Há cerca de um ano, meus colegas e eu fomos encarregados de resolver o problema usando o popular sistema de monitoramento de infraestrutura de rede - Zabbix. Após estudar a documentação, imediatamente procedemos ao teste de carregamento: queríamos avaliar quantos parâmetros o Zabbix pode funcionar sem quedas perceptíveis de desempenho. Somente o PostgreSQL foi usado como DBMS.
Durante os testes, foram identificados alguns recursos arquiteturais do layout do banco de dados e o comportamento do próprio sistema de monitoramento, que, por padrão, não permitem que o sistema de monitoramento alcance sua potência máxima. Como resultado, algumas medidas de otimização foram desenvolvidas, conduzidas e testadas principalmente em termos de ajuste do banco de dados.
Quero compartilhar os resultados do trabalho realizado neste artigo. Este artigo será útil para os administradores de Zabbix e PostgreSQL DBA, bem como para todos que desejam entender e entender melhor o popular DBMS PosgreSQL.
Um pequeno spoiler: em uma máquina fraca com uma carga de 200 mil parâmetros por minuto, conseguimos reduzir o iowait da CPU de 20% para 2%, reduzir o tempo de gravação em partes nas tabelas de dados primárias em 250 vezes e nas tabelas de dados agregadas em 32 vezes, reduzir o tamanho dos índices 5 a 10 vezes e acelere o recebimento de amostras históricas em alguns casos até 18 vezes.
Teste de carga
O teste de carga foi realizado de acordo com o esquema: um servidor Zabbix, um proxy Zabbix ativo, dois agentes. Cada agente foi configurado para fornecer 50 toneladas de números inteiros e 50 toneladas de parâmetros de sequência por minuto (um total de 200 toneladas de parâmetros por minuto ou 3333 parâmetros por segundo). Para gerar parâmetros do agente, usamos um
plug-in para o Zabbix.Para verificar quantos parâmetros um agente pode gerar, você precisa usar um
script especial do mesmo autor do plug-in zabbix_module_stress . O administrador da web do Zabbix tem dificuldades em registrar modelos grandes, portanto, dividimos os parâmetros em 20 modelos com 5 toneladas de parâmetros (2500 numérico e 2500 string).
Modelo de gerador de script para teste de carga em pythonimport argparse """ . 20 5000 ( 2500 : echo, ; ping, ) """ TEMP_HEAD = """ <?xml version="1.0" encoding="UTF-8"?> <zabbix_export> <version>2.0</version> <date>2015-08-17T23:15:01Z</date> <groups> <group> <name>Templates</name> </group> </groups> <templates> <template> <template>Template Zabbix Srv Stress {count} passive {char}</template> <name>Template Zabbix Srv Stress {count} passive {char}</name> <description/> <groups> <group> <name>Templates</name> </group> </groups> <applications/> <items> """ TEMP_END = """</items> <discovery_rules/> <macros/> <templates/> <screens/> </template> </templates> </zabbix_export> """ TEMP_ITEM = """<item> <name>{k}</name> <type>0</type> <snmp_community/> <multiplier>0</multiplier> <snmp_oid/> <key>{k}</key> <delay>1m</delay> <history>3</history> <trends>365</trends> <status>0</status> <value_type>{t}</value_type> <allowed_hosts/> <units/> <delta>0</delta> <snmpv3_contextname/> <snmpv3_securityname/> <snmpv3_securitylevel>0</snmpv3_securitylevel> <snmpv3_authprotocol>0</snmpv3_authprotocol> <snmpv3_authpassphrase/> <snmpv3_privprotocol>0</snmpv3_privprotocol> <snmpv3_privpassphrase/> <formula>1</formula> <delay_flex/> <params/> <ipmi_sensor/> <data_type>0</data_type> <authtype>0</authtype> <username/> <password/> <publickey/> <privatekey/> <port/> <description/> <inventory_link>0</inventory_link> <applications/> <valuemap/> <logtimefmt/> </item> """ TMP_FNAME_DEFAULT = "Template_App_Zabbix_Server_Stress_{count}_passive_{char}.xml" chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" if __name__ == "__main__": parser = argparse.ArgumentParser( description=' zabbix') parser.add_argument('--items', dest='items', type=int, default=1000, help='- (default: 1000)') parser.add_argument('--templates', dest='templates', type=int, default=1, help=f'- [1-{len(chars)}] (default: 1)') args = parser.parse_args() items_count = args.items tmps_count = args.templates if not (tmps_count >= 1 and tmps_count <= len(chars)): sys.exit(f"Templates must be in range 1 - {len(chars)}") for i in range(tmps_count): fname = TMP_FNAME_DEFAULT.format(count=items_count, char=chars[i]) with open(fname, "w") as output: output.write(TEMP_HEAD.format(count=items_count, char=chars[i])) for k,t in [('stress.ping[{}-I-{:06d}]',3), ('stress.echo[{}-S-{:06d}]',4)]: for j in range(int(items_count/2)): output.write(TEMP_ITEM.format(k=k.format(chars[i],j),t=t)) output.write(TEMP_END)
A métrica da CPU iostat é um bom indicador do desempenho do Zabbix - reflete a fração da unidade de tempo durante a qual o processador aguarda o acesso ao disco. Quanto mais alto, mais o disco é ocupado com operações de leitura e gravação, o que indiretamente afeta a degradação do desempenho do sistema de monitoramento como um todo. I.e. este é um sinal claro de que algo está errado com o monitoramento. A propósito, nos espaços abertos da rede, a pergunta bastante popular é “como remover o gatilho do iostat no Zabbix”, então esse é um ponto doloroso, porque existem muitas razões para aumentar o valor da métrica iowait.
