Redes neurais capturam o mundo. Eles contam visitantes, monitoram a qualidade, mantêm estatísticas e avaliam a segurança. Um monte de startups, uso industrial.
Grandes estruturas. O que é PyTorch, qual é o segundo TensorFlow. Tudo está se tornando mais conveniente e conveniente, mais simples e mais simples ...
Mas há um lado sombrio. Eles tentam ficar calados sobre ela. Não há nada alegre lá, apenas escuridão e desespero. Toda vez que você vê um artigo positivo, você suspira tristemente, porque entende que apenas uma pessoa não entendeu alguma coisa. Ou escondeu.
Vamos falar sobre produção em dispositivos embarcados.

Qual é o problema
Parece. Veja o desempenho do dispositivo, verifique se é suficiente, execute-o e obtenha lucro.
Mas, como sempre, existem algumas nuances. Vamos colocá-los nas prateleiras:
- Produção. Se o seu dispositivo não for fabricado em cópias únicas, você precisará ter certeza de que o sistema não travará, que os dispositivos não superaquecerão, que, se houver uma falha de energia, tudo será inicializado automaticamente. E isso é em uma grande festa. Isso oferece apenas duas opções - o dispositivo deve ser totalmente projetado, levando em consideração todos os problemas possíveis. Ou você precisa superar os problemas do dispositivo de origem. Bem, por exemplo, estes são ( 1 , 2 ). Que, é claro, é estanho. Para resolver os problemas do dispositivo de outra pessoa em grandes lotes, uma quantidade irreal de energia deve ser gasta.
- Benchmarks reais. Muita farsa e truques. A NVIDIA na maioria dos exemplos superestima o desempenho em 30 a 40%. Mas não só ela se diverte. Abaixo, dou muitos exemplos em que a produtividade pode ser 4-5 vezes menor do que você deseja. Você não pode transar "tudo funcionou bem no computador, será proporcionalmente pior aqui".
- Suporte muito limitado à arquitetura de rede neural. Existem muitas plataformas de hardware embarcadas que limitam bastante as redes que podem ser executadas nelas (Coral, gyrfalcone, snapdragon). Portar para essas plataformas será doloroso.
- Suporte. Algo não funciona para você, mas o problema está no lado do dispositivo? .. Este é o destino, não vai funcionar. Somente para RPi, a comunidade fecha a maioria dos bugs. E, em parte, para a Jetson.
- Preço Parece para muitos que embutido é barato. Mas, na realidade, com o crescimento do desempenho do dispositivo, o preço aumentará quase exponencialmente. O RPi-4 é 5 vezes mais barato que o Jetson Nano / Google Coral e 2-3 vezes mais fraco. O Jetson Nano é 5 vezes mais barato que o Jetson TX2 / Intel NUC e 2-3 vezes mais fraco que eles.
- Lorgus. Lembre-se deste design da Zhelyazny?
Parece que eu a defini como a imagem-título ... " O Logrus é um labirinto tridimensional mutável que representa as forças do Caos no multiverso " . Tudo isso é uma abundância de insetos e buracos, todas essas várias peças de ferro, todas as estruturas em mudança ... É normal quando o mercado muda completamente em 2-3 meses. Durante este ano, ele mudou 3-4 vezes. Você não pode entrar no mesmo rio duas vezes. Portanto, todos os pensamentos atuais são verdadeiros para o verão de 2019.
O que é
Vamos colocar em ordem, não tem um sabor doce ... O que agora existe e é adequado para os neurônios? Não há tantas opções, apesar da variabilidade. Algumas palavras gerais para limitar a pesquisa:
- Não analisarei neurônios / inferências em telefones. Isso por si só é um tópico enorme. Mas como os telefones são plataformas incorporadas com um ajuste de interferência, não acho que seja ruim.
- Vou tocar no Jetson TX1 | TX2. Nas condições atuais, essas não são as melhores plataformas para o preço, mas há situações em que ainda são convenientes de usar.
- Não garanto que a lista inclua todas as plataformas existentes hoje. Talvez eu tenha esquecido alguma coisa, talvez não saiba de alguma coisa. Se você conhece plataformas mais interessantes - escreva!
Então As principais coisas que estão claramente incorporando. No artigo, vamos compará-los precisamente:

- Plataforma Jetson . Existem vários dispositivos para isso:
- Jetson Nano - um brinquedo barato e bastante moderno (primavera de 2019)
- Jetson Tx1 | Tx2 - bastante caro, mas bom em plataformas de desempenho e versatilidade
- Raspberry Pi . Na realidade, apenas o RPi4 tem o desempenho para redes neurais. Mas algumas tarefas separadas podem ser realizadas na terceira geração. Eu até criei grades muito simples no começo.
- Google Coral Platform. De fato, para dispositivos de incorporação, há apenas um chip e dois dispositivos - Dev Board e USB Accelerator
- Plataforma Intel Movidius . Se você não é uma empresa grande, apenas os bastões Movidius 1 | Movidius 2 estarão disponíveis para você.
- Plataforma Gyrfalcone . O milagre da tecnologia chinesa. Já existem duas gerações - 2801, 2803
Misc. Falaremos sobre eles após as principais comparações:
- Processadores Intel. Primeiro de tudo, assembléias NUC.
- GPUs móveis da Nvidia. Soluções prontas podem ser consideradas não incorporadas. E se você coletar incorporação, ela resultará decentemente nas finanças.
- Telefones celulares. O Android é caracterizado pelo fato de que, para usar o desempenho máximo, é necessário usar exatamente o hardware que um fabricante específico possui. Ou use algo universal, como luz tensorflow. Para a Apple, a mesma coisa.
- O Jetson AGX Xavier é uma versão cara do Jetson com mais desempenho.
- GAP8 - processadores de baixa potência para dispositivos super baratos.
- Bosque misterioso AI BONÉ
Jetson
Trabalhamos com a Jetson há muito tempo. Em 2014,
Vasyutka inventou a matemática para o então
Swift precisamente em Jetson. Em 2015, em uma reunião com a Artec 3D, conversamos sobre como é uma plataforma bacana, após o que eles sugeriram que construíssemos um protótipo baseado nela. Depois de alguns meses, o protótipo estava pronto. Apenas alguns anos de trabalho de toda a empresa, alguns anos de maldições na plataforma e no céu ... E
Artec Leo nasceu - o scanner mais legal da sua classe. Até a Nvidia na apresentação do TX2 o
mostrou como um dos projetos mais interessantes criados na plataforma.
Desde então, o TX1 / TX2 / Nano usamos em algum lugar em 5-6 projetos.
E, provavelmente, conhecemos todos os problemas que estavam com a plataforma. Vamos tomá-lo em ordem.
Jetson tk1
Eu não vou falar especialmente sobre ele. A plataforma era muito eficiente em poder de computação em seu dia. Mas ela não era mercearia. A NVIDIA vendeu os chips
TegraTK1 que sustentavam a Jetson. Mas esses chips eram impossíveis de usar para pequenos e médios fabricantes. Na realidade, apenas o Google / HTC / Xiaomi / Acer / Google poderia fazer algo além da Nvidia. Todos os outros integrados ao produto ou debugam placas ou saquearam outros dispositivos.
Jetson TX1 | TX2
A Nvidia tirou as conclusões corretas e a próxima geração foi fantástica. TX1 | TX2, esses não são mais chips, mas um chip no tabuleiro.


Eles são mais caros, mas têm um nível completamente de supermercado. Uma pequena empresa pode integrá-los em seu produto, este produto é previsível e estável. Eu pessoalmente vi como 3-4 produtos foram trazidos para a produção - e tudo estava bem.
Vou falar sobre TX2, porque a partir da linha atual é a placa principal.
Mas, é claro, nem todos agradecem a Deus. O que há de errado:
- Jetson TX2 é uma plataforma cara. Na maioria dos produtos, você usará o módulo principal (pelo que entendi, pelo tamanho do lote, o preço será algo entre 200-250 e 350-400 cu cada). Ele precisa de um CarrierBoard. Não conheço o mercado atual, mas antes era de 100 a 300 cu dependendo da configuração. Bem, além de seu kit para o corpo.
- O Jetson TX2 não é a plataforma mais rápida. A seguir, discutiremos velocidades comparativas; mostrarei por que essa não é a melhor opção.
- É necessário remover muito calor. Provavelmente isso é verdade para quase todas as plataformas sobre as quais falaremos. A carcaça deve resolver o problema de dissipação de calor. Fãs
- Esta é uma plataforma ruim para pequenas festas. Muitas centenas de dispositivos - aprox. Encomendar placas-mãe, desenvolver projetos e embalagens é a norma. Muitos milhares de dispositivos? Crie sua placa-mãe - e chique. Se você precisar de 5-10 - ruim. Você terá que usar o DevBoard provavelmente. Eles são grandes, são um pouco nojentos para piscar. Esta não é uma plataforma pronta para RPi.
- Suporte técnico ruim da Nvidia. Ouvi muitos juramentos de que as respostas são respondidas, que são informações secretas ou mensais.
- Má infraestrutura na Rússia. É difícil encomendar, leva muito tempo. Mas, ao mesmo tempo, os revendedores funcionam bem. Recentemente, deparei com um Jetson nano que queimava no dia do lançamento - alterado sem questionar. Sam apanhado pelo correio / trouxe um novo. WAH! Além disso, ele próprio viu que o escritório de Moscou aconselha bem. Porém, assim que seu nível de conhecimento não permitir responder à pergunta e exigir uma solicitação ao escritório internacional - eles terão que esperar por respostas por um longo tempo.
O que é incrível:
- Muita informação, uma comunidade muito grande.
- Em torno da Nvidia, existem muitas pequenas empresas que produzem acessórios. Eles estão abertos a negociações, você pode ajustar a decisão deles. E CarierBoard, firmware e sistemas de refrigeração.
- Suporte para todas as estruturas normais (TensorFlow | PyTorch) e suporte completo para todas as redes. A única conversão que você pode precisar fazer é transferir o código para o TensorRT. Isso economizará memória, possivelmente acelerará. Comparado ao que estará em outras plataformas, isso é ridículo.
- Eu não sei como criar pranchas. Mas daqueles que fizeram isso pela Nvidia, ouvi dizer que o TX2 é uma boa opção. Existem manuais que correspondem à realidade.
- Bom consumo de energia. Mas tudo o que exatamente "incorporado" estará conosco - o pior :)
- Pinça na Rússia (explicado acima por que)
- Ao contrário do movidius | RPi Coral Gyrfalcon é uma GPU real. Você pode usar nele não apenas grades, mas também algoritmos normais
Como resultado, essa é uma boa plataforma para você, se você tiver dispositivos de peça, mas, por algum motivo, não poderá entregar um computador completo. Algo enorme? Biometria - provavelmente não. O reconhecimento de número está no limite, dependendo do fluxo. Dispositivos portáteis com um preço de mais de 5 mil dólares - possível. Carros - não, é mais fácil colocar uma plataforma mais poderosa um pouco mais cara.
Parece-me que, com o lançamento de uma nova geração de dispositivos baratos, o TX2 morrerá com o tempo.
As placas-mãe para Jetson TX1 | TX2 | TX2i e outras são parecidas com esta:

