Às vezes acontece assim:
- Venha, nós caímos. Se você não aumentar agora, será exibido na TV.
E nós estamos indo. À noite. Para o outro lado do país.
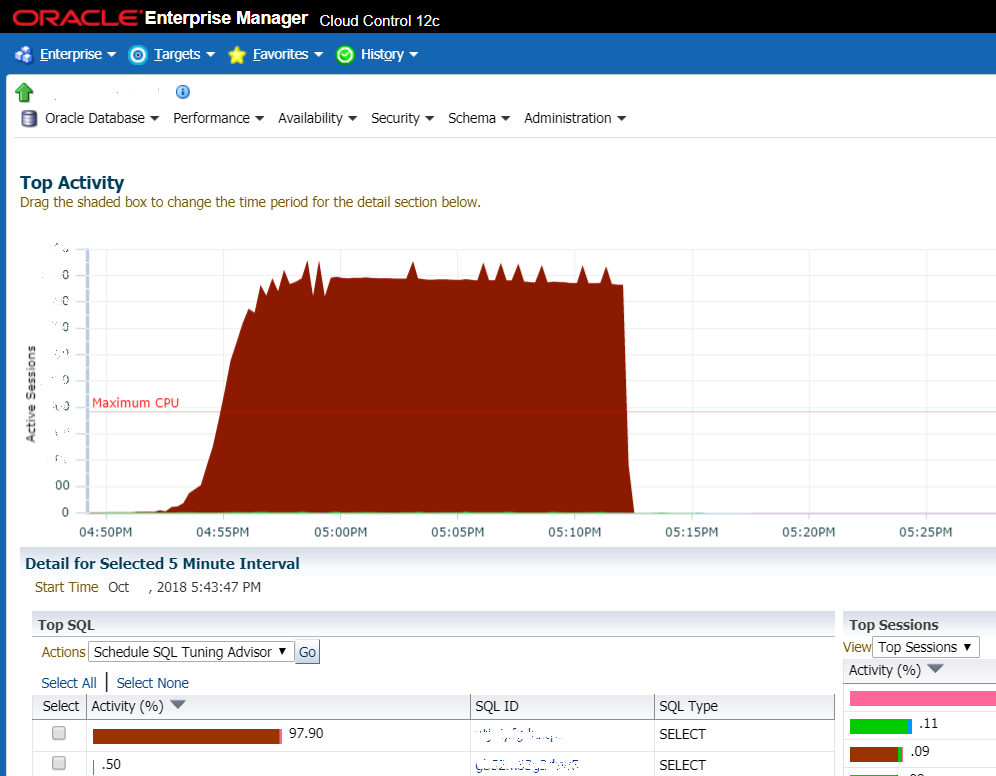 A situação em que não há sorte: o gráfico mostra um aumento acentuado na carga no DBMS. Muitas vezes, essa é a primeira coisa que os administradores de sistema olham e este é o primeiro sinal de que um idiota chegou
A situação em que não há sorte: o gráfico mostra um aumento acentuado na carga no DBMS. Muitas vezes, essa é a primeira coisa que os administradores de sistema olham e este é o primeiro sinal de que um idiota chegouMas, mais frequentemente, estamos falando de algumas coisas típicas. Por exemplo, um cliente enfrenta um sistema de fluxo de trabalho ruim. Nas segundas e terças-feiras, o sistema travava, eles reiniciavam o servidor e tudo funcionava. O banco de dados estava sufocado. Eles queriam comprar equipamentos (longos e caros), nos chamaram para calcular a estimativa. Calculamos suas estimativas e, ao mesmo tempo, nos oferecemos para descobrir o que exatamente fica mais lento. Em três a quatro horas, a fonte do problema foi localizada. Descobrimos que essas são consultas lentas do banco de dados e esquemas de indexação abaixo do ideal. Criamos os índices ausentes, procuramos o otimizador de consultas no Oracle, alguns problemas exigiram a alteração do código - alteramos as condições de pesquisa (sem alterar a funcionalidade), substituímos algumas das solicitações pelo uso de visualizações pré-calculadas. Se eles tivessem uma pessoa normal no banco de dados - eles mesmos poderiam fazer o mesmo. Mas, em vez de uma pessoa normal, o banco de dados era auditado a cada seis meses por oracleists legais - eles emitiam recomendações gerais sobre configurações e hardware.