Aqui está a imagem para a métrica da CPU iowait que recebemos três dias depois inicialmente:
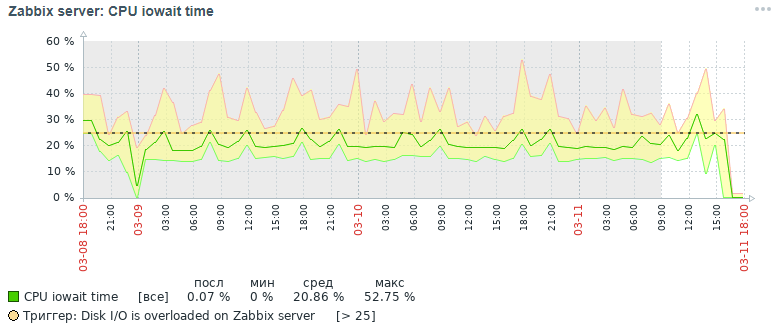
Mas que quadro para a mesma métrica também obtivemos dentro de três dias no final, depois de todas as medidas de otimização que foram feitas, que serão discutidas abaixo:
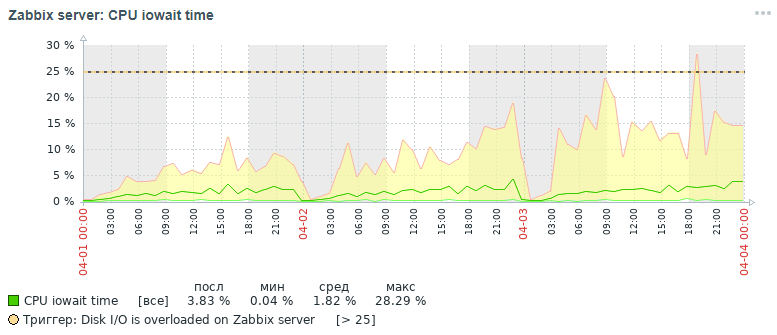
Como pode ser visto nos gráficos, o indicador cpu iowait caiu de quase 20% para 2%, o que indiretamente acelerou o tempo de execução de todas as solicitações de adição e leitura de dados. Agora vamos ver por que, com as configurações padrão do banco de dados, o desempenho geral do sistema de monitoramento diminui e como corrigi-lo.
Razões para a queda no desempenho do Zabbix
Com o acúmulo de mais de 10 milhões de valores de parâmetros em cada tabela de dados primários, percebeu-se que o desempenho do sistema de monitoramento cai acentuadamente, devido aos seguintes motivos:
- a métrica iowait para a CPU do servidor é aumentada em mais de 20%, o que indica um aumento no tempo durante o qual a CPU espera acessar as operações de leitura e gravação de disco
- índices de tabelas nas quais os dados de monitoramento são bastante inflados
- a métrica de utilização é aumentada para 100% para um disco com dados de monitoramento, o que indica a carga completa do disco com operações de leitura e gravação
- valores obsoletos não têm tempo para serem excluídos das tabelas de histórico ao serem limpos de acordo com a programação da governanta
A situação é agravada no início de cada hora, quando, além disso, são calculadas estatísticas horárias agregadas - ao mesmo tempo, é realizada a leitura e gravação ativas das páginas de índice do disco, a exclusão de dados desatualizados do histórico, o que leva ao mesmo resultado - uma queda no desempenho do banco de dados e um aumento no tempo de execução pedidos (no limite, um pedido com duração de até 5 minutos foi anotado!).
Uma pequena ajuda na organização de um data warehouse de monitoramento no Zabbix. Além disso, armazena dados primários e dados agregados em diferentes tabelas, com a separação dos tipos de parâmetros. Cada tabela armazena um campo itemid (uma referência implícita a um item de dados registrado no sistema), um registro de data e hora para registrar o valor do relógio no formato de registro de data e hora unix (milissegundos em uma coluna separada) e um valor em uma coluna separada (a exceção é a tabela de log, possui mais campos - semelhante ao log de eventos ):
Atividades de otimização
Para melhorar o desempenho do banco de dados PostgreSQL, várias medidas de otimização foram realizadas, as principais das quais são particionamento e alteração de índices. No entanto, vale mencionar algumas palavras sobre algumas medidas importantes e úteis que podem acelerar o trabalho de qualquer banco de dados no sistema de gerenciamento de banco de dados PostgreSQL.
Nota importante. No momento da coleta do material do artigo, usamos o Zabbix versão 4.0, embora a versão 4.2 já tenha sido lançada e a versão 4.4 esteja sendo preparada para a liberação. Por que é importante mencionar isso? Como a partir da versão 4.2, o Zabbix começou a oferecer suporte a uma extensão poderosa especial para trabalhar com séries temporais do TimescaleDB, mas até agora no modo experimental: para todas as vantagens de usar essa extensão, acredita-se que algumas solicitações começaram a funcionar mais lentamente e ainda existem problemas de desempenho não resolvidos (haverá resolvido na versão 4.4) -
leia este artigo .
No próximo artigo, pretendo escrever sobre os resultados dos testes de carga já usando a extensão TimescaleDB em comparação com este caso de solução. A versão do PostgreSQL foi usada 10, mas todas as informações fornecidas são relevantes para as versões 11 e 12 (estamos aguardando!).
Portanto, as primeiras coisas primeiro:
- configurando um arquivo de configuração usando o utilitário pgtune
- colocando o banco de dados em um disco físico separado
- Particionando Tabelas de Histórico com pg_pathman
- alterando tipos de índice de tabelas de histórico para brin (clock) e btree-gin (itemid)
- coleta e análise de estatísticas de execução de consultas pg_stat_statements
- definindo parâmetros de monitoramento de disco físico
- melhoria de desempenho de hardware
- criação de um cluster distribuído (material fora do escopo deste artigo)
Configurando um arquivo de configuração usando o utilitário pgtune
De fato, o PostgreSQL é um DBMS bastante leve. Seu arquivo de configuração padrão é configurado para que, como diz meu colega, "trabalhe até na máquina de café", ou seja, em um ferro muito modesto. Portanto, é necessário configurar o PostgreSQL para a configuração do servidor, levando em consideração a quantidade de memória, o número de processadores, o tipo de uso pretendido do banco de dados, o tipo de disco (HDD ou SSD) e o número de conexões.
Infelizmente, não existe uma fórmula única para ajustar todos os DBMSs, mas existem certas regras e padrões que são adequados para a maioria das configurações (o ajuste mais fino já é o trabalho de um especialista). Para simplificar a vida do DBA, foi escrito o utilitário
pgtune , que foi complementado pela
versão web por
le0pard , autor de um livro interessante e útil sobre administração do PostgreSQL.
Um exemplo de execução do utilitário no console com 100 conexões (o Zabbix possui um administrador da Web exigente) para o tipo de aplicativo "Data warehouses":
pgtune -i postgresql.conf -o new_postgresql.conf -T DW -c 100
Os parâmetros de configuração que o utilitário pgtune altera com uma descrição da finalidade (os valores são fornecidos como exemplo) # DB Version: 11
# Tipo de SO: linux
# Tipo de banco de dados: web
# Memória total (RAM): 8 GB
# CPUs num: 1
# Conexões num: 100
# Armazenamento de dados: hdd
max_connections = 100 # número máximo de conexões simultâneas com o banco de dados
shared_buffers = tamanho de memória de 2 GB # para vários buffers (principalmente cache de blocos de tabela e de índice) na memória compartilhada
effective_cache_size = 6GB # tamanho máximo de memória necessária para execução da consulta usando índices
maintenance_work_mem = 512MB # afeta a velocidade das operações VACUUM, ANALYZE, CREATE INDEX
checkpoint_completion_target = 0.7 # hora prevista para concluir o procedimento do ponto de verificação
wal_buffers = 16MB # quantidade de memória usada pela memória compartilhada para manter os logs de transações
default_statistics_target = 100 # quantidade de estatísticas coletadas pelo comando ANALYZE - ao aumentar, o otimizador cria consultas mais lentamente, mas melhor
random_page_cost = 4 # custo condicional do acesso do índice às páginas de dados - afeta a decisão de usar o índice
effective_io_concurrency = 2 # número de operações de E / S assíncronas que o DBMS tentará executar em uma sessão separada
work_mem = 10485kB # a quantidade de memória usada para classificação e tabelas de hash antes de usar arquivos temporários no disco
min_wal_size = 1GB # limites abaixo do número de arquivos WAL que serão reciclados para uso futuro
max_wal_size = 2GB # limita no topo o número de arquivos WAL que serão reciclados para uso futuro
Algumas opções úteis de configuração do postgresql # gerenciamento de manipuladores de solicitação simultâneos
max_worker_processes = 8 # o número máximo de processos em segundo plano - pelo menos um por banco de dados
max_parallel_workers_per_gather = 4 # número máximo de processos paralelos em uma única solicitação
max_parallel_workers = 8 # o número máximo de processos de trabalho que o sistema pode suportar para operações paralelas
# logging settings (uma maneira fácil de descobrir o tempo de execução das solicitações sem usar a extensão pg_stat_statements)
log_min_duration_statement = 3000 # grava nos logs a duração da execução de todos os comandos cujo tempo de operação> = do valor especificado em ms
log_duration = off # registra a duração de cada comando concluído
log_statement = 'none' # qual comando SQL deve ser gravado no log, valores: none (desativado), ddl, mod e all (todos os comandos)
debug_print_plan = off # saída da árvore do plano de consulta para análise posterior
# extrair o máximo do banco de dados e estar pronto para obtê-lo por qualquer falha (para os mais reprimidos, que ignoram a existência de ssd e um cluster distribuído)
#fsync = off # gravação física no disco de alterações, desativar o fsync aumenta a velocidade, mas pode levar a falhas permanentes
#synchronous_commit = off # permite que você responda ao cliente antes mesmo de as informações da transação estarem no WAL - uma alternativa quase segura para desativar o fsync
#full_page_writes = off # shutdown acelera as operações normais, mas pode causar corrupção ou corrupção de dados se o sistema travar
Listando um banco de dados em um disco físico separado
Esse item é opcional e, em vez disso, é uma solução de transição para um cluster distribuído completo, mas será útil conhecer essa possibilidade. Para acelerar o banco de dados, você pode colocá-lo em um disco separado. Montamos o disco inteiro no diretório base, onde todos os bancos de dados PostgreSQL são armazenados, mas em geral isso pode ser feito de maneira diferente: crie uma nova base de tabelas e transfira o banco de dados (ou apenas parte dela - as tabelas de dados de monitoramento primário e agregado) para essa base de tabelas em um disco separado.
Exemplo de montagemPrimeiro, você precisa formatar o disco com o sistema de arquivos ext4 e conectá-lo ao servidor. Monte o disco para o banco de dados com o rótulo noatime:
mount / dev / sdc1 / var / lib / pgsql / 10 / data / base -o noatime
Para montagem permanente, adicione a linha ao arquivo / etc / fstab:
# onde UUID é o identificador do disco, você pode vê-lo usando o utilitário blkid
UUID = 121efe29-70bf-410b-bc71-90704568ce3b / var / lib / pgsql / 10 / data / banco de dados ext4 padrões, noatime 0 0
Particionando tabelas de histórico com pg_pathman
Um dos problemas que encontramos durante o teste de estresse do Zabbix - PostgreSQL não consegue excluir dados obsoletos do banco de dados. Usando o particionamento, é possível dividir a tabela em suas partes constituintes, reduzindo assim o tamanho dos índices e partes constituintes da supertabela, o que afeta positivamente a velocidade do banco de dados como um todo.
O particionamento resolve dois problemas ao mesmo tempo:
1. acelere a remoção de dados obsoletos excluindo tabelas inteiras
2. índices de divisão para cada tabela composta
Existem quatro mecanismos para particionar no PostgreSQL:
1. restrição_exclusão padrão
2. extensão pg_partman (
não confunda com pg_pathman )
3. extensão
pg_pathman4. criar e manter manualmente partições por nós mesmos
A solução de particionamento mais conveniente, confiável e otimizada, em nossa opinião, é a extensão
pg_pathman . Com esse método de particionamento, o planejador de consultas determina de maneira flexível em quais partições procurar dados.
Há rumores de que na 12ª versão do PostgreSQL haverá uma excelente partição já pronta para uso.Assim, começamos a escrever dados de monitoramento para cada dia em uma tabela herdada separada da supertabela e a remoção de valores de parâmetros obsoletos começou a ocorrer através da remoção de todas as tabelas obsoletas de uma só vez, o que é muito mais fácil para um DBMS para custos de mão-de-obra. A exclusão foi feita chamando a função de usuário do banco de dados como um parâmetro de monitoramento do servidor Zabbix às 2 da manhã, com uma indicação do intervalo aceitável de armazenamento de estatísticas.
Instale e configure o particionamento para o PostgreSQL 10Instale e configure a extensão
pg_pathman a partir do repositório OS padrão (para obter instruções sobre como construir a versão mais recente da extensão a partir das fontes, procure no mesmo repositório no github):
yum install pg_pathman10
nano /var/pgsqldb/postgresql.conf
shared_preload_libraries = 'pg_pathman' # important - escreva aqui pg_pathman por último na lista
Reinicializamos o DBMS, criamos a extensão para o banco de dados e configuramos o particionamento (1 dia para os dados primários de monitoramento e 3 dias para os dados de monitoramento agregados - isso pode ser feito por 1 dia):
systemctl restart postgresql-10.service
psql -d zabbix -U postgres
CRIAR EXTENSÃO pg_pathman;
# configure um dia para as tabelas de dados de monitoramento primário
# 1552424400 - contagem regressiva como carimbo de data e hora unix, 86400 - segundos em dias
selecione create_range_partitions ('history', 'clock', 1552424400, 86400);
selecione create_range_partitions ('history_uint', 'clock', 1552424400, 86400);
selecione create_range_partitions ('history_text', 'clock', 1552424400, 86400);
selecione create_range_partitions ('history_str', 'clock', 1552424400, 86400);
selecione create_range_partitions ('history_log', 'clock', 1552424400, 86400);
# configure por três dias para tabelas de dados de monitoramento agregadas
# 1552424400 - contagem regressiva como carimbo de data e hora unix, 259200 - segundos em três dias
selecione create_range_partitions ('tendências', 'relógio', 1545771600, 259200);
selecione create_range_partitions ('trends_uint', 'clock', 1545771600, 259200);
Se ainda não houver dados em nenhuma das tabelas, ao chamar a função create_range_partitions, mais um argumento adicional p_count = 0_ deve ser passado.Consultas úteis para monitorar e gerenciar partições:
# lista geral de tabelas particionadas, armazenamento de configuração principal:
selecione * em pathman_config;
# representação com todas as seções existentes, assim como seus pais e limites de intervalo:
selecione * em pathman_partition_list;
# parâmetros adicionais que substituem o comportamento padrão do pg_pathman:
selecione * em pathman_config_params;
# copie o conteúdo de volta para a tabela pai e exclua as partições:
selecione drop_partitions ('table_name' :: regclass, false);
Script útil para visualizar estatísticas sobre o número e tamanho das partições:
SELECT nspname AS schemaname, relname, relkind, cast (reltuples as int), pg_size_pretty(pg_relation_size(C.oid)) AS "size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') and (relname like 'history%' or relname like 'trends%') and relkind = 'r'
Ajuste automático da exclusão de partições obsoletas (ahtung - uma grande função SQL)Para configurar a exclusão automática de partições, você precisa criar uma função no banco de dados
(texto amplo, removi o realce da sintaxe):
CRIAR OU SUBSTITUIR FUNÇÃO public.delete_old_partitions (history_days inteiro, trends_days inteiro, str_days inteiro)
DEVOLUÇÃO texto
LANGUAGE plpgsql
Função $ AS $
/ *
A função exclui todas as partições anteriores ao número de dias especificado:
