Meu nome é Azat Razetdinov, estou na Yandex há 12 anos, gerencio o serviço de desenvolvimento de interface na Y. Real Estate. Hoje eu gostaria de falar sobre um monorepositório. Se você tiver apenas um repositório no trabalho - parabéns, você já vive em um único repositório. Agora, sobre por que os outros precisam.
De acordo com Marina Pereskokova, chefe do serviço de desenvolvimento da API Yandex.Map, meu avô plantou um monorepa, e um monorepa cresceu muito.
- Nós da Yandex tentamos diferentes maneiras de trabalhar com vários serviços e notamos - assim que você tem mais de um serviço, inevitavelmente começam a aparecer partes comuns: modelos, utilitários, ferramentas, trechos de código, modelos, componentes. A questão é: onde colocar tudo isso? Claro, você pode copiar e colar, nós podemos fazê-lo, mas eu quero muito bem.
Até tentamos uma entidade como SVN externals para quem se lembra. Tentamos submódulos git. Tentamos pacotes npm quando eles apareceram. Mas tudo isso foi demorado, ou algo assim. Você suporta qualquer pacote, encontra um erro, faz as correções. Então você precisa lançar uma nova versão, executar os serviços, atualizar para esta versão, verificar se tudo funciona, executar os testes, encontrar o erro, voltar ao repositório da biblioteca, corrigir o erro, lançar a nova versão, executar os serviços, atualizar e assim por diante círculo. Apenas se transformou em dor.

Depois, pensamos se deveríamos nos reunir em um repositório. Leve todos os nossos serviços e bibliotecas, transfira e desenvolva em um repositório. Havia muitas vantagens. Não estou dizendo que essa abordagem seja ideal, mas do ponto de vista da empresa e até do departamento de vários grupos, vantagens significativas aparecem.
Para mim, pessoalmente, o mais importante é a atomicidade das confirmações, que como desenvolvedor, posso consertar a biblioteca, ignorar todos os serviços, fazer alterações, executar testes, verificar se tudo funciona, enviá-la para o mestre e tudo isso com uma única alteração. Não há necessidade de reconstruir, publicar, atualizar nada.
Mas se tudo é tão bom, por que todo mundo ainda não se mudou para o mono-repositório? Claro, também existem desvantagens.

De acordo com Marina Pereskokova, diretora do serviço de desenvolvimento da API Yandex.Map, meu avô plantou um monorepa e um monorepa cresceu muito. Isso é um fato, não uma piada. Se você coletar muitos serviços em um único repositório, isso inevitavelmente aumenta. E se estamos falando sobre o git, que extrai todos os arquivos e todo o histórico por toda a existência do seu código, esse é um espaço em disco bastante grande.
O segundo problema é a injeção no mestre. Você preparou uma solicitação de pool, passou por uma revisão, está pronto para mesclá-la. E acontece que alguém conseguiu ficar à sua frente e você precisa resolver conflitos. Você resolveu os conflitos, novamente pronto para entrar, e novamente não teve tempo. Esse problema está sendo resolvido, existem sistemas de filas de mesclagem, quando um robô especial automatiza esse trabalho, solicita o pool de faixas, tenta resolver conflitos, se puder. Se não puder, chama o autor. No entanto, esse problema existe. Existem soluções que o nivelam, mas é preciso ter isso em mente.
Esses são pontos técnicos, mas também existem pontos organizacionais. Suponha que você tenha várias equipes que prestam vários serviços diferentes. Quando eles se mudam para um único repositório, sua responsabilidade começa a diminuir. Porque eles fizeram um lançamento, lançado na produção - algo quebrou. Começamos a discussão. Acontece que é um desenvolvedor de outra equipe que comprometeu algo com o código geral, nós o retiramos, o não lançamos, não o vimos, tudo quebrou. E não está claro quem é o responsável. É importante entender e usar todos os métodos possíveis: testes de unidade, testes de integração, linter - tudo o que é possível para reduzir esse problema da influência de um código em todos os outros serviços.
Curiosamente, quem mais além do Yandex e de outros jogadores usa o mono-repositório? Muita gente. Estes são React, Jest, Babel, Ember, Meteor, Angular. As pessoas entendem - é mais fácil, mais barato, mais rápido desenvolver e publicar pacotes npm em um único repositório do que em vários repositórios pequenos. O mais interessante é que, junto com esse processo, começaram a se desenvolver ferramentas para trabalhar com um monorepositório. Apenas sobre eles e eu quero conversar.
Tudo começa com a criação de um monorepositório. A ferramenta front-end mais famosa do mundo para isso é chamada lerna.

Apenas abra seu repositório, execute o npx lerna init, ele fará algumas perguntas sugestivas e adicionará algumas entidades à sua cópia de trabalho. A primeira entidade é a configuração lerna.json, que indica pelo menos dois campos: a versão de ponta a ponta de todos os seus pacotes e a localização dos seus pacotes no sistema de arquivos. Por padrão, todos os pacotes são adicionados à pasta packages, mas você pode configurá-lo como quiser, pode até adicioná-los à raiz, o lerna também pode buscá-lo.
O próximo passo é como adicionar seus repositórios ao repositório mono, como transferi-los?
O que queremos alcançar? Provavelmente, você já possui algum tipo de repositório, neste caso A e B.

Esses são dois serviços, cada um em seu próprio repositório, e queremos transferi-los para o novo mono-repositório na pasta packages, de preferência com um histórico de confirmações, para que você possa culpar o git, o git log e assim por diante.

Existe uma ferramenta de importação lerna para isso. Você simplesmente especifica a localização do seu repositório e o lerna o transfere para o seu monorepo. Ao mesmo tempo, ela primeiro pega uma lista de todos os commits, modifica cada commit, alterando o caminho para os arquivos da raiz para packages / package_name, e os aplica um após o outro, os sobrepõe no seu mono-repositório. De fato, cada confirmação é preparada, alterando os caminhos do arquivo. Essencialmente, lerna faz mágica para você. Se você ler o código fonte, simplesmente os comandos git serão executados em uma determinada sequência.
Esta é a primeira maneira. Tem uma desvantagem: se você trabalha em uma empresa onde há processos de produção, onde as pessoas já estão escrevendo algum tipo de código e você as traduz em um monorep, é improvável que você o faça em um dia. Você precisará descobrir, configurar, verificar se tudo começa, testes. Mas as pessoas não têm trabalho, continuam fazendo alguma coisa.

Para uma transição mais suave para o mono-rap, existe uma ferramenta como a subárvore git. Isso é algo mais sofisticado, mas ao mesmo tempo nativo do git, que permite não apenas importar repositórios individuais para um repositório mono por algum tipo de prefixo, mas também trocar mudanças. Ou seja, a equipe que produz o serviço pode ser facilmente desenvolvida com mais facilidade em seu próprio repositório, enquanto você pode extrair suas alterações através da subárvore git pull, fazer suas próprias alterações e enviá-las de volta através da subárvore git push. E viva assim no período de transição pelo tempo que quiser.
E quando você configura tudo, verifica se todos os testes estão em execução, a implantação está funcionando, todo o CI / CD está configurado, você pode dizer que é hora de seguir em frente. Para o período de transição, uma ótima solução, eu recomendo.
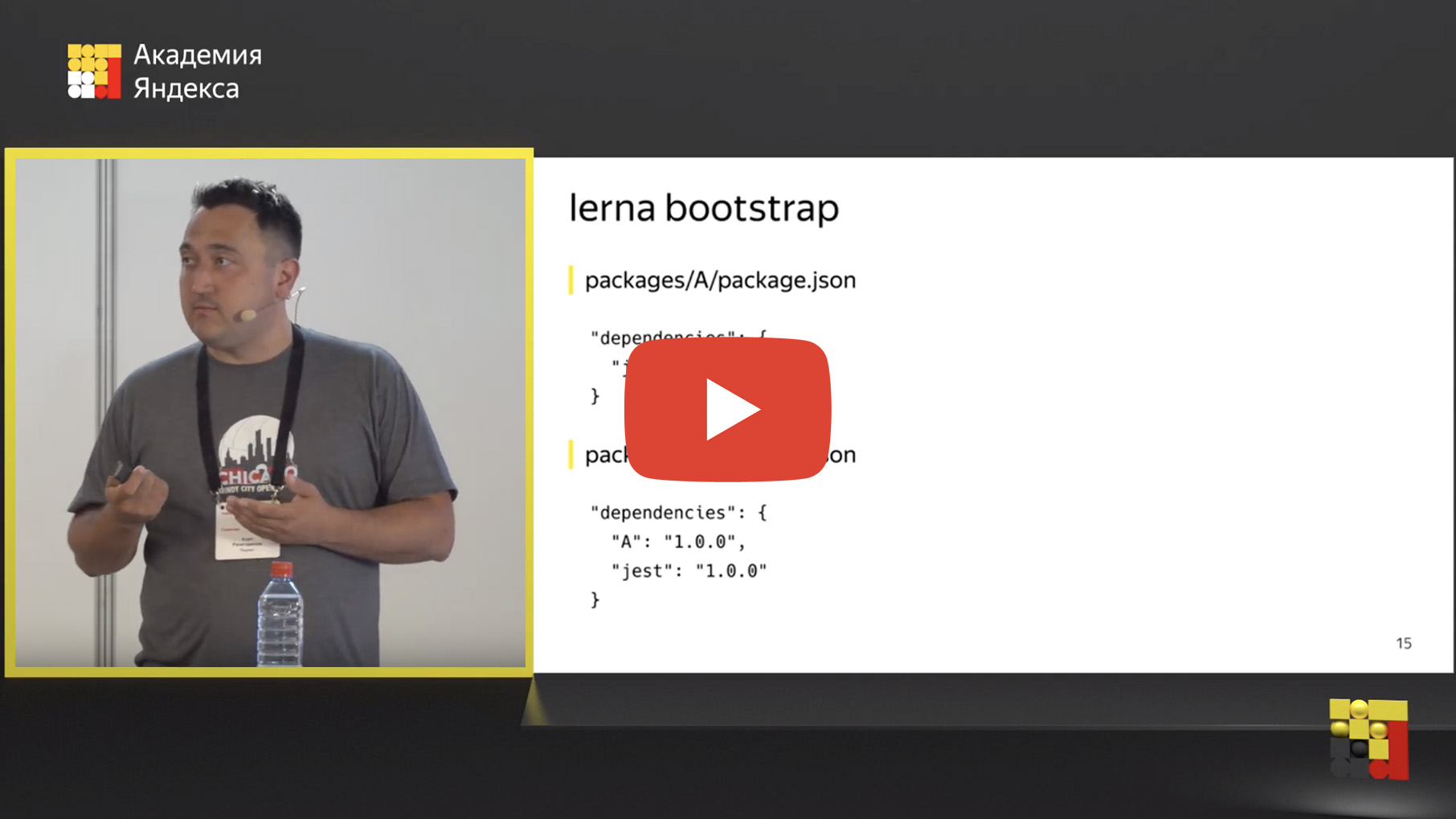
Bem, mudamos nossos repositórios para um mono-repositório, mas onde está a mágica em algum lugar? Mas queremos destacar as partes comuns e usá-las de alguma forma. E para isso, existe um mecanismo de "ligação a dependências". O que é ligação de dependência? Existe uma ferramenta lerna bootstrap, um comando semelhante ao npm install, apenas executa o npm install em todos os seus pacotes.

Mas isso não é tudo. Além disso, ela está procurando dependências internas. Você pode usar outro em um pacote dentro do seu repositório. Por exemplo, se você possui o pacote A, que depende do Jest, nesse caso, há o pacote B, que depende do Jest e do pacote A. Se o pacote A é uma ferramenta comum, um componente comum, o pacote B é um serviço que o possui usos.
Lerna define essas dependências internas e substitui fisicamente essa dependência por um link simbólico no sistema de arquivos.


Depois de executar o lerna bootstrap, dentro da pasta node_modules, em vez da pasta física A, aparece um link simbólico que leva à pasta com o pacote A. Isso é muito conveniente porque você pode editar o código no pacote A e verificar imediatamente o resultado no pacote B , execute testes, integração, unidades, o que você quiser. O desenvolvimento é bastante simplificado, você não precisa mais montar o pacote A, publicar, conectar o pacote B. Ele foi consertado aqui, verificado lá.
Observe que, se você olhar para as pastas node_modules e houver brincadeiras, duplicamos o módulo instalado. Em geral, é bastante tempo quando você inicia o lerna bootstrap, aguarde até que tudo pare, devido ao fato de que existe muito trabalho repetido, são obtidas dependências duplicadas em cada pacote.
Para acelerar a instalação de dependências, é usado o mecanismo para aumentar dependências. A ideia é muito simples: você pode levar as dependências gerais para o node_modules raiz.

Se você especificar a opção --hoist (esta é uma atualização do inglês), quase todas as dependências serão movidas para o node_modules raiz. E quase sempre funciona. Noda está tão disposta que, se ela não encontrou as dependências em seu nível, ela começa a procurar um nível mais alto, se não estiver lá, outro nível mais alto e assim por diante. Quase nada muda. Mas, de fato, pegamos e desduplicamos nossas dependências, transferimos as dependências para a raiz.
Ao mesmo tempo, lerna é inteligente o suficiente. Se houver algum conflito, por exemplo, se o pacote A usou a versão 1 do Jest e o pacote B usou a versão 2, um deles seria exibido e o segundo permaneceria no seu nível. Isso é aproximadamente o que o npm está realmente fazendo dentro da pasta node_modules normal, ele também tenta desduplicar dependências e, no máximo, carregá-las para a raiz.
Infelizmente, essa mágica nem sempre funciona, especialmente com ferramentas, com Babel, com Jest. Muitas vezes acontece que ele inicia, porque Jest tem seu próprio sistema para resolver módulos, Noda começa a ficar atrasado, gera um erro. Especialmente nos casos em que a ferramenta não lida com as dependências que foram para a raiz, existe a opção nohoist, que permite ressaltar que esses pacotes não são transferidos para a raiz, deixando-os no lugar.

