Tentarei dizer a você como é fácil obter resultados interessantes simplesmente aplicando uma abordagem completamente padrão do tutorial do curso de aprendizado de máquina aos dados que não são usados no Deep Learning. A essência do meu post é que cada um de nós pode fazer isso, basta olhar para o conjunto de informações que conhece bem. Para isso, de fato, é muito mais importante simplesmente entender bem seus dados do que ser um especialista nas estruturas mais recentes das redes neurais. Ou seja, na minha opinião, estamos nesse ponto de ouro no desenvolvimento da DL, quando, por um lado, já é uma ferramenta que pode ser usada sem a necessidade de um doutorado, e, por outro, ainda existem muitas áreas em que ninguém realmente o usou, se você olhar Um pouco além dos temas tradicionais.

Lendo artigos e de passagem examinando como o aprendizado de máquina se desenvolve, você e eu podemos facilmente ter a sensação de que esse trem está passando. De fato, se você faz os cursos mais famosos (por exemplo, Andrew Ng ) ou a maioria dos artigos sobre Habré da mesma excelente comunidade de Open Data Science, você rapidamente percebe que não há nada a fazer aqui a partir das profundezas da memória do instituto de conhecimento em matemática superior, bem, pelo menos alguns resultados sensatos (mesmo em exemplos de " brinquedos ") só podem ser alcançados após várias semanas de estudo da teoria de terry e de diferentes maneiras de sua implementação. Mas muitas vezes você quer outra, deseja ter uma ferramenta que desempenhe sua função, que resolva uma certa classe de problemas, para que, aplicando-a em seu campo, obtenha o resultado. De fato, em outras áreas tudo é exatamente o mesmo, se você, por exemplo, escreve um jogo e sua tarefa é garantir a transferência de informações do jogador para o servidor, não estuda a teoria dos gráficos, não descobre como otimizar a conectividade para que seus pacotes cheguem mais rapidamente - você pega a ferramenta (biblioteca, estrutura) que faz isso por você e se concentra no que é exclusivo para uma tarefa específica (por exemplo, que tipo de informação você precisa transferir para frente e para trás). Por que isso não acontece com o aprendizado profundo?
De fato, agora estamos à beira do tempo em que está se tornando quase assim . E para mim, quase achei essa ferramenta - fast.ai. Uma biblioteca excelente e um curso ainda mais íngreme, cujo princípio é apenas construído de cima para baixo: primeiro resolvendo problemas reais, geralmente no nível de precisão da previsão dos modelos de última geração, até a estrutura interna da biblioteca e a teoria por trás dela.
Claro, nem tudo é tão simples.Antecipando acusações de não profissionalismo e a superficialidade do meu conhecimento (o que, é claro, é mais verdadeiro do que não), quero fazer uma reserva imediatamente. É necessário estudar a teoria, assistir a essas palestras fundamentais, lembrar o cálculo matricial, etc.? Claro que sim. E quanto mais você mergulhar no tópico, mais precisará dele e terá que se apegar às fontes principais. Porém, quanto mais consciente a imersão, mais fácil será entender exatamente como esses fundamentos afetam o resultado. O ponto principal do princípio de cima para baixo é precisamente que deve ser feito depois. Depois de já ter escrito algo tangível, você pode mostrar aos seus amigos. Depois de ter mergulhado o suficiente no tópico e ele o fascinou. E a teoria do conhecimento o ultrapassará, ela está sendo apresentada no exato momento em que será mais fácil correlacioná-la com o que você já fez. Como uma explicação do porquê e como ele realmente funciona.
Tenho mais certeza de que alguém se sente mais à vontade com a abordagem tradicional de baixo para cima. E é bom que haja os dois lados, o principal é que nos encontramos no meio
Com esse conhecimento, decidi aplicar a DL a um tópico no qual eu próprio me interessei há muito tempo e ver o que isso pode levar. E, claro, a primeira coisa que me veio à mente foi o futebol. E quando eu encontrei essas maravilhosas estatísticas de transferência no kaggle, a escolha se tornou ainda mais óbvia.
