Olá pessoal!
Eu já falei neste blog sobre a organização de um sistema modular de monitoramento para arquitetura de microsserviços e sobre a transição do Graphite + Whisper para Graphite + ClickHouse para armazenar métricas sob altas cargas. Depois disso, meu colega Sergey Noskov escreveu sobre o primeiro link do nosso sistema de monitoramento - o Bioyino desenvolvido por nós, um agregador de métricas escaláveis distribuídas.
Chegou a hora de atualizar as informações sobre como estamos preparando o monitoramento no Avito - nosso último artigo já estava em 2018 e, durante esse período, houve várias mudanças interessantes na arquitetura de monitoramento, gerenciamento de gatilhos e notificações, várias otimizações de dados no ClickHouse e outras inovações, sobre o qual eu só quero lhe contar.

Mas vamos começar em ordem.
Em 2017, mostrei um diagrama da interação dos componentes que era relevante naquele momento e gostaria de demonstrá-lo novamente para que você não precise alternar as guias novamente.

A partir desse momento, aconteceu o seguinte.
O número de servidores no cluster Graphite aumentou de 3 para 6.
( 56 CPU 2.60GHz, 384GB RAM, 10 SSD SAS 745GB, Raid 6, 10GBit/s Net ).
Substituímos brubeck por bioyino - nossa própria implementação do StatsD pelo Rust, e até escrevemos um artigo inteiro sobre isso . No entanto, após o lançamento do artigo, criamos suporte para tags (Graphite) e Raft nele para selecionar um líder.
Nós estudamos a possibilidade de usar o bioyino como um agente StatsD e colocamos esses agentes ao lado das instâncias do monólito, bem como onde era necessário nos k8s.
Finalmente nos livramos do antigo sistema de monitoramento Munin (formalmente ainda o temos, mas seus dados não são mais usados).
A coleta de dados dos clusters do Kubernetes foi organizada por meio do Prometheus / Federations, pois o Heapster não era suportado em novas versões do Kubernetes.
Monitoramento
Nos últimos dois anos, o número de métricas aceitas e processadas aumentou cerca de 9 vezes.
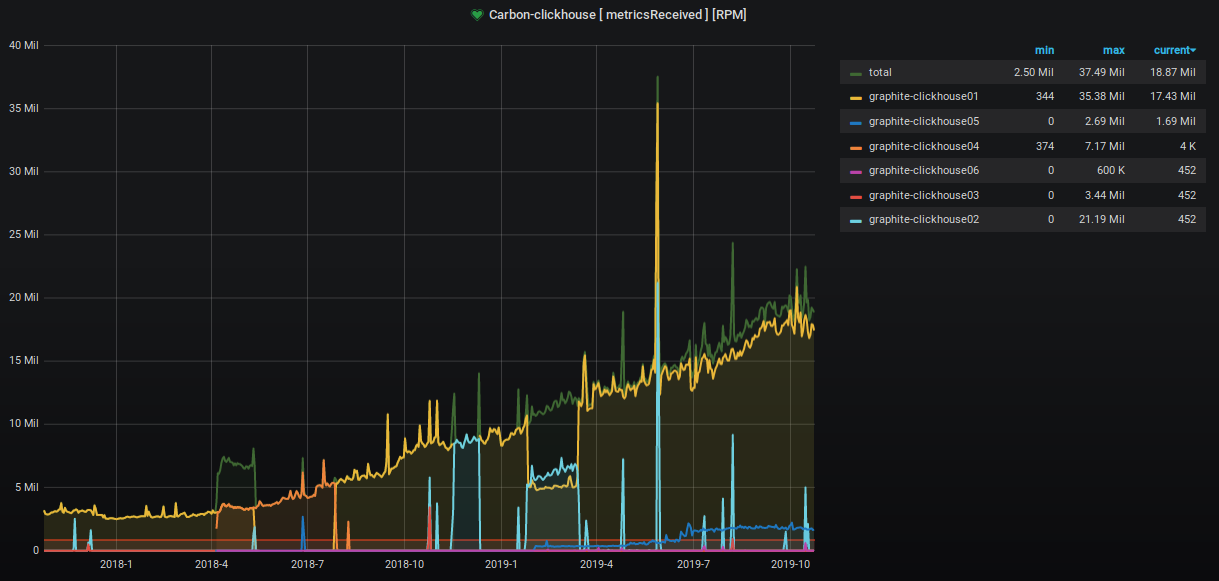
A porcentagem de espaço ocupado no servidor também está aumentando inexoravelmente e estamos tomando várias medidas para reduzi-lo. Isso é claramente visível no gráfico.
