A capacidade de trabalhar dentro de um sistema de controle de versão é uma habilidade que todo programador precisa. Frequentemente, pode parecer que cavar no Git e entender seus elementos internos é um desperdício de tempo extra e tarefas básicas podem ser resolvidas por meio de um conjunto básico de comandos.
A equipe do AppsCast, é claro, queria aprender mais e, para obter conselhos sobre a aplicação prática de todos os recursos do Git, os caras se voltaram para
Yegor Andreyevich, da Square.
 Daniil Popov
Daniil Popov : Olá pessoal. Hoje, Yegor Andreyevich, da Square, se juntou a nós.
Egor Andreyevich : Olá a todos. Moro no Canadá e trabalho para a Square, uma empresa de software e hardware para o setor financeiro. Começamos com terminais para aceitar pagamentos com cartão de crédito, agora prestamos serviços para empresários. Estou trabalhando em um produto Cash App. Este é um banco móvel que permite trocar dinheiro com amigos, solicitar um cartão de débito para pagamento nas lojas. A empresa possui muitos escritórios em todo o mundo e o escritório canadense possui cerca de 60 programadores.
Daniil Popov : No ambiente de desenvolvedores de Android, a
Square é conhecida por seus projetos de código aberto que se tornaram padrões da indústria: OkHttp, Picasso, Retrofit. É lógico que, ao desenvolver essas ferramentas abertas a todos, você trabalha muito com o Git. Gostaríamos de conversar sobre isso.
O que é git
Egor Andreevich : Eu uso o Git há muito tempo como ferramenta e, em algum momento, tornou-se interessante para mim aprender mais sobre ele.
Git é um sistema de arquivos simplificado, além de um conjunto de operações para trabalhar com controle de versão.
O Git permite salvar arquivos em um formato específico. Cada vez que você escreve um arquivo, o Git retorna a chave do seu objeto -
hash .
Daniil Popov : Muitas pessoas perceberam que o repositório tem um diretório oculto mágico
.git . Por que é necessário? Posso excluir ou renomeá-lo?
Egor Andreevich : É possível criar um repositório através do comando
git init . Ele cria o diretório
.git que o Git usa para controlar arquivos.
O .Git armazena tudo o que você faz no seu projeto, apenas em um formato compactado. Portanto, você pode restaurar o repositório deste diretório.
Alexei Kudryavtsev : Acontece que sua pasta do projeto é uma das versões da pasta expandida do Git?
Egor Andreevich : Dependendo de qual ramo você está, o git restaura um projeto com o qual você pode trabalhar.
Alexei Kudryavtsev : O que há dentro da pasta?
Egor Andreevich : O Git cria pastas e arquivos específicos. A pasta mais importante é .git / objects, onde todos os objetos são armazenados. O objeto mais simples é o blob, essencialmente o mesmo que um arquivo, mas em um formato que o git entende. Quando você deseja salvar um arquivo de texto no repositório, o Git o compacta, arquiva, adiciona dados e cria um blob.
Existem diretórios - são pastas com subpastas, ou seja, O Git tem um tipo de objeto de
árvore que contém referências ao blob, a outras árvores.
Basicamente, uma árvore é um instantâneo que descreve o estado do seu diretório em um determinado ponto.
Ao criar uma confirmação, um link para o diretório de trabalho é uma árvore fixa.
Uma confirmação é um link para uma árvore com informações sobre quem a criou: email, nome, hora de criação, link para pai (filial pai) e mensagem. O Git também comprime e grava confirmações no diretório de objetos.
Para ver como tudo isso funciona, você precisa listar os subdiretórios na linha de comando.
Benefícios de trabalhar com o Git
Daniil Popov : Como o Git funciona? Por que o algoritmo de ação é tão complicado?
