mais complicado declarar a tarefa de reconhecimento.
Segundo, os marcos são incrivelmente diversos. Estes podem ser edifícios de valor histórico ou cultural, como um templo, palácio ou castelo. Como alternativa, esses podem ser todos os tipos de monumentos. Ou características naturais: lagos, desfiladeiros, cachoeiras e assim por diante. Além disso, existe um modelo único que deve ser capaz de encontrar todos esses pontos de referência.
Terceiro, as imagens com pontos de referência são extremamente poucas. De acordo com nossas estimativas, eles representam apenas 1 a 3 por cento das fotos dos usuários. É por isso que não podemos nos dar ao luxo de cometer erros de reconhecimento, porque se mostrarmos a alguém uma fotografia sem um marco, será bastante óbvio e causará uma reação adversa. Ou, inversamente, imagine que você mostre uma foto com um local de interesse em Nova York para uma pessoa que nunca esteve nos Estados Unidos. Assim, o modelo de reconhecimento deve ter baixo FPR (taxa de falsos positivos).
Quarto, cerca de 50% dos usuários ou mais geralmente desabilitam o salvamento de dados geográficos. Precisamos levar isso em conta e usar apenas a própria imagem para identificar o local. Hoje, a maioria dos serviços capazes de lidar com pontos de referência de alguma forma usa dados geográficos das propriedades da imagem. No entanto, nossos requisitos iniciais eram mais rigorosos.
Agora, deixe-me mostrar alguns exemplos.
Aqui estão três objetos parecidos, três catedrais góticas na França. À esquerda, a catedral de Amiens, a do meio, a catedral de Reims, e a Notre-Dame de Paris, à direita.

Até um humano precisa de algum tempo para olhar atentamente e ver que são catedrais diferentes, mas o mecanismo deve ser capaz de fazer o mesmo, e ainda mais rápido do que um humano.
Aqui está outro desafio: todas as três fotos aqui apresentam a Notre-Dame de Paris filmada de diferentes ângulos. As fotos são bem diferentes, mas ainda precisam ser reconhecidas e recuperadas.

Os recursos naturais são totalmente diferentes da arquitetura. À esquerda, Cesaréia em Israel, à direita, Englischer Garten, em Munique.

Essas fotos dão ao modelo poucas pistas para adivinhar.
Nosso método
Nosso método é completamente baseado em redes neurais convolucionais profundas. A estratégia de treinamento que escolhemos foi a chamada aprendizagem curricular, o que significa aprender em várias etapas. Para obter maior eficiência com e sem dados geográficos disponíveis, fizemos uma inferência específica. Deixe-me falar sobre cada etapa com mais detalhes.
Conjunto de dados
Os dados são o combustível do aprendizado de máquina. Primeiro, tivemos que reunir o conjunto de dados para ensinar o modelo.
Dividimos o mundo em 4 regiões, cada uma sendo usada em uma etapa específica do processo de aprendizado. Em seguida, selecionamos países em cada região, escolhemos uma lista de cidades para cada país e coletamos um banco de fotos. Abaixo estão alguns exemplos.

Primeiro, tentamos fazer nosso modelo aprender com o banco de dados obtido. Os resultados foram ruins. Nossa análise mostrou que os dados estavam sujos. Havia muito barulho interferindo no reconhecimento de cada ponto de referência. O que deveríamos fazer? Seria caro, complicado e pouco inteligente revisar todo o volume de dados manualmente. Por isso, criamos um processo para limpeza automática de banco de dados, onde o manuseio manual é usado apenas em uma etapa: escolhemos 3 a 5 fotografias de referência para cada ponto de referência, o que definitivamente mostra o objeto desejado em um ângulo mais ou menos adequado. Ele funciona rápido o suficiente porque a quantidade desses dados de referência é pequena em comparação com o banco de dados inteiro. Em seguida, é realizada a limpeza automática com base em redes neurais convolucionais profundas.
Mais adiante, usarei o termo "incorporação", com o que quero dizer o seguinte. Temos uma rede neural convolucional. Nós o treinamos para classificar objetos, depois cortamos a última camada de classificação, pegamos algumas imagens, as analisamos pela rede e obtivemos um vetor numérico na saída. Isso é o que chamarei de incorporação.
Como eu disse antes, organizamos nosso processo de aprendizado em várias etapas correspondentes a partes de nosso banco de dados. Então, primeiro, pegamos a rede neural da etapa anterior ou a rede de inicialização.
Temos fotos de referência de um ponto de referência, processamos pela rede e obtemos vários incorporamentos. Agora podemos proceder à limpeza de dados. Tiramos todas as fotos do conjunto de dados para o ponto de referência e também processamos cada uma pela rede. Nós obtemos alguns casamentos e determinamos a distância para referenciar casamentos para cada um. Em seguida, determinamos a distância média e, se exceder algum limite que é um parâmetro do algoritmo, tratamos o objeto como não marco. Se a distância média for menor que o limite, mantemos a fotografia.
