O desenvolvimento mudou muito nos últimos anos. Em vez de aplicativos monolíticos, microsserviços e funções vieram. Os bancos de dados de monstros industriais universais degeneraram em alvos estreitos. Docker mudou de idéia sobre a implantação. Mas nossa ideia de logs mudou?
Um dos grandes problemas do Yandex.Verticals eram os logs - 18 TB por dia e 250.000 logs por segundo, tudo é gravado em arquivos. Os logs são heterogêneos porque existem muitas linguagens: Scala, Java, Python, Go. Em seguida, eles são coletados pela Fluent Bit, escreve em Kafka, manipuladores trabalham em uma máquina de ferro, montam a partir de Kafka e escrevem tudo em disco. Além disso, esta é a segunda versão dos logs.

Como resultado, surge um longo problema de pesquisa. Esses logs são pesquisados usando grep. Em alguns serviços, o grep pode chegar a horas. Se você tiver problemas na produção, não procurará seus registros por horas. Para resolver o problema, a Yandex decidiu escrever sua própria bicicleta de entrega de logs para pesquisa. O que aconteceu com
Alexei Danilov (
danevge ) - o desenvolvedor da equipe de infraestrutura da Yandex.Verticals. Desenvolve, escreve e suporta projetos auto.ru e Yandex.Real Estate.
Isenção de responsabilidade. O artigo fala sobre desenvolvimento moderno e é adequado para arquitetura de microsserviço. Vários produtos são apresentados aqui - essas são as ferramentas usadas no Yandex.Verticals. Sob outras condições, os análogos são possíveis com mais êxito, mas eles executam quase as mesmas funções. Nota O artigo é uma versão estendida do relatório de Alexey Danilov, “Logs não são necessários” no RIT ++ 2019 DevOps Conf, que é estilisticamente modificado e complementado com novo material. Você pode encontrar a gravação em vídeo do discurso de Alexey no link do nosso canal do YouTube.
A equipe do Yandex.Vertical tem 300 pessoas, cerca de 100 delas são desenvolvedores. No desenvolvimento, não somos diferentes da maioria das empresas que criam suas próprias soluções de produtos. Microsserviços, todo mundo mora no Docker, um monólito em PHP está acumulando poeira em um canto escuro, implantado via Hashicorp Nomad e mantemos um zoológico de idiomas: Scala, Java, Go, Node.js, Python.
Um dos grandes problemas de infraestrutura do Yandex.Verticals são os logs de aplicativos. Quando abordamos esse problema com seriedade, usamos a terceira versão de sua coleta e processamento. Simplificado, funcionou assim:
- aplicativos gravados em arquivos;
- O Fluent Bit leu os arquivos e os enviou linha a linha para o Kafka;
- Em uma máquina de ferro dedicada, havia um aplicativo que lia o tópico Kafka e escrevia nos arquivos do disco.
Na estação quente, tínhamos 18 TB de toras por dia, ou 250.000 linhas por segundo. Essa é uma quantidade muito grande, o que complica o trabalho com esses dados. A única maneira de analisar isso é grep, pois tudo é armazenado em arquivos. Para aplicativos grandes, a análise pode levar horas. Para problemas na produção, você não tem esse tempo.
Soluções prontas não cabiam em preço, recursos ou velocidade. Eles não podiam lidar de maneira aceitável com o nosso fluxo. É difícil até contar o número de tentativas de cozinhar o Elasticsearch. Suponho que não sabemos como cozinhá-lo. Mas não é disso que precisamos, se para usá-lo como um repositório de logs, são necessárias habilidades (habilidades) especiais.
Nessa situação, decidimos implementar nosso próprio sistema para coletar e analisar logs.
Bicicleta
 Nota: Se a próxima bicicleta não for interessante, prossiga imediatamente para a seção "Tipificação".
Nota: Se a próxima bicicleta não for interessante, prossiga imediatamente para a seção "Tipificação".Formatar
Usamos vários PLs e adoramos microsserviços. Para trabalhar com os logs, formamos uniformemente nosso próprio formato JSON. Ele cobre a maioria das necessidades de trabalho adicional com logs.
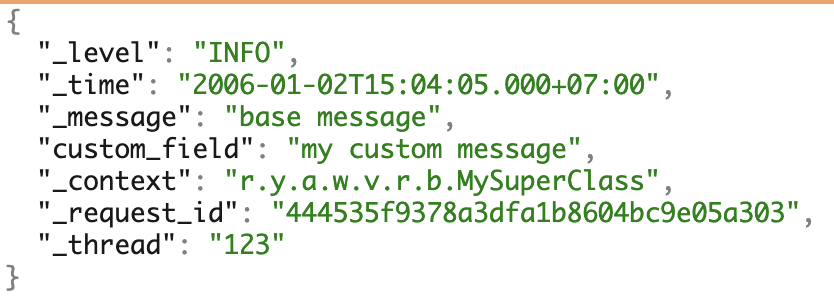 Um exemplo de logs com todos os campos possíveis.
