O curso completo em russo pode ser encontrado neste link .
O curso de inglês original está disponível neste link .

Conteúdo
- Entrevista com Sebastian Trun
- 1. Introdução
- Transferir modelo de aprendizagem
- MobileNet
- CoLab: Gatos contra cães com treinamento de transferência
- Mergulhando em redes neurais convolucionais
- Parte prática: determinação de cores com a transferência de treinamento
- Sumário
Entrevista com Sebastian Trun
- Esta é a lição 6 e é totalmente dedicada à transferência de aprendizado. Transferência de aprendizado é o processo de usar um modelo existente com pouco refinamento para novas tarefas. A transferência de treinamento ajuda a reduzir o tempo de treinamento do modelo, aumentando a eficiência do aprendizado desde o início. Sebastian, o que você acha da transferência de treinamento? Você já foi capaz de usar a metodologia de transferência de ensino em seu trabalho e pesquisa?
- Minha dissertação foi dedicada apenas ao tópico da transferência de treinamento e foi chamada " Explicação com base na transferência de treinamento ". Quando estávamos trabalhando em uma dissertação, a idéia era que é possível ensinar a distinguir todos os outros objetos desse tipo em um objeto (conjunto de dados, entidade) em várias variações e formatos. No trabalho, utilizamos o algoritmo desenvolvido, que distinguia as principais características (atributos) do objeto e podia compará-las com outro objeto. Bibliotecas como o Tensorflow já vêm com modelos pré-treinados.
- Sim, na Tensorflow, temos um conjunto completo de modelos pré-treinados que você pode usar para resolver problemas práticos. Falaremos sobre conjuntos prontos um pouco mais tarde.
- sim sim! Se você pensar bem, as pessoas estão envolvidas na transferência de treinamento o tempo todo ao longo de suas vidas.
- Podemos dizer que, graças ao método de transferência de treinamento, nossos novos alunos em algum momento não precisarão saber algo sobre aprendizado de máquina porque será suficiente para conectar um modelo já preparado e usá-lo?
- Programação é escrever linha por linha, damos comandos ao computador. Nosso objetivo é garantir que todos no planeta possam e possam programar, fornecendo ao computador apenas exemplos de dados de entrada. Concorde que, se você deseja ensinar um computador a distinguir gatos de cães, é bastante difícil encontrar 100 mil imagens diferentes de gatos e 100 mil imagens diferentes de cães. Graças à transferência de treinamento, você pode resolver esse problema em várias linhas.
- Sim é mesmo! Obrigado pelas respostas e vamos finalmente prosseguir com o aprendizado.
1. Introdução
- Olá e bem vindo de volta!
- Na última vez, treinamos uma rede neural convolucional para classificar gatos e cães na imagem. Nossa primeira rede neural foi treinada novamente, portanto seu resultado não foi tão alto - cerca de 70% de precisão. Depois disso, implementamos a extensão e a eliminação de dados (desconexão arbitrária de neurônios), o que nos permitiu aumentar a precisão das previsões em até 80%.
- Apesar de 80% parecer um excelente indicador, o erro de 20% ainda é muito grande. Certo? O que podemos fazer para aumentar a precisão da classificação? Nesta lição, usaremos a técnica de transferência de conhecimento (transferência do modelo de conhecimento), que nos permitirá usar o modelo desenvolvido por especialistas e treinado em grandes conjuntos de dados. Como veremos na prática, transferindo o modelo de conhecimento, podemos alcançar 95% de precisão na classificação. Vamos começar!
Transferência de modelo de aprendizagem
Em 2012, a rede neural AlexNet revolucionou o mundo do aprendizado de máquina e popularizou o uso de redes neurais convolucionais para classificação ao vencer o desafio de reconhecimento visual ImageNet em larga escala.
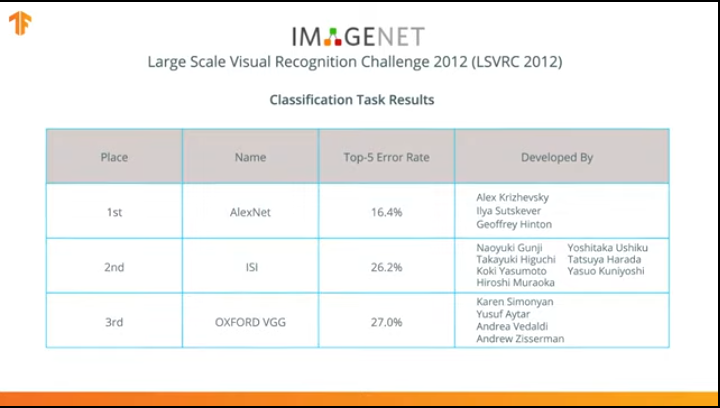
Depois disso, a luta começou a desenvolver redes neurais mais precisas e eficientes que poderiam superar o AlexNet nas tarefas de classificação de imagens do conjunto de dados do ImageNet.
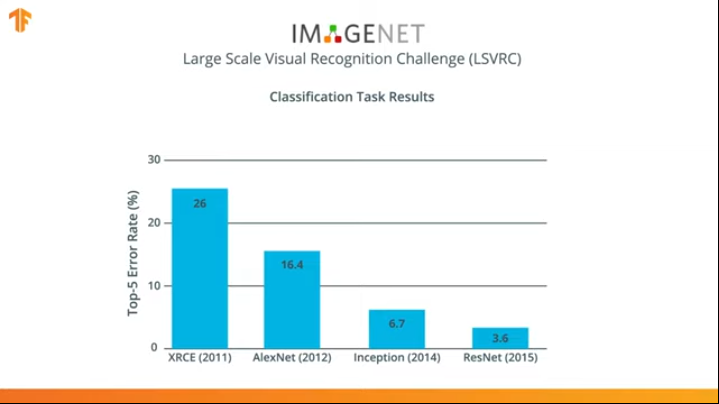
Por vários anos, redes neurais foram desenvolvidas para lidar melhor com a tarefa de classificação do que o AlexNet - Inception e ResNet.
Concorda que seria ótimo poder tirar proveito dessas redes neurais já treinadas em grandes conjuntos de dados da ImageNet e usá-las em seu classificador para cães e gatos?
Acontece que nós podemos fazer isso! A técnica é chamada de transferência de aprendizado. A idéia principal do método de transferência do modelo de treinamento é baseada no fato de que, após treinar uma rede neural em um grande conjunto de dados, podemos aplicar o modelo obtido a um conjunto de dados que este modelo ainda não encontrou. É por isso que a técnica é chamada de transferência de aprendizado - transferência do processo de aprendizado de um conjunto de dados para outro.
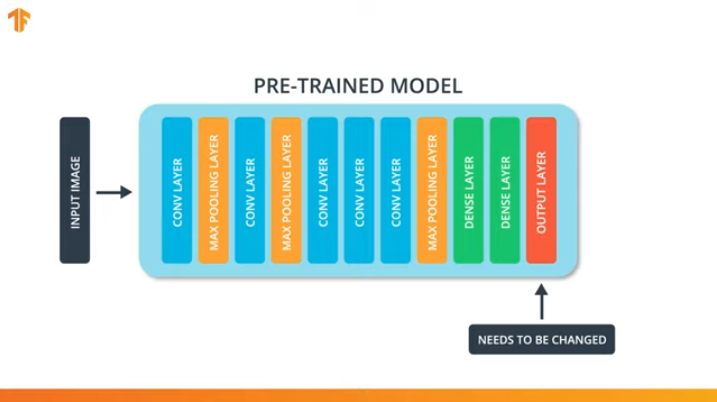
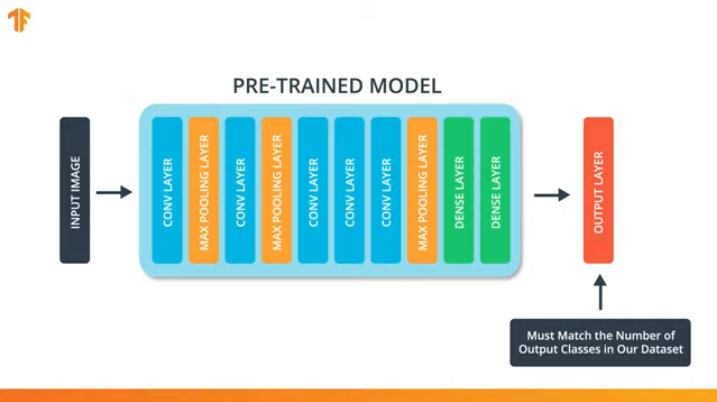
Para aplicarmos a metodologia de transferência do modelo de treinamento, precisamos alterar a última camada de nossa rede neural convolucional:
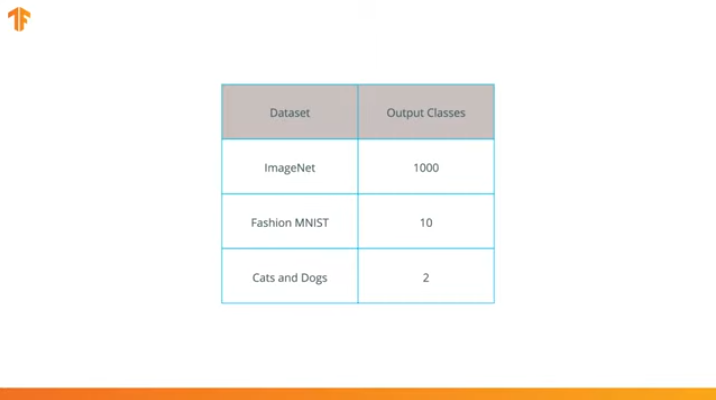
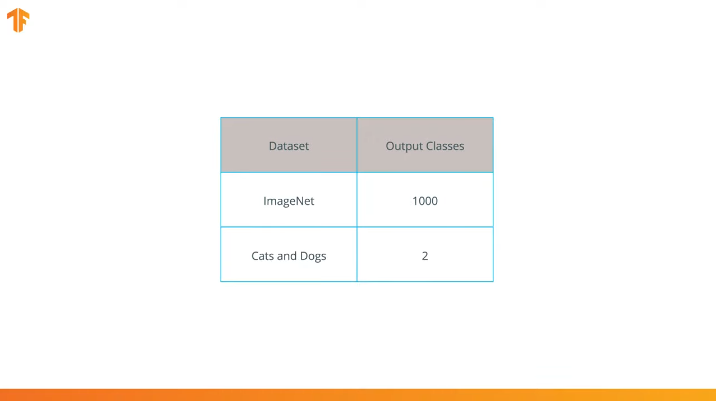
Executamos essa operação porque cada conjunto de dados consiste em um número diferente de classes de saída. Por exemplo, os conjuntos de dados no ImageNet contêm 1000 classes de saída diferentes. FashionMNIST contém 10 classes. Nosso conjunto de dados de classificação consiste em apenas 2 classes - gatos e cães.
É por isso que é necessário alterar a última camada de nossa rede neural convolucional para que ela contenha o número de saídas que corresponderiam ao número de classes no novo conjunto.
Também precisamos garantir que não alteremos o modelo pré-treinado durante o processo de treinamento. A solução é desativar as variáveis do modelo pré-treinado - simplesmente proibimos que o algoritmo atualize os valores da distribuição direta e reversa para alterá-los.
Esse processo é chamado de "congelamento do modelo".
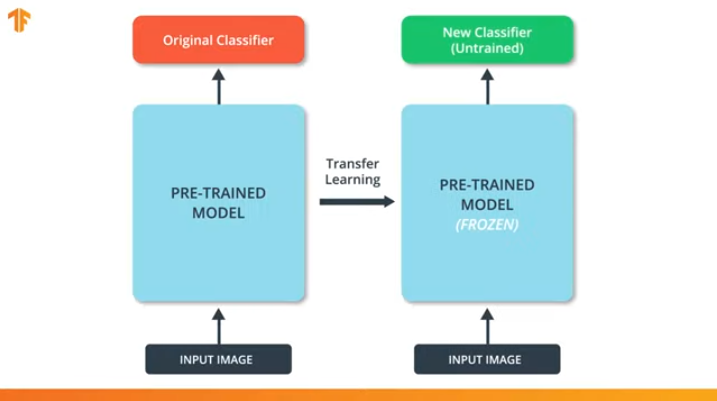
Ao “congelar” os parâmetros do modelo pré-treinado, permitimos aprender apenas a última camada da rede de classificação, os valores das variáveis do modelo pré-treinado permanecem inalterados.
Outra vantagem indiscutível dos modelos pré-treinados é que reduzimos o tempo de treinamento treinando apenas a última camada com um número significativamente menor de variáveis, e não o modelo inteiro.
Se não congelarmos as variáveis do modelo pré-treinado, durante o processo de treinamento, os valores das variáveis serão alterados no novo conjunto de dados. Isso ocorre porque os valores das variáveis na última camada da classificação serão preenchidos com valores aleatórios. Devido a valores aleatórios na última camada, nosso modelo cometerá grandes erros na classificação, o que, por sua vez, acarretará fortes mudanças nos pesos iniciais no modelo pré-treinado, o que é extremamente indesejável para nós.
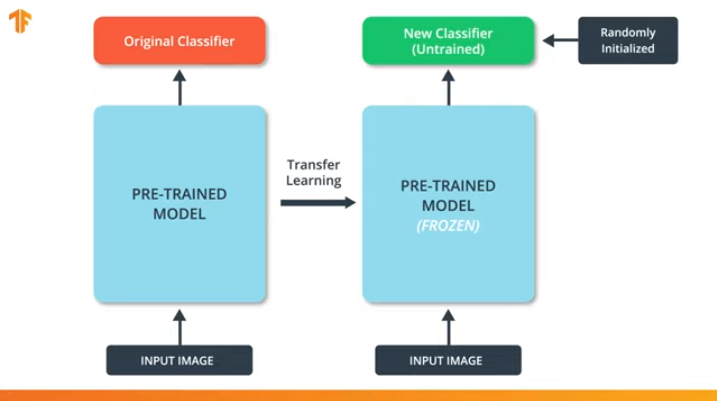
É por esse motivo que devemos sempre lembrar que, ao usar modelos existentes, os valores das variáveis devem ser "congelados" e a necessidade de treinar um modelo pré-treinado deve ser desativada.
Agora que sabemos como a transferência do modelo de treinamento funciona, basta escolher uma rede neural pré-treinada para uso em nosso próprio classificador! Isso faremos na próxima parte.
MobileNet
Como mencionamos anteriormente, foram desenvolvidas redes neurais extremamente eficientes que apresentaram altos resultados nos conjuntos de dados ImageNet - AlexNet, Inception, Resonant. Essas redes neurais são redes muito profundas e contêm milhares e até milhões de parâmetros. Um grande número de parâmetros permite que a rede aprenda padrões mais complexos e, assim, obtenha maior precisão na classificação. Um grande número de parâmetros de treinamento da rede neural afeta a velocidade do aprendizado, a quantidade de memória necessária para armazenar a rede e a complexidade dos cálculos.
Nesta lição, usaremos a moderna rede neural convolucional MobileNet. MobileNet é uma arquitetura de rede neural convolucional eficiente que reduz a quantidade de memória usada para computação, mantendo alta precisão das previsões. É por isso que o MobileNet é ideal para uso em dispositivos móveis com uma quantidade limitada de memória e recursos de computação.