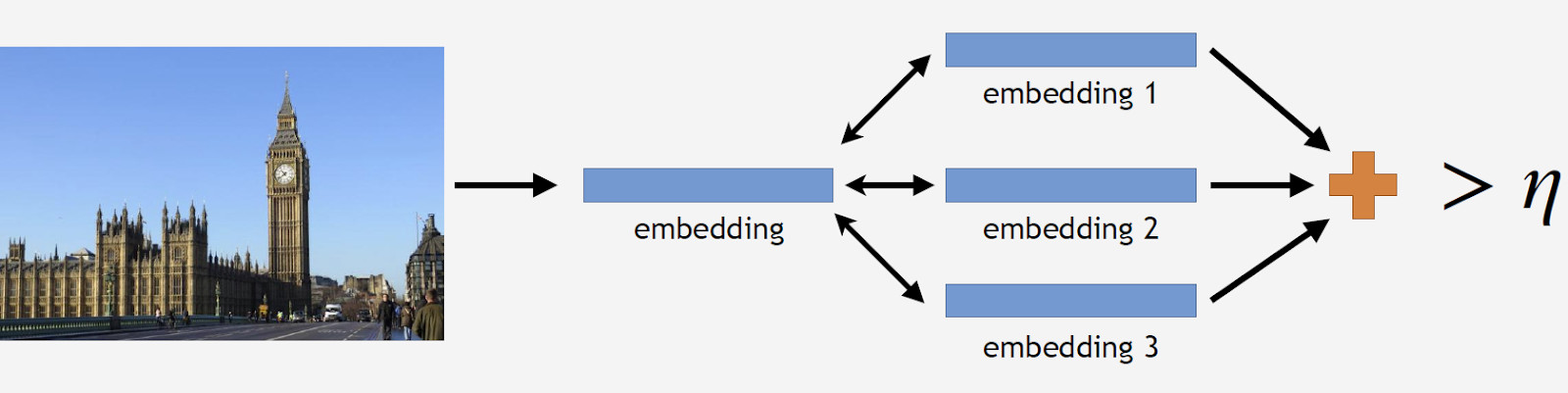
Como resultado, tínhamos um banco de dados que continha mais de 11 mil pontos de referência de mais de 500 cidades em 70 países, mais de 2,3 milhões de fotos. Lembre-se de que a maior parte das fotografias não possui pontos de referência. Precisamos contar aos nossos modelos de alguma forma. Por esse motivo, adicionamos 900 mil fotos sem pontos de referência ao nosso banco de dados e treinamos nosso modelo com o conjunto de dados resultante.
Introduzimos um teste offline para medir a qualidade da aprendizagem. Como os pontos de referência ocorrem apenas em 1 a 3% de todas as fotos, compilamos manualmente um conjunto de 290 fotos que mostram um ponto de referência. Essas fotos eram bastante diversas e complexas, com um grande número de objetos fotografados de diferentes ângulos para tornar o teste o mais difícil possível para o modelo. Seguindo o mesmo padrão, escolhemos 11 mil fotografias sem pontos de referência, também bastante complicados, e tentamos encontrar objetos que se parecessem muito com os pontos de referência em nosso banco de dados.
Para avaliar a qualidade da aprendizagem, medimos a precisão do nosso modelo usando fotos com e sem pontos de referência. Essas são nossas duas principais métricas.
Abordagens existentes
Há relativamente poucas informações sobre o reconhecimento de referências na literatura. A maioria das soluções é baseada em recursos locais. A idéia principal é que tenhamos alguma imagem de consulta e uma imagem do banco de dados. Os recursos locais - pontos principais - são encontrados e, em seguida, correspondidos. Se o número de correspondências for grande o suficiente, concluímos que encontramos um ponto de referência.
Atualmente, o melhor método é o DELF (recursos locais profundos) oferecido pelo Google, que combina recursos locais correspondentes ao aprendizado profundo. Ao processar uma imagem de entrada pela rede convolucional, obtemos alguns recursos do DELF.
