Oi Temos mais de 15.260 objetos e 38.000 dispositivos de rede que precisam ser configurados, atualizados e verificados para estarem operacionais. A manutenção dessa frota de equipamentos é bastante difícil e requer muito tempo, esforço e pessoas. Portanto, precisávamos automatizar o trabalho com equipamentos de rede e decidimos adaptar o conceito de Rede como um código para gerenciar a rede em nossa empresa. Leia o histórico de automação, os erros cometidos e um plano adicional para a construção de sistemas.
Para encurtar a história, queremos automatizar a rede
Oi Meu nome é Alexander Prokhorov e, junto com a equipe de engenheiros de rede de nosso departamento, estamos
trabalhando em uma rede no
#IT X5 . Nosso departamento desenvolve infraestrutura de rede, monitoramento, automação de rede e a direção moderna da Rede como um Código.
Inicialmente, eu realmente não acreditava em nenhuma automação em nossa rede em princípio. Havia muitos erros legados e de configuração - nem em todos os lugares havia autorização central, nem todo o hardware era compatível com SSH, nem em todo lugar em que o
SNMP estava configurado. Tudo isso minou muito a crença na automação. Portanto, em primeiro lugar, colocamos em ordem o necessário para iniciar a automação, a saber: padronização da conexão SSH, perfis de autorização única (
AAA ) e SNMP. Toda essa base permite que você escreva uma ferramenta para entrega em massa de configurações para um dispositivo, mas surge a pergunta: posso obter mais? Então chegamos à necessidade de elaborar um plano para o desenvolvimento da automação e, em particular, o conceito de Rede como Código.
O conceito de rede como código, de acordo com a Cisco, significa os seguintes princípios:
- Armazenar configurações de destino no repositório, Controle de Origem
- As alterações de configuração passam pelo repositório, Fonte Única da Verdade
- Incorporando configurações através da API

Os dois primeiros pontos permitem aplicar a abordagem DevOps ou NetDevOps para gerenciar sua infraestrutura de rede. Com o terceiro parágrafo, há dificuldades, por exemplo, o que fazer se não houver API? Claro, SSH e CLI, somos networkers!
E isso é tudo o que precisamos?A aplicação desses princípios por si só não resolve todos os problemas da infraestrutura de rede, assim como a aplicação deles requer uma certa base com os dados da rede.
Perguntas que surgiram quando pensamos sobre isso:
- OK, eu guardo a configuração como código, como devo aplicá-la em um objeto específico?
- Ok, eu tenho um modelo de configuração no repositório, mas como posso configurar automaticamente uma configuração para um objeto com base nele?
- Como descobrir qual modelo e qual fornecedor deve estar nesse objeto? Posso fazer isso automaticamente?
- Como posso verificar se as configurações atuais do objeto correspondem aos parâmetros no repositório?
- Como trabalhar com alterações no repositório e replicá-las em uma rede produtiva?
- Que conjunto de dados e sistemas eu preciso pensar sobre o Zero Touch Provisioning?
- E as diferenças de fornecedores e até modelos do mesmo fornecedor?
- Como armazenar sub-redes para configuração automática?
Com base em todas as perguntas acima, ficou claro que precisamos de um conjunto de sistemas que resolvam vários problemas, trabalhem em conjunto e nos forneçam informações completas sobre a infraestrutura de rede.

Além de tentar aplicar novas abordagens ao gerenciamento de rede, queríamos resolver alguns problemas mais agudos na infraestrutura de rede, como integridade dos dados, atualização e, é claro, automação. Por automação, entendemos não apenas a entrega em massa de configurações para o equipamento, mas também a configuração automática, a coleta automática de dados de inventário de equipamentos de rede e a integração com sistemas de monitoramento. Mas as primeiras coisas primeiro.
A funcionalidade que visamos é:
- Banco de dados de equipamentos de rede (+ descoberta, + atualização automática)
- Endereços de rede base (verificações de validação IPAM +)
- Integração de sistemas de monitoramento com dados de inventário
- Armazenamento de padrões de configuração no sistema de controle de versão
- Formação automática de configurações de destino para um objeto
- Entrega em massa de configurações para equipamentos de rede
- Implemente um processo de CI / CD para gerenciar alterações na configuração da rede
- Testando configurações de rede com CI / CD
- ZTP (Zero Touch Provisioning) - configuração automática de equipamento para um objeto
Longa história, tentamos automatizarComeçamos a tentar automatizar o trabalho de configuração de rede há 2 anos. Por que agora essa pergunta surgiu novamente e precisa de atenção?
