
Esta é uma instrução passo a passo para a classificação de imagens multiespectrais do satélite Landsat 5. Hoje, em várias áreas, o aprendizado profundo domina como uma ferramenta para resolver problemas complexos, incluindo os geoespaciais. Espero que você esteja familiarizado com os conjuntos de dados de satélite, em particular o Landsat 5 TM. Se você estiver um pouco familiarizado com os algoritmos de aprendizado de máquina, isso ajudará você a aprender rapidamente este manual. E para aqueles que não entendem, será suficiente saber que, de fato, o aprendizado de máquina consiste em estabelecer relações entre várias características (um conjunto de atributos X) de um objeto com sua outra propriedade (valor ou etiqueta, a variável de destino Y). Alimentamos o modelo com muitos objetos para os quais as características e o valor do indicador / classe de destino do objeto (dados rotulados) são conhecidos e o treinamos para que ele possa prever o valor da variável de destino Y para novos dados (sem marcação).
Qual é o principal problema com imagens de satélite?
Duas ou mais classes de objetos (por exemplo, edifícios, terrenos baldios e poços de fundação) em imagens de satélite podem ter as mesmas características espectrais do valor; portanto, nos últimos vinte anos, sua classificação tem sido uma tarefa difícil.
Por esse motivo, é possível usar modelos clássicos de aprendizado de máquina com e sem um professor, mas sua qualidade estará longe do ideal. Eles sempre têm as mesmas desvantagens. Considere um exemplo:

Se você usar uma linha vertical como classificador e movê-la ao longo do eixo X, não será fácil classificar imagens de casas. Os dados são distribuídos para que seja impossível separá-los em classes usando uma linha vertical (nesses casos, diz-se que "objetos de classes diferentes não são linearmente separáveis"). Mas isso não significa que as casas não possam ser classificadas!
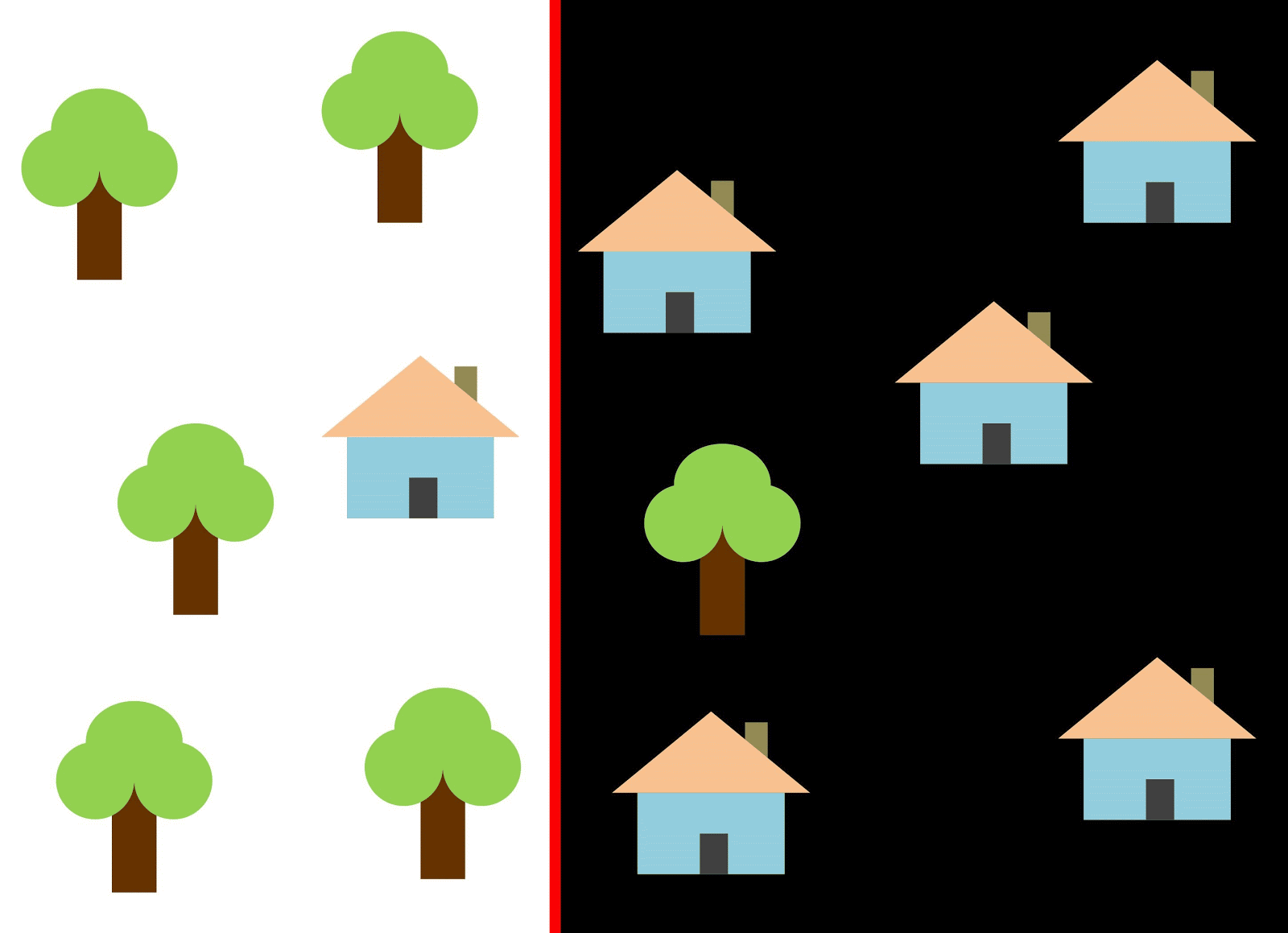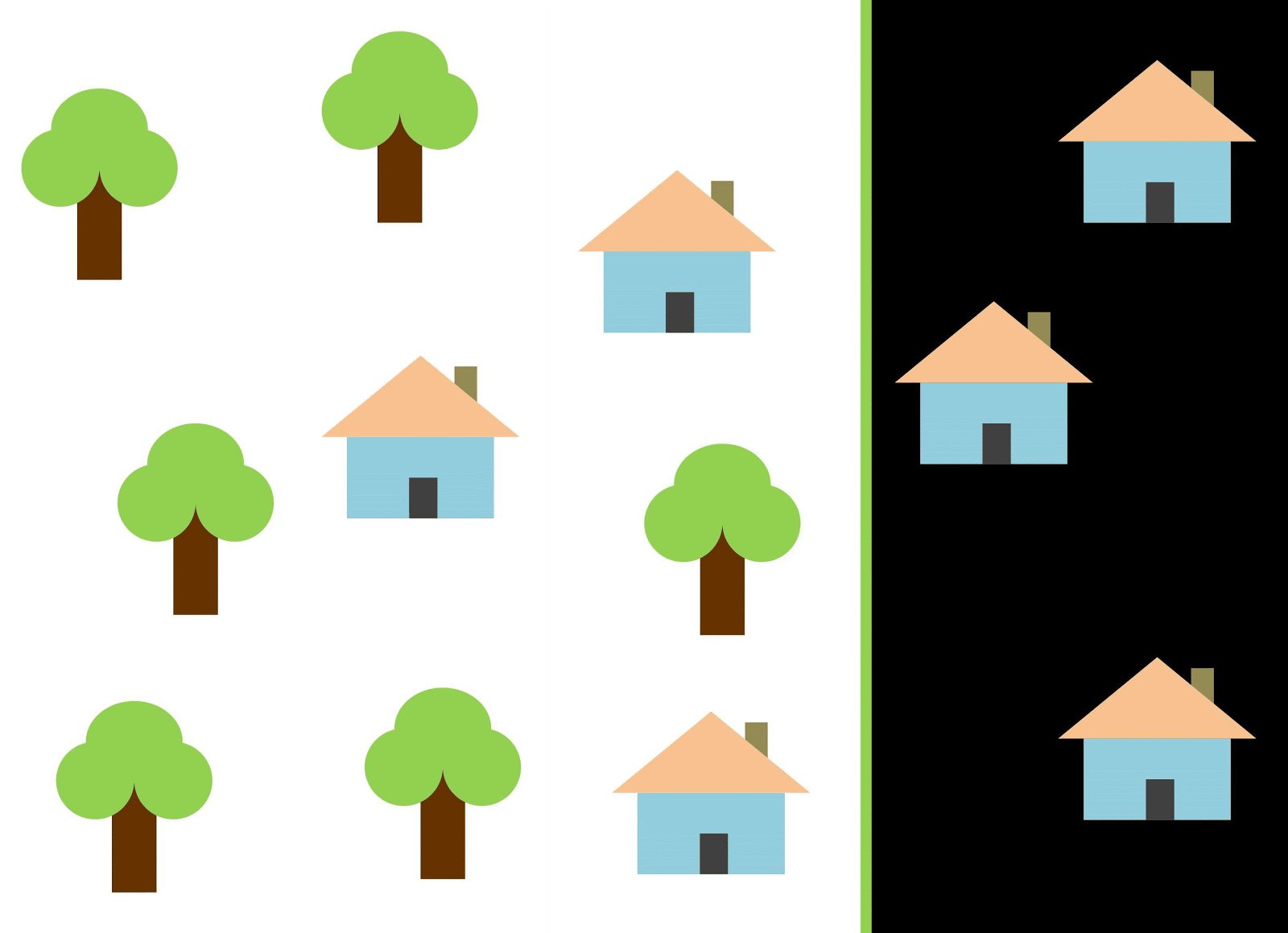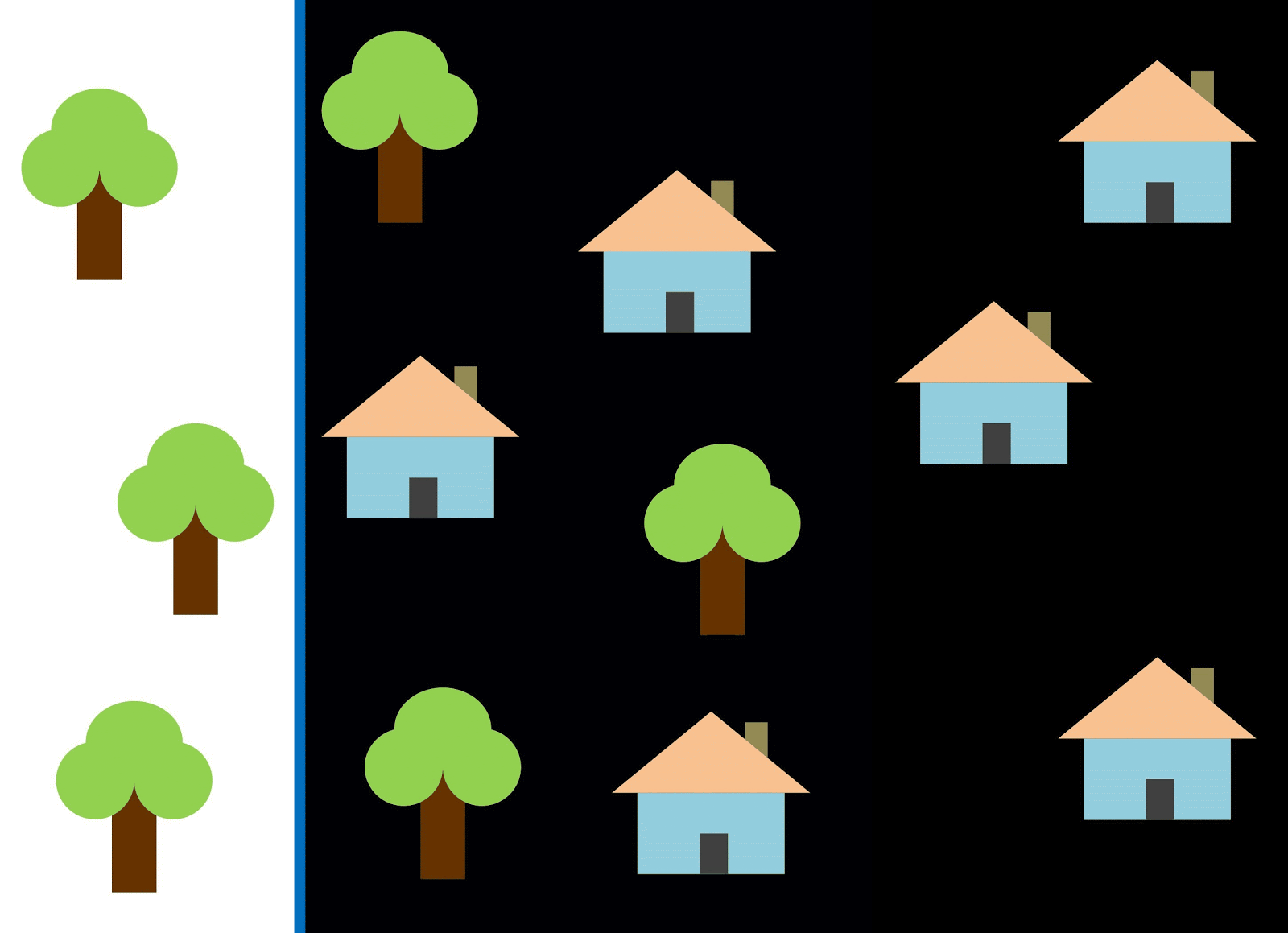
