No
último artigo, descobrimos que o cache é certamente uma coisa útil, mas no que diz respeito à lógica do controlador, às vezes cria dificuldades. Em particular, introduz imprevisibilidade de durações de pulso ou outros atrasos na formação programática de diagramas de tempo. Bem, e no plano "programático geral", a má localização da função pode reduzir o ganho do cache para nada, constantemente provocando a reinicialização da memória lenta. Mencionei que há 15 anos tínhamos que criar um pré-processador especial que solucionasse os problemas que surgiam para o processador SPARC-8, e prometi dizer como seria fácil corrigir essas dificuldades ao desenvolver um processador Nios II sintetizado recomendado para uso em Redd. Chegou a hora de cumprir a promessa.

Artigos anteriores da série:
- Desenvolvimento do “firmware” mais simples para FPGAs instalados no Redd e depuração usando o teste de memória como exemplo.
- Desenvolvimento do “firmware” mais simples para FPGAs instalados em Redd. Parte 2. Código do programa.
- Desenvolvimento de núcleo próprio para incorporação em um sistema de processador baseado em FPGA.
- Desenvolvimento de programas para o processador central Redd no exemplo de acesso ao FPGA.
- As primeiras experiências usando o protocolo de streaming no exemplo da comunicação da CPU e do processador no FPGA do Redd.
- Merry Quartusel, ou como o processador ganhou vida.
- Métodos de otimização de código para Redd. Parte 1: efeito de cache.
Hoje, nosso livro de referência será o
Embedded Design Handbook , ou melhor, sua seção
7.5. Usando a memória firmemente acoplada com o tutorial do processador Nios II . A seção em si é colorida. Hoje, projetamos sistemas de processador para FPGAs da Intel no programa Platform Designer. Nos dias de Altera, era chamado QSys (daí a extensão
.qsys do arquivo do projeto). Porém, antes que o QSsys aparecesse, todos usavam seu ancestral, SOPC Builder (em cuja memória a extensão do arquivo
.sopcinfo foi
deixada ). Portanto, embora o documento esteja marcado com o logotipo da Intel, mas as imagens nele são capturas de tela deste SOPC Builder. Foi claramente escrito há mais de dez anos e, desde então, apenas os termos foram corrigidos. É verdade que os textos são bastante modernos, portanto este documento é bastante útil como um manual de treinamento.
Preparação de Equipamentos
Então Queremos adicionar memória ao nosso sistema de processador Spartan, que nunca é armazenado em cache e, ao mesmo tempo, é executado na velocidade mais alta possível. Obviamente, essa será a memória interna do FPGA. Adicionaremos memória para código e dados, mas esses serão blocos diferentes. Vamos começar com a memória de dados como a mais simples.
Adicionamos a memória OnChip já conhecida ao sistema.
Bem, digamos que seu volume será de 2 kilobytes (o principal problema com a memória interna do FPGA é que ele é pequeno, então você precisa salvá-lo). O resto é memória comum, que já adicionamos.

Mas não vamos conectá-lo ao barramento de dados, mas a um barramento especial. Para fazê-lo aparecer, entramos nas propriedades do processador, na guia
Caches and Memory Interfaces e na lista de seleção
Número de portas principais de dados fortemente acopladas, selecione o valor 1.