O MobileNet foi desenvolvido pelo Google e treinado no conjunto de dados ImageNet.
Como o MobileNet foi treinado em 1.000 classes a partir do conjunto de dados ImageNet, o MobileNet possui 1.000 classes de saída, em vez das duas de que precisamos - um gato e um cachorro.
Para concluir a transferência do treinamento, pré-carregamos o vetor de recurso sem uma camada de classificação:

No Tensorflow, um vetor de recurso carregado pode ser usado como uma camada Keras comum com dados de entrada de um determinado tamanho.
Como o MobileNet foi treinado no conjunto de dados ImageNet, precisaremos trazer o tamanho dos dados de entrada para aqueles que foram usados no processo de treinamento. No nosso caso, o MobileNet foi treinado em imagens RGB de tamanho fixo de 224x224 px.
O TensorFlow contém um repositório pré-treinado chamado TensorFlow Hub.
O TensorFlow Hub contém alguns modelos pré-treinados nos quais a última camada de classificação foi excluída da arquitetura da rede neural para posterior reutilização.
Você pode usar o TensorFlow Hub no código em várias linhas:

Basta especificar a URL do vetor de recurso do modelo de treinamento desejado e, em seguida, incorporar o modelo em nosso classificador com a última camada com o número desejado de classes de saída. É a última camada que será submetida a treinamento e alteração dos valores dos parâmetros. A compilação e o treinamento do nosso novo modelo são realizados da mesma maneira que fizemos antes:
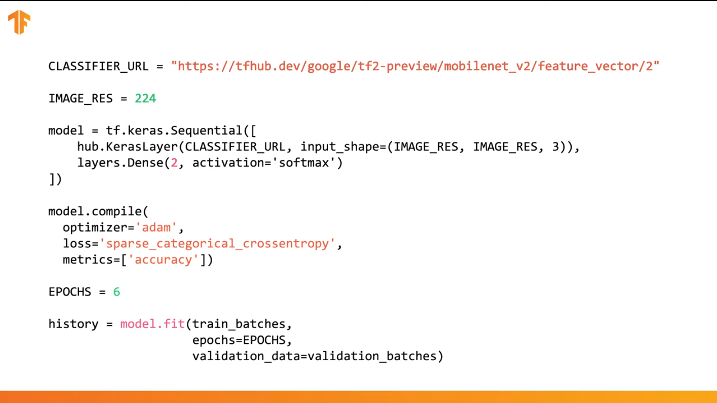
Vamos ver como isso realmente funciona e escrever o código apropriado.
CoLab: Gatos contra cães com treinamento de transferência
Link para o CoLab em russo e o CoLab em inglês .
O TensorFlow Hub é um repositório com modelos pré-treinados que podemos usar.
A transferência de aprendizado é um processo no qual pegamos um modelo pré-treinado e o expandimos para executar uma tarefa específica. Ao mesmo tempo, deixamos intactas a parte do modelo pré-treinado que integramos na rede neural, mas apenas treinamos as últimas camadas de saída para obter o resultado desejado.
Nesta parte prática, testaremos as duas opções.
Este link permite explorar a lista inteira de modelos disponíveis.
Nesta parte da Colab
- Usaremos o modelo do TensorFlow Hub para previsões;
- Usaremos o modelo TensorFlow Hub para o conjunto de dados de cães e gatos;
- Vamos transferir o treinamento usando o modelo do TensorFlow Hub.
Antes de prosseguir com a implementação da parte prática atual, recomendamos redefinir o Runtime -> Reset all runtimes...
Importações de bibliotecas
Nesta parte prática, usaremos vários recursos da biblioteca TensorFlow que ainda não estão no release oficial. É por isso que instalaremos primeiro a versão do TensorFlow e TensorFlow Hub para desenvolvedores.
A instalação da versão dev do TensorFlow ativa automaticamente a versão mais recente instalada. Depois de terminarmos de lidar com esta parte prática, recomendamos restaurar as configurações do TensorFlow e retornar à versão estável através do item de menu Runtime -> Reset all runtimes... A execução deste comando redefinirá todas as configurações do ambiente para as originais.
!pip install tf-nightly-gpu !pip install "tensorflow_hub==0.4.0" !pip install -U tensorflow_datasets
Conclusão:
Requirement already satisfied: absl-py>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.7.1) Requirement already satisfied: google-pasta>=0.1.6 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.1.7) Collecting tf-estimator-nightly (from tf-nightly-gpu) Downloading https://files.pythonhosted.org/packages/ea/72/f092fc631ef2602fd0c296dcc4ef6ef638a6a773cb9fdc6757fecbfffd33/tf_estimator_nightly-1.14.0.dev2019092201-py2.py3-none-any.whl (450kB) |████████████████████████████████| 450kB 45.9MB/s Requirement already satisfied: numpy<2.0,>=1.16.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.16.5) Requirement already satisfied: wrapt>=1.11.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.11.2) Requirement already satisfied: astor>=0.6.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.0.1) Requirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.33.6) Requirement already satisfied: h5py in /usr/local/lib/python3.6/dist-packages (from keras-applications>=1.0.8->tf-nightly-gpu) (2.8.0) Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (3.1.1) Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (41.2.0) Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (0.15.6) Installing collected packages: tb-nightly, tf-estimator-nightly, tf-nightly-gpu Successfully installed tb-nightly-1.15.0a20190911 tf-estimator-nightly-1.14.0.dev2019092201 tf-nightly-gpu-1.15.0.dev20190821 Collecting tensorflow_hub==0.4.0 Downloading https://files.pythonhosted.org/packages/10/5c/6f3698513cf1cd730a5ea66aec665d213adf9de59b34f362f270e0bd126f/tensorflow_hub-0.4.0-py2.py3-none-any.whl (75kB) |████████████████████████████████| 81kB 5.0MB/s Requirement already satisfied: protobuf>=3.4.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (3.7.1) Requirement already satisfied: numpy>=1.12.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.16.5) Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.12.0) Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.4.0->tensorflow_hub==0.4.0) (41.2.0) Installing collected packages: tensorflow-hub Found existing installation: tensorflow-hub 0.6.0 Uninstalling tensorflow-hub-0.6.0: Successfully uninstalled tensorflow-hub-0.6.0 Successfully installed tensorflow-hub-0.4.0 Collecting tensorflow_datasets Downloading https://files.pythonhosted.org/packages/6c/34/ff424223ed4331006aaa929efc8360b6459d427063dc59fc7b75d7e4bab3/tensorflow_datasets-1.2.0-py3-none-any.whl (2.3MB) |████████████████████████████████| 2.3MB 4.9MB/s Requirement already satisfied, skipping upgrade: future in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.16.0) Requirement already satisfied, skipping upgrade: wrapt in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.11.2) Requirement already satisfied, skipping upgrade: dill in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.3.0) Requirement already satisfied, skipping upgrade: numpy in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.16.5) Requirement already satisfied, skipping upgrade: requests>=2.19.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.21.0) Requirement already satisfied, skipping upgrade: tqdm in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (4.28.1) Requirement already satisfied, skipping upgrade: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (3.7.1) Requirement already satisfied, skipping upgrade: psutil in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (5.4.8) Requirement already satisfied, skipping upgrade: promise in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.2.1) Requirement already satisfied, skipping upgrade: absl-py in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.8.0) Requirement already satisfied, skipping upgrade: tensorflow-metadata in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.14.0) Requirement already satisfied, skipping upgrade: six in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.12.0) Requirement already satisfied, skipping upgrade: termcolor in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.1.0) Requirement already satisfied, skipping upgrade: attrs in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (19.1.0) Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2.8) Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2019.6.16) Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (3.0.4) Requirement already satisfied, skipping upgrade: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (1.24.3) Requirement already satisfied, skipping upgrade: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.6.1->tensorflow_datasets) (41.2.0) Requirement already satisfied, skipping upgrade: googleapis-common-protos in /usr/local/lib/python3.6/dist-packages (from tensorflow-metadata->tensorflow_datasets) (1.6.0) Installing collected packages: tensorflow-datasets Successfully installed tensorflow-datasets-1.2.0
Já vimos e usamos algumas importações antes. A partir do new - import tensorflow_hub , que instalamos e que usaremos nesta parte prática.
from __future__ import absolute_import, division, print_function, unicode_literals import matplotlib.pylab as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
Conclusão:
WARNING:tensorflow: TensorFlow's `tf-nightly` package will soon be updated to TensorFlow 2.0. Please upgrade your code to TensorFlow 2.0: * https://www.tensorflow.org/beta/guide/migration_guide Or install the latest stable TensorFlow 1.X release: * `pip install -U "tensorflow==1.*"` Otherwise your code may be broken by the change.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Parte 1: use o MobileNet do TensorFlow Hub para previsões
Nesta parte do CoLab, vamos pegar um modelo pré-treinado, carregá-lo no Keras e testá-lo.
