Quem trabalha com dados sabe que a felicidade não está na rede neural, mas em como processar os dados corretamente. Mas, para processá-las, você deve primeiro analisar as correlações, selecionar os dados necessários, jogar fora o desnecessário e assim por diante. Para tais fins, a visualização usando a biblioteca matplotlib é frequentemente usada.

Encontre-me "por dentro"!
Personalização
Execute o seguinte código para configurar. Os gráficos individuais, no entanto, substituem suas próprias configurações.
Correlação
Gráficos de correlação são usados para visualizar o relacionamento entre 2 ou mais variáveis. Ou seja, como uma variável muda em relação à outra.
1. Gráfico de dispersão
Scatteplot é uma visualização clássica e fundamental do gráfico usada para examinar o relacionamento entre duas variáveis. Se você tiver vários grupos em seus dados, poderá visualizar cada grupo em uma cor diferente. No matplotlib, você pode fazer isso facilmente usando plt.scatterplot ().

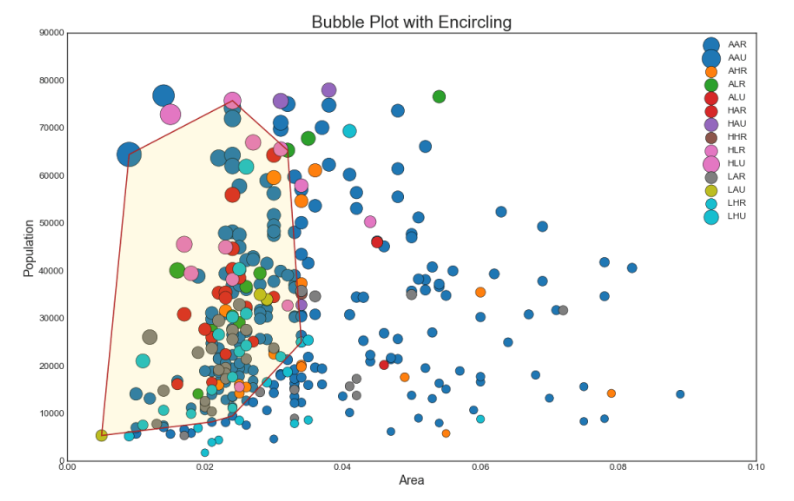
2. Gráfico de bolhas com captura de grupo
Às vezes, você deseja mostrar um grupo de pontos dentro da borda para enfatizar sua importância. Neste exemplo, obtemos os registros do quadro de dados que devem ser alocados e os passamos para circundar () descrito no código abaixo.
Mostrar código from matplotlib import patches from scipy.spatial import ConvexHull import warnings; warnings.simplefilter('ignore') sns.set_style("white")
3. Gráfico de regressão linear de melhor ajuste
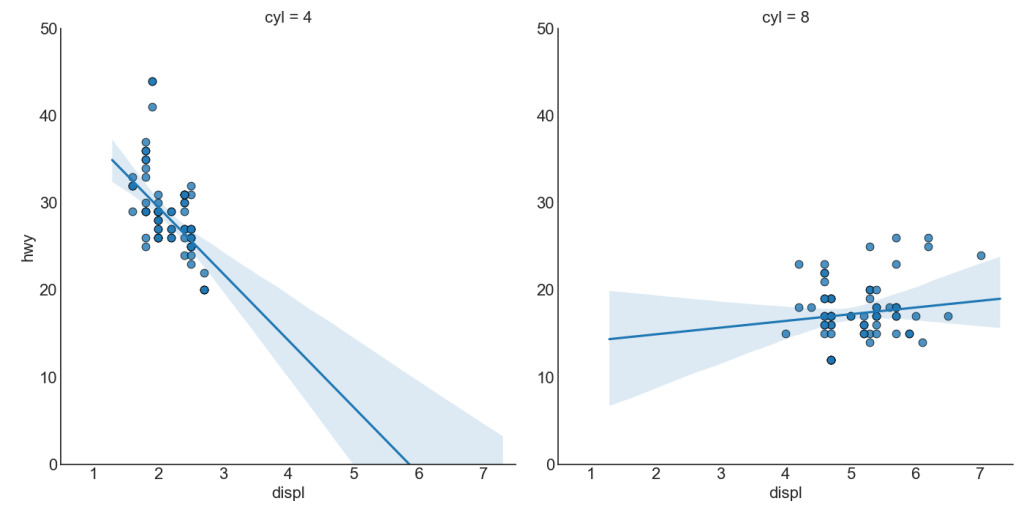
Se você quiser entender como duas variáveis mudam uma em relação à outra, a melhor linha de ajuste é a melhor. O gráfico abaixo mostra como o melhor ajuste difere entre diferentes grupos de dados. Para desativar agrupamentos e simplesmente desenhar uma linha de melhor ajuste para todo o conjunto de dados, remova o parâmetro hue = 'cyl' de sns.lmplot () abaixo.

Cada linha de regressão em sua própria coluna
Além disso, você pode mostrar a melhor linha de ajuste para cada grupo em uma coluna separada. Você deseja fazer isso definindo o parâmetro col = groupingcolumn dentro de sns.lmplot ().
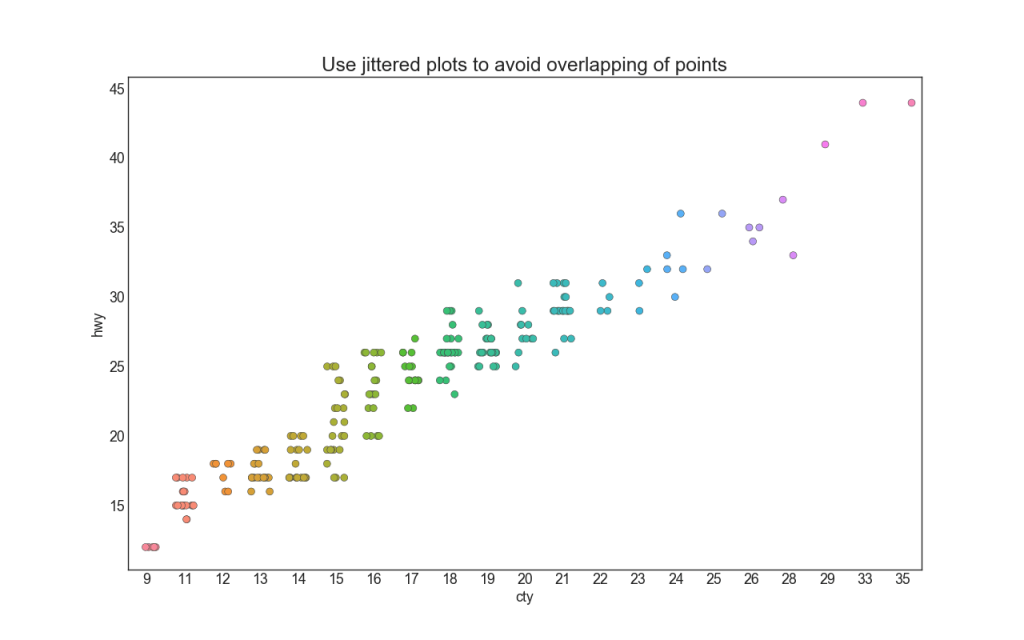
4. Stripplot
Geralmente, vários pontos de dados têm os mesmos valores X e Y. Como resultado, vários pontos de dados são plotados um sobre o outro e ocultados. Para evitar isso, afaste os pontos um pouco para que você possa vê-los visualmente. Isso é feito convenientemente usando stripplot ().
5. Gráfico de contagem
Outra opção que evita o problema de sobreposição de pontos é aumentar o tamanho do ponto, dependendo de quantos pontos existem nesse local. Assim, quanto maior o tamanho do ponto, maior a concentração de pontos ao seu redor.

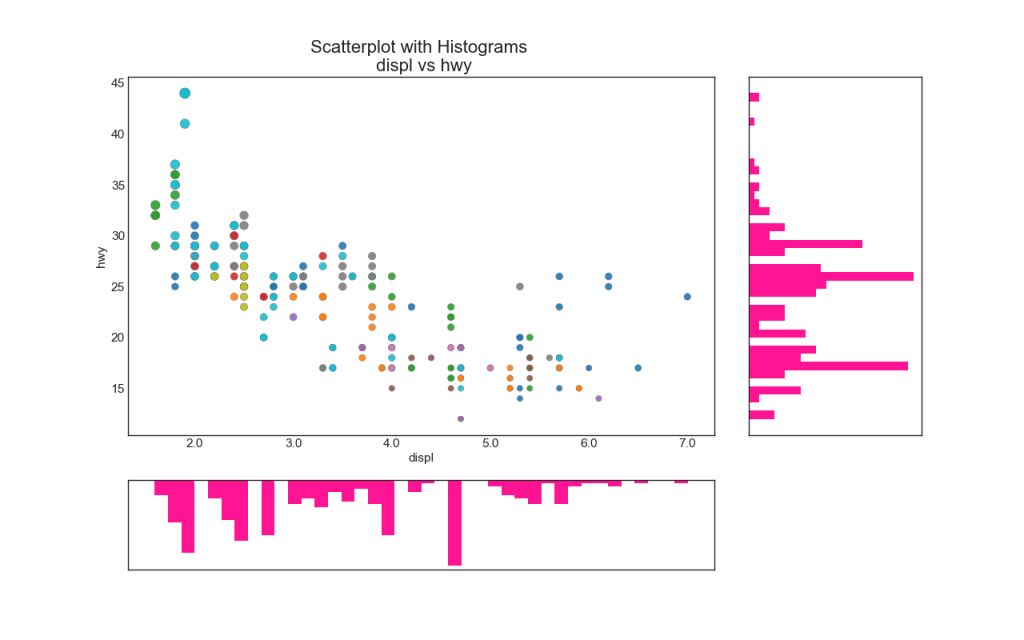
6. Um gráfico de barras
Os histogramas de linha têm um histograma ao longo das variáveis dos eixos X e Y. Isso é usado para visualizar a relação entre X e Y juntamente com a distribuição unidimensional de X e Y individualmente. Este gráfico é frequentemente usado em análise de dados (EDA).
7. Boxplot
O boxplot serve ao mesmo objetivo que um histograma linha por linha. No entanto, este gráfico ajuda a identificar a mediana, os percentis 25 e 75 de X e Y.
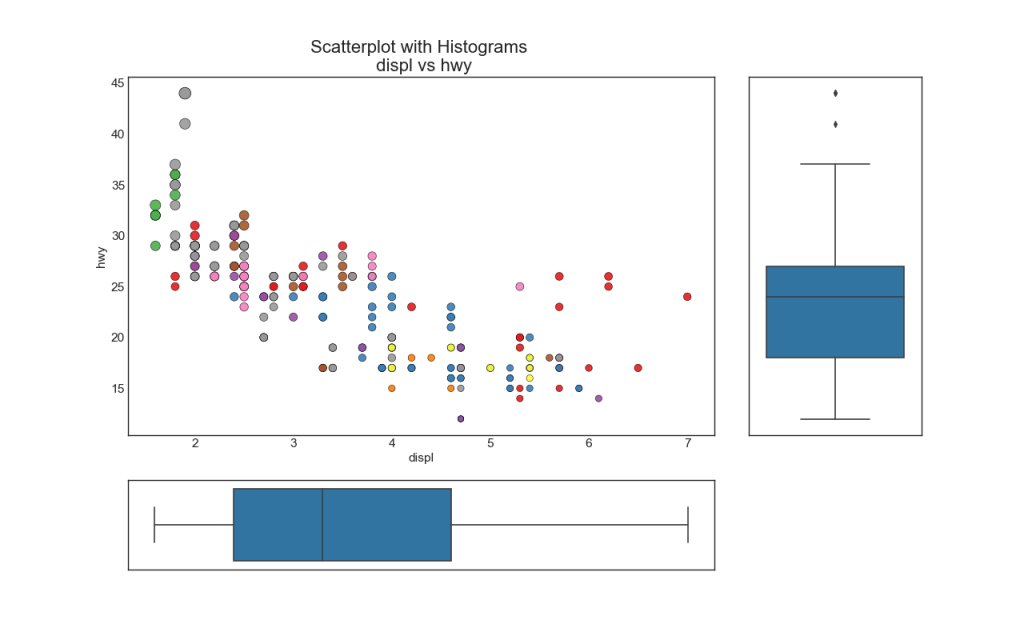
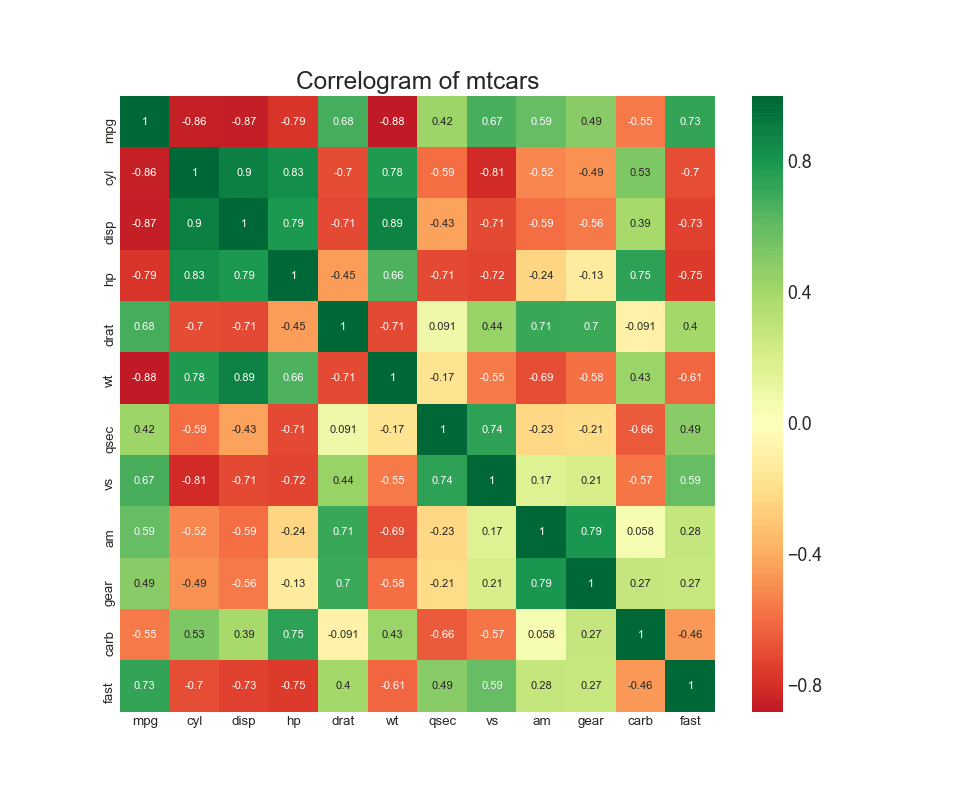
8. O diagrama de correlação
O diagrama de correlação é usado para visualizar visualmente a métrica de correlação entre todos os pares possíveis de variáveis numéricas em um determinado conjunto de dados (ou matriz bidimensional).
9. Programação de pares
Geralmente usado na análise de pesquisa para entender a relação entre todos os pares possíveis de variáveis numéricas. Esta é uma ferramenta essencial para a análise bidimensional.
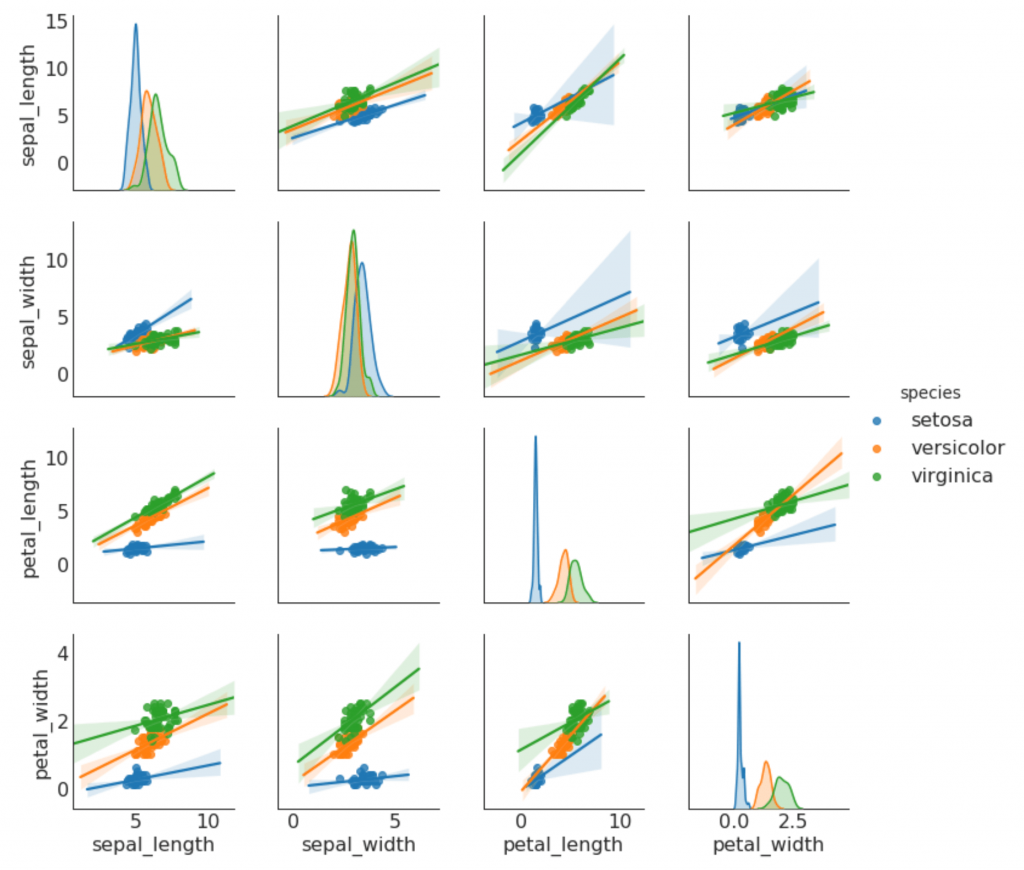
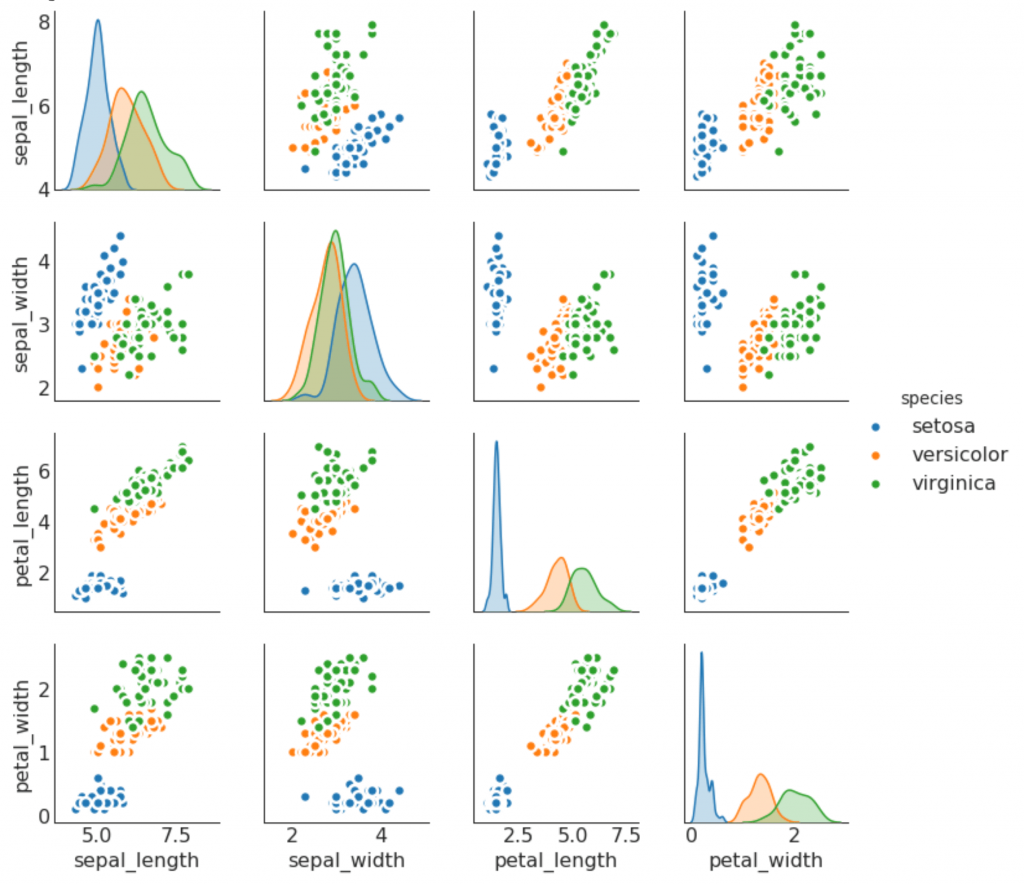
Desvio
10. Colunas divergentes
Se você deseja ver como os elementos mudam dependendo de uma métrica e visualizar a ordem e magnitude dessa dispersão, as colunas divergentes são uma ótima ferramenta. Ajuda a diferenciar rapidamente o desempenho dos grupos nos seus dados, é bastante intuitivo e transmite instantaneamente significado.

11. Colunas divergentes com texto
- parecem colunas divergentes, e isso é preferível se você quiser mostrar o significado de cada elemento no gráfico de uma maneira boa e apresentável.
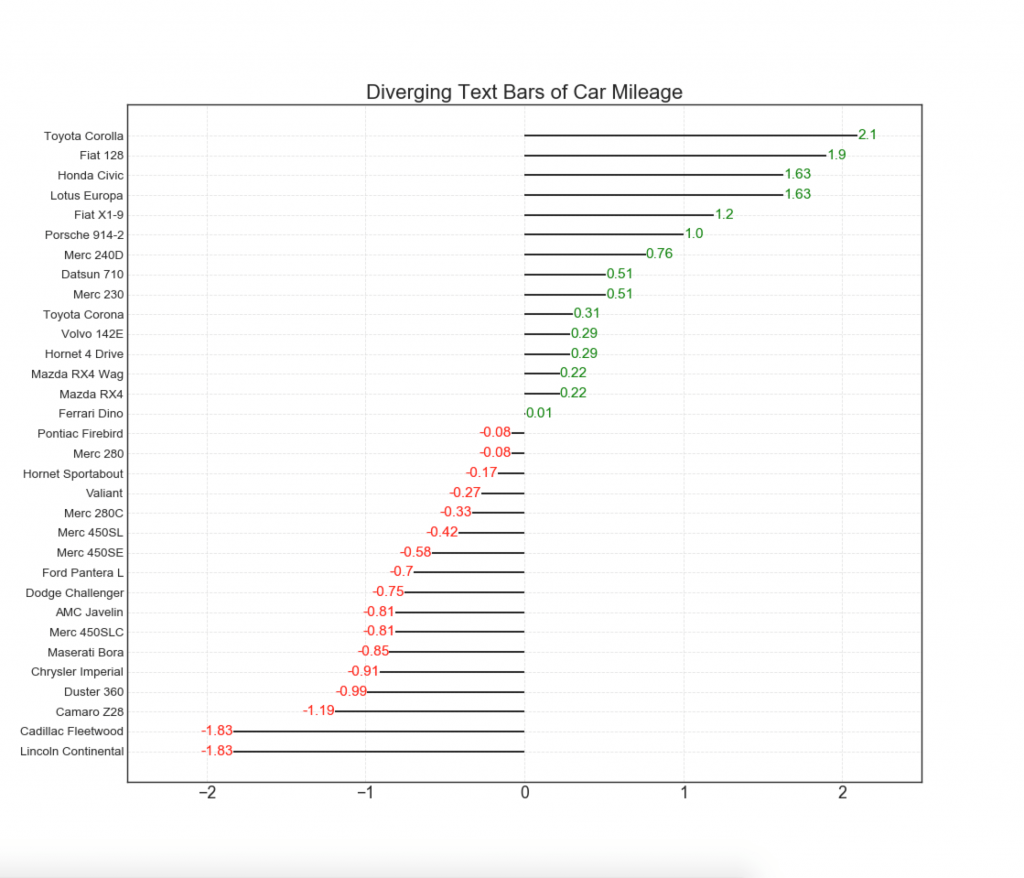
12. pontos divergentes
O gráfico de pontos divergentes também é semelhante às colunas divergentes. No entanto, comparada às colunas divergentes, a ausência de colunas reduz o grau de contraste e discrepância entre os grupos.
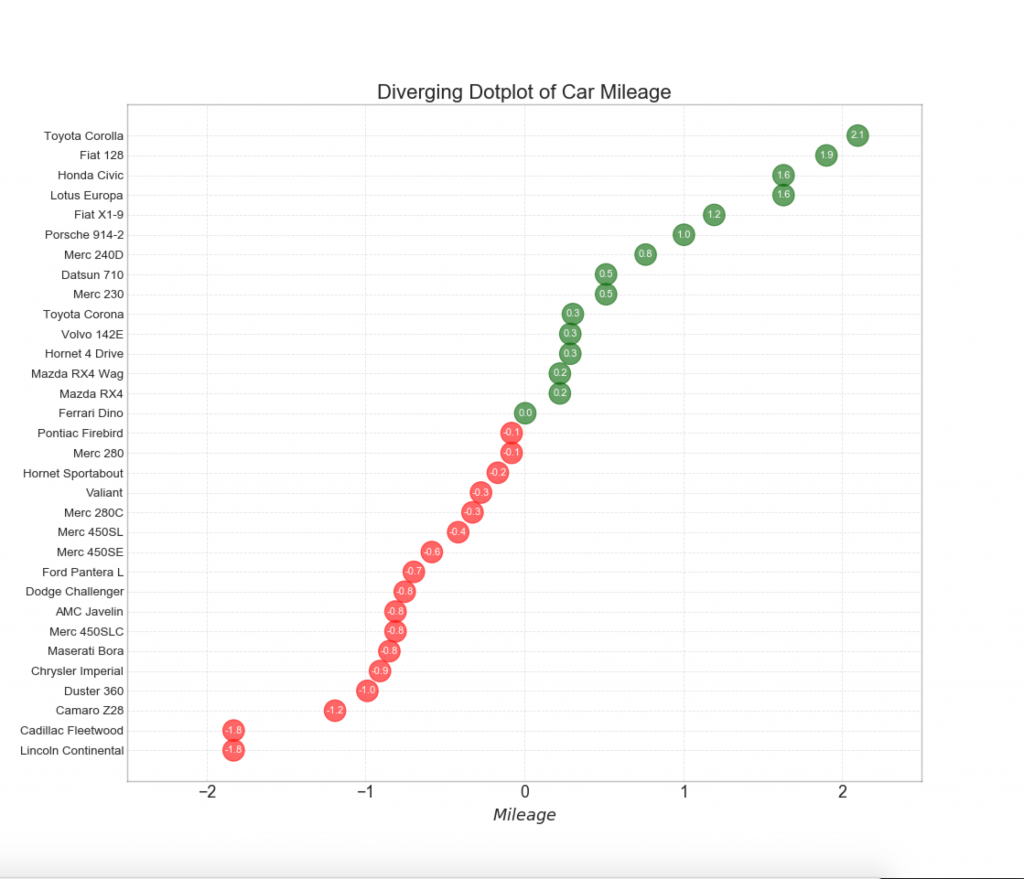
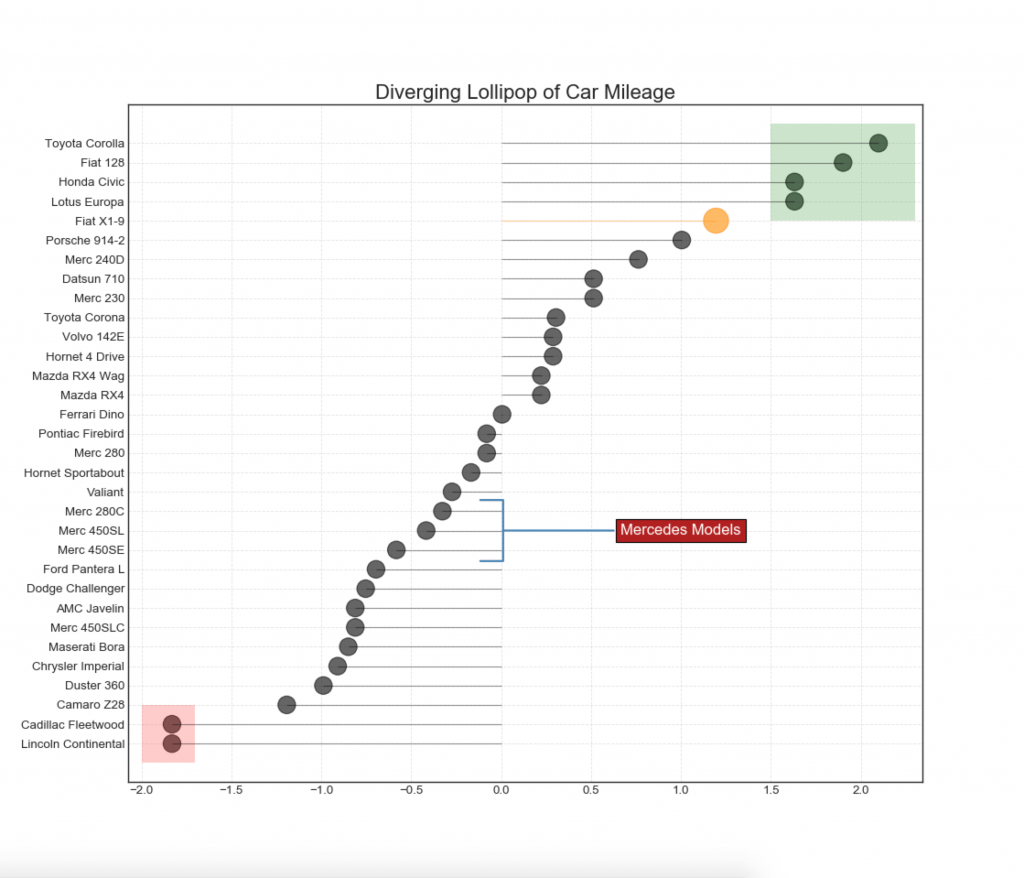
13. Tabela de pirulitos divergentes com marcadores
O Lollipop fornece uma maneira flexível de visualizar discrepâncias, concentrando-se em quaisquer pontos de dados relevantes aos quais você deseja prestar atenção.
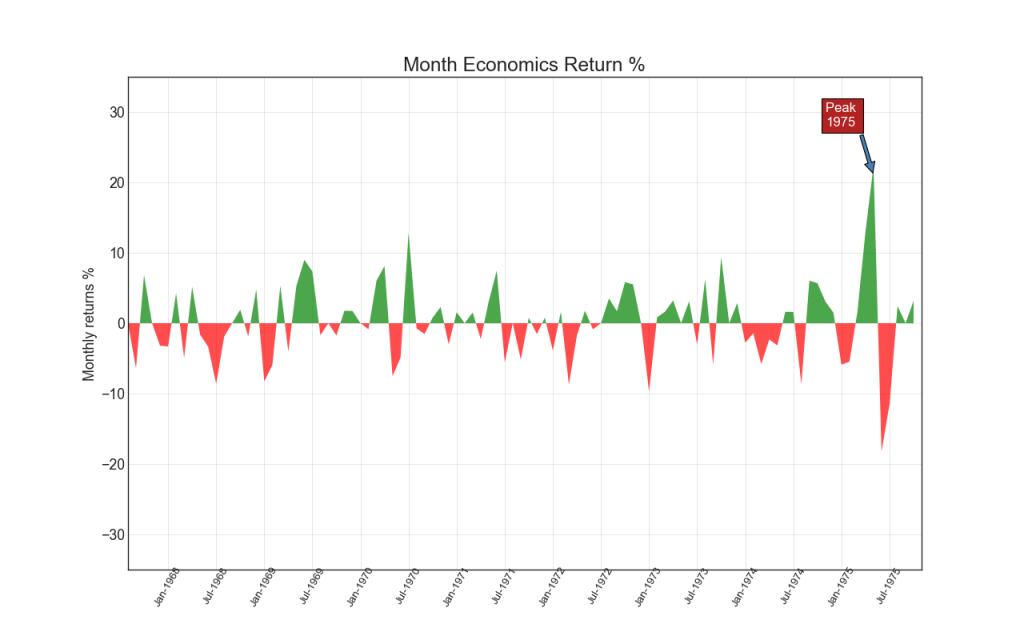
14. Gráfico de área
Colorindo a área entre o eixo e as linhas, o diagrama da área enfatiza picos e vales, mas também na duração dos altos e baixos. Quanto mais altos os altos, maior a área sob a linha.
Mostrar código import numpy as np import pandas as pd
Ranking
15. Histograma ordenado
Um histograma ordenado efetivamente transmite a ordem de classificação dos elementos. Mas, adicionando um valor métrico acima do gráfico, o usuário recebe informações precisas do próprio gráfico.
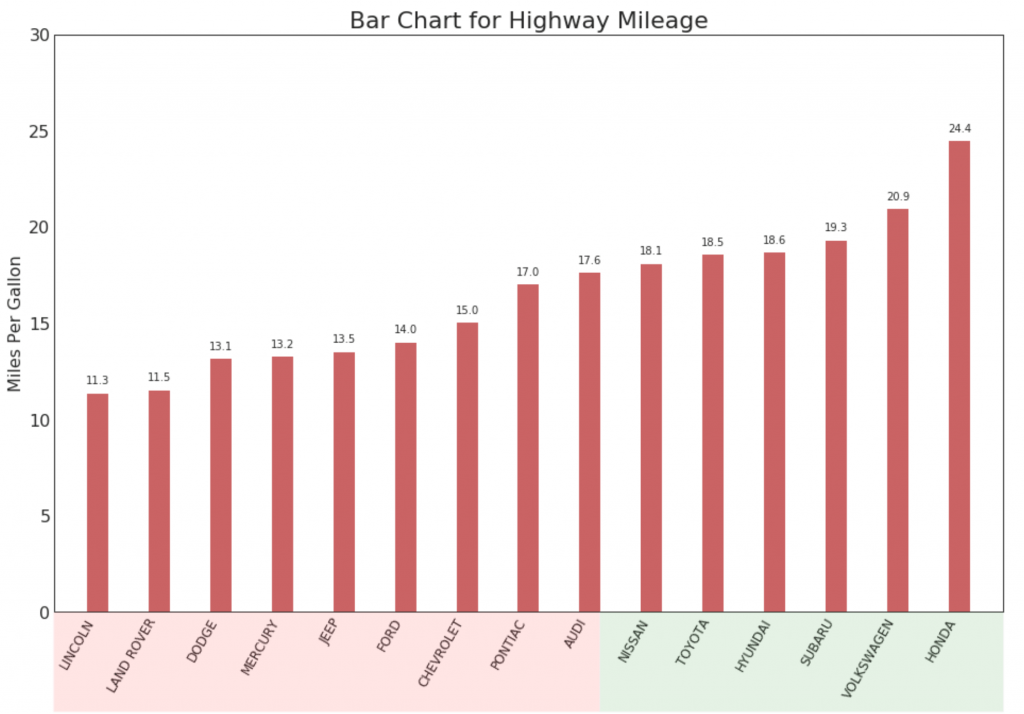
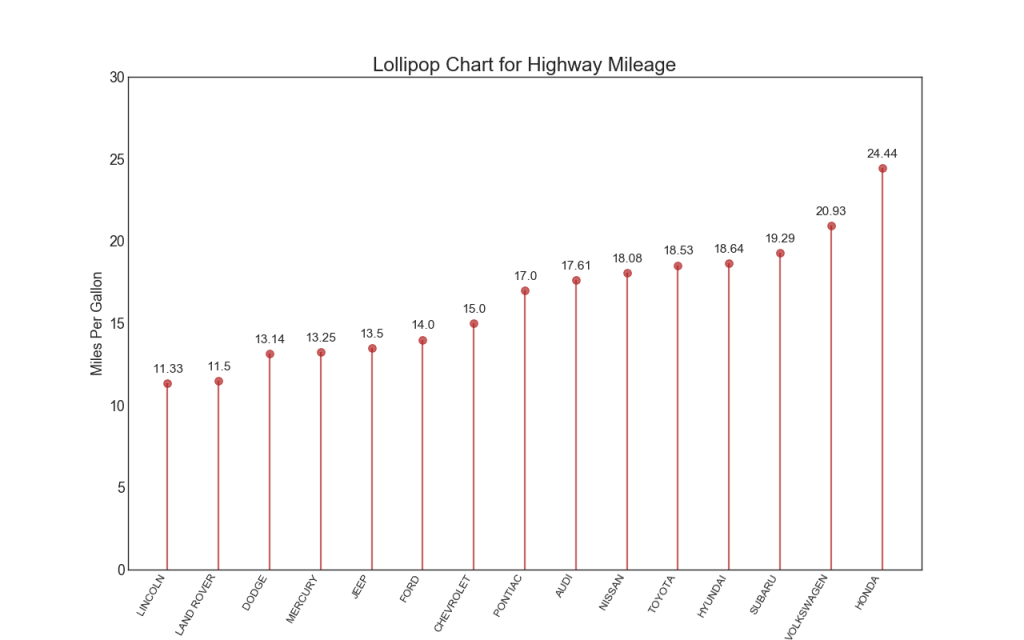
16. gráfico pirulito
O gráfico Lollipop serve a uma finalidade semelhante a um histograma ordenado de uma maneira visualmente agradável.
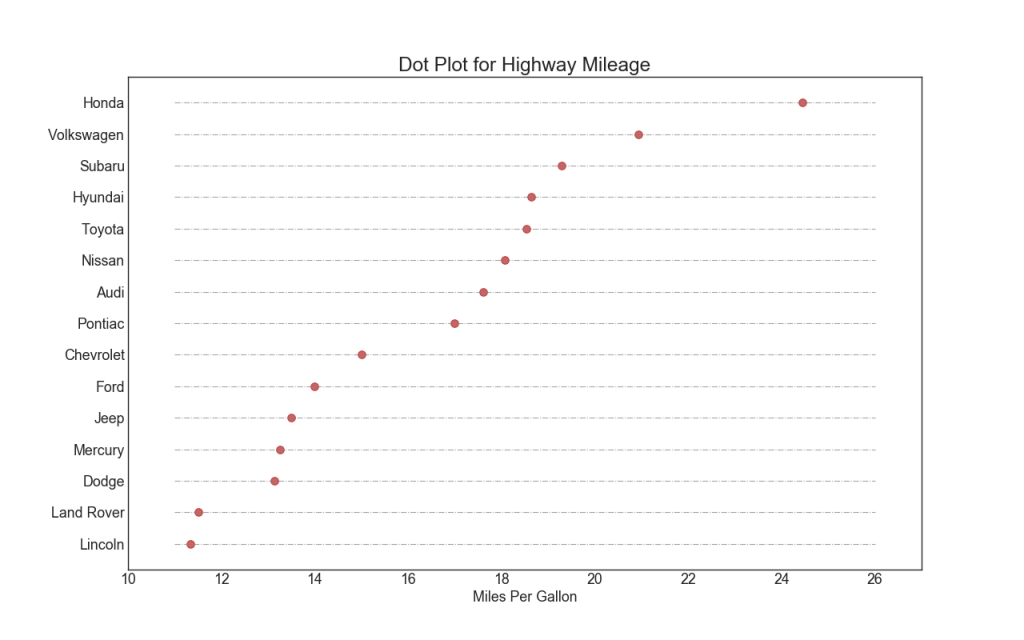
17. Gráfico pontilhado com assinaturas
Um gráfico de dispersão transmite a classificação dos itens. E, como está alinhado ao longo do eixo horizontal, você pode avaliar visualmente a distância entre os pontos.
18. mapa inclinado
O gráfico de inclinação é mais adequado para comparar as posições "Antes" e "Depois" de uma determinada pessoa / sujeito.
Mostrar código import matplotlib.lines as mlines

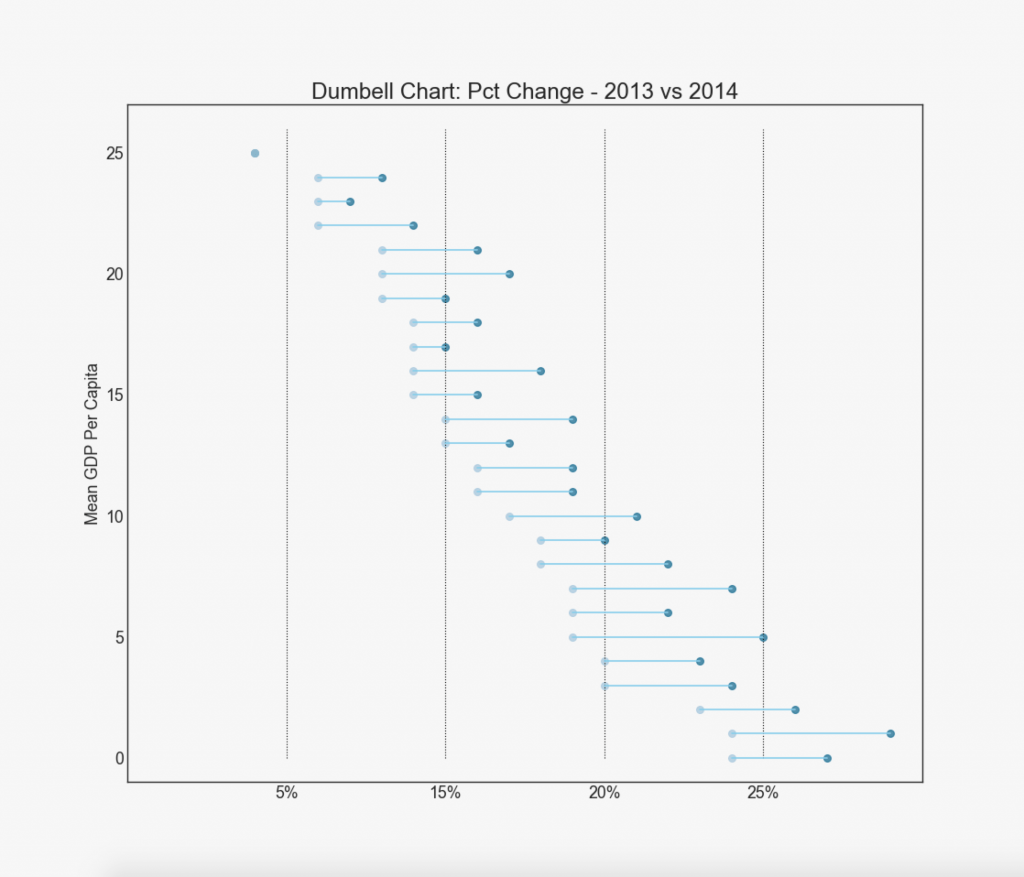
19. "Halteres"
O gráfico “Dumbbell” transmite as posições “antes” e “depois” de várias influências, bem como a ordem de classificação dos itens. Isso é muito útil se você deseja visualizar o efeito de algo em diferentes objetos.
Mostrar código import matplotlib.lines as mlines
Distribuição
20. Histograma para uma variável contínua
O histograma mostra a distribuição de frequência dessa variável. A apresentação a seguir agrupa as faixas de frequência com base em uma variável categórica.
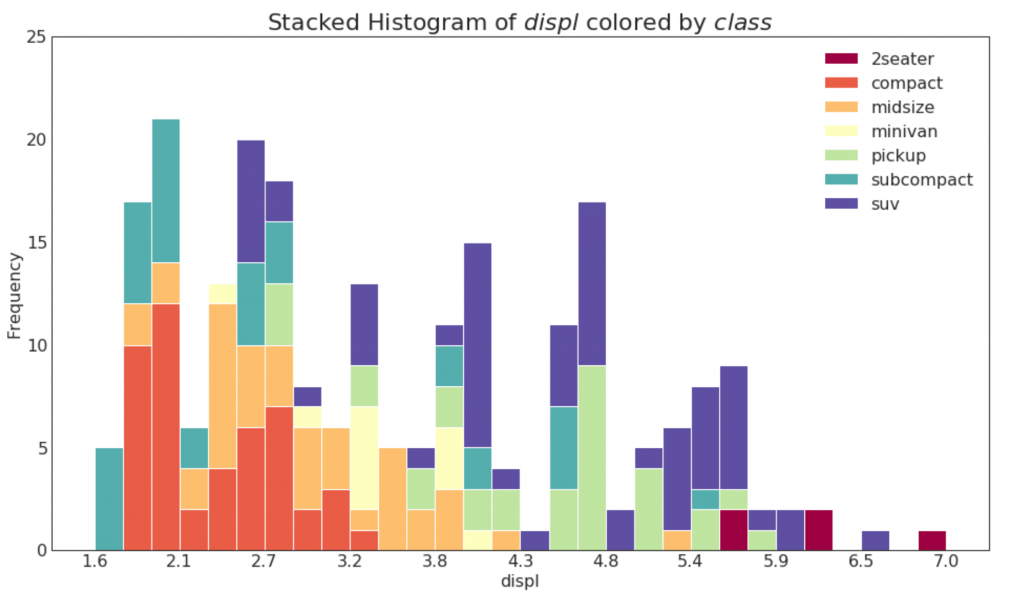
21. Histograma para uma variável categórica
O histograma de uma variável categórica mostra a distribuição de frequência dessa variável. Ao colorir as colunas, você pode visualizar a distribuição em relação a outra variável categórica que representa cores.