Um pouco sobre esses dados. Eles contêm informações sobre quem e onde se mudou para o futebol europeu nos últimos 10 anos. Há informações sobre clubes, estatísticas de jogadores, ligas em que participam, treinadores e agentes e muito mais (existem mais de cem campos diferentes no total). Os dados são muito interessantes, mas é possível determinar quanto um jogador deve custar deles?
Se você pensar bem, o preço de um jogador depende de um grande número de fatores. Ao mesmo tempo, é ótimo, e eu (se não a maioria) a parte deles é simplesmente não formalizável. Como entender que o clube acaba de vender o jogador a um preço alto, precisa de um atacante e está pronto para pagar em excesso; como entender que um novo treinador chegou e requer atualização da lista; como entender que o zagueiro principal do clube notou o grand e começou a jogar sem entusiasmo, exigindo uma transferência? Tudo isso afeta fundamentalmente a quantidade de uma transação, mas não é apresentada nos dados. A partir disso, minhas expectativas iniciais sobre a precisão de tal previsão foram pequenas.
Eu sou um programador falsoNeste momento, é hora de inserir o aviso padrão de que não # um # , não ganho dinheiro com isso; portanto, meu código é terrível e provavelmente pode (e deve?) Ser reescrito muito melhor, mas como a tarefa era investigar a ideia e (não ?) Confirme a teoria, então o código é o que é :)
Modelo
Comecei excluindo transferências mais baratas que US $ 1 milhão, que são muito caóticas. Depois, ele trouxe todos os dados para uma grande mesa com cem campos e meio, nos quais, para cada transferência, havia todas as informações disponíveis sobre ele (tanto sobre a transferência em si, sobre o jogador e suas estatísticas, quanto sobre os clubes participantes, ligas etc.) )
Vejamos as etapas de como eu criei o modelo :
Depois que concluímos todas as importações do Python e carregamos a tabela de transferência desnormalizada, a primeira coisa que precisamos determinar é quais dos campos que consideraremos como numéricos e quais são categóricos. Este é um tópico muito interessante por si só, você pode falar sobre isso nos comentários, mas para economizar tempo, apenas descrevo a regra que uso: por padrão, considero todos os campos categóricos, exceto aqueles que são representados como números de ponto flutuante ou aqueles em que o número de valores diferentes é grande o suficiente.
Nesse contexto, por exemplo, considero o ano da transferência categórico, embora esse seja inicialmente um número, porque o número de valores diferentes é pequeno aqui (10 - de 2008 a 2018). Mas, por exemplo, o desempenho do jogador na última temporada (que é representado pelo número médio de gols por partida) é flutuante e pode ter quase qualquer valor, por isso considero numérico.