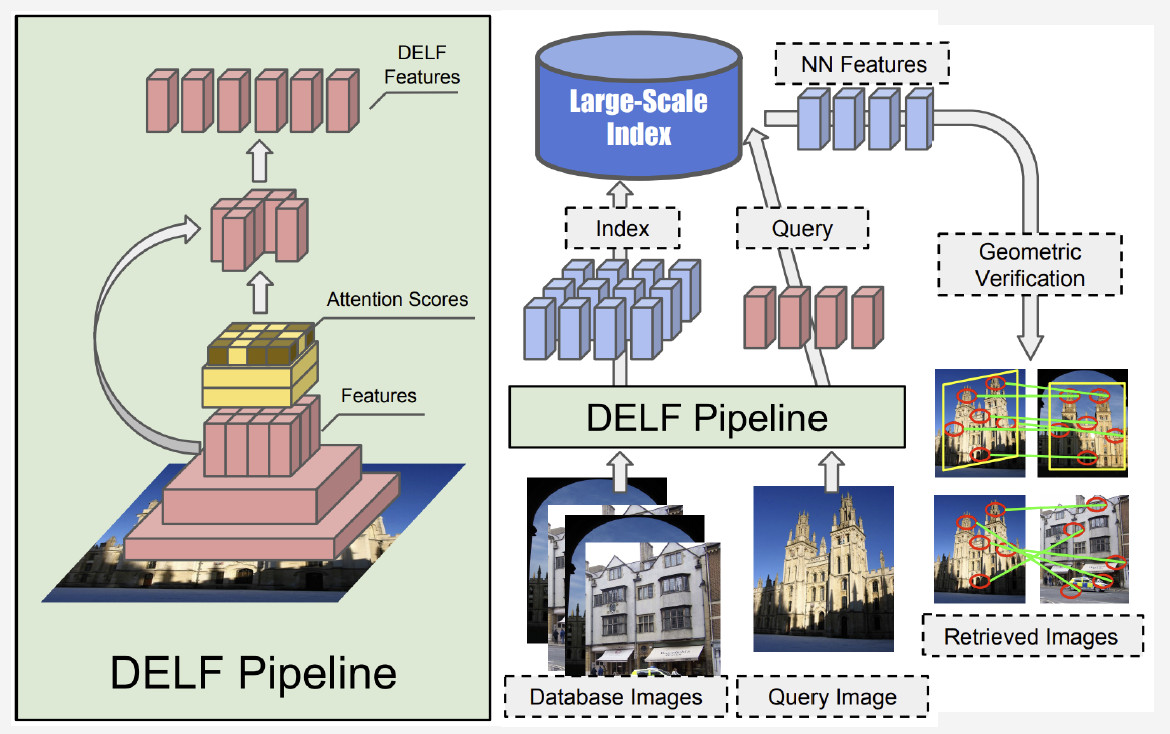
Como o reconhecimento de pontos de referência funciona? Temos um banco de fotos e uma imagem de entrada e queremos saber se mostra um ponto de referência ou não. Ao executar a rede DELF de todas as fotos, é possível obter os recursos correspondentes para o banco de dados e a imagem de entrada. Em seguida, realizamos uma pesquisa pelo método do vizinho mais próximo e obtemos imagens candidatas com recursos na saída. Usamos a verificação geométrica para combinar os recursos: se for bem-sucedido, concluímos que a imagem mostra um ponto de referência.
Rede neural convolucional
O pré-treinamento é crucial para o Deep Learning. Então, usamos um banco de dados de cenas para pré-treinar nossa rede neural. Por que assim? Uma cena é um objeto múltiplo que compreende um grande número de outros objetos. Marco é uma instância de uma cena. Ao pré-treinar o modelo com esse banco de dados, podemos dar uma idéia de alguns recursos de baixo nível que podem ser generalizados para um reconhecimento de referência bem-sucedido.
Utilizamos uma rede neural da família de redes residuais como modelo. A diferença crítica dessas redes é que elas usam um bloco residual que inclui conexão de salto, que permite que um sinal salte sobre camadas com pesos e passe livremente. Essa arquitetura permite treinar redes profundas com um alto nível de qualidade e controlar o efeito gradiente de fuga, essencial para o treinamento.
Nosso modelo é o Wide ResNet-50-2, uma versão do ResNet-50 onde o número de convoluções no bloco de gargalo interno é dobrado.

A rede funciona muito bem. Nós o testamos com nosso banco de dados de cenas e aqui estão os resultados:
O Wide ResNet trabalhou quase duas vezes mais rápido que o ResNet-200. Afinal, é a velocidade de execução crucial para a produção. Dadas todas essas considerações, escolhemos Wide ResNet-50-2 como nossa principal rede neural.
Treinamento
Precisamos de uma função de perda para treinar nossa rede. Decidimos usar a abordagem de aprendizado métrico para selecioná-la: uma rede neural é treinada para que itens da mesma classe se agrupem em um cluster, enquanto que clusters para classes diferentes devem ser espaçados o máximo possível. Para pontos de referência, usamos a perda de centro, que puxa elementos de uma classe para algum centro. Uma característica importante dessa abordagem é que ela não requer amostragem negativa, o que se torna algo bastante difícil de ser feito em épocas posteriores.
