Atualmente, as palavras "inteligência artificial" significam muitos sistemas diferentes - de uma rede neural para reconhecimento de imagens a um bot para jogar Quake. A Wikipedia fornece uma definição maravilhosa de IA - essa é "a propriedade de sistemas inteligentes para executar funções criativas que são tradicionalmente consideradas prerrogativas do homem". Ou seja, é claramente visto a partir da definição - se uma determinada função foi automatizada com sucesso, ela deixa de ser considerada inteligência artificial.
No entanto, quando a tarefa de "criar inteligência artificial" foi definida pela primeira vez, a IA significava algo diferente. Esse objetivo agora é chamado de IA forte ou AI de uso geral.
Declaração do problema
Agora, existem duas formulações bem conhecidas do problema. O primeiro é IA forte. O segundo é uma IA de uso geral (também conhecida como Artifical General Intelligence, AGI abreviada).
Upd. Nos comentários, eles me dizem que essa diferença é mais provável no nível do idioma. Em russo, a palavra "inteligência" não significa exatamente o que a palavra "inteligência" em inglês
Uma IA forte é uma IA hipotética que poderia fazer tudo o que uma pessoa poderia fazer. Costuma-se mencionar que ele deve passar no teste de Turing no cenário inicial (hum, as pessoas passam?), Estar ciente de si mesmo como uma pessoa separada e ser capaz de atingir seus objetivos.
Ou seja, é algo como uma pessoa artificial. Na minha opinião, a utilidade de uma IA desse tipo é principalmente pesquisa, porque as definições de uma IA forte não dizem em lugar algum quais serão seus objetivos.
AGI ou AI de uso geral é uma "máquina de resultados". Ela recebe um determinado objetivo na entrada - e fornece algumas ações de controle em motores / lasers / placas de rede / monitores. E o objetivo é alcançado. Ao mesmo tempo, a AGI inicialmente não tem conhecimento sobre o meio ambiente - apenas sensores, atuadores e o canal através do qual estabelece metas. O sistema de gerenciamento será considerado um AGI se conseguir atingir algum objetivo em qualquer ambiente. Nós a colocamos para dirigir um carro e evitar acidentes - ela vai lidar com isso. Nós a colocamos no controle de um reator nuclear para que haja mais energia, mas não exploda - ela pode lidar com isso. Vamos dar uma caixa de correio e instruir para vender aspiradores de pó - também vai lidar. AGI é um solucionador de "problemas inversos". Verificar quantos aspiradores de pó são vendidos é uma questão simples. Mas descobrir como convencer uma pessoa a comprar esse aspirador de pó já é uma tarefa para o intelecto.
Neste artigo, vou falar sobre a AGI. Sem testes de Turing, sem autoconsciência, sem personalidades artificiais - IA excepcionalmente pragmática e operadores menos pragmáticos.
Situação atual
Agora, existe uma classe de sistemas como Aprendizado por Reforço ou Aprendizado Reforçado. Isso é algo como AGI, apenas sem versatilidade. Eles são capazes de aprender e, devido a isso, alcançar objetivos em uma variedade de ambientes. Mas ainda estão muito longe de alcançar metas em qualquer ambiente.
Em geral, como são organizados os sistemas de Aprendizado por Reforço e quais são seus problemas?
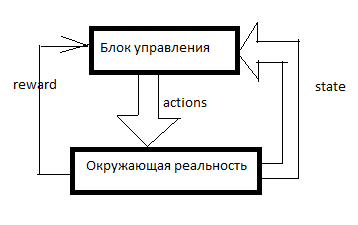
Qualquer RL é organizado assim. Existe um sistema de controle, alguns sinais sobre a realidade circundante entram através dos sensores (estado) e através dos órgãos de governo (ações) que atuam na realidade circundante. Recompensa é um sinal de reforço. Nos sistemas RL, o reforço é formado de fora da unidade de controle e indica o quão bem a IA lida com a consecução do objetivo. Quantos aspiradores de pó vendidos no último minuto, por exemplo.
Em seguida, uma tabela é formada de algo assim (vou chamá-la de tabela SAR):

O eixo do tempo é direcionado para baixo. A tabela mostra tudo o que a IA fez, tudo o que ele viu e todos os sinais de reforço. Geralmente, para que RL faça algo significativo, ele primeiro precisa fazer movimentos aleatórios por um tempo ou observar os movimentos de outra pessoa. Em geral, o RL inicia quando já existem pelo menos algumas linhas na tabela SAR.
O que acontece depois?
Sarsa
A forma mais simples de aprendizado por reforço.
