As informações sobre o tópico da arquitetura de aplicativos de microsserviço, que já conseguiu preencher sua vantagem, são suficientes hoje para decidir se elas se adequam ao seu produto ou não. E não é segredo que as empresas que decidiram escolher esse caminho precisam enfrentar muitos desafios culturais e de engenharia. Uma das fontes de problemas é a sobrecarga que se multiplica em todos os lugares, e isso se aplica igualmente à rotina associada aos processos de produção.

Fonte da imagem:
Como você pode imaginar, o Anti-plágio é exatamente uma empresa dessas, onde gradualmente chegou-se ao entendimento de que estamos com os microsserviços ao longo do caminho. Mas antes de começar a comer o cacto, decidimos limpá-lo e cozinhá-lo. E como todas as únicas soluções verdadeiras e corretas para cada uma são únicas, em vez de slides universais do DevOps com lindas flechas, decidimos compartilhar nossa própria experiência e contar como já cobrimos uma parte considerável de nosso caminho especial para, espero, sucesso.
Se você está produzindo um produto verdadeiramente único, composto em larga escala por know-how, quase não há chance de se esquivar desse caminho em particular, pois é formado por muitos particulares: a partir da cultura e dos dados históricos desenvolvidos na empresa, terminando com sua própria especificidade e a pilha tecnológica usada .
Uma das tarefas de qualquer empresa e equipe é encontrar o equilíbrio ideal entre liberdades e regras, e os microsserviços levam esse problema a um novo nível. Isso pode parecer contradizer a própria idéia de microsserviços, o que implica ampla liberdade na escolha de tecnologias, mas se você não se concentrar diretamente em questões arquitetônicas e tecnológicas, mas observar os problemas de produção como um todo, o risco de estar em algum lugar da trama do “Jardim das Delícias Terrenas” é bastante tangível .
No entanto, no livro "Criando microsserviços", Sam Newman oferece uma solução para esse problema, onde, literalmente, desde as primeiras páginas, ele fala da necessidade de limitar a criatividade das equipes no âmbito de acordos técnicos. Portanto, uma das chaves para o sucesso, especialmente no contexto de um recurso limitado a mão livre, é a padronização de tudo o que só pode ser negociado e que ninguém realmente gostaria de fazer o tempo todo. Ao elaborar acordos, criamos regras claras do jogo para todos os participantes na produção e operação dos componentes do sistema. E conhecendo as regras do jogo, você deve concordar, jogá-lo deve ser mais fácil e agradável. No entanto, seguir essas regras em si pode se tornar uma rotina e causar desconforto aos participantes, o que leva diretamente a todos os tipos de desvios deles e, como conseqüência, ao fracasso de toda a ideia. E a saída mais óbvia é colocar todos os acordos no código, porque nem um único regulamento pode fazer o que a automação e as ferramentas convenientes podem usar, cujo uso é intuitivo e natural.
Seguindo nessa direção, fomos capazes de automatizar cada vez mais, e mais forte nosso processo se tornou um transportador de ponta a ponta para a produção de bibliotecas e micro (ou não) serviços.
Isenção de responsabilidadeEste texto não é uma tentativa de indicar “como deveria”, não há soluções universais, apenas uma descrição de nossa posição no caminho evolutivo e na direção escolhida. Todas as opções acima podem não agradar a todos, mas, no nosso caso, faz sentido em grande parte porque:
- O desenvolvimento da empresa em 90% dos casos é feito em C #;
- Não havia necessidade de começar do zero, parte dos padrões, abordagens e tecnologias aceitos - este é o resultado da experiência acumulada ou simplesmente de um legado histórico;
- Repositórios com projetos .NET, diferentemente de equipes, dezenas (e haverá mais);
- Gostamos de usar um pipeline de CI muito simples, evitando o aprisionamento do fornecedor o máximo possível;
- Para um desenvolvedor .NET comum, as palavras "contêiner", "janela de encaixe" e "Linux" ainda podem causar surtos de horror existencial, mas não quero quebrar ninguém no joelho.
Um pouco de fundo
Na primavera de 2017, a Microsoft apresentou ao mundo uma prévia do .NET Core 2.0, e este ano os astrólogos de C # imediatamente correram para declarar o Ano do Linux, então ...