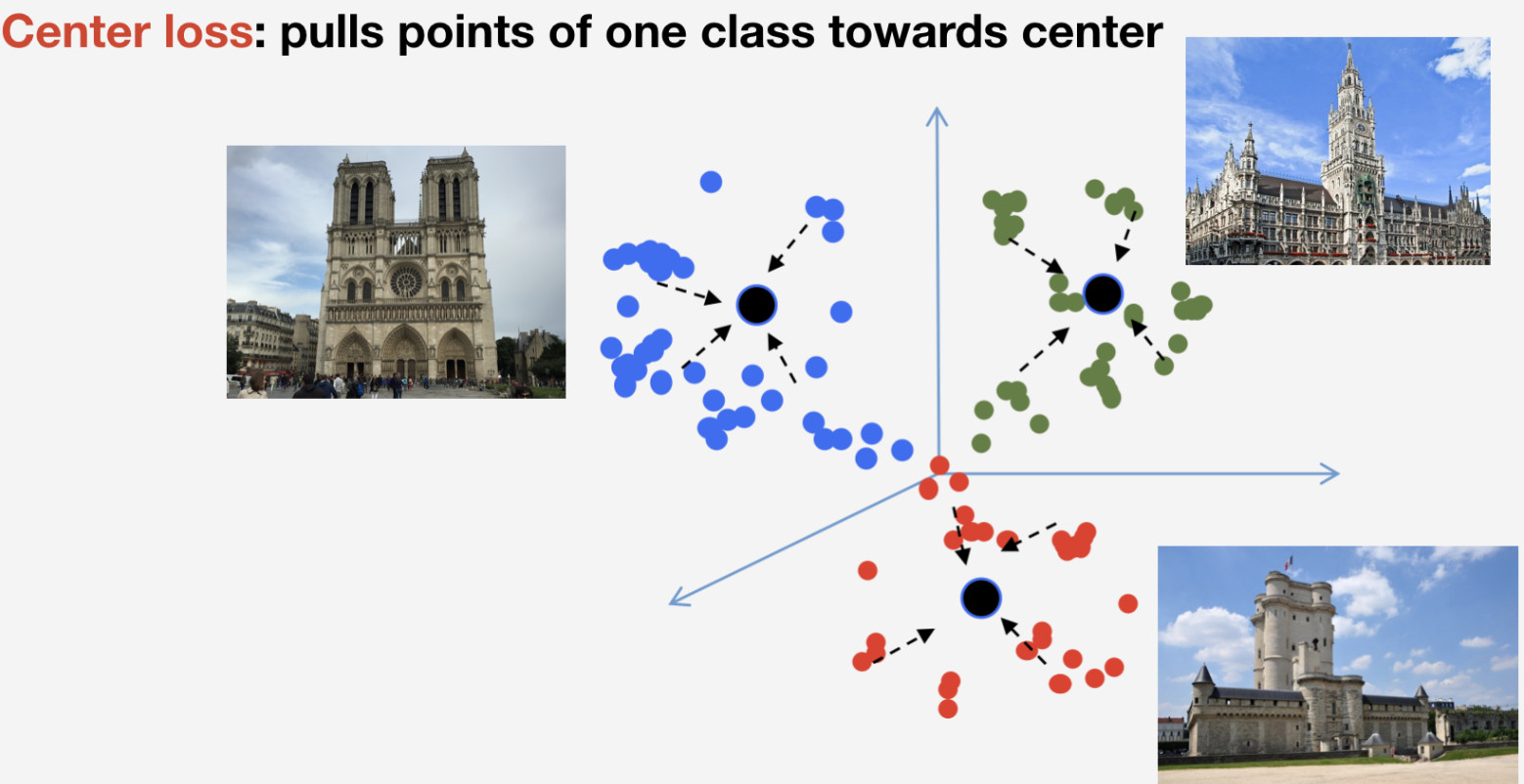
Lembre-se de que temos n classes de pontos de referência e mais uma classe "sem pontos de referência" para a qual a perda do Center não é usada. Implicamos que um ponto de referência é um e o mesmo objeto, e possui estrutura, por isso faz sentido determinar seu centro. Quanto ao não marco, ele pode se referir a qualquer coisa, portanto, não faz sentido determinar o centro para ele.
Reunimos tudo isso e existe o nosso modelo de treinamento. Compreende três partes principais:
- Rede neural convolucional ampla ResNet 50-2 pré-treinada com um banco de dados de cenas;
- Peça de incorporação compreendendo uma camada totalmente conectada e uma camada de norma de lote;
- Classificador que é uma camada totalmente conectada, seguida por um par composto por perda Softmax e perda Center.

Como você se lembra, nosso banco de dados é dividido em 4 partes por região. Usamos essas quatro partes em um paradigma de aprendizado curricular. Temos um conjunto de dados atual e, em cada estágio do aprendizado, adicionamos outra parte do mundo para obter um novo conjunto de dados para treinamento.
O modelo compreende três partes e usamos uma taxa de aprendizado específica para cada uma no processo de treinamento. Isso é necessário para que a rede possa aprender pontos de referência de uma nova parte do conjunto de dados que adicionamos e lembrar os dados já aprendidos. Muitos experimentos provaram que essa abordagem é a mais eficiente.
Então, treinamos nosso modelo. Agora precisamos entender como isso funciona. Vamos usar o mapa de ativação de classe para encontrar a parte da imagem à qual nossa rede neural reage mais facilmente. A imagem abaixo mostra imagens de entrada na primeira linha e as mesmas imagens sobrepostas ao mapa de ativação de classe da rede que treinamos na etapa anterior são mostradas na segunda linha.

O mapa de calor mostra quais partes da imagem são mais atendidas pela rede. Como mostra o mapa de ativação de classe, nossa rede neural aprendeu o conceito de marco com êxito.