Um exemplo de logs com todos os campos possíveis.Driver de log do Docker
Para coletar os logs, escrevemos nosso próprio
driver de log do docker - um aplicativo no Go. Ele é montado de uma maneira especial, entregue por comandos do plugin docker, armazenados no registro e executado em uma única instância executando o Docker.
Como qualquer problema com o driver de log pode afetar negativamente todo o trabalho, tentamos escrever uma implementação mínima. Nosso driver escuta o stdout do contêiner e passa imediatamente os logs para o aplicativo que está próximo. Ele já lida com a parte mais complexa da entrega.
Os problemas
Mencionarei separadamente os problemas de atualização da versão do driver de log do docker.
 Captura de tela do Grafana interno.
Captura de tela do Grafana interno.À esquerda está a proporção de versões instaladas para máquinas. Agora, três versões estão instaladas em todo o hardware - nenhum carro é perdido em lugar nenhum e não há instalações desnecessárias. À direita está o número de contêineres que usam esta ou aquela versão.
O driver da janela de encaixe não pode ser atualizado imediatamente. Para fazer isso, você precisaria reiniciar todos os contêineres e todos os serviços, o que poderia resultar em problemas. Portanto, para instalar a nova versão, basta aguardar a atualização de todos os contêineres.
Esquema geral
Considere o esquema geral de um novo sistema para coletar e entregar logs. Outros detalhes não são tão interessantes.
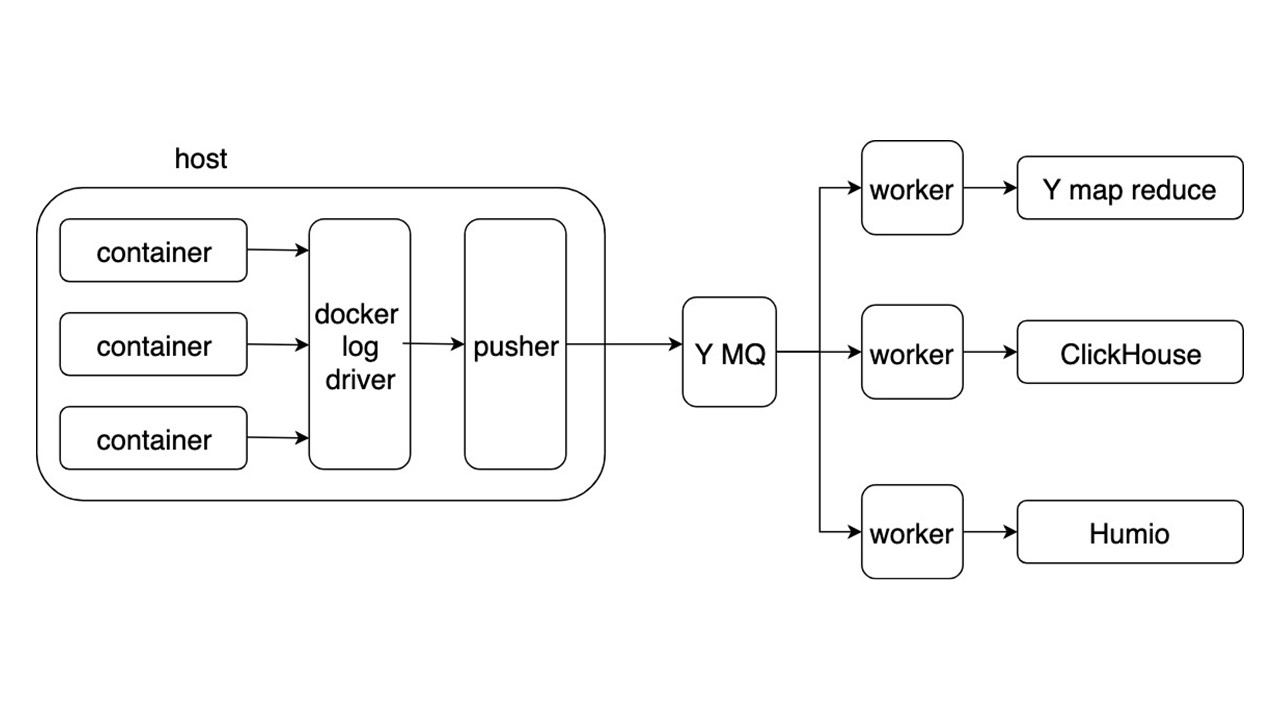
Os aplicativos gravam logs no formato JSON no stdout. O Docker escuta o pipe do contêiner e o redireciona para o driver do Docker. O driver do Docker lê e re-derrete de forma assíncrona tudo no Pusher.