O modelo que usamos é o MobileNet v2 (em vez do MobileNet, qualquer outro modelo de classificador de imagem compatível com tf2 com tfhub.dev pode ser usado).
Classificador de download
Faça o download do modelo MobileNet e crie um modelo Keras a partir dele. O MobileNet na entrada espera receber uma imagem de 224x224 pixels de tamanho com 3 canais de cores (RGB).
CLASSIFIER_URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2" IMAGE_RES = 224 model = tf.keras.Sequential([ hub.KerasLayer(CLASSIFIER_URL, input_shape=(IMAGE_RES, IMAGE_RES, 3)) ])
Execute o classificador em uma única imagem
O MobileNet foi treinado no conjunto de dados ImageNet. O ImageNet contém 1000 classes de saída e uma dessas classes é um uniforme militar. Vamos encontrar a imagem na qual o uniforme militar estará localizado e que não fará parte do kit de treinamento do ImageNet para verificar a precisão da classificação.
import numpy as np import PIL.Image as Image grace_hopper = tf.keras.utils.get_file('image.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg') grace_hopper = Image.open(grace_hopper).resize((IMAGE_RES, IMAGE_RES)) grace_hopper
Conclusão:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg 65536/61306 [================================] - 0s 0us/step

grace_hopper = np.array(grace_hopper)/255.0 grace_hopper.shape
Conclusão:
(224, 224, 3)
Lembre-se de que os modelos sempre recebem um conjunto (bloco) de imagens para processamento na entrada. No código abaixo, adicionamos uma nova dimensão - o tamanho do bloco.
result = model.predict(grace_hopper[np.newaxis, ...]) result.shape
Conclusão:
(1, 1001)
O resultado da previsão foi um vetor com um tamanho de 1.001 elementos, em que cada valor representa a probabilidade de o objeto na imagem pertencer a uma determinada classe.
A posição do valor máximo de probabilidade pode ser encontrada usando a função argmax . No entanto, há uma pergunta que ainda não respondemos - como podemos determinar a qual classe um elemento pertence com probabilidade máxima?
predicted_class = np.argmax(result[0], axis=-1) predicted_class
Conclusão:
653
Decifrando previsões
Para determinarmos a classe à qual as previsões se relacionam, carregamos a lista de tags ImageNet e, pelo índice com fidelidade máxima, determinamos a classe à qual a previsão se refere.
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt') imagenet_labels = np.array(open(labels_path).read().splitlines()) plt.imshow(grace_hopper) plt.axis('off') predicted_class_name = imagenet_labels[predicted_class] _ = plt.title("Prediction: " + predicted_class_name.title())
Conclusão:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt 16384/10484 [==============================================] - 0s 0us/step

Bingo! Nosso modelo identificou corretamente o uniforme militar.
Parte 2: use o modelo do TensorFlow Hub para um conjunto de dados de gatos e cães
Agora vamos usar a versão completa do modelo MobileNet e ver como ele lida com o conjunto de dados de cães e gatos.
Conjunto de dados
Podemos usar os conjuntos de dados TensorFlow para baixar um conjunto de dados de gatos e cães.
splits = tfds.Split.ALL.subsplit(weighted=(80, 20)) splits, info = tfds.load('cats_vs_dogs', with_info=True, as_supervised=True, split = splits) (train_examples, validation_examples) = splits num_examples = info.splits['train'].num_examples num_classes = info.features['label'].num_classes
Conclusão:
Downloading and preparing dataset cats_vs_dogs (786.68 MiB) to /root/tensorflow_datasets/cats_vs_dogs/2.0.1... /usr/local/lib/python3.6/dist-packages/urllib3/connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) WARNING:absl:1738 images were corrupted and were skipped Dataset cats_vs_dogs downloaded and prepared to /root/tensorflow_datasets/cats_vs_dogs/2.0.1. Subsequent calls will reuse this data.
Nem todas as imagens em um conjunto de dados de gato e cachorro são do mesmo tamanho.
for i, example_image in enumerate(train_examples.take(3)): print("Image {} shape: {}".format(i+1, example_image[0].shape))
Conclusão:
Image 1 shape: (500, 343, 3) Image 2 shape: (375, 500, 3) Image 3 shape: (375, 500, 3)
Portanto, as imagens do conjunto de dados obtidos requerem redução para um tamanho único, o que o modelo MobileNet espera na entrada - 224 x 224.
A função .repeat() e steps_per_epoch não são necessárias aqui, mas permitem economizar cerca de 15 segundos por iteração de treinamento, porque o buffer temporário deve ser inicializado apenas uma vez no início do processo de aprendizado.
def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES)) / 255.0 return image, label BATCH_SIZE = 32 train_batches = train_examples.shuffle(num_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_examples.map(format_image).batch(BATCH_SIZE).prefetch(1)
Execute o classificador em conjuntos de imagens
Deixe-me lembrá-lo de que, nesta etapa, ainda existe uma versão completa da rede MobileNet pré-treinada, que contém 1.000 classes de saída possíveis. O ImageNet contém um grande número de imagens de cães e gatos; portanto, vamos tentar inserir uma das imagens de teste do nosso conjunto de dados e ver qual previsão o modelo nos dará.
image_batch, label_batch = next(iter(train_batches.take(1))) image_batch = image_batch.numpy() label_batch = label_batch.numpy() result_batch = model.predict(image_batch) predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)] predicted_class_names
Conclusão:
array(['Persian cat', 'mink', 'Siamese cat', 'tabby', 'Bouvier des Flandres', 'dishwasher', 'Yorkshire terrier', 'tiger cat', 'tabby', 'Egyptian cat', 'Egyptian cat', 'tabby', 'dalmatian', 'Persian cat', 'Border collie', 'Newfoundland', 'tiger cat', 'Siamese cat', 'Persian cat', 'Egyptian cat', 'tabby', 'tiger cat', 'Labrador retriever', 'German shepherd', 'Eskimo dog', 'kelpie', 'mink', 'Norwegian elkhound', 'Labrador retriever', 'Egyptian cat', 'computer keyboard', 'boxer'], dtype='<U30')
Os rótulos são semelhantes aos nomes de raças de cães e gatos. Vamos agora exibir algumas imagens do nosso conjunto de dados de cães e gatos e colocar um rótulo previsto em cada um deles.
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) plt.title(predicted_class_names[n]) plt.axis('off') _ = plt.suptitle("ImageNet predictions")

Parte 3: Implementar a transferência de aprendizado com o hub TensorFlow
Agora vamos usar o TensorFlow Hub para transferir a aprendizagem de um modelo para outro.
No processo de transferência de treinamento, reutilizamos um modelo pré-treinado alterando sua última camada ou várias camadas e, em seguida, iniciamos o processo de treinamento novamente em um novo conjunto de dados.
