Em novembro de 2018, um departamento de suporte à informação foi criado na Lituânia e convidou
Andrei Yumashev para liderar. No ano passado, o departamento ajuda a empresa a trabalhar e desenvolver e mantém toda a infraestrutura sob controle. Mas esse nem sempre foi o caso. Antes de começar o trabalho, Andrei se deparou com ruínas: Nagios meio morto, Cacti vivo e Puppet em coma, Wiki morto de 120 páginas, tabelas de tarefas incoerentes e lista de ferro, arquitetura desatualizada, 340 núcleos inativos, 2 TB de RAM e 17 TB espaço em disco que, por algum motivo, não foi registrado nas tabelas de inventário. Planos que não funcionam, prazos que terminam, ambiente de trabalho e ferramentas que não existem - tudo isso aguardava Andrei em um novo projeto.

No
DevOpsConf 2019, Andrei fez um relatório no qual mostrou em exemplos ao vivo o que vale e o que não deve ser feito quando você entra em um projeto que não viu ou conhece mal. Sob o corte, há uma versão atualizada da história - como analisar adequadamente a variedade de problemas e criar um plano de atividades, como calcular o KPI corretamente e quando parar no tempo.
Andrey Yumashev é o proprietário de suas próprias empresas de desenvolvimento em vários campos (online e offline), consultor na construção de processos e chefe do departamento de suporte a informações da LiteRes.
Um pouco sobre o LiteRes. Este é o maior fornecedor de livros eletrônicos e de áudio na Rússia, uma editora e vários projetos de parceria. São centenas de milhares de linhas de Perl, vários clusters e repositórios de bancos de dados. São 2 GB de tráfego de saída por segundo, centenas de milhares de solicitações exclusivas por dia, vários racks em diferentes datacenters e mais de 100 servidores. Em suma, não se trata apenas de uma livraria eletrônica.
Primeiros passos
Eu trabalhava no LiteRes em uma base de peça. A empresa pratica o desenvolvimento de pessoal externo com registro de funcionários remotos no estado.
O sistema de realização de tarefas em litros trabalha com o princípio de um "leilão". No rastreador de tarefas interno, gerentes e arquitetos descrevem tarefas para projetos internos e as avaliam na moeda local. A moeda é "cogumelos, grama e árvore".
Em seguida, começa o "leilão fácil" - qualquer desenvolvedor pode aceitar a tarefa ou barganhar. Bem feito - você é pago. Eu não trabalhei de jeito nenhum - você não entende. De uma maneira divertida, as pessoas estão interessadas em concluir tarefas. Para saber mais sobre esse sistema, consulte a
apresentação de Dmitry Gribov.
 Trabalhe para os cogumelos.
Trabalhe para os cogumelos.O sistema me convinha - apoiei a experiência de programação em Perl, trabalhei quando era conveniente e não gastei muito tempo com isso. Nesse modo, passei alguns anos até novembro do ano passado e pensei entender a estrutura do ecossistema.
Eu estava errado
Fui convidado para a empresa e informei que meus serviços como desenvolvedor Perl não eram necessários e me ofereceram a chefia de um novo departamento. Em novembro de 2018, tornei-me chefe do departamento de informações.
Na minha frente, havia espaços abertos: vários racks com ferro em vários data centers em Moscou, arquitetura desatualizada, recursos externos e a quase completa ausência de documentação relevante para isso. O introdutório soou algo como isto: "Agora este é o seu patrimônio, melhore, não quebre e apoie". Havia uma lista pronta de tarefas e planos aproximados para o próximo ano. Era necessário compreender tudo isso e trazê-lo para uma forma humana.
Havia um sentimento de que eu estava olhando para o abismo, e o abismo estava olhando para mim.
A experiência dos últimos anos me ajudou muito quando desenvolvi uma posição clara ao trabalhar com um estranho ou incompreensível. Primeiro de tudo, este é um estudo completo e um plano de ação mínimo. Foi aqui que eu comecei.
Limpeza é a chave para a saúde
A ordem é antes de tudo.
Durante o primeiro mês conseguiu encontrar:
- Google Sheets espalhados com tarefas atuais e uma pitada de informações úteis;
- documentos espalhados: Word, textos, fragmentos de páginas antigas do Wiki 120;
- Nagios meio morto;
- monitoramento condicional ao vivo de cactos;
- fantoche muito antigo com raros sinais de vida.