É cansativo e chato configurar mais de algumas dezenas de dispositivos com as mãos. Às vezes, a mão do engenheiro se contrai e ele comete erros. Para várias dezenas, geralmente é suficiente um script escrito por um engenheiro, que lança as configurações atualizadas no equipamento de rede.
Por que não parar por aí? De fato, muitos engenheiros de rede já sabem como fazer todos os tipos de pitões, e aqueles que não sabem como poderão fazê-lo muito em breve (Natalya Samoilenko, no entanto, publicou
um excelente trabalho em Python , especialmente para redes). Qualquer pessoa encarregada de configurar os roteadores n + 1 pode escrever um script e implementar as configurações muito rapidamente. Muito mais rápido do que então capaz de trazer tudo de volta. De acordo com a experiência da automação “todo homem por si”, ocorrem erros quando você pode restaurar a comunicação apenas com as mãos e apenas com grande sofrimento de toda a equipe.

Exemplo
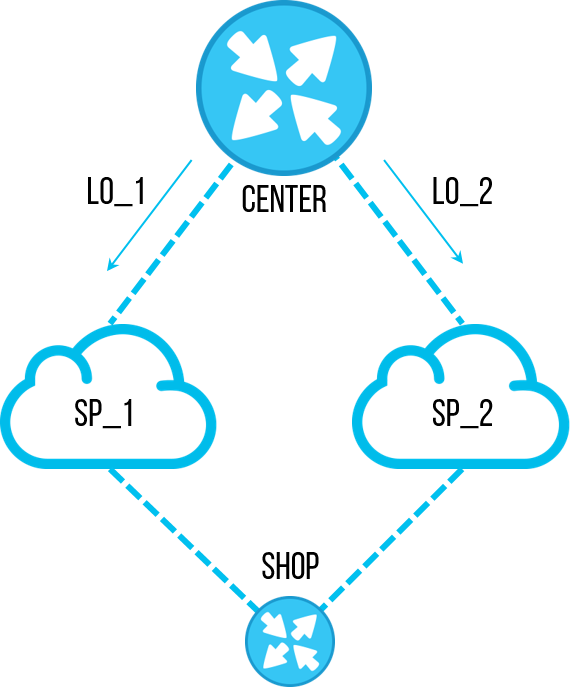
Uma vez, um dos engenheiros decidiu executar uma tarefa importante - restaurar a ordem nas configurações dos roteadores. Como resultado da auditoria em vários objetos, foi encontrada uma
lista de prefixos obsoleta com sub-redes específicas, das quais não precisamos mais. Anteriormente, era usado para filtrar os endereços de
loopback dos sites centrais para que eles passassem por apenas um canal, e podíamos testar a conexão nesse canal. Mas o mecanismo foi otimizado e eles pararam de usar esse esquema de teste de canal. O funcionário decidiu remover essa
lista de prefixos para não aparecer na configuração e causar confusão no futuro. Todos concordaram em excluir a
lista de prefixos não utilizados, a tarefa é simples, eles se esqueceram imediatamente. Mas remover a mesma
lista de prefixos com as mãos em dezenas de objetos é muito chato e demorado. E o engenheiro escreveu um script que passará rapidamente pelo equipamento, não fará
"lista de prefixos pl-cisco-primer" e salvará solenemente a configuração.
Algum tempo depois da discussão, algumas horas ou um dia, não me lembro, um objeto caiu. Depois de alguns minutos, outro, semelhante. O número de objetos inacessíveis continuou a crescer, em meia hora para 10 e a cada 2-3 minutos, um novo foi adicionado. Todos os engenheiros foram conectados para o diagnóstico. 40 a 50 minutos após o início do acidente, todos foram questionados sobre as alterações e o funcionário interrompeu o script. Naquela época, já havia cerca de 20 objetos com canais quebrados. Uma restauração completa levou sete engenheiros por várias horas.
Lado técnico
A lista de prefixos foi usada para filtrar os
loopbacks - um foi filtrado em um canal e o segundo no backup. Isso foi usado para testar a comunicação sem alternar o tráfego produtivo entre os canais. Portanto, a primeira regra de um
mapa de rota de entrada em um vizinho
BGP foi
DENY com
"lista de prefixos de endereços IP correspondentes" . O restante das regras no
mapa de rotas foram todas
permitidas .
Existem várias nuances que podem ser dignas de nota:
- A regra do mapa de rotas na qual não há correspondência - ignora tudo
- No final da lista de prefixos está negado implícito , mas apenas se não estiver vazio
- Uma lista de prefixos vazia é uma permissão implícita
Todas as alternativas acima são verdadeiras para o
Cisco IOS . Uma
lista de prefixos vazia pode aparecer quando você declarar um
mapa de rotas , faça com que
“corresponda à lista de prefixos de endereços IP pl-test-cisco” . Esta
lista de prefixos não será declarada explicitamente na configuração (além da linha com
correspondência ), mas pode ser encontrada na
lista de prefixos IP da mostra .
2901-NOC-4.2(config)#route-map rm-test-in 2901-NOC-4.2(config-route-map)#match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh run | i prefix match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh ip prefix ip prefix-list pl-test-in: 0 entries 2901-NOC-4.2(config-route-map)#
Voltando ao que aconteceu, quando a
lista de prefixos foi excluída pelo script, ela ficou vazia, porque ainda estava na primeira regra
DENY no
mapa de rotas . Uma
lista de prefixos vazia permite todas as sub-redes; portanto, tudo o que um par de
BGP nos passou passou para a primeira regra
DENY .
Por que o engenheiro não notou imediatamente que ele havia quebrado a conexão? Aqui desempenhou o papel de temporizadores
BGP na Cisco.
O próprio
BGP não troca rotas de acordo com o cronograma e, se você atualizou a política de roteamento do
BGP , é necessário redefinir a sessão do BGP para aplicar as alterações,
"clear ip bgp <peer-ip>" à Cisco.
Para não redefinir a sessão, existem dois mecanismos:
- Reconfiguração suave da Cisco
- Atualização de rota como RFC2918
A reconfiguração suave retém as informações recebidas em
UPDATE do vizinho sobre as rotas até que as políticas sejam aplicadas
na tabela local
adj-RIB-in . Ao atualizar políticas, torna-se possível emular
UPDATE de um vizinho.
A atualização de rota é a "capacidade" dos pares de enviar
UPDATE mediante solicitação. A disponibilidade desta oportunidade é acordada ao estabelecer um bairro. Prós - Não há necessidade de armazenar uma cópia do
UPDATE localmente. Contras - na prática, após uma solicitação
UPDATE de um vizinho, você precisa esperar até que ele a envie. A propósito, você pode desativar o recurso na Cisco com um comando oculto:
neighbor <peer-ip> dont-capability-negotiate
Há um recurso não documentado da Cisco - um temporizador de 30 segundos, que é acionado por uma alteração nas políticas de
BGP . Depois de alterar as políticas, em 30 segundos o processo de atualização de rotas usando uma das tecnologias acima será iniciado. Não foi possível encontrar uma descrição documentada desse timer, mas há uma menção no
BUG CSCvi91270 . Você pode aprender sobre sua disponibilidade na prática,

depois de fazer alterações no laboratório e procurar
depurar solicitações
UPDATE para o vizinho ou o
processo de reconfiguração suave . (Se houver informações adicionais sobre o tópico - você pode deixar nos comentários)
Para
a reconfiguração suave , o cronômetro funciona da seguinte maneira:
2901-NOC-4.2(config)#no ip prefix-list pl-test seq 10 permit 10.5.5.0/26 2901-NOC-4.2(config)#do sh clock 16:53:31.117 Tue Sep 24 2019 Sep 24 16:53:59.396: BGP(0): start inbound soft reconfiguration for Sep 24 16:53:59.396: BGP(0): process 10.5.5.0/26, next hop 10.0.0.1, metric 0 from 10.0.0.1 Sep 24 16:53:59.396: BGP(0): Prefix 10.5.5.0/26 rejected by inbound route-map. Sep 24 16:53:59.396: BGP(0): update denied, previous used path deleted Sep 24 16:53:59.396: BGP(0): no valid path for 10.5.5.0/26 Sep 24 16:53:59.396: BGP(0): complete inbound soft reconfiguration, ran for 0ms Sep 24 16:53:59.396: BGP: topo global:IPv4 Unicast:base Remove_fwdroute for 10.5.5.0/26 2901-NOC-4.2(config)#
Para
atualização de
rota do lado do vizinho, assim:
2801-RTR (config-router)# *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 rcv REFRESH_REQ for afi/sfai: 1/1 *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 start outbound soft reconfig for afi/safi: 1/1
Se
a Atualização de rota não
for suportada por um dos pares e
a entrada de reconfiguração suave não estiver ativada, a atualização de rotas pela nova política não ocorrerá automaticamente.
Assim,
a lista de prefixos foi excluída, a conexão permaneceu, após 30 segundos desapareceu. O script conseguiu alterar a configuração, verificar a conexão e salvar a configuração. A queda do script não foi conectada imediatamente, no contexto de um grande número de objetos.
Tudo isso poderia ser facilmente evitado através de testes, replicação parcial de configurações.Há um entendimento de que a automação deve ser centralizada e controlada.

Os sistemas que precisamos e suas conexões
Uma breve conclusão do spoiler - é melhor sistematizar e controlar o processo de entrega em massa de configurações para não chegar à entrega em massa de erros nas configurações.
- DevOps: 50ms 4 - : ", !@#$%"
O esquema a que chegamos consiste em blocos de dados mestre de "negócios", blocos de dados mestre de "rede", sistemas de monitoramento de infraestrutura de rede, sistemas de entrega de configuração, sistemas de controle de versão com uma unidade de teste.
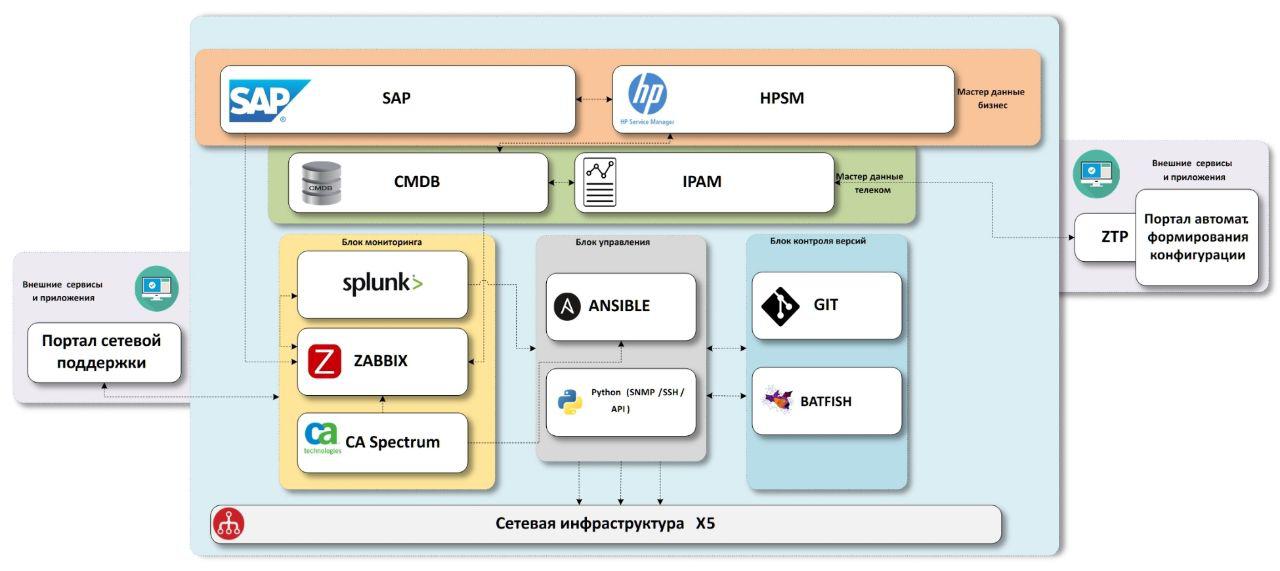
Tudo o que precisamos é de dados
Primeiro, precisamos saber quais objetos estão na empresa.
Sistema da empresa
SAP -
ERP . Os dados sobre quase todas as instalações estão lá, e mais precisamente em todas as lojas e centros de distribuição. Assim como existem dados sobre equipamentos que passaram por um armazém de TI com números de estoque, que também serão úteis para nós no futuro. Apenas faltam escritórios, eles não são iniciados no sistema. Estamos tentando resolver esse problema em um processo separado. A partir do momento da abertura, precisamos de uma conexão em cada objeto e selecionamos as configurações de comunicação; portanto, em algum momento, neste momento, precisamos criar dados mestre. Mas a insuficiência de dados é um tópico separado; é melhor colocar essa descrição em um artigo separado, se houver interesse nisso.
HPSM - um sistema que contém um
CMDB comum para TI, gerenciamento de incidentes, gerenciamento de mudanças. Como o sistema é comum a toda a TI, ele deve ter todo o equipamento de TI, incluindo o equipamento de rede. Este é o local onde adicionaremos todos os dados finais na rede. Com o gerenciamento de incidentes e mudanças, planejamos interagir a partir de sistemas de monitoramento no futuro.
Sabemos quais objetos temos e os enriquecemos com dados na rede. Para esse fim, temos dois sistemas -
IPAM da
SolarWinds e nosso próprio sistema CMDB.noc.
IPAM - armazenamento de sub-redes IP, os dados mais corretos e corretos sobre a propriedade do endereço IP na empresa devem estar aqui.
CMDB.noc - um banco de dados com uma interface WEB na qual os dados estáticos dos equipamentos de rede são armazenados - roteadores, comutadores, pontos de acesso, além de provedores e suas características. Sob estática, significa que sua mudança é realizada apenas com a participação do homem. Em outras palavras, a descoberta automática não faz alterações nesse banco de dados; precisamos entender o que "deve" ser instalado no objeto. Sua base é necessária como um amortecedor entre os sistemas produtivos com os quais toda a empresa trabalha e as ferramentas de rede internas. Acelera o desenvolvimento, adicionando os campos necessários, novos relacionamentos, ajustando parâmetros, etc. Além disso, esta solução não está apenas na velocidade do desenvolvimento, mas também na presença desses relacionamentos entre os dados de que precisamos, sem compromisso. Como um mini-exemplo, usamos vários
exid no banco de dados para comunicação entre IPAM, SAP e HPSM.
Como resultado, recebemos dados completos sobre todos os objetos, com equipamentos de rede e endereços IP conectados. Agora precisamos de modelos de configuração ou serviços de rede que fornecemos nesses sites.

Fonte única da verdade
Aqui, chegamos à aplicação do primeiro princípio NaaC - armazenando configurações de destino no repositório. No nosso caso, este é o Gitlab. A escolha para nós foi simples:
- Em primeiro lugar, já temos essa ferramenta em nossa empresa, não precisamos implantá-la do zero
- Em segundo lugar, é bastante adequado para todas as nossas tarefas atuais e futuras na infraestrutura de rede
A principal parte interessante da automação acontecerá no Gitlab - o processo de alterar o padrão de configuração ou, mais simplesmente, o modelo.
Exemplo de processo de mudança padrão
Um dos tipos de objetos que temos é a loja Pyaterochka. Lá, uma topologia típica consiste em um roteador e um / dois comutadores. O arquivo de configuração do modelo é armazenado no Gitlab, nesta parte tudo é simples. Mas isso não é exatamente NaaC.
Agora, digamos que um novo projeto chegue até nós. As tarefas do novo projeto de TI são fazer um piloto em um determinado volume de lojas. De acordo com os resultados do piloto - se for bem-sucedido, faça uma replicação para todos os objetos desse tipo; caso contrário, retire o piloto sem executar uma replicação.
Esse processo se encaixa muito bem na lógica do Git:
- Para um novo projeto, criamos um Branch, onde fazemos alterações nas configurações.
- No Branch, também mantemos uma lista de objetos nos quais este projeto está sendo testado.
- Se for bem-sucedido, fazemos uma solicitação de mesclagem na ramificação principal, que precisará ser replicada para a rede de produtos
- Em caso de falha, deixe o Branch para o histórico ou simplesmente exclua

Em uma primeira aproximação - mesmo sem automação, é uma ferramenta muito conveniente para trabalhar juntos em uma configuração de rede. Especialmente se você imaginar que três ou mais projetos surgiram ao mesmo tempo. Quando chegar a hora do lançamento dos projetos no prod, você precisará resolver todos os conflitos de configuração nas solicitações de mesclagem e verificar se as alterações nas configurações não são mutuamente exclusivas. E isso é muito conveniente para fazer no git.
Além disso, essa abordagem nos adiciona a flexibilidade de usar as ferramentas de CI / CD do Gitlab para testar virtualmente as configurações, para automatizar a entrega de configurações para uma bancada de testes ou um grupo piloto de objetos. // E mesmo em prod, se você quiser.
Implantando a configuração em qualquer ambiente
Inicialmente, o objetivo principal era precisamente a entrega em massa de configurações, como uma ferramenta que claramente permite economizar tempo dos engenheiros e acelerar a execução das tarefas de configuração. Para fazer isso, mesmo antes do início da grande atividade “Rede como um código”, escrevemos uma solução em
python para conectar-se a equipamentos para coletar configurações de equipamentos ou para configurá-las. Isto é
netmiko , isto é
pysnmp , isto é
jinja2 , etc.