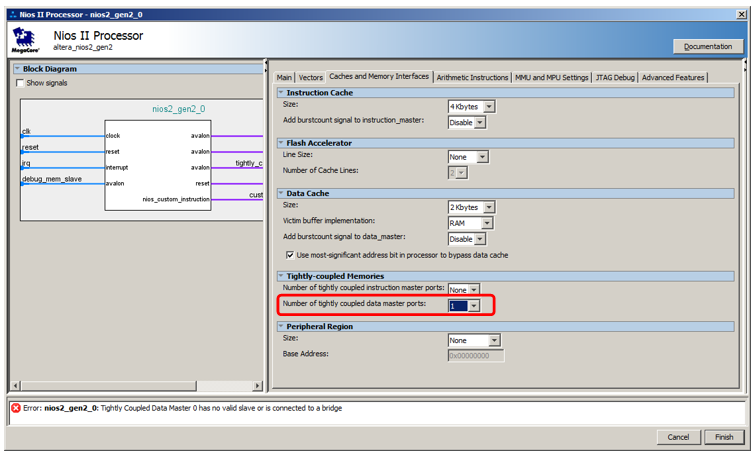
Aqui está uma nova porta para o processador:

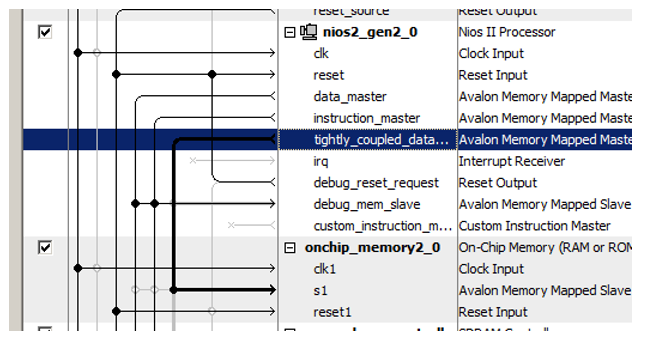
Recentemente, conectamos o bloco de memória recém-adicionado a ele!
Outro truque é atribuir endereços a essa nova memória. O documento tem uma longa linha de raciocínio sobre a otimização da decodificação de endereço. Ele afirma que a memória não armazenada em cache deve ser diferenciada de todos os outros tipos de memória por um bit claramente expresso do endereço. Portanto, no documento, toda a memória não armazenável em cache pertence ao intervalo 0x2XXXXXXX. Portanto, digite manualmente o endereço 0x2000000 e bloqueie-o para que não seja alterado com as seguintes atribuições automáticas.

Bem, e puramente para estética, renomeie o bloco ... Vamos chamá-lo, digamos,
NonCachedData .

Com hardware para memória de dados não em cache, é isso. Passamos para a memória para armazenamento de código. Tudo é quase o mesmo aqui, mas um pouco mais complicado. De fato, tudo pode ser feito de forma totalmente idêntica, apenas a porta mestre do barramento é aberta na lista
Número de portas mestre de instruções fortemente acopladas , no entanto, não será possível depurar esse sistema. Quando o programa é preenchido com o depurador, ele flui para lá através do barramento de dados. Quando parado, o código desmontado também é lido pelo depurador através do barramento de dados. E mesmo que o programa seja carregado a partir de um carregador externo (ainda não consideramos esse método, especialmente porque na versão gratuita do ambiente de desenvolvimento somos obrigados a trabalhar apenas com o depurador JTAG conectado, mas em geral, ninguém proíbe isso), o preenchimento também passa pelo barramento dados. Portanto, a memória terá que fazer porta dupla. Para uma porta, conecte um assistente de instruções não armazenado em cache que funcione no horário principal e à outra - um barramento de dados auxiliar em tempo integral. Ele será usado para baixar o programa de fora e obter o conteúdo da RAM pelo depurador. O resto do tempo esse pneu ficará inativo. É assim que tudo fica na parte teórica do documento:

Observe que o documento não explica o motivo, mas observe que, mesmo com memória de porta dupla, apenas uma porta pode ser conectada a um mestre não armazenado em cache. O segundo deve estar conectado ao habitual.
