Oi Meu nome é Antonina, sou desenvolvedor Oracle da divisão de TI do Sportmaster Lab. Trabalho aqui há apenas dois anos, mas graças a uma equipe amigável, uma equipe unida, um sistema de orientação e treinamento corporativo, a massa muito crítica se acumulou quando você deseja não apenas consumir conhecimento, mas também compartilhar sua experiência.

Redefinição baseada em edição. Por que tivemos tanta necessidade de estudar essa tecnologia, além disso, o termo “alta disponibilidade” e como a Redefinição baseada em edição nos ajuda a que os desenvolvedores da Oracle economizem tempo?
O que é proposto como uma solução pela Oracle? O que está acontecendo no quintal ao aplicar essa tecnologia, que problemas encontramos ... Em geral, existem muitas perguntas. Vou tentar respondê-las em dois posts sobre o assunto, e o primeiro deles já está em discussão.
Cada equipe de desenvolvedores, criando seu próprio aplicativo, se esforça para criar o algoritmo mais acessível, tolerante a falhas e mais confiável. Por que todos nós lutamos por isso? Provavelmente não porque somos tão bons e queremos lançar um produto legal. Mais precisamente, não apenas porque somos tão bons. Também é importante para os negócios. Apesar de podermos escrever um algoritmo interessante, cobri-lo com testes de unidade, ver que ele é tolerante a falhas, ainda (os desenvolvedores da Oracle) temos um problema - somos confrontados com a necessidade de atualizar nossos aplicativos. Por exemplo, nossos colegas no sistema de fidelidade são forçados a fazer isso à noite.
Se isso acontecesse rapidamente, os usuários veriam uma imagem: "Por favor, com licença!", "Não fique triste!", "Espere, temos atualizações e trabalho técnico aqui". Por que isso é tão importante para os negócios? Mas é muito simples - por um longo tempo, os negócios têm colocado em suas perdas não apenas as perdas de alguns bens reais, valores materiais, mas também as perdas por tempo de inatividade da infraestrutura. Por exemplo, de acordo com a revista Forbes, em 13 anos, um minuto de falta de serviços na Amazon custava 66 mil dólares. Ou seja, em meia hora os caras perderam quase US $ 2 milhões.