cat_vars_tpl = ('season','trs_year','trs_month','trs_day','trs_till_deadline', 'contract_left_months', 'contract_left_years','age', 'is_midseason','is_loan','is_end_of_loan', 'nat_national_name','plr_position_main', 'plr_other_positions','plr_nationality_name', 'plr_other_nationality_name','plr_place_of_birth_country_name', 'plr_foot','plr_height','plr_player_agent','from_club_name','from_club_is_first_team', 'from_clb_place','from_clb_qualified_to','from_clb_is_champion','from_clb_is_cup_winner', 'from_clb_is_promoted','from_clb_lg_name','from_clb_lg_country','from_clb_lg_group', 'from_coach_name', 'from_sport_dir_name', 'to_club_name','to_club_is_first_team','to_clb_place', 'to_clb_qualified_to', 'to_clb_is_champion','to_clb_is_cup_winner','to_clb_is_promoted', 'to_clb_lg_name','to_clb_lg_country', 'to_clb_lg_group','to_coach_name', 'to_sport_dir_name', 'plr_position_0','plr_position_1','plr_position_2', 'stats_leag_name_0', 'stats_leag_grp_0', 'stats_leag_name_1', 'stats_leag_grp_1', 'stats_leag_name_2', 'stats_leag_grp_2') cont_vars_tpl = ('nat_months_from_debut','nat_matches_played','nat_goals_scored','from_clb_pts_avg', 'from_clb_goals_diff_avg','to_clb_pts_avg','to_clb_goals_diff_avg','plr_apps_0', 'plr_apps_1','plr_apps_2','stats_made_goals_0','stats_conc_gols_0','stats_cards_0', 'stats_minutes_0','stats_team_points_0','stats_made_goals_1','stats_conc_gols_1', 'stats_cards_1','stats_minutes_1','stats_team_points_1','stats_made_goals_2', 'stats_conc_gols_2','stats_cards_2','stats_minutes_2','stats_team_points_2', 'pop_log1p')
Depois de indicar explicitamente o que preveremos - o valor da transferência ( fee ), dividimos aleatoriamente nossos dados em 2 partes de 80% e 20%. No primeiro deles, ensinaremos nossa rede neural, por outro - a verificar a precisão da previsão.
ln = len(df) valid_idx = np.random.choice(ln, int(ln*0.2), replace=False)
No último estágio preparatório, precisamos fazer uma escolha de como mediremos a plausibilidade de nossas previsões. Então, não escolhi a métrica mais padrão na parte local do universo - a mediana do erro percentual ( MdAPE ). Ou, para simplificar, quantos por cento (o preço absoluto de uma transferência pode diferir em ordens de grandeza) provavelmente cometeremos um erro no preço de uma transferência tomada aleatoriamente. Pareceu-me mais próximo do que exatamente a frase “precisão do sistema de previsão de transferência” significa para mim.
Agora é hora de começar a aprender a rede.
data = (TabularList.from_df(df, path=path, cat_names=cat_vars, cont_names=cont_vars, procs=procs) .split_by_idx(valid_idx) .label_from_df(cols=dep_var, label_cls=FloatList, log=True) .databunch(bs=BS)) learn = tabular_learner(data, layers=layers, ps=layers_drop, emb_drop=emb_drop, y_range=y_range, metrics=exp_mmape, loss_func=MAELossFlat(), callback_fns=[CSVLogger]) learn.fit_one_cycle(cyc_len=cycles, max_lr=max_lr, wd=w_decay)
Precisão de previsão

Validation Error = 0.3492 significa que, após o treinamento em um novo validation set dados ( validation set , validation set ), o modelo em média (mediana) é 34% equivocado em relação ao preço real de transferência. E conseguimos apenas como resultado de várias linhas de código retiradas do tutorial.
34% de erro, é muito ou pouco? Tudo é relativo. A única fonte comparável, cujos dados podem ser tomados como uma " previsão " do valor da transferência, é, obviamente, transfermarkt . Felizmente, existe um campo nos dados do kaggle que mostra como este site classificou um jogador no momento da transferência, e isso pode ser comparado. Note-se aqui que a transfermarkt nunca alegou que seu market value é o provável preço de transferência. Pelo contrário, enfatizaram que é o " valor honesto " de um ou outro jogador. E quanto dinheiro um clube em particular pagará por isso em uma situação específica é uma coisa muito individual e pode flutuar em uma direção ou outra dentro de limites muito amplos. Mas é o melhor que temos, vamos comparar .

Erro Transfermarkt - 35% , nosso modelo - 35% . Muito estranho e, para ser sincero, muito desconfiado.