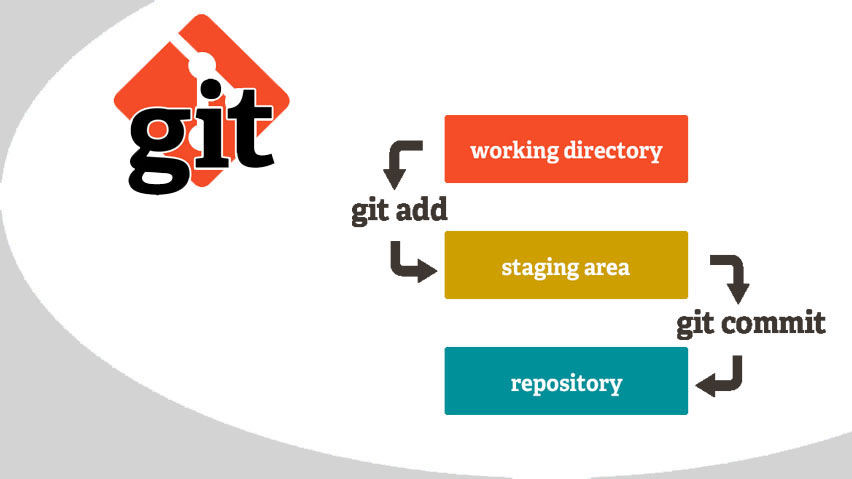
Egor Andreevich : Se você comparar o Git com o Subversion (SVN), no primeiro sistema, existem várias funções que você precisa entender. Começarei com a
área de preparação , que não deve ser considerada uma limitação do Git, mas sim dos recursos.
É sabido que, ao trabalhar com código, nem tudo acontece imediatamente: em algum lugar é necessário alterar o layout, em algum lugar para corrigir bugs. Como resultado, após uma sessão de trabalho, são exibidos vários arquivos afetados que não estão interconectados. Se você fizer todas as alterações em uma confirmação, será inconveniente, pois as alterações são de natureza diferente. Em seguida, uma série de confirmações chega à saída, que pode ser criada apenas graças à área de preparação. Por exemplo, todas as alterações no arquivo de layout são enviadas para uma série, por exemplo, corrija os testes de unidade para outra. Pegamos vários arquivos, os movemos para a área de preparação e criamos um commit apenas com a participação deles. Outros arquivos do diretório de trabalho não se enquadram nele. Assim, você divide todo o trabalho realizado no diretório de trabalho em várias confirmações, cada uma representando um trabalho específico.
Alexei Kudryavtsev : Como o Git é diferente de outros sistemas de controle de versão?
Egor Andreevich : Pessoalmente, comecei com o SVN e depois mudei imediatamente para o Git. Importante, o Git é um sistema de controle de versão descentralizado. Todas as cópias do repositório Git são exatamente iguais. Cada empresa possui um servidor em que a versão principal está localizada, mas não é diferente daquela que o desenvolvedor possui no computador.
O SVN possui um repositório central e cópias locais. Isso significa que qualquer desenvolvedor pode interromper o repositório central sozinho.
No Git, isso não vai acontecer. Se o servidor central perder os dados do repositório, eles poderão ser restaurados a partir de qualquer cópia local. O Git foi projetado de maneira diferente e oferece os benefícios da velocidade.
Daniil Popov : O Git é famoso por sua ramificação, que é notavelmente mais rápida que o SVN. Como ele faz isso?
Egor Andreevich : No SVN, um ramo é uma cópia completa do ramo anterior. Não há representação física de ramificação no Git. Este é um link para o último commit em uma linha de desenvolvimento específica. Quando o Git salva objetos, ao criar um commit, ele cria um arquivo com informações específicas sobre o commit. O Git cria um arquivo simbólico - link simbólico com um link para outro arquivo. Quando você tem muitas ramificações, refere-se a diferentes confirmações no repositório. Para rastrear o histórico de uma ramificação, você precisa ir de cada confirmação usando o link de volta para a confirmação pai.
Agências Merjim
Daniil Popov : Existem duas maneiras de mesclar duas ramificações em uma - isso é mesclar e refazer. Como você os usa?
Egor Andreevich : Cada método tem suas próprias vantagens e desvantagens.
Mesclar é a opção mais fácil. Por exemplo, existem duas ramificações: mestre e o recurso selecionado.
Para mesclar, você pode usar o avanço rápido. Isso é possível se, a partir do momento em que o trabalho foi iniciado na ramificação de recursos, nenhuma nova confirmação foi feita no mestre. Ou seja, o primeiro commit no recurso é o último commit no master.
Nesse caso, o ponteiro é fixo na ramificação principal e passa para a confirmação mais recente na ramificação do recurso. Dessa forma, a ramificação é eliminada conectando a ramificação do recurso ao encadeamento principal principal e removendo a ramificação desnecessária. Acontece uma história linear em que todos os commits se seguem. Na prática, essa opção acontece com pouca frequência, porque constantemente alguém funde as confirmações no mestre.
Pode ser de outra forma. O Git cria uma nova confirmação de consolidação - mesclagem, que possui dois links para consolidação de pais: um no mestre e outro no recurso. Com a nova confirmação, duas ramificações são conectadas e o recurso pode ser excluído novamente.