Todas essas ruínas também coletaram 400 métricas.
 As ruínas que encontrei no primeiro mês.
As ruínas que encontrei no primeiro mês.Fiquei um pouco divertido, li tudo fluentemente e fiquei preso aos processos do Trello. Ele transferiu as tarefas atuais de seus colegas para ele e começou a sonhar - escrever um plano para o trimestre e o ano.
Primeiro erro
Não há planos até explorar a área.
O plano brilhava com calor e saúde, mas não levava em conta a realidade. Era bonito e simples: implementar monitoramento, analisar logs e transferir a implantação para o CI / CD. Em algum lugar no final, houve uma "análise das fraquezas do projeto". Primeiros passos clássicos.
Eu esqueci a coisa principal. Minha primeira prioridade não é implementar ferramentas para a implementação de ferramentas, mas garantir a viabilidade e a estabilidade do serviço como um todo.
Enquanto escrevia o plano e atormentado pelas perguntas dos meus colegas, chegaram os primeiros problemas. Um dos nós de um dos clusters de cluster ficou sem espaço e o SSD como um todo terminou no outro nó do mesmo cluster. Comprei urgentemente novos discos maiores e nosso departamento rapidamente adquiriu experiência na substituição desses discos, copiando o sistema de disco para disco. Após a substituição dos discos, criamos o cluster do zero através do SST. O cluster é construído em Percona e Galera, e esse entretenimento não chega a ele por nada.
Enquanto eu viajava entre os data centers, surgiram as
primeiras dúvidas sobre o plano.
 Ahhhhhh!
Ahhhhhh!Ao mesmo tempo, a intensidade do trabalho preto era tão alta que nem pensei em coletar um histórico médico completo, mas simplesmente tirei algumas fotos para estudos adicionais.
Paralelamente, outra introdução apareceu. Em litros, existem versões em áudio de livros. Para que o ouvinte não rebobine a gravação novamente, temos um mecanismo que rastreia o momento da parada. Na próxima vez que você ouvir, a versão em áudio será reproduzida na seção desejada. Para esta tarefa, demorou cerca de 500 núcleos mais rapidamente, um terabyte de RAM e um pouco de análise em Java.
Comecei a informar o Azure, Google, DigitalOcean e tudo mais que as soluções de gotículas forneciam. A conteinerização implora, por que não implementá-la alegremente? Além disso, no "grande" plano, havia um ponto separado sobre isso.
Um mês se passou em correspondência e licitação, tudo foi adicionado às tarefas do Trello, das quais gerei uma parte significativa, mas o resultado não avançou. Eu me perguntei se eu estava indo para lá. Antes de mim, tudo funcionou de alguma forma e não vai parar, não importa quanta atividade vazia eu mostre. Sentei-me cuidadosamente para estudar o inventário que consegui coletar pouco a pouco. Então ele se levantou e foi para a segunda rodada de data centers.
A segunda visita calma aos data centers colocou tudo em seu lugar. Quando vi tudo isso não no console, não no Excel, mas vivo, minha consciência da realidade mudou radicalmente. Percebi que não estou nem um pouco ocupada com o que deveria. Porque primeiro você precisa entender com o que estou trabalhando.
Até entender o que estou trabalhando, todos os planos são uma perda de tempo.
Estudei as prateleiras, comparei a realidade com as listas, fiz edições e me deparei com uma semi-unidade com 20 lâminas. Dos 20, apenas 4. Trabalharam com as lâminas e percebi que não precisávamos de gotículas para a solução. Porque eu encontrei 340 núcleos inativos, 2 terabytes de RAM e 17 terabytes de espaço em disco! Esses são backends antigos, velhos nós de clusters que simplesmente pararam de usar e o tempo apagou a memória de sua existência. Coloquei o Kubernetes nessas lâminas e me livrei de uma tarefa importante.
Primeira saída de erro
Analise e estude. Sem uma análise preliminar da situação, o trem não se move.