Mas é hora de dividirmos a configuração em massa em várias subespécies:
Entrega de configurações para zonas de teste e pilotoEsse item é baseado no Gitlab CI, que permite ativar a entrega da configuração nas zonas piloto e de teste no pipeline.
Duplicação de configurações no prod- Um item separado, geralmente a replicação para dispositivos de 38k, ocorre em várias ondas - aumentando o volume - para monitorar a situação no prod. Além disso, um trabalho dessa magnitude requer coordenação do trabalho, portanto, é melhor iniciar esse processo manualmente. Para isso, é conveniente usar o Ansible + -AWX e fixar a compilação dinâmica de inventário dos nossos sistemas de dados mestre.
- Além disso, é uma solução conveniente quando você precisa fornecer à segunda linha o lançamento de playbooks pré-configurados que executam operações complexas e importantes, como a troca de tráfego entre sites.
Coleta de dados- Descoberta automática de dispositivos de rede
- Configurações de backup
- Verifique a conectividade
Alocamos essa tarefa em um bloco separado, pois há momentos em que alguém desmantela um switch de repente ou instala um novo dispositivo, mas não sabíamos disso com antecedência. Consequentemente, este dispositivo não estará em nossos dados mestre e ficará fora do processo de entrega da configuração, monitoramento e, em geral, trabalho operacional. Acontece que o equipamento foi instalado legitimamente, mas a configuração foi "vazada" incorretamente e, por algum motivo,
ssh ,
snmp ,
aaa ou senhas não padrão para acesso não funcionam lá. Para fazer isso, temos o python para tentar todos os métodos de conexão
herdados possíveis que poderíamos ter na empresa, criar força bruta para todas as senhas antigas e tudo para chegar ao pedaço de ferro e prepará-lo para trabalhar com monitoramento e monitoramento. .
Existe uma maneira simples: tornar vários arquivos de
inventário ansible, onde descrever todos os dados possíveis para conexões (todos os tipos de fornecedores com todos os pares possíveis de nome de usuário / senha) e executar um
manual para cada variante de
inventário . Esperávamos uma solução melhor, mas na conferência RedHat, o arquiteto Ansible aconselhou da mesma maneira. Geralmente, supõe-se que você saiba antecipadamente com o que está se conectando.
Queríamos uma solução universal - ao remover um backup, procure novos equipamentos e, se encontrado, adicione-os a todos os sistemas necessários. Portanto, escolhemos uma solução em python - saiba o que poderia ser mais bonito do que um programa que pode detectar um hardware de rede para conectar-se a ele, independentemente do que estiver configurado nele (dentro de limites razoáveis, é claro), configure conforme necessário, remova a configuração e, ao mesmo tempo, Adicione dados da API aos sistemas necessários.
Verificação como monitoramento
Uma das tarefas da automação é, obviamente, descobrir o que aconteceu com essa automação. Nem todos os 38k estão configurados perfeitamente na primeira vez, até acontece que alguém configura o equipamento com as mãos. E é necessário rastrear essas alterações e restaurar a
justiça na configuração de destino.
Existem três abordagens para verificar a conformidade da configuração com o padrão:
- Faça uma verificação uma vez por período - descarregue o estado atual, verifique o alvo e corrija as deficiências identificadas.
- Sem verificar nada, uma vez por período - implante as configurações de destino. É verdade que existe o risco de quebrar algo - talvez não houvesse tudo na configuração de destino.
- Uma abordagem conveniente é quando as diferenças da configuração de destino na Fonte Única da Verdade são consideradas alertas e são monitoradas pelo sistema de monitoramento. Isso inclui: uma incompatibilidade com o padrão de configuração atual, uma diferença entre o hardware e o especificado nos dados mestre, uma incompatibilidade com os dados no IPAM .
No terceiro caso, uma opção parece transferir esse trabalho para o gerenciamento de incidentes (SO), para que as inconsistências sejam eliminadas em pequenas porções durante todo o tempo do que uma vez por emergência.
O Zabbix , sobre o qual escrevi anteriormente no artigo
“Como monitoramos 14.000 objetos”, é o nosso sistema de monitoramento de objetos distribuídos, onde podemos fazer disparos e alertas em que podemos pensar. Desde que escrevemos o último artigo, atualizamos para o Zabbix 4.0
LTS .
Com base no
Web Zabbix, fizemos uma atualização em nosso portal de suporte de rede, onde agora você pode encontrar todas as informações sobre um objeto em todos os nossos sistemas em uma única tela, além de executar scripts para verificar se há problemas frequentes.