Fonte da imagem:
Por algum tempo, não confiando em mágica, coletamos e testamos tudo no Windows e Linux, publicamos artefatos com alguns scripts SSH, tentamos configurar antigos pipelines de CI / CD no modo de faca suíço. Mas depois de algum tempo eles perceberam que estávamos fazendo algo errado. Além disso, as referências a microsserviços e contêineres eram cada vez mais frequentes. Por isso, também decidimos aproveitar a onda do hype e explorar essas instruções.
Já no estágio de reflexão sobre o possível futuro do microsserviço, surgiram várias questões, ignorando quais, arriscamos nesse mesmo futuro novos problemas que nós mesmos teríamos criado em troca de resolvê-los.
Primeiramente, quando observamos o lado da operação do mundo dos microsserviços teóricos sem regras, ficamos assustados com a perspectiva de caos com todas as conseqüências resultantes, incluindo não apenas a qualidade imprevisível do resultado, mas também conflitos entre equipes, desenvolvedores e engenheiros. E tentar fazer algumas recomendações, não sendo capaz de garantir a conformidade com elas, parecia imediatamente um empreendimento vazio.
Em segundo lugar, ninguém realmente sabia como criar contêineres corretamente e escrever arquivos docker, que, no entanto, já começaram a movimentar-se em nossos repositórios. Além disso, muitos “leem em algum lugar” que nem tudo é tão simples lá. Então, alguém teve que se aprofundar e descobrir, e depois retornar com as melhores práticas de montagem de contêineres. Mas a perspectiva de assumir o papel de um docker packer em tempo integral, deixado sozinho com pilhas de arquivos, por algum motivo, não inspirou ninguém na empresa. Além disso, como se viu, mergulhar uma vez claramente não é suficiente, e mesmo olhando à primeira vista, bom e certo, pode acabar errado ou simplesmente não muito bom.
E, em terceiro lugar, queria ter certeza de que as imagens obtidas com os serviços não apenas estivessem corretas do ponto de vista das práticas de contêineres, mas também seriam previsíveis em seu comportamento e teriam todas as propriedades e atributos necessários para simplificar o controle dos contêineres lançados. Em outras palavras, eu queria obter imagens com aplicativos igualmente configurados e gravar logs, fornecer uma interface única para obter métricas, ter um conjunto consistente de rótulos e similares. Também era importante que a montagem no computador do desenvolvedor produzisse o mesmo resultado que a montagem em qualquer sistema de IC, incluindo aprovação em testes e geração de artefatos.
Assim, nasceu a compreensão de que seria necessário algum processo para gerenciar e centralizar novos conhecimentos, práticas e padrões, e o caminho desde o primeiro commit para uma imagem do docker completamente pronta para a infraestrutura do produto deve ser unificado e o mais automatizado possível, não indo além dos termos que começam com a palavra contínua.
CLI vs. GUI
O ponto de partida para um novo componente, seja um serviço ou uma biblioteca, é criar um repositório. Esse estágio pode ser dividido em duas partes: criando e configurando o repositório na hospedagem do sistema de controle de versão (temos o Bitbucket) e inicializando-o com a criação de uma estrutura de arquivos. Felizmente, já existiam vários requisitos para ambos. Portanto, formalizá-los em código era uma tarefa lógica.
Então, qual deve ser o nosso repositório:
- Localizado em um dos projetos, no qual nome, direitos de acesso, políticas para aceitação de solicitações pull, etc;
- Contêm arquivos e diretórios necessários, como:
- arquivo com a configuração e as informações sobre o repositório
SolutionInfo.props (mais sobre isso abaixo); - códigos-fonte do projeto no diretório
src ; .gitignore , README.md , etc.
- Conter os submódulos Git necessários;
- O projeto deve ser derivado de um dos modelos.
Como a API REST do Bitbucket fornece controle total sobre a configuração dos repositórios, um utilitário especial foi criado para interagir com ela - o gerador de repositório. No modo pergunta-resposta, ela recebe do usuário todos os dados necessários e cria um repositório que atende totalmente a todos os nossos requisitos, a saber:
- Define um projeto no Bitbucket para escolher;
- Valida o nome de acordo com nosso contrato;
- Faz todas as configurações necessárias que não podem ser herdadas do projeto;
- Atualiza a lista de modelos personalizados (usamos o modelo de dotnet ) para o projeto e sugere a sua escolha;
- Preenche as informações mínimas necessárias sobre o repositório no arquivo de configuração e nos documentos
*.md ; - Ele conecta submódulos à configuração de pipeline de CI / CD (no nosso caso, são Bamboo Specs ) e scripts de montagem.
