Olá pessoal! Neste post, mostrarei quais abordagens usamos no Mail.ru Search para comparar textos. Para que é isso? Assim que aprendermos a comparar textos diferentes, o mecanismo de pesquisa poderá entender melhor as solicitações do usuário.
Do que precisamos para isso? Para começar, defina estritamente a tarefa. Você precisa determinar quais textos consideramos semelhantes e quais não, e então formular uma estratégia para determinar automaticamente a similaridade. No nosso caso, os textos das consultas do usuário serão comparados com os textos dos documentos.
A tarefa de determinar a relevância do texto consiste em três estágios. Primeiro, o mais simples: procure palavras correspondentes em dois textos e tire conclusões sobre a similaridade com base nos resultados. A próxima tarefa mais difícil é procurar a conexão entre palavras diferentes, entendendo sinônimos. E, finalmente, a terceira etapa: análise de toda a frase / texto, isolando o significado e comparando frases / textos por significados.

Uma maneira de resolver esse problema é encontrar algum mapeamento do espaço de texto para outro mais simples. Por exemplo, você pode converter textos em espaço vetorial e comparar vetores.
Vamos voltar ao início e considerar a abordagem mais simples: encontrar palavras correspondentes em consultas e documentos. Tal tarefa em si já é bastante complicada: para fazer isso bem, precisamos aprender a obter a forma normal de palavras, que por si só não é trivial.
O modelo de mapeamento direto pode ser bastante aprimorado. Uma solução é combinar sinônimos condicionais. Por exemplo, você pode inserir suposições probabilísticas na distribuição de palavras nos textos. Você pode trabalhar com representações vetoriais e isolar implicitamente as conexões entre as palavras incompatíveis, e fazê-lo automaticamente.
Como estamos envolvidos na pesquisa, temos muitos dados sobre o comportamento dos usuários ao receber determinados documentos em resposta a algumas consultas. Com base nesses dados, podemos tirar conclusões sobre a relação entre palavras diferentes.
Vamos tomar duas frases:

Atribua a cada par de palavras da consulta e do título algum peso, o que significa quanto a primeira palavra está associada à segunda. Vamos prever o clique como uma transformação sigmoidal da soma desses pesos. Ou seja, definimos a tarefa de regressão logística, na qual os atributos são representados por um conjunto de pares do formulário (palavra da consulta, palavra do título / texto do documento). Se pudermos treinar esse modelo, entenderemos quais palavras são sinônimos, com mais precisão, podem ser conectadas e quais provavelmente não podem.
Agora você precisa criar um bom conjunto de dados. Acontece que basta levar o histórico de cliques dos usuários e adicionar exemplos negativos. Como misturar em exemplos negativos? É melhor adicioná-los ao conjunto de dados na proporção de 1: 1. Além disso, os exemplos em si no primeiro estágio do treinamento podem ser feitos aleatoriamente: para um par de consulta-documento, encontramos outro documento aleatório e consideramos esse par negativo. Nos estágios posteriores do treinamento, é vantajoso dar exemplos mais complexos: aqueles que têm interseções, bem como exemplos aleatórios que o modelo considera semelhantes (mineração com negação bruta).
Exemplo: sinônimos para a palavra "triângulo".
Nesse estágio, já podemos distinguir uma boa função que corresponde às palavras, mas não é para isso que estamos nos esforçando.Uma função nos permite fazer a correspondência indireta de palavras e queremos comparar sentenças inteiras.
