Não há necessidade de representar especificamente a base do FIAS:

Você pode baixá-lo clicando no
link , este banco de dados está aberto e contém todos os endereços de objetos na Rússia (registro de endereços). O interesse nesse banco de dados é causado pelo fato de os arquivos que ele contém serem bastante volumosos. Assim, por exemplo, o menor é 2,9 GB. Propõe-se parar e ver se os pandas conseguem lidar com isso se você trabalhar em uma máquina com apenas 8 GB de RAM. E se você não consegue lidar, quais são as opções para alimentar este arquivo com pandas?
De coração, nunca encontrei essa base e isso é um obstáculo adicional, porque o formato dos dados apresentados não é totalmente claro.
Depois de baixar o arquivo fias_xml.rar com a base, obtemos o arquivo - AS_ADDROBJ_20190915_9b13b2a6-b3bd-4866-bd1c-7ab966fafcf0.XML. O arquivo está no formato xml.
Para um trabalho mais conveniente em pandas, é recomendável converter xml para csv ou json.
No entanto, todas as tentativas de converter programas de terceiros e o próprio python levam a um erro ou congelamento de "MemoryError".
Hum. E se eu cortar o arquivo e convertê-lo em partes? É uma boa ideia, mas todos os "cortadores" também tentam ler o arquivo inteiro na memória e travar, o próprio python, que segue o caminho dos "cortadores", não o corta. Obviamente, 8 GB não são suficientes? Bem, vamos ver.
Programa Vedit
Você precisará usar um programa vedit de terceiros.
Este programa permite que você leia um arquivo xml de 2,9 GB e trabalhe com ele.
Também permite dividi-lo. Mas há um pequeno truque.
Como você pode ver ao ler um arquivo, ele possui, entre outras coisas, uma tag AddressObjects de abertura:

Portanto, ao criar partes desse arquivo grande, não se esqueça de fechá-lo (tag).
Ou seja, o início de cada arquivo xml será assim:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
e final:
</AddressObjects>
Agora corte a primeira parte do arquivo (para as demais partes, as etapas são as mesmas).
No programa vedit:
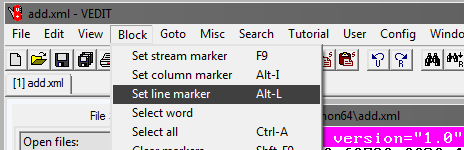
Em seguida, selecione Saltar e Nº da linha. Na janela que se abre, escreva o número da linha, por exemplo, 1.000.000:

Em seguida, você precisa ajustar o bloco selecionado para capturar até o final o objeto no banco de dados antes da tag de fechamento:
Tudo bem se houver uma leve sobreposição no objeto subsequente.
Em seguida, no programa vedit, salve o fragmento selecionado - Arquivo, Salvar como.
Da mesma forma, criamos as partes restantes do arquivo, marcando o início do bloco de seleção e o final em incrementos de 1 milhão de linhas.
Como resultado, você deve obter o quarto arquivo xml com um tamanho de aproximadamente 610 MB.
Finalizamos as partes xml
Agora você precisa adicionar tags nos arquivos xml recém-criados para que eles sejam lidos como xml.
Abra os arquivos no vedit, um por um e adicione no início de cada arquivo:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
e no final:
</AddressObjects>
Portanto, agora temos 4 partes xml do arquivo de origem dividido.
Xml para CSV
Agora traduza xml para csv escrevendo um programa python.
Código do programa
.
Usando o programa, você precisa converter todos os 4 arquivos em csv.
O tamanho do arquivo diminuirá, cada um terá 236 MB (compare com 610 MB em xml).
Em princípio, agora você já pode trabalhar com eles, através do Excel ou do bloco de notas ++.
No entanto, os arquivos ainda são o quarto em vez de um e não atingimos a meta - processar o arquivo em pandas.
Cole os arquivos em um
No Windows, isso pode se tornar uma tarefa difícil, portanto, usaremos o utilitário do console em python chamado csvkit. Instalado como um módulo python:
pip install csvkit
* Na verdade, este é um conjunto completo de utilitários, mas um será necessário a partir daí.
Depois de entrar na pasta com os arquivos para colar no console, faremos a colagem em um arquivo. Como todos os arquivos estão sem cabeçalho, atribuiremos os nomes de coluna padrão ao colar: a, b, c, etc .:
csvstack -H fias-0-10.csv fias-10-20.csv fias-20-30.csv fias-30-40.csv > joined2.csv
A saída é um arquivo csv finalizado.
Vamos trabalhar em pandas para otimizar o uso da memória
Se você enviar o arquivo imediatamente para os pandas
import pandas as pd import numpy as np gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a') print (gl.info(memory_usage='deep'))
e verifique quanta memória será necessária, o resultado pode surpreender desagradavelmente:

3 GB! E isso apesar do fato de que ao ler dados, a primeira coluna "foi" como uma coluna de índice * e, portanto, o volume seria ainda maior.
* Por padrão, o pandas define seu próprio índice de coluna.
Realizaremos a otimização usando métodos da
postagem e do
artigo anteriores:
- objeto na categoria;
- int64 em uint8;
- float64 em float32.
Para fazer isso, ao ler o arquivo, adicione dtypes e a leitura das colunas no código terá a seguinte aparência:
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' })
Agora, abrindo o arquivo pandas, o uso da memória seria sábio:

Resta adicionar ao arquivo csv, se desejado, os nomes das colunas reais da linha para que os dados façam sentido:
AOID,AOGUID,PARENTGUID,PREVID,FORMALNAME,OFFNAME,SHORTNAME,AOLEVEL,REGIONCODE,AREACODE,AUTOCODE,CITYCODE,CTARCODE,PLACECODE,STREETCODE,EXTRCODE,SEXTCODE,PLAINCODE,CODE,CURRSTATUS,ACTSTATUS,LIVESTATUS,CENTSTATUS,OPERSTATUS,IFNSFL,IFNSUL,OKATO,OKTMO,POSTALCODE
* Você pode substituir os nomes das colunas por esta linha, mas precisará alterar o código.
Salve as primeiras linhas do arquivo dos pandas
gl.head().to_csv('out.csv', encoding='ANSI',index_label='a')
e veja o que aconteceu no excel:

Código de programa para abertura otimizada de um arquivo csv com um banco de dados:
código import os import time import pandas as pd import numpy as np # : object-category, float64-float32, int64-int gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' }) pd.set_option('display.notebook_repr_html', False) pd.set_option('display.max_columns', 8) pd.set_option('display.max_rows', 10) pd.set_option('display.width', 80) #print (gl.head()) print (gl.info(memory_usage='deep')) # def mem_usage(pandas_obj): if isinstance(pandas_obj,pd.DataFrame): usage_b = pandas_obj.memory_usage(deep=True).sum() else: # , , usage_b = pandas_obj.memory_usage(deep=True) usage_mb = usage_b / 1024 ** 2 # return "{:03.2f} " .format(usage_mb)
Concluindo, vejamos o tamanho do conjunto de dados:
gl.shape
(3348644, 28)
3,3 milhões de linhas, 28 colunas.
Conclusão: com o tamanho inicial do arquivo csv de 890 MB, "otimizado" para trabalhar com pandas, ele ocupa 1,2 GB de memória.
Assim, com um cálculo aproximado, pode-se supor que um arquivo de 7,69 GB de tamanho possa ser aberto em pandas, tendo-o "otimizado" anteriormente.