E
aqui ou
aqui há mais variações.
Jetson nano

Jetson Nano é uma coisa muito interessante. Para a Nvidia, esse é um novo fator de forma que, em termos de revolução, teria que se comparar com o TK1. Mas os concorrentes já estão se esgotando. Existem outros dispositivos sobre os quais falaremos. É 2 vezes mais fraco que o TX2, mas 4 vezes mais barato. Mais precisamente ... A matemática é complicada. Jetson Nano na placa demo custa 100 dólares (na Europa). Mas se você comprar apenas um chip, será mais caro. E você precisará criá-lo (ainda não há uma placa-mãe para ele). E Deus não permita que seja duas vezes mais barato em uma grande festa que o TX2.
De fato, a Jetson Nano, em sua base, é um produto de publicidade para institutos / revendedores / amadores, o que deve estimular o interesse e a aplicação comercial. Por vantagens e desvantagens (cruza parcialmente com TX2):
- O design é fraco e não é depurado:
- Superaquece, com uma carga constante periodicamente trava / voa. Uma empresa familiar tenta resolver todos os problemas há três meses - não dá certo.
- Eu tenho um queimado quando alimentado por USB. Ouvi dizer que um amigo tinha uma saída USB queimada e o plugue estava funcionando. Provavelmente alguns problemas com a alimentação USB.
- Se você empacotar a placa original, não haverá radiador suficiente da NVIDIA; por exemplo, ele superaquecerá.
- A velocidade não é suficiente. Quase duas vezes menos que TX2 (na realidade, pode ser 1,5, mas depende da tarefa).
- Muitos dispositivos de 5 a 10 são geralmente muito bons. 50-200 - é difícil, você precisará compensar todos os erros do fabricante, pendurá-lo em seus cães, se precisar adicionar algo como POE, isso vai doer. Festas maiores. Hoje não ouvi falar de projetos de sucesso. Mas parece-me que podem surgir dificuldades como no TK1. Para ser sincero, gostaria de esperar que o próximo ano seja lançado o Jetson Nano 2, onde essas doenças infantis serão corrigidas.
- O suporte está ruim, o mesmo que o TX2
- Infraestrutura deficiente
Bom:
- Orçamento suficiente em comparação com os concorrentes. Especialmente para pequenas festas. Preço / desempenho favoráveis
- Ao contrário do movidius | RPi Coral Gyrfalcon é uma GPU real. Você pode usar nele não apenas grades, mas também algoritmos normais
- Basta iniciar qualquer rede (igual ao TX2)
- Consumo de energia (o mesmo que tx2)
- Pinça na Rússia (o mesmo que tx2)
O próprio Nano saiu no início da primavera, em algum lugar de abril / maio, eu o cutuquei ativamente. Já conseguimos fazer dois projetos neles. Em geral, os problemas identificados acima. Como um produto de hobby / produto para pequenos lotes - muito legal. Mas se ainda é possível arrastar a produção e como fazê-lo, ainda não está claro.
Fale sobre a velocidade da Jetson.
Iremos comparar com outros dispositivos muito mais tarde. Enquanto isso, apenas fale sobre Jetson e velocidade. Por que a Nvidia está mentindo para nós. Como otimizar seus projetos.
Abaixo está escrito tudo sobre o TensorRT-5.1. O TensorRT-6.0.1 foi lançado em 17 de setembro de 2019, todas as instruções devem ser verificadas duas vezes lá.
Vamos supor que acreditamos na Nvidia. Vamos abrir o
site deles e ver o tempo de inferência do SSD-mobilenet-v2 para 300 * 300:
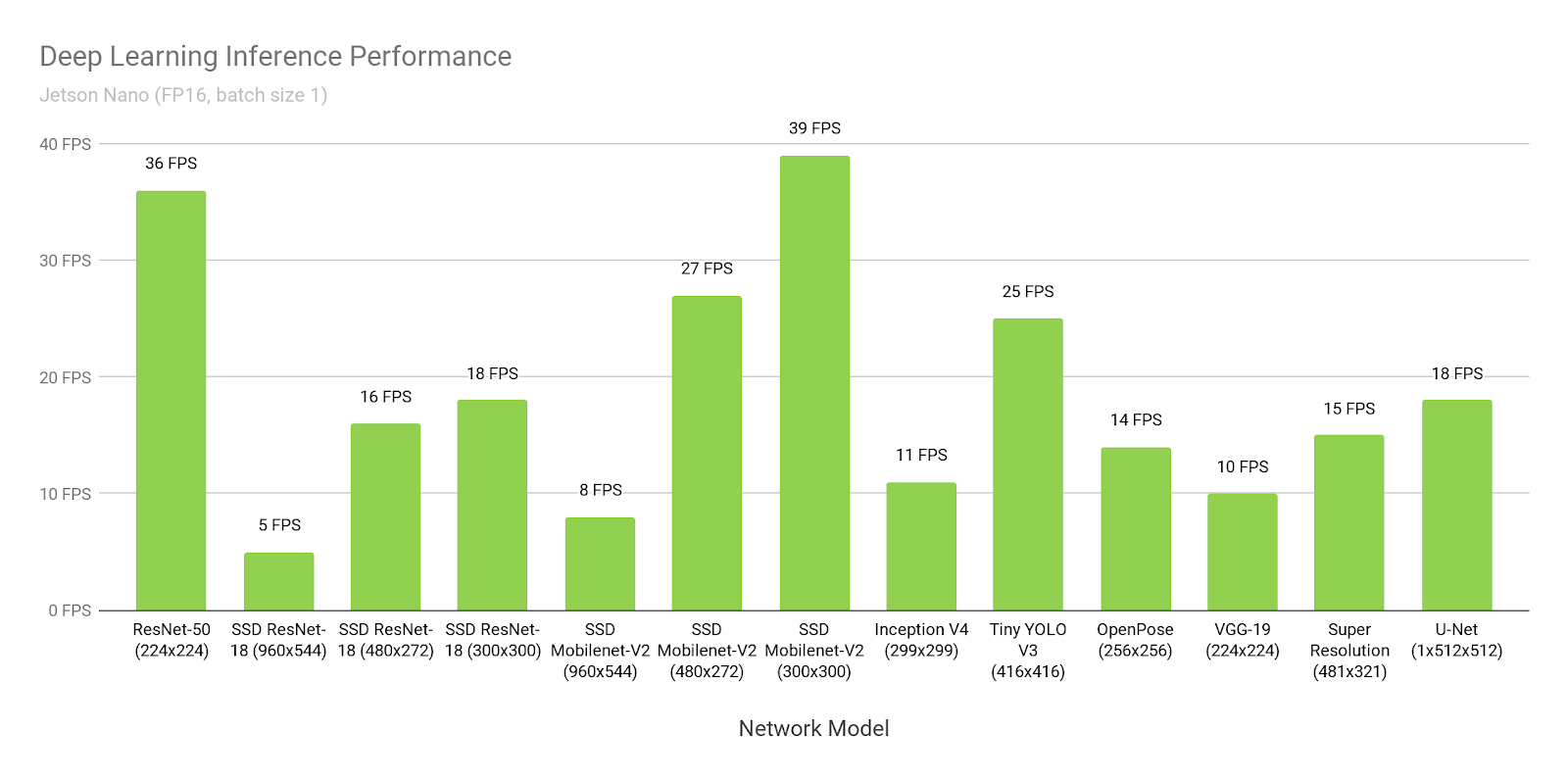
Uau, 39FPS (25ms). Sim, e o código fonte está
definido !
Hmm ... Mas por que está escrito
aqui sobre 46ms?
Espere ... E aqui
eles escrevem que 309 ms são nativos e 72ms são portados ...
Onde esta a verdade
A verdade é que todo mundo pensa muito diferente:
- SSD consiste em duas partes. Uma parte é o neurônio. A segunda parte é o pós-processamento do que o neurônio produziu (não supressão máxima) + o pré-processamento do que é carregado na entrada.
- Como eu disse anteriormente, no Jetson tudo precisa ser convertido para o TensorRT. Essa é uma estrutura nativa da NVIDIA. Sem ele, tudo será ruim. Só há um problema. Nem tudo é portado para lá, especialmente do TensorFlow. Globalmente, existem duas abordagens:
- O Google, percebendo que isso é um problema, lançou para o TensorFlow uma coisa chamada "tf-trt". De fato, este é um complemento para tf, que permite converter qualquer grade para tensorrt. As partes que não são suportadas são inferidas na CPU, o restante na GPU.
- Reescreva todas as camadas / encontre seus análogos
Nos exemplos acima:
- Nesse link, o tempo de 300ms é o fluxo tensor usual sem otimização.
- Lá, 72ms é a versão tf-trt. Lá, todos os nms são essencialmente feitos no processo.
- Esta é uma versão para fãs, onde uma pessoa transferiu todos os nms e os escreveu no próprio gpu.
- E isso ... Essa NVIDIA decidiu medir todo o desempenho sem pós-processamento, sem mencioná-lo explicitamente em qualquer lugar.
Você precisa entender por si mesmo que, se fosse o seu neurônio, que ninguém teria convertido antes de você, sem problemas você seria capaz de iniciá-lo a uma velocidade de 72ms. E a uma velocidade de 46 ms, sentado sobre os manuais e sorsa dia-semana.
Comparado a muitas outras opções, isso é muito bom. Mas não esqueça que, faça o que fizer - nunca acredite nos benchmarks da NVIDIA!
RaspberryPI 4
Produção? .. E eu ouvi como dezenas de engenheiros começaram a rir da menção das palavras "RPI" e "produção" nas proximidades. Mas, devo dizer - o RPI ainda é mais estável que o Jetson Nano e o Google Coral. Mas, é claro, o TX2 perde e, aparentemente, gyrfalcone.