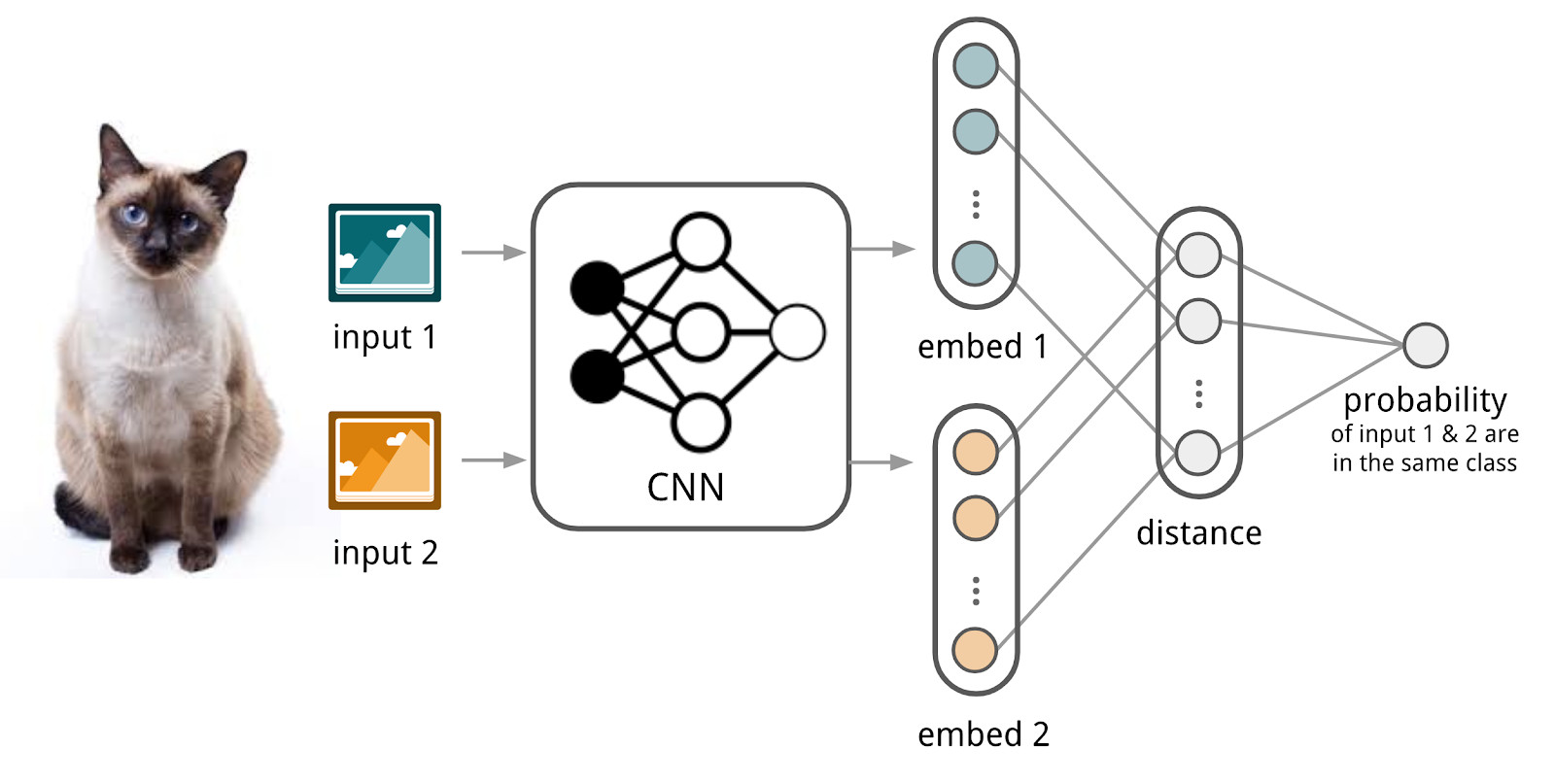
Aqui, as redes neurais nos ajudarão. Vamos criar um codificador que aceite texto (uma solicitação ou um documento) e produza uma representação vetorial de forma que textos semelhantes tenham vetores próximos e distantes. Por exemplo, você pode usar a distância do cosseno como uma medida de similaridade.