Vamos usar a linha vermelha para separar as duas classes. Nesse caso, o classificador identificou a maioria das casas, mas uma casa não foi atribuída à sua classe e mais três árvores foram atribuídas por engano às "casas". Para não perder uma única casa, você pode usar o classificador na forma de uma linha azul. Então, tudo será coberto em casa, ou seja, dizemos que a métrica de recall (plenitude) é alta. No entanto, nem todos os valores classificados acabaram sendo casas, ou seja, ao mesmo tempo, obtivemos um valor baixo da métrica de precisão. Se usarmos a linha verde, todas as imagens classificadas como casas serão realmente casas, ou seja, o classificador mostrará alta precisão. Nesse caso, a plenitude será menor, uma vez que as três casas não serão contabilizadas. Na maioria dos casos, precisamos encontrar um compromisso entre precisão e perfeição.
Esse problema de casas e árvores é semelhante ao problema de prédios, terrenos baldios e poços. A prioridade das métricas de classificação de imagens de satélite pode variar dependendo da tarefa. Por exemplo, se você precisa garantir que todos os territórios construídos sejam classificados como prédios sem exceção, e esteja pronto para tolerar a presença de pixels de outras classes com assinaturas semelhantes, que também serão classificadas como prédios, será necessário um modelo com uma alta completude. E se for mais importante classificar um edifício, sem adicionar pixels de outras classes, e você estiver pronto para abandonar a classificação de territórios mistos, escolha um classificador com alta precisão. No caso de casas e árvores, o modelo usual usará a linha vermelha, mantendo um equilíbrio entre precisão e perfeição.
Dados utilizados
Como sinais, usaremos os valores de seis faixas (banda 2 - banda 7) da imagem do Landsat 5 TM e tentaremos prever a classe de desenvolvimento binário. Para treinamento e teste, serão utilizados dados multiespectrais (imagens e uma camada com uma classe de construção binária) com o Landsat 5 para 2011 para Bangalore. E para previsão serão utilizados dados multiespectrais do Landsat 5 obtidos em 2005 em Hyderabad.
Como usamos dados marcados para o ensino, isso é chamado de ensino com o professor.
 Dados de treinamento multiespectrais e a camada binária correspondente com o desenvolvimento.
Dados de treinamento multiespectrais e a camada binária correspondente com o desenvolvimento.Para criar uma rede neural, usaremos o Python - a biblioteca do Google Tensorflow. Também precisaremos dessas bibliotecas:
- pyrsgis - para ler e escrever GeoTIFF.
- scikit-learn - para pré-processamento de dados e avaliação de precisão.
- numpy - para operações básicas com matrizes.
E agora, sem mais delongas, vamos escrever o código.
Coloque os três arquivos em um diretório, escreva o caminho e os nomes dos arquivos de entrada no script e leia os arquivos GeoTIFF.
import os from pyrsgis import raster os.chdir("E:\\yourDirectoryName") mxBangalore = 'l5_Bangalore2011_raw.tif' builtupBangalore = 'l5_Bangalore2011_builtup.tif' mxHyderabad = 'l5_Hyderabad2011_raw.tif'
O módulo
raster do pacote
pyrsgis lê dados de geolocalização GeoTIFF e valores de número digital (DN) como matrizes NumPy separadas. Se você estiver interessado em detalhes, leia
aqui .
Agora exibimos o tamanho dos dados lidos.
print("Bangalore multispectral image shape: ", featuresBangalore.shape) print("Bangalore binary built-up image shape: ", labelBangalore.shape) print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)
Resultado:
Bangalore multispectral image shape: 6, 2054, 2044 Bangalore binary built-up image shape: 2054, 2044 Hyderabad multispectral image shape: 6, 1318, 1056
Como você pode ver, as imagens de Bangalore têm o mesmo número de linhas e colunas que na camada binária (correspondente ao edifício). O número de camadas nas imagens multiespectrais em Bangalore e Hyderabad também coincide. O modelo aprenderá a decidir quais pixels pertencem ao edifício e quais não, com base nos valores correspondentes para todos os 6 espectros. Portanto, imagens multiespectrais devem ter o mesmo número de recursos (intervalos) listados na mesma ordem.
Agora, transformamos as matrizes em duas dimensões, onde cada linha representa um pixel separado, porque isso é necessário para a operação da maioria dos algoritmos de aprendizado de máquina. Faremos isso usando o módulo
convert do pacote
pyrsgis .
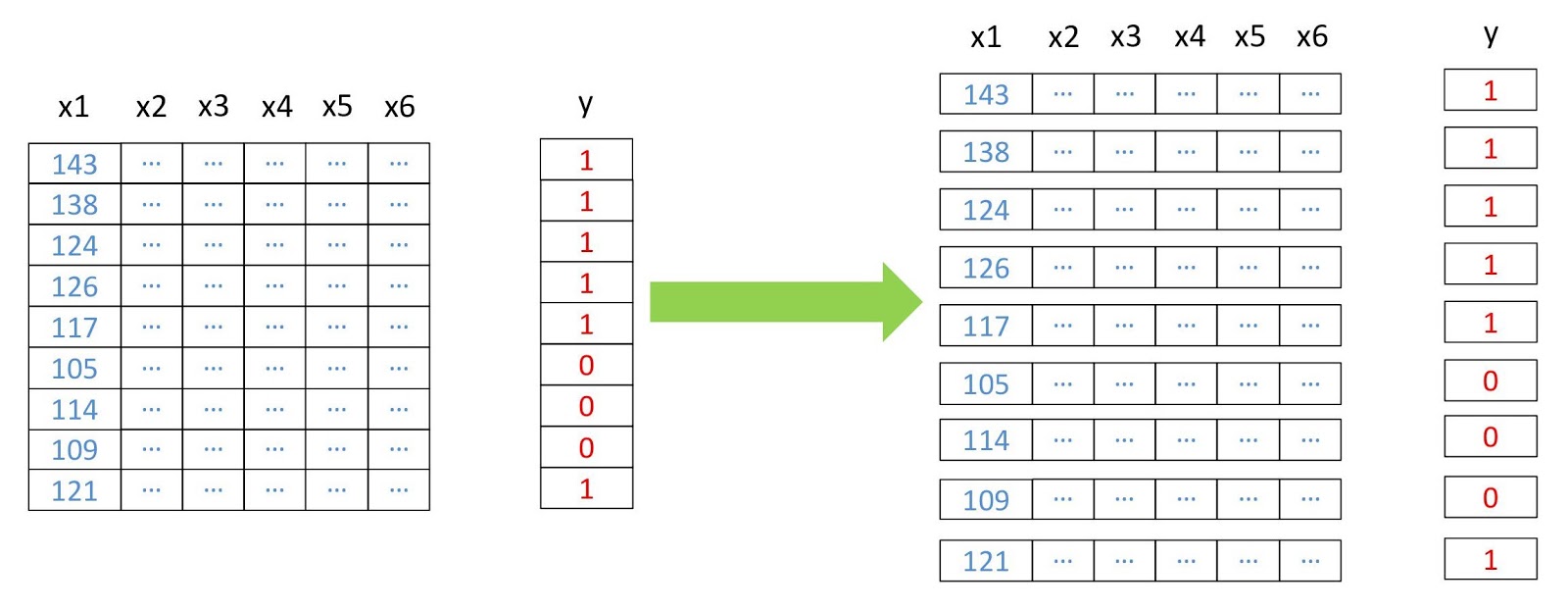
 Esquema de reestruturação de dados.
Esquema de reestruturação de dados. from pyrsgis.convert import changeDimension featuresBangalore = changeDimension(featuresBangalore) labelBangalore = changeDimension (labelBangalore) featuresHyderabad = changeDimension(featuresHyderabad) nBands = featuresBangalore.shape[1] labelBangalore = (labelBangalore == 1).astype(int) print("Bangalore multispectral image shape: ", featuresBangalore.shape) print("Bangalore binary built-up image shape: ", labelBangalore.shape) print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)
Resultado:
Bangalore multispectral image shape: 4198376, 6 Bangalore binary built-up image shape: 4198376 Hyderabad multispectral image shape: 1391808, 6
Na sétima linha, extraímos todos os pixels com um valor de 1. Isso ajuda a evitar problemas com pixels sem informação (NoData), que geralmente têm valores extremamente altos ou baixos.
Agora vamos dividir os dados em amostras de treinamento e validação. Isso é necessário para que o modelo não veja os dados de teste e funcione tão bem com as novas informações. Caso contrário, o modelo será treinado novamente e funcionará bem apenas nos dados de treinamento.
from sklearn.model_selection import train_test_split xTrain, xTest, yTrain, yTest = train_test_split(featuresBangalore, labelBangalore, test_size=0.4, random_state=42) print(xTrain.shape) print(yTrain.shape) print(xTest.shape) print(yTest.shape)
Resultado:
(2519025, 6) (2519025,) (1679351, 6) (1679351,) test_size=0.4
significa que os dados são divididos em treinamento e validação na proporção de 60/40.
Muitos algoritmos de aprendizado de máquina, incluindo redes neurais, precisam de dados normalizados. Isso significa que eles devem ser distribuídos dentro de um determinado intervalo (neste caso, de 0 a 1). Portanto, para cumprir esse requisito, normalizamos os sintomas. Isso pode ser feito extraindo o valor mínimo e dividindo-o pelo spread (a diferença entre os valores máximo e mínimo). Como o conjunto de dados do Landsat é de oito bits, os valores mínimo e máximo serão 0 e 255 (2
⁸ = 256 valores).
Observe que, para normalização, é sempre melhor calcular os valores mínimo e máximo com base nos dados. Para simplificar a tarefa, manteremos o intervalo de oito bits por padrão.
Outra etapa do processamento preliminar é a transformação da matriz de sinais de bidimensional para tridimensional, para que o modelo perceba cada linha como um pixel separado (um objeto de aprendizado separado).