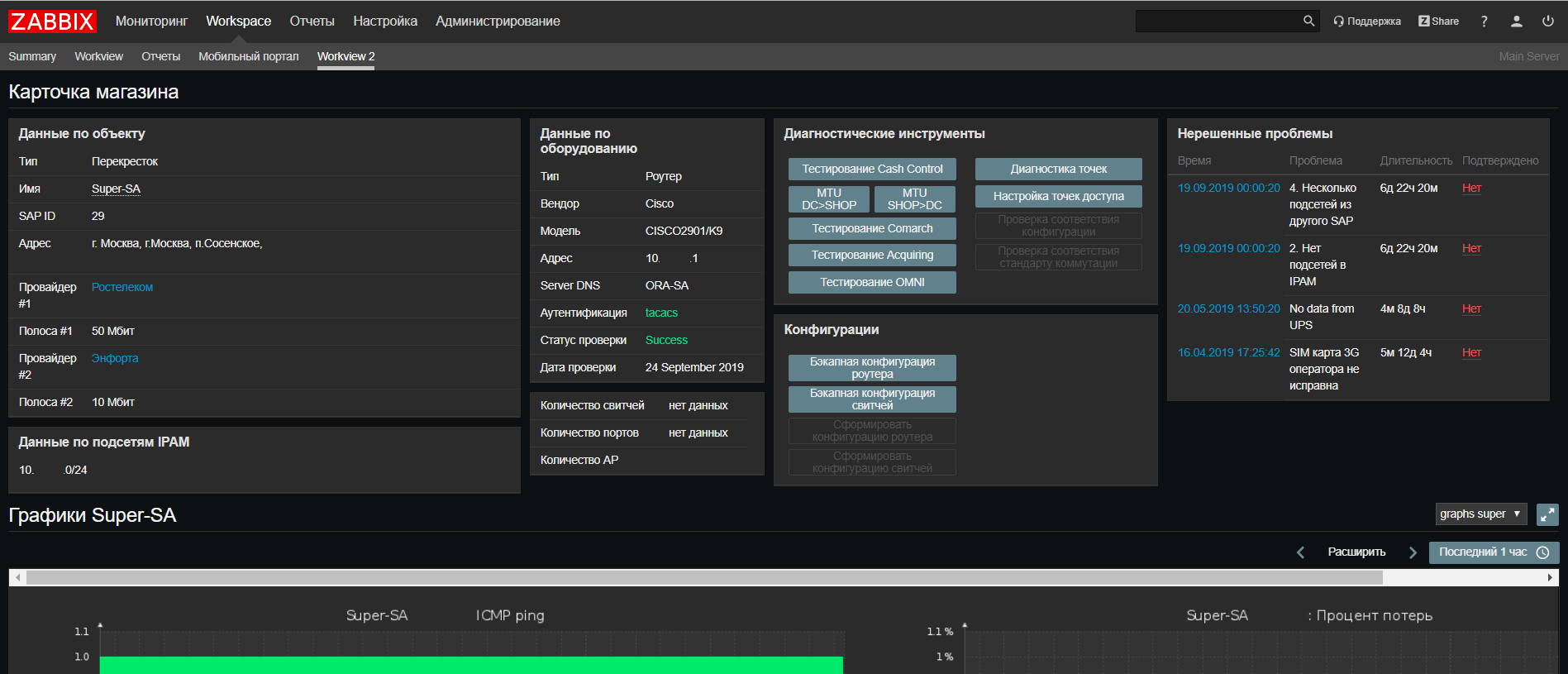
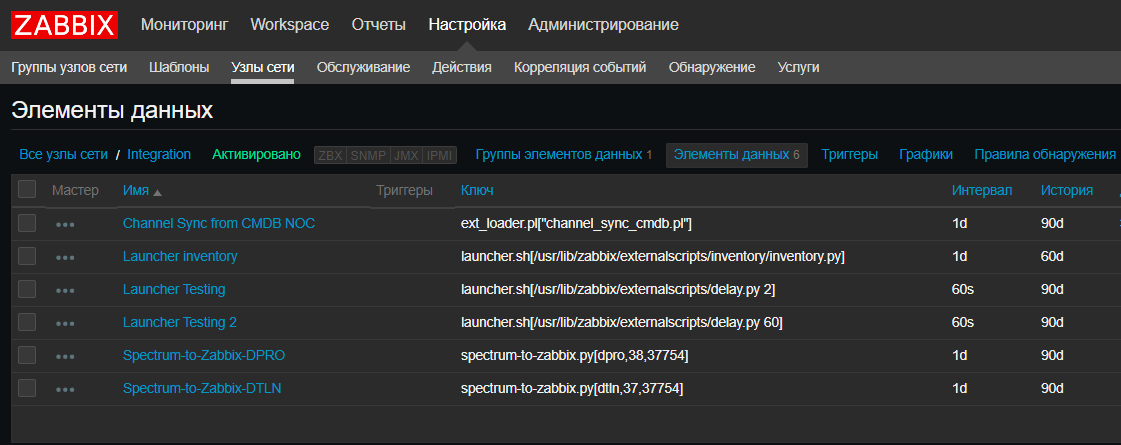
Também introduzimos um novo recurso - para nós, o Zabbix se tornou, de alguma forma, um
CRON para o lançamento de scripts agendados, como scripts de integração de sistemas, scripts de descoberta automática. Isso é realmente conveniente quando você precisa examinar os scripts atuais e quando e onde eles são executados sem verificar todos os servidores. É verdade que, para scripts que são executados por mais de 30 segundos, você precisará de um
iniciador que os inicie sem esperar pelo fim. Felizmente, é simples:
 Splunk
Splunk é uma solução que permite coletar logs de eventos de equipamentos de rede e também pode ser usada para monitorar a automação. Por exemplo, coletando um backup de configuração, um script
python gera uma mensagem de
LOG CFG-5-BACKUP , um roteador ou switch envia uma mensagem para o Splunk, na qual contamos o número de mensagens desse tipo nos equipamentos de rede. Isso nos permite rastrear a quantidade de equipamento que o script detectou. E vemos quantas peças de ferro foram capazes de reportar isso ao
Splunk e verificamos se as mensagens de todas as peças de ferro chegaram.
O Spectrum é um sistema abrangente que usamos para monitorar objetos críticos, uma ferramenta bastante poderosa que nos ajuda muito na solução de incidentes críticos de rede. Na automação, usamos apenas os dados extraídos, não é
de código aberto , portanto as possibilidades são um pouco limitadas.
A cereja no bolo

Usando sistemas com dados mestres no equipamento, podemos pensar em criar ZTP, ou Zero Touch Provisioning. Como um botão "auto-tuning", mas apenas sem um botão.
Temos todos os dados necessários dos blocos anteriores - sabemos o objeto, seu tipo, que equipamento existe (fornecedor e modelo), quais são os endereços (IPAM), qual é o padrão de configuração atual (Git). Ao reunir todos eles, podemos pelo menos preparar um modelo de configuração para fazer o upload para o dispositivo, será mais parecido com o One Touch Provisioning, mas às vezes não é necessário mais.