Empurrador está em todos os carros de ferro. Ele prepara, satura, vira e envia logs para a fila de mensagens Yandex. O fluxo de logs do MQ é analisado por três tipos de trabalhadores e gravado nos repositórios.
Existem três repositórios para registrar logs.
- Yandex mapReduce para armazenar e analisar logs por um longo período de tempo. Este é um análogo do Hadoop.
- ClickHouse para armazenar logs durante o último dia.
- Humio (como um experimento) para armazenar logs para o último dia.
Lucro
O formato geral permite gravar e processar logs da mesma maneira. A coleta de logs é automática, sem usar um disco, e a entrega ocorre na área de alguns segundos. A chave pesquisa de 2 segundos a 5 segundos. Armazenamento e recuperação por um longo período de tempo.
Para volumes menores, considere alternativas: Humio, Splunk e Elastic. Os dois últimos possuem drivers oficiais do Docker. Se você mora na AWS, é o Amazon CloudWatch.
Amazon cloudwatch
O Amazon CloudWatch lida com métricas, eventos e logs. Ele não procura o último, não fornece itens de super busca e não os processa da forma usual. O Amazon CloudWatch processa logs, análises, filtros e exibições em gráficos.
 O Amazon CloudWatch converte logs em métricas e gráficos.
O Amazon CloudWatch converte logs em métricas e gráficos.O que fazer com os logs?
De volta à nossa bicicleta - ela atende a todos os casos? Não, nossa solução permite encontrar os logs, mas eles exigem uma heterogeneidade muito maior de informações e seus tipos. Os logs são usados em muito mais casos.
Assim que você coletar os logs, a seguinte frase será: "Vamos analisar algo, de alguma forma processá-lo, anotá-lo em algum lugar e começar a ser exibido em gráficos, em painéis". Este é o caminho para o inferno. Especialmente se estamos falando de ferramentas comuns.
Se você imaginar os logs como um certo caos ou log de eventos de qualquer dado, eles não funcionarão.
Esta será uma grande confusão de informações que não podem ser processadas. Um jogo começará na formalização dos logs: "Vamos escrever essas linhas em um formato especial para que seja conveniente analisá-las mais tarde!" Isso também não funciona. Acredite em nós, tentamos.
Digitação
Se você dividir os logs em tipos e processá-los separadamente, poderá encontrar ferramentas que facilitarão o trabalho com eles. Trabalhando não mais como com logs, mas com dados úteis - esse trabalho é mais transparente e conveniente. Alguns tipos de logs podem ser descartados por completo.
Apenas no caso
Esse tipo de registro "ser" é o meu favorito. Se é impossível responder claramente por que essa ou aquela linha é necessária, então elas são. Esse tipo também pode ser chamado de "logs apenas por precaução".
// validate customer func Validate(customer Customer) { // ??? log.debug(“Validate customer %v”, customer) … log.Error(“Customer not valid %v. Reason: %s”, ...) …. }
Os logs não são comentários que podem ser excluídos. Isso faz parte do código que é mais difícil de modificar, manter e, mais ainda, excluir.
Na melhor das hipóteses, esse log pode se transformar em depuração ou rastreamento. Esse tipo
desorganiza o código . Devido ao registro precipitado, posso obter dados pessoais, senhas e cookies dos usuários.
O caminho certo é
jogá-los fora e esquecê-los . Mas então nos deparamos com um novo problema. Como analisar a situação com um erro?
Erro fatal / crítico
Para começar, consideramos apenas erros críticos. Esses são erros devido aos quais usuários e desenvolvedores sofrem. O primeiro - quando eles não conseguem concluir a operação. O segundo - quando você precisa fazer correções manualmente.
Por que os logs não se encaixam?
Nenhuma resposta rápida . Se a equipe de desenvolvimento aprender sobre o erro dos usuários por meio do suporte ou do Twitter, é hora de mudar alguma coisa.
Não há contexto . Uma linha separada do log de erros é inútil. Temos que coletar o contexto pouco a pouco. Mesmo assim, pode não ser suficiente, pois esse é o contexto do processo, não o erro.
Não existe uma imagem grande . Nenhuma resposta para as perguntas:
- com que frequência esse erro ocorre;
- ocorreu nas réplicas restantes do serviço;
- foi antes?