É claro que, para médias e pequenas empresas, e não para gigantes como a Amazônia, essas características quantitativas serão significativamente menores, mas, no entanto, em termos relativos, essa continua sendo uma característica significativa da avaliação.
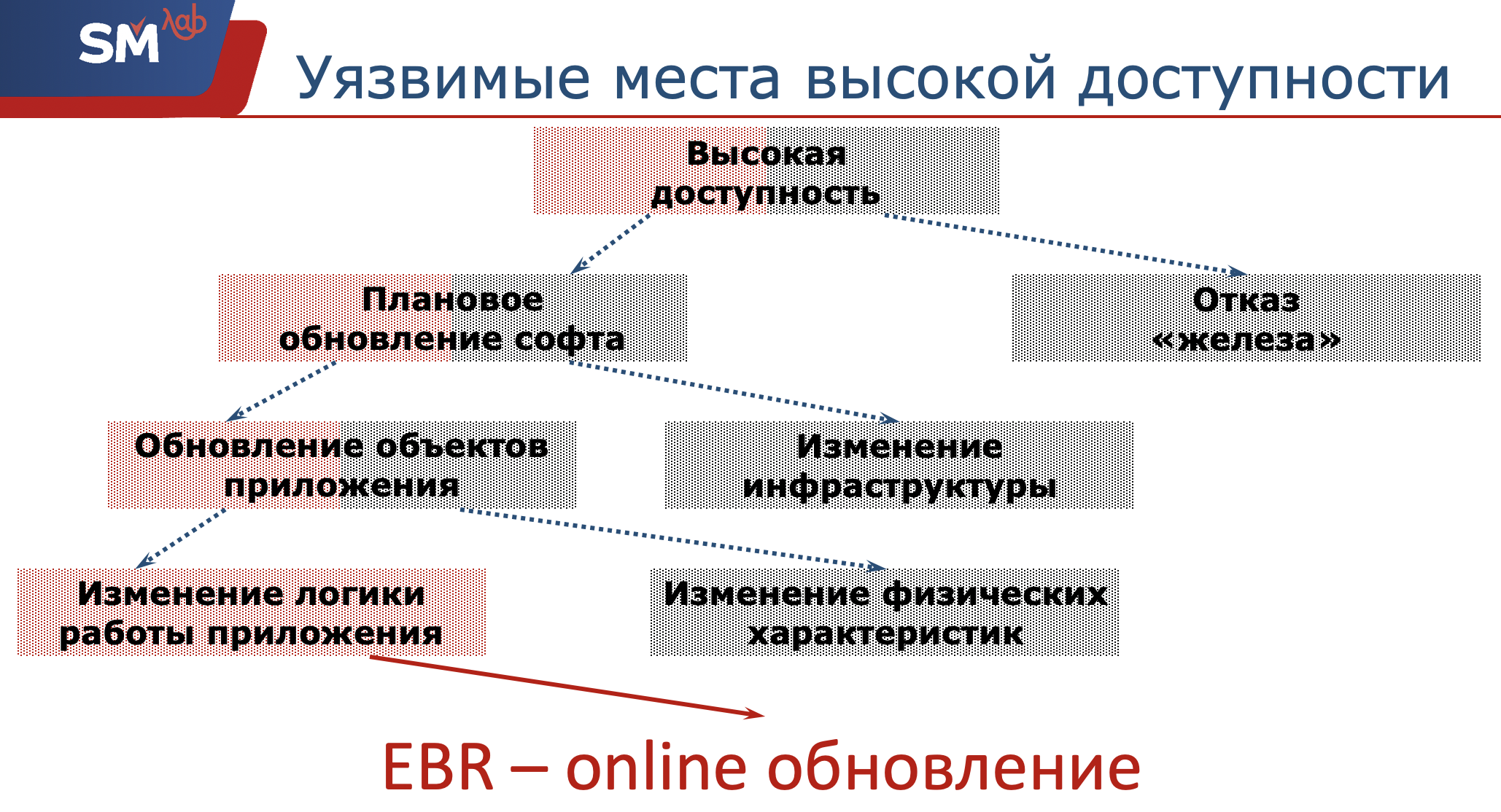
Portanto, precisamos garantir a alta disponibilidade de nosso aplicativo. Quais são alguns dos lugares potencialmente perigosos que os desenvolvedores da Oracle têm para essa acessibilidade?
Primeiramente, nosso hardware pode falhar. Nós, como desenvolvedores, não somos responsáveis por isso. Os administradores de rede devem garantir que o servidor e os objetos estruturais estejam operacionais. Estamos levando a uma atualização de software. Novamente, as atualizações de software agendadas podem ser divididas em duas classes. Ou estamos mudando algum tipo de infraestrutura, por exemplo, atualizando o sistema operacional no qual o servidor está rodando. Decidimos mudar para a nova versão do Oracle (seria bom se a migrássemos com sucesso :)) ... Ou, a segunda classe, é com isso que temos a máxima relação - é atualizar os objetos do aplicativo que estamos desenvolvendo com você.
Novamente, esta atualização pode ser dividida em mais duas classes.
Ou alteramos algumas características físicas desse objeto (acho que todo desenvolvedor Oracle às vezes encontrou o fato de que seu índice caiu, ele teve que reconstruir o índice rapidamente). Ou, digamos, introduzimos novas seções em nossas tabelas, ou seja, nenhuma parada ocorrerá. E esse lugar muito problemático é uma mudança na lógica do aplicativo.
Então, o que a Redefinição baseada em edição tem a ver com isso? E essa tecnologia - é apenas sobre como atualizar o aplicativo on-line, em tempo real, sem afetar o trabalho dos usuários.

Quais são os requisitos para esta atualização online? Devemos fazer isso despercebido pelo usuário, ou seja, tudo deve permanecer em condições de trabalho, em todos os aplicativos. Desde que tal situação possa ocorrer quando o usuário se sentou, começou a trabalhar e lembrou-se de que teve uma reunião urgente ou que precisava levar o carro ao serviço. Ele se levantou e acabou por causa de seu local de trabalho. E nesse momento, de alguma forma, atualizamos nosso aplicativo, a lógica do trabalho mudou, novos usuários já se conectaram a nós, os dados começaram a ser processados de uma nova maneira. Portanto, precisamos garantir a troca de dados entre a versão original do aplicativo e a nova versão do aplicativo. Aqui estão dois requisitos apresentados para atualizações online.

O que é proposto como uma solução? A partir da versão 11.2 Release Oracle, a tecnologia de redefinição baseada em edição é introduzida e conceitos como edição, objetos editáveis, exibição de edição e gatilho entre edições são introduzidos. Nós nos permitimos uma tradução como "versionamento". Em geral, a tecnologia EBR com alguma extensão pode ser chamada de versionamento de objetos DBMS dentro do próprio DBMS.
Então, o que é a Edição como uma entidade?
Esse é um tipo de contêiner dentro do qual você pode alterar e definir o código. Dentro de seu próprio escopo, dentro de sua própria versão. Nesse caso, os dados serão alterados e gravados apenas nas estruturas visíveis na edição atual. As representações de versão serão responsáveis por isso e consideraremos o trabalho deles.

É assim que a tecnologia se parece do lado de fora. Como isso funciona? Para iniciantes - no nível do código. Teremos nosso aplicativo original, versão 1, no qual existem alguns algoritmos que processam nossos dados. Quando entendemos que precisamos atualizar, ao criar uma nova edição, acontece o seguinte: todos os objetos que processam o código são herdados na nova edição ... Ao mesmo tempo, nesta sandbox recém-criada, podemos nos divertir como queremos, invisivelmente para o usuário: podemos mudar qual trabalho funções, procedimentos; mudar o pacote; podemos até nos recusar a usar qualquer objeto.
O que vai acontecer? A versão original permanece inalterada, permanece disponível para o usuário e toda a funcionalidade está disponível. Na versão que criamos, na nova edição, os objetos que não foram alterados permaneceram inalterados, isto é, herdados da versão original do aplicativo. Com o bloco em que tocamos, os objetos são atualizados na nova versão. E, é claro, quando você exclui um objeto, ele não está disponível para nós na nova versão do nosso aplicativo, mas permanece funcional na versão original.É assim que funciona simples no nível do código.

O que acontece com as estruturas de dados e o que a visão de versão tem a ver com isso?

Já que por estruturas de dados queremos dizer uma tabela e uma visão de versão, isso é, de fato, um shell (eu me chamei de “pesquisa etológica” da nossa tabela), que é uma projeção nas colunas originais. Quando entendemos que precisamos alterar a operação do nosso aplicativo e, digamos, de alguma forma adicionar colunas à tabela ou até mesmo proibir seu uso, criamos uma nova visualização de versão em nossa nova versão.

Nesse sentido, usaremos apenas o conjunto de colunas que precisamos, que processaremos. Portanto, na versão original do aplicativo, os dados são gravados no conjunto definido neste escopo. O novo aplicativo gravará no conjunto de colunas definido em seu escopo.