Como isso acontece
Os detalhes são um pouco alterados a pedido de segurança. Existe um sistema de gerenciamento de documentos em centenas de instalações industriais. Ela às vezes cai e o trabalho aumenta. Ou seja, os objetos podem funcionar, mas nenhum documento é aprovado e não é assinado. E isso, em particular, o envio de matérias-primas, salários e pedidos, o que e quanto produzir por turno. Todo outono é uma dor, lágrimas, conhaque para o CIO, porque é difícil para ele: muitas perdas.
O diretor, a propósito, tem apenas seis meses neste local depois do passado. E o ano passado durou. E os dois trabalham em um sistema que o diretor introduziu três gerações atrás. O segundo do final tentou introduzir o seu, mas não teve tempo antes da demissão. A situação é muito realista.
À primeira vista, não há desempenho suficiente. O perfil de carregamento é bloqueios (classe de espera "Aplicativo"). Ou seja, competição pelas linhas. Começamos a investigar o incidente. Uma sessão é aberta para cada transação do usuário. Ele rapidamente entra em um estado de bloqueio de uma ordem, segundo o qual as tarefas e instruções de execução são gravadas, porque o usuário deve colocar um visto "Familiar" no mínimo.
O último caso - eles criaram um novo padrão sobre a frequência com que os funcionários devem passar por um exame médico. O oficial de alto nível escreveu um pedido e o enviou a todas as organizações. Ou seja, cada funcionário de cada produção. Dezenas de milhares de usuários receberam transações com vistos. Eles começaram a abrir pedidos quase simultaneamente, colocar uma longa cadeia de bloqueios no banco de dados. Devido ao código não ideal, ocorreu um estouro “pequeno” como resultado e tudo foi bloqueado. Cerca de 40 mil usuários não trabalham. A partir do esquema de backup - apenas telefones e correio. A produção não para, mas a eficiência cai muito, o que causa perdas financeiras específicas. E então as chamadas começam de cada empresa pessoalmente para o diretor de TI com um discurso. Na prática, eles têm um SLA, mas ainda não há acordo. E a situação assume as características finais da história puramente russa.
O problema "instigado" foi resolvido por perfis profundos, análise da lógica de bloqueio de objetos, excluindo objetos desnecessários nos quais o bloqueio foi acionado, embora não fosse necessário porque o objeto não foi alterado (por exemplo, diretórios, direitos de acesso etc.). Depois, em alguns meses, as principais seções do código foram refatoradas.
Como essas seções de código são pesquisadas?
Além das ferramentas padrão (despejos de encadeamento, logs, métricas, AWR, dados de representações do sistema, etc.), usamos mais ferramentas civis, incluindo as comerciais.
Exemplo 1: Log de transações lentasForam recebidas reclamações dos usuários sobre a operação lenta da revista (um problema conhecido e frequente).
Encontramos a visualização do problema e, em seguida, procuramos a solicitação nas operações para a visualização deal_journal_view. Procuramos todas as transações em que existe uma solicitação desse tipo.

Para cada uma das operações, você pode ver seus detalhes e encontrar a própria solicitação com os parâmetros de execução, o que permite analisar a operação da solicitação, validar e ajustar o plano. Encontrou uma solicitação lenta específica.

Eles mesmos analisaram e propuseram opções de otimização. E somente então, para rastrear esse grupo de operações de negócios (exibir o log de transações), crie um Tipo de Transação e configure alertas.
 Exemplo 2: localizando os motivos do trabalho lento do usuário 1
Exemplo 2: localizando os motivos do trabalho lento do usuário 1O usuário 1 recebeu reclamações sobre o funcionamento lento do aplicativo. Nós olhamos:

Todas as operações do usuário foram pesquisadas e classificadas por duração. Em seguida, as operações mais lentas foram analisadas e as consultas lentas no sistema externo (SAP) foram detectadas.

Apontou para a equipe adjacente, consertou.
Exemplo 3: outro usuário reclama da operação lenta do aplicativoNós olhamos da mesma maneira. Desta vez, vemos um grande número de chamadas para um serviço de assinatura externa. Acabou que, sob certas condições, eles assinaram alguns documentos duas vezes. Corrigido.
 Exemplo 4: quando não há detalhes suficientes
Exemplo 4: quando não há detalhes suficientesÀs vezes, para analisar partes mais complexas do código, recorremos ao uso de criadores de perfil personalizados, que nos permitem estudar o comportamento do aplicativo mais profundamente. Por exemplo, como aqui: muita lógica incompreensível durante a operação da lógica no sistema. Descobrimos a lógica, adicionamos alguns caches, solicitações otimizadas.