O True Zero Touch precisa de uma maneira de entregar automaticamente a configuração ao hardware não configurado. Além disso, é desejável, independentemente do fornecedor. Existem várias opções de trabalho - um servidor de console, se todo o equipamento passar pelo armazém central, soluções de console móvel, se o equipamento chegar imediatamente. Estamos apenas trabalhando nessas soluções, mas assim que houver uma opção de trabalho, podemos compartilhá-la.
Conclusão
No total, em nosso conceito de
rede como código , havia cinco marcos principais:
- Dados mestres (comunicação de sistemas e dados entre si, API de sistemas, suficiência de dados para suporte e lançamento)
- Monitoramento de dados e configurações (descoberta automática de dispositivos de rede, verificação da relevância da configuração na instalação)
- Controle de versão, configurações de teste e pilotagem (Gitlab CI / CD conforme aplicado à rede, ferramentas de teste de configuração de rede)
- Entrega de configuração (scripts Ansible, AWX, python para conectar)
- Zero Touch Provisioning (que dados são necessários, como criar um processo, como conectar-se a uma peça de hardware não configurada)
Não funcionou para encaixar tudo em um artigo, cada item é digno de uma discussão separada, podemos falar sobre algo agora, sobre algo quando verificamos as soluções na prática. Se você estiver interessado em algum dos tópicos - no final, haverá uma pesquisa na qual você poderá votar no próximo artigo. Se o tópico não estiver incluído na lista, mas for interessante ler sobre ele, deixe um comentário o mais rápido possível, compartilhe nossa experiência.
Agradecimentos especiais a Virilin Alexander (
xscrew ) e Sibgatulin Marat (
eucariot ) pela visita de referência no outono de 2018 à nuvem yandex e à história sobre a automação na infraestrutura de rede em nuvem. Depois dele, tivemos inspiração e muitas idéias sobre o uso da automação e do NetDevOps na infraestrutura do X5 Retail Group.