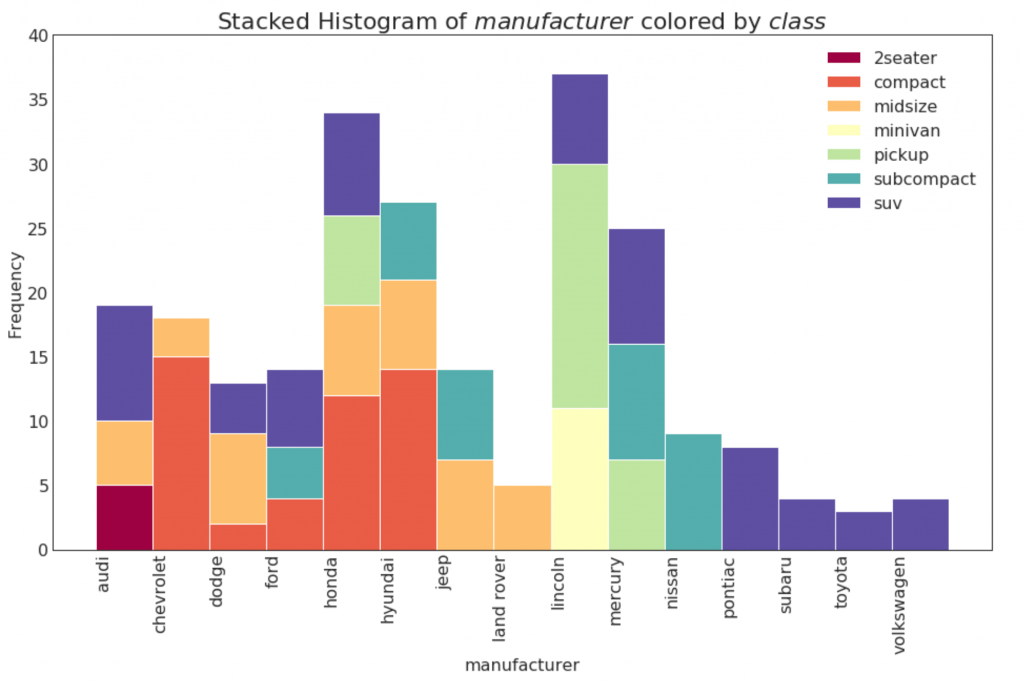
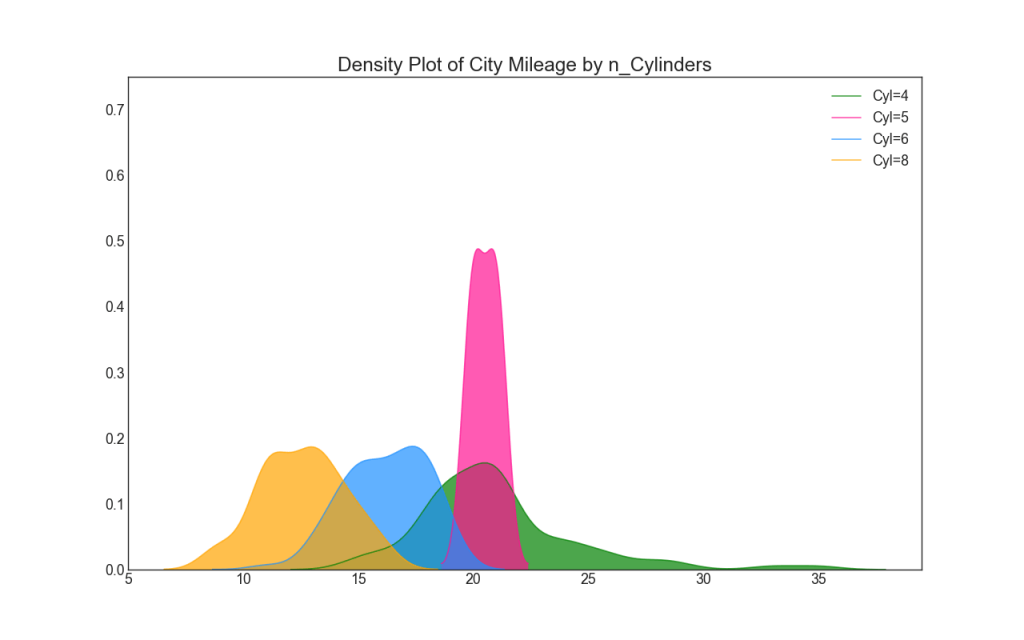
22. gráfico de densidade
Os gráficos de densidade são uma ferramenta amplamente usada para visualizar a distribuição de uma variável contínua. Depois de agrupados pela variável "resposta", é possível verificar a relação entre X e Y. A seguir, é apresentado um exemplo se, para maior clareza, descrevermos como a distribuição da milhagem na cidade varia de acordo com o número de cilindros.
23. Curvas de densidade com um histograma
A curva de densidade com um histograma combina as informações de resumo transmitidas pelos dois gráficos para que você possa ver as duas em um só lugar.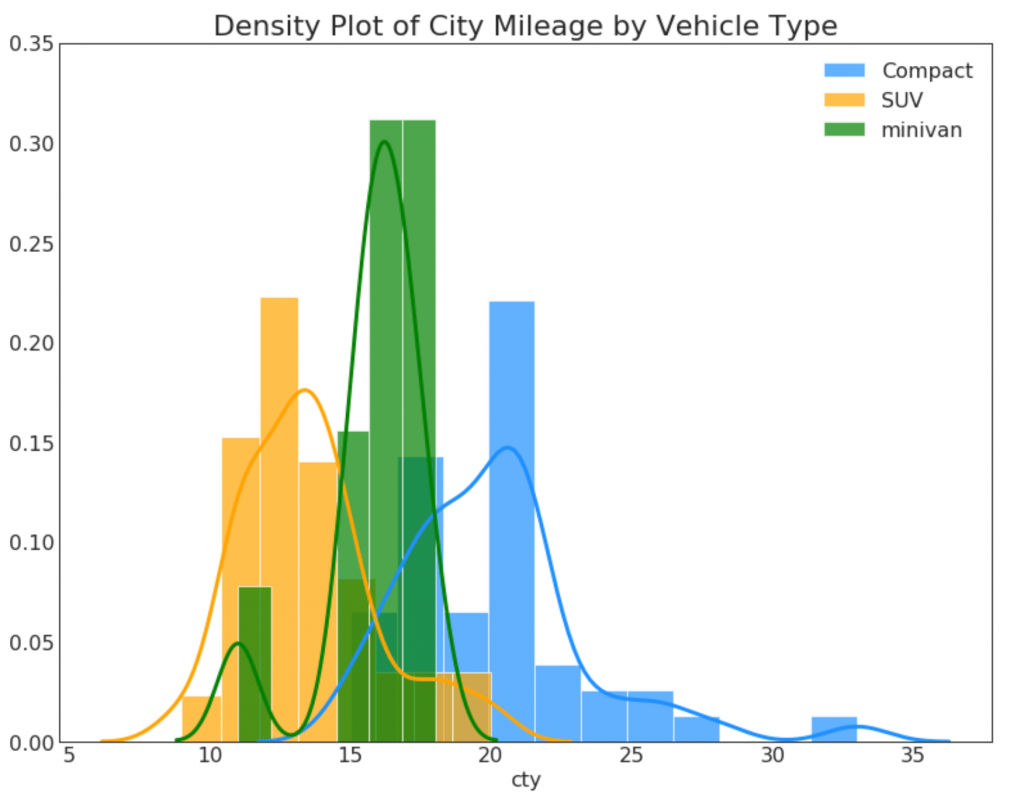
24. Joy chart
O gráfico Joy permite que você sobreponha as curvas de densidade de diferentes grupos. Essa é uma ótima maneira de visualizar a distribuição de um grande número de grupos em relação um ao outro. Parece agradável aos olhos e transmite claramente apenas as informações corretas.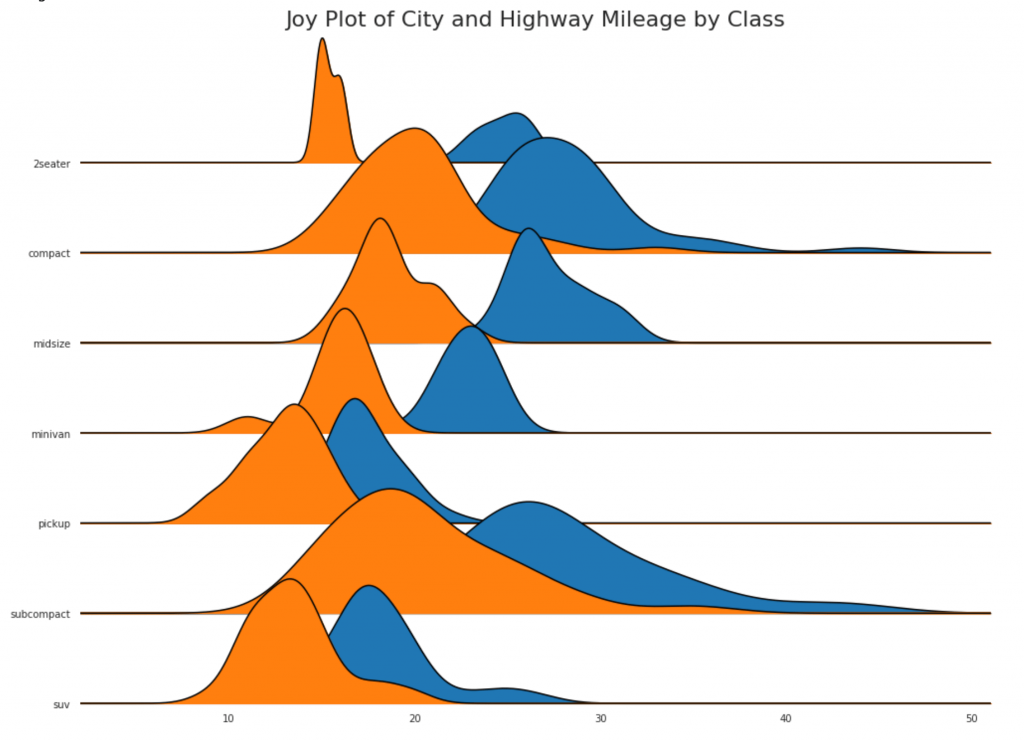
25. Gráfico de Dispersão Distribuída
O gráfico de dispersão distribuído mostra uma distribuição unidimensional de pontos segmentados em grupos. Quanto mais escuros os pontos, maior a concentração de pontos de dados nessa região. Ao colorir a mediana de maneiras diferentes, o arranjo real dos grupos se torna aparente instantaneamente.Mostrar código import matplotlib.patches as mpatches

26. Gráficos com retângulos
Esses gráficos são uma ótima maneira de visualizar a distribuição, conhecendo os medianos, 25º, 75º quartis e máximos com mínimos. No entanto, você deve ter cuidado ao interpretar o tamanho dos campos, o que pode distorcer o número de pontos contidos nesse grupo. Assim, a indicação manual do número de observações em cada célula ajudará a superar essa desvantagem.Por exemplo, os dois primeiros retângulos à esquerda têm o mesmo tamanho, embora tenham 5 e 47 elementos de dados, respectivamente. Portanto, é necessário anotar o número de observações.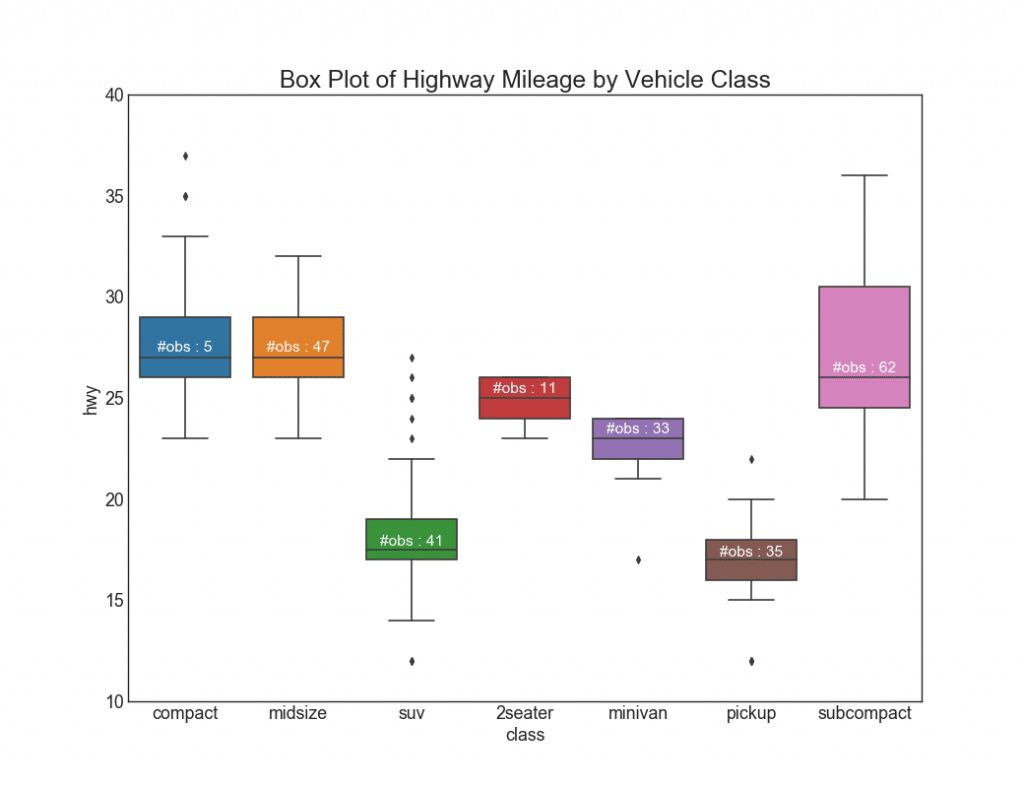
