Conteúdo
Às vezes, os próprios erros nos encontram. Então, empurramos uma grande linha de dados - e o sistema travou. É por causa de 1 milhão de caracteres que caíram? Ou ela não gostou de uma em particular?
Ou o arquivo foi carregado no sistema e travou. Porque Devido ao nome, extensão, dados internos ou tamanhos? Você pode enviar a localização para o desenvolvedor, deixar que ele pense no que há de ruim no arquivo. Mas muitas vezes você pode encontrar o motivo e descrever o problema com mais precisão.
Se você encontrar os dados mínimos para reproduzir, então:
- Você economizará tempo para o desenvolvedor - ele não precisará se conectar ao banco de testes, carregar o arquivo e estréia
- O gerente poderá avaliar facilmente a prioridade da tarefa - é necessário corrigir com urgência ou o bug pode esperar? Embora o nome "alguns arquivos caiam, xs why" é difícil de executar ...
- Uma descrição do bug para entender a causa da queda também será beneficiada.
Como encontrar os dados mínimos para reproduzir um bug? Se houver dicas nos logs, aplique-as. Se não houver pistas, o melhor método é o método de divisão bissecional (também conhecido como método de "bissecção" ou "dicotomia").
Descrição do método
O método é usado para encontrar o local exato da queda:
- Pegue um pacote caindo de dados.
- Quebre ao meio.
- Verifique metade 1
- Se ele caiu, o problema está aí. Trabalhamos mais com ela.
- Se não cair → verifique a metade 2.
- Repita as etapas 1 a 3 até que um valor em queda permaneça.

O método permite que você localize rapidamente o problema, principalmente se for feito de forma programática. Os desenvolvedores integram esses mecanismos ao processamento de dados. E se eles não o incorporam, eles mesmos sofrem mais tarde quando o testador chega até eles e diz: "Ele está nesse arquivo, mas não consegui encontrar o motivo exato".
Aplicação por testadores
Linha de dados
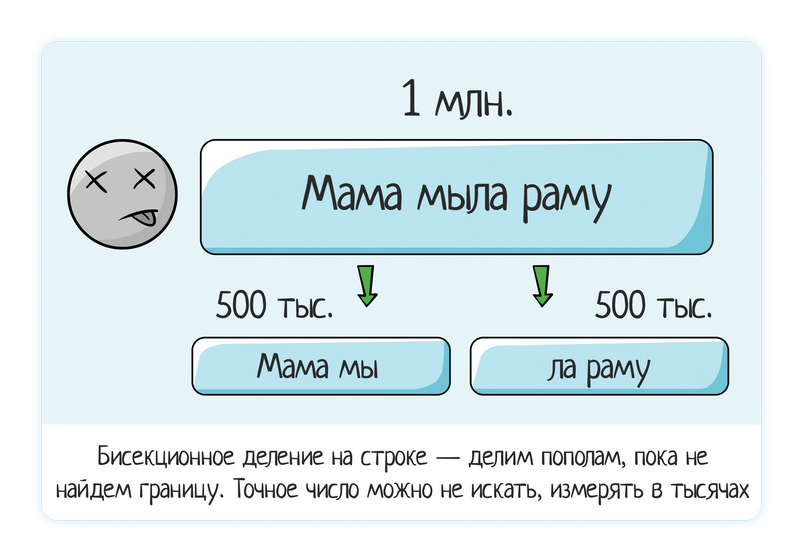
Carregou uma linha de 1 milhão de dados - o sistema congela.
Tentamos 500 mil (divididos ao meio) - ainda trava.
Tentamos 250 mil - não trava, está tudo bem.
↓
Daí a conclusão de que o problema está entre 250 e 500 mil. Novamente, aplicamos a divisão bissecional.
Tentamos 350 mil (dividindo "a olho") - é perfeitamente permitido, você não precisa encontrar números exatos ao tocar manualmente) - está tudo bem
Tentamos 450 mil - é ruim.
Tentamos 400 mil - é ruim.
↓
Em geral, você já pode receber um bug. É muito raramente exigido do testador relatar que a borda ou o bug está claramente no número 286 586. É suficiente localizá-lo aproximadamente - 290 mil.
É apenas uma coisa verificar "10" e imediatamente "300 mil", e é completamente diferente fornecer informações mais completas: "até 10 mil tudo está bem, de 10 a 280 mil freios começam, já cai para 290 mil".
É claro que, quando a quantidade é medida em milhares, levará muito tempo para procurar manualmente uma face específica. Sim, o desenvolvedor não precisa disso. Bem, ninguém quer perder tempo em vão.
