Este e os guias a seguir o guiarão pelo processo de criação de uma solução baseada no projeto Discovery.js . Nosso objetivo é criar um inspetor para dependências do NPM, ou seja, uma interface para examinar a estrutura de node_modules .
Nota: O Discovery.js está em um estágio inicial de desenvolvimento, portanto, com o tempo, algo será simplificado e se tornará mais útil. Se você tem idéias sobre como melhorar algo, escreva-nos .
Anotação
Abