Como saber com certeza o que está dentro do pão?
Talvez você engula, e dentro dele há um rio? © Tanya Zadorozhnaya
O que é Data Science hoje, ao que parece, não apenas as crianças, mas também os animais de estimação sabem. Pergunte a qualquer gato, e ele dirá: estatística, Python, R, BigData, aprendizado de máquina, visualização e muitas outras palavras, dependendo das qualificações. Mas nem todos os gatos, assim como aqueles que desejam se tornar um especialista em Ciência de Dados, sabem exatamente como o projeto de Ciência de Dados está estruturado, em que estágios ele consiste e como cada um deles afeta o resultado final, o uso intensivo de recursos de cada estágio do projeto. A metodologia é geralmente usada para responder a essas perguntas. No entanto, a maioria dos cursos de treinamento dedicados à Ciência de Dados não diz nada sobre a metodologia, mas simplesmente revela mais ou menos consistentemente a essência das tecnologias mencionadas acima, e todo iniciante do Data Scientist conhece a estrutura do projeto a partir de sua própria experiência (e rake). Mas, pessoalmente, gosto de ir à floresta com um mapa e uma bússola, e gosto de imaginar antecipadamente o plano da rota que você está movendo. Após algumas pesquisas, consegui encontrar uma boa metodologia da IBM, um conhecido fabricante de guias e métodos para gerenciar qualquer coisa.
Portanto, no projeto Data Science, existem 3 blocos de 3 estágios em cada um, totalizando 9 estágios. Em resumo, o projeto consiste em trabalhar com requisitos de negócios, dados e o próprio modelo.
Trabalhar com requisitos de negócios
Nesta etapa, não sabemos nada sobre quais dados temos. Devemos nos aprofundar na declaração do problema, entender o resultado necessário para obter o projeto, aprender tudo sobre os participantes e as partes interessadas. Além disso, de acordo com uma tarefa específica, devemos decidir por qual método o problema será resolvido. O resultado desta etapa serão os requisitos de dados: ok, a tarefa é clara, o método foi escolhido, agora vamos pensar no que precisamos para uma solução bem-sucedida?
Trabalhar com dados
Na segunda etapa, começamos a procurar dados para resolver o problema: descobrimos quais fontes estão disponíveis para nós e formamos uma amostra com a qual continuaremos trabalhando. Após a coleta dos dados, é necessário realizar uma série de estudos para entender melhor como a amostra está organizada: investigar a posição central e a variabilidade, identificar correlações entre as características e construir gráficos de distribuição. Após esta etapa, você pode começar a preparar os dados. Como regra, esse estágio é o mais demorado e pode levar até 90% de todo o tempo do projeto, mas o sucesso de todo o projeto depende de quão bem ele é concluído.
Desenvolvimento e implementação
Finalmente, o terceiro passo. Quando os dados estiverem prontos, você poderá prosseguir com o desenvolvimento e a implementação reais. Programamos o modelo, configuramos na amostra de treinamento, verificamos no teste, se o resultado for satisfatório, depois demonstramos ao cliente, implementamos, montamos o feedback e ... você pode começar tudo de novo.
Todo o processo é apresentado na forma de um círculo vicioso: em um bom sentido, um projeto de DS nunca pode ser considerado finalizado (aproximadamente, como um reparo, que, como você sabe, não pode ser concluído, mas só pode ser interrompido):
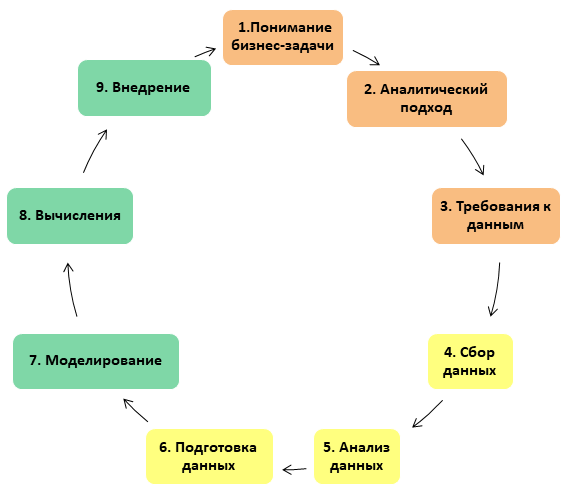
Vamos entrar em mais detalhes em cada uma das etapas.
1. Compreendendo o desafio comercial
Esse estágio é a base de todo trabalho subsequente: sem ele você não pode construir nada. É necessário definir claramente o objetivo do estudo: qual é o problema? Por que o problema deve ser resolvido? Quem é afetado pelo problema? Quais são as alternativas? E o mais importante: por quais métricas o sucesso do projeto será medido?
Em outras palavras, é necessário identificar claramente o objetivo do cliente. Por exemplo, o proprietário de uma empresa pergunta: podemos reduzir o custo de uma determinada atividade? Precisa esclarecer: o objetivo é aumentar a eficácia dessa atividade? Ou aumentar a receita comercial?
Uma vez definido o objetivo, você pode prosseguir para a próxima etapa.