Em outras palavras, o desenvolvedor, iniciando um novo projeto, inicia o utilitário, preenche vários campos, seleciona o tipo de projeto e recebe, por exemplo, o “Hello world!” Completamente finalizado. um serviço que já esteja conectado ao sistema de IC, de onde o serviço pode até ser publicado se você fizer uma confirmação que altere a versão para diferente de zero.
O primeiro passo foi dado. Sem trabalho manual e erros, procurando documentação, registros e SMS. Agora vamos ao que foi gerado lá.
Estrutura
A padronização da estrutura do repositório criou raízes conosco por um longo tempo e foi necessária para simplificar a montagem, a integração com o sistema de IC e o ambiente de desenvolvimento. Inicialmente, partimos da ideia de que o pipeline no IC deve ser tão simples e, como você pode imaginar, padrão, o que garantiria a portabilidade e a reprodutibilidade da montagem. Ou seja, o mesmo resultado pode ser facilmente obtido em qualquer sistema de IC e no local de trabalho do desenvolvedor. Portanto, tudo o que não se relaciona aos recursos de um ambiente de integração contínua específico é submetido a um submódulo Git especial e é um sistema de construção auto-suficiente. Mais precisamente, o sistema de padronização de montagem. O pipeline em si, com uma aproximação mínima, deve executar apenas o script build.sh , pegar um relatório nos testes e iniciar uma implantação, se necessário. Para maior clareza, vamos ver o que acontece se você gerar o repositório SampleService em um projeto com o nome falado Sandbox .
. ├── [bamboo-specs] ├── [devops.build] │ ├── build.sh │ └── ... ├── [docs] ├── [.scripts] ├── [src] │ ├── [CodeAnalysis] │ ├── [Sandbox.SampleService] │ ├── [Sandbox.SampleService.Bootstrap] │ ├── [Sandbox.SampleService.Client] │ ├── [Sandbox.SampleService.Tests] │ ├── Directory.Build.props │ ├── NLog.config │ ├── NuGet.Config │ └── Sandbox.SampleService.sln ├── .gitattributes ├── .gitignore ├── .gitmodules ├── CHANGELOG.md ├── README.md └── SolutionInfo.props
Os dois primeiros diretórios são submódulos do Git. bamboo-specs é “Pipeline as Code” para o sistema Atlassian Bamboo CI (poderia haver algum arquivo Jenkins em seu lugar), devops.build é o nosso sistema de compilação, o qual discutirei em mais detalhes abaixo. O diretório .scripts também .scripts . O projeto .NET em si está localizado em src : NuGet.Config contém a configuração do repositório privado do NuGet , NLog.config configuração em tempo de desenvolvimento do NLog . Como você pode imaginar, usar o NLog em uma empresa também é um dos padrões. Entre as coisas interessantes aqui está o arquivo Directory.Build.props quase mágico. Por alguma razão, poucas pessoas conhecem essa possibilidade em projetos .NET, como a personalização do assembly . Em resumo, os arquivos com os nomes Directory.Build.props e Directory.Build.targets importados automaticamente para seus projetos e permitem configurar propriedades comuns para todos os projetos em um único local. Por exemplo, é assim que conectamos o analisador StyleCop.Analyzers e sua configuração do diretório CodeAnalysis a todos os projetos em estilo de código, definimos regras de versão e alguns atributos comuns para bibliotecas e pacotes ( empresa , direitos autorais etc.) e também conectamos via <Import> arquivo SolutionInfo.props , que é precisamente o mesmo arquivo de configuração do repositório, discutido acima. Ele já contém a versão atual, informações sobre os autores, a URL do repositório e sua descrição, além de várias propriedades que afetam o comportamento do sistema de montagem e os artefatos resultantes.