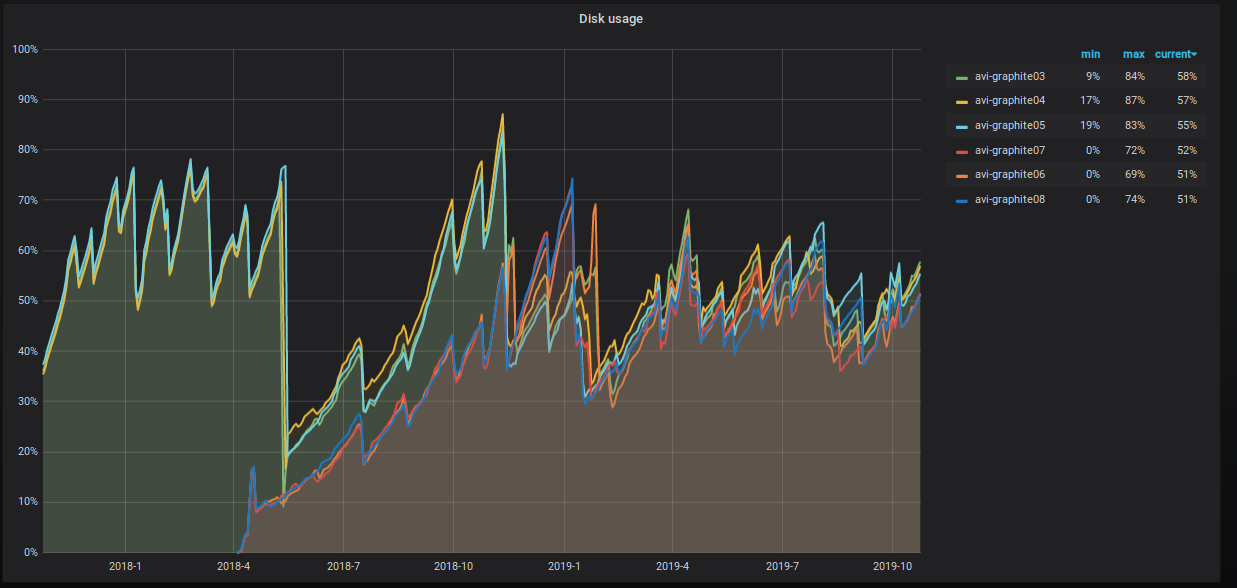
O que exatamente estamos fazendo?
10 10 10 * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data' and max_date between today()-55 AND today()-35;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "OPTIMIZE TABLE graphite.data PARTITION ('"$PART"') FINAL";done
- Nós compartilhamos tabelas de dados. Agora, temos três shards com duas réplicas, cada uma com uma chave de sharding sharding em nome da métrica. Essa abordagem nos dá a oportunidade de executar procedimentos de rollup , pois todos os valores para uma métrica específica estão no mesmo shard e o espaço em disco em todos os shards é usado de maneira uniforme.
O esquema da tabela distribuída é o seguinte.
CREATE TABLE graphite.data_all ( `Path` String, `Value` Float64, `Time` UInt32, `Date` Date, `Timestamp` UInt32 ) ENGINE = Distributed ( 'graphite_cluster', 'graphite', 'data', jumpConsistentHash(cityHash64(Path), 3) )
Também atribuímos ao usuário direitos de leitura "padrão" e jogamos a execução de procedimentos de gravação nas tabelas para um sistema de usuário separado systemXXX .
A configuração do cluster Graphite no ClickHouse é a seguinte.
<remote_servers> <graphite_cluster> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse01</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse04</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse02</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse05</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse03</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse06</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> </graphite_cluster> </remote_servers>
Além da carga de gravação, o número de solicitações para ler dados do Graphite aumentou. Esses dados são usados para:
- processamento de gatilho e geração de alerta;
- exibindo gráficos em monitores no escritório e telas de laptop e PC de um número crescente de funcionários da empresa.
Para impedir que o monitoramento se afogue sob essa carga, usamos outro hack: armazenamos os dados dos últimos dois dias em uma placa “pequena” separada e enviamos todas as solicitações de leitura dos últimos dois dias, reduzindo a carga na tabela principal do shard. Também para este tablet "pequeno", usamos um esquema de armazenamento métrico reverso, que acelerou bastante a pesquisa dos dados contidos nele e organizou uma partição diária para ele. O esquema desta placa é o seguinte.