Inferência
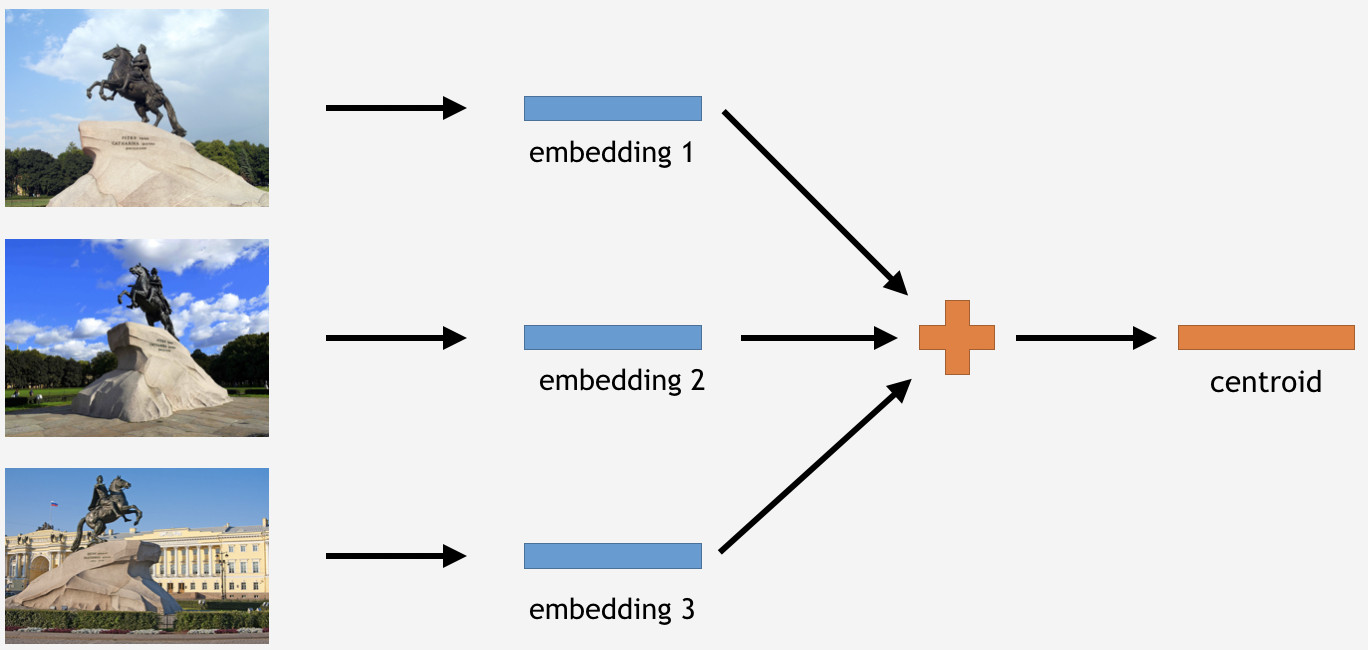
Agora precisamos usar esse conhecimento de alguma forma para fazer as coisas. Como usamos a perda do Center para treinamento, no caso de inferência, parece bastante lógico determinar também os centróides para pontos de referência.
Para fazer isso, tiramos uma parte das imagens do conjunto de treinamento para algum marco, digamos, o Cavaleiro de Bronze em São Petersburgo. Em seguida, processamos a rede, obtemos casamentos, medimos a média e obtemos um centróide.
No entanto, aqui está uma pergunta: quantos centróides por ponto de referência faz sentido derivar? Inicialmente, parecia claro e lógico dizer: um centróide. Não exatamente, como se viu. Inicialmente, decidimos criar um único centróide também, e o resultado não foi ruim. Então, por que vários centróides?
Primeiro, os dados que temos não são tão limpos. Embora tenhamos limpado o conjunto de dados, removemos apenas dados óbvios de desperdício. No entanto, ainda pode haver imagens não obviamente desperdiçadas, mas afetando adversamente o resultado.
Por exemplo, tenho uma aula de referência no Palácio de Inverno em São Petersburgo. Eu quero derivar um centróide para isso. No entanto, seu conjunto de dados inclui algumas fotos com a Praça do Palácio e o arco da Sede Geral, porque esses objetos estão próximos um do outro. Se o centróide for determinado para todas as imagens, o resultado não será tão estável. O que precisamos fazer é agrupar de alguma forma os casamentos deles derivados da rede neural, pegar apenas o centróide que lida com o Palácio de Inverno e calcular a média usando os dados resultantes.

Segundo, as fotografias podem ter sido tiradas de diferentes ângulos.
Aqui está um exemplo desse comportamento ilustrado com o campanário de Bruges. Dois centróides foram derivados para isso. Na linha superior da imagem, existem as fotos mais próximas do primeiro centróide e na segunda linha - as que estão mais próximas do segundo centróide.

O primeiro centróide lida com mais fotografias "grandiosas" que foram tiradas no mercado de Bruges a curta distância. O segundo centróide lida com fotografias tiradas à distância em ruas específicas.
Acontece que, ao derivar vários centróides por classe de ponto de referência, podemos refletir na inferência diferentes ângulos de câmera para esse ponto de referência.