Se você especificar --nohoist = jest, todas as dependências, exceto jest, irão para a raiz e o jest permanecerá no nível do pacote. Não é de admirar que eu tenha dado esse exemplo - é a piada que tem problemas com esse comportamento, e o nohoist ajuda com isso.
Outra vantagem da recuperação de dependência:

Se antes você tinha o package-lock.json separado para cada serviço, para cada pacote, quando você é aborrecido, tudo sobe e o único package-lock.json permanece. Isso é conveniente do ponto de vista de despejar no mestre, resolver conflitos. Uma vez que todos foram mortos, e é isso.
Mas como a lerna consegue isso? Ela é bastante agressiva com a NPM. Quando você especifica hoist, ele pega seu package.json na raiz, faz o backup, substitui outro por ele, agrega todas as suas dependências, executa o npm install, quase tudo é colocado na raiz. Em seguida, este package.json temporário é removido e restaura o seu. Se, depois disso, você executar qualquer comando com o npm, por exemplo, npm remove, o npm não entenderá o que aconteceu, por que todas as dependências apareceram repentinamente na raiz. Lerna viola o nível de abstração, ela se arrasta para a ferramenta, que está abaixo do nível dela.
Os caras da Yarn foram os primeiros a perceber esse problema e disseram: o que estamos atormentando, vamos fazer tudo por você de forma nativa, para que tudo saia da caixa funcione.

O fio já pode fazer o mesmo imediatamente: dependências de empate, se ele vir que o pacote B depende do pacote A, ele fará um link simbólico gratuitamente. Ele sabe como aumentar dependências, faz isso por padrão, tudo se soma à raiz. Como o lerna, ele pode deixar o único yarn.lock na raiz do repositório. Todos os outros fios. Travam você não precisa mais.

Está configurado de maneira semelhante. Infelizmente, o yarn assume que todas as configurações foram adicionadas ao package.json, sei que existem pessoas que tentam tirar todas as configurações das ferramentas de lá, deixando apenas um mínimo. Infelizmente, o yarn ainda não aprendeu a especificar isso em outro arquivo, apenas no package.json. Existem duas novas opções, uma nova e outra obrigatória. Como se supõe que o repositório raiz nunca será publicado, o yarn exige que private = true seja especificado lá.
Mas as configurações dos espaços de trabalho são armazenadas na mesma chave. A configuração é muito semelhante às configurações do lerna, há um campo de pacotes onde você especifica a localização dos seus pacotes e há uma opção nohoist, muito semelhante à opção nohoist no lerna. Basta especificar essas configurações e obter a mesma estrutura que no lerna. Todas as dependências comuns foram para a raiz e as especificadas na chave nohoist permaneceram em seu nível.

A melhor parte é que o lerna pode trabalhar com fios e escolher suas configurações. Basta especificar dois campos no lerna.json, o lerna imediatamente entenderá que você está usando o yarn, entre no package.json, obtenha todas as configurações de lá e trabalhe com elas. Essas duas ferramentas já se conhecem e trabalham juntas.

E por que ainda não há suporte às npm se tantas empresas grandes usam um repositório mono?

Eles dizem que tudo será, mas na sétima versão. Suporte básico no sétimo, estendido - no oitavo. Esta publicação foi lançada há um mês, mas, ao mesmo tempo, a data ainda é desconhecida quando a sétima npm será lançada. Estamos esperando que ele finalmente alcance o fio.
Quando você possui vários serviços em um único repositório, surge inevitavelmente a questão de como gerenciá-los para não ir a cada pasta, não executar comandos? Existem operações massivas para isso.


O fio possui um comando da área de trabalho do fio, seguido pelo nome do pacote e pelo nome do comando. Como o yarn from the box, ao contrário do npm, pode fazer as três coisas: executar seus próprios comandos, adicionar uma dependência ao gracejo, executar scripts do package.json, como test, e também pode executar arquivos executáveis da pasta node_modules / .bin. Ele ensinará para você com a ajuda de heurísticas e entenderá o que você deseja. É muito conveniente usar o espaço de trabalho do fio para operações pontuais em um pacote.
Existe um comando semelhante que permite executar um comando em todos os pacotes que você possui.