27. Gráficos com retângulos e pontos
O gráfico Dot + Box transmite informações semelhantes, como boxplot, divididas em grupos. Além disso, os pontos dão uma idéia do número de elementos de dados em cada grupo.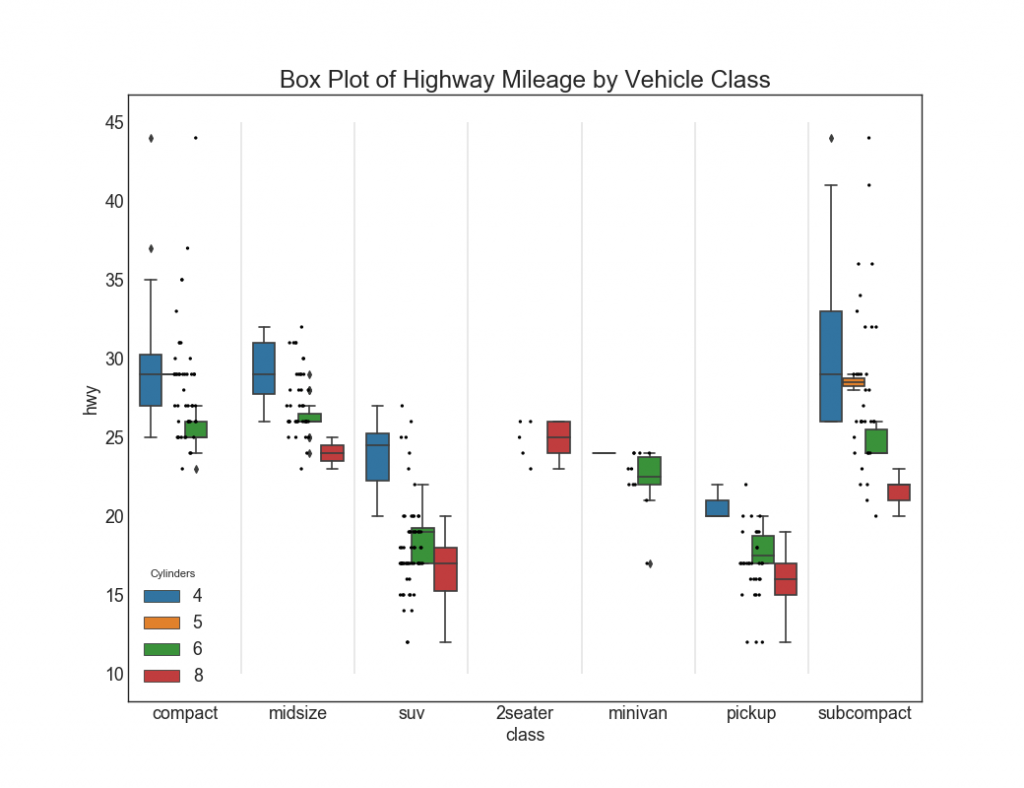
28. Cronograma de "violinos"
Essa programação é uma alternativa visualmente agradável ao boxplot. A forma ou área do "violino" depende da quantidade de dados neste grupo. No entanto, esses gráficos podem ser mais difíceis de ler e geralmente não são usados em configurações profissionais.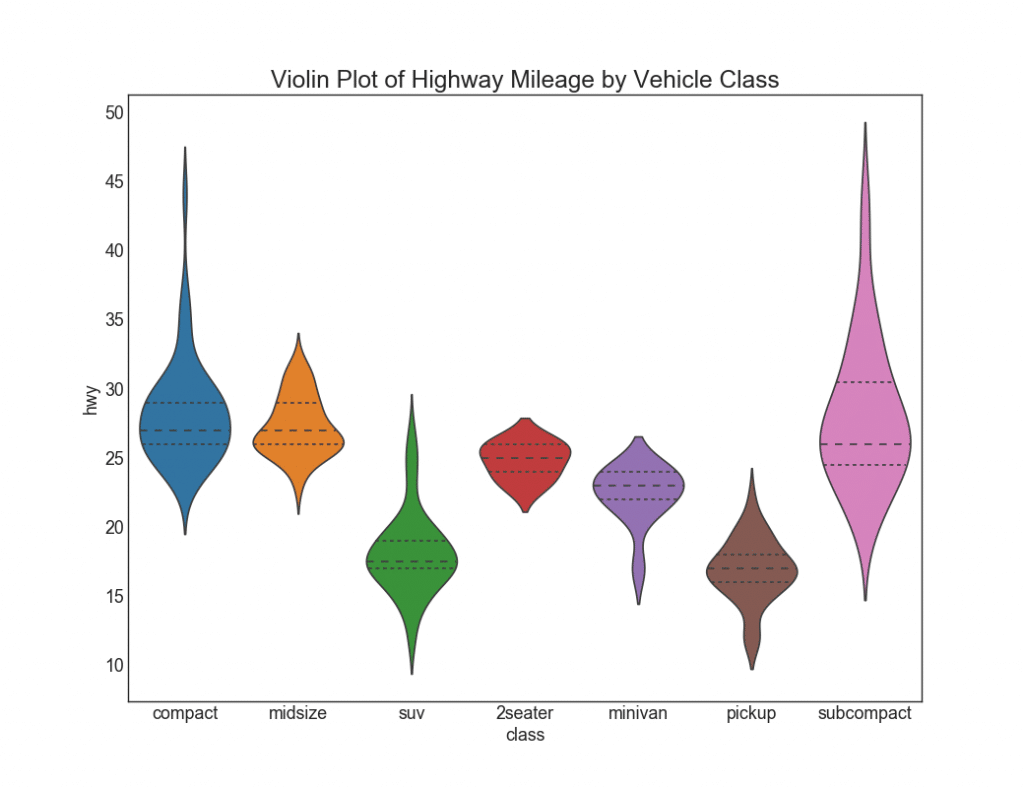
29. Pirâmide da população
Uma pirâmide populacional pode ser usada para mostrar a distribuição dos grupos ordenados por volume ou para mostrar a filtragem em fases da população, como mostrado abaixo, para visualizar quantas pessoas passam por cada estágio do funil de marketing.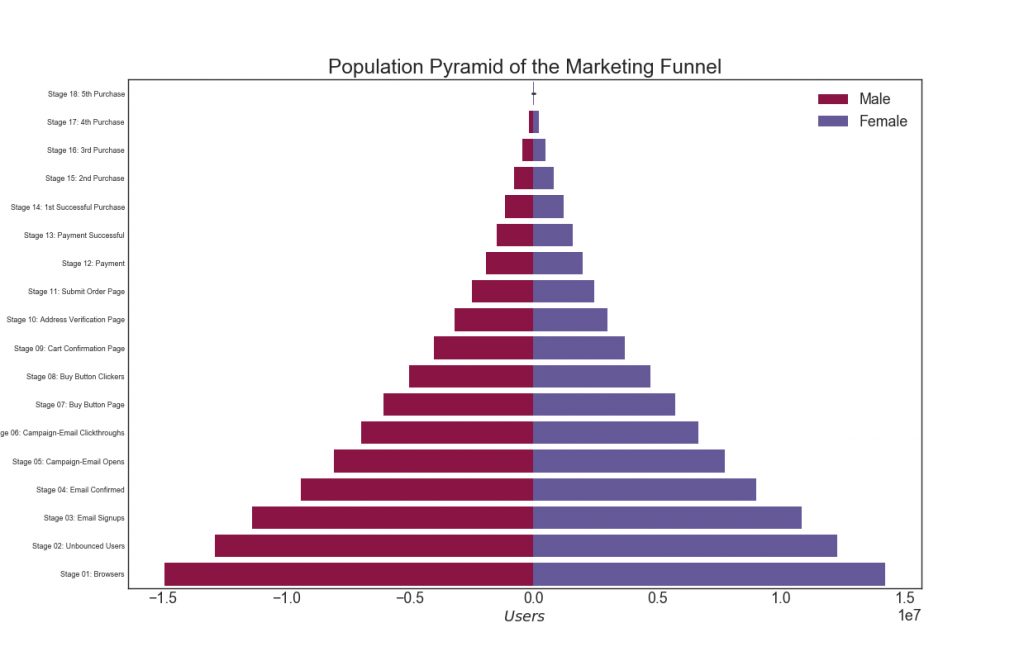
30. Gráficos categóricos
Os gráficos categóricos fornecidos pela biblioteca marítima podem ser usados para visualizar a distribuição do número de duas ou mais variáveis categóricas entre si.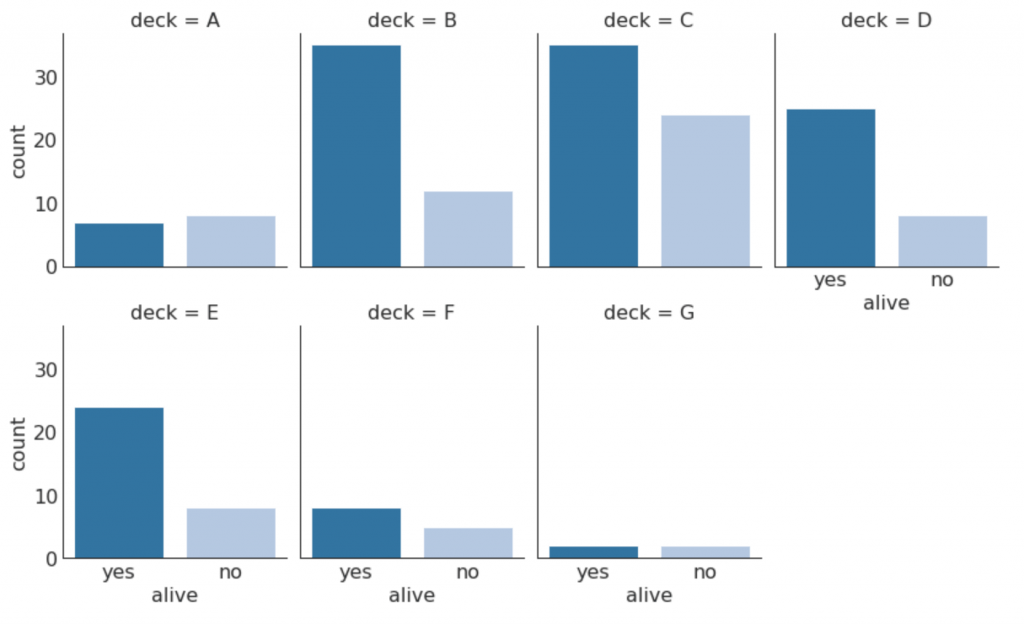
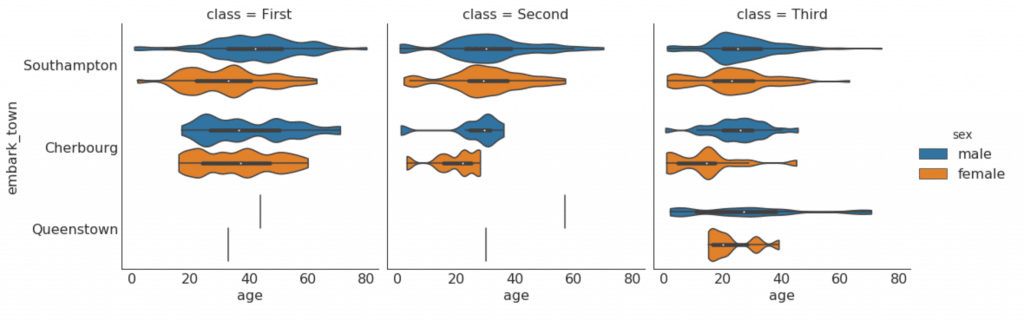
Montagem, composição
31. Diagrama de waffle
Um gráfico de waffle pode ser criado usando o pacote pywaffle e é usado para exibir composições de grupo na maior parte da população.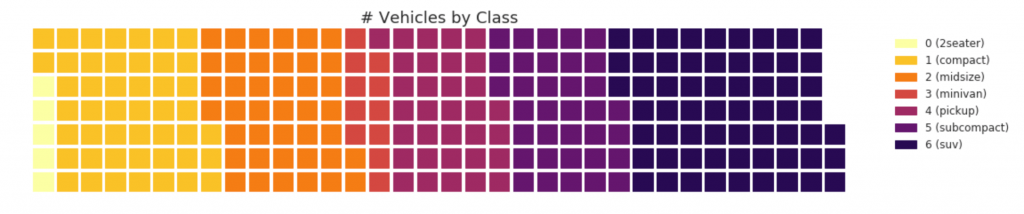
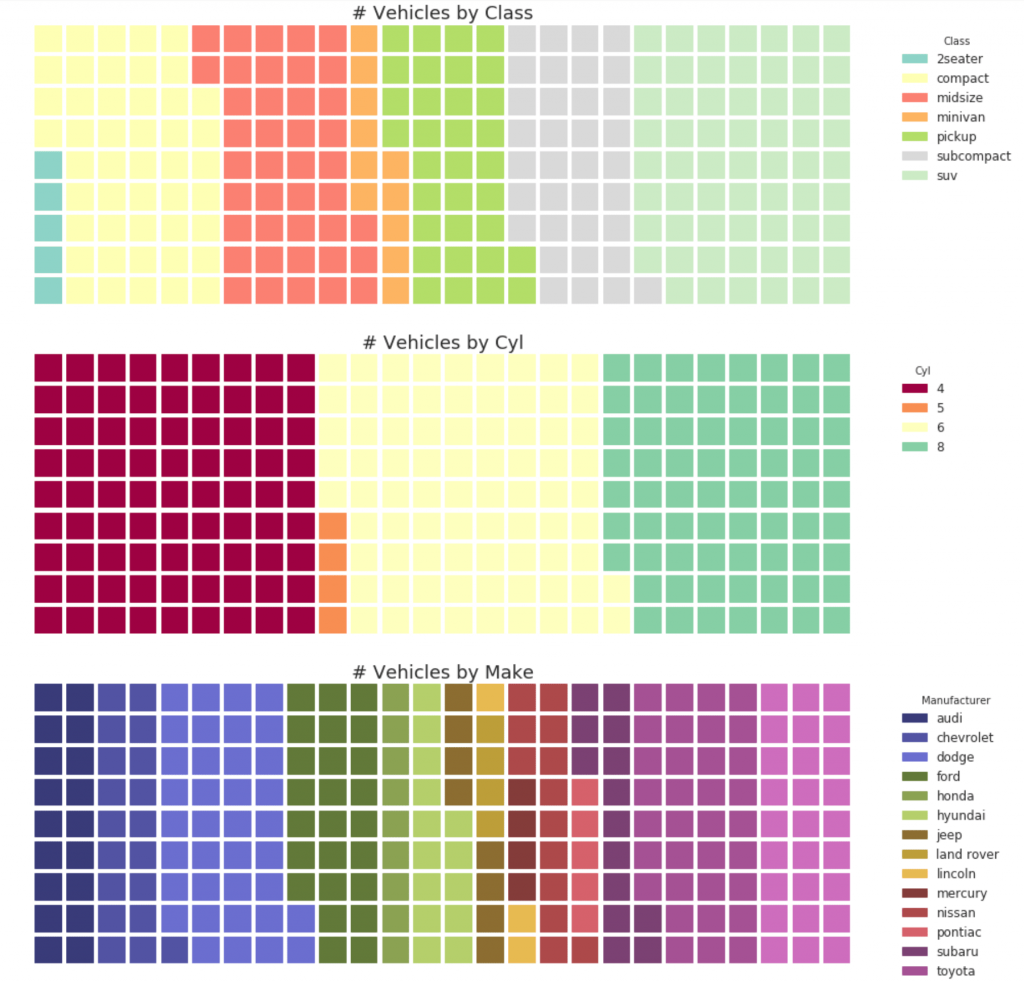
32. Gráfico de pizza
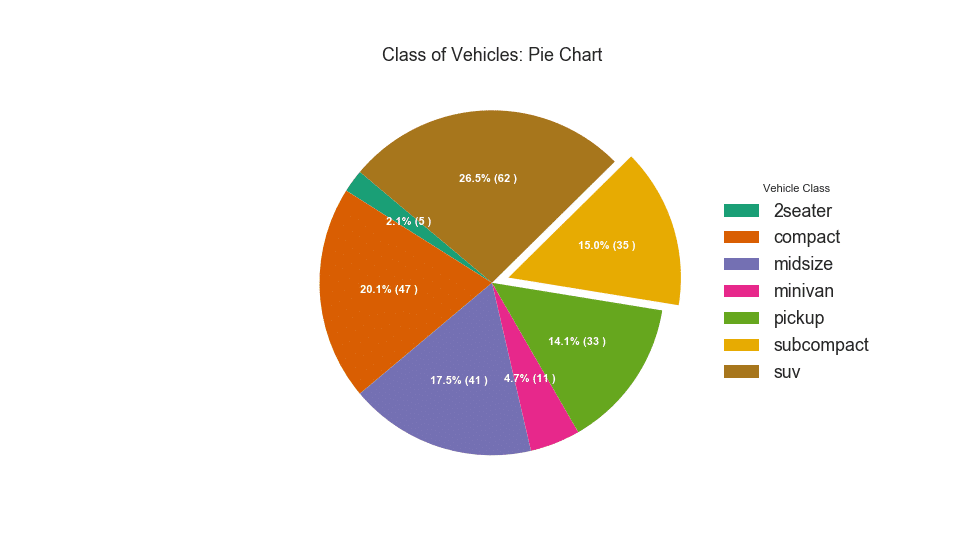
Um gráfico de pizza é uma maneira clássica de mostrar a composição dos grupos. No entanto, atualmente não é geralmente recomendado usar esse gráfico porque a área dos segmentos pode às vezes ser enganosa. Portanto, se você deseja usar um gráfico de pizza, é altamente recomendável que você registre explicitamente a porcentagem ou o número de cada parte do gráfico de pizza.