Resultado:
(2519025, 1, 6) (1679351, 1, 6) (1391808, 1, 6)
Tudo está pronto, vamos montar nosso modelo com
keras . Para começar, vamos usar o modelo seqüencial, adicionando camadas uma após a outra. Teremos uma camada de entrada com o número de nós igual ao número de faixas (
nBands ) - no nosso caso, existem 6. Também usaremos uma camada oculta com 14 nós e a
ReLu ativação
ReLu . A última camada consiste em dois nós para definir uma classe de construção binária com a
softmax ativação
softmax , adequada para exibir um resultado categorizado. Leia mais sobre as funções de ativação
aqui .
from tensorflow import keras
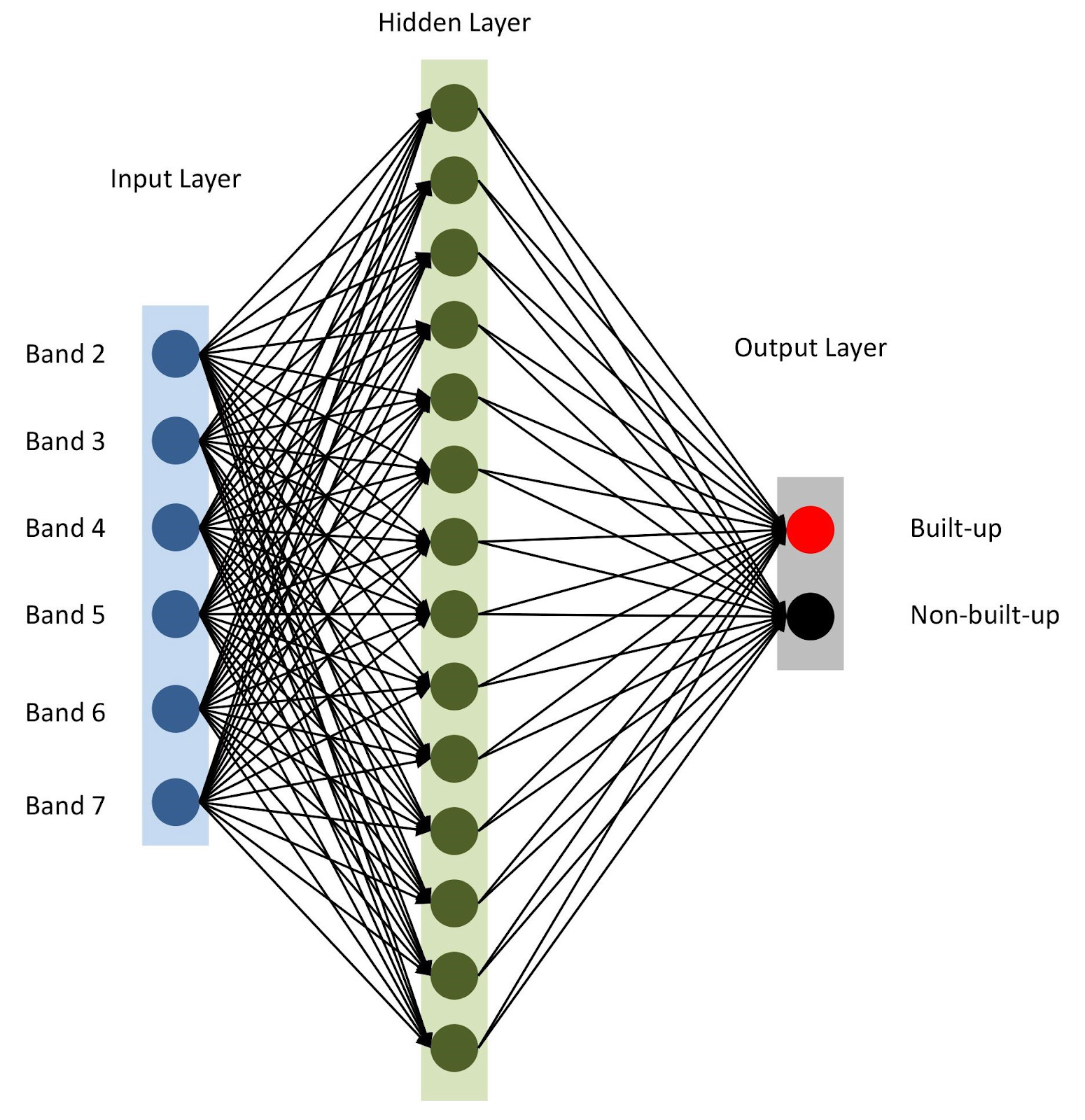 Arquitetura de rede neural
Arquitetura de rede neuralConforme mencionado na linha 10, especificamos
adam como o otimizador de modelo (existem vários
outros ). Neste caso, usaremos a entropia cruzada como uma função de perda (en.
