O que é o reconhecimento de fala End2End e por que é necessário? Qual é a diferença da abordagem clássica? E por que, para treinar um bom modelo baseado no End2End, precisamos de uma enorme quantidade de dados - em nossa publicação hoje.
A abordagem clássica ao reconhecimento de fala
Antes de falar sobre a abordagem End2End, você deve primeiro falar sobre a abordagem clássica do reconhecimento de fala. Como ele é?

Extração de recursos
De fato, essa não é uma sequência completamente linear de blocos de ação. Vamos nos aprofundar em cada bloco com mais detalhes. Temos algum tipo de discurso de entrada, ele cai no primeiro bloco - Extração de Recursos. Este é um bloco que puxa sinais da fala. Deve-se ter em mente que a própria fala é uma coisa bastante complicada. Você precisa trabalhar com ele de alguma forma, para que existam métodos padrão para isolar recursos da teoria do processamento de sinais. Por exemplo, coeficientes Mel-cepstral (MFCC) e assim por diante.
Modelo acústico
O próximo componente é o modelo acústico. Pode ser baseado em redes neurais profundas ou com base em misturas de distribuições gaussianas e modelos ocultos de Markov. Seu principal objetivo é obter de uma seção do sinal acústico as distribuições de probabilidade de vários fonemas nesta seção.
Em seguida, vem o decodificador, que procura o caminho mais provável no gráfico com base no resultado da última etapa. O resgate é o toque final no reconhecimento, cuja principal tarefa é pesar novamente as hipóteses e produzir o resultado final.
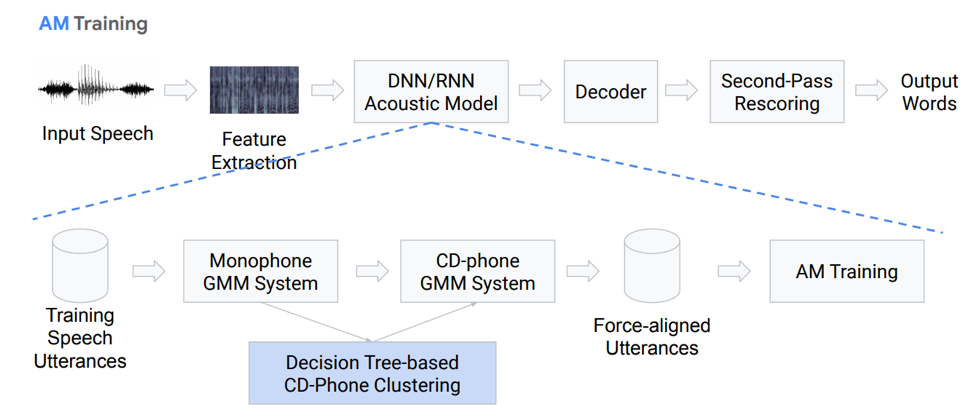
Vamos falar mais detalhadamente do modelo acústico. Como ela é? Temos algumas gravações de voz que entram em um determinado sistema baseado no GMM (mono Gausovy mix) ou HMM. Ou seja, temos representações na forma de fonemas, usamos monofones, ou seja, fonemas independentes do contexto. Além disso, fazemos misturas de distribuições gaussianas baseadas em fonemas sensíveis ao contexto. Ele usa clustering com base em árvores de decisão.
Então tentamos construir alinhamento. Um método completamente não trivial nos permite obter um modelo acústico. Não parece muito simples, na verdade é ainda mais complicado, existem muitas nuances, recursos. Mas, como resultado, um modelo treinado em centenas de horas é muito capaz de simular acústica.

Decodificador
O que é um decodificador? Este é o módulo que seleciona o caminho de transição mais provável de acordo com o gráfico HCLG, que consiste em 4 partes:
Módulo H baseado em HMM
Módulo de Dependência de Contexto C
Módulo de pronúncia L
Módulo de modelo de linguagem G
Construímos um gráfico sobre esses quatro componentes, com base nos quais decodificaremos nossos recursos acústicos em certas construções verbais.
Mais ou menos, é claro que a abordagem clássica é bastante complicada e difícil, é difícil de treinar, pois consiste em um grande número de partes separadas, para cada uma das quais você precisa preparar seus próprios dados para treinamento.