Obviamente, se o problema original estava em uma linha com 10 a 30 caracteres, você pode encontrar a borda exata. É uma questão de uma relação razoável com o tempo - se você usar adivinhação ou divisão bissecional, poderá encontrar rapidamente o valor exato e ele é pequeno (até 100 geralmente) - estamos procurando com certeza. Se os problemas estiverem em uma linha grande, mais de 1000 → procure aproximadamente.
Ficheiro
Carregou um arquivo - travou! Como, porque? Primeiro, tentamos analisar por nós mesmos o que poderia afetar o que nosso teste testou? Este é o principal chip de regra "primeiro positivo, depois negativo". Se você não tentar colocar tudo em um teste ao mesmo tempo:
- Verificou um pequeno arquivo de amostra
- Verificamos um enorme arquivo de 2 GB, com várias colunas, várias colunas, além de diferentes variações dos dados internos
Será difícil localizar aqui. E se você separar as verificações:
- Muitas linhas (mas os dados são positivos e verificados anteriormente)
- Muitas colunas
- Peso pesado
- ...
Isso já é aproximadamente compreensível, qual é o motivo. Por exemplo, ele cai em um grande número de linhas - de 100 mil. Ok, estamos procurando uma borda mais precisa usando a divisão bissecional:
- Dividimos o arquivo em dois por 50 mil, verificamos o primeiro.
- Se você cair, divida
- E assim, até encontrarmos um lugar específico para cair
Se a queda depende do número de linhas, procuramos uma borda aproximada: "Após 5000 quedas, não há 4000 mil". Não é necessário procurar um local específico (4589). Muito tempo e não vale o tempo.
Este bug foi encontrado por estudantes em Dadat . Os arquivos de dados podem ser carregados lá, o sistema processará e padronizará esses dados: corrigir erros de digitação, determinar as informações ausentes nos diretórios (código KLADR, FIAS, coordenadas geográficas, distrito da cidade, CEP ...).
A garota tentou baixar um arquivo grande e obteve o resultado: o sistema mostra uma barra de progresso com 100% de carga e trava por mais de 30 minutos.
A localização foi além - quando começa o congelamento? Isso é importante porque afeta a prioridade da tarefa. Qual é o tamanho típico do download? Com que frequência os usuários enviam LOTS diretos?
Talvez o sistema tenha sido projetado para processar milhares de linhas, um bug desse tipo está repleto de "Fix it some day". Ou downloads típicos - de 10 a 50 mil linhas que processam normalmente, bem, isso significa que o erro não está queimando, vamos corrigi-lo um pouco mais tarde.
Localização da tarefa:
- para um arquivo com 50 mil linhas, 15 segundos travados,
- para um arquivo com 100 mil linhas, 30 segundos travados,
- para um arquivo com 150 mil linhas, 1 minuto trava,
- para um arquivo com 165 mil linhas trava 4 minutos,
- para um arquivo 172 mil linhas com uma barra de progresso 100% completa congela por mais de meia hora
É aqui que o trabalho do testador já é feito qualitativamente. São fornecidas informações completas sobre a operação do sistema, com base nas quais o gerente já pode concluir com que urgência é necessário corrigir o bug.
A verificação também não leva muito tempo. Você pode ir ou do final - aqui, baixamos 200 mil linhas e quando o problema começa? Usamos o método de divisão bissecional!
Ou comece com um número relativamente pequeno - 50 mil, aumentando gradualmente (pela metade, o método de divisão bisecional, exatamente o oposto). Sabendo que tudo será ruim em 200 mil, entendemos que não haverá muitos testes. Verificamos 50, 100, 150 - em três testes, encontramos uma borda aproximada. E então a escavação não é mais necessária.
Mas lembre-se de que você também precisa testar sua teoria. É verdade que o problema está no número de linhas e não nos dados dentro do arquivo? Verificar isso é muito fácil - crie um arquivo de 5000 linhas com um único valor "positivo". Esse valor que funciona exatamente que você já verificou anteriormente. Se não houver queda, o assunto é impuro =)) Parece que a teoria do número de linhas estava incorreta e o assunto está nos próprios dados.
Embora você possa experimentar 10 mil linhas com exatamente um valor positivo. É possível que a queda aconteça novamente. Apenas o seu arquivo de origem estava em várias colunas. Ou havia caracteres dentro que ocupavam mais bytes que um valor positivo ... Em geral, não rejeite imediatamente a teoria do tamanho do arquivo ou do número de linhas. Tente a divisão bissecional, pelo contrário - dobre o arquivo.
Mas, em qualquer caso, lembre-se de que quanto mais verificações forem misturadas em uma, mais difícil será localizar o erro. Portanto, é melhor testar imediatamente o número de linhas ou colunas em um único valor positivo. Para ter certeza de que está testando a quantidade de dados, não os dados em si. Análise de teste e tudo isso =)
Mas e se o problema não estiver no número de linhas, mas nos próprios dados? E você não sabe exatamente onde. Talvez você tenha inserido dados de “Guerra e Paz” em um arquivo de teste ou baixado uma grande planilha de algum lugar da Internet ... Ou o usuário encontrou um problema: ele fez o upload do arquivo e tudo caiu. Ele veio para apoiar, o apoio veio para você: o arquivo está em você, reproduza-o.
Outras ações dependem da situação. Se os prazos do usuário estiverem em execução ou o dinheiro for debitado dele e o processamento do arquivo cair, será um erro de bloqueio. E não há tempo para treinar um testador de localização. É mais fácil fornecer o arquivo que está caindo exatamente ao desenvolvedor, deixá-lo livre e descobrir o motivo.
Mas se você encontrou um erro, é hora de cavar você mesmo. Novamente, não esquecendo o senso comum, como sempre na localização. A princípio, tentamos tirar conclusões nós mesmos e depois fomos buscar ajuda. Para concluir você mesmo, é necessário:
- verifique os logs, pode haver a resposta certa;
- veja o conteúdo do arquivo: algo pode chamar sua atenção, essa é a primeira teoria;
- use o método de divisão bissecional.
Como resultado, em vez do erro "Arquivo quedas, por que xs, aqui está um anexo de arquivo de 2 GB", você coloca um erro bem pensado e localizado: "O arquivo cai se a data do formato DD / MM / AAAAA estiver dentro". E então você não precisa de um arquivo de 2 GB, apenas um arquivo para uma linha e uma coluna!

Aplicação por desenvolvedores
Em uma grande quantidade de dados, o testador não procura um limite claro, porque não é razoável fazer isso manualmente. Mas os desenvolvedores usam o método de divisão bissecional no código e sempre podem encontrar um local específico para cair. Afinal, o sistema se dividirá em vitória, e não uma pessoa!
Por exemplo, temos um mecanismo para carregar dados no sistema. Pode carregar 10 mil e um milhão. Mas isso não importa, pois o download está em lotes de 200 entradas. Se algo desse errado, o próprio sistema conduz a divisão bissecional. Próprio. Até encontrar um lugar problemático. Em seguida, leia os logs:
- Obteve 1000 entradas
- Processado 200 registros
- Processado 400 registros
- Opa, caiu em um pacote de 200 discos!
- Eu tento processar um pacote de tamanho 100
- Eu tento processar um pacote de tamanho 50
- Eu tento processar um pacote de tamanho 25
...
- Erro nesses identificadores: o campo de email obrigatório não é preenchido
- Processado 600 registros
...
Aqui, é claro, mais lógica também depende do desenvolvedor. O processamento para após encontrar um erro ou vai além. Tropeçou em um pacote de 200 entradas? Chegamos ao ponto de encontrar um gargalo, marcar a entrada como incorreta, processar as 199 restantes e seguir em frente.
Mas e se o pacote inteiro desmoronar? Marcamos o registro como incorreto, mas os 199 restantes também não foram capazes de processar. Porque Aplicamos o mesmo método, procurando um novo problema. O truque é que você sempre deve poder parar a tempo.
Se o número de erros for superior a 10-50-100, é melhor parar o download. É possível que tenha ocorrido um erro de upload no sistema original e recebemos um milhão de "curvas" de dados. Se o sistema dividir cada pacote de 200 registros pela metade e depois dividir os 199 restantes, e assim por diante, será ruim para todos:
- O log cresce dos 15 mb habituais para 3 gb e fica ilegível;
- O sistema pode travar ao tentar gerar uma mensagem de erro final (eu falei sobre essa situação na seção BMW Mnemonics );
- É gasto muito tempo pesquisando todos os erros. Sim, o sistema faz isso mais rapidamente do que uma pessoa, mas se você dividir um milhão de pacotes de 200 registros, isso levará tempo.
Portanto, o cérebro deve ser incluído em todos os lugares - tanto no teste manual quanto na escrita do código do programa. Você sempre deve entender quando parar. Somente no caso de testes manuais, ele estará "prestes a encontrar a fronteira" e no desenvolvimento "parará se houver muitas quedas".
Sumário
O método de divisão bisecional é usado para procurar a localização exata da queda e a localização do bug.
Procure o número e comece a dividi-lo ao meio:
- comprimento da linha;
- tamanho do arquivo
- peso do arquivo;
- número de linhas / colunas;
- quantidade de memória livre em um telefone celular;
- ...
Mas lembre-se - um dia você tem que parar! Não é necessário parar e procurar o número exato, se for necessário milhares de testes adicionais. Mas 5 a 10 minutos podem ser dados à localização.
PS - procure artigos mais úteis no meu blog com a tag "útil"