No TensorFlow Hub, você pode encontrar não apenas modelos pré-treinados completos (com a última camada), mas também modelos sem a última camada de classificação. Este último pode ser facilmente usado para transferir treinamento. Continuaremos a usar o MobileNet v2 pelo simples motivo de que, nas partes subseqüentes de nosso curso, transferiremos esse modelo e o iniciaremos em um dispositivo móvel usando o TensorFlow Lite.
Também continuaremos a usar o conjunto de dados de cães e gatos, para que tenhamos a oportunidade de comparar o desempenho desse modelo com os que implementamos do zero.
Observe que chamamos o modelo parcial com o Hub TensorFlow (sem a última camada de classificação) feature_extractor . Esse nome é explicado pelo fato de o modelo aceitar dados como entrada e transformá-los em um conjunto finito de propriedades selecionadas (características). Assim, nosso modelo identificou o conteúdo da imagem, mas não produziu a distribuição final de probabilidade sobre as classes de saída. O modelo extraiu um conjunto de propriedades da imagem.
URL = 'https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2' feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
Vamos executar um conjunto de imagens através do feature_extractor e ver o formulário resultante (formato de saída). 32 - o número de imagens, 1280 - o número de neurônios na última camada do modelo pré-treinado com o TensorFlow Hub.
feature_batch = feature_extractor(image_batch) print(feature_batch.shape)
Conclusão:
(32, 1280)
Congelamos as variáveis na camada de extração de propriedades para que apenas os valores das variáveis da camada de classificação sejam alteradas durante o processo de treinamento.
feature_extractor.trainable = False
Adicionar uma camada de classificação
Agora envolva a camada do TensorFlow Hub no modelo tf.keras.Sequential e adicione uma camada de classificação.
model = tf.keras.Sequential([ feature_extractor, layers.Dense(2, activation='softmax') ]) model.summary()
Conclusão:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 2) 2562 ================================================================= Total params: 2,260,546 Trainable params: 2,562 Non-trainable params: 2,257,984 _________________________________________________________________
Modelo de trem
Agora, treinamos o modelo resultante da maneira que fizemos antes de chamar a compile seguida pela fit ao treinamento.
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'] ) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
Conclusão:
Epoch 1/6 582/582 [==============================] - 77s 133ms/step - loss: 0.2381 - acc: 0.9346 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 582/582 [==============================] - 70s 120ms/step - loss: 0.1827 - acc: 0.9618 - val_loss: 0.1629 - val_acc: 0.9670 Epoch 3/6 582/582 [==============================] - 69s 119ms/step - loss: 0.1733 - acc: 0.9660 - val_loss: 0.1623 - val_acc: 0.9666 Epoch 4/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1677 - acc: 0.9676 - val_loss: 0.1627 - val_acc: 0.9677 Epoch 5/6 582/582 [==============================] - 68s 118ms/step - loss: 0.1636 - acc: 0.9689 - val_loss: 0.1634 - val_acc: 0.9675 Epoch 6/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1604 - acc: 0.9701 - val_loss: 0.1643 - val_acc: 0.9668
Como você provavelmente notou, conseguimos atingir ~ 97% de precisão das previsões no conjunto de dados de validação. Awesome! A abordagem atual aumentou significativamente a precisão da classificação em comparação com o primeiro modelo que treinamos e obtivemos uma precisão de classificação de ~ 87%. O motivo é que o MobileNet foi projetado por especialistas e cuidadosamente desenvolvido por um longo período de tempo, e depois treinado em um conjunto de dados ImageNet incrivelmente grande.
Você pode ver como criar seu próprio MobileNet em Keras neste link .
Vamos criar gráficos de alterações nos valores de precisão e perda nos conjuntos de dados de treinamento e validação.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.show()
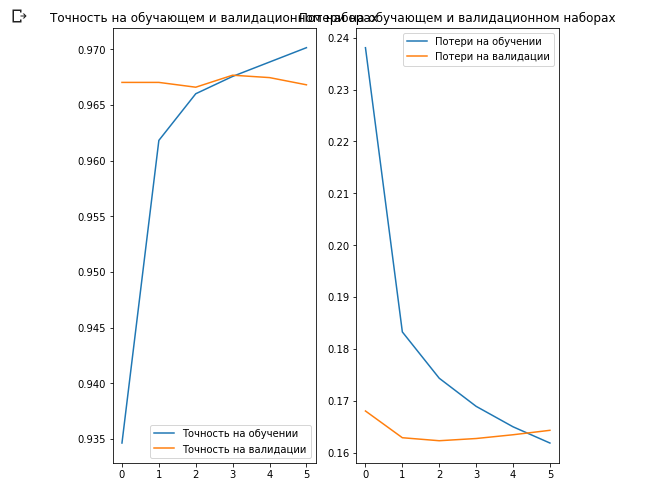
O interessante aqui é que os resultados no conjunto de dados de validação são melhores do que os resultados no conjunto de dados de treinamento desde o início até o final do processo de aprendizado.
Uma razão para esse comportamento é que a precisão no conjunto de dados de validação é medida no final da iteração de treinamento, e a precisão no conjunto de dados de treinamento é considerada como o valor médio entre todas as iterações de treinamento.
A maior razão para esse comportamento é o uso da sub-rede MobileNet pré-treinada, que foi treinada anteriormente em um grande conjunto de dados de cães e gatos. No processo de aprendizado, nossa rede continua expandindo o conjunto de dados de treinamento de entrada (o mesmo aumento), mas não o conjunto de validação. Isso significa que as imagens geradas no conjunto de dados de treinamento são mais difíceis de classificar do que as imagens normais do conjunto de dados validado.
Verificar resultados da previsão
Para repetir o gráfico da seção anterior, primeiro você precisa obter uma lista classificada de nomes de classe:
class_names = np.array(info.features['label'].names) class_names
Conclusão:
array(['cat', 'dog'], dtype='<U3')
Passe o bloco com imagens pelo modelo e converta os índices resultantes em nomes de classe:
predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] predicted_class_names
Conclusão:
array(['cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'dog', 'dog', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog'], dtype='<U3')
Vamos dar uma olhada nos rótulos verdadeiros e previstos:
print(": ", label_batch) print(": ", predicted_ids)
Conclusão:
: [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 1 1 0 0 1] : [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 1 0 0 1]
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle(" (: , : )")

Mergulhando em redes neurais convolucionais
Usando redes neurais convolucionais, conseguimos garantir que eles lidem bem com a tarefa de classificar imagens. No entanto, no momento, mal podemos imaginar como eles realmente funcionam. Se pudéssemos entender como o processo de aprendizagem ocorre, então, em princípio, poderíamos melhorar ainda mais o trabalho de classificação. Uma maneira de entender como as redes neurais convolucionais funcionam é visualizar as camadas e os resultados de seu trabalho. É altamente recomendável que você estude os materiais aqui para entender melhor como visualizar os resultados das camadas convolucionais.

O campo da visão computacional viu a luz no fim do túnel e fez progressos significativos desde o advento das redes neurais convolucionais. A incrível velocidade com que as pesquisas são realizadas nessa área e as enormes séries de imagens publicadas na Internet deram resultados incríveis nos últimos anos. A ascensão das redes neurais convolucionais começou com a AlexNet em 2012, criada por Alex Krizhevsky, Ilya Sutskever e Jeffrey Hinton e ganhou o famoso Desafio de reconhecimento visual em grande escala ImageNet. Desde então, não havia dúvida no futuro brilhante usando redes neurais convolucionais, e o campo da visão computacional e os resultados do trabalho nele apenas confirmaram esse fato. Começando com o reconhecimento do seu rosto em um telefone celular e terminando com o reconhecimento de objetos em carros autônomos, as redes neurais convolucionais já conseguiram mostrar e provar sua força e resolver muitos problemas do mundo real.