Exemplo `SolutionInfo.props` <?xml version="1.0"?> <Project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="devops.build/SolutionInfo.xsd"> <PropertyGroup> <Product>Sandbox.SampleService</Product> <BaseVersion>0.0.0</BaseVersion> <EntryProject>Sandbox.SampleService.Bootstrap</EntryProject> <ExposedPort>4000/tcp</ExposedPort> <GlobalizationInvariant>false</GlobalizationInvariant> <RepositoryUrl>https://bitbucket.contoso.com/projects/SND/repos/sandbox.sampleservice/</RepositoryUrl> <DocumentationUrl>https://bitbucket.contoso.com/projects/SND/repos/sandbox.sampleservice/browse/README.md</DocumentationUrl> <Authors>User Name <username@contoso.com></Authors> <Description>The sample service for demo purposes.</Description> <BambooBlanKey>SMPL</BambooBlanKey> </PropertyGroup> </Project>
Exemplo `Directory.Build.props` <Project> <Import Condition="Exists('..\SolutionInfo.props')" Project="..\SolutionInfo.props" /> <ItemGroup> <None Include="$(MSBuildThisFileDirectory)/CodeAnalysis/stylecop.json" Link="stylecop.json" CopyToOutputDirectory="Never"/> <PackageReference Include="StyleCop.Analyzers" Version="1.*" PrivateAssets="all" /> </ItemGroup> <PropertyGroup> <CodeAnalysisRuleSet>$(MSBuildThisFileDirectory)/CodeAnalysis/stylecop.ruleset</CodeAnalysisRuleSet> <GenerateDocumentationFile>true</GenerateDocumentationFile> <LangVersion>latest</LangVersion> <BaseVersion Condition="'$(BaseVersion)' == ''">0.0.0</BaseVersion> <BuildNumber Condition="'$(BuildNumber)' == ''">0</BuildNumber> <BuildNumber>$([System.String]::Format('{0:0000}',$(BuildNumber)))</BuildNumber> <VersionSuffix Condition="'$(VersionSuffix)' == ''">local</VersionSuffix> <VersionSuffix Condition="'$(VersionSuffix)' == 'prod'"></VersionSuffix> <VersionPrefix>$(BaseVersion).$(BuildNumber)</VersionPrefix> <IsPackable>false</IsPackable> <PackageProjectUrl>$(RepositoryUrl)</PackageProjectUrl> <Company>Contoso</Company> <Copyright>Copyright $([System.DateTime]::Now.Date.Year) Contoso Ltd</Copyright> </PropertyGroup> </Project>
Assembléia
Vale mencionar imediatamente que eu e meus colegas já tivemos uma experiência bem-sucedida no uso de diferentes sistemas de compilação . E, em vez de ponderar uma ferramenta existente com funcionalidade completamente incomum, decidiu-se fazer outra, especializada em nosso novo processo, e deixar a antiga em paz para realizar suas tarefas como parte de projetos legados. A idéia da correção era o desejo de obter uma ferramenta que transformasse o código em uma imagem do docker que atenda a todos os nossos requisitos, usando um único processo padrão, ao mesmo tempo em que elimina a necessidade de os desenvolvedores se aprofundarem nos meandros da montagem, mas preserva a possibilidade de alguma personalização.
A seleção de uma estrutura adequada foi iniciada. Com base nos requisitos de reprodutibilidade do resultado, tanto na construção de máquinas com Linux quanto nas máquinas Windows de qualquer desenvolvedor, a verdadeira plataforma cruzada e o mínimo de dependências predefinidas se tornaram uma condição essencial. Em momentos diferentes, consegui conhecer bastante bem algumas das estruturas de montagem para desenvolvedores .NET: do MSBuild e suas monstruosas configurações XML, que foram posteriormente traduzidas para Psake (Powershell), até o exótico FAKE (F #). Mas desta vez eu queria algo novo e leve. Além disso, já estava decidido que a montagem e o teste deveriam ser executados inteiramente em um ambiente de contêiner isolado, portanto, não planejei executar dentro de nada além dos comandos CLI do Docker e Git, ou seja, a maior parte do processo deveria ter sido descrita no arquivo Dockerfile.
Naquela época, o FAKE 5 e o Cake for .NET Core ainda não estavam prontos; portanto, com uma plataforma cruzada, esses projetos eram mais ou menos. Mas o meu querido PowerShell 6 Core já foi lançado e eu o usei ao máximo. Portanto, decidi voltar para o Psake novamente e, enquanto me vira, me deparei com um interessante projeto Invoke-Build , que é repensar o Psake e, como o próprio autor aponta, é o mesmo, apenas melhor e mais fácil. Assim é. Não vou me debruçar sobre isso em detalhes na estrutura deste artigo, observarei apenas que a compacidade me suborna se todas as funções básicas dessa classe de produtos estiverem disponíveis:
- A sequência de ações é descrita por um conjunto de tarefas inter-relacionadas (tarefas), que podem ser controladas usando suas interdependências e condições adicionais.
