
Olá pessoal! Recentemente,
foi realizado um webinar aberto
"Fornecendo armazenamento tolerante a falhas" . Ele examinou quais problemas surgem no design das arquiteturas, por que a falha do servidor não é uma desculpa para travar um servidor e como reduzir ao mínimo o tempo de inatividade. O webinar foi organizado por
Ivan Remen , chefe de desenvolvimento de servidores do Citimobil e professor do curso
"High Load
Architect" .
Por que se preocupar com a resiliência de armazenamento?
Pensar na resiliência do armazenamento escalável e entender os problemas básicos de armazenamento em cache deve estar
no estágio de inicialização . É claro que, quando você cria uma inicialização, no início você cria a versão mínima do produto. Porém, quanto mais você cresce, mais rapidamente obtém produtividade, o que pode levar a uma parada completa dos negócios. E se você receber dinheiro de investidores, é claro que eles também exigirão crescimento constante e novos recursos de negócios. Para encontrar o equilíbrio certo, você precisa escolher entre velocidade e qualidade. Ao mesmo tempo, você não pode sacrificar um ou outro, e se você sacrifica - então conscientemente e dentro de certos limites. No entanto, não existem receitas universais aqui, assim como soluções ideais.
Descansamos contra a base da leitura
Este é o primeiro cenário. Imagine que temos 1 servidor, cuja carga no processador ou no disco rígido é de 99%. Nesse caso:
- 90% dos pedidos são lidos;
- 10% dos pedidos são um registro.
A melhor solução nessa situação é pensar em réplicas. Porque Esta é a solução mais barata e fácil.
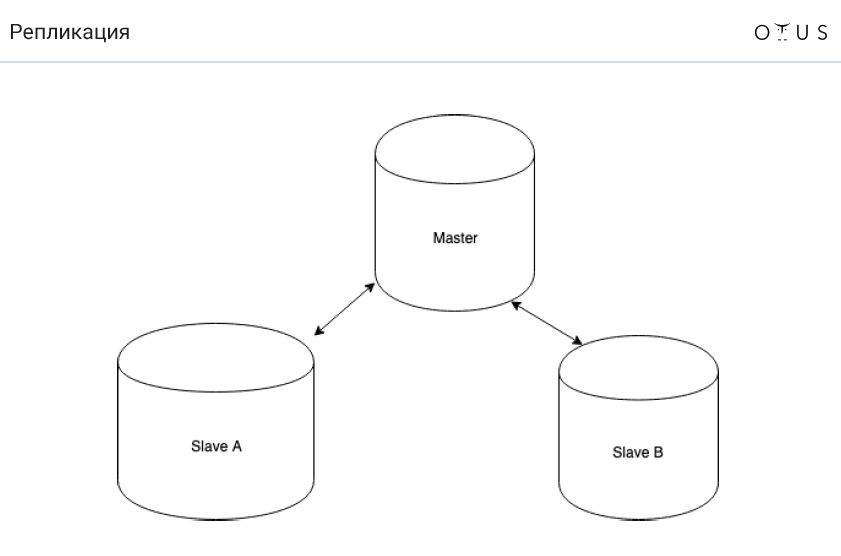
A replicação é classificada:
1. Por sincronização:
- síncrona;
- assíncrono;
- semi-síncrona.
2. De acordo com dados portáteis:
- lógico (baseado em linhas, baseado em instruções, misto);
- físico.
3. Pelo número de nós por registro:
- mestre / escravo;
- mestre / mestre.
4. Pelo iniciador:
E agora a
tarefa é sobre um balde de água . Imagine que temos MySQL e replicação assíncrona de mestre-escravo. A limpeza está ocorrendo no centro de distribuição e, como resultado, o limpador tropeça e derrama um balde de água no servidor com a base principal. A automação alterna com êxito um dos mais recentes escravos para o modo mestre. E tudo continua a funcionar. Onde está o problema?
A resposta é simples - perdemos transações que não conseguimos replicar. Consequentemente, a propriedade D do ACID é violada.
Agora vamos falar sobre como a replicação assíncrona (MySQL) funciona:
- registrar uma transação no mecanismo de armazenamento (InnoDB);
- registrar uma transação em um log binário;
- conclusão da transação no mecanismo de armazenamento;
- confirmação de devolução ao cliente;
- transferir parte do log para a réplica;
- execução de uma transação em uma réplica (p. 1-3).
E agora a pergunta é: o que precisa ser alterado nos parágrafos acima para que nunca terminemos com replicação?
E apenas dois pontos precisam ser trocados: 4 e 5 ("transferindo parte do log para a réplica" e "retornando confirmação ao cliente"). Assim, se o nó principal desaparecer, sempre teremos um log de transações em algum lugar (ponto 2). E se a transação for registrada no log binário, a transação também acontecerá em algum momento.
Como resultado, obtemos replicação semi-síncrona (MySQL), que funciona da seguinte maneira:
- registrar uma transação no mecanismo de armazenamento (InnoDB);
- registrar uma transação em um log binário;
- conclusão da transação no mecanismo de armazenamento;
- transferir parte do log para a réplica;
- confirmação de devolução ao cliente;
- execução de uma transação em uma réplica (p. 1-3).