Então, como obtemos esses conjuntos para derivar centróides? Aplicamos o cluster hierárquico (link completo) aos conjuntos de dados para cada ponto de referência. Nós o usamos para encontrar clusters válidos dos quais os centróides devem ser derivados. Por agrupamentos válidos, entendemos aqueles que compreendem pelo menos 50 fotografias como resultado do agrupamento. Os outros clusters são rejeitados. Como resultado, obtivemos cerca de 20% dos pontos de referência com mais de um centróide.
Agora, para inferência. É obtido em duas etapas: em primeiro lugar, alimentamos a imagem de entrada em nossa rede neural convolucional e obtemos incorporação e, então, combinamos a incorporação com centróides usando o produto escalar. Se as imagens tiverem dados geográficos, restringimos a pesquisa aos centróides, que se referem a pontos de referência localizados a um quadrado de 1 x 1 km do local da imagem. Isso permite uma pesquisa mais precisa e um limite mais baixo para correspondência subsequente. Se a distância resultante exceder o limite, que é um parâmetro do algoritmo, concluímos que uma foto tem um ponto de referência com o valor máximo do produto com pontos. Se for menor, é uma foto que não é um marco.
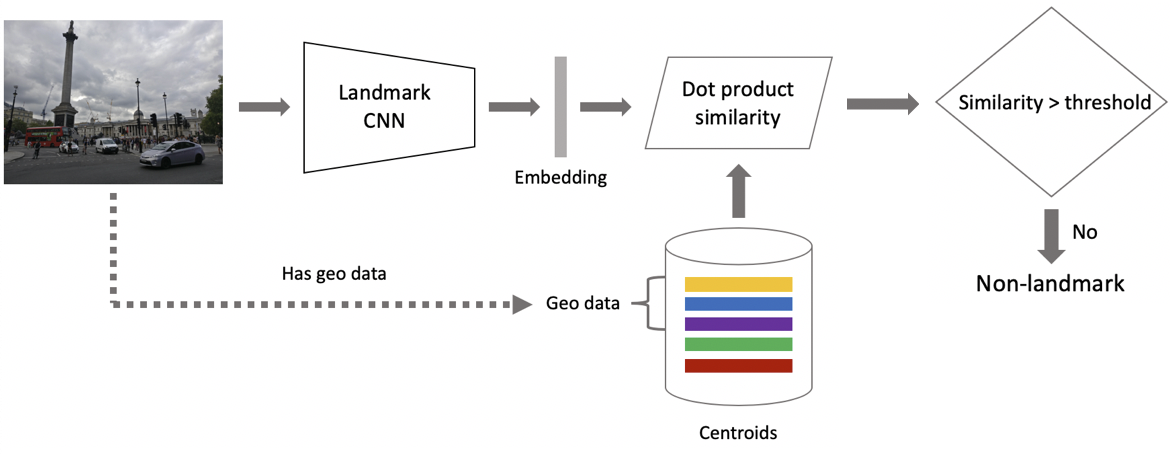
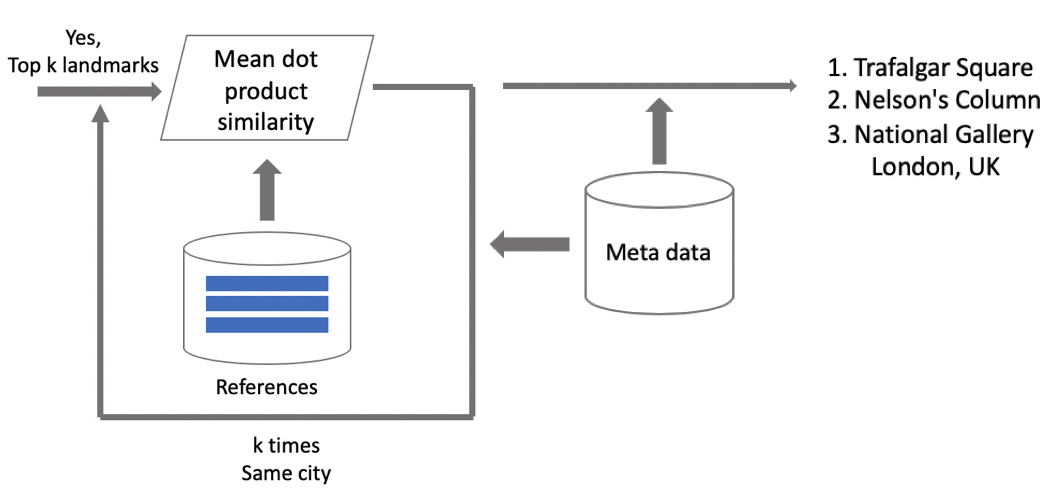
Suponha que uma foto tenha um ponto de referência. Se tivermos dados geográficos, os usaremos e obteremos uma resposta. Se os dados geográficos não estiverem disponíveis, executaremos uma verificação adicional. Quando limpávamos o conjunto de dados, fizemos um conjunto de imagens de referência para cada classe. Podemos determinar incorporações para eles e, em seguida, obter uma distância média deles até a incorporação da imagem da consulta. Se exceder algum limite, a verificação é aprovada e trazemos metadados e obtemos um resultado. É importante observar que podemos executar este procedimento para vários pontos de referência encontrados em uma imagem.