Vamos adicionar 8 kilobytes de memória, torná-lo de porta dupla, deixar o restante por padrão:
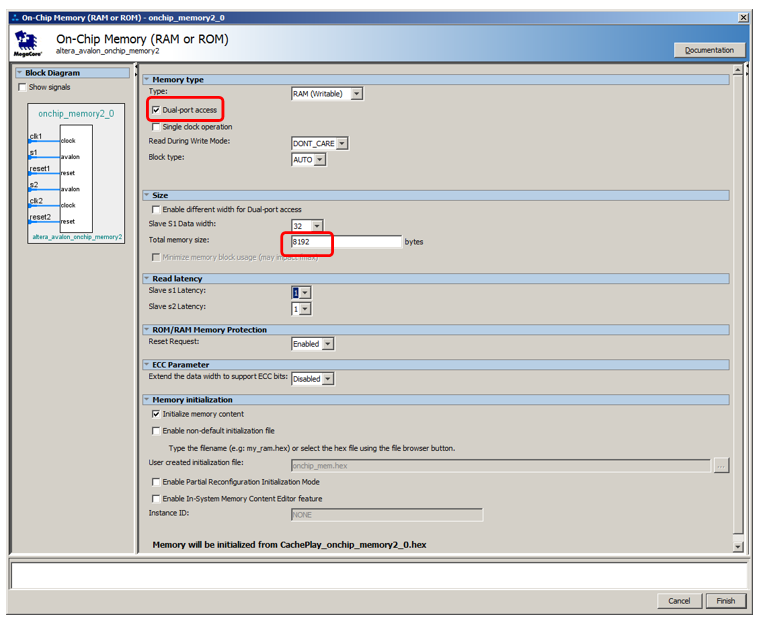
Adicione uma porta de instruções não armazenável em cache ao processador:

Chamamos a memória de
NonCachedCode , conectamos a memória aos barramentos, atribuímos a ela o endereço 0x20010000 e travamos (para as duas portas). Total, temos algo parecido com isto:
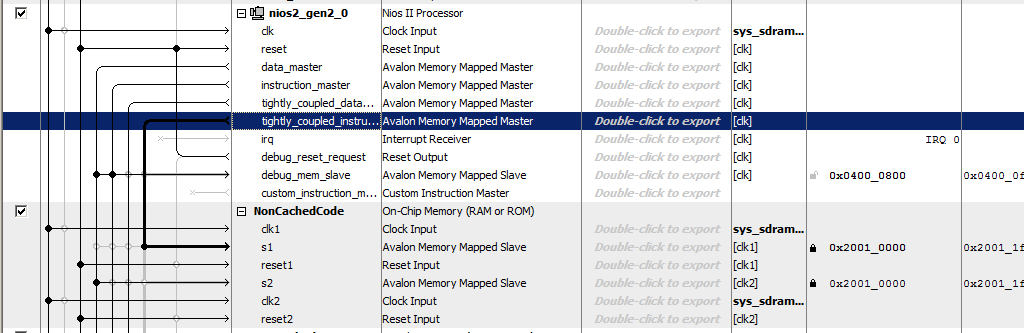
Só isso. Salvamos e geramos o sistema, coletamos o projeto. O hardware está pronto. Passamos para a parte do software.