Adotamos algum tipo de modelo de aprendizado de máquina e, usando uma combinação de S e A (estado e ação), prevemos o R total para os próximos ciclos de clock. Por exemplo, veremos que (com base na tabela acima) se você disser a uma mulher "seja homem, compre um aspirador de pó!", A recompensa será baixa e, se você disser a mesma coisa a um homem, será alta.
Quais modelos específicos podem ser usados - descreverei mais adiante, por enquanto apenas direi que essas não são apenas redes neurais. Você pode usar árvores de decisão ou até mesmo definir uma função em forma de tabela.
E então acontece o seguinte. O AI recebe outra mensagem ou link para outro cliente. Todos os dados do cliente são inseridos na AI de fora - consideraremos a base de clientes e o contador de mensagens como parte do sistema do sensor. Ou seja, resta atribuir um A (ação) e aguardar reforços. A IA toma todas as ações possíveis e, por sua vez, prevê (usando o mesmo modelo de Machine Learning) - o que acontecerá se eu fizer isso? E se for? E quanto reforço será para isso? E então RL executa a ação para a qual a recompensa máxima é esperada.
Eu introduzi um sistema tão simples e desajeitado em um dos meus jogos. A SARSA contrata unidades no jogo e se adapta em caso de alteração nas regras do jogo.
Além disso, em todos os tipos de treinamento reforçado, há um desconto de recompensas e um dilema de explorar / explorar.
O desconto de prêmios é uma abordagem desse tipo quando a RL tenta maximizar não o valor da recompensa para os próximos N movimentos, mas o valor ponderado de acordo com o princípio "100 rublos agora é melhor que 110 em um ano". Por exemplo, se o fator de desconto for 0,9 e o horizonte de planejamento for 3, treinaremos o modelo não no R total para os próximos 3 ciclos de relógio, mas em R1 * 0,9 + R2 * 0,81 + R3 * 0,729. Por que isso é necessário? Então, essa IA, criando lucro em algum lugar no infinito, não precisamos. Precisamos de uma IA que gere lucro aqui e agora.
Explorar / explorar o dilema. Se a RL fizer o que o modelo considera ideal, nunca saberá se existem estratégias melhores. Explorar é uma estratégia na qual RL faz o que promete recompensas máximas. Explore é uma estratégia na qual a RL faz algo para explorar o ambiente em busca de melhores estratégias. Como implementar uma inteligência eficaz? Por exemplo, você pode executar uma ação aleatória a cada poucas medidas. Ou você pode criar não um modelo preditivo, mas vários com configurações ligeiramente diferentes. Eles produzirão resultados diferentes. Quanto maior a diferença, maior o grau de incerteza dessa opção. Você pode executar a ação para que ela tenha o valor máximo: M + k * std, em que M é a previsão média de todos os modelos, std é o desvio padrão das previsões e k é o coeficiente de curiosidade.
Quais são as desvantagens?Digamos que temos opções. Vá para a meta (que fica a 10 km de distância e o caminho é bom) de carro ou a pé. E então, após essa escolha, temos opções - mova-se com cuidado ou tente colidir com cada pilar.
A pessoa dirá imediatamente que geralmente é melhor dirigir um carro e se comportar com cuidado.
Mas SARSA ... Ele analisará o que a decisão de ir de carro levou antes. Mas isso levou a isso. No estágio do conjunto inicial de estatísticas, a IA dirigiu de forma imprudente e caiu em algum lugar na metade dos casos. Sim, ele pode dirigir bem. Mas quando ele escolhe ir de carro, ele não sabe o que escolherá na próxima jogada. Ele tem estatísticas - então, na metade dos casos, ele escolheu a opção apropriada e na metade - suicida. Portanto, em média, é melhor andar.
A SARSA acredita que o agente seguirá a mesma estratégia usada para preencher a tabela. E age nessa base. Mas e se assumirmos o contrário - que o agente aderirá à melhor estratégia nos próximos movimentos?
Q-learning
Este modelo calcula para cada estado a recompensa total máxima alcançável a partir dele. E ele escreve em uma coluna especial Q. Ou seja, se do estado S você pode obter 2 pontos ou 1, dependendo da jogada, então Q (S) será igual a 2 (com uma profundidade de previsão de 1). Que recompensa pode ser obtida do estado S, aprendemos com o modelo preditivo Y (S, A). (Estado S, ação A).
Em seguida, criamos um modelo preditivo Q (S, A) - ou seja, em que estado Q iremos se executarmos a ação A de S. E criamos a próxima coluna na tabela - Q2. Ou seja, o Q máximo que pode ser obtido do estado S (classificamos todos os possíveis A).