history_days - para partições history_x, history_uint_x
trends_days - para partições trends_x, trends_uint_x
str_days - para partições history_str_x, history_text_x, history_log_x
* /
declarar clock_today_start int;
declarar clock_delete_less_history int = 0;
declarar clock_delete_less_trends int = 0;
declarar clock_delete_less_strings int = 0;
clock_delete_less int = 0;
declarar iterador int = 0;
declarar result_str text = '';
declare buf_table_size text;
declarar buf_table_len text;
declarar texto nome_da_partição;
declare clock_max text;
declarar texto err_detail;
declarar t_start timestamp = clock_timestamp ();
declarar t_end timestamp;
começar
se $ 1 <= 0 retornar 'ups, algo errado: o argumento history_days deve ser um valor inteiro positivo'; fim se;
se $ 2 <= 0 retornar 'ups, algo errado: o argumento trends_days deve ser um valor inteiro positivo'; fim se;
se $ 3 <= 0 retornar 'ups, algo errado: o argumento str_days deve ser um valor inteiro positivo'; fim se;
clock_today_start = extract (época de date_trunc ('dia', agora ())) :: int;
clock_delete_less_history = extract (época de date_trunc ('dia', agora ()) - ($ 1 :: texto || 'dias') :: intervalo) :: int;
clock_delete_less_trends = extract (época de date_trunc ('dia', agora ()) - ($ 2 :: texto || 'dias') :: intervalo) :: int;
clock_delete_less_strings = extract (época de date_trunc ('dia', agora ()) - ($ 3 :: texto || 'dias') :: intervalo) :: int;
clock_delete_less = menos (clock_delete_less_history, clock_delete_less_trends, clock_delete_less_strings);
- aviso de aumento 'clock_today_start% (%)', to_timestamp (clock_today_start), clock_today_start;
- aviso de aumento 'clock_delete_less_history% (%)% days', to_timestamp (clock_delete_less_history), clock_delete_less_history, $ 1;
- aviso de aumento 'clock_delete_less_trends% (%)% days', to_timestamp (clock_delete_less_trends), clock_delete_less_trends, $ 2;
- aviso de aumento 'clock_delete_less_strings% (%)% days', to_timestamp (clock_delete_less_strings), clock_delete_less_strings, $ 3;
para partition_name, clock_max na partição selecionada, range_max de pathman_partition_list em que
range_max :: int <= greatest (clock_delete_less_history, clock_delete_less_trends, clock_delete_less_strings) e
(partition :: texto como 'history%' ou partition :: texto como 'trends%') ordene pela partição asc
laço
if (nome da partição ~ 'history_uint_ \ d' e clock_max :: int <= clock_delete_less_history)
ou (partition_name ~ 'history_ \ d' e clock_max :: int <= clock_delete_less_history)
ou (partition_name ~ 'trends_ \ d' e clock_max :: int <= clock_delete_less_trends)
ou (partition_name ~ 'history_log_ \ d' e clock_max :: int <= clock_delete_less_strings)
ou (partition_name ~ 'history_str_ \ d' e clock_max :: int <= clock_delete_less_strings)
ou (partition_name ~ 'history_text_ \ d' e clock_max :: int <= clock_delete_less_strings)
então
iterador = iterador + 1;
aumentar aviso '%', formato ('!!! excluir% s% s', nome da partição, clock_max);
selecione max (reltuples :: int), pg_size_pretty (sum (pg_relation_size (pg_class.oid)))) como "tamanho" de pg_class, em que relname como partition_name || '%' em estrito buf_table_len, buf_table_size;
if result_str! = '' então result_str = result_str || ','; fim se;
result_str = result_str || formato ('% s (dt <% s, len% s,% s)', nome_da_partição, to_char (to_timestamp (clock_max :: int), 'AAAA-MM-DD'), buf_table_len, buf_table_size);
executar formato ('soltar tabela se existir% s', nome_da_partição);
fim se;
loop final;
se iterador = 0 então result_str = format ('não há partições para excluir mais antigas, então% s data', to_char (to_timestamp (clock_delete_less), 'YYYY-MM-DD'));