Para corrigir esses problemas, use uma ferramenta adequada, por exemplo,
sentry.io . Ele permite que você trabalhe com informações de erro representativas e completas (contextuais) com
alerting rule personalizável.
O site sentinela descreve as diferenças nos logs do uso de sentry.io.
Erro não crítico
Lançamos erros fatais e críticos e agora eles estão escritos no Sentry. Mas houve erros internos - várias bibliotecas ou respostas de serviços de terceiros.
Um bom exemplo é uma nova tentativa bem-sucedida. Suponha que o serviço A esteja voltado para o serviço B, mas, devido a problemas de rede, não foi possível obter uma resposta. Após o erro, o serviço A voltou para o serviço B e recebeu uma resposta válida. O erro na primeira chamada é crítico? Não. Nesse caso, o processo foi concluído com êxito e o usuário pôde usar o serviço.
Se esses erros não são críticos para o serviço funcionar e não afetam o usuário com uma repetição rara, eles não são erros. Isso é uma degradação do serviço, embora a resposta ao usuário tenha chegado 50 ms depois. Este tipo de log refere-se a avisos - aviso.
Advertência
Alertas são informações sobre degradação de um serviço.
Aqui veremos os mesmos problemas inerentes a erros críticos, mas com uma reserva. A reação a um evento individual não é importante - sua quantidade ao longo do tempo é importante.
Considere um exemplo em que um serviço não pode recuperar uma entrada de cache e acessa o armazenamento a frio. Se isso acontecer uma vez por minuto, isso pode ser feito para a operação normal do serviço.
Emissões raras não são importantes .
Mas, ao mesmo tempo, você precisa de uma ferramenta para visualizar o panorama geral, precisa
de análise em tempo real . Para acompanhar as alterações por um longo período, seria bom ter uma
análise retrospectiva também. A degradação acima de um determinado nível (limites) pode afetar adversamente os usuários - você precisa de uma
reação com degradação grave .
Não precisamos dos logs marcados como Aviso, mas das métricas de degradação.
A ferramenta de coleta de métricas mais popular é o Prometheus, e você pode usar o Grafana para visualização. Se você precisar de um contexto grande (o mesmo que o erro), o mesmo Sentry fará, mas com os alertas desativados. No entanto, na maioria dos casos, haverá contexto suficiente. Será usado para gráficos - etiquetas Prometheus.
Exemplos.
Três eventos ocorreram no
user_service condicional. Eles afetam a operação do serviço: uma longa solicitação ao banco de dados, acesso repetido à API do serviço
service_b e nenhum direito do usuário foi encontrado no cache. Gráficos e alertas serão configurados como importantes para os desenvolvedores do serviço, graças ao contexto.
Rastreamento
Essa é a primeira coisa a começar, se escolhermos o caminho em que você precisa analisar os logs. Por si só, essas informações nos logs são inúteis, porque você precisa criar cadeias de chamadas, ver dados dentro de solicitações, erros nas cadeias de chamadas, tempos de resposta, o número de RPS.
Existem ótimas ferramentas para rastreamento - Jaeger ou Zipkin. Eu recomendo usar o OpenTracing, que ambos suportam.
Você pode coletar o rastreamento de três fontes.
- Se você usar balanceadores compartilhados, analise os logs deles e envie-os para o Jaeger.
- Os próprios serviços , se receberem endereços pelo Service Discovery e forem diretamente. Nesse caso, o rastreamento dos serviços é enviado diretamente ao Jaeger.
- Malha de serviço inteligente. Ele sabe como coletar e enviar um rastreamento, por exemplo, Istio.
Informação inicial
Essas informações são sobre chamadas de serviço da API, inicialização do Cron, consultas ao banco de dados ou chamadas para outros serviços.
{ "_message": "Request: ...; request_id: ...,... ", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcHandler", "_tread": "785534" }
Essas informações pertencem ao bloco "Apenas no caso", mas são separadas porque são mais comuns. Esta informação é necessária para analisar o erro e
você pode descartá-lo .
Se as informações sobre chamadas para métodos internos são extremamente importantes e você não pode prescindir dela, mesmo com o contexto coletado em caso de erro, vale a pena instrumentar as chamadas de método como um rastreio.
Tempo de execução
Essas informações são sobre o tempo de execução de métodos, APIs, consultas ao banco de dados ou outros serviços.
{ "_message": "Get customer 12ms", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcCustomerRepository", "_tread": "785534" }
Não há valor nos logs, porque você precisa analisar essas informações, exibi-las nos gráficos e configurar limites. Esse tipo de log precisa ser substituído por
métricas , por exemplo, no Prometheus.