Neste ponto, proponho pensar novamente. Um site com uma enorme história, criado apenas para mostrar o `` valor '' dos jogadores, que depende do poder total do efeito multidão (deriva do valor das classificações de visitantes comuns e profissionais do mercado) e do conhecimento de especialistas, por um lado, e do modelo, que não sabe nada sobre futebol, não vê nada, exceto os dados que fornecemos (e fora desses dados no mundo real ainda existem muitas coisas que as pessoas com a transfermarkt levam em consideração), por outro lado, eles mostram o mesmo erro . Além disso, nosso modelo também permite prever o preço do aluguel do jogador, que o market value , por razões óbvias, não mostra (levando em conta essas transações, o resultado da transfermarkt foi ainda pior ).
Honestamente, ainda acho que tenho algum tipo de erro aqui, tudo é bom demais para ser verdade. Mas, no entanto, vamos além.
Uma maneira fácil de se testar é tentar calcular as previsões de duas fontes (modelos e transfermarkt). Se as previsões forem verdadeiramente independentes umas das outras e não houver erro irritante, o resultado deverá melhorar.

De fato, a média das previsões reduz o erro de previsão para 32% (!). Isso pode parecer um pouco, mas precisamos entender que estamos filtrando mais informações dos dados, que são tão compactados ao máximo.
Mas o que faremos a seguir, na minha opinião, é ainda mais surpreendente e interessante, embora esteja além do escopo do tutorial fast.ai.
Importância do recurso
As redes neurais, para não dizer que são completamente imerecidas, são frequentemente consideradas uma "caixa preta". Sabemos quais dados podemos colocar lá, podemos obter as previsões do modelo, podemos até avaliar o quanto essas previsões são verdadeiras, em média. Mas não podemos explicar por quais critérios o modelo "tomou" essa ou aquela decisão. A estrutura interna da rede em si é tão complexa e, mais importante, não linear, que é impossível rastrear diretamente toda a cadeia de tomada de decisão e tirar conclusões significativas do mundo real a partir daí. Mas realmente quero. Eu gostaria de entender o que influencia o valor da transferência acima de tudo.
Bem, não vamos subir dentro da rede. Mas o que significa a importância de cada campo, vamos chamá-lo de Importância de Recursos (FI)? Uma opção para entender 'importância' é calcular quanto as coisas piorarão se não tivermos esse campo. E é exatamente isso que podemos medir. Agora temos uma ferramenta que fornece previsões para qualquer conjunto de dados. Portanto, se apenas calcularmos quanto o erro de previsão aumentará quando substituirmos dados aleatórios no campo, podemos estimar quanto ele (o campo) afeta o resultado final, o que significa o quanto é importante. Para permanecer dentro da distribuição real dos dados, o campo será preenchido não apenas com números aleatórios, mas com valores misturados aleatoriamente (ou seja, apenas misturaremos a coluna, por exemplo, 'ano de transferência', na tabela original). Por fidelidade, esse processo pode ser realizado várias vezes para cada campo, calculando a média do resultado. Tudo é bem simples. Agora vamos ver como isso dá o resultado:
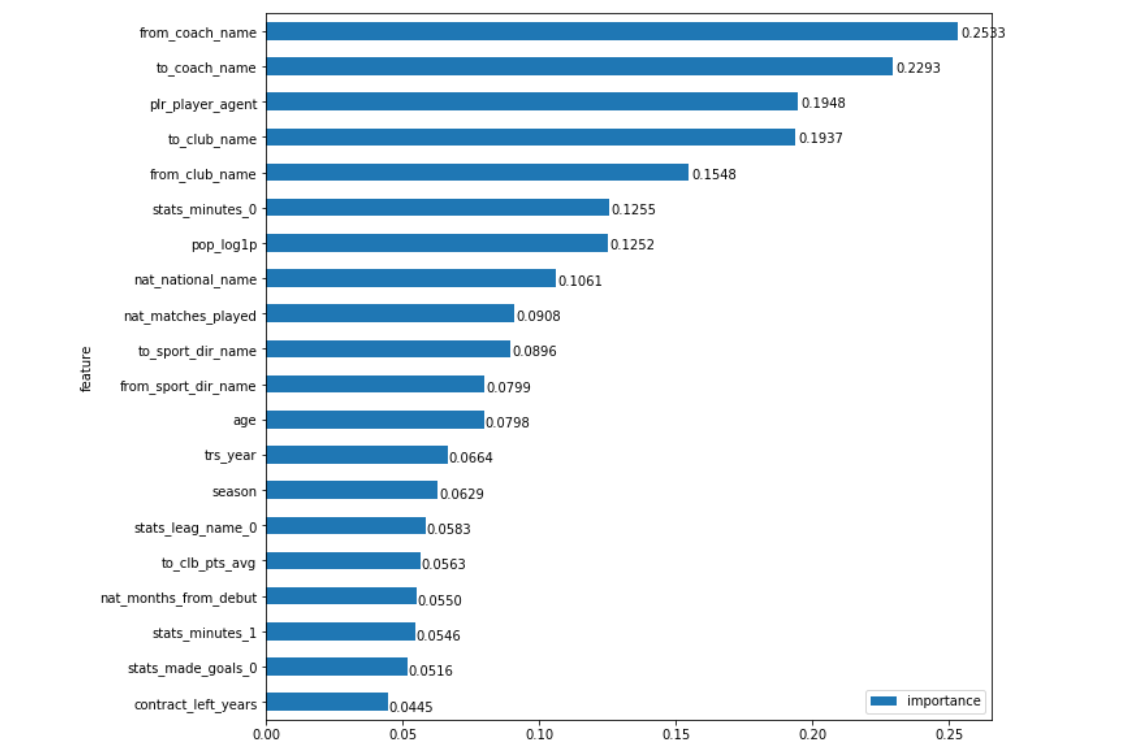
Meu intestino diz: 'Sim e não!'
Por um lado, os campos que você espera ver estavam no topo: treinadores de equipe de onde e para onde from_coach_name jogador foi (de from_coach_name , para to_coach_name ), os próprios clubes que participaram da transferência ( from_club_name , to_club_name ), o agente do jogador ( plr_player_agent ), sua fama nas redes sociais ( pop_log1p ) etc. Mas por outro lado ... Intuitivamente, não parece que os nomes dos treinadores devam ter mais peso no preço de transferência do que, por exemplo, os próprios clubes (sabemos bem que o Benfica condicional é capaz de vender seus jogadores caros). A marca de um treinador influencia mais fortemente o preço do que a marca do clube? A chegada do Mancini condicional força tanto o clube a pagar em excesso? O que acontece quando os dados nos fornecem informações novas, um pouco contra-intuitivas, ou apenas um erro no modelo?
Vamos acertar. Com um olhar atento ao gráfico, o olho rapidamente se apega a uma coisa estranha. Logo abaixo do centro, existem 2 campos de trs_year e season trs_year , eles representam o ano da transferência e a estação em que a transição será realizada (em geral, eles podem não coincidir, embora isso não ocorra com tanta frequência). Em primeiro lugar, parece que eles devem ser mais altos, sabemos quanto os preços dos jogadores de futebol subiram nos últimos anos e, em segundo lugar, obviamente significam a mesma coisa. O que fazer sobre isso? Apenas resuma sua importância? Não é o fato de que isso pode ser feito! Mas o que definitivamente podemos fazer é aplicar a mesma abordagem (misturando valores) não separadamente nesses dois campos, mas como um grupo. Ou seja, meça como o erro será alterado se houver valores aleatórios nessas 2 colunas de uma só vez. Bem, desde que fazemos isso ao longo dos anos, precisamos ver se temos outros campos tão "conectados".
Por exemplo, para um clube, temos vários parâmetros: o próprio clube ( club_name do clube), bem como um conjunto de informações sobre ele - de qual liga, país etc. ( club_is_first_team , clb_lg_name , clb_lg_country , clb_lg_group ). Somente em alguns casos, estamos interessados em saber quanto isso afeta o preço, por exemplo, o país para o qual o jogador vai separadamente ( clb_lg_country ). Na maioria das vezes, é importante entendermos qual é o peso total do campo 'clube', que já está em um determinado país, liga etc. .
Assim, podemos combinar todos os campos em grupos de acordo com o conteúdo semântico. Isso nos ajudará apenas como conhecimento da área de assunto e senso comum, bem como a 'proximidade' calculada dos recursos. O último mostra apenas como os campos se correlacionam, ou seja, quanto é possível considerá-los como um único grupo.
Aplicando essa abordagem, obtemos um gráfico ainda mais intuitivo da importância dos campos:
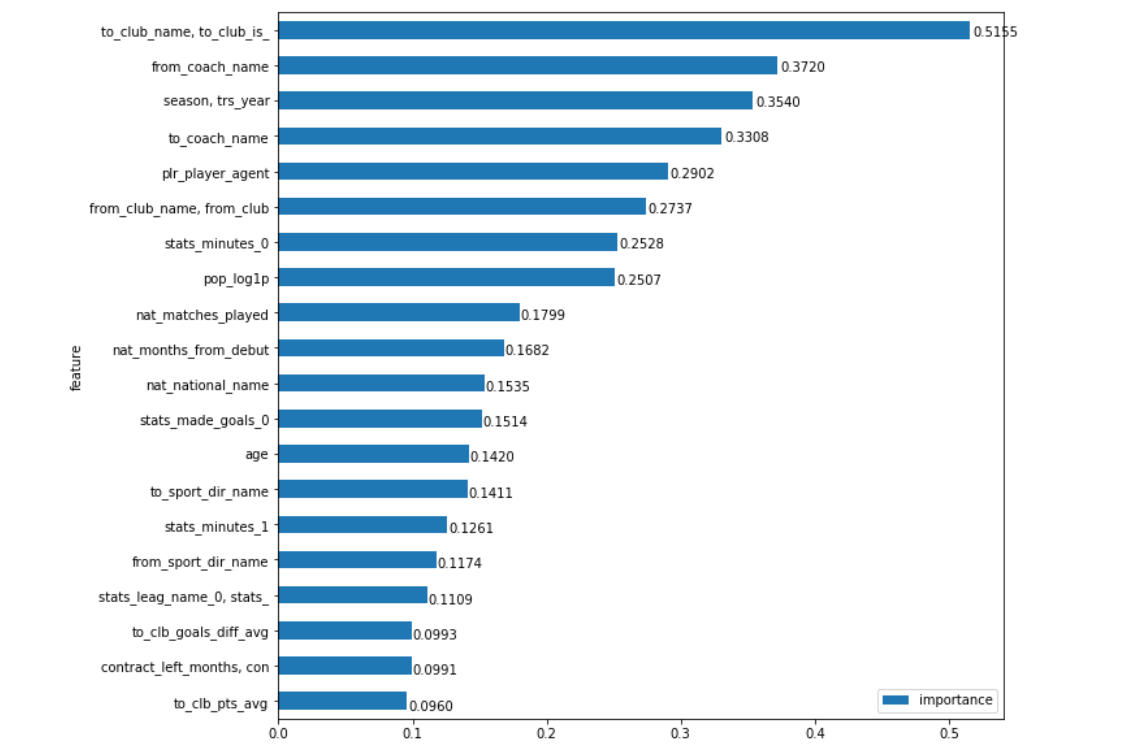
Lá vai você. Exatamente o clube que o jogador mais compra afeta o valor da transferência, com uma margem muito boa. Oi Man City, Barcelona, Zenit e, por exemplo, o mesmo Benfica (afinal, " influencia fortemente " a mesma coisa sobre o fato de que alguns clubes, pelo contrário, conseguem comprar jogadores de qualidade mais baratos que o "mercado"). Parece-me que o mais interessante ao trabalhar com dados é que, quando obtidos, as conclusões são óbvias, por um lado (bem, eu duvidava que o comprador do clube tivesse a influência mais poderosa sobre o valor da transferência) e, por outro lado, é um pouco surpreendente (e os candidatos pela primeira vez). intuitivamente, o local poderia ser um pouco, e a separação do segundo não parecia tão significativa)
Ainda há muitas coisas interessantes para descobrir. Por exemplo, o nome do treinador de onde o jogador é comprado, do ponto de vista do modelo, ainda é mais importante que o clube ... Deixe a diferença ser bastante reduzida. Uma explicação lógica para isso pode ser encontrada em princípio (embora às vezes possa ser encontrada para qualquer coisa). Existem treinadores (Guardiola, Klopp, Benitez, Berdyev) que aderem a uma certa ideologia do jogo em clubes diferentes, o que melhor revela ou vice-versa torna determinadas posições no campo menos brilhantes e a visibilidade do jogador afeta muito seu preço. Sobre clubes, por assim dizer, quase impossível. E o fato de vermos treinadores que não se afastam radicalmente de seus princípios de jogo com muito mais frequência do que os clubes trocando de treinador, mas que permanecem dentro da mesma filosofia (por exemplo, de improviso, exceto que o Ajax vem à mente e o Barcelona é muito questionável), fala de que, talvez, certos gerentes revelem jogadores mais estáveis que os clubes. Embora aqui não me apegue fortemente à minha afirmação.