Graças a uma viagem cuidadosa aos campos, eu já tinha em mãos um plano bastante relevante para o equipamento e a arquitetura geral do sistema. No quintal era janeiro. Passei dois meses nisso, dos quais metade eu arremessei de um lado para o outro. Eu não sabia que tipo de fogo extinguir primeiro, que problema resolver antes de tudo - a rotina com suporte não foi a lugar nenhum.
Paralelamente, deduzi três regras. Estas são as consequências do primeiro erro.
 Três corolários.
Três corolários.Segundo plano
Joguei tarefas secundárias em primeiro plano - análise de log e implementação de CI / CD. Na escala de uma catástrofe geral, essas pequenas coisas não são importantes. Litros trabalhou por anos e desenvolveu sua própria lógica para trabalhar com toras, e adquiriu um demônio rolante de fabricação própria. Empurrei para o quinto plano o que funcionava e não exigia intervenção.
O segundo plano parecia algo assim.
Lidar com o monitoramento . Na sua forma atual, não refletia pelo menos um terço dos problemas, embora funcionasse.
Descreva a lógica geral de todos os litros . Os nomes dos servidores são ótimos, mas os principais pacotes são um conhecimento crítico: o que, onde, onde, por que e por que. O erro anterior deixou claro que sem isso, de forma alguma.
Dimensionamento . Quase os últimos recursos gratuitos levaram o Kubernetes. De acordo com estimativas mínimas, ele deveria terminar todo o conjunto de trabalhos em seis meses.
Inventário e condição do equipamento . Como parte da viagem, eu literalmente limpei uma web de vários servidores assustados com suas tags - "backup", "inscrição", "bgp". Mais uma vez, discos, largando discos.
Adaptação de guias à realidade . A maioria das instruções está desatualizada ou incompleta.
Os primeiros seis meses passaram despercebidos na rotatividade, compra de equipamentos e problemas, e finalmente me estabeleci no segundo erro.
Segundo erro
Não subestime.
Qualquer termo que vem à mente é subestimado . Claro, você pode se beneficiar rapidamente do projeto. Mas, para maximizar os retornos, multiplique o tempo planejado por
pelo menos duas vezes . Especialmente em um projeto complexo e altamente carregado, que cresce constantemente no tráfego em mais de 100% ao ano.
Por que pelo menos duas vezes? Se o projeto for instável e não for pesquisado, esteja preparado para o fato de que qualquer atividade dará origem a outras em locais vizinhos. Parece que a substituição de discos - o que é mais fácil? O procedimento é simples até você encontrar uma compra, programar o tempo para nós específicos do tempo de inatividade e fazer a manutenção após a substituição de um disco. Estimei essa operação simples por semana. No final, demorou duas semanas e meia - mesmo com um simples esquema de compras.
Outro exemplo é a compra e instalação de novos equipamentos. Compre e cole, o que é tão difícil? Não demorei mais de um mês para isso sem levar em consideração o tempo de entrega. De fato, um dos três chassis ainda está de pé em frente à minha mesa. Isso ocorre porque o equipamento simplesmente não tinha espaço suficiente - calculamos o local nos orifícios entre a instalação atual. Quando chegamos a um dos data centers com a intenção de sacudir o rack, percebemos subitamente que os dois servidores eram "intocáveis". O primeiro é o host e simplesmente não é seguro tocá-lo. O segundo é uma cesta de 16 discos, encerrados, repletos de um monte de dados. Os canudos não foram depositados, a análise não foi realizada e é bom que eles tenham conseguido colar dois em três.
Se parece que tudo será simples - em breve você terá problemas . Essa instalação levantou uma nova questão - se tudo está tão ruim com o local, como vamos expandir? Uma pequena tarefa agora gerou um suor gigante. Em 2020, de acordo com o plano, a transferência de um data center para outro e a expansão do restante por racks. Isso significa migração dentro do data center entre os módulos. A migração foi complementada pela reestruturação da rede e sua transferência para 10G.
Não subestime o tempo, o limite de entrada e as consequências.
Conceitos básicos
Obviamente, a essência dos erros já está descrita no Wiki como conceitos básicos.
Qualquer processo burocrático dura pelo menos um mês . Isso se aplica a compras, a conclusão de novas condições com um data center ou outros fornecedores - a tudo. Tome isso como um fato.