Preparação do BSP na parte do software
Normalmente, depois de alterar o sistema do processador, basta selecionar o item de menu
Generate BSP , mas hoje temos que abrir o BSP Editor. Como raramente fazemos isso, deixe-me lembrá-lo de onde o item de menu correspondente está localizado:
Lá vamos para a guia
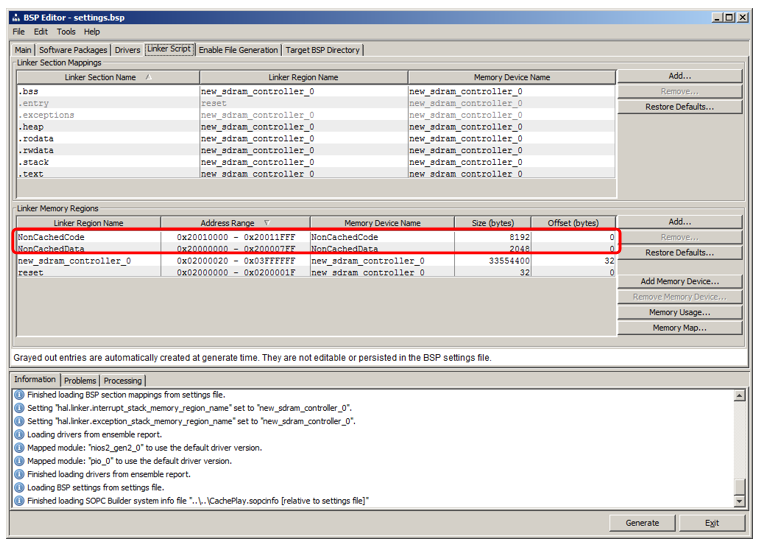
Script do
vinculador . Vimos que adicionamos regiões que herdam nomes de blocos de RAM:
Vou mostrar como adicionar uma seção na qual o código será colocado. Na seção seção, clique em Adicionar:
Na janela exibida, forneça o nome da seção (para evitar confusão no artigo, o nomeei muito diferente do nome da região, ou seja, nccode) e associei-o à região (selecionei
NonCachedCode da lista):

É isso, gere o BSP e feche o editor.
Colocando código em uma nova seção de memória
Deixe-me lembrá-lo de que temos duas funções no programa herdadas do artigo anterior:
MagicFunction1 () e
MagicFunction2 () . Na primeira passagem, os dois carregaram seus corpos no cache, visível no osciloscópio. Além disso - dependendo da situação no ambiente, eles trabalhavam à velocidade máxima ou constantemente se esfregavam com seus corpos, provocando downloads constantes da SDRAM.