33. mapa de árvore
O mapa da árvore se parece com um gráfico de pizza e funciona melhor sem enganar a participação de cada grupo.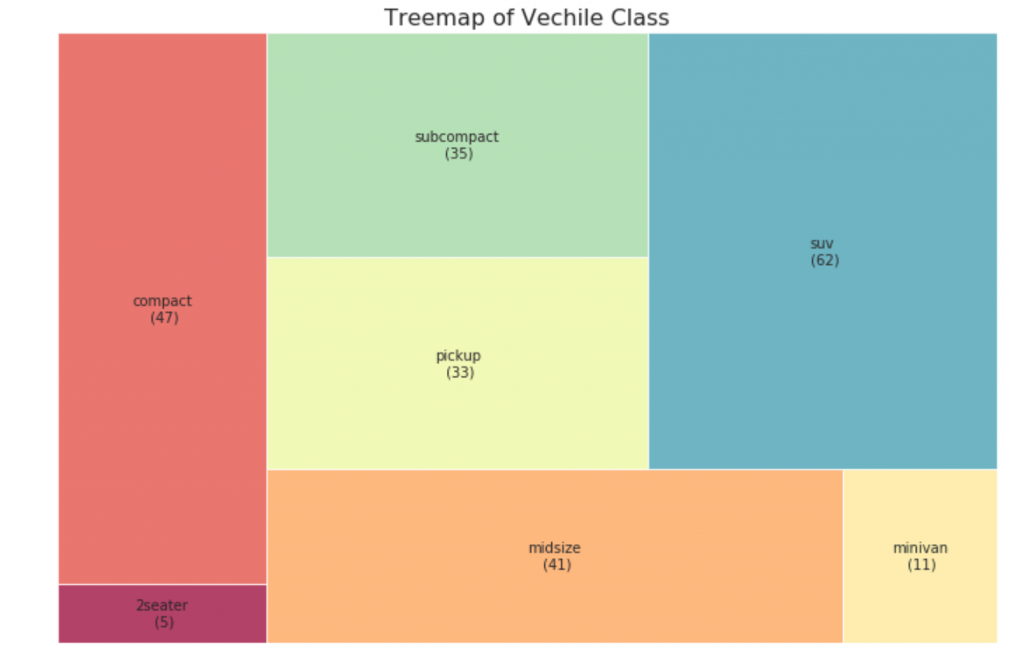
34. Histograma
Um histograma é uma maneira clássica de visualizar elementos com base na quantidade ou em qualquer métrica especificada. No diagrama abaixo, usei cores diferentes para cada elemento, mas você pode escolher uma cor para todos os elementos, se não quiser colori-los em grupos. Os nomes das cores são armazenados em all_colors no código abaixo. Você pode alterar a cor das faixas definindo o parâmetro de cor em .plt.plot ()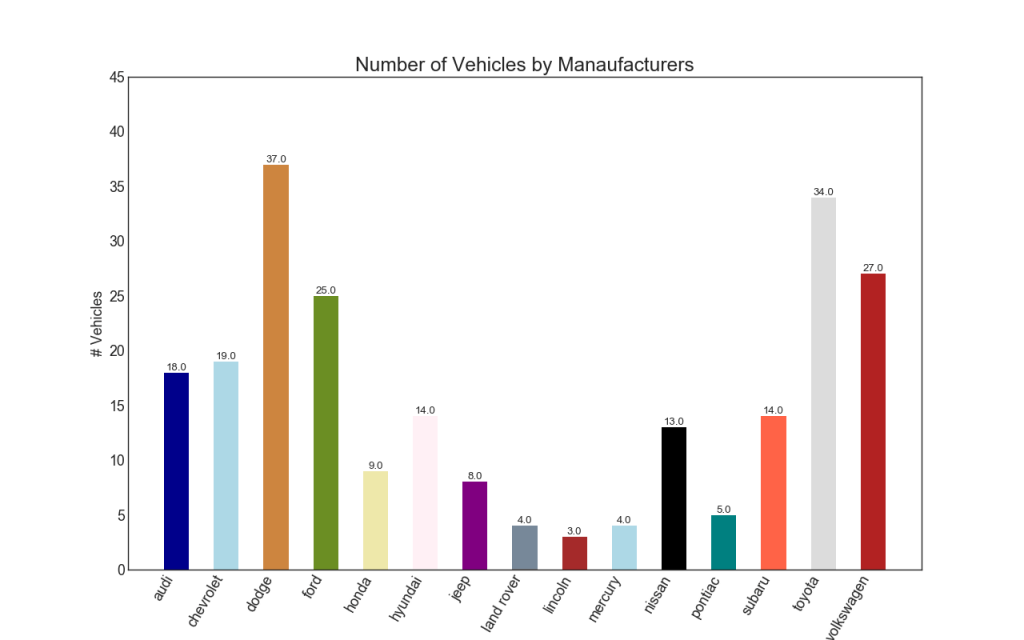
Alterar rastreamento
35. Gráfico de séries temporais
Um gráfico de séries temporais é usado para visualizar como um determinado indicador muda ao longo do tempo. Aqui você pode ver como o fluxo de passageiros mudou de 1949 para 1969.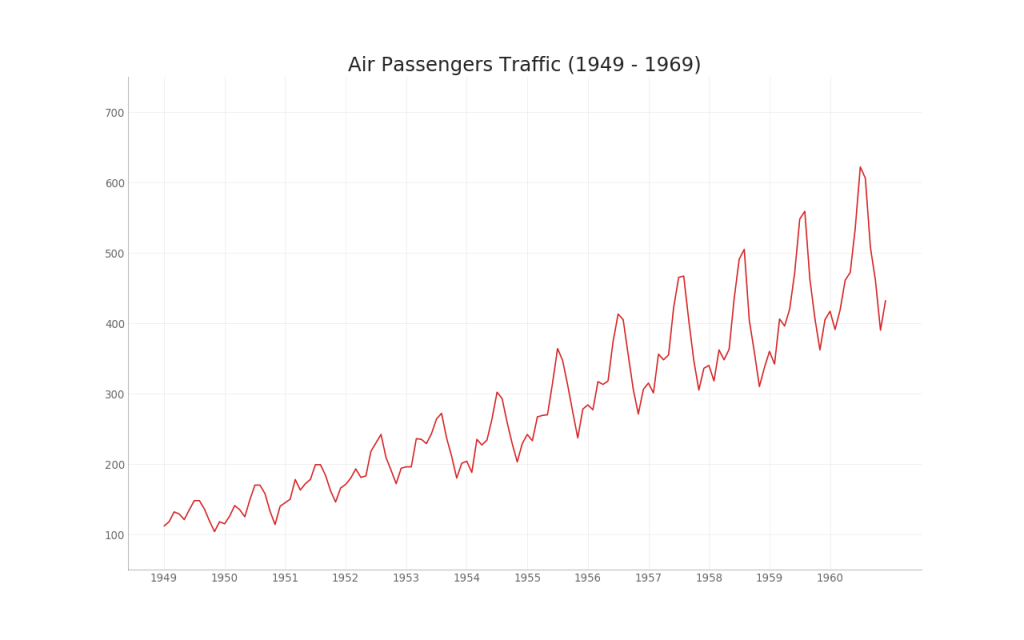
36. Séries cronológicas com picos e vales
A série temporal abaixo exibe todos os picos e vales e marca a ocorrência de eventos especiais individuais.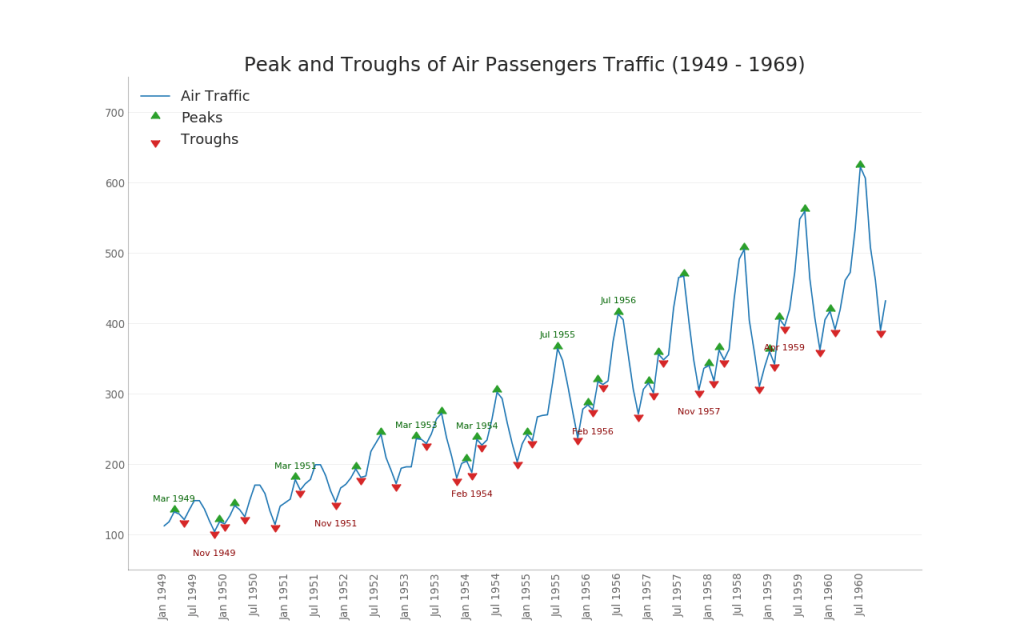
37. (ACF) (PACF)
O gráfico ACF mostra a correlação de uma série temporal com seu próprio tempo. Cada linha vertical (no gráfico de autocorrelação) representa uma correlação entre a série e seu tempo, começando no tempo 0. A área sombreada em azul no gráfico é um nível de significância. Aqueles momentos acima da linha azul são significativos.Então, como você interpreta isso?Para os AirPassengers, vemos que em x = 14, os “pirulitos” cruzaram a linha azul e são, portanto, de grande importância. Isso significa que o tráfego de passageiros observado até 14 anos atrás tem um impacto no tráfego observado hoje.O PACF, por outro lado, mostra a autocorrelação de um determinado momento (série temporal) com a série atual, mas com a remoção de influências entre elas.Mostrar código from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
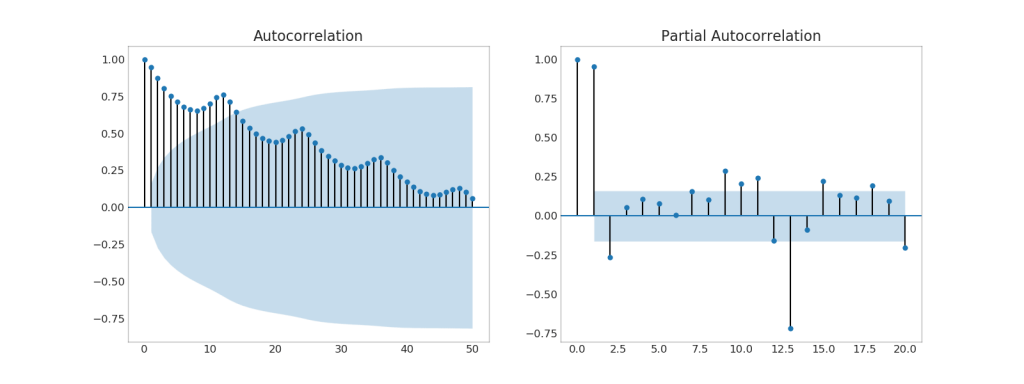
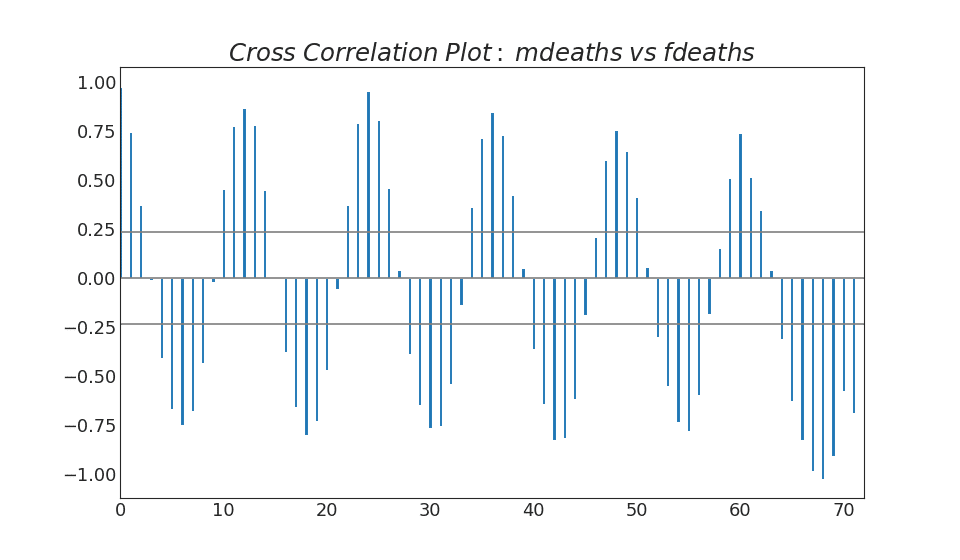
38. Gráfico de correlação cruzada
O gráfico de correlação cruzada mostra os atrasos de duas séries temporais entre si.Mostrar código import statsmodels.tsa.stattools as stattools