- Existem vários auxiliares úteis, por exemplo, exec {} para manipular corretamente os códigos de saída do aplicativo do console.
- Qualquer exceção ou interrupção do uso de Ctrl + C será processada corretamente em um bloco Exit-Build interno especial. Por exemplo, você pode excluir todos os arquivos temporários, um ambiente de teste ou desenhar um relatório agradável aos olhos.
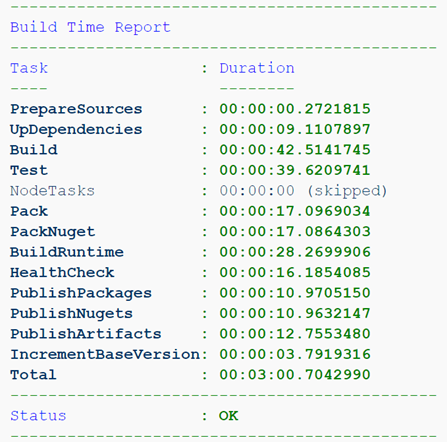
Dockerfile genérico
O próprio Dockerfile e o conjunto usando a docker build fornecem recursos de parametrização bastante fracos, e a flexibilidade dessas ferramentas não é um pouco maior do que a de uma alça de pá. Além disso, existem várias maneiras de tornar a imagem “errada”, muito grande, insegura, pouco intuitiva ou simplesmente imprevisível. Felizmente, a documentação da Microsoft já oferece vários exemplos de Dockerfile , que permitem entender rapidamente os conceitos básicos e criar seu primeiro Dockerfile, melhorando gradualmente mais tarde. Ele já usa um padrão de vários estágios e cria uma imagem especial " Test Runner " para executar testes.
Padrão e argumentos em vários estágios
O primeiro passo é dividir os estágios de montagem em outros menores e adicionar novos. Portanto, vale destacar o lançamento da dotnet build do dotnet build como um estágio separado, pois para projetos que contêm apenas bibliotecas, não faz sentido executar a dotnet publish . Agora, a nosso critério, só podemos executar as etapas de montagem necessárias usando
dotnet build --target <name>
Por exemplo, aqui estamos coletando um projeto contendo apenas bibliotecas. Os artefatos aqui são apenas pacotes NuGet, o que significa que não faz sentido coletar uma imagem de tempo de execução.
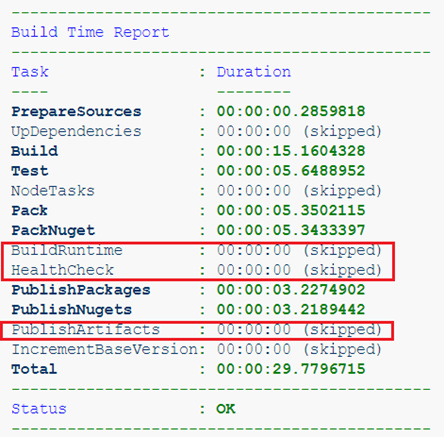
Ou já estamos construindo um serviço, mas a partir do ramo de recursos. Não precisamos de artefatos dessa montagem, é importante apenas passar nos testes e na verificação de saúde.
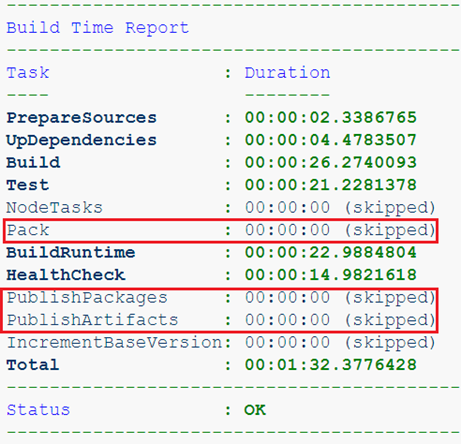
A próxima coisa a fazer é parametrizar o uso de imagens básicas. Já há algum tempo, no Dockerfile, a diretiva ARG pode ser colocada fora dos estágios de construção e os valores transferidos podem ser usados no nome da imagem base.
ARG DOTNETCORE_VERSION=2.2 ARG ALPINE_VERSION= ARG BUILD_BASE=mcr.microsoft.com/dotnet/core/sdk:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION} ARG RUNTIME_BASE=mcr.microsoft.com/dotnet/core/runtime:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION} FROM ${BUILD_BASE} AS restore ... FROM ${RUNTIME_BASE} AS runtime ...
Então, temos novas oportunidades, à primeira vista, e não oportunidades óbvias. Primeiro, se queremos criar uma imagem com um aplicativo ASP.NET Core, a imagem de tempo de execução precisará de uma imagem diferente: mcr.microsoft.com/dotnet/core/aspnet . O parâmetro com uma imagem básica não padrão deve ser salvo na configuração do repositório SolutionInfo.props e passado como argumento durante a montagem. Também facilitamos ao desenvolvedor o uso de outras versões das imagens do .NET Core: visualizações, por exemplo, ou mesmo personalizadas (você nunca sabe!).
Em segundo lugar, a capacidade de "expandir" o Dockerfile é ainda mais interessante, tendo participado das operações em outro assembly, cujo resultado será tomado como base na preparação da imagem de tempo de execução. Por exemplo, alguns de nossos serviços usam JavaScript e Vue.js, cujo código prepararemos em uma imagem separada, simplesmente adicionando um Dockerfile "em expansão" ao repositório:
ARG DOTNETCORE_VERSION=2.2 ARG ALPINE_VERSION= ARG RUNTIME_BASE=mcr.microsoft.com/dotnet/core/aspnet:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION} FROM node:alpine AS install WORKDIR /build COPY package.json . RUN npm install FROM install AS src COPY [".babelrc", ".eslintrc.js", ".stylelintrc", "./"] COPY ClientApp ./ClientApp FROM src AS publish RUN npm run build-prod FROM ${RUNTIME_BASE} AS appbase COPY --from=publish /build/wwwroot/ /app/wwwroot/
Vamos coletar essa imagem com a tag, que passaremos para o estágio de montagem da imagem de tempo de execução do serviço ASP.NET como argumento para RUNTIME_BASE. Assim, você pode expandir a montagem o quanto quiser, inclusive, pode parametrizar o que não pode fazer na docker build . Deseja parametrizar a adição de Volume? Fácil:
ARG DOTNETCORE_VERSION=2.2 ARG ALPINE_VERSION= ARG RUNTIME_BASE=mcr.microsoft.com/dotnet/core/aspnet:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION} FROM ${RUNTIME_BASE} AS runtime ARG VOLUME VOLUME ${VOLUME}
Iniciamos a montagem deste Dockerfile quantas vezes quisermos adicionar diretivas VOLUME. Usamos a imagem resultante como base para o serviço.
Executando testes
Em vez de executar testes diretamente nas etapas de montagem, é mais correto e mais conveniente fazer isso em um contêiner especial "Test Runner". Transmitindo brevemente a essência dessa abordagem, observo que ela permite:
- Execute todos os lançamentos agendados, mesmo se um deles travar;
- Monte o diretório do sistema de arquivos host no contêiner para receber um relatório de teste, que é vital ao criar no sistema de IC;
- Execute o teste em um ambiente temporário passando o nome de sua rede para o
docker run --network <test_network_name> .
O último parágrafo significa que agora podemos executar não apenas testes de unidade, mas também testes de integração. Descrevemos o ambiente, por exemplo, em docker-compose.yaml e o executamos por toda a compilação. Agora você pode verificar a interação com o banco de dados ou nosso outro serviço e salvar os logs deles, caso precise deles para análise.
Sempre verificamos a imagem de tempo de execução resultante para passar na verificação de integridade, que também é um tipo de teste. Um ambiente de teste temporário pode ser útil aqui se o serviço que está sendo testado tiver dependências em seu ambiente.
Também observo que a abordagem com os contêineres de corredor montados no estágio com a dotnet build servirá muito bem para o lançamento da dotnet publish dotnet pack , dotnet pack dotnet nuget push e dotnet nuget push . Isso nos permitirá salvar artefatos de montagem localmente.