Após a conclusão do contrato e pagamento, qualquer entrega dura pelo menos uma semana e meia , de discos a processadores. Aprenda a negociar com os fornecedores as datas de pré-entrega. Por exemplo, os discos são enviados em pequenos lotes para nós agora até o pagamento e mesmo antes da aprovação do aplicativo.
Embora não haja um entendimento claro da implementação, qualquer plano para implementar algo permanece um plano. Quanto mais curtos os passos, melhor.
Por exemplo, para alternar do MySQL para o ClickHouse, uma grande etapa se parece com a seguinte: “Vamos preencher um servidor, desenhar um ticket para reintegração e voar!” De fato, um estudo detalhado da questão levou a novas etapas: compra adicional de equipamentos, por exemplo, processadores e discos, tickets detalhados para alterar a lógica do rastreador de comportamento do usuário, mantendo a integração reversa, os servidores de filas e muitos outros.
Quanto mais detalhado o plano, melhor. Escrever com uma pincelada ampla é uma garantia de 100% de erro no prazo.
Submeter qualquer plano a críticas máximas e esperar o risco máximo . Certifique-se de examinar o plano do ponto de vista comercial - que lucro cada etapa trará.
Tivemos que realizar implementações obrigatórias: monitoramento, Ansible, mas não esquecemos o componente de negócios.
- Ao alterar a arquitetura da rede, poderemos aceitar tráfego adicional e resolver muitos problemas atuais.
- Ao alterar o tipo de armazenamento de conteúdo, reduziremos o número de bugs com o retorno de livros e aumentaremos a velocidade de trabalho com dados.
- Mova o back-end para a nuvem - dimensione instantaneamente a carga durante as campanhas de marketing.
- Traduzir o rastreamento para o ClickHouse é uma oportunidade para os analistas entenderem melhor as necessidades de nossos amados leitores e ouvintes.
A melhor maneira de lidar com uma situação em que você é pouco versado no tópico é pedir a ajuda de especialistas, não o Stack Overflow . O contato por voz resolve o problema muitas vezes mais rápido que a correspondência longa ou a leitura da documentação.
Seis meses depois
Apesar do fato de que as tarefas básicas em que eu me concentrei no início ainda estavam derrapando, graças a pesquisas e correções, algo de bom apareceu em minhas mãos.
Ferramenta auto-escrita para inventário de redes e endereços. Ele tocava regularmente em todas as nossas sub-redes e adicionalmente verificava os dados com a configuração do BIND. Isso tornou fácil e rápido encomendar novos serviços e entender a carga real dos pools de rede. Eu realmente não queria gastar tempo nisso, mas não consegui encontrar uma alternativa pronta e encontrar um endereço para alocar para um novo recurso levou muito tempo. Enquanto escrevia a ferramenta, o primeiro rascunho do plano apareceu na rede.
Puppet não está mais tão morto e confuso . Eu estava armado com uma conclusão do erro número um e nem tentei me mudar para Ansible, o que é mais confortável para mim.
Nagios mais ou menos equipado . Mudei do escritório para o data center e o distribuí em três pontos. Era muito mais rápido e mais barato do que implementar o Zabbix. Fechamos um buraco com alertas incorretos no tempo e nos eventos, uma simples reconfiguração das regras e a introdução de nós de controle adicionais.
Noções básicas sobre a manutenção de clusters de banco de dados usados.
Wiki pesadamente inchado . Ela "engordou" com comentários e instruções sobre como trabalhar com ambientes.
Três chassis HP que compramos para instalação futura.
Compreendendo o caminho para o restante de 2019 em uma aproximação mais clara.
Ecossistema reciclado para o trabalho do departamento.
Todos esses seis meses trabalhei quase sozinho. Os funcionários que herdaram eram mais administradores de sistema. Eles não estavam realmente ansiosos para se aprofundar na essência do DevOps.
Com muita dificuldade, encontrei dois especialistas na equipe - junior e médio. Reuni a quantidade máxima de conhecimentos, aparências e senhas dos administradores atuais e parti com eles com o coração pesado.
Sistema de trabalho, ambiente e ferramentas
Vou falar sobre a importância de introduzir um ecossistema e ambiente de trabalho. Eu já mencionei o Trello, mas não disse por que e por que o implementei. Nenhum trabalho será construído sem definir metas e dados estruturados. Isso é parcialmente evidenciado pelo primeiro erro - colete tudo o que é.