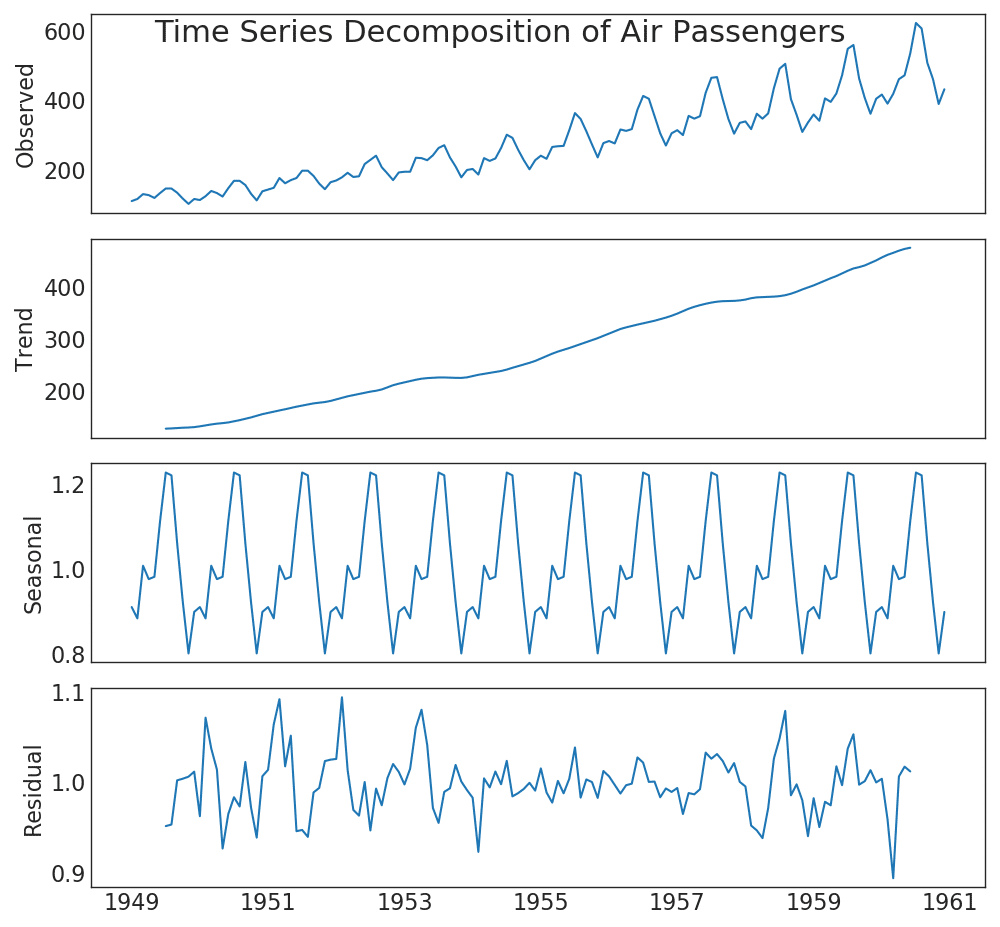
39. Expansão de séries temporais
O gráfico de expansão das séries cronológicas mostra a divisão das séries cronológicas em componentes de tendência, sazonal e residual.Mostrar código from statsmodels.tsa.seasonal import seasonal_decompose from dateutil.parser import parse
40. Várias séries temporais
Você pode criar várias séries temporais que medem o mesmo valor em um único gráfico, como mostrado abaixo.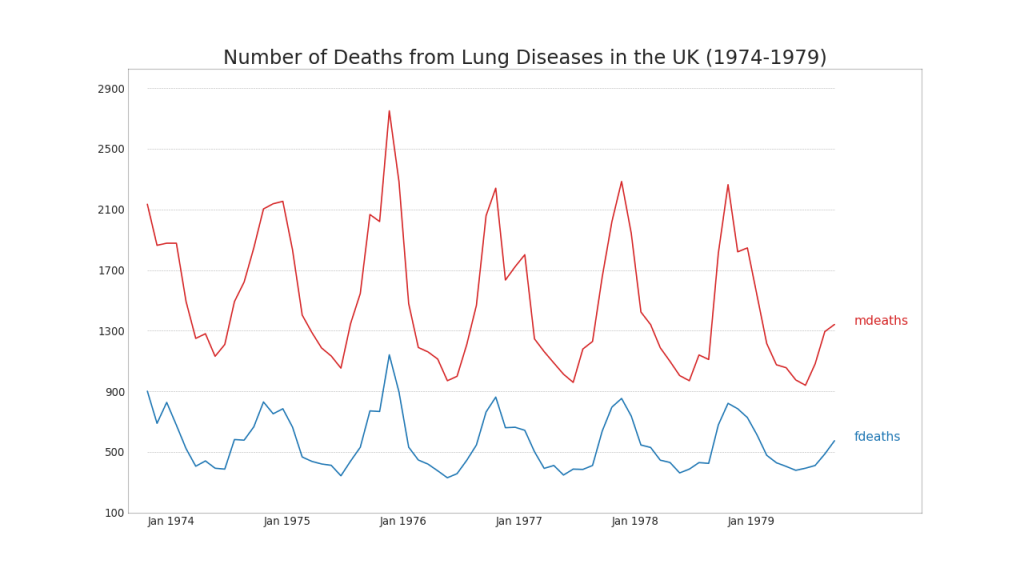
41. Construir em escalas diferentes usando o eixo Y secundário
Se você deseja mostrar duas séries temporais que medem dois valores diferentes ao mesmo tempo, é possível criar a segunda série novamente no eixo Y secundário à direita.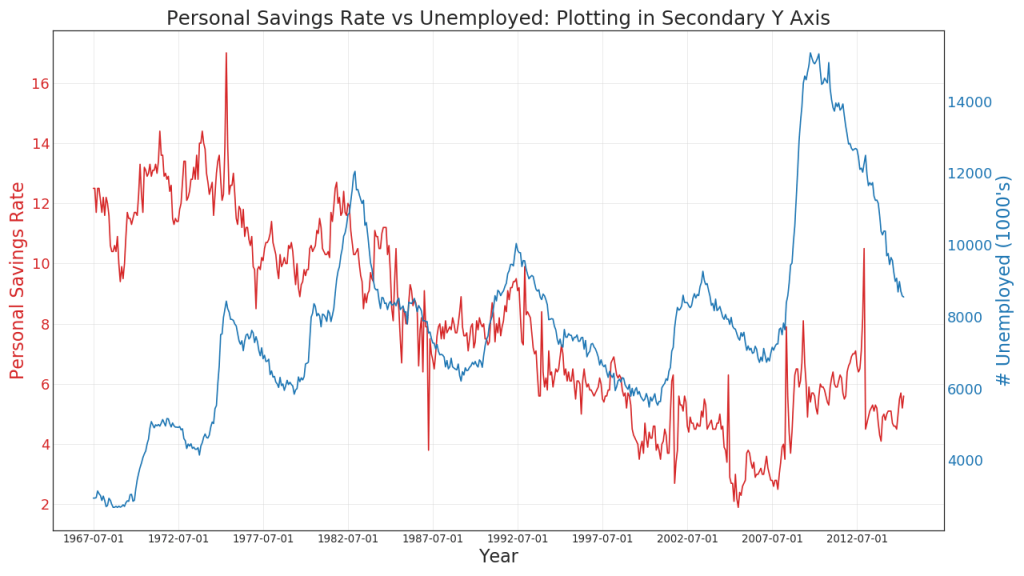
42. Séries temporais com barras de erro
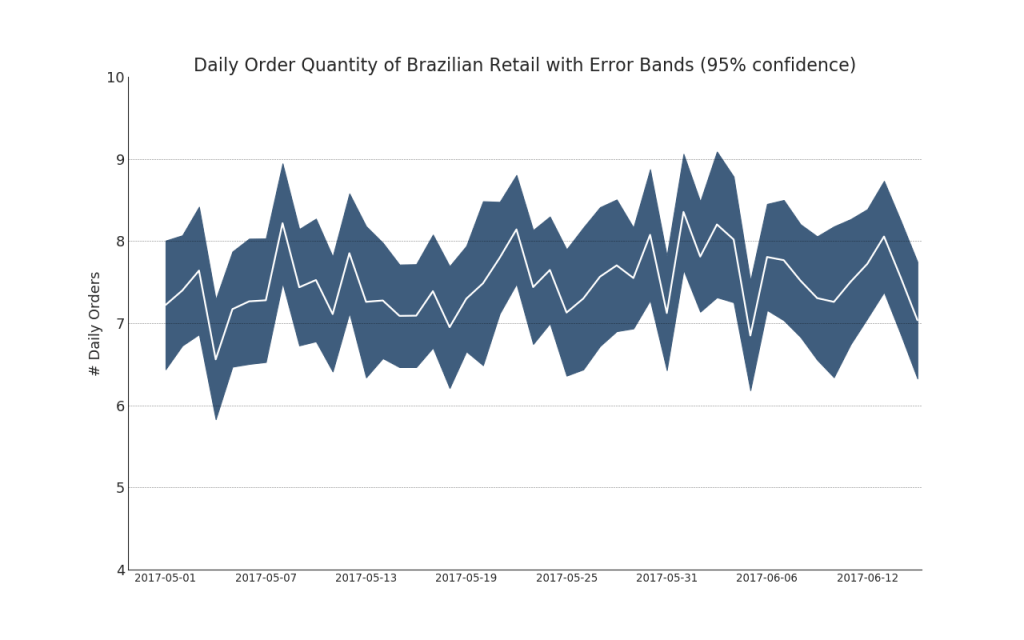
Séries temporais com barras de erro podem ser construídas se você tiver um conjunto de dados de séries temporais com várias observações para cada ponto do tempo (data / hora). Abaixo, você pode ver alguns exemplos com base no recebimento de pedidos em diferentes horários do dia. E outro exemplo do número de pedidos recebidos em 45 dias.Com essa abordagem, o número médio de pedidos é indicado por uma linha branca. E intervalos de 95% são calculados e plotados em torno da média.Mostrar código from scipy.stats import sem
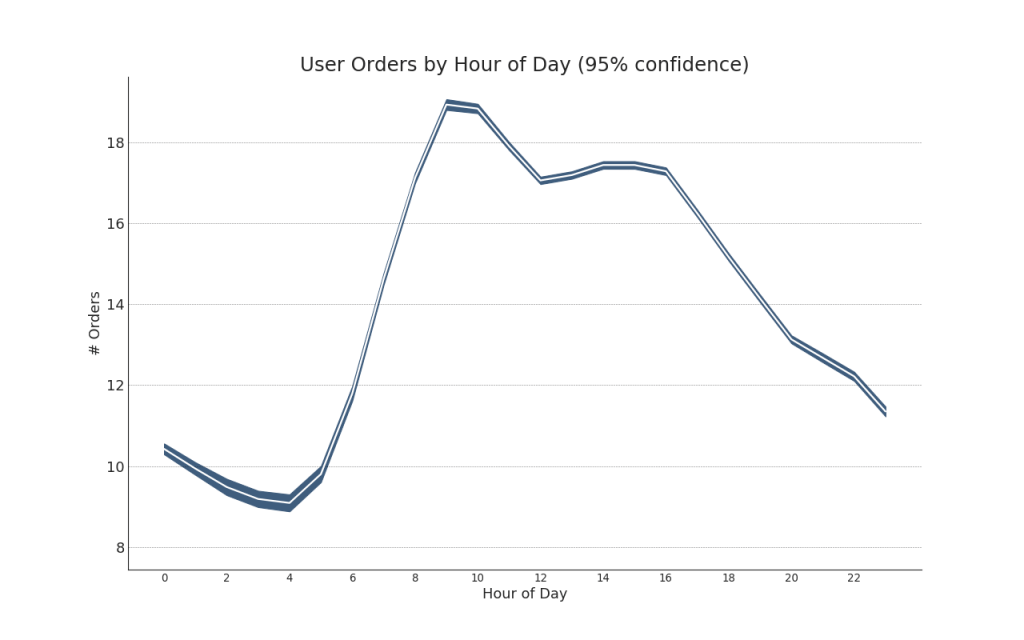
Mostrar código "Data Source: https://www.kaggle.com/olistbr/brazilian-ecommerce#olist_orders_dataset.csv" from dateutil.parser import parse from scipy.stats import sem
43. Gráfico com acumulação
O gráfico de áreas empilhadas fornece uma representação visual da taxa de contribuição de várias séries temporais.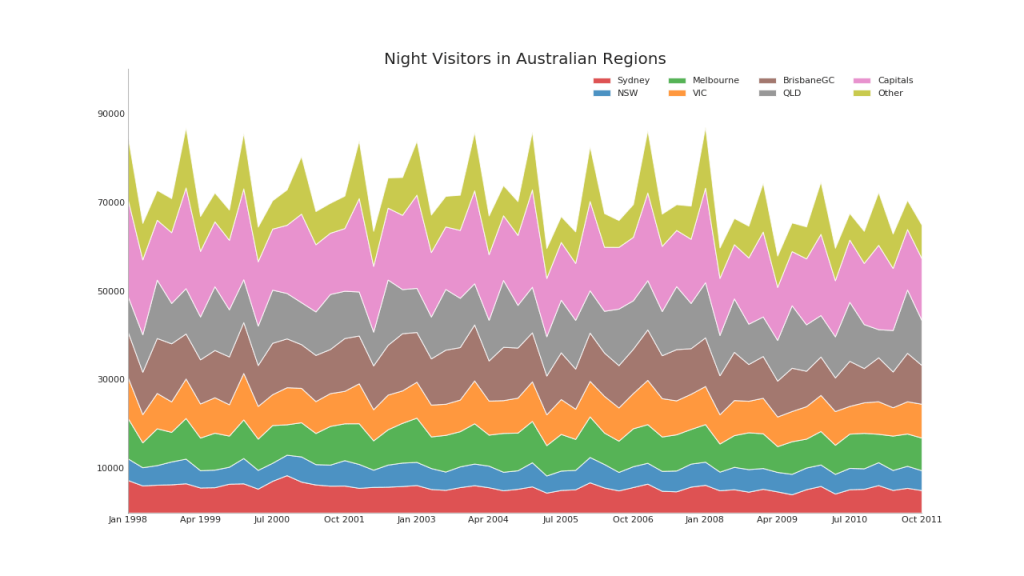
44. Gráfico de áreas Não empilhado
Um gráfico de área aberta é usado para visualizar o progresso (altos e baixos) de duas ou mais linhas em relação uma à outra. No diagrama abaixo, você pode ver claramente como a taxa de poupança pessoal diminui com um aumento na duração média do desemprego. Um diagrama com seções abertas mostra bem esse fenômeno.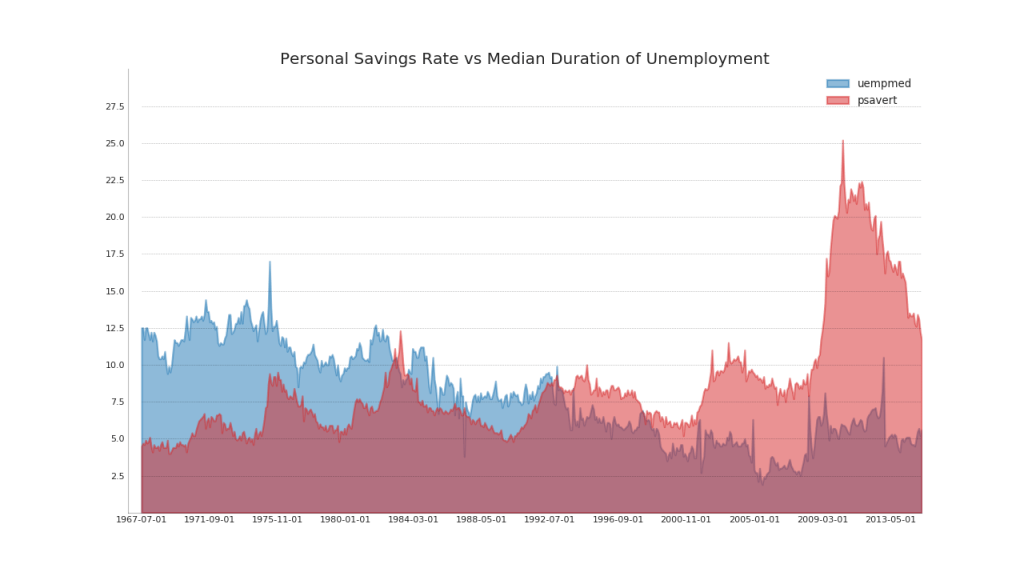