categorical-sparse-crossentropy - mais sobre isso está escrito
aqui ). Para avaliar a qualidade do modelo, usaremos a métrica de
accuracy .
Por fim, começaremos a treinar nosso modelo para duas eras (ou iterações) no
xTrain e
yTrain . Isso levará algum tempo, dependendo do tamanho dos dados e do poder de processamento. Aqui está o que você verá após a compilação:

Vamos prever os valores para os dados de validação que armazenamos separadamente e calcular várias métricas de precisão.
from sklearn.metrics import confusion_matrix, precision_score, recall_score
A função
softmax gera colunas separadas para valores de probabilidade para cada classe. Usamos apenas os valores da primeira classe ("existe um edifício"), como pode ser visto na sexta linha do código acima. Avaliar o trabalho dos modelos de análise geoespacial não é tão simples, ao contrário de outros problemas clássicos do aprendizado de máquina. Será injusto confiar em um erro total generalizado. A chave para um modelo de sucesso é o layout espacial. Assim, a matriz de confusão, a precisão e a integridade podem fornecer uma idéia mais correta da qualidade do modelo.
 Portanto, o console exibe a matriz de erros, a precisão e a integridade.
Portanto, o console exibe a matriz de erros, a precisão e a integridade.Como você pode ver na matriz de confusão, existem milhares de pixels relacionados a edifícios, mas são classificados de maneira diferente e vice-versa. No entanto, sua participação no volume total de dados não é muito grande. A precisão e integridade dos dados do teste excederam o limite de 0,8.
Você pode gastar mais tempo e executar várias iterações para encontrar o número ideal de camadas ocultas, o número de nós em cada camada oculta e o número de eras para alcançar a precisão desejada. Conforme necessário, índices de sensoriamento remoto como NDBI ou NDWI podem ser usados como recursos. Ao atingir a precisão desejada, use o modelo para prever o desenvolvimento com base em novos dados e exportar o resultado para o GeoTIFF. Para essas tarefas, você pode usar um modelo semelhante com pequenas alterações.
predicted = model.predict(feature2005) predicted = predicted[:,1]
Observe que exportamos o GeoTIFF com valores de probabilidade previstos e não com sua versão com limiar binarizado. Posteriormente, no ambiente GIS, podemos definir o valor limite de uma camada do tipo float, conforme mostrado na figura abaixo.
 Camada acumulada de Hyderabad prevista pelo modelo com base em dados multiespectrais.
Camada acumulada de Hyderabad prevista pelo modelo com base em dados multiespectrais.A precisão do modelo já foi medida com precisão e recuperação. Você também pode executar verificações tradicionais (por exemplo, usando o coeficiente kappa) em uma nova camada prevista. Além das dificuldades acima mencionadas na classificação de imagens de satélite, outras limitações óbvias incluem a impossibilidade de previsão com base em imagens tiradas em diferentes épocas do ano e em diferentes regiões, uma vez que elas terão diferentes assinaturas espectrais.
O modelo descrito neste artigo possui a arquitetura mais simples para redes neurais. Melhores resultados podem ser alcançados com modelos mais complexos, incluindo redes neurais convolucionais. A principal vantagem dessa classificação é sua escalabilidade (aplicabilidade) após o treinamento do modelo.
Os dados usados e todo o código estão
aqui .