 Exemplo 5: mais freios
Exemplo 5: mais freiosO usuário reclamou do trabalho lento com os cartões de contrato.

As operações lentas do usuário (parâmetro = 'userlogin = ”...”') por uma semana são analisadas. A maioria dos problemas ocorreu com consultas de pesquisa sob contratos, mas também foram encontradas operações com um cartão de documento. A maior parte do tempo é gasta na criação de um grande número de tarefas nas atribuições. Foram encontrados identificadores (a coluna Valor do parâmetro na captura de tela) das tarefas armazenadas e o tempo de salvamento.
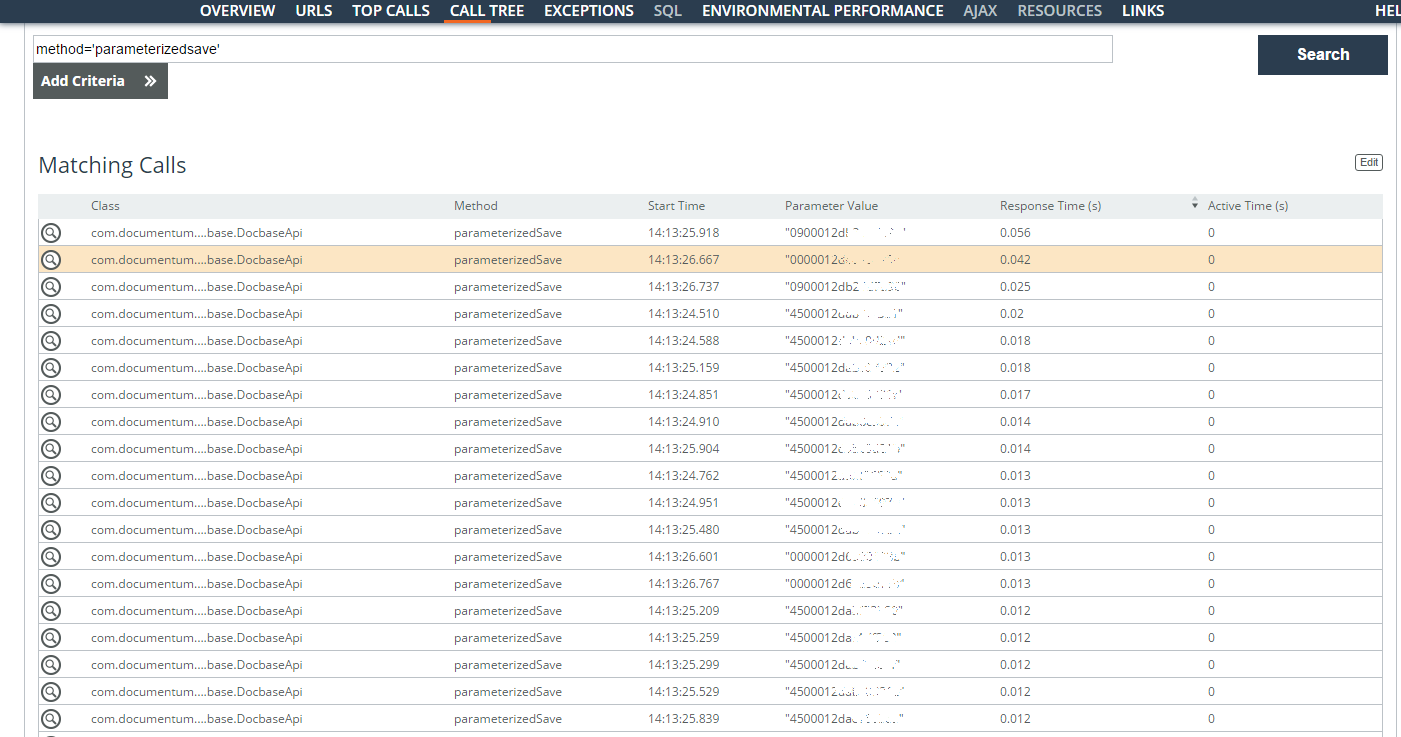
Logicamente, quando eles podem ser criados de forma assíncrona, mas agora estão na fila e exigem bloqueios excepcionais. Aqui você já precisa se aprofundar na arquitetura.
É simples: você precisa encontrar um gargalo - e é isso?
Não.
E novamente, não.
Isso tudo é um tratamento para os sintomas.