Aqui vamos usar o aparato das redes siamesas, porque elas são muito mais fáceis de treinar. A rede siamesa consiste em um codificador, que é aplicado para amostrar dados de duas ou mais famílias e uma operação de comparação (por exemplo, distância do cosseno). Ao aplicar o codificador a elementos de famílias diferentes, os mesmos pesos são usados; isso por si só dá uma boa regularização e reduz bastante o número de fatores necessários para o treinamento.
O codificador produz representações vetoriais a partir de textos e aprende, para que o cosseno entre representações de textos semelhantes seja máximo e entre representações de textos diferentes seja mínimo.
Uma rede de DSSM de complexidade semântica profunda é adequada para nossa tarefa. Nós o usamos com pequenas alterações, que discutirei abaixo.
Como o DSSM clássico funciona: consultas e documentos são apresentados na forma de uma bolsa de trigramas, a partir dos quais é obtida uma representação vetorial padrão. É passado por várias camadas totalmente conectadas e a rede é treinada de forma a maximizar a probabilidade condicional do documento mediante solicitação, o que equivale a maximizar a distância do cosseno entre as representações vetoriais obtidas por uma passagem completa pela rede.
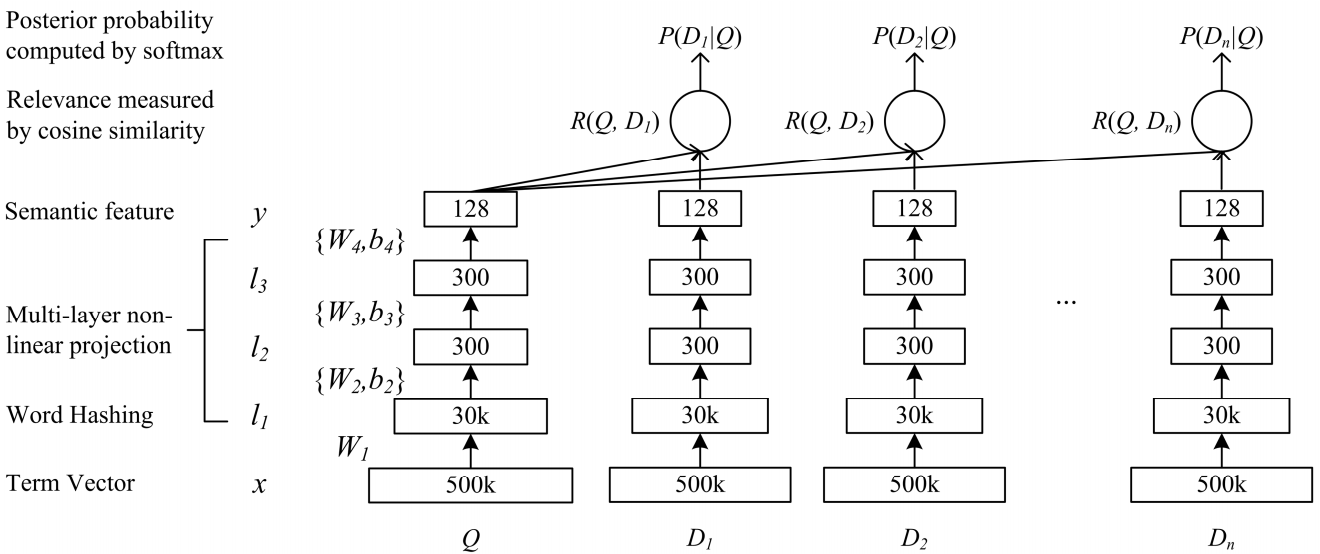 Po-Sen Huang Xiaodong He Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Aprendendo modelos semânticos estruturados em profundidade para pesquisa na Web usando dados de clique
Po-Sen Huang Xiaodong He Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Aprendendo modelos semânticos estruturados em profundidade para pesquisa na Web usando dados de cliqueNós fomos quase da mesma maneira. Ou seja, cada palavra na consulta é representada como um vetor de trigramas e o texto como um vetor de palavras, deixando assim informações sobre qual palavra estava. Em seguida, usamos convoluções unidimensionais dentro das palavras, suavizando a representação delas e a operação de extração máxima global para agregar informações sobre a sentença em uma representação vetorial simples.