Após a consolidação da mesclagem, você pode olhar para a história e ver se ela está bifurcada. Se você usar uma ferramenta que renderiza graficamente as confirmações, visualmente ela parecerá uma árvore de Natal. Isso não quebra o Git, mas é difícil para um desenvolvedor assistir a essa história.
Outra ferramenta é
rebase . Conceitualmente, você pega todas as alterações da ramificação de recursos e as vira sobre a ramificação principal. A primeira confirmação de recurso se torna a nova confirmação sobre a confirmação principal mais recente.
Existe um problema: o Git não pode alterar confirmações. Havia um recurso de confirmação e não podemos envolvê-lo no mestre, pois cada confirmação tem um carimbo de data / hora.
No caso de rebase, o Git lê todos os commits no recurso, o salva temporariamente e o recria na mesma ordem no master. Após a rebase, as confirmações iniciais desaparecem e novas confirmações com o mesmo conteúdo aparecem na parte superior do mestre. Há problemas Quando você tenta refazer uma ramificação com a qual outras pessoas trabalham, você pode interromper o repositório. Por exemplo, se alguém iniciou sua ramificação a partir de uma confirmação que estava no recurso, e você destruiu e recriou essa confirmação. Rebase é mais adequado para filiais locais.
Daniil Popov : Se você introduzir restrições de que apenas uma pessoa trabalha em uma ramificação de recursos, concorda que não pode fazer amizade com uma ramificação de recursos de outra, então esse problema não ocorre. Mas que abordagem você pratica?
Egor Andreevich : Nós não usamos ramificações de recurso no sentido direto deste termo. Toda vez que fazemos uma alteração, crie um novo ramo, trabalhe nele e coloque-o imediatamente no mestre. Não há ramificações de longa duração.
Isso resolve um grande número de problemas com mesclagem e rebase, especialmente conflitos. As ramificações existem por uma hora e há uma alta probabilidade de avançar rapidamente, pois ninguém adicionou nada a ser dominado. Quando mesclamos na solicitação pull, apenas mesclamos com a criação de confirmação de mesclagem
Daniil Popov : Como você não tem medo de mesclar um recurso principal ocioso, porque decompor uma tarefa em intervalos de uma hora geralmente não é realista?
Egor Andreevich : Usamos a abordagem de
sinalizadores de recursos . Esses são sinalizadores dinâmicos, um recurso específico com diferentes estados. Por exemplo, a função de enviar pagamentos um para o outro é ativada ou desativada. Temos um serviço que entrega dinamicamente esse estado aos clientes. Você do servidor obtém o recurso de valor ou não. Você pode usar esse valor no código - desligue o botão que vai para a tela. O código em si está no aplicativo e pode ser liberado, mas não há acesso a essa funcionalidade, porque está atrás do sinalizador de recurso.
Daniil Popov : Muitas vezes, os recém-chegados ao Git são informados de que, após a reformulação, você precisa pressionar com força. De onde é?
Egor Andreevich : Quando você pressiona, outro repositório pode gerar um erro: você está tentando iniciar uma ramificação, mas você tem confirmações completamente diferentes nessa ramificação. O Git verifica todas as informações para que você não quebre o repositório acidentalmente. Quando você diz
git push force , desative essa verificação, acreditando que você conhece melhor que ele, e exija reescrever o ramo.
Por que isso é necessário após o rebase? Rebase recria confirmações. Acontece que o ramo também é chamado, mas confirma com outros hashes, e Git jura com você. Nessa situação, é absolutamente normal fazer um empurrão forçado, pois você está no controle da situação.
Daniil Popov : Ainda existe o conceito de
rebase interativa , e muitos têm medo disso.
Egor Andreevich : Não há nada terrível. Devido ao fato de o Git recriar a história durante o rebase, ele a armazena temporariamente antes de lançá-la. Quando possui armazenamento temporário, pode fazer qualquer coisa com confirmações.
Rebase no modo interativo pressupõe que o Git before rebase lança uma janela de um editor de texto na qual você pode especificar o que precisa ser feito com cada confirmação individual. Parece várias linhas de texto, em que cada linha é um dos commits que estão na ramificação. Antes de cada confirmação, há uma indicação da operação que vale a pena executar. A operação padrão mais simples é
escolher , ou seja, tomar e incluir na rebase. O mais comum é o
squash , então o Git pegará as alterações desse commit e o mesclará com as alterações do anterior.
Muitas vezes, existe esse cenário. Você trabalhou localmente em sua filial e criou confirmações para salvar. O resultado é uma longa história de confirmações, o que é interessante para você, mas da mesma forma não deve ser despejada na história principal. Então você dá squash para renomear para o commit geral.
A lista de equipes é longa. Você pode lançar o commit -
drop e desaparecer, alterar a mensagem de commit, etc.
Alexei Kudryavtsev : Quando você tem conflitos em rebase interativa, passa por todos os círculos do inferno.
Egor Andreevich : Estou muito longe de compreender toda a sabedoria do rebase interativo, mas é uma ferramenta poderosa e complexa.
Aplicação prática do Git
Daniil Popov : Vamos para a prática. Na entrevista, muitas vezes pergunto: “Você tem mil commits. No primeiro está tudo bem, no milésimo teste quebrado. Como encontrar a mudança que levou a isso com a ajuda de um gita?
Egor Andreevich : Nesta situação, você precisa usar a
bissetriz , embora seja mais fácil culpar.
Vamos começar com o interessante. O Git bisect é aplicável a uma situação em que você tem regressão - foi funcional, funcionou, mas parou subitamente. Para descobrir quando a funcionalidade foi interrompida, teoricamente, você pode reverter aleatoriamente para a versão anterior do aplicativo, ver o código, mas existe uma ferramenta que permitirá uma abordagem estruturada do problema.
Git bisect é uma ferramenta interativa. Existe um comando git bisect bad através do qual você relata a presença de um commit quebrado e o git bisect good - para um commit em funcionamento. Cada vez que o aplicativo é lançado, lembramos do hash do commit a partir do qual o release foi feito. Esse hash também pode ser usado para indicar confirmações ruins e boas. O Bisect recebe informações sobre o intervalo em que um dos commits quebrou a funcionalidade e inicia uma sessão de
pesquisa binária , onde gradualmente emite os commit para verificar se eles funcionam ou não.
Você iniciou a sessão, o Git muda para uma das confirmações no intervalo, informa isso. No caso de mil confirmações, não haverá muitas iterações.
A verificação terá que ser feita manualmente: através de testes de unidade ou execute o aplicativo e clique manualmente. Git bisect é convenientemente programável. Cada vez que ele emite um commit, você fornece a ele um script para verificar se o código está funcionando.
A culpa é uma ferramenta mais simples que, com base em seu nome, permite encontrar o "culpado" de uma falha funcional. Devido a essa definição negativa, muitos membros da comunidade de culpa não gostam disso.
O que ele esta fazendo? Se você atribuir ao git culpado um arquivo específico, ele linearmente neste arquivo mostrará qual confirmação alterou esta ou aquela linha. Eu nunca usei a culpa do git na linha de comando. Como regra, isso é feito no IDEA ou no Android Studio - clique e veja quem alterou qual linha do arquivo e em que confirmação.
Daniil Popov : A propósito, no Android Studio era chamado Annotate. A conotação negativa da culpa foi removida.
Alexei Kudryavtsev : Exatamente, no xCode eles o renomearam Autores.
Egor Andreevich : Eu também li que há um elogio ao utilitário git - para encontrar quem escreveu esse excelente código.
Daniil Popov : Note-se que, sob a culpa, as sugestões dos revisores sobre o trabalho de solicitação de recebimento. Ele olha quem tocou em um arquivo específico, acima de tudo, e sugere que essa pessoa poderá revisar bem seu código.
No caso do exemplo, cerca de mil confirmações, a culpa em 99% dos casos mostrará o que deu errado. Bisect já é o último recurso.
Egor Andreevich : Sim, eu uso bissectos muito raramente, mas uso anotações regularmente. Embora, às vezes, seja impossível entender por que é nulo verificado na linha de código, fica claro em todo o commit o que o autor queria fazer.
Como trabalhar com PRs empilhados?
Daniil Popov : Ouvi dizer que o Square usa solicitações de recebimento empilhado (PRs).
Egor Andreevich : Pelo menos em nossa equipe de Android, costumamos usá-los.
Dedicamos muito tempo para facilitar a revisão de cada solicitação pull. Às vezes, há uma tentação de alimentar, alimentar rapidamente e deixar os revisores entenderem. Tentamos criar pequenas solicitações pull e uma breve descrição - o código deve falar por si. Quando as solicitações pull são pequenas, é fácil e rápido gritar.