45. Mapa de calor do calendário
Um mapa de calendário é uma opção alternativa e menos preferida para visualizar dados com base no tempo em comparação com uma série temporal. Embora possam ser visualmente atraentes, os valores numéricos não são totalmente óbvios.Mostrar código import matplotlib as mpl import calmap

46. Gráfico sazonal
O cronograma sazonal pode ser usado para comparar séries temporais realizadas no mesmo dia da temporada anterior (ano / mês / semana, etc.).Mostrar código from dateutil.parser import parse
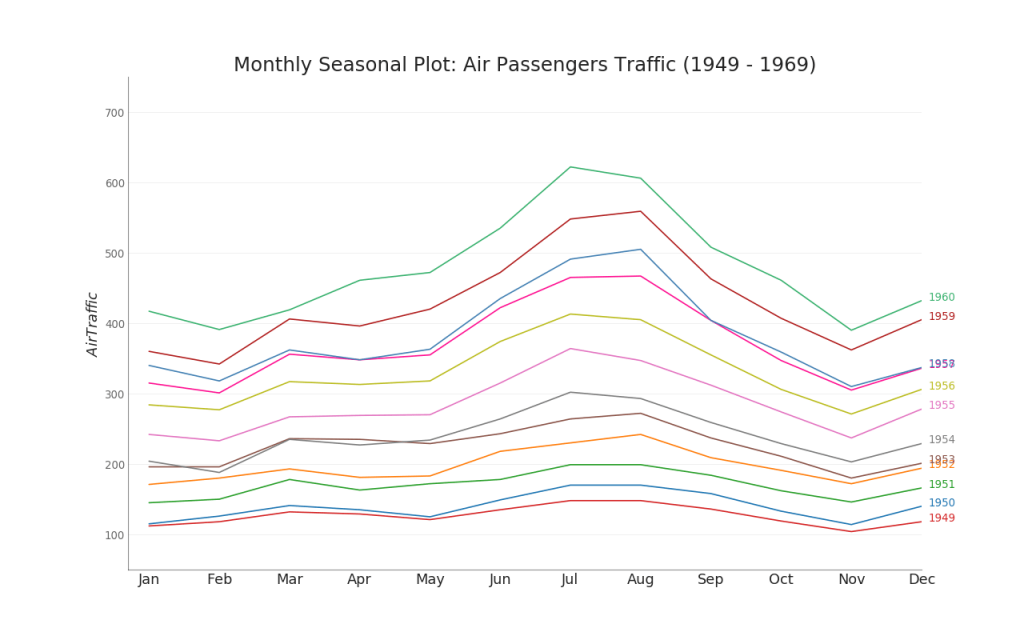
Grupos
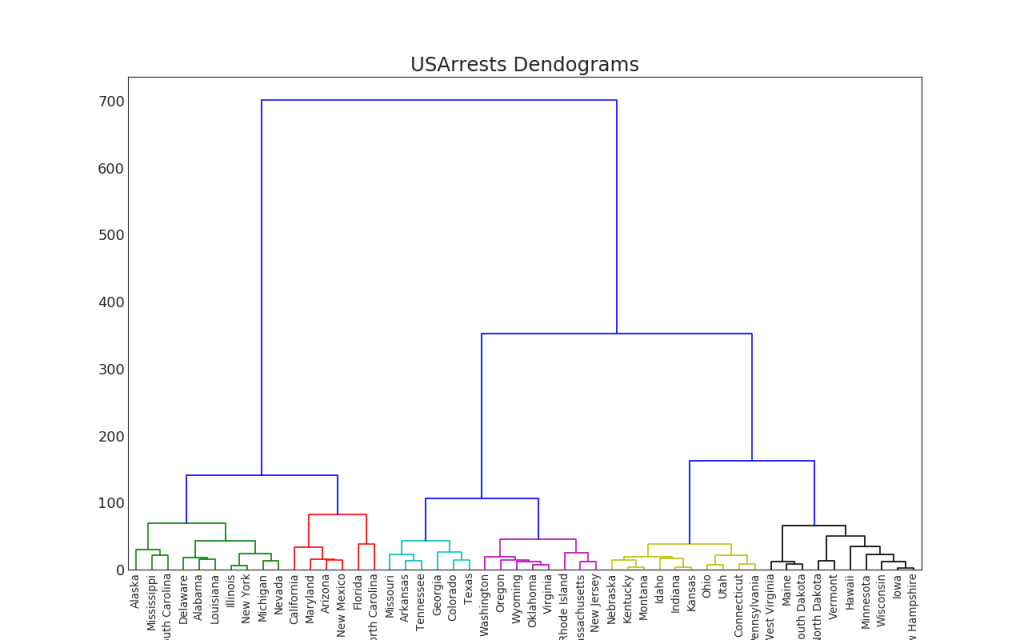
47. Dendrograma
O dendrograma agrupa pontos semelhantes com base em uma determinada métrica de distância e os organiza na forma de links de árvore com base na similaridade de pontos.Mostrar código import scipy.cluster.hierarchy as shc
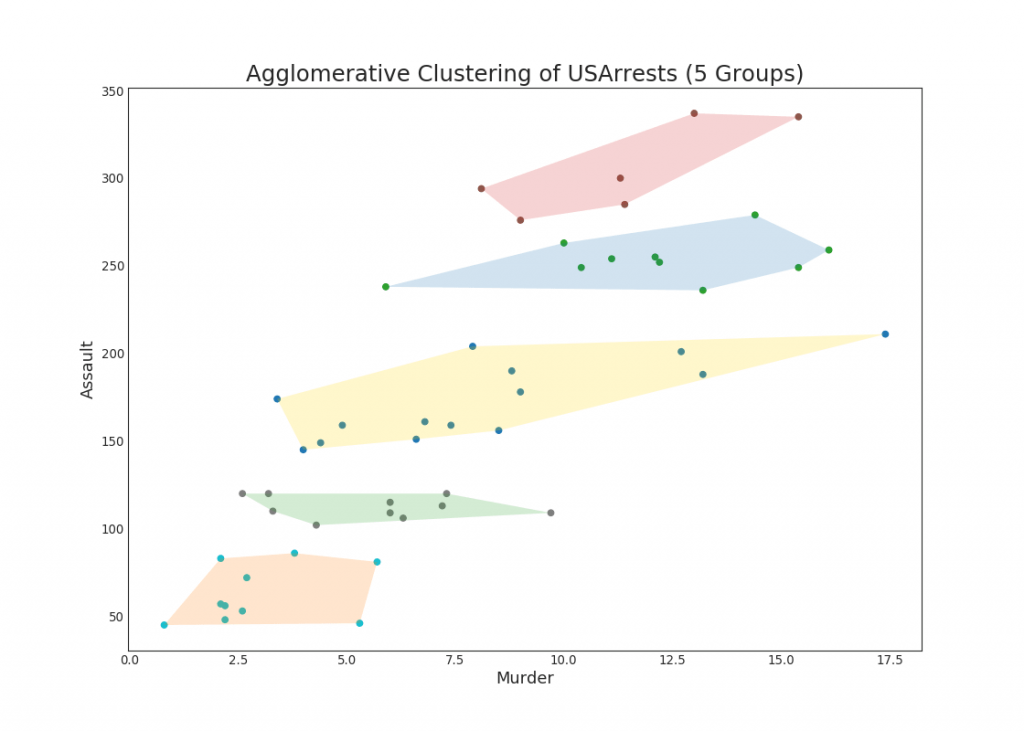
48. Diagrama de cluster
O gráfico de cluster pode ser usado para distinguir pontos pertencentes a um cluster. A seguir, é apresentado um exemplo ilustrativo de agrupamento de estados dos EUA em 5 grupos, com base no conjunto de dados USArrests. Este gráfico de cluster usa as colunas "matar" e "atacar" como os eixos X e Y. Como alternativa, você pode usar o primeiro dos componentes principais como os eixos X e Y.Mostrar código from sklearn.cluster import AgglomerativeClustering from scipy.spatial import ConvexHull
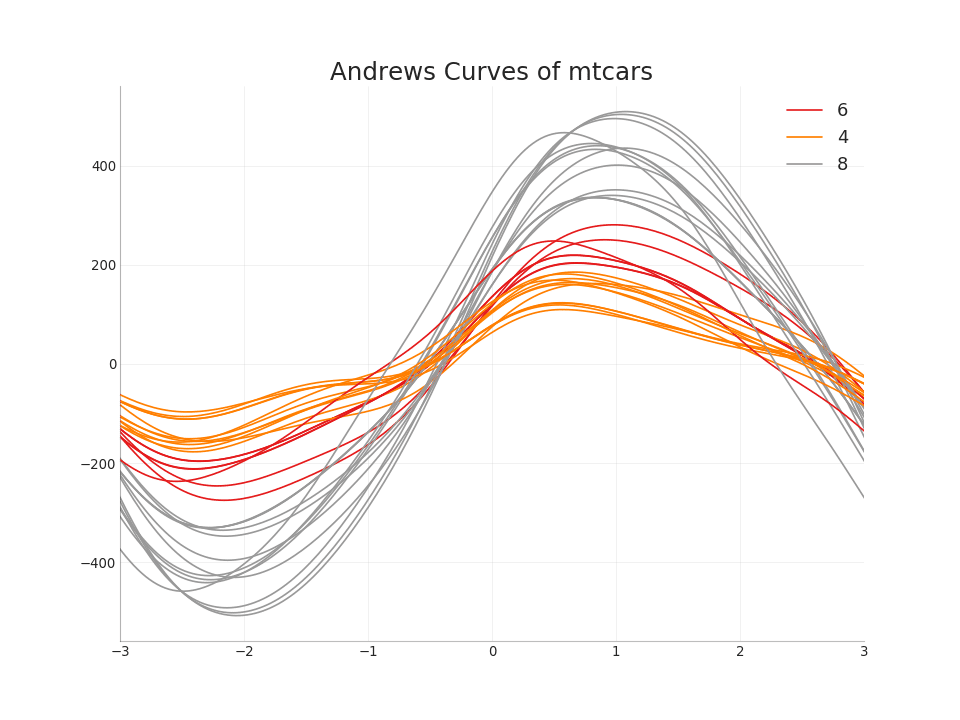
49. Curva de Andrews
A curva de Andrews ajuda a visualizar se os recursos numéricos inerentes a um agrupamento existem com base em um determinado agrupamento. Se os objetos (colunas no conjunto de dados) não ajudarem a distinguir o grupo, as linhas não serão bem separadas, como mostrado abaixoMostrar código from pandas.plotting import andrews_curves
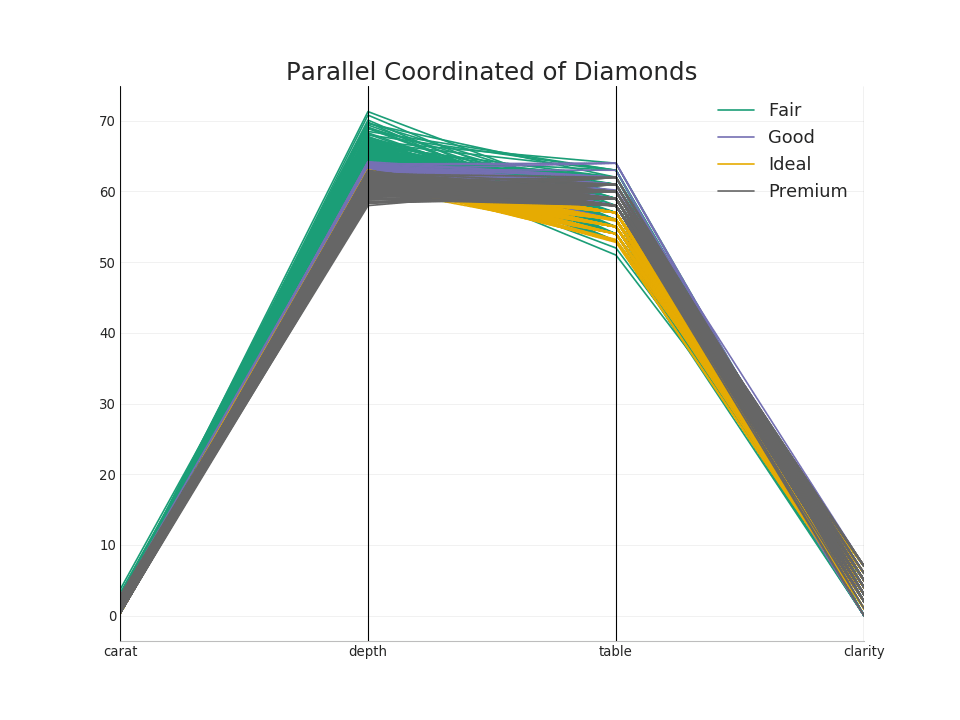
50. Coordenadas paralelas
Coordenadas paralelas ajudam a visualizar se uma função ajuda a separar efetivamente grupos. Se ocorrer segregação, esse recurso provavelmente será muito útil para prever esse grupo.Mostrar código from pandas.plotting import parallel_coordinates
 Código de bônus em Júpiter
Código de bônus em JúpiterGanso, você prometeu vibrações!