O conjunto de dados que usamos para treinamento quase coincide essencialmente com o usado para o modelo linear.
Nós não paramos por aí. Primeiro, eles criaram um modo de pré-treinamento. Tomamos uma lista de consultas para o documento, informando quais usuários interagem com este documento e treinamos a rede neural para incorporar esses pares. Como esses pares são da mesma família, é mais fácil aprender essa rede. Além disso, é mais fácil treiná-lo novamente em exemplos de combate quando comparamos solicitações e documentos.
Exemplo: os usuários acessam e.mail.ru/login com solicitações: email, entrada de email, endereço de email, ...Finalmente, a última parte difícil, com a qual ainda estamos lutando e na qual quase alcançamos sucesso, é a tarefa de comparar a solicitação com algum documento longo. Por que essa tarefa é mais difícil? Aqui, o mecanismo das redes siamesas já é mais adequado, porque a solicitação e o longo documento pertencem a diferentes famílias de objetos. No entanto, não podemos mudar a arquitetura. Só é necessário adicionar convoluções também por palavras, o que salvará mais informações sobre o contexto de cada palavra para a representação vetorial final do texto.
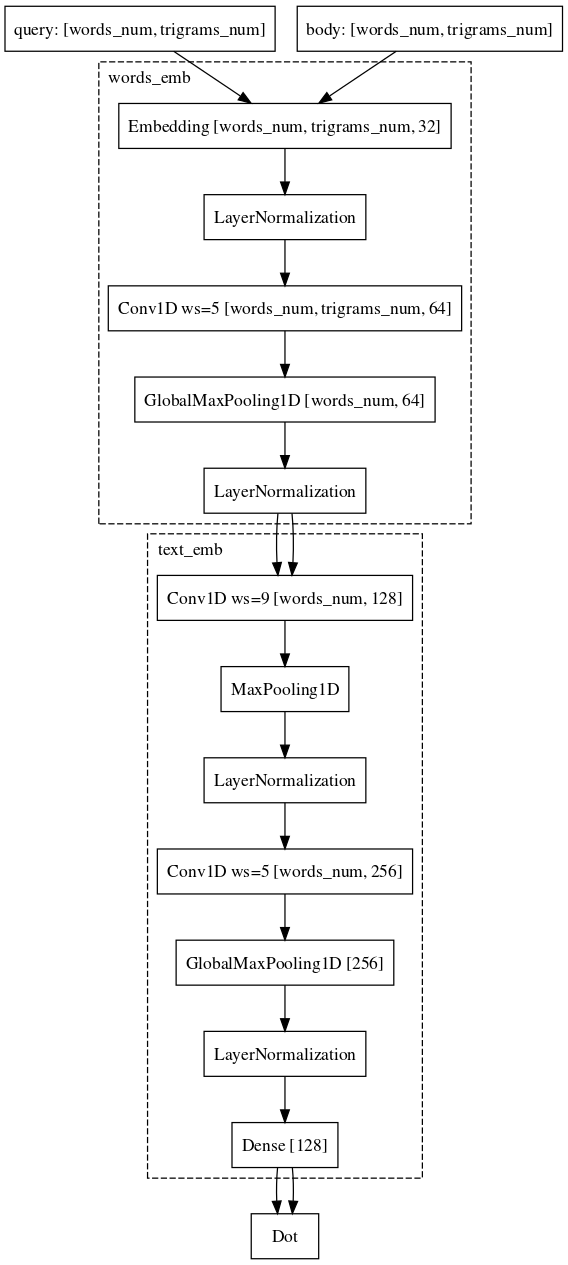
No momento, continuamos a melhorar a qualidade de nossos modelos, modificando arquiteturas e experimentando fontes de dados e mecanismos de amostragem.