Pegue tudo, não dê nada.
O processo é o motor do progresso . Portanto, todo esse tempo trabalhei no sistema, apesar da obstrução da pesquisa e do fluxo de trabalho. Graças ao sistema, seis meses depois, coloquei a locomotiva a vapor do departamento em trilhos estáveis.
A introdução de ferramentas de suporte e um breve curso sobre seu uso economizam muito tempo para você e seus colegas. Especialmente se você ainda no topo entender em gerenciamento e um pouco capaz de manter a ordem na área de trabalho e na vida.
Não complicamos as ferramentas, passamos do simples e apresentamos o necessário . No começo do ano, pensei em qual rastreador de tarefas nos conviria. Imediatamente demitido Jira e Redmine - muito controle. Passaríamos algum tempo preenchendo os formulários, não as tarefas. Planilhas Google - acho que não vale a pena explicar por que não.
Trello foi perfeito . Algumas colunas simples: “Backlog” - onde todos os erros ou tarefas observados para o futuro são adicionados, “Conclusão” - as principais tarefas que precisam ser executadas e “Concluir”. Um pouco mais tarde, havia cinco colunas: "Backlog", "Pause", "Sprint", "Finish" e "Study".
Na "Pausa", carregava coisas que perderam relevância no processo de sprint. Em "Aprendizado" - tarefas que exigiam pesquisa e não deveriam ser perdidas até o momento de entender e transferir conhecimento para o Wiki. O Sprint se tornou uma evidência de que mudamos para o sistema de sprint. Experimentamos e escolhemos o momento ideal - 2 semanas. Agora usamos esse segmento, mas outro será adequado para você.
O tempo de sprint é individual para cada empresa .
As reuniões semanais obrigatórias são a próxima inovação após o Trello. Praticamente não trabalhamos no escritório. O tempo que poderíamos gastar na estrada, dedicamos ao trabalho. Mas uma vez por semana, todo o departamento se reúne no escritório por 2-3 horas intermitentemente e discute o curso do sprint e as tarefas que surgiram. Assim, além de uma vez a cada duas semanas, planejamos o próximo sprint.
Em seguida, foram implementadas as ferramentas mínimas necessárias. Todos os repositórios de serviços com configurações - Puppet, Nagios, DNS - foram retirados do SVN para o novo GitLab. Eles prenderam Jenkins a ele. Agora, as configurações de DNS foram atualizadas automaticamente e as edições dos colegas do Puppet podiam ser lidas através de solicitações de mesclagem mais fácil e mais conveniente. Anteriormente, as senhas eram transmitidas de pessoa para pessoa, agora são coletadas ordenadamente no 1Password. Agora, essa é a única solução paga na infraestrutura.
Ferramentas fáceis de implementar e configurar geraram o processo e são mais fáceis de controlar.
Os problemas
Em litros, o tráfego cresceu e acrescentou mais trabalho: cachos fracassados, pedaços de ferro quebrados, componentes. A segunda metade do ano estava se aproximando, para a qual estava planejado o desenvolvimento da escala.
Nesse momento, dois best-sellers apareceram - um novo livro de um autor popular e um decreto do presidente de um país amigo sobre o bloqueio de litros. Reclamações maciças sobre a inacessibilidade do site. O decreto foi emitido há muito tempo, mas só descobrimos quando começaram a realmente bloquear-nos em todo o vasto conjunto de endereços. Felizmente, o decreto se referia a apenas um nome de domínio - "litres.ru".
O aumento do tráfego (todo mundo queria um best-seller) por meio de proxies, confundimos um ataque DDoS e pagamos por ele com moeda forte. Lembro-me de como pagamos as contas de uma empresa que nos prometeu proteção contra DDoS. Imediatamente após o pagamento, mudei o DNS para os endereços deles e, após 10 minutos, lembrei-me do primeiro erro e virei o DNS freneticamente. Não havia tráfego de lixo, mas havia um preço de cavalo para o tráfego que passava por eles - livros, áudio, capas. Não vou dizer quanto nos custou 20 minutos de vida nos endereços de outras pessoas.