CREATE TABLE graphite.data_reverse ( `Path` String, `Value` Float64, `Time` UInt32 CODEC(Delta(4), ZSTD(1)), `Date` Date, `Timestamp` UInt32 ) ENGINE = ReplicatedGraphiteMergeTree ( '/clickhouse/tables/{cluster}/data_reverse', '{replica}', 'graphite_rollup' ) PARTITION BY Date ORDER BY (Path, Time) SETTINGS index_granularity = 4096
Para direcionar dados, adicionamos uma nova seção ao arquivo de configuração do aplicativo carbon-clickhouse .
[upload.graphite_reverse] type = "points-reverse" table = "graphite.data_reverse" threads = 2 url = "http://systemXXX:XXXXXXX@localhost:8123/" timeout = "60s" cache-ttl = "6h0m0s" zero-timestamp = true
Para excluir partições com mais de dois dias, escrevemos uma tarefa cron. Parece algo assim.
1 12 * * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data_reverse' and max_date<today()-2;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "ALTER TABLE graphite.data_reverse DROP PARTITION ('"$PART"')";done
Para ler os dados da tabela, no arquivo de configuração grafite-clickhouse , uma seção foi adicionada:
[[data-table]] table = "graphite.data_reverse" max-age = "48h" reverse = true
Como resultado, temos uma tabela com 100% dos dados replicados para todos os seis servidores que processam toda a carga de leitura de solicitações com uma janela de menos de dois dias (e temos 95% deles). E também temos uma tabela fragmentada com 1/3 dos dados em cada shard, que fornece a leitura de todos os dados históricos. E mesmo que essas solicitações sejam muito menores, a carga delas é muito maior.
O que está acontecendo com a CPU ?! Como resultado do aumento no volume de dados gravados e lidos no cluster Graphite, a carga total da CPU nos servidores também aumentou. Parece algo assim.
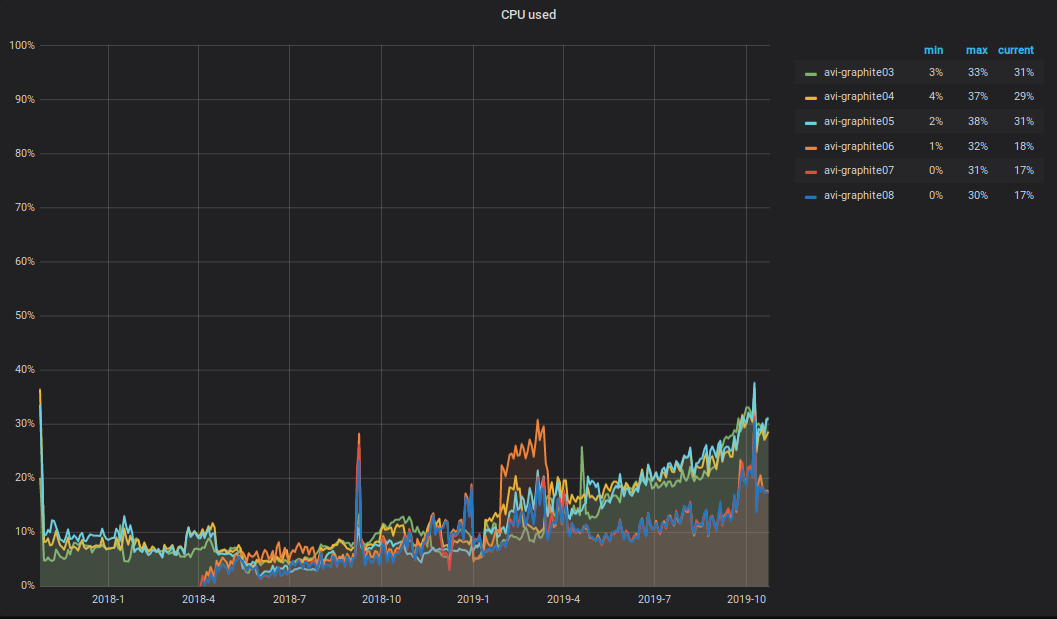
Gostaria de chamar a atenção para as seguintes nuances: metade da CPU vai para análise e processamento primário de métricas em relé carbono-c (v3.2 de 05-09-2018, que é responsável pelo transporte de métricas), localizado em três dos seis servidores. Como você pode ver no gráfico, são esses três servidores que estão no TOP.