II Abordagem End2End
Então, o que é o reconhecimento de voz End2End e por que é necessário? Este é um determinado sistema, projetado para refletir diretamente a sequência de sinais acústicos na sequência de grafemas (letras) ou palavras. Você também pode dizer que este é um sistema que otimiza critérios que afetam diretamente a métrica final da avaliação da qualidade. Por exemplo, nossa tarefa é especificamente a palavra taxa de erro. Como eu disse, há apenas uma motivação - apresentar esses componentes complexos de vários estágios como um componente simples que exibirá diretamente, produzirá palavras ou grafemas a partir do discurso de entrada.
Problema de simulação
Aqui temos um problema imediatamente: a fala sonora é uma sequência e, na saída, também precisamos dar uma sequência. E até 2006, não havia maneira adequada de modelar isso. Qual é o problema da modelagem? Havia a necessidade de cada registro criar uma marcação complexa, o que implica em que segundo pronunciamos um som ou letra em particular. Esse é um layout complexo e muito complexo e, portanto, um grande número de estudos sobre esse tópico não foi realizado. Em 2006, foi publicado um interessante artigo de Alex Graves, “Classificação temporal conexionista” (CTC), no qual esse problema é, em princípio, resolvido. Mas o artigo foi publicado e não havia poder computacional suficiente na época. E algoritmos de reconhecimento de fala de trabalho reais apareceram muito mais tarde.
No total, temos: o algoritmo CTC foi proposto por Alex Graves há treze anos, como uma ferramenta que permite treinar / treinar modelos acústicos sem a necessidade dessa marcação complexa - alinhamento dos quadros de sequência de entrada e saída. Com base nesse algoritmo, inicialmente apareceu um trabalho que não estava completo no final do final; os fonemas foram emitidos como resultado. Vale ressaltar que os fonemas sensíveis ao contexto baseados no STS alcançam um dos melhores resultados no reconhecimento da liberdade de expressão. Mas também vale a pena notar que esse algoritmo, aplicado diretamente às palavras, permanece em algum lugar no momento.

O que é STS
Agora falaremos um pouco mais detalhadamente sobre o que é o STS e por que é necessário, que função ele executa. O STS é necessário para treinar o modelo acústico sem a necessidade de alinhamento quadro a quadro entre som e transcrição. O alinhamento quadro a quadro ocorre quando dizemos que um quadro específico de um som corresponde a um quadro da transcrição. Temos um codificador convencional que aceita sinais acústicos como entrada - ele fornece algum tipo de ocultação do estado, com base no qual obtemos probabilidades condicionais usando o softmax. O codificador geralmente consiste em várias camadas de LSTMs ou outras variações de RNNs. Vale ressaltar que o STS opera além dos caracteres comuns com um caractere especial chamado caractere vazio ou símbolo em branco. Para resolver o problema que surge devido ao fato de que nem todo quadro acústico possui um quadro na transcrição e vice-versa (ou seja, temos letras ou sons que soam muito mais longos e há sons curtos, repetidos), e há este símbolo em branco.
O STS propriamente dito visa maximizar a probabilidade final de sequências de caracteres e generalizar o possível alinhamento. Como queremos usar esse algoritmo em redes neurais, entende-se que devemos entender como funcionam seus modos de operação para frente e para trás. Não vamos nos debruçar sobre a justificativa matemática e os recursos da operação desse algoritmo, caso contrário, isso levará muito tempo.
O que temos: o primeiro ASR baseado no algoritmo STS aparece em 2014. Mais uma vez, Alex Graves apresentou uma publicação baseada no STS caractere por caractere que exibe diretamente a fala de entrada em uma sequência de palavras. Um dos comentários que eles fizeram neste artigo é que o uso de um modelo de som externo é importante para obter um bom resultado.
5 maneiras de melhorar o algoritmo
Existem muitas variações e melhorias diferentes no algoritmo acima. Aqui estão, por exemplo, os cinco mais populares recentemente.
• O modelo de linguagem está incluído na decodificação durante a primeira passagem
o [Hannun et al., 2014] [Maas et al., 2015]: decodificação direta de primeira passagem com um LM em vez de resgatar como em [Graves & Jaitly, 2014]
o [Miao et al., 2015]: estrutura EESEN para decodificação com WFSTs, kit de ferramentas de código aberto
• Treinamento em larga escala na GPU; Aumento de Dados várias línguas
o [Hannun et al., 2014; DeepSpeech] [Amodei et al., 2015; DeepSpeech2]: treinamento em GPU em larga escala; Aumento de Dados; Mandarim e Inglês
• Uso de unidades longas: palavras em vez de caracteres
o [Soltau et al., 2017]: metas de CTC no nível da palavra, treinadas em 125.000 horas de fala. Desempenho próximo ou melhor que um sistema convencional, mesmo sem o uso de um LM!
o [Audhkhasi et al., 2017]: Modelos de acústica direta para palavra no quadro de distribuição
Vale a pena prestar atenção à implementação do DeepSpeach como um bom exemplo de solução CTC end2end e a uma variação que usa um nível verbal. Mas há uma ressalva: para treinar esse modelo, você precisa de 125 mil horas de dados rotulados, o que na verdade é bastante real.