É aqui que o problema surge. Você está trabalhando em um recurso que exigirá um grande número de alterações na base de código. O que você pode fazer? Você pode colocá-lo em uma solicitação pull, mas será enorme. Você pode trabalhar criando gradualmente uma solicitação pull, mas o problema será que você criou uma ramificação, adicionou algumas alterações e enviou uma solicitação pull, retornou ao mestre e o código que você tinha na solicitação pull não estará disponível no master até mesclagem não vai acontecer. Se você depende de alterações nesses arquivos, é difícil continuar trabalhando porque não existe esse código.
Como contornar isso? Depois de criarmos a primeira solicitação pull, continuamos a trabalhar, crie uma nova ramificação a partir da ramificação existente, que usamos antes da solicitação pull. Cada ramificação não vem do mestre, mas da ramificação anterior. Quando terminarmos o trabalho nessa parte da funcionalidade, envie outra solicitação de recebimento e indique novamente que, com a mesclagem, ela não se mescla no mestre, mas na ramificação anterior. Acontece uma cadeia de solicitações pull - prs empilhados. Quando uma pessoa revisa, ela vê as alterações que foram feitas apenas por esse recurso, mas não a anterior.
A tarefa é tornar cada solicitação de recebimento o mais pequena e clara possível, para que não haja necessidade de alteração. Porque se você precisar alterar o código nos ramos que estão no meio da pilha, tudo no topo será interrompido, porque você precisará refazer a recuperação. Se as solicitações pull são pequenas, tentamos congelá-las o mais rápido possível, e todas as mesclagens empilhadas passo a passo no master.
Daniil Popov : Entendo corretamente que, no final, haverá uma última solicitação de recebimento que contém todos os pedidos de recebimento pequenos. Você derrama esse fio sem olhar?
Egor Andreevich : A mesclagem vem da origem empilhada: primeiro, a primeira solicitação pull é mesclada no master, no próximo, a base muda do ramo para o master e, consequentemente, o Git calcula que já existem algumas alterações no master, menos snapshot.
Alexei Kudryavtsev : Você tem condições de corrida quando o primeiro ramo já está congelado e somente depois o segundo parou no primeiro porque não mudou o alvo para dominar?
Egor Andreevich :
Seguramos com a mão, então não existem situações assim. Abro uma solicitação de recebimento, anote os colegas dos quais quero obter uma revisão e, quando estiverem prontos, vou ao bitbucket, pressione mesclar.
Alexei Kudryavtsev : Mas e quanto à verificação da CI de que nada está quebrado?
Egor Andreevich : Nós não fazemos isso. O IC é executado na ramificação, que é a base para a solicitação de recebimento e, após a verificação, alteramos a base. Tecnicamente, isso não muda, pois você também segmenta o número de alterações.
Daniil Popov : Você vai direto ao mestre ou se desenvolve? E quando você libera, indica explicitamente o commit do qual coletar?
Egor Andreevich : Não temos desenvolvimento, apenas mestre. Definitivamente lançaremos a cada duas semanas. Quando começamos a preparar uma liberação, abrimos uma ramificação de liberação e algumas últimas correções vão para o mestre e para essa ramificação. Usamos tags - links permanentes para um commit específico, opcionalmente com algumas informações. Se algum tipo de commit for um release, seria bom manter no histórico que fizemos um release a partir desse commit. Uma tag é criada, o Git salva as informações da versão e você pode retornar posteriormente.
Alexei Kudryavtsev : Onde ensinar Git, o que ler?
Egor Andreevich : O Git tem um
livro oficial . Eu gosto do jeito que está escrito, há bons exemplos. Há um capítulo sobre o interior, você pode estudá-lo completamente. Você pode encontrar muitas situações e soluções esotéricas no StackOverflow. Eles também podem ser usados.
Não falaremos sobre o Git no próximo Saint AppsConf . Por outro lado, decidimos fazer um experimento e adicionamos relatórios introdutórios ao programa da conferência, em que palestrantes de indústrias de desenvolvimento relacionadas compartilham conhecimento para expandir os horizontes de um desenvolvedor móvel. Aconselhamos que você preste atenção na apresentação de Nikolai Golov, da Avito, sobre bancos de dados : como não cometer um erro e escolher o banco de dados certo, como se preparar para o crescimento e o que é relevante em 2019.
O AppsCast é lançado a cada duas semanas às quartas-feiras e, se você preferir a versão em áudio à versão em texto, inscreva-se no SoundCloud , curta e discuta tópicos em nosso bate-papo .