É certo salvar rapidamente a situação, que agora está pegando fogo. E depois coloque os processos. É raro que as pessoas que trabalham com um sistema não entendam o que estão fazendo. É que eles precisam justificar os meios para reduzir sua dívida técnica (e ninguém acredita neles) ou alterar os processos para outros mais modernos (para os quais também não há recursos), ou fazer algo assim.
Em geral, viemos do nível superior e sentimos dor no cliente. Então pegamos o gargalo. Às vezes, termina com a introdução de um sistema de monitoramento. E se o cliente entende que é necessário alterar os processos de desenvolvimento de software, o estágio começa "longo, caro e nem sequer impressionante".
Analisamos dois ou três projetos, selecionamos todos os documentos, repositórios, entrevistamos pessoas. Em seguida, preparamos modelos para novos documentos, preparamos procedimentos, analisamos as ferramentas para gerenciar requisitos, testando. E nós ajudamos a implementar. Às vezes, basta dar uma opinião sobre o que mudar, e o CIO alado com papel recebe um orçamento. Às vezes é necessário injetar diretamente sangue e lágrimas.
Tudo pode se tornar um problema, desde a escolha incorreta da arquitetura até alguns recursos do fluxo de trabalho.
Esses exemplos são sobre jogos em processos em diferentes empresas em todo o país.
Em relação à otimização do banco de dados, aqui está um exemplo típico. Existe um sistema médico (um dos que caíram). Eles nos chamaram para assistir. Chegamos quando eles já haviam desligado todos os módulos, exceto o fluxo de trabalho dos médicos, para que pelo menos de alguma forma as análises fossem realizadas e a gravação através do registro fosse. A gravação online, em particular, estava entre os módulos desativados. Consegui consertar tudo em uma semana. Inicialmente, o cliente pensou que os problemas estavam na camada do aplicativo: houve falhas de tempo limite e os threads travaram. Descobrimos que o problema está no banco de dados. Havia uma estrutura complexa, um monte de seções por dia e mês. Aconteceu que eles se esqueceram de alguns índices, os desenvolvedores não sabiam completamente o que se tornaria ao longo do tempo - e aqui está o resultado. Aproximadamente o mesmo conjunto de operações mais restrições de pesquisa (quando você precisa descarregar algo em um período, seria bom procurar entre essas datas e não em todo o banco de dados).
É claro que essa otimização nem sempre resolve o problema. Por exemplo, (por arquitetura), o setor de energia: o cliente pede para ver com o que o sistema está desligando. E lá tudo voou na entrega, mas depois de alguns anos havia muito mais documentos e tudo freou muito bem. O cliente sentou-se com um cronômetro no local de trabalho do operador e disse: esta operação agora leva 31 segundos, queremos 3. Este é 40 segundos, queremos 2. E assim por diante. É claro que medir dessa maneira não é muito correto, mas a tarefa é bastante específica e pode ser facilmente apresentada na forma de critérios objetivos. Nós não fizemos tudo, demoramos cerca de seis meses para "limpar". Na maioria das vezes, a lógica foi transferida para execução assíncrona, alguns dos bancos de dados foram alterados para noSQL, o mecanismo de pesquisa Solar foi instalado, em uma seção foi necessário selecionar o banco de dados mais ativo e torná-lo na memória. Como resultado, cerca de 90% das necessidades foram encerradas, mas em alguns lugares elas não puderam reduzir os atrasos. Este é o trabalho de bibliotecas de terceiros, as limitações físicas da plataforma e assim por diante. Tudo isso foi monitorado pelo monitoramento e foi capaz de provar claramente exatamente onde e o que fica mais lento.
Por que mais esse monitoramento pode ser necessário?
Utilizamos diferentes softwares de monitoramento para encontrar rapidamente processos inibitórios e otimizá-los. A equipe de TI de um dos principais clientes analisou como fazemos isso e pediu para implementá-lo em uma das instalações como uma ferramenta permanente. OK, monitorou todos os processos e nós, personalizou seu sistema para tarefas, trabalhou por quase quatro meses, mas criou um conjunto de ferramentas para apoiá-los. E existem 80 mil usuários, há a primeira e a segunda linhas dentro e a terceira com frequência - com prestadores de serviços ou também dentro.