Verificação de integridade e dependências do SO
Muito rapidamente ficou claro que nossos serviços padronizados ainda seriam únicos à sua maneira. Eles podem ter requisitos diferentes para pacotes pré-instalados do sistema operacional na imagem e diferentes maneiras de verificar a verificação de integridade. E se o curl é adequado para verificar o status de um aplicativo da Web, então para um back-end de gRPC ou, além disso, um serviço sem cabeça, ele será inútil e também será um pacote extra no contêiner.
Para dar aos desenvolvedores a oportunidade de personalizar a imagem e expandir sua configuração, usamos o contrato em vários scripts especiais que podem ser redefinidos no repositório:
.scripts ├── healthcheck.sh ├── run.sh └── runtime-deps.sh
O script healthcheck.sh contém os comandos necessários para verificar o status:
Usando o runtime-deps.sh , as dependências são instaladas e, se necessário, são executadas quaisquer outras ações necessárias no sistema operacional básico para o funcionamento normal do aplicativo dentro do contêiner. Exemplos típicos:
Portanto, a maneira de gerenciar dependências e verificar o estado é padronizada, mas há espaço para alguma flexibilidade. Quanto ao run.sh , é mais adiante.
Script de ponto de entrada
Tenho certeza de que todos que ao menos uma vez escreveram seu Dockerfile se perguntaram qual diretiva usar - CMD ou ENTRYPOINT . Além disso, essas equipes também têm duas opções de sintaxe, que da maneira mais dramática afetam o resultado. Não explicarei a diferença em detalhes, repetindo depois daqueles que já esclareceram tudo . Apenas recomendo lembrar que em 99% das situações é correto usar ENTRYPOINT e a sintaxe exec:
PONTO DE ENTRADA ["/ caminho / para / executável"]
Caso contrário, o aplicativo iniciado não poderá processar corretamente os comandos do SO, como SIGTERM, etc., e você também poderá ter problemas na forma de processos zumbis e tudo relacionado ao problema do PID 1 . Mas e se você quiser iniciar o contêiner sem iniciar o aplicativo? Sim, você pode substituir o ponto de entrada:
docker run --rm -it --entrypoint ash <image_name> <params>
Não parece muito confortável e intuitivo, certo? Mas há boas notícias: você pode fazer melhor! Ou seja, use um script de ponto de entrada . Esse script permite tornar arbitrariamente complexa a inicialização ( exemplo ), processamento de parâmetros e o que você desejar.
No nosso caso, por padrão, o cenário mais simples, mas ao mesmo tempo funcional, é usado:
Permite controlar o lançamento do contêiner de maneira muito intuitiva:
docker run <image> env - apenas executa env na imagem, mostrando variáveis de ambiente.
docker run <image> -param1 value1 - inicia o serviço com os argumentos especificados.
Separadamente, é preciso prestar atenção ao comando exec : sua presença antes de chamar o aplicativo executável fornecerá o cobiçado PID 1 em seu contêiner.
O que mais
Obviamente, durante mais de um ano e meio de uso, o sistema de compilação acumulou muitas funcionalidades diferentes. Além de gerenciar as condições de lançamento de vários estágios, trabalhando com o armazenamento de artefatos, versão e outros recursos, também foi desenvolvido nosso "padrão" do contêiner. Ele foi preenchido com atributos importantes que o tornam mais previsível e conveniente em termos administrativos:
- Todas as etiquetas de imagem necessárias estão instaladas: versões, números de revisão, links para documentação, autor e outros.
- No contêiner de tempo de execução, a configuração do NLog é redefinida para que, após a publicação, todos os logs sejam imediatamente apresentados em um formulário estruturado usando json, cuja versão é versionada.
- As regras de análise estática e quaisquer outros padrões são mantidos automaticamente atualizados.
Essa ferramenta, é claro, sempre pode ser aprimorada e desenvolvida. Tudo depende de necessidades e imaginação. Por exemplo, além de tudo, era possível empacotar utilitários cli adicionais em uma imagem. Um desenvolvedor pode facilmente colocá-los em uma imagem especificando no arquivo de configuração apenas o nome do utilitário necessário e o nome do projeto .NET a partir do qual ele deve ser construído (por exemplo, nossa verificação de healthcheck ).
Conclusão
Descrito aqui é apenas parte de uma abordagem integrada à padronização. , , , , , . . , .
, Linux , - . , , . , , , Code Style, , .
, ! , « », , . , Docker .