(A imagem é
daqui . Parece-me que prender os fãs ao RPi4 é uma diversão folclórica separada.)
Da lista inteira, este é o único dispositivo que não segurei nas mãos / não testei. Mas ele iniciou neurônios em Rpi, Rpi2, Rpi3 (por exemplo, ele me disse
aqui ). Em geral, o Rpi4, como eu o entendo, difere apenas no desempenho. Parece-me que os prós e contras da RPi sabem tudo, mas ainda assim. Contras:
- Por mais que eu não queira, esta não é uma solução de supermercado. Superaquecimento . Congelamentos periódicos. Mas, devido à enorme comunidade, existem centenas de soluções para todos os problemas. Isso não torna o Rpi bom para milhares de tiragens. Mas dezenas / centenas - observa wai.
- Velocidade. Este é o dispositivo mais lento de todos os principais sobre os quais estamos falando.
- Quase não há suporte do fabricante. Este produto é destinado a entusiastas.
Prós:
- Preço Não, é claro, se você mesmo criar o tabuleiro, usando o gyrfalcone poderá torná-lo mais barato em milhares. Mas provavelmente isso não é realista. Onde o desempenho do RPi é suficiente - será a solução mais barata.
- Popularidade. Quando o Caffe2 foi lançado, havia uma versão para o Rpi no release base. Tensorflow light? Claro que funciona. I.T.D., I.T.P. O que o fabricante não faz é transferir usuários. Corri em diferentes RPi, Caffe, Tensorflow e PyTorch, e várias coisas mais raras.
- Conveniência para pequenas festas / peças. Basta piscar o pen drive e executar. Há Wi-Fi a bordo, ao contrário do JetsonNano. Você pode simplesmente ligá-lo através do PoE (parece que você precisa comprar um adaptador que é vendido ativamente).
Falaremos sobre a velocidade Rpi no final. Como o fabricante não postula que seu produto para neurônios, existem poucos parâmetros de referência. Todo mundo entende que o Rpi não é perfeito em velocidade. Mas mesmo ele é adequado para algumas tarefas.
Tivemos algumas tarefas de semi-produto que implementamos na Rpi. A impressão foi agradável.
Movidius 2

A partir daqui e abaixo, não serão processados processadores completos, mas processadores projetados especificamente para redes neurais. É como se seus pontos fortes e fracos ao mesmo tempo.
Então Movidius. A empresa foi comprada pela Intel em 2016. No segmento que nos interessa, a empresa lançou dois produtos, Movidius e Movidius 2. O segundo é mais rápido, falaremos apenas sobre o segundo.
Não, não é assim. A conversa não deve começar com o Movidius, mas com o Intel
OpenVino . Eu diria que isso é ideologia. Mais especificamente, a estrutura. De fato, esse é um conjunto de neurônios pré-treinados e inferências para eles, otimizados para produtos Intel (processadores, GPUs, computadores especiais). Integrado ao OpenCV, ao Raspberry Pi, a vários outros apitos e peidos.
A vantagem do OpenVino é que ele possui muitos neurônios. Primeiro de tudo, os detectores mais famosos. Neurônios para reconhecimento de pessoas, pessoas, números, letras, poses, etc., etc. (
1 ,
2 ,
3 ). E eles são treinados. Não por conjuntos de dados abertos, mas por conjuntos de dados compilados pela própria Intel. Eles são muito maiores / mais diversificados e mais abertos. Eles podem ser reciclados de acordo com os seus casos, e geralmente funcionarão bem.
É possível fazer melhor? Claro que você pode. Por exemplo, o reconhecimento dos números que fizemos - funcionou significativamente melhor. Mas passamos muitos anos desenvolvendo-o e entendendo como torná-lo perfeito. , .
OpenVino, , . . - — . . GAN . . , , , - , .
, :

, Intel OpenVino . . , . — . 70% OpenVino.
Movidius . . ( , ).
. USB , , !!! USB. . Intel
. - (
1 ,
2 )
. -. - .
?.. :)
, . OpenVino, , , ( Computer Vision ). :
( AI 2.0, OpenVino ).
, . Movidius 2. :
- . Rpi Jetson Nano. — . . Third Party ?
- . . .
- . .
- . USB 3.0
- , . -. . Movidius . .
Prós:
- . . .
- ,
- ,
. — .
, “ 20-30 , , ” — Movidius.
Intel
. , .
 UPD
UPD. . embedded . PCI-e . . — 200 .. . …
Google Coral
Estou desapontado Não, não há nada que eu não previsse. Mas estou desapontado que o Google tenha decidido divulgar isso. Testar é um milagre no começo do verão. Talvez algo tenha mudado desde então, mas descreverei minha experiência na época.
Configurando ... Para atualizar o Jetson Tk-Tx1-Tx2, você precisava conectá-lo ao computador host e à fonte de alimentação. E isso foi o suficiente. Para fazer flash Jetson Nano e RPi, você só precisa enviar a imagem para a unidade flash USB.
E para piscar Coral, você precisa prender três fios na
ordem correta :

E não tente cometer um erro! A propósito, há erros / comportamento indescritível no guia. Provavelmente não vou descrevê-los, já que desde o início do verão eles poderiam ter consertado alguma coisa. Lembro que, depois de instalar o Mendel, qualquer acesso via ssh foi perdido, incluindo o descrito por eles, e tive que editar manualmente algumas configurações do Linux.
Levei 2-3 horas para concluir este processo.
Ok Lançado. Você acha que é fácil executar sua grade nela? Quase nada :)
Aqui está uma lista do que você pode deixar para trás.
Para ser sincero, não cheguei a esse ponto rapidamente. Passou meio dia. Na verdade não. Você não pode fazer o download do modelo do
repositório TF e executar no dispositivo. Ou lá é necessário cortar todas as camadas. Não encontrei instruções.
Então aqui. É necessário pegar o modelo do repositório de cima. Não existem muitos (foram adicionados 3 modelos desde o início do verão). E como treiná-la? Abrir no TensorFlow em um pipeline padrão? HAHAHAHAHAHAHAHA. Claro que não !!!
Você tem um
contêiner de Doker especial e o modelo treinará apenas nele. (Provavelmente, você também pode zombar do seu TF ... Mas há instruções, instruções ... que não eram e não parecem ser.)
Baixe / instale / inicie. O que é ... Por que a GPU está em zero? .. PORQUE O TREINAMENTO ESTÁ NA CPU. Docker é apenas para ele !!! Quer mais diversão? O manual diz "baseado em uma CPU de 6 núcleos com estação de trabalho com memória de 64G". Parece que isso é apenas um conselho? Talvez. Só que agora eu não tinha o suficiente dos meus 8 shows nesse servidor, onde a maioria dos modelos treina. O treinamento na quarta hora consumia todos. Um forte sentimento de que eles tinham algo fluindo. Tentei alguns dias com parâmetros diferentes em máquinas diferentes, o efeito foi um.
Não verifiquei isso antes de publicar o artigo. Para ser sincero, foi o suficiente para mim uma vez.
O que mais a acrescentar? Que esse código não gera um modelo? Para gerá-lo, você deve:
- Contagem de atraso
- Converta-o para tflite
- Compile no TPU do Formal Edge. Graças a Deus agora isso é feito em um computador. Na primavera, isso só poderia ser feito online. E lá foi necessário marcar "Não o usarei para o mal / não viole nenhuma lei com esse modelo". Agora, graças a Deus não há nada disso.

Esse é o maior desgosto que experimentei em relação a um produto de TI no ano passado ...
Globalmente, Coral deve ter a mesma ideologia que o OpenVino com o Movidius. Só agora a Intel está nesse caminho há vários anos. Com excelentes manuais, suporte e bons produtos ... E o Google. Bem, é apenas o Google ...
Contras:
- Este fórum não é uma mercearia no nível do AD. Eu não ouvi falar sobre a venda de chips => a produção não é realista
- O nível de desenvolvimento é o mais terrível possível. Tudo bazhet. O pipeline de desenvolvimento não se encaixa nos esquemas tradicionais.
- O fã. No "chip energeticamente ótimo", eles colocam. Ok, não vou mais falar sobre produção.
- Custo. Mais caro que o TX2.
- Duas grades não podem ser mantidas na memória ao mesmo tempo. É necessário realizar o upload-download. O que diminui a inferência de várias redes.
Prós:
- De tudo o que falamos, Coral é o mais rápido
- Potencialmente, se o chip é ativado, é mais produtivo que o Movidius. E parece que sua arquitetura é mais justificada para os neurônios.
Gyrfalcon