Na segunda linha, há apenas esse conjunto de ferramentas. Agora, em cerca de 50% dos casos, eles usam o monitoramento para diagnosticar, procurar gargalos e causas de congelamentos, para que seus próprios desenvolvedores possam ver, entender e otimizar. É economizado muito tempo de suporte, identificando rapidamente a causa do problema. Após o piloto ser escalado por transação. Foi isso que levou quatro meses: há uma operação comercial para qualquer ação. Abrir um cartão de documento é uma transação comercial. Entrar em um sistema de fluxo de trabalho é uma transação comercial. Relatório de upload ou pesquisa também. 1.500 operações comerciais em quatro meses são descritas para entender onde e o que funciona. O monitoramento antes disso via chamadas http e vê os métodos e funções chamados, solicitações específicas. Antes disso, apenas os desenvolvedores entendiam que se tratava de acordo ou pesquisa de acordo. Para que o sistema de monitoramento mostre dados relevantes para diferentes linhas de suporte e negócios, configuramos todos esses pacotes.

A empresa também começou a cortar relatórios sobre seu próprio desenvolvimento de TI. Mais sobre os logs, ninguém escolhe especialmente.
A propósito, sobre tudo por que os sistemas de classe
APM são necessários e como escolhê-los, falaremos em um
webinar em 1º de outubro .
O que mais existem "tampões" do lado técnico?
Mais alguns exemplos. Um grande banco estrangeiro com escritórios de representação na Rússia. Apoiamos o Oracle DB e o Oracle Weblogic. Observou-se uma diminuição gradual da produtividade no sistema, as operações de negócios foram realizadas mais lentamente, o trabalho do operador tornou-se cada vez menos eficaz e, durante os períodos de importação e sincronização com o NSI, tudo estava congelando completamente. Nesses casos, usamos ferramentas padrão Java e Oracle para coletar dados: coletamos despejos de encadeamentos, analisamos em serviços gratuitos ou usamos ferramentas de análise auto-escritas, analisamos o AWR, rastreamos a execução de consultas SQL, analisamos planos e estatísticas de execução. Como resultado, além de itens padrão, como otimizar a composição dos índices e ajustar os planos de consulta, propusemos introduzir o particionamento dividindo os dados. Descobriu-se dois segmentos: histórico (deixou no HDD) e operacional - colocado no SSD. Antes disso, era bastante difícil entender quais dados se relacionam com o que, porque os dados históricos ainda precisavam ser descidos regularmente, tanto em relatórios longos quanto em operações comuns. Como resultado da separação correta, mais de 98% das operações principais não entraram em dados históricos lentos. O que é importante, não havia como entrar no código do sistema. Acontece que algumas de nossas recomendações exigem alterações no código do aplicativo, que não é suportado por nós, então geralmente concordamos.
O segundo exemplo: um fabricante internacional no campo da indústria leve e o segmento FMCG em geral. O tempo de inatividade do site principal custa cerca de 20 milhões de rublos. A carga média na base é de 200 AS (sessões ativas) com picos de 800-1000. Não é incomum que um otimizador de consultas perca a cabeça, os planos começam a flutuar não para melhor e começa uma concorrência feroz pelo cache do buffer. Ninguém está seguro disso, mas você pode reduzir a probabilidade: por dois meses monitoramos o sistema, analisando o perfil de carga, extinguindo incêndios ao longo do caminho, ajustando os esquemas de indexação e particionamento, lógica de processamento de dados ao lado do código PL / SQL. Aqui você precisa entender que, em um sistema vivo e em desenvolvimento, essa auditoria deve ser realizada regularmente, embora o teste de estresse ajude, mas nem sempre. E as empresas conduzem uma auditoria convidando oracleists de terceiros, mas raramente elas caem no nível da lógica de negócios e estão prontas para se aprofundar nos dados, interagindo com os desenvolvedores. Nós fazemos isso.
Bem, quero dizer que o problema nem sempre é a falta de limpeza regular ou suporte adequado. Muitas vezes, os problemas estão nos processos.
Por que precisamos de tais serviços com seus desenvolvedores ao vivo?
Porque os negócios adoram decisões, não processos. Esta é a principal razão.
A segunda é que nem todos podem alocar recursos para procurar um gargalo em um aplicativo, especialmente se for um aplicativo de terceiros. E longe de sempre em uma equipe, há pessoas com as competências necessárias. No momento, temos um engenheiro de sistema, engenheiros de rede, especialistas em Oracle e 1C, pessoas capazes de otimizar Java e o front-end de nossa equipe.
Bem, se você estiver interessado em se aprofundar nos detalhes,
em 1º de outubro, haverá nosso webinar sobre o que você pode fazer com antecedência, antes que tudo caia. E aqui está o meu e-mail para perguntas - sstrelkov@croc.ru.