As estruturas são claras, mas o que acontece com os dados? E como tudo isso está interconectado, tivemos dados armazenados nas estruturas originais. Quando entendemos que temos um certo algoritmo que nos permite converter dados da estrutura original e decompor esses dados em uma nova estrutura, esse algoritmo pode ser colocado nos chamados gatilhos de versão cruzada. Eles apenas visam estruturas de diferentes versões do aplicativo. Ou seja, sujeito à disponibilidade de tal algoritmo, podemos pendurá-lo em uma tabela. Nesse caso, os dados serão transformados das estruturas originais para as novas, e os gatilhos de avanço progressivo serão responsáveis por isso. Desde que seja necessário garantir a transferência de dados para a versão antiga, novamente, com base em algum tipo de algoritmo, os gatilhos reversos serão responsáveis por isso.
O que acontece quando decidimos que nossa estrutura de dados mudou e estamos prontos para trabalhar em modo paralelo, tanto para a versão antiga do aplicativo quanto para a nova versão do aplicativo? Podemos simplesmente inicializar o preenchimento de novas estruturas com alguma atualização ociosa. Depois disso, ambas as versões do aplicativo ficam disponíveis para uso do usuário. A funcionalidade permanece para usuários antigos da versão antiga do aplicativo; para novos usuários, a funcionalidade será da nova versão do aplicativo.
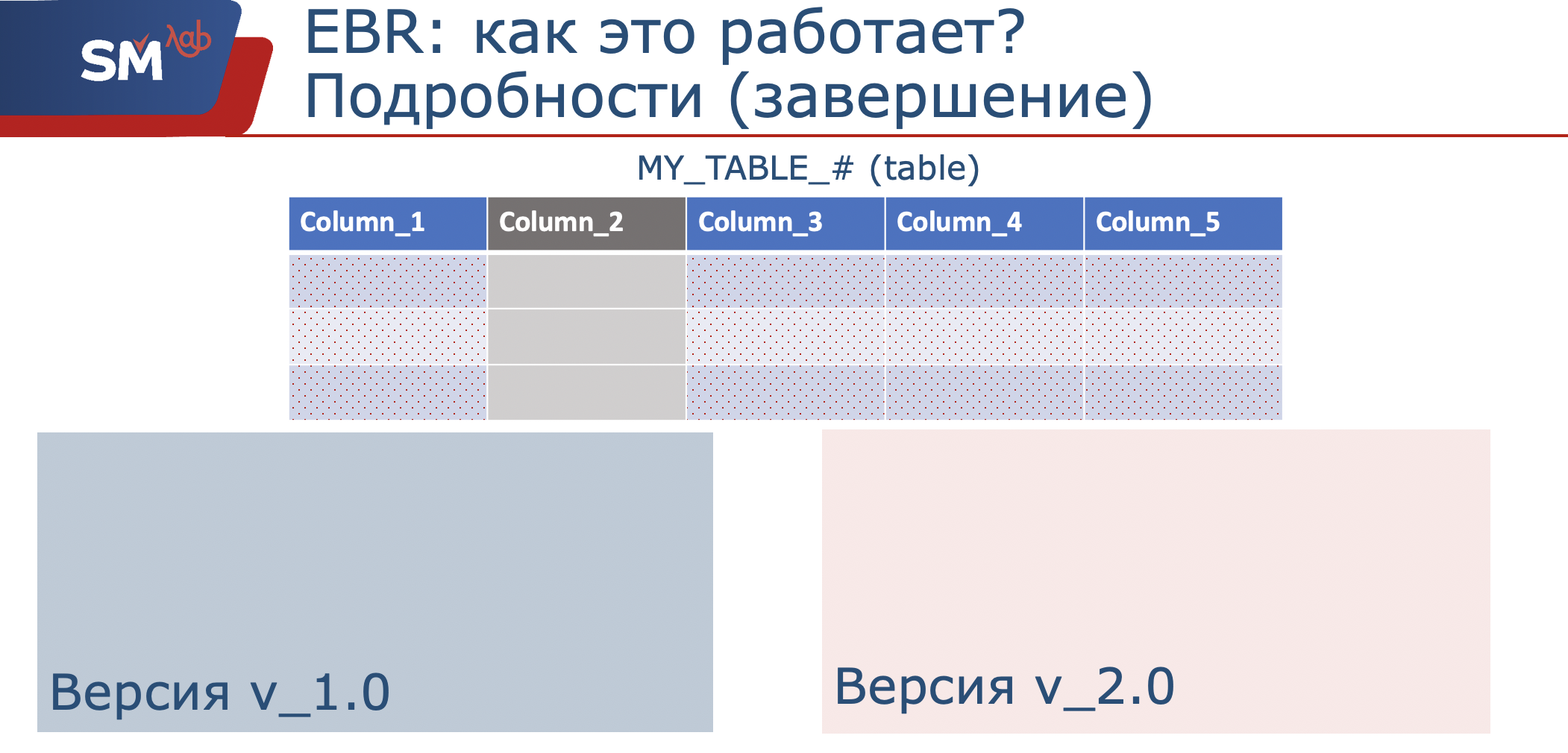
Quando percebemos que todos os usuários do aplicativo antigo estavam desconectados, essa versão podia ficar oculta. Talvez até a estrutura de dados tenha sido alterada. Lembramos que, conosco, a visualização de versão na versão recém-criada já analisará apenas o conjunto de colunas 1, 3,4,5. Bem e, consequentemente, se não precisarmos dessa estrutura, ela poderá ser excluída. Aqui está um breve resumo de como funciona.