Vamos mover a primeira função para um novo segmento não armazenado em cache, deixar a segunda no lugar e, em seguida, executar algumas execuções.
Para colocar uma função em uma nova seção, adicione o atributo de seção a ela.
Antes de definir a função
MagicFunction1 () , também colocamos sua declaração com este atributo:
void MagicFunction1()__attribute__ ((section("nccode"))); void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
Realizamos a primeira execução de uma iteração do loop (coloquei um ponto de interrupção na linha while):
while (1) { MagicFunction1(); MagicFunction2(); }
Vemos o seguinte resultado:
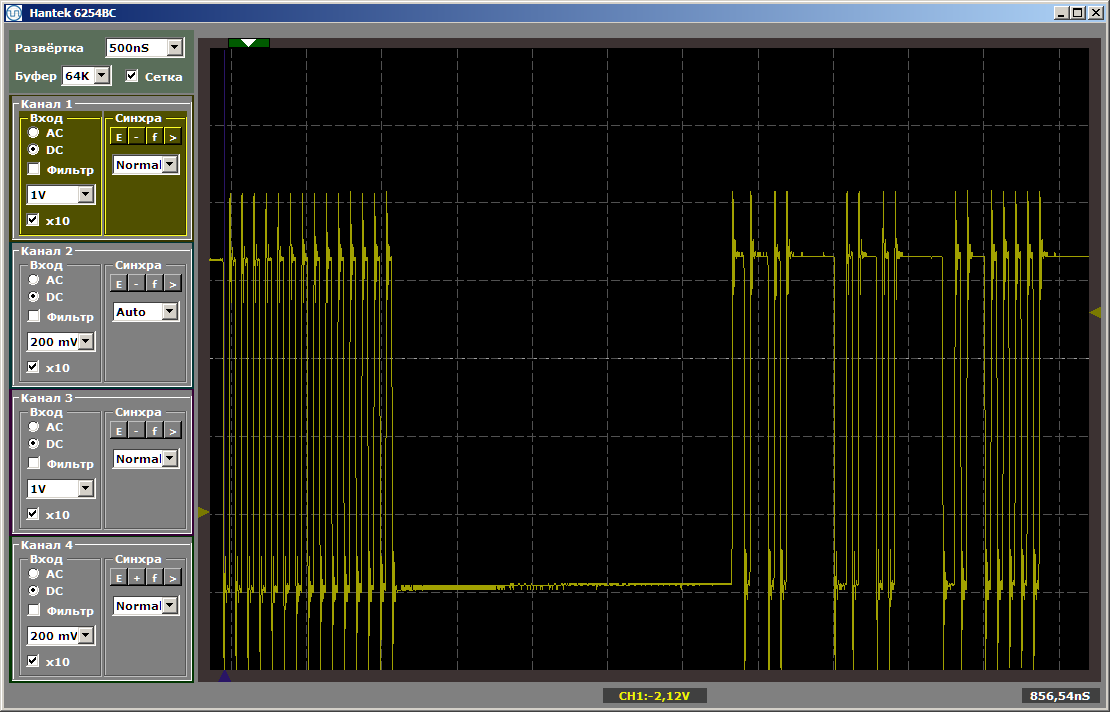
Como você pode ver, a primeira função é realmente executada na velocidade máxima, a segunda é carregada da SDRAM. Execute a segunda execução:
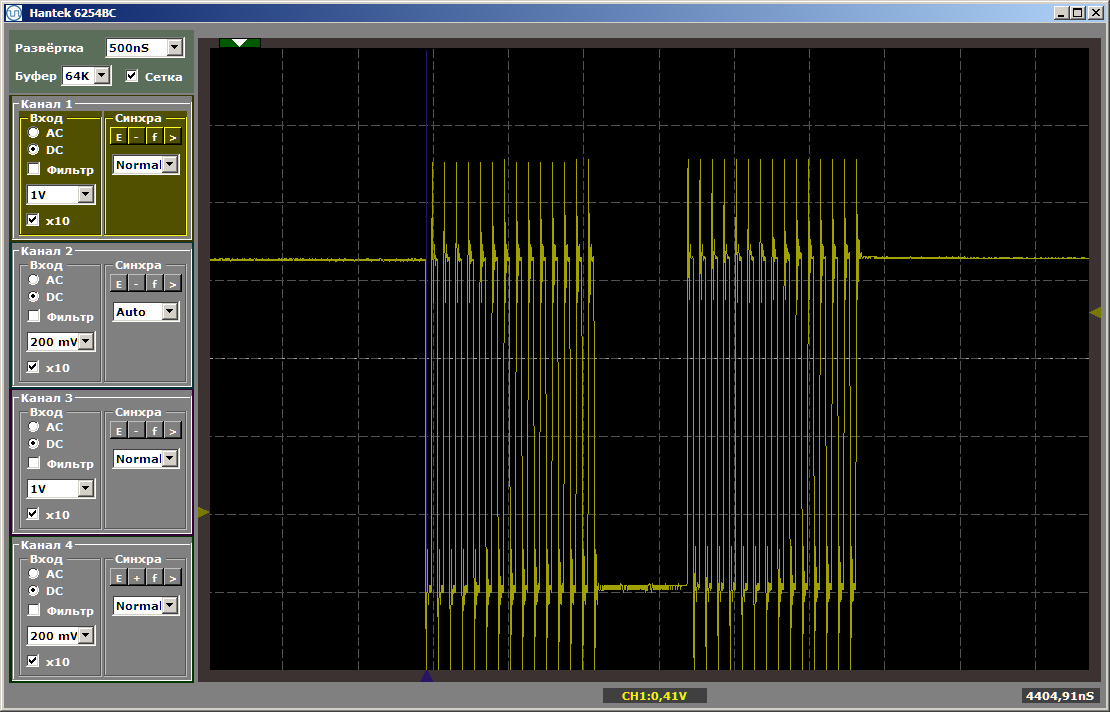
Ambas as funções operam na velocidade máxima. E a primeira função não descarrega a segunda do cache, apesar do fato de que entre elas está a inserção que eu deixei depois de escrever o último artigo:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
Essa inserção não afeta mais a posição relativa das duas funções, pois a primeira delas foi deixada em uma área completamente diferente da memória.