Resultados dos testes
Comparamos nosso modelo com o DELF, para o qual adotamos parâmetros com os quais ele apresentaria o melhor desempenho em nosso teste. Os resultados são quase idênticos.
Em seguida, classificamos os pontos de referência em dois tipos: frequentes (mais de 100 fotografias no banco de dados), responsáveis por 87% de todos os pontos de referência no teste, e raros. Nosso modelo funciona bem com os frequentes: 85,3% de precisão. Com marcos raros, tínhamos 46%, o que também não era ruim, o que significa que nossa abordagem funcionou razoavelmente bem, mesmo com poucos dados.
Em seguida, executamos o teste A / B com fotos do usuário. Como resultado, a taxa de conversão de compra do espaço na nuvem cresceu 10%, a taxa de conversão de desinstalação de aplicativos para dispositivos móveis foi reduzida em 3% e o número de visualizações de álbuns aumentou 13%.
Vamos comparar nossa velocidade com a DELF. Com a GPU, o DELF requer 7 execuções de rede porque usa 7 escalas de imagem, enquanto nossa abordagem usa apenas 1. Com a CPU, o DELF usa uma pesquisa mais longa pelo método do vizinho mais próximo e uma verificação geométrica muito longa. No final, nosso método foi 15 vezes mais rápido com a CPU. Nossa abordagem mostra maior velocidade nos dois casos, o que é crucial para a produção.
Resultados: lembranças de férias
No início deste artigo, mencionei uma solução para rolar e encontrar as imagens de referência desejadas. Aqui está.
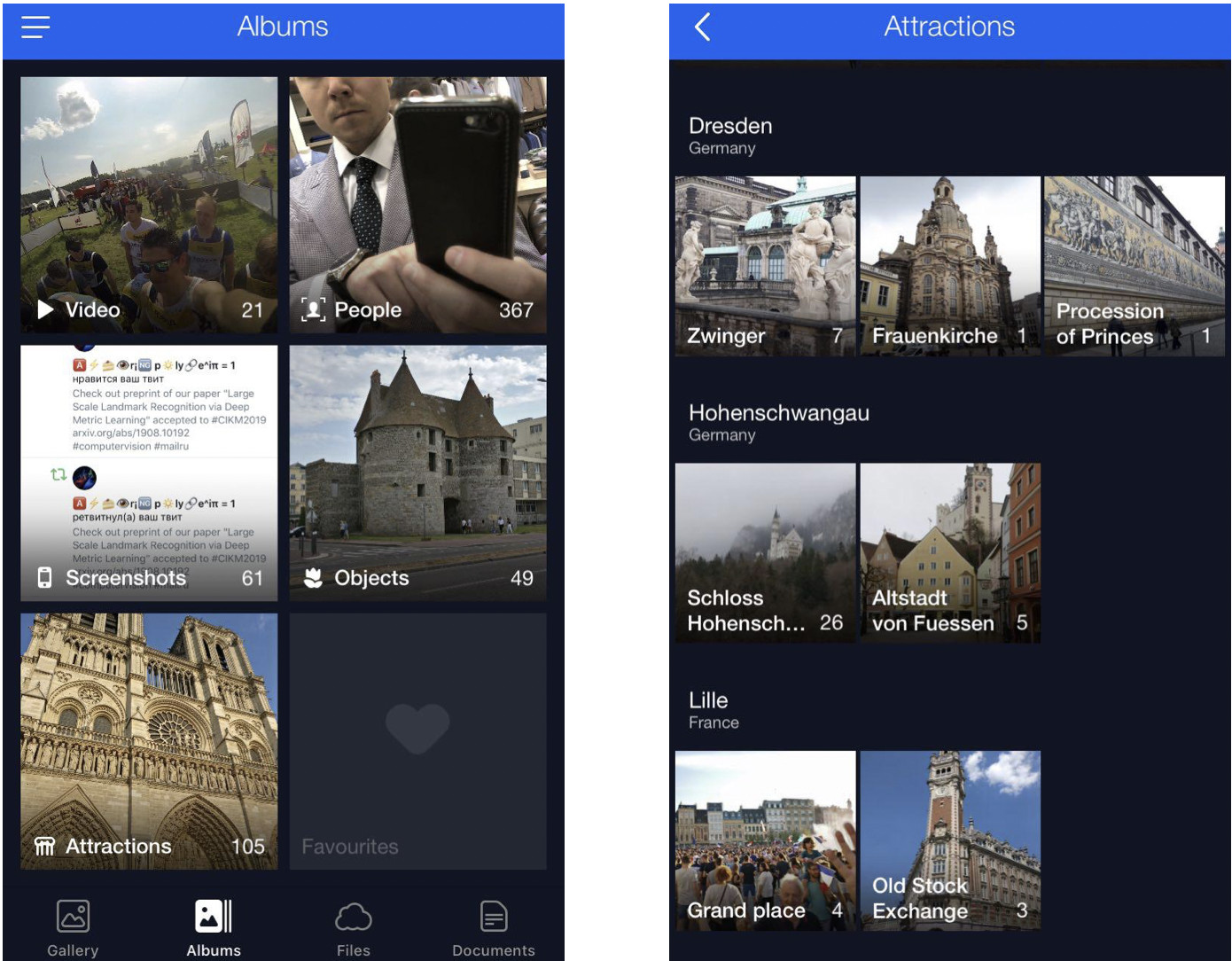
Esta é a minha nuvem, onde todas as fotos são classificadas em álbuns. Existem álbuns "Pessoas", "Objetos" e "Atrações". No álbum Atrações, os pontos de referência são classificados em álbuns agrupados por cidade. Um clique no Dresdner Zwinger abre um álbum apenas com fotos deste ponto de referência.