Alerta
Como sistema de alerta, ainda temos o Moira e o cliente do moira escritos para ele. Para um gerenciamento flexível de gatilhos, notificações e escalações, usamos uma descrição declarativa chamada alert.yaml. Ele é gerado automaticamente quando um serviço é criado via PaaS (mais sobre isso pode ser encontrado no artigo de Vadim Madison “O que sabemos sobre microsserviços” ) e é colocado em seu repositório. Para trabalhar com alert.yaml, criamos uma ligação no moira-client e chamamos de alert-autoconf (estamos planejando abrir). Há uma etapa na montagem do serviço no TeamCity com a exportação de gatilhos e notificações para o Moira via alert-autoconf. Ao confirmar as alterações no alert.yaml, são executados testes automáticos que verificam a validade do arquivo yaml e também fazem solicitações ao Graphite para cada modelo de métrica, a fim de verificar sua correção.
Para equipes de infraestrutura que não usam PaaS, organizamos um repositório separado chamado Alerting. Ele criou a estrutura do formulário: Team / Project / alert.yaml. Para cada alert.yaml, geramos um assembly separado no TeamCity, que executa testes e envia o conteúdo do alert.yaml no Moira.
Assim, todos os nossos funcionários podem gerenciar seus gatilhos, notificações e escalações usando uma única abordagem.
Como antes já tínhamos gatilhos acionados por meio da GUI, implementamos a capacidade de enviá-los no formato yaml. O conteúdo do documento yaml recebido pode ser inserido em alert.yaml praticamente sem transformações adicionais e, em seguida, envie as alterações ao assistente. Durante a compilação, o alert-autoconf entenderá que esse gatilho já existe e o registrará em nosso registro no Redis.
E não faz muito tempo, recebemos uma troca de engenheiros 24x7. Para transferir gatilhos para eles para manutenção, basta o seu alerta.yaml preencher corretamente a descrição de "o que fazer se você o vir", colocar a tag [24x7] e enviar as alterações ao assistente. Após rolar alert.yaml, todos os gatilhos descritos nele cairão automaticamente no monitoramento de turno de 24 horas 24x7. U - Simplifique! Beleza!
Coleção de métricas de negócios
Desde o último artigo sobre a coleta e o processamento de métricas de negócios, nosso bioyino se tornou ainda melhor.
- Em vez de escolher um líder através do Consul , a jangada interna é usada .
- As tags são processadas corretamente no formato Grafite .
- Agora você pode usar o bioyino (servidor StatsD) como um agente.
- Para contar valores exclusivos, o formato "set" é suportado.
- A agregação final de métricas pode ser feita em vários threads.
- Os dados podem ser enviados para pedaços de grafite em várias conexões paralelas.
- Corrigidos todos os erros encontrados.
Agora funciona assim.
Começamos a apresentar ativamente os agentes StatsD ao lado de todos os grandes geradores de métricas grandes: em contêineres com instâncias de monólito, em pods de k8s próximos a serviços, em hosts com componentes de infraestrutura etc.
O agente Statsd está localizado próximo ao aplicativo. Ele leva métricas desse aplicativo da mesma forma sobre o UDP, mas não usa mais o subsistema de rede (devido a otimizações no kernel do Linux). Todos os eventos são pré-agregados e os dados coletados a cada segundo (o intervalo pode ser configurado) são enviados para o cluster principal dos servidores StatsD (bioyino0 [1-3]) no formato Cap'n Proto.
O processamento e agregação de métricas adicionais, a escolha de um líder no cluster StatsD e o envio das métricas pelo líder à Graphite permaneceram praticamente inalterados. Você pode ler sobre isso em detalhes em nosso último artigo .
Quanto aos números, eles são os seguintes.