Apesar do grande número de grandes conjuntos de dados e modelos pré-treinados de redes neurais convolucionais, às vezes é extremamente difícil entender como a rede funciona e para que exatamente essa rede é treinada, especialmente para pessoas que não têm conhecimento suficiente no campo de aprendizado de máquina. , , , Inception, . . , , , , .
" Python"
François Chollet. , . Keras, , " " TensorFlow, MXNET Theano. , , . , .
, , .
(training accuracy) . , , , , Inception, .
, , . Inception v3 ( ImageNet) , Kaggle. Inception, , Inception v3 .
10 () 32 , 2292293. 0.3195, — 0.6377. ImageDataGenerator , . GitHub .
, "" , . .
, Inception v3 , .

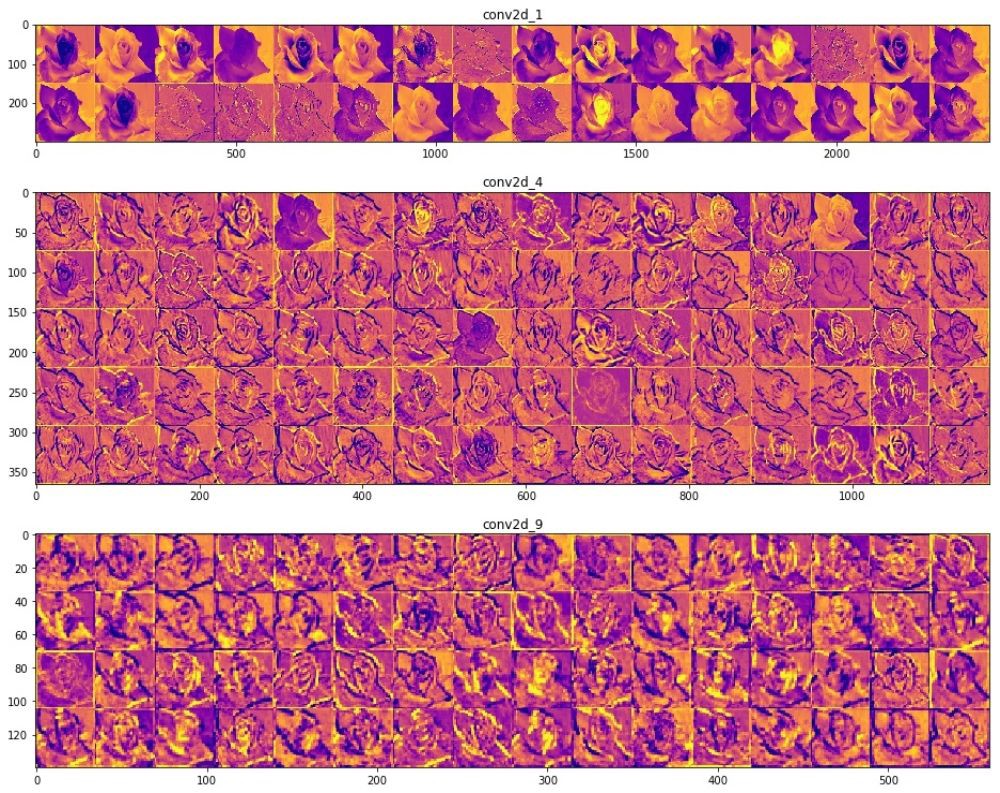
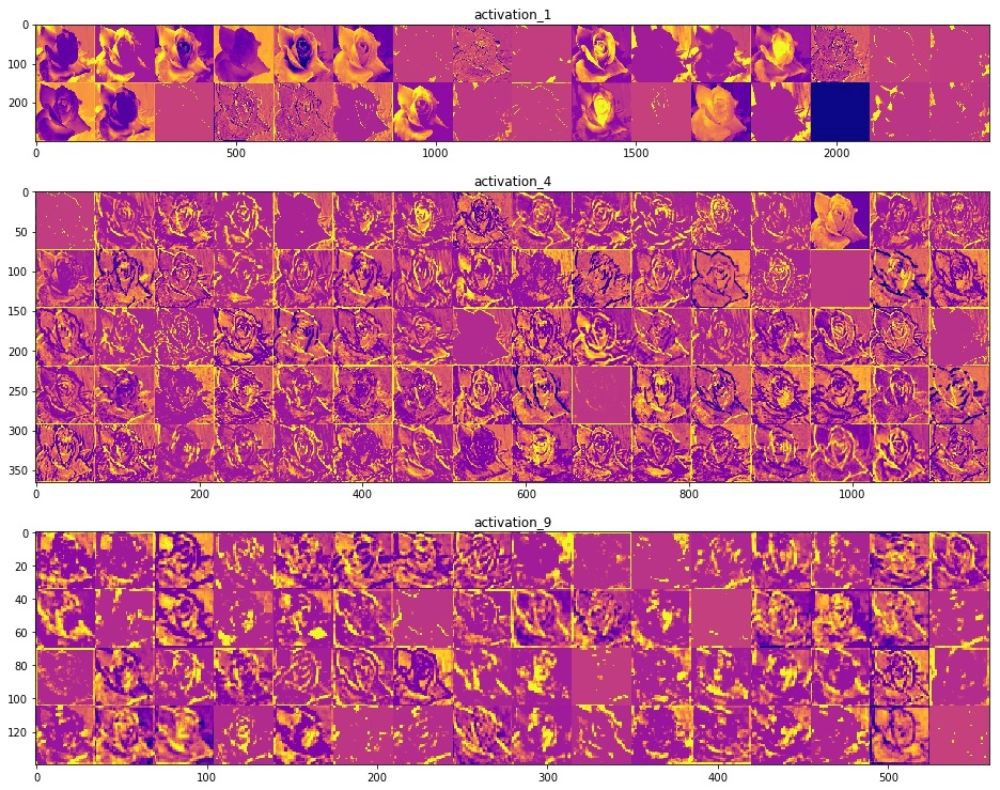
— . .
, () . (), , , , . , , , , .
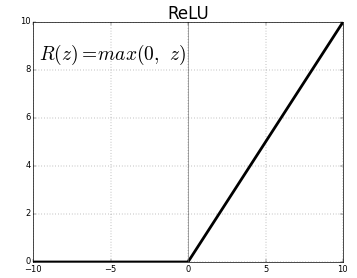
ReLU- . , ReLU(z) = max(0, z) .