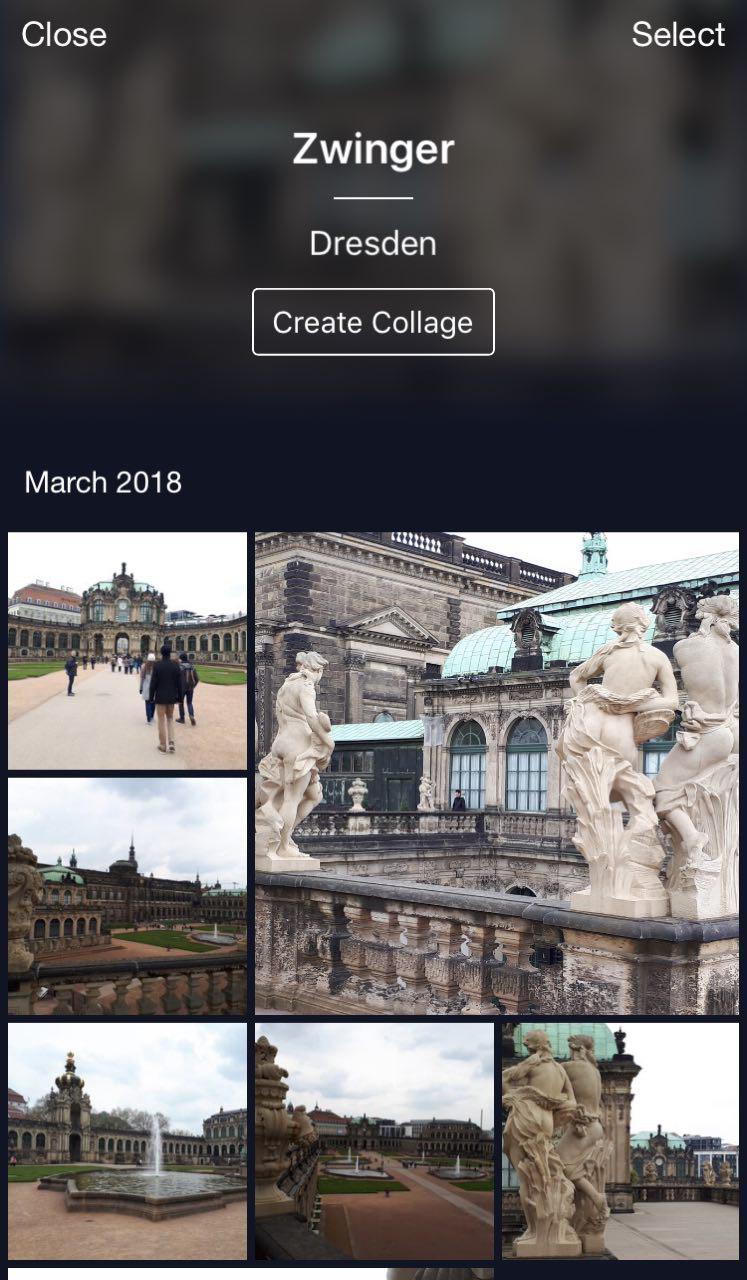
Um recurso útil: você pode sair de férias, tirar algumas fotos e armazená-las na sua nuvem. Mais tarde, quando você desejar enviá-los para o Instagram ou compartilhar com amigos e familiares, não precisará pesquisar e escolher muito tempo - as fotos desejadas estarão disponíveis em apenas alguns cliques.
Conclusões
Deixe-me lembrá-lo dos principais recursos de nossa solução.
- Limpeza semi-automática de banco de dados. Um pouco de trabalho manual é necessário para o mapeamento inicial e, em seguida, a rede neural fará o resto. Isso permite limpar novos dados rapidamente e usá-los para treinar novamente o modelo.
- Utilizamos redes neurais convolucionais profundas e aprendizado métrico profundo, o que nos permite aprender a estrutura das aulas com eficiência.
- Usamos a aprendizagem do currículo, ou seja, o treinamento em partes, como paradigma de treinamento. Essa abordagem tem sido muito útil para nós. Usamos vários centróides na inferência, o que permite o uso de dados mais limpos e a localização de pontos de vista diferentes.
Pode parecer que o reconhecimento de objetos é uma tarefa trivial. No entanto, explorando as necessidades dos usuários da vida real, encontramos novos desafios, como o reconhecimento de marcos. Essa técnica permite dizer às pessoas algo novo sobre o mundo usando redes neurais. É muito encorajador e motivador!