Algumas palavras sobre dados
Da mesma forma, você pode criar uma seção de dados não armazenados em cache e colocar variáveis globais lá, atribuindo-lhes o mesmo atributo, mas para economizar espaço, não darei exemplos.
Criamos uma região para essa memória, o mapeamento para a seção pode ser feito da mesma maneira que para a seção de código. Resta apenas entender como atribuir o atributo correspondente a uma variável. Aqui está o primeiro exemplo de declaração desses dados encontrados nas entranhas do código gerado automaticamente:
volatile alt_u32 alt_log_boot_on_flag \ __attribute__ ((section (".sdata"))) = ALT_LOG_BOOT_ON_FLAG_SETTING;
O que isso nos dá
Bem, na verdade, a partir de coisas óbvias: agora podemos colocar a parte principal do código no SDRAM e, na seção não armazenável em cache, podemos destacar as funções que formam diagramas de tempo programaticamente ou cujo desempenho deve ser máximo, o que significa que elas não devem desacelerar devido a que alguma outra função despeja constantemente o código correspondente do cache.
Dê uma olhada nos pneus.
Agora, observe atentamente os pneus no sistema de processador resultante. Temos quase quatro deles. Eu circulei em vermelho o ônibus principal (que é a união dos dois, e é por isso que escrevi “quase”: fisicamente - existem dois pneus, mas logicamente - um). Destaquei em verde o barramento que conduz à memória de instruções não armazenada em cache, em azul - para a memória de dados não armazenados em cache.
Estes três pneus trabalham em paralelo e independentemente um do outro!
Lembre-se, no
artigo sobre DMA, argumentei que um dos fatores limitadores de desempenho é que os dados são transmitidos no mesmo barramento? O bloco DMA lê dados do barramento, grava dados nele e, ao mesmo tempo, o núcleo do processador usa o mesmo barramento. Como você pode ver, essa desvantagem de sistemas fechados é completamente eliminada no FPGA. Nos controladores prontos, os fabricantes, ao estabelecer as conexões, são forçados a se separar entre necessidades e capacidades. O programador pode precisar dessa opção. E tal. E tal. E então ... Muitas coisas podem ser necessárias. Mas os recursos custam dinheiro e nem sempre há espaço suficiente para eles no cristal selecionado. Você não pode postar tudo. Temos que escolher o que todos realmente precisam e o que é necessário em casos isolados. E quais casos isolados devem ser introduzidos e quais devem ser esquecidos. E, em seguida, aparecem soluções de compromisso, cujas sutilezas, se houver um desejo de usá-las, o programador deve ter em mente. No nosso caso, podemos agir sem mais delongas. O que precisamos hoje é hoje colocado. Nosso recurso é flexível. Nós o gastamos para que o equipamento seja ideal para a tarefa de hoje. Para as tarefas de amanhã e de ontem, os recursos não precisam ser reservados. Porém, nos dias de hoje, colocaremos tudo de forma que o programa funcione da maneira mais eficiente possível, sem a necessidade de delícias especiais de programação.
Era uma vez, em uma universidade em um curso sobre processadores de sinais, aprendemos a arte de usar dois ônibus em paralelo com uma equipe. Tanto quanto sei, nos modernos controladores ARM, o conhecimento detalhado da matriz de barramento também permite a otimização. Mas tudo isso é bom quando um desenvolvedor trabalha com o mesmo sistema há anos. Se você precisar montar peças de hardware completamente diferentes de projeto para projeto, não poderá memorizar tudo. No caso dos FPGAs, não estudamos os recursos do ambiente, somos livres para personalizar o ambiente para nós mesmos.