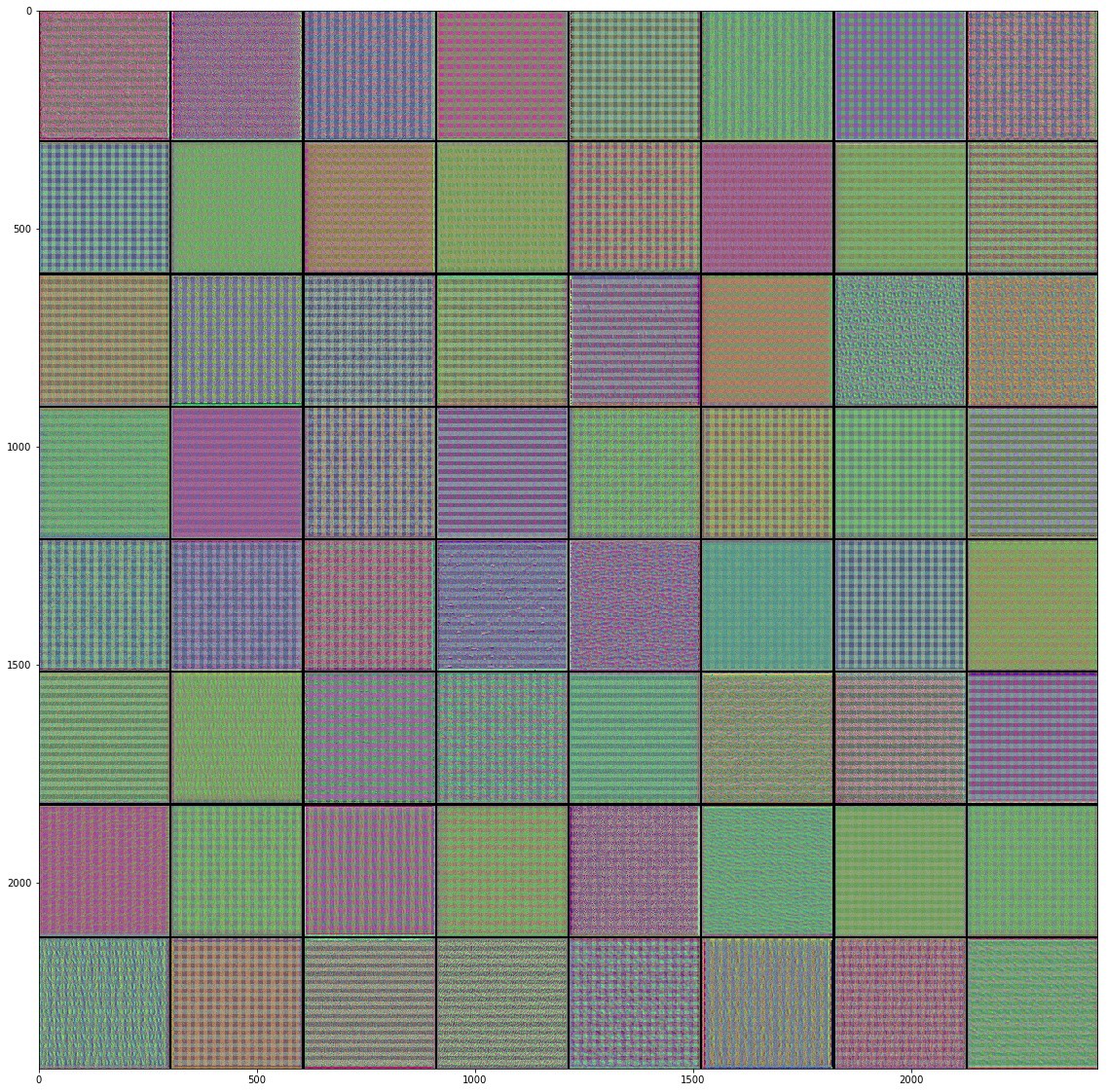
, , , , , , , , .. , . "" () , , , .
"" . .
, Inveption V3 :
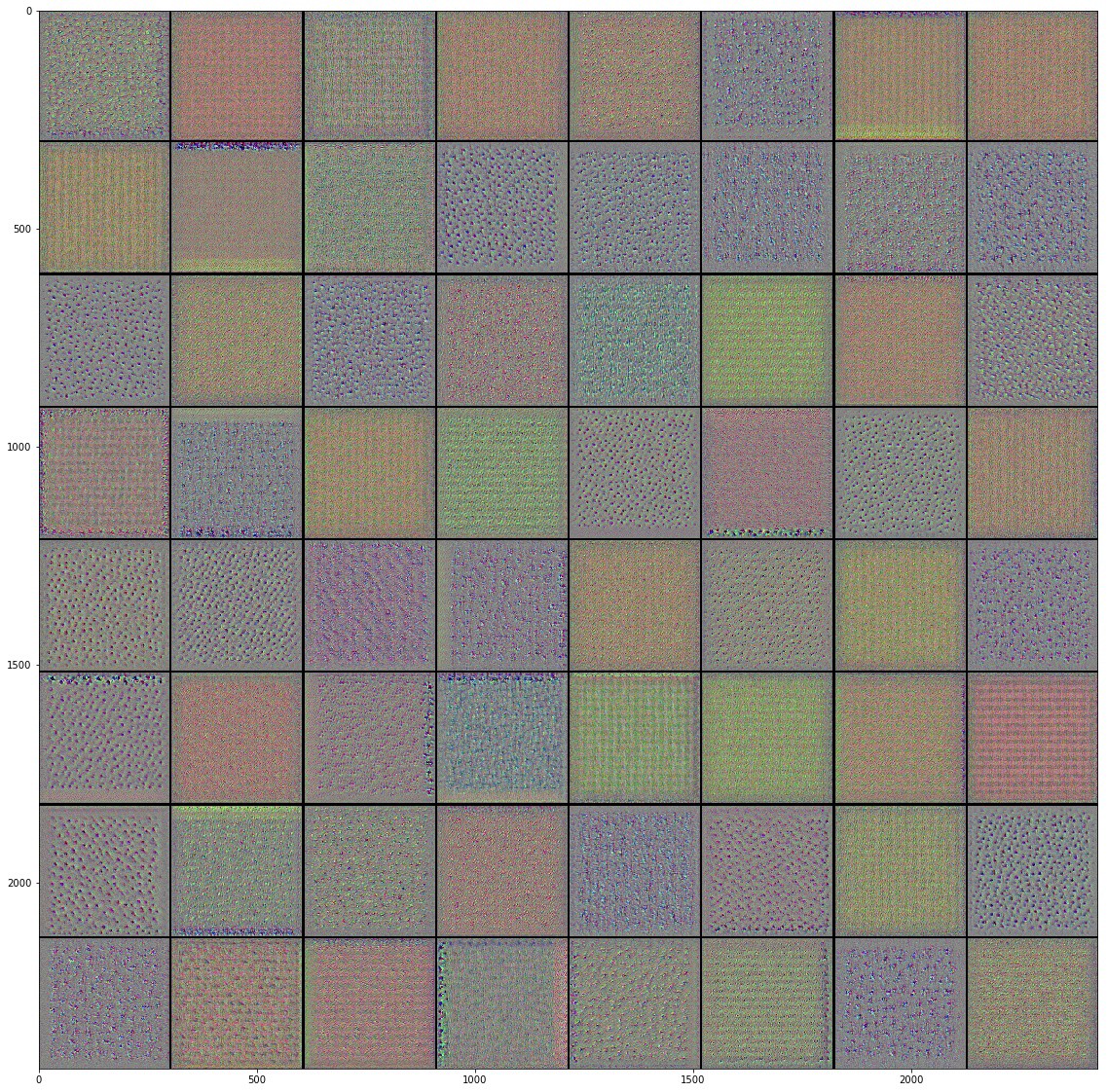

, . , , , , .. , , . , , , "" ( , ).
, , , . , .
Class Activation Map ( ). CAM . 2D , .
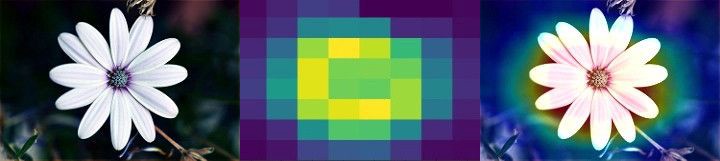

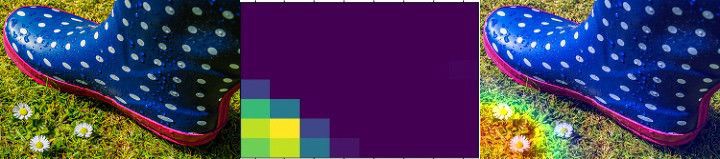
, . , , Mixed- Inception V3-, . () , .
, , . , , . , . , , , , .
, "" - . . .
, , .
:
Colab Colab .
TensorFlow Hub
TensorFlow Hub , .
. , , , .
.
Runtime -> Reset all runtimes...