else result_str = formato ('% s excluídas partições em% s segundos:', iterador, trunc (extract (segundos de (clock_timestamp () - t_start)) :: numeric, 3)) || result_str;
fim se;
- aviso de aumento '%', result_str;
retornar result_str;
exceção quando outros
obter diagnósticos empilhados err_detail = PG_EXCEPTION_CONTEXT;
formato de retorno ('ups, algo errado:% s [código de erro% s],% s', sqlerrm, sqlstate, err_detail);
fim;
$ função $;
Para chamar automaticamente a função de partição de limpeza automática, você precisa criar um item de dados para o host do servidor zabbix do tipo "Database Monitor" com as seguintes configurações:
- tipo: monitor de banco de dados
- nome: delete_old_history_partitions
- chave: db.odbc.select [delete_old_history_partitions, zabbix]
- expressão sql: selecione delete_old_partitions (3, 30, 30);
# aqui, os parâmetros da chamada da função delete_old_partitions indicam o tempo de armazenamento em dias
# para valores numéricos, valores numéricos agregados e valores de sequência
- tipo de dados: texto
- intervalo de atualização: 0
- intervalo do usuário: agendado em h2
- período de armazenamento histórico: 90 dias
- grupo de elementos de dados: banco de dados
Como resultado, obteremos estatísticas sobre a limpeza de partições aproximadamente do seguinte tipo:
2019-09-16 02:00:00, excluído 3 partições em 0,024 segundos: trends_78 (dt <2019-08-17, len 1, 48 kB), history_193 (dt <2019-09-13, len 85343, 9448 kB ), history_uint_186 (dt <2019-09-13, len 27969, 3480 kB)
Importante! Após configurar a exclusão automática de partições através do elemento de dados e da função do usuário, é necessário desativar o histórico e a limpeza de tendências no agendador de tarefas do Zabbix:
através do item de menu do zabbix, selecione "Administração" -> "Geral" -> selecione "Limpar histórico" na lista no canto -> desativar todas as caixas de seleção nas seções "Histórico" e "Dinâmica das alterações". Alterando tipos de índice de tabelas de histórico para brin (clock) e btree-gin (itemid)
Agradecimentos especiais a
erogov pela
excelente série de artigos sobre os índices do PostgreSQL .
E de fato toda a equipe do PostgresPRO. .
, btree(itemid, clock) — , , «» , — 10 .
, , .: brin clock btree-gin itemid .
brin , - , .. . btree-gin — gin , btree .. gin , . btree-gin PostgreSQL.
Zabbix . :
Para avaliar os resultados, três tipos de consultas foram realizadas:- para um parâmetro específico itemid data do último mês, de fato os últimos três dias (total de 1660 registros)
explicar analisar selecionar * do history_uint em que itemid = 313300
and clock> = extract (época de '2019-03-09 00:00:00' :: timestamp) :: int
e clock <= extract (época de '2019-04-09 12:00:00' :: timestamp) :: int;
- para um dado de parâmetro específico por 12 horas de um dia (649 entradas no total)
explicar analisar selecionar * do histórico_texto em que itemid = 310650
and clock> = extract (época de '2019-04-09 00:00:00' :: timestamp) :: int
e clock <= extract (época de '2019-04-09 12:00:00' :: timestamp) :: int;
- para um dado de parâmetro específico por uma hora (61 registros no total):
explicar analisar contar contagem (*) de history_text em que itemid = 336540
and clock> = extract (época de '2019-04-08 11:00:00' :: timestamp) :: int
e clock <= extract (época de '2019-04-08 12:00:00' :: timestamp) :: int;
Os resultados dos testes foram tabulados abaixo:*
** 1 — 3 , 2 — 12 , 3 —
, 100 , btree brin btree-gin .
history_uint trends_uint ( 2000 ).
zabbix , zabbix , 10 . «» btree — ( utilization), CPU ( iowait).
, para que o índice btree-gin possa trabalhar com o tipo de dados bigint (in8), que é a coluna itemid, é necessário registrar uma família de operadores bigint para o índice btree-gin.Registrando uma família de operadores bigint para o índice btree-gin/*
gin biginteger integer .