Em relação à abordagem "não gastamos muito tempo em desenvolvimento", soa assim:
Não precisamos nos esforçar para otimizar o uso de pneus padrão prontos, podemos colocá-los rapidamente da maneira mais ideal para a tarefa a ser resolvida, concluir rapidamente esse desenvolvimento auxiliar e garantir rapidamente o processo de depuração ou teste do projeto principal.
Vamos dar uma olhada em um exemplo de inclusão de um bloco DMA no
Guia do Usuário de IP de Periféricos Incorporados para consolidar o material.
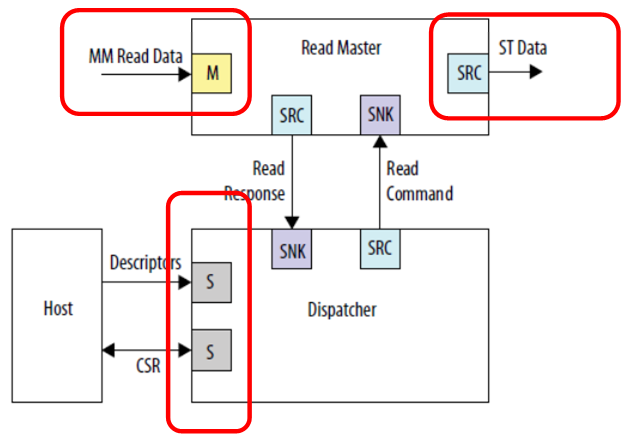
Vemos três conexões independentes. Dados de entrada (nesta figura, é um barramento projetado na memória), dados de saída (nesta figura, é um tipo completamente diferente de barramento - uma interface de fluxo) e comunicação com o processador de controle. Ninguém se preocupa em conectar tudo a barramentos diferentes, então o trabalho será paralelo. Os dados de entrada (por exemplo, da SDRAM) irão para um fluxo, com o qual ninguém interfere; a saída irá para um fluxo diferente, digamos, para o canal FT245-FIFO, que já consideramos; e o processador central não corroerá esses barramentos de relógio, pois o barramento principal está isolado. Embora neste caso, é claro, a memória no SDRAM, estando em um barramento separado, esteja indisponível de forma programática. Mas ninguém impedirá que seja lido pelo DMA. Se o objetivo é alcançar alto desempenho com o buffer, ele deve ser alcançado a todo custo. A menos que o programa inteiro precise caber na memória incorporada no FPGA, pois não há outras unidades de armazenamento no hardware Redd.
Para paralelizar pneus, você também pode usar pneus sem cache, porque vimos que pode haver vários. Várias restrições são impostas aos escravos conectados a esses barramentos:
- o escravo é sempre um no ônibus;
- o escravo não usa o mecanismo de atraso do barramento;
- a latência de gravação é sempre zero; a latência de leitura é sempre uma.
Se essas condições forem atendidas, esse dispositivo escravo poderá ser conectado a um barramento não armazenado em cache. Obviamente, provavelmente, será um barramento de dados.
Em geral, conhecendo esses princípios básicos, você certamente pode usá-los em tarefas reais. Mas, em geral, você pode. Você pode ficar sem isso, se o resultado for alcançado por meios convencionais. Mas tenha isso em mente. Às vezes, otimizar um sistema por meio desses mecanismos é mais simples do que ajustar o programa.
Conclusão
Examinamos uma técnica para transferir seções de código críticas para o desempenho ou para a previsibilidade da execução do processamento na memória não armazenável em cache. Ao longo do caminho, examinamos a possibilidade de otimizar o desempenho através do uso de vários pneus operando em paralelo e independentemente um do outro.
Para finalizar o tópico, ainda precisamos aprender como aumentar a frequência do clock do sistema (agora ele está limitado aos componentes que geram pulsos de clock para o chip SDRAM). Mas como os artigos seguem o princípio de “uma coisa - um artigo”, faremos isso na próxima vez.