, :
from __future__ import absolute_import, division, print_function, unicode_literals import numpy as np import matplotlib.pyplot as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
:
WARNING:tensorflow: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons * https://github.com/tensorflow/io (for I/O related ops) If you depend on functionality not listed there, please file an issue.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
TensorFlow Datasets
TensorFlow Datasets. , — tf_flowers . , . tfds.splits (70%) (30%). tfds.load . tfds.load , , .
splits = tfds.Split.TRAIN.subsplit([70, 30]) (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits)
:
Downloading and preparing dataset tf_flowers (218.21 MiB) to /root/tensorflow_datasets/tf_flowers/1.0.0... Dl Completed... 1/|/100% 1/1 [00:07<00:00, 3.67s/ url] Dl Size... 218/|/100% 218/218 [00:07<00:00, 30.69 MiB/s] Extraction completed... 1/|/100% 1/1 [00:07<00:00, 7.05s/ file] Dataset tf_flowers downloaded and prepared to /root/tensorflow_datasets/tf_flowers/1.0.0. Subsequent calls will reuse this data.
, , () , , — .
num_classes = dataset_info.features['label'].num_classes num_training_examples = 0 num_validation_examples = 0 for example in training_set: num_training_examples += 1 for example in validation_set: num_validation_examples += 1 print('Total Number of Classes: {}'.format(num_classes)) print('Total Number of Training Images: {}'.format(num_training_examples)) print('Total Number of Validation Images: {} \n'.format(num_validation_examples))
:
Total Number of Classes: 5 Total Number of Training Images: 2590 Total Number of Validation Images: 1080
— .
for i, example in enumerate(training_set.take(5)): print('Image {} shape: {} label: {}'.format(i+1, example[0].shape, example[1]))
:
Image 1 shape: (226, 240, 3) label: 0 Image 2 shape: (240, 145, 3) label: 2 Image 3 shape: (331, 500, 3) label: 2 Image 4 shape: (240, 320, 3) label: 0 Image 5 shape: (333, 500, 3) label: 1
— , MobilNet v2 — 224224 (grayscale). image () label () .
IMAGE_RES = 224 def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES))/255.0 return image, label BATCH_SIZE = 32 train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1)
TensorFlow Hub
TensorFlow Hub . , , .
feature_extractor MobileNet v2. , TensorFlow Hub ( ) . . tf2-preview/mobilenet_v2/feature_vector , URL MobileNet v2 . feature_extractor hub.KerasLayer input_shape .
URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
, :
feature_extractor.trainable = False
, . . .
model = tf.keras.Sequential([ feature_extractor, layers.Dense(num_classes, activation='softmax') ]) model.summary()
:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 5) 6405 ================================================================= Total params: 2,264,389 Trainable params: 6,405 Non-trainable params: 2,257,984
, .
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 17s 216ms/step - loss: 0.7765 - acc: 0.7170 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 12s 147ms/step - loss: 0.3806 - acc: 0.8757 - val_loss: 0.3485 - val_acc: 0.8833 Epoch 3/6 81/81 [==============================] - 12s 146ms/step - loss: 0.3011 - acc: 0.9031 - val_loss: 0.3190 - val_acc: 0.8907 Epoch 4/6 81/81 [==============================] - 12s 147ms/step - loss: 0.2527 - acc: 0.9205 - val_loss: 0.3031 - val_acc: 0.8917 Epoch 5/6 81/81 [==============================] - 12s 148ms/step - loss: 0.2177 - acc: 0.9371 - val_loss: 0.2933 - val_acc: 0.8972 Epoch 6/6 81/81 [==============================] - 12s 146ms/step - loss: 0.1905 - acc: 0.9456 - val_loss: 0.2870 - val_acc: 0.9000
~90% 6 , ! , , ~76% 80 . , MobilNet v2 .
.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.show()
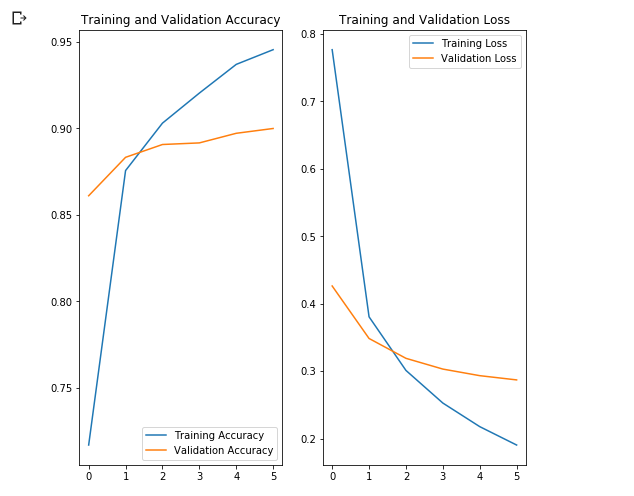
, , .
, , .
- MobileNet, . ( augmentation), . .
NumPy. , .
class_names = np.array(dataset_info.features['label'].names) print(class_names)
:
['dandelion' 'daisy' 'tulips' 'sunflowers' 'roses']
next() image_batch ( ) label_batch ( ). image_batch label_batch NumPy .numpy() . .predict() . np.argmax() . .
image_batch, label_batch = next(iter(train_batches)) image_batch = image_batch.numpy() label_batch = label_batch.numpy() predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] print(predicted_class_names)
:
['sunflowers' 'roses' 'tulips' 'tulips' 'daisy' 'dandelion' 'tulips' 'sunflowers' 'daisy' 'daisy' 'tulips' 'daisy' 'daisy' 'tulips' 'tulips' 'tulips' 'dandelion' 'dandelion' 'tulips' 'tulips' 'dandelion' 'roses' 'daisy' 'daisy' 'dandelion' 'roses' 'daisy' 'tulips' 'dandelion' 'dandelion' 'roses' 'dandelion']
print("Labels: ", label_batch) print("Predicted labels: ", predicted_ids)
:
Labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0] Predicted labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0]
plt.figure(figsize=(10,9)) for n in range(30): plt.subplot(6,5,n+1) plt.subplots_adjust(hspace = 0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")

Inception-
TensorFlow Hub tf2-preview/inception_v3/feature_vector . Inception V3 . , Inception V3 . , Inception V3 299299 . Inception V3 MobileNet V2.
IMAGE_RES = 299 (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits) train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1) URL = "https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3), trainable=False) model_inception = tf.keras.Sequential([ feature_extractor, tf.keras.layers.Dense(num_classes, activation='softmax') ]) model_inception.summary()
:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 2048) 21802784 _________________________________________________________________ dense_1 (Dense) (None, 5) 10245 ================================================================= Total params: 21,813,029 Trainable params: 10,245 Non-trainable params: 21,802,784
model_inception.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model_inception.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 44s 541ms/step - loss: 0.7594 - acc: 0.7309 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3927 - acc: 0.8772 - val_loss: 0.3945 - val_acc: 0.8657 Epoch 3/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3074 - acc: 0.9120 - val_loss: 0.3586 - val_acc: 0.8769 Epoch 4/6 81/81 [==============================] - 35s 434ms/step - loss: 0.2588 - acc: 0.9282 - val_loss: 0.3385 - val_acc: 0.8796 Epoch 5/6 81/81 [==============================] - 35s 436ms/step - loss: 0.2252 - acc: 0.9375 - val_loss: 0.3256 - val_acc: 0.8824 Epoch 6/6 81/81 [==============================] - 35s 435ms/step - loss: 0.1996 - acc: 0.9440 - val_loss: 0.3164 - val_acc: 0.8861
Sumário
. :
- : , . .
- : . "" , , .
- MobileNet: Google, . MobileNet .
MobileNet . . MobileNet .
… call-to-action — , share :)
YouTube
Telegram
VKontakte
Ojok .