Em seguida, criamos um modelo de regressão Q3 (S, A) - isto é, para o estado em que Q2 iremos se executarmos a ação A de S.
E assim por diante Assim, podemos alcançar uma profundidade ilimitada de previsão.
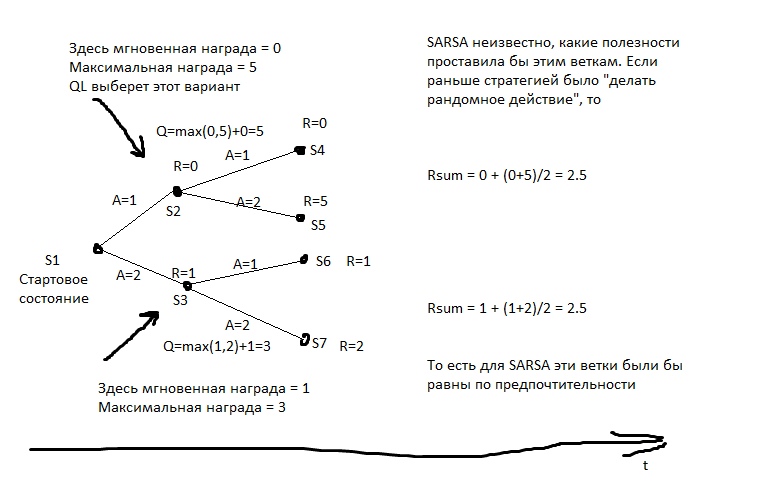
Na figura, R é o reforço.
E então, a cada movimento, selecionamos a ação que promete o maior Qn. Se aplicássemos esse algoritmo ao xadrez, obteríamos algo como um minimax ideal. Algo quase equivalente a calcular mal os movimentos para grandes profundidades.
Um exemplo comum de comportamento de q-learning. O caçador tem uma lança, e ele vai com ele até o urso, por sua própria iniciativa. Ele sabe que a grande maioria de seus movimentos futuros tem uma recompensa negativa muito grande (há muito mais maneiras de perder do que maneiras de ganhar), ele sabe que existem movimentos com uma recompensa positiva. O caçador acredita que no futuro ele fará as melhores jogadas (e não se sabe quais são as da SARSA) e, se ele fizer as melhores jogadas, derrotará o urso. Ou seja, para ir ao urso, basta que ele seja capaz de criar todos os elementos necessários à caça, mas não é necessário ter experiência de sucesso imediato.
Se o caçador agisse no estilo da SARSA, ele assumiria que suas ações no futuro seriam as mesmas de antes (apesar do fato de que agora ele tem uma bagagem de conhecimento diferente), e ele só aceitaria o urso se ele já fosse para e ele venceu, por exemplo, em> 50% dos casos (bem, ou se outros caçadores venceram em mais da metade dos casos, se ele aprender com a experiência deles).
Quais são as desvantagens?- O modelo não lida com a realidade em mudança. Se toda a nossa vida nos foi premiada por pressionar o botão vermelho, e agora eles estão nos punindo, e nenhuma mudança visível ocorreu ... QL dominará esse padrão por muito tempo.
- Qn pode ser uma função muito complexa. Por exemplo, para calculá-lo, você precisa rolar um ciclo de N iterações - e isso não funcionará mais rápido. Um modelo preditivo geralmente tem complexidade limitada - mesmo uma grande rede neural tem um limite de complexidade e quase nenhum modelo de aprendizado de máquina pode girar ciclos.
- A realidade geralmente tem variáveis ocultas. Por exemplo, que horas são agora? É fácil descobrir se olhamos para o relógio, mas assim que desviar o olhar, essa já é uma variável oculta. Para levar em conta esses valores não observáveis, é necessário que o modelo leve em consideração não apenas o estado atual, mas também algum tipo de histórico. Na QL, você pode fazer isso - por exemplo, para alimentar não apenas o S atual, mas também vários anteriores no neurônio ou o que temos lá. Isso é feito no RL, que joga os jogos da Atari. Além disso, você pode usar uma rede neural recorrente para previsão - deixe que ela execute sequencialmente vários quadros do histórico e calcule o Qn.
Sistemas baseados em modelo
Mas e se predizermos não apenas R ou Q, mas geralmente todos os dados sensoriais? Teremos constantemente uma cópia de bolso da realidade e poderemos verificar nossos planos. Nesse caso, estamos muito menos preocupados com a dificuldade de calcular a função Q. Sim, é preciso calcular muitos relógios - bem, de qualquer maneira, para cada plano, executaremos repetidamente o modelo de previsão. Planejando 10 avança? Lançamos o modelo 10 vezes e cada vez que alimentamos suas saídas com suas entradas.