Indique apenas seus comandos com todos os argumentos.

Para os profissionais, é muito conveniente administrar equipes diferentes. Dos pontos negativos, por exemplo, é impossível executar comandos do shell. Suponha que eu queira excluir todas as pastas dos módulos do nó, não posso executar os espaços de trabalho do yarn, execute rm.
É impossível especificar uma lista de pacotes, por exemplo, quero remover a dependência em apenas dois pacotes, apenas por vez ou individualmente.
Bem, ele trava no primeiro erro. Se eu quiser remover a dependência de todos os pacotes - e, de fato, apenas dois deles a possuem, mas não quero pensar onde ela está, mas só quero removê-la -, o fio não permitirá, mas trava na primeira situação onde este pacote não está nas dependências. Isso não é muito conveniente, às vezes você deseja ignorar erros, percorrer todos os pacotes.

O Lerna tem um kit de ferramentas muito mais interessante, existem dois comandos run e exec separados. O Run pode executar scripts do package.json e, diferentemente do yarn, ele pode filtrar tudo por pacotes, você pode especificar --scope, você pode usar asteriscos, globs, tudo é bastante universal. Você pode executar essas operações em paralelo, pode ignorar erros através da opção --no-bail.

Exec é muito parecido. Diferentemente do yarn, ele permite não apenas executar arquivos executáveis a partir do node_modules.bin, mas também executar qualquer comando arbitrário do shell. Por exemplo, você pode remover node_modules ou executar alguma marca, o que quiser. E a mesma opção é suportada.

Ferramentas muito convenientes, algumas vantagens. Este é o caso quando lerna rasga o fio, está no nível certo de abstração. É exatamente disso que a lerna precisa: simplifique o trabalho com vários pacotes no monorepe.
Com monoreps, há mais um menos. Quando você tem um IC / CD, não pode otimizá-lo. Quanto mais serviços você tiver, mais tempo leva. Suponha que você comece a testar todos os serviços para cada solicitação de pool e, quanto mais houver, mais tempo demorará o trabalho. Operações seletivas podem ser usadas para otimizar esse processo. Vou citar três maneiras diferentes. Os dois primeiros podem ser usados não apenas no monorep, mas também em seus projetos, se por algum motivo você não usar esses métodos.
O primeiro é o lint-estágios, que permite executar linter, testes, tudo o que você deseja, apenas para arquivos que foram alterados ou serão confirmados nesse commit. Execute o fiapo inteiro, não em todo o projeto, mas apenas nos arquivos que foram alterados.


A configuração é muito simples. Coloque ganchos pré-confirmados, roucos e com estágio de fiapos e diga que ao alterar qualquer arquivo js, você precisa executar o eslint. Assim, a verificação pré-confirmação é muito acelerada. Especialmente se você tiver muitos serviços, um repositório mono muito grande. A execução de eslint em todos os arquivos é muito cara e você pode otimizar os ganchos de pré-confirmação no lint dessa maneira.

Se você escreve testes no Jest, ele também possui ferramentas para executar seletivamente os testes.

Essa opção permite que você forneça uma lista de arquivos de origem e encontre todos os testes que de uma maneira ou de outra afetam esses arquivos. O que pode ser usado em conjunto com estágios de fiapos? Observe que aqui não estou especificando todos os arquivos js, mas apenas a fonte. Excluímos os próprios arquivos js com testes internos; olhamos apenas para a fonte. Começamos o findRelatedTests e aceleramos bastante a execução da unidade para pré-confirmar ou pré-empurrar, conforme desejado.
E o terceiro método está associado aos monorepositórios. Esta é a lerna, que pode determinar quais pacotes foram alterados em comparação com o commit base. Provavelmente, não se trata de ganchos, mas do seu CI / CD: Travis ou outro serviço que você usa.


Os comandos run e exec têm a opção since, que permite executar qualquer comando apenas nos pacotes que foram alterados desde algum tipo de confirmação. Em casos simples, você pode especificar um assistente se derramar tudo nele. Se você desejar com mais precisão, é melhor especificar a confirmação básica da sua solicitação de pool por meio de sua ferramenta de CI / CD, pois esse será um teste mais honesto.
Como o lerna conhece todas as dependências dentro dos pacotes, também pode detectar dependências indiretas. Se você alterar a biblioteca A, que é usada na biblioteca B, que é usada no serviço C, o lerna entenderá isso. , . , C — , . lerna .
, :
c lerna ,
yarn workspaces
.
, . , . . ? , , , . , , . , - . , Babel. , , . . , .
:
mishanga . , , . , .