O que é importante observar sobre o STS
- Questões ou omissões. Para eficiência, é importante fazer suposições sobre independência. Ou seja, o STS pressupõe que a saída da rede em diferentes quadros seja condicionalmente independente, o que é realmente incorreto. Mas essa suposição é feita para simplificar, sem ela, tudo se torna muito mais complicado.
- Para obter um bom desempenho do modelo STS, é necessário o uso de um modelo de linguagem externo, pois a decodificação direta gananciosa não funciona muito bem.
Atenção
Que alternativa temos para este STS? Provavelmente não é segredo para ninguém que existe algo como Atenção ou "Atenção", que revolucionou em certa medida e foi diretamente das tarefas de tradução automática. E agora a maioria de todas as decisões de modelagem de sequência de sequência são baseadas nesse mecanismo. Como ele é? Vamos tentar descobrir. Pela primeira vez sobre Atenção nas tarefas de reconhecimento de fala, as publicações apareceram em 2015. Alguém Chen e Cherowski publicaram duas publicações semelhantes e diferentes ao mesmo tempo.
Vamos nos debruçar sobre o primeiro - chamado Ouvir, assistir e soletrar. Em nossa simulação clássica, na sequência em que temos um codificador e um decodificador, outro elemento é adicionado, chamado atenção. O echnoder executará as funções que o modelo acústico costumava executar. Sua tarefa é transformar o discurso de entrada em recursos acústicos de alto nível. Nosso decodificador executará as tarefas que executamos anteriormente no modelo de idioma e modelo de pronúncia (léxico); ele preverá automaticamente cada token de saída, como uma função dos anteriores. E a própria atenção dirá diretamente qual quadro de entrada é mais relevante / importante para prever essa saída.
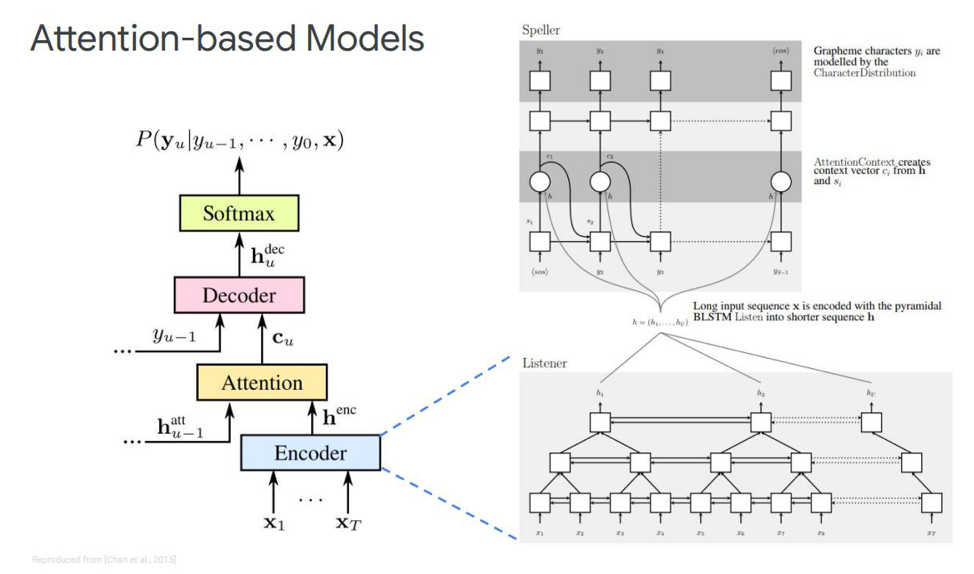
O que são esses blocos? O codificador ecológico no artigo é descrito como um ouvinte, é um RNN bidirecional clássico baseado em LSTMs ou qualquer outra coisa. Em geral, nada de novo - o sistema simplesmente simula a sequência de entrada em recursos complexos.
Atenção, por outro lado, cria um certo vetor de contexto C a partir desses vetores, o que ajudará a decodificar o decodificador corretamente diretamente, o próprio decodificador, que é, por exemplo, também alguns LSTMs que serão decodificados na sequência de entrada dessa camada de atenção, que já destacou os sinais de estado mais importantes, alguma sequência de saída de caracteres.