Quais são as restrições impostas? Ou seja, Oracle bem feito, excelente Oracle, excelente Oracle: eles criaram algo bacana. A primeira limitação no momento são objetos do tipo com versão, são objetos PL / SQL, ou seja, procedimentos, pacotes, funções, gatilhos e assim por diante. Os sinônimos são versionados e as visualizações são versionadas.
O que não é versionado e nunca será versionado são tabelas e índices, visualizações materializadas. Ou seja, na primeira versão, apenas alteramos os metadados e podemos armazenar cópias deles tanto quanto você deseja ... de fato, um número limitado de cópias desses metadados, mas mais sobre isso posteriormente. O segundo diz respeito aos dados do usuário, e sua replicação exigiria muito espaço em disco, o que não é lógico e é muito caro.

A próxima limitação é que os objetos do esquema terão versão completa, se e somente se pertencerem ao usuário autorizado pela versão. De fato, esses privilégios para o usuário são apenas algum tipo de marca no banco de dados. Você pode conceder essas permissões com o comando usual. Mas chamo sua atenção para o fato de que essa ação é irreversível. Portanto, não vamos arregaçar imediatamente as mangas, digitar tudo isso no servidor de batalha e primeiro testaremos.
A próxima limitação é que objetos não-versionados não podem depender dos versionados. Bem, isso é bastante lógico. No mínimo, não entenderemos qual edição, qual versão do objeto olhar. Neste ponto, gostaria de chamar a atenção, porque tivemos que competir com esse momento.
Próximo. As visualizações com versão pertencem ao proprietário do esquema, proprietário da tabela e somente em cada versão. Na sua essência, uma visualização com versão é um invólucro de tabela; portanto, fica claro que deve ser exclusivo em todas as versões do aplicativo.
O que também é importante, o número de versões na hierarquia pode ser 2000. Provavelmente, isso se deve ao fato de você não carregar o dicionário de alguma maneira. Eu disse inicialmente que os objetos, ao criar uma nova edição, são herdados. Agora essa hierarquia é construída exclusivamente linear - um pai, um descendente. Talvez haja algum tipo de estrutura em árvore, vejo alguns pré-requisitos para isso no fato de que você pode definir o comando de criação de versão como um herdeiro de uma edição específica. Atualmente, essa é uma hierarquia estritamente linear e o número de links nessa cadeia é 2000.
É claro que, com algumas atualizações freqüentes de nosso aplicativo, esse número pode ser esgotado ou ultrapassado, mas a partir do 12º lançamento do Oracle, as edições extremas criadas nessa cadeia podem ser cortadas sob a condição de que não são mais usadas.

Espero que agora você entenda aproximadamente como isso funciona. Se você decidir - “Sim, queremos tocá-lo” - o que precisa ser feito para mudar para o uso dessa tecnologia?
Primeiras coisas primeiro, você precisa determinar a estratégia de uso. Sobre o que é isso? Entenda com que frequência nossas estruturas de tabela são alteradas, se precisamos usar visualizações com versão, especialmente se precisamos de gatilhos entre versões para garantir alterações nos dados. Ou apenas versão nosso código PL / SQL. No nosso caso, quando estávamos testando, vimos que ainda havia tabelas alteradas, portanto provavelmente também usaremos visualizações com versão.
Além disso, naturalmente, o esquema selecionado recebe privilégios com versão.
Depois disso, renomeamos a tabela. Por que isso é feito? Apenas para proteger nossos objetos de código PL / SQL da modificação de tabelas.
Decidimos lançar um símbolo afiado no final de nossas tabelas, considerando o limite de 30 caracteres. Depois disso, as visualizações de versão são criadas com o nome da tabela original. E eles já serão usados dentro do código. É importante que na primeira versão para a qual estamos migrando, a visualização com versão seja um conjunto completo de colunas na tabela de origem, porque os objetos de código PL / SQL podem acessar todas essas colunas exatamente da mesma maneira.
Depois disso, superamos os gatilhos DML das tabelas para as visualizações com versão (sim, as visualizações com versão nos permitem colocar gatilhos nelas). Talvez revogemos as concessões das tabelas e as apresentemos às visualizações recém-criadas ... Em teoria, todos esses pontos são suficientes, basta recompilar o código PL / SQL e as visualizações dependentes.
Eu-e-e-e-e ... Naturalmente, testes, testes e tantos testes quanto possível. Por que testes? Não poderia ser tão simples. Sobre o que tropeçamos?
É sobre isso que
meu segundo post será abordado.