Dos indicadores puramente estatísticos, o valor mais alto é simplesmente o tempo que um jogador passou em campo no ano passado em sua competição principal ( stats_minutes_0 ). Isso é bastante lógico, porque o quanto esse jogador foi o “principal” em seu clube na última temporada parece um indicador estatístico mais universal de seu sucesso do que outros - por exemplo, o número de gols marcados ou cartões recebidos.
A popularidade do jogador ( pop_log1p ) fecha esse grupo dos 8 parâmetros mais importantes. Vale lembrar que os dados que apresentamos nos últimos 10 anos. Eu acho que a importância desse campo seria maior se estivéssemos considerando os últimos 5 anos, e para o valor médio da última década esse é um resultado completamente compreensível, especialmente se levarmos em conta a diferença do próximo lugar.
Bem, a última coisa que gostaria de chamar a atenção é a importância do campo do agente ( plr_player_agent ). Deixarei isso sem comentários, porque, se você pode quebrar as margens das cópias em disputas sobre a (des) necessidade de agentes, não há dúvida sobre o grau de sua influência no mercado de transferências moderno (embora o modelo sugira não superestimá-lo).

A propósito, talvez a coisa mais interessante nesse método de análise seja sua acessibilidade: não é necessário criar um modelo “ ideal ” para obter informações sobre a importância dos parâmetros. Em muitos casos, basta prever, no mínimo, que seja estatisticamente significativamente diferente de jogar uma moeda, e você já obtém resultados que geralmente contêm informações interessantes ou informam de que lado novo você pode ver os dados.
Chegou a hora de terminar, para não aumentar o texto tão sobrecarregado. Ao me despedir, gostaria de pedir novamente a todos os interessados no tópico que experimentem (o melhor, na minha opinião, para iniciantes) o curso Deep Learning - fast.ai e apliquem o conhecimento adquirido em 'seu campo de atuação', é provável que você seja o primeiro a chegar :)
E, se você gostar, tentarei dominar a segunda parte do texto sobre minhas experiências nas quais o modelo usando uma ferramenta igualmente poderosa - Dependência Parcial dirá a você: qual cliente da agência é melhor para se tornar jogador de futebol, quais clubes têm a política de transferência mais eficaz, qual treinador aumenta melhor o custo dos jogadores (além dos candidatos óbvios, existem muitas 'marcas' não tão promovidas que claramente valem uma olhada mais de perto) e muito mais.
Parte 2 - Modelo de transferências de futebol: cavando mais fundo