Também existem diferentes representações dessa própria atenção - que é a diferença entre essas duas publicações publicadas por Chen e Charowski. Eles usam atenção diferente. Chen usa Atenção com produtos pontuais e Charowski usa Atenção com Aditivos.

Para onde ir a seguir?
Trata-se de mais ou menos todas as principais realizações recebidas até o momento em questões de reconhecimento de fala não on-line. Que melhorias são possíveis aqui? Para onde ir a seguir? O mais óbvio é o uso de um modelo em pedaços de palavras, em vez de usar grafemas diretamente. Pode ser alguns morfemas separados ou algo mais.
Qual é a motivação para usar fatias de palavras? Normalmente, os modelos de linguagem do nível verbal têm muito menos perplexidade em comparação com o nível do grafema. A modelagem de palavras permite criar um decodificador mais forte do modelo de linguagem. E a modelagem de elementos mais longos pode melhorar a eficiência da memória em um decodificador baseado em LSTMs. Também permite que você se lembre potencialmente da ocorrência de palavras de frequência. Elementos mais longos permitem decodificar em menos etapas, o que acelera diretamente a inferência deste modelo.
Além disso, o modelo em pedaços de palavras nos permite resolver o problema das palavras OOV (fora do vocabulário) que surgem no modelo de linguagem, uma vez que podemos modelar qualquer palavra usando pedaços de palavras. E vale a pena notar que esses modelos são treinados para maximizar a probabilidade de um modelo de linguagem em um conjunto de dados de treinamento. Esses modelos são dependentes da posição e podemos usar o algoritmo guloso para decodificar.
Que outras melhorias além do modelo de palavras podem ser? Existe um mecanismo chamado atenção múltipla. Foi descrito pela primeira vez em 2017 para tradução automática. A atenção de várias cabeças implica um mecanismo que possui várias chamadas cabeças que permitem gerar uma distribuição diferente dessa mesma atenção, o que melhora os resultados diretamente.
Modelos online
Passamos para a parte mais interessante - estes são modelos online. É importante observar que o LAS não está sendo transmitido. Ou seja, este modelo não pode funcionar no modo de decodificação online. Vamos considerar os dois modelos online mais populares até o momento. Transdutor RNN e Transdutor Neural.
O transdutor RNN foi proposto por Graves em 2012-2017. A idéia principal é complicar um pouco nosso modelo STS com a ajuda de um modelo recursivo.
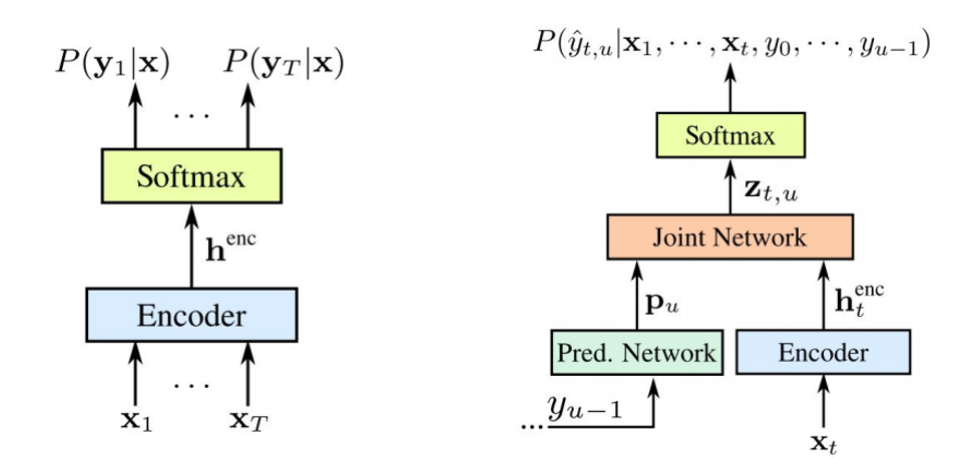
Vale a pena notar que os dois componentes são treinados juntos com os dados acústicos disponíveis. Como o STS, essa abordagem não requer alinhamento de quadros no conjunto de dados de treinamento. Como podemos ver na figura: à esquerda está o nosso STS clássico e à direita está o transdutor RNN. E temos dois novos elementos - a
rede prevista e a
rede de junção .