Naquela noite, liguei para a Cloudflare e conversei sobre nossos problemas. Anti-DDoS . , Cloudflare . . , DDoS' , .
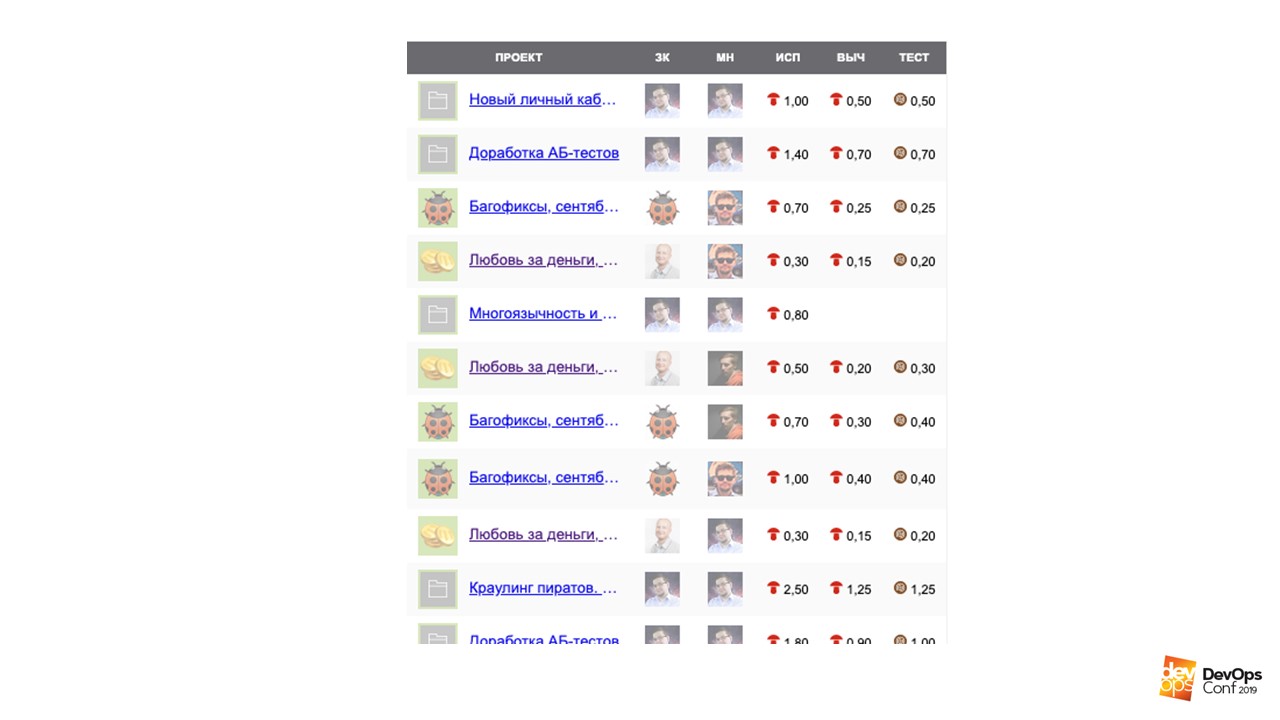
. KPI.
KPI
. . , , .
KPI. — .
- . — .
- Downtime. — .
- . , --, , . , .
KPI, — . , , KPI, .
. 90%. , . — , . . , .
-Nagios -Puppet Zabbix Grafana Ansible. « ».
Prometheus , Zabbix. Zabbix, Prometheus — . — . .
, , .
. ,
, . — . , .
. - -, - . , . . . . .
, .
2 . 3 « », — . .
. : , , , Ansible, .
. , . . .
.
— , , . .
. — , .
. , . . 2019. , , , — . .
. .
.
, - , . .
- , , .
- , .
- , , — .
- , , , — , .
. , - . , , , .
.
— , , . , , .

, — - . , .
« , ». , — , , , .
, , .
—
Ansible? , , Puppet ? — .

CI/CD? , . CI/CD , — .
., , . - ? , KPI? , -.
- — , , .
.
:DevOpsConf . — , , . DevOps- HighLoad++ 2019 . DevOps 13 AWS, Lamoda, , Kubernetes, Kubernetes, Kubernetes . « » . HighLoad++ — , -. . — .