Sincronização vs semi-sincronização e async vs semi-sincronização
Por alguma razão, na Rússia, a maioria das pessoas não ouviu falar sobre replicação semi-síncrona. A propósito, é bem implementado no PostgreSQL e não muito no MySQL. Leia mais sobre isso
aqui , mas a tese pode ser formulada da seguinte maneira:
- a replicação semi-síncrona ainda está atrasada (mas não tanto) quanto a assíncrona;
- nós não perdemos transações;
- basta levar os dados para apenas um escravo.
A propósito, a replicação semi-síncrona é usada no Facebook.
Descansamos contra a base recorde
Vamos falar sobre um problema diametralmente oposto quando temos:
- 90% dos pedidos - registro;
- 10% dos pedidos são lidos;
- 1 servidor;
- carga - 99% (processador ou disco rígido).
Fragmento conhecido vem em socorro aqui. Mas agora vamos falar de outra coisa:

Muitas vezes, nesses casos, eles começam a usar o mestre-mestre. No entanto,
isso não ajuda nessa situação . Porque É simples: o registro no servidor não fica menor. Afinal, a replicação implica que há dados em todos os nós. Com a replicação baseada em instruções, o SQL será executado em TODOS os nós. C baseado em linha é um pouco mais fácil, mas ainda caro. E também mestre-mestre tem problemas com conflitos.
De fato, faz sentido usar master-master nas seguintes situações:
- tolerância a falhas de gravação (a idéia é que você sempre grave em apenas um mestre). Você pode implementar usando o endereço IP virtual ;
- sistemas distribuídos geograficamente.
No entanto, lembre-se de que a replicação mestre-mestre é sempre difícil. E muitas vezes mestre-mestre traz mais problemas do que resolve.
Sharding
Já mencionamos sharding. Em resumo, o sharding é uma maneira infalível de escalar um registro. A ideia é distribuir dados entre servidores independentes (mas nem sempre). Cada fragmento pode se replicar independentemente.
A primeira regra do sharding é que os dados usados juntos devem estar no mesmo shard. A
sharding_key -> shard_id funciona
sharding_key -> shard_id . Assim,
sharding_key para os dados que são usados juntos devem corresponder. A primeira dificuldade é que, se você escolher a chave
sharding_key errada, será muito difícil reorganizar tudo. Em segundo lugar, se você tiver algum tipo de
sharding_key , algumas solicitações serão muito difíceis de executar. Por exemplo, você não pode encontrar o valor médio.
Para demonstrar isso, vamos imaginar que temos dois shards com três valores em cada: (1; 2; 3) (0; 0; 500). O valor médio será igual a (1 + 2 + 3 + 500) / 6 = 84.33333.
Agora imagine que temos dois servidores independentes. E recalcule o valor médio separadamente para cada fragmento. No primeiro deles, temos 2, no segundo - 166.66667. E mesmo que calculemos a média desses valores, ainda obteremos um número que será diferente do correto: (2 + 166.66667) / 2 = 86.33334.
Ou seja, a
média dos meios não é igual à média de tudo: avg(a, b, c, d) != avg(avg(a, b) + (avg(c, d))
Matemática simples, mas é importante lembrar.
Tarefa de sharding
Suponha que tenhamos um sistema de diálogo em uma rede social. Só pode haver 2 pessoas em um diálogo. Todas as mensagens estão em uma tabela, na qual existe:
- ID da mensagem
- ID do remetente
- ID do destinatário
- texto da mensagem;
- data em que a mensagem foi enviada;
- algumas bandeiras.
Qual chave de sharding deve ser escolhida com base no fato de termos a primeira regra de sharding descrita acima?
Existem várias opções para resolver esse problema clássico:
- crc32 (id_src // id_dst);
- crc32 (1 // 2)! = crc32 (2 // 1);
- crc32 (de + a)% n;
- crc32 (min (de, para). max (de, para))% n.
Caches
E algumas palavras sobre caches. Podemos dizer que os
caches são um antipadrão , embora se possa argumentar com essa afirmação (muitas pessoas gostam de usar caches). Mas, em geral, os caches são necessários apenas para aumentar a taxa de resposta. E eles não podem ser configurados para suportar a carga.
A conclusão é simples - devemos viver em silêncio, sem caches. A única razão pela qual eles podem ser necessários é exatamente pelo mesmo motivo pelo qual são necessários no processador: aumentar a velocidade de resposta. Se o banco de dados não suportar a carga como resultado do cache desaparecer, isso é ruim. Esse é um padrão arquitetural extremamente malsucedido, portanto não deve ser. E quaisquer recursos que você tiver, um dia seu cache certamente cairá, independentemente do que você faça.
Os problemas de cache são:- comece com um cache frio;
- problema de invalidação de cache;
- consistência de cache.
Se você ainda usa caches, o hash consistente o ajudará. Essa é uma maneira de criar tabelas de hash distribuídas, nas quais a falha de um ou mais servidores de armazenamento não leva à necessidade de uma realocação completa de todas as chaves e valores armazenados. No entanto, você pode ler mais sobre isso
aqui .

Bem, obrigado por assistir! Para não perder nada da última palestra, é melhor
assistir ao webinar inteiro .