Os últimos anos e meio têm falado sobre esta besta chinesa.
Há um
ano, eu
estava dizendo algo sobre ele. Mas falar é uma coisa, e dar informação é outra. Conversei com 3 a 4 grandes empresas, onde os gerentes / diretores de projetos me disseram como esse Girfalkon era legal. Mas eles não tinham nenhuma documentação. E eles não o viram vivo. O
site quase não
possui informações.
Faça o
download do site pelo menos algo que só pode ser parceiro (desenvolvedor de hardware). Além disso, as informações no site são muito contraditórias. Em um lugar, eles escrevem que suportam apenas
VGG , em outro, que apenas seus neurônios são baseados na GNet (que, de acordo com
suas garantias, são muito pequenos e realmente sem perda de precisão). No terceiro está escrito que tudo é convertido com TF | Caffe | PyTorch, e no quarto está escrito sobre o telefone celular e outros encantos.
Compreender a verdade é quase impossível. Uma vez eu estava cavando e cavando alguns vídeos nos quais pelo menos alguns números escorregam:
Se isso for verdade, significa SSD (no celular?) Abaixo de 224 * 224 no chip GTI2801, eles têm ~ 60ms, o que é bastante comparável ao movidius.
Parece que eles têm um chip 2803 muito mais rápido, mas as informações sobre ele são ainda menos:
Neste verão, temos uma
prancha de vaga-lume em nossas mãos (
este módulo é instalado lá para cálculos).
Havia uma esperança de que finalmente veríamos vivos. Mas não deu certo. O quadro estava visível, mas não funcionou. Rastreando frases individuais em inglês na documentação chinesa, eles quase entenderam qual era o problema (o sistema serrilhado inicial não suportava o módulo neural, era necessário reconstruir e refazer tudo nós mesmos). Mas simplesmente não deu certo e já havia suspeitas de que o conselho não se encaixaria em nossa tarefa (2 GB de RAM é muito pequeno para redes neurais + sistemas. Além disso, não havia suporte para duas redes ao mesmo tempo).
Mas eu consegui ver a documentação original. A partir disso, pouco se entende (chinês). Para o bem, era necessário testar e olhar a fonte.
O suporte técnico da RockChip marcou estupidamente em nós.
Apesar desse horror, é claro para mim que aqui, mesmo assim, os batentes do RockChip estão aqui antes de tudo. E tenho uma esperança de que, em um quadro normal, o Gyrfalcon possa ser bastante usado. Mas, devido à falta de informações, é difícil para mim dizer.
Contras:
- Não há vendas abertas, apenas interaja com empresas
- Pouca informação, nenhuma comunidade. As informações existentes costumam estar em chinês. Os recursos da plataforma não podem ser previstos com antecedência
- Provavelmente, a inferência não é mais do que uma rede por vez.
- Somente os fabricantes de ferro podem interagir com o próprio giroplano. O restante precisa procurar alguns intermediários / fabricantes de placas.
Prós:
- Pelo que entendi, o preço de um chip girfcon é muito mais barato que o resto. Mesmo na forma de pen drives.
- Já existem dispositivos de terceiros com um chip integrado. Portanto, o desenvolvimento é um pouco mais fácil que o movidius.
- Eles garantem que existem muitas grades pré-treinadas, a transferência de grades é muito mais fácil do que o Movidius | Coral. Mas eu não garantiria isso como verdade. Nós não tivemos sucesso.
Em suma, a conclusão é esta: muito pouca informação. Você não pode apenas se deitar nesta plataforma. E antes de fazer algo - você precisa fazer uma grande revisão.
Velocidades
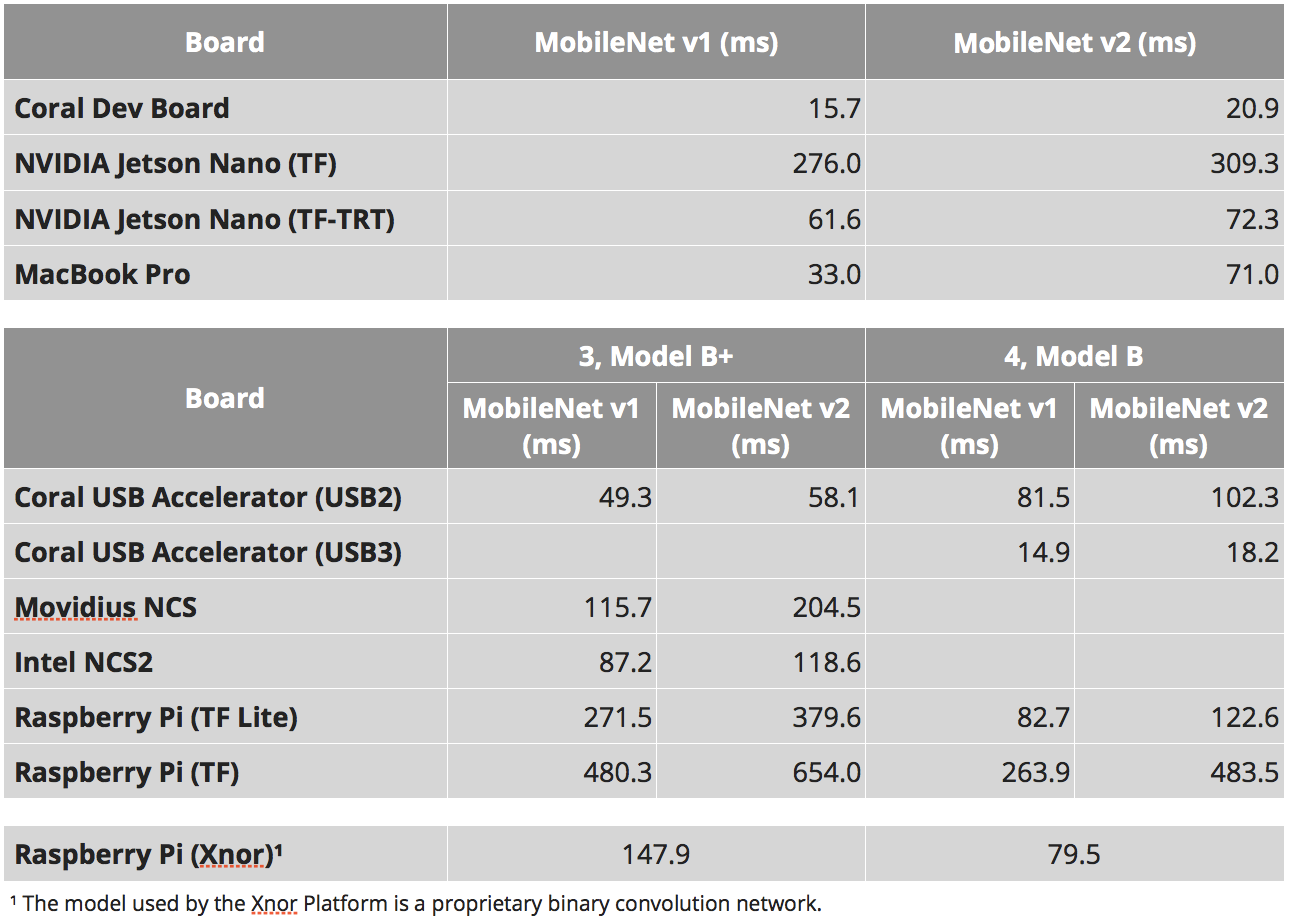
Eu realmente gosto de como 90% das comparações de dispositivos incorporados reduzem a velocidade nas comparações. Como você entendeu acima, essa característica é muito arbitrária. No Jetson Nano, você pode executar neurônios como fluxo tensor puro, usar tensorflow-tensorrt ou usar tensororr puro. Dispositivos com arquitetura especial de tensores (movidius | coral | gyrfalcone) - podem ser rápidos, mas, em primeiro lugar, podem funcionar apenas com arquiteturas padrão. Mesmo para o Raspberry Pi, nem tudo é tão simples. Os neurônios do
xnor.ai dão uma vez e meia de aceleração. Mas não sei o quanto são honestos e o que foi ganho ao mudar para int8 ou outras piadas.
Ao mesmo tempo, outra coisa interessante é esse momento. Quanto mais complexo o neurônio, mais complexo o dispositivo de inferência - mais imprevisível é a aceleração final que pode ser retirada. Tome um pouco de OpenPose. Existe uma rede não trivial, pós-processamento complexo. Isso e aquilo podem ser otimizados devido a:
- Migração de pós-processamento de GPU
- Otimize o pós-processamento
- Otimização de rede neural para recursos da plataforma, por exemplo:
- Usando redes otimizadas para plataforma
- Usando módulos de rede para a plataforma
- Portando para Int8 | Int16 | Binarização
- Usando várias calculadoras (GPU | CPU | etc.). Lembro que no Jetson TX1 uma vez aceleramos bem quando transferimos toda a funcionalidade relacionada ao streaming de vídeo para os aceleradores internos para esse fim. Banal, mas a rede acelerou. Ao balancear, muitas combinações interessantes aparecem
Às vezes, alguém tenta avaliar algo para todas as combinações possíveis. Mas realmente, como me parece, isso é inútil. Primeiro você precisa decidir sobre a plataforma e só então tentar extrair completamente tudo o que é possível.
Por que eu sou tudo isso? Além disso, o teste "
quanto tempo o MobileNet " é um teste muito ruim. Ele pode dizer que a plataforma X é ideal. Mas quando você tenta implantar seu neurônio e pós-processamento lá, pode ficar muito decepcionado.
Mas comparar o mobilnet'ov ainda fornece algumas informações sobre a plataforma. Para tarefas simples. Para situações em que você entende que de qualquer maneira é mais fácil reduzir a tarefa para abordagens padrão. Quando você deseja avaliar a velocidade da calculadora.
A tabela abaixo é retirada de vários lugares:
- Estes estudos são: 1 , 2 , 3
- Para SSD, existe esse parâmetro "número de classes de saída". E a partir deste parâmetro, a taxa de inferência pode variar bastante. Tentei escolher estudos com o mesmo número de aulas. Mas isso pode não ser o caso em todos os lugares.
- Nossa experiência com o TensorRT. Eu sabia que tipos funcionam e quais não.
- Para o gyrfalcon, esses vídeos são baseados no fato de que o mobilnet v2 existe + uma estimativa de quanto a área muda. Este vídeo diz que 2803 pode ser 3-4 vezes mais rápido. Mas para 2803 não há classificações de SSD. Em geral, eu duvido muito das velocidades neste momento.
- Tentei escolher o estudo que deu a velocidade máxima real (não peguei a versão da Nvidia sem o NMS, por exemplo)
- Para a Jetson TX2, usei essas classificações, mas existem 5 classes, no mesmo número de classes em que o restante será mais lento. De alguma forma, descobri pela experiência / comparação com o Nano nos núcleos o que deveria estar lá
- Não levei em conta piadas com taxa de bits. Não sei em que testemunha Movidius e Gyrfalcon trabalharam.
Como resultado, temos:

Comparação de plataformas
Vou tentar trazer tudo o que eu disse acima para uma única tabela. Eu destaquei em amarelo aqueles lugares onde meu conhecimento não é suficiente para chegar a uma conclusão inequívoca. E, na verdade, 1-6 - essa é uma avaliação comparativa das plataformas. Quanto mais próximo de 1, melhor.

Eu sei que o consumo de energia é crítico para muitos. Mas parece-me que tudo aqui é um tanto ambíguo, e eu entendo isso muito mal - então não entrei. Além disso, a própria ideologia parece ser a mesma em todos os lugares.
Etapa lateral
O que estávamos falando é apenas um pequeno ponto no vasto espaço de variações do seu sistema. Provavelmente as palavras comuns que podem caracterizar esta área:
- Baixo consumo de energia
- Tamanho pequeno
- Alto poder de computação
Porém, globalmente, se você reduzir a importância de um dos critérios, poderá adicionar muitos outros dispositivos à lista. Abaixo, vou abordar todas as abordagens que conheci.
Intel
Como dissemos quando discutimos o Movidius, a Intel possui uma plataforma OpenVino. Ele permite um processamento muito eficiente de neurônios nos processadores Intel. Além disso, a plataforma permite que você suporte até todos os tipos de intel-gpu em um chip. Agora, tenho medo de dizer exatamente que tipo de desempenho existe para quais tarefas. Mas, pelo que entendi, uma boa pedra com uma GPU a bordo bastante ⅓ fornece um desempenho de 1080. Para algumas tarefas, pode ser ainda mais rápido.

Nesse caso, o fator de forma, por exemplo, Intel NUC, é bastante compacto. Bom resfriamento, embalagem, etc. A velocidade será mais rápida que o Jetson TX2. Pela disponibilidade / facilidade de compra - muito mais fácil. A estabilidade da plataforma fora da caixa é maior.
Dois contras - consumo de energia e preço. O desenvolvimento é um pouco mais complicado.
Jetson agx

Este é outro jetson. Essencialmente a versão mais antiga. A velocidade é cerca de 2 vezes mais rápida que o Jetson TX2, além de haver suporte para cálculos int8, o que permite que você faça overclock por mais 4 vezes. A propósito, confira esta
foto da Nvidia:
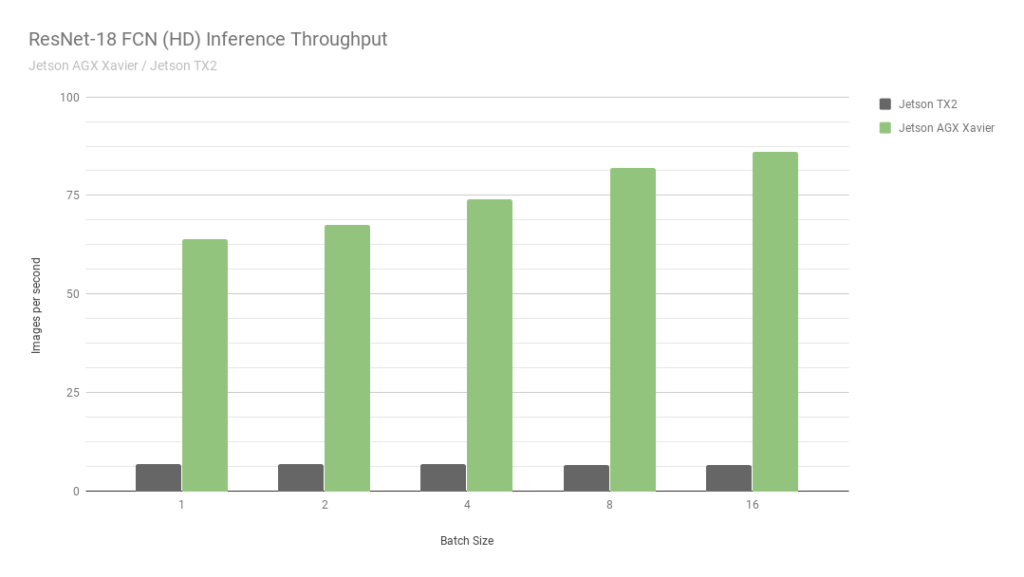
Eles comparam dois de seus próprios Jetson. Um no int8, o segundo no int32. Nem sei o que dizer aqui ... Em suma: "NUNCA ACREDITE NA NVIDIA GRAPHICS".
Apesar do fato de o AGX ser bom - ele não alcança as GPUs normais da Nvidia em termos de poder de computação. No entanto, em termos de eficiência energética - eles são muito legais. O principal menos o preço.
Nós mesmos não trabalhamos com eles, por isso é difícil para mim dizer algo mais detalhado, descrever a variedade de tarefas em que elas são as melhores.
Nvidia gpu versão para laptop
Se você remover a restrição estrita de consumo de energia, o Jetson TX2 não parecerá ideal. Como o AGX. Geralmente, as pessoas têm medo de usar a GPU na produção. Pagamento separado, tudo isso.
Mas existem milhões de empresas que oferecem a você montar uma solução personalizada em uma placa. Geralmente são placas para laptops / minicomputadores. Ou, no final, assim:

Uma das startups em que trabalho nos últimos 2,5 anos (
CherryHome )
seguiu esse caminho. E estamos muito satisfeitos.
Menos, como sempre, o consumo de energia, o que não foi crítico para nós. Bem, o preço morde um pouco.
Telemóveis
Não quero me aprofundar neste tópico. Para dizer tudo o que há nos telefones celulares modernos para neurônios / quais estruturas / quais hardwares etc., você precisará de mais de um artigo com esse tamanho. E, levando em conta o fato de que seguimos nessa direção apenas 2-3 vezes, considero-me incompetente para isso. Então, apenas algumas observações:
- Existem muitos aceleradores de hardware nos quais os neurônios podem ser otimizados.
- Não existe uma solução geral que corra bem em todos os lugares. Agora, há alguma tentativa de tornar o Tensorflow uma solução desse tipo. Mas, pelo que entendi, ainda não se tornou um.
- Alguns fabricantes têm suas próprias fazendas especiais. Ajudamos a otimizar a estrutura do Snapdragon há um ano. E foi terrível. A qualidade dos neurônios é muito menor do que em tudo que eu falei hoje. Não há suporte para 90% das camadas, mesmo as básicas, como "adição".
- Como não existe python, a inferência de redes é muito estranha, ilógica e inconveniente.
- Em termos de desempenho, acontece que tudo é muito bom (por exemplo, em alguns iphone).
Parece-me que para telefones celulares embutidos não é a melhor solução (a exceção é alguns sistemas de reconhecimento de rosto de baixo orçamento). Mas vi alguns casos quando eles foram usados como protótipos iniciais.
Gap8
Esteve recentemente em uma conferência de
Usedata . E um dos relatórios era sobre a inferência de neurônios nas porcentagens mais baratas (GAP8). E, como se costuma dizer, a necessidade de invenções é astuta. Na história, um exemplo foi muito rebuscado. Mas o autor contou como eles foram capazes de obter inferência pessoalmente em cerca de um segundo. Em uma grade muito simples, essencialmente sem detector. Por otimizações loucas e longas e economia em partidas.
Eu sempre não gosto de tais tarefas. Nenhuma pesquisa, apenas sangue.
Mas vale a pena reconhecer que posso imaginar quebra-cabeças em que porcentagens de baixo consumo fornecem um resultado interessante. Provavelmente não para reconhecimento facial. Mas em algum lugar onde você pode reconhecer a imagem de entrada em 5 a 10 segundos ...
Grove AI HAT

Enquanto preparava este artigo, me deparei com
essa plataforma incorporada. Há muito pouca informação sobre isso. Pelo que entendi, zero apoio. A produtividade também está em zero ... E nem um único teste de velocidade ...
Servidor / Reconhecimento Remoto
Toda vez que eles procuram nosso conselho em uma plataforma incorporada, eu quero gritar “corra, seus tolos!”. É necessário avaliar cuidadosamente a necessidade dessa solução. Confira outras opções. Eu sempre recomendo a todos que façam um protótipo com a arquitetura do servidor. E durante sua operação, você decide se deve implementar um verdadeiro embarcado. Afinal, incorporado é:
- Maior tempo de desenvolvimento, geralmente 2-3 vezes.
- Suporte sofisticado e depuração na produção. Qualquer desenvolvimento com ML é uma revisão constante, atualização de neurônios, atualizações do sistema. Incorporado ainda é mais difícil. Como recarregar o firmware? E se você já tem acesso a todas as unidades, por que calcular nelas quando pode calcular em um dispositivo?
- Complexidade do sistema / risco aumentado. Mais pontos de falha. Ao mesmo tempo, embora o sistema não funcione como um todo, pode-se não entender: a plataforma é adequada para esta tarefa?
- Aumento de preço. Uma coisa é colocar um quadro simples como o nano pi. E o outro é comprar TX2.
Sim, eu sei que existem tarefas em que as decisões do servidor não podem ser tomadas. Mas, curiosamente, eles são muito menores do que se costuma acreditar.
Conclusões
No artigo, tentei ficar sem conclusões óbvias. É mais uma história sobre o que é agora. Para tirar conclusões - é necessário investigar em cada caso. E não apenas plataformas. Mas a tarefa em si. Qualquer tarefa pode ser levemente simplificada / levemente modificada / levemente afiada sob o dispositivo.
O problema com este tópico é que o tópico está mudando. Novos dispositivos / estruturas / abordagens estão chegando. Por exemplo, se a NVIDIA ativar o suporte int8 ao Jetson Nano amanhã, a situação mudará drasticamente. Quando escrevo este artigo, não posso ter certeza de que as informações não foram alteradas há dois dias. Mas espero que meu conto o ajude a navegar melhor em seu próximo projeto.
Seria legal se você tiver informações adicionais / eu perdi algo / disse algo errado - escreva detalhes aqui.
ps
Já quando eu terminei de escrever o artigo quase,
snakers4 soltou um
post recente de seu canal de telegrama Spark em mim, que é quase o mesmo problema com Jetson. Mas, como escrevi acima, - nas condições de qualquer consumo de energia - eu colocaria algo como zotacs ou IntelNUC. E como o jetson incorporado não é a pior plataforma.