Quais são as desvantagens?- Intensidade de recursos. Suponha que precisamos escolher duas alternativas em cada medida. Então, por 10 ciclos de relógio, teremos 2 ^ 10 = 1024 planos possíveis. Cada plano é de 10 lançamentos de modelos. Se controlarmos um avião com dezenas de órgãos de governo? E simulamos a realidade com um período de 0,1 segundos? Deseja ter um horizonte de planejamento por pelo menos alguns minutos? Teremos que executar o modelo muitas vezes, há muitos ciclos de clock do processador para uma solução. Mesmo que você otimize de alguma forma a enumeração de planos, mesmo assim, existem ordens de magnitude com mais cálculos do que na QL.
- O problema do caos. Alguns sistemas são projetados para que até uma pequena imprecisão da simulação de entrada leve a um enorme erro de saída. Para combater isso, você pode executar várias simulações da realidade - um pouco diferente. Eles produzirão resultados muito diferentes e, a partir disso, será possível entender que estamos na zona dessa instabilidade.
Método de enumeração da estratégia
Se tivermos acesso ao ambiente de teste para IA, se o executarmos não na realidade, mas em uma simulação, poderemos anotar de alguma forma a estratégia do comportamento de nosso agente. E então escolha - com a evolução ou outra coisa - uma estratégia que leve ao lucro máximo.
“Escolha uma estratégia” significa que precisamos primeiro aprender a escrever uma estratégia de tal maneira que ela possa ser inserida no algoritmo de evolução. Ou seja, podemos escrever a estratégia com o código do programa, mas em alguns lugares deixamos os coeficientes e deixamos que a evolução os pegue. Ou podemos escrever uma estratégia com uma rede neural - e deixar a evolução pegar o peso de suas conexões.
Ou seja, não há previsão aqui. Nenhuma tabela SAR. Simplesmente selecionamos uma estratégia e ela imediatamente distribui ações.
Esse é um método poderoso e eficaz. Se você quiser experimentar o RL e não souber por onde começar, recomendo. Esta é uma maneira muito barata de "ver um milagre".
Quais são as desvantagens?- A capacidade de executar as mesmas experiências muitas vezes é necessária. Ou seja, devemos ser capazes de retroceder a realidade ao ponto de partida - dezenas de milhares de vezes. Para tentar uma nova estratégia.
A vida raramente oferece tais oportunidades. Normalmente, se temos um modelo do processo em que estamos interessados, não podemos criar uma estratégia astuta - podemos simplesmente elaborar um plano, como em uma abordagem baseada em modelos, mesmo com força bruta. - Intolerância à experiência. Temos uma tabela SAR para anos de experiência? Podemos esquecer, isso não se encaixa no conceito.
Um método de enumerar estratégias, mas "ao vivo"
A mesma enumeração de estratégias, mas na realidade viva. Tentamos 10 medidas de uma estratégia. Então 10 mede outro. Então 10 medidas do terceiro. Depois, selecionamos aquele em que houve mais reforço.
Os melhores resultados para caminhar humanóides foram obtidos por esse método.

Para mim, isso parece um tanto inesperado - parece que a abordagem baseada no modelo QL + é matematicamente ideal. Mas nada disso. As vantagens da abordagem são aproximadamente as mesmas que as anteriores - mas são menos pronunciadas, já que as estratégias não são testadas por muito tempo (bem, não temos milênios na evolução), o que significa que os resultados são instáveis. Além disso, o número de testes também não pode ser elevado ao infinito - o que significa que a estratégia terá que ser buscada em um espaço de opções não muito complicado. Ela não apenas terá "canetas" que podem ser "torcidas". Bem, a intolerância à experiência não foi cancelada. E, comparados a QL ou baseados em modelo, esses modelos usam a experiência de maneira ineficiente. Eles precisam de muito mais interações com a realidade do que abordagens que usam aprendizado de máquina.
Como você pode ver, qualquer tentativa de criar uma AGI em teoria deve incluir aprendizado de máquina para prêmios de previsão ou alguma forma de notação paramétrica de uma estratégia - para que você possa pegar essa estratégia com algo como evolução.
Este é um forte ataque contra pessoas que se oferecem para criar IA com base em bancos de dados, lógica e gráficos conceituais. Se você, proponente da abordagem simbólica, leia isso - seja bem-vindo aos comentários, ficarei feliz em saber o que a AGI pode fazer sem a mecânica descrita acima.