Informações comerciais
Essas informações são necessárias para análise de negócios, análise de comportamento do cliente, cálculos financeiros. Nesse local, historicamente usamos a abordagem oposta - logs analisados. Mas este é um bom exemplo do que os logs do aplicativo podem degenerar se você trabalhar com eles dessa maneira.
Para logs com dados corporativos, acordos foram formados com campos fixos no formato TSKV, necessários para análises. Os aplicativos gravaram logs de negócios em um arquivo dedicado. Em seguida, os logs foram lidos e enviados linha a linha para o MQ, e um aplicativo separado os processou e os gravou no banco de dados. Este é um exemplo do que qualquer análise se transforma.
Não funcionará para analisar todo o fluxo de logs na esperança de que os dados converjam.
Convenções, formatos, regras e requisitos de confiabilidade estão surgindo. Isso já se parece um pouco com os logs do aplicativo. Nesse caso, o log se torna a fila de entrega de dados com todos os requisitos subsequentes para o MQ. É perceptível que o middleware na forma de um log é supérfluo aqui.
Uma boa solução é enviar esses dados diretamente para o MQ. Já serão processados, armazenados no armazenamento apropriado e usados pela equipe de análise. Por exemplo, para exibição, usamos o Tableau.
Desempenho
Esse tipo de log raramente é encontrado nos logs do aplicativo e é mais frequentemente coletado como uma métrica. Separadamente, acrescento que, para coletar as métricas básicas específicas do idioma, basta usar a biblioteca do Prometheus. Por padrão, ela coletará tudo o que alcançar. O custo de adicionar essas métricas é pequeno.

Resultado de digitação
Depois de classificar os logs por tipo, podemos pegar ferramentas mais poderosas para trabalhar com eles. Não existem sistemas complexos ou tecnologias espaciais como a Amazon, não há nada que não possa ser criado amanhã. Você provavelmente já possui alguns desses sistemas ou análogos: Sentry está acumulando poeira em algum lugar, Prometheus está trabalhando em algum lugar.

O problema não está na tecnologia, mas em uma armadilha cognitiva quando confiamos nos logs como um meio de representação confiável do estado do nosso sistema. Não é assim, os logs são um conjunto de eventos caóticos.
Há uma exceção - Debug-logs, que pode ser usada em casos raros.
Log de depuração
Os logs de depuração devem ser informações detalhadas. Eles não devem duplicar o que já está sendo enviado para os sistemas que descrevemos acima. Este tipo existe para analisar casos especiais. Por exemplo, um bug incompreensível ocorre na produção e, no momento, não está claro pelas métricas o que está acontecendo.
Ative os logs de depuração a quente, sem reiniciar o serviço . Como estamos falando de vários serviços, não haverá muitos deles. Infraestrutura sofisticada não é necessária. Pilha de ELK suficiente sem "preparação" complicada. Também faz sentido adicionar um alerta ao Sentry com todo o contexto necessário.
Os logs de depuração podem ser usados para desenvolvimento . Mas eles são perfeitamente substituídos por depuração.
Resumir
Nós escrevemos nossa entrega de registro de bicicleta para pesquisa . Não satisfazemos os clientes do serviço - todos eles vêm até nós para analisá-los, coletá-los e agregá-los em algum lugar. Isso pode ser evitado - sistemas complexos de processamento de logs não são necessários.
Os logs brutos são inúteis, mas podem ser transformados em métricas úteis.
Basta criar uma infraestrutura para fornecer métricas e dados úteis em torno dos serviços. Como resultado, serão exibidas métricas úteis que falam sobre serviços e mostram transparentemente tudo o que acontece com eles.
Os erros devem conter o contexto do próprio erro.
Isso ajudará a lidar com isso e corrigi-lo imediatamente.
Erros e degradação devem levar à ação , para que os desenvolvedores aprendam instantaneamente sobre os problemas e os corrijam mesmo antes das solicitações irritadas dos usuários.
As ferramentas certas tornarão o trabalho com seus serviços mais agradável e transparente . A depuração tem um lugar para estar, mas você precisa ser rigoroso com ela.
No HighLoad ++ 2019 em novembro, haverá uma seção DevOps - 13 relatórios sobre cargas na AWS, um sistema de monitoramento em Lamoda, transportadores para entrega de modelos, vida útil sem o Kubernetes e muito mais. Veja a lista completa de tópicos e resumos na página separada “ Relatórios ”. E nos encontraremos no DevOpsConf na primavera - inscreva-se no boletim informativo e informe-nos quando determinarmos as datas e o local.