- gin int2, int4, int8,
bigint , bigint (<= 2147483647)
intger_ops, :
create index on tablename using gin(columnname int8_family_ops) with (fastupdate = false);
*/
-- btree_gin
CREATE EXTENSION btree_gin;
CREATE OPERATOR FAMILY integer_ops using gin;
CREATE OPERATOR CLASS int4_family_ops
FOR TYPE int4 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint4cmp(int4,int4),
FUNCTION 2 gin_extract_value_int4(int4, internal),
FUNCTION 3 gin_extract_query_int4(int4, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int4(int4,int4,int2, internal),
STORAGE int4;
CREATE OPERATOR CLASS int8_family_ops
FOR TYPE int8 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint8cmp(int8,int8),
FUNCTION 2 gin_extract_value_int8(int8, internal),
FUNCTION 3 gin_extract_query_int8(int8, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int8(int8,int8,int2, internal),
STORAGE int8;
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int4,int8),
OPERATOR 2 <=(int4,int8),
OPERATOR 3 =(int4,int8),
OPERATOR 4 >=(int4,int8),
OPERATOR 5 >(int4,int8);
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int8,int4),
OPERATOR 2 <=(int8,int4),
OPERATOR 3 =(int8,int4),
OPERATOR 4 >=(int8,int4),
OPERATOR 5 >(int8,int4);
Este script redistribui todos os índices no banco de dados PostgreSQL para Zabbix da configuração padrão para a configuração ideal descrita acima./*
*/
--
drop index history_1;
drop index history_uint_1;
drop index history_str_1;
drop index history_text_1;
drop index history_log_1;
-- PK
-- ( , )
alter table trends drop constraint trends_pk;
alter table trends_uint drop constraint trends_uint_pk;
-- bree-gin itemid
-- btree-gin bigint
-- https://habr.com/ru/company/postgrespro/blog/340978/#comment_10545932
-- create extension btree_gin;
create index on history using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_uint using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_str using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_text using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_log using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends_uint using gin(itemid int8_family_ops) with (fastupdate = false);
-- bree-gin itemid
-- brin 128 ,
-- ,
-- https://habr.com/ru/company/postgrespro/blog/346460/
create index on history using brin(clock) with (pages_per_range = 128);
create index on history_uint using brin(clock) with (pages_per_range = 128);
create index on history_str using brin(clock) with (pages_per_range = 128);
create index on history_text using brin(clock) with (pages_per_range = 128);
create index on history_log using brin(clock) with (pages_per_range = 128);
create index on trends using brin(clock) with (pages_per_range = 128);
create index on trends_uint using brin(clock) with (pages_per_range = 128);
brin 100 . (100 . history 100 . history_uint) , 512 , 128 , . brin , - , , .
, , Zabbix: « » . . , . , history btree(itemid, clock desc) , «» , , .
:
- « » 100 (.. , « » )
- Zabbix , , « »
- , , « » ( , web- Zabbix « » — , 5000 , web- ).
pg_stat_statements
Pg_stat_statements — . , PostgreSQL.
pg_stat_statementspsql:
CREATE EXTENSION pg_stat_statements;
postgresql.conf:
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.max = 10000 # sql , ( );
pg_stat_statements.track = all # all - ( ), top - /, none -
pg_stat_statements.save = true #
:
SELECT pg_stat_statements_reset();
:
select substring(query from '[^(]*') as query_sub, sum(calls) as calls, avg(mean_time) as mean_time from pg_stat_statements where query ~ 'insert into' or query ~ 'update trends' group by substring(query from '[^(]*') order by calls desc
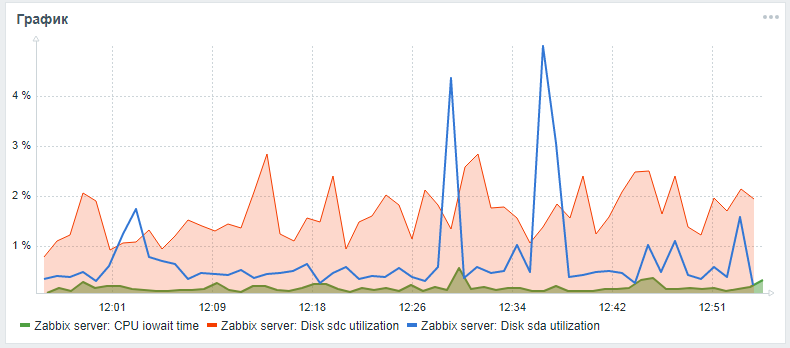
Zabbix vfs.dev.read vfs.dev.write. . utilization, await .
iowait cpu sql , zabbix . ,
lesovsky : iostat json , .
Pull request ,
fork .
Zabbix iowait cpu utiliztion ( ). (sda — , sdc — ):
 Depois de configurar o DBMS, a indexação e o particionamento, você pode prosseguir para a escala vertical - para melhorar as características de hardware do servidor: adicione RAM, altere as unidades para estado sólido e adicione núcleos de processador. Esse é um aumento de desempenho garantido, mas é melhor fazer isso somente após a otimização do software.
Depois de configurar o DBMS, a indexação e o particionamento, você pode prosseguir para a escala vertical - para melhorar as características de hardware do servidor: adicione RAM, altere as unidades para estado sólido e adicione núcleos de processador. Esse é um aumento de desempenho garantido, mas é melhor fazer isso somente após a otimização do software.Criando um cluster distribuído
— : , -.
( ) , Zabbix pg_pathman TimescaleDB.
, !