Modelos de aprendizado de máquina para RL
Quase qualquer modelo de ML pode ser usado para aprendizado reforçado. As redes neurais são, obviamente, boas. Mas há, por exemplo, KNN. Para cada par S e A, procuramos os mais semelhantes, mas no passado. E estamos procurando o que será R. Estúpido depois disso? Sim, mas funciona. Existem árvores decisivas - aqui é melhor dar um passeio nas palavras-chave "aumento de gradiente" e "floresta decisiva". As árvores são pobres na captura de dependências complexas? Use a engenharia de recursos. Deseja que sua IA seja mais próxima do General? Use FE automático! Passe por várias fórmulas diferentes, envie-as como recursos para seu impulso, descarte as fórmulas que aumentam o erro e deixe as fórmulas que melhoram a precisão. Em seguida, envie as melhores fórmulas como argumentos para as novas fórmulas e assim por diante.
Você pode usar regressões simbólicas para previsão - ou seja, apenas classificando fórmulas na tentativa de obter algo que se aproxime de Q ou R. É possível tentar classificar algoritmos - então você obtém uma coisa chamada indução de Solomonov, que é teoricamente ideal, mas quase muito difícil de treinar. aproximações de funções.
Mas redes neurais são geralmente um compromisso entre expressividade e complexidade de aprendizado. A regressão algorítmica idealmente capta qualquer dependência - por centenas de anos. A árvore de decisão funcionará muito rapidamente - mas não poderá extrapolar y = a + b. Uma rede neural é algo no meio.
Perspectivas de desenvolvimento
Quais são as maneiras de fazer exatamente a AGI agora? Pelo menos teoricamente.
Evolução
Podemos criar muitos ambientes de teste diferentes e iniciar a evolução de alguma rede neural.
As configurações que obtiverem mais pontos no total em todas as tentativas serão multiplicadas.A rede neural deve ter memória e seria desejável ter pelo menos parte da memória na forma de uma fita, como uma máquina de Turing ou como um disco rígido.O problema é que, com a ajuda da evolução, você pode cultivar algo como RL, é claro. Mas como deve ser a linguagem na qual a RL parece compacta - para que a evolução a encontre - e ao mesmo tempo que a evolução não encontrar soluções como "mas vou criar um neurônio para cento e cinquenta camadas, para que todos fiquem loucos enquanto eu o ensino!" . A evolução é como uma multidão de usuários analfabetos - encontrará falhas no código e abandonará todo o sistema.Aixi
Você pode criar um sistema baseado em modelo com base em um pacote de muitas regressões algorítmicas. O algoritmo é garantido como Turing completo - o que significa que não haverá padrões que não possam ser captados. O algoritmo é escrito em código - o que significa que sua complexidade pode ser facilmente calculada. Isso significa que é possível refinar matematicamente suas hipóteses sobre o dispositivo de complexidade do mundo. Com redes neurais, por exemplo, esse truque não funcionará - aí a penalidade pela complexidade é muito indireta e heurística.Resta apenas aprender a treinar rapidamente regressões algorítmicas. Até agora, o melhor para isso é a evolução, e é imperdoávelmente longa.Seed AI
Seria legal criar uma IA que se aprimore. Melhore sua capacidade de resolver problemas. Isso pode parecer uma idéia estranha, mas esse problema já foi resolvido para sistemas de otimização estática, como a evolução . Se você conseguir perceber isso ... Tudo o que o expositor sabe é? Obteremos uma IA muito poderosa em muito pouco tempo.Como fazer isso?Você pode tentar organizar que, na RL, algumas das ações afetem as configurações da própria RL.Ou dê ao sistema RL alguma ferramenta para criar novos processadores de pré e pós-dados para você. Deixe a RL ser burra, mas ela poderá criar calculadoras, notebooks e computadores para si mesma.Outra opção é criar algum tipo de IA usando a evolução, na qual parte das ações afetará seu dispositivo no nível do código.Mas, no momento, não vi opções viáveis para o Seed AI - embora muito limitadas. Os desenvolvedores estão se escondendo? Ou essas opções são tão fracas que não mereceram atenção geral e passaram por mim?No entanto, agora o Google e o DeepMind trabalham principalmente com arquiteturas de redes neurais. Aparentemente, eles não querem se envolver na enumeração combinatória e tentam tornar suas idéias adequadas para o método de propagação reversa do erro.Espero que este artigo de revisão seja útil =) Comentários são bem-vindos, especialmente comentários como "Eu sei como melhorar a AGI"!