O codificador STS é exatamente o mesmo - este é o nível de entrada RNN, que determina a distribuição em todos os alinhamentos com todas as seqüências de saída que não excedem o comprimento da sequência de entrada - isso foi descrito por Graves em 2006. No entanto, a tarefa dessas conversões de texto em fala também é excluída, onde a sequência de entrada maior que a sequência de entrada do STS não modela o relacionamento entre as saídas. O transdutor expande esse mesmo STS, determinando a distribuição das seqüências de saída de todos os comprimentos e modelando em conjunto a dependência da entrada-saída e saída-saída.
Acontece que nosso modelo é capaz de lidar com as dependências da saída da entrada e da saída da última etapa.
Então, o que é uma
rede prevista ou uma rede preditiva? Ela tenta modelar cada elemento levando em consideração os anteriores, portanto, é semelhante ao RNN padrão com a previsão da próxima etapa. Somente com a capacidade adicional de fazer hipóteses nulas.
Como podemos ver na figura, temos uma rede prevista, que recebe o valor anterior da saída, e há um codificador, que recebe o valor atual da entrada. E na saída nós novamente, esse tem o valor atual
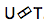
.
Transdutor Neural . Esta é uma complicação da abordagem clássica seq-2seq. A sequência acústica de entrada é processada pelo codificador para criar vetores de estado ocultos a cada etapa do tempo. Tudo parece ser como sempre. Mas há um elemento transdutor adicional que recebe um bloco de entrada a cada etapa e gera até tokens de saída M usando o modelo baseado em seq-2seq acima dessa entrada. O transdutor mantém seu estado em blocos usando conexões periódicas com as etapas de tempo anteriores.
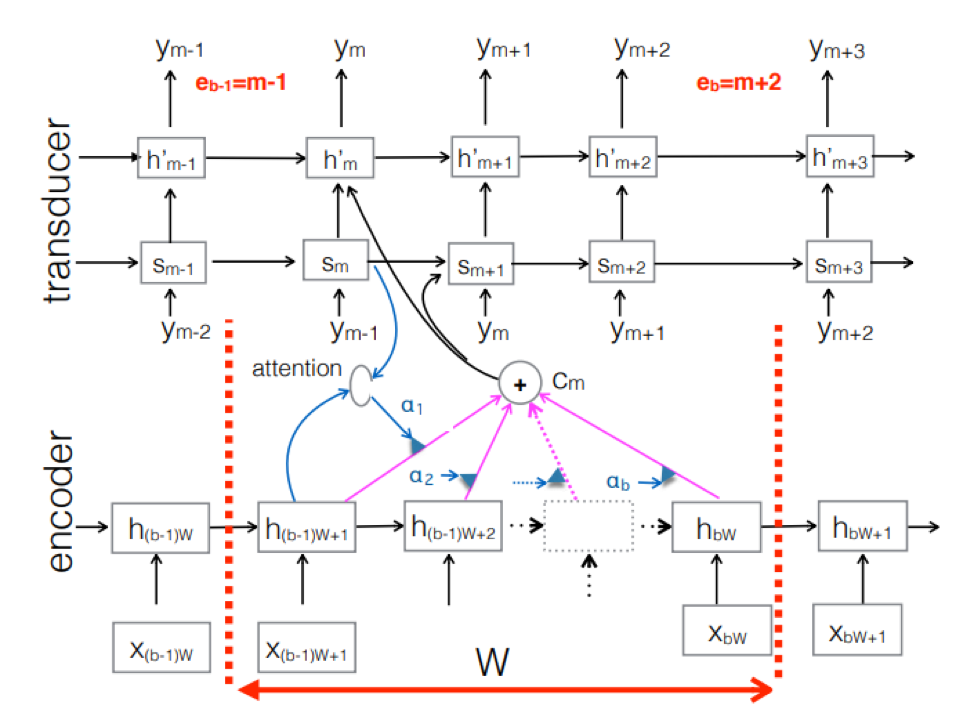 A figura mostra o transdutor, produzindo tokens para o bloco para a sequência usada no bloco do Ym correspondente.
A figura mostra o transdutor, produzindo tokens para o bloco para a sequência usada no bloco do Ym correspondente.Então, examinamos o estado atual do reconhecimento de fala com base na abordagem End2End. Vale dizer que, infelizmente, essas abordagens hoje exigem uma grande quantidade de dados. E os resultados reais alcançados pela abordagem clássica, exigindo de 200 a 500 horas de gravações sonoras marcadas para o treinamento de um bom modelo baseado no End2End, exigirão vários, ou talvez dezenas de vezes mais dados. Agora, este é o maior problema com essas abordagens. Mas talvez em breve tudo mude.
Desenvolvedor líder do centro de AI MTS Nikita Semenov.