Gráfico de eventos StatsD recebidos
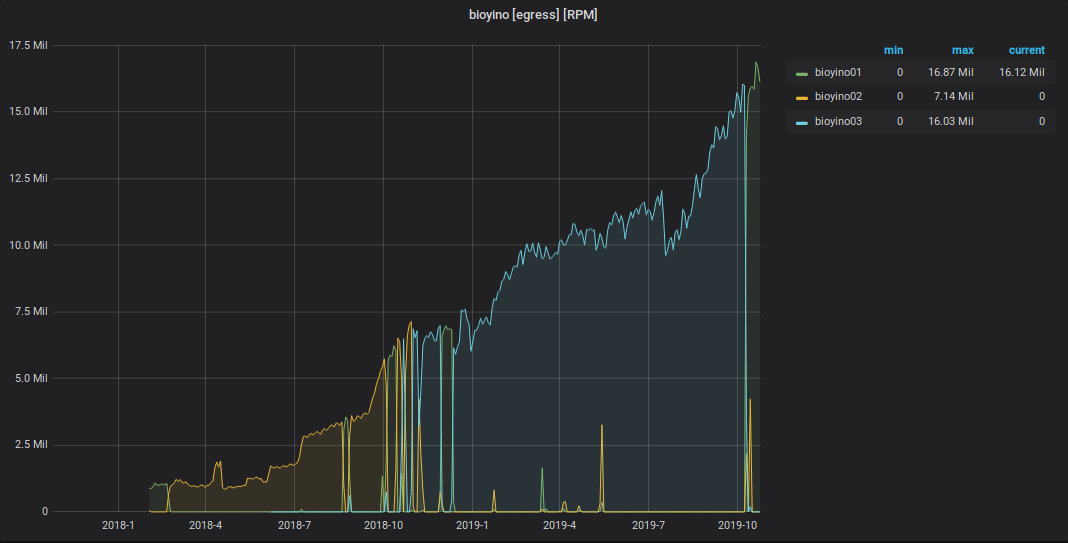

Gráfico de métricas enviadas de StatsD para Graphite
Total
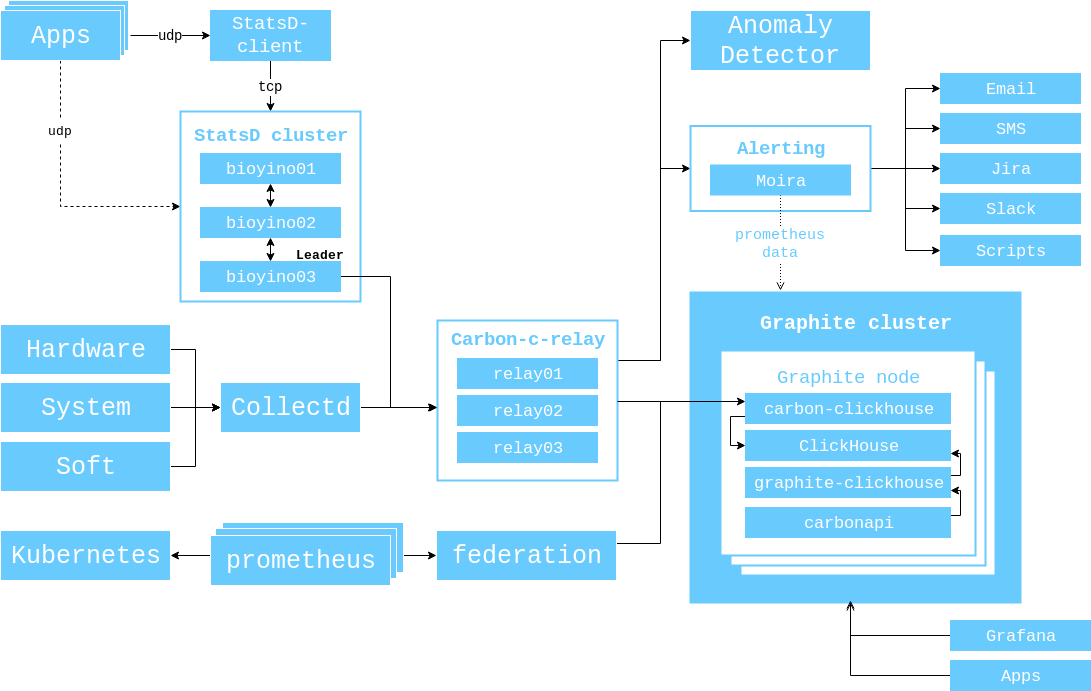
O esquema geral de interação entre os componentes de monitoramento no momento se parece com isso.
Número total de métricas: 2 189 484 898 474.
Profundidade total de armazenamento de métricas: 3 anos.
O número de nomes de métricas exclusivos: 6 585 413 171.
Número de gatilhos: 1053, eles veiculam de 1 a 15 mil métricas.
Planos para o futuro próximo:
- começar a mover os serviços do produto para um esquema de armazenamento métrico marcado;
- adicione mais três servidores ao cluster Graphite;
- faça amigos em Moira com tecido persistente ;
- Encontre outro desenvolvedor na equipe de monitoramento.
Ficarei feliz em comentar e fazer perguntas aqui - escreva. E também vou me apresentar no Highload ++ no dia 7 de novembro , se você estiver lá, podemos conversar.