2. A abordagem analítica
Agora você precisa escolher uma abordagem analítica para resolver um problema de negócios. A escolha da abordagem depende do tipo de resposta que você precisa obter no final: se a resposta for sim / não, um classificador Bayes ingênuo é adequado. Se você precisar de uma resposta na forma de um sinal numérico, os modelos de regressão são adequados. As árvores de decisão podem lidar com dados numéricos e categóricos. Se a questão é determinar as probabilidades de certos resultados, é necessário usar um modelo preditivo. Se os links precisarem ser identificados, uma abordagem descritiva será usada.
3. Requisitos de dados
Quando o objetivo do estudo é claramente definido e a abordagem é escolhida, ou seja, entendemos claramente que tipo de resposta à pergunta que estamos procurando, é necessário determinar quais dados nos permitirão dar a resposta desejada. Devemos preparar requisitos de dados: conteúdo, formatos e fontes que serão usados na próxima etapa do projeto.
4. Coleta de dados
Nesta fase, coletamos dados das fontes disponíveis: garantimos que as fontes estejam disponíveis, sejam confiáveis e possam ser usadas para obter os dados necessários na qualidade exigida. Após a coleta inicial de dados, é necessário entender se recebemos os dados que desejávamos. Nesse estágio, você pode revisar os requisitos de dados e tomar decisões sobre a necessidade de dados adicionais (ou seja, é provável que você precise retornar ao estágio 3). Lacunas podem ser identificadas nos dados e um plano pode ser elaborado sobre como fechá-las ou encontrar uma substituição.
5. Análise de Dados
A análise dos dados inclui todo o trabalho de projeto de amostragem. Nesta fase, é necessário obter uma resposta para a pergunta: os dados coletados são representativos da tarefa?
Aqui precisamos de estatística descritiva. Aplica-se a todas as variáveis que serão usadas no modelo selecionado: a posição central (média, mediana, modo) é examinada, são pesquisados os outliers e estimada a variabilidade (como regra, essa é a magnitude, variação e desvio padrão). Histogramas da distribuição de variáveis também são construídos. Os histogramas são uma boa ferramenta para entender como os valores dos dados são distribuídos e que tipo de preparação é necessária para que a variável seja mais útil na construção de um modelo. Outras ferramentas de visualização, como caixas de bigode, também podem ser úteis.
Em seguida, são realizadas comparações aos pares: as correlações entre as variáveis são calculadas para determinar quais delas estão relacionadas e quanto. Se houver correlações significativas entre as variáveis, algumas delas podem ser descartadas como redundantes.
6. Preparação de dados
Juntamente com a coleta e análise de dados, a preparação de dados é uma das atividades que mais consomem recursos do projeto: essas fases podem levar 70, ou mesmo 90% do tempo do projeto. Nesse estágio, processamos os dados de maneira conveniente: exclua duplicatas, processe dados ausentes ou incorretos, verifique e, se necessário, corrija os erros de formatação.
Também nesta fase, estamos construindo um conjunto de fatores com os quais o aprendizado de máquina funcionará nas próximas etapas: extraímos e selecionamos recursos que potencialmente ajudarão a resolver um problema de negócios. Os erros nesse estágio podem vir a ser críticos para todo o projeto, portanto, vale a pena prestar uma atenção especial a ele: um número excessivo de atributos pode levar à reciclagem do modelo e insuficiente para a falta de treinamento do modelo.
7. Construindo um modelo
A escolha do modelo, como você pode ver, é realizada no início do trabalho e depende da tarefa do negócio. Assim, quando o tipo de modelo é determinado e há uma amostra de treinamento, o analista desenvolve o modelo e verifica como ele funciona no conjunto de recursos criados na etapa 6.
8. Aplicação do modelo
A aplicação do modelo está intimamente ligada à construção real do modelo: os cálculos se alternam com a configuração do modelo. Nesse estágio, devemos responder à pergunta se o modelo construído atende à tarefa de negócios.
O cálculo do modelo possui duas fases: são realizadas medições de diagnóstico que ajudam a entender se o modelo funciona como pretendido. Se um modelo preditivo for usado, uma árvore de decisão poderá ser usada para entender que a saída do modelo corresponde ao plano original. Na segunda fase, a significância estatística da hipótese é verificada. É necessário garantir que os dados no modelo sejam usados e interpretados corretamente e que o resultado obtido esteja além do erro estatístico.
9. Implementação
Se o modelo nos der uma resposta satisfatória para a pergunta, essa resposta deve começar a ser benéfica. Quando o modelo é desenvolvido e o analista está confiante no resultado de seu trabalho, é necessário apresentar ao cliente a ferramenta desenvolvida. Faz sentido atrair não apenas o proprietário do produto, mas também outras partes interessadas: marketing, desenvolvedores, administradores de sistema: todos que de alguma forma possam influenciar o uso futuro dos resultados do projeto. Em seguida, você precisa seguir para a implementação. A implementação pode ocorrer em etapas, por exemplo, para um grupo limitado de usuários ou em um ambiente de teste. Também é necessário estabelecer um sistema de feedback para rastrear com que êxito o modelo desenvolvido lida com a tarefa. Após algum tempo, esse feedback será útil para melhorar o modelo. Novas fontes de dados, novas partes interessadas também podem aparecer, sem mencionar o fato de que a própria tarefa de negócios pode ser especificada. Portanto, não há limite para a perfeição: mesmo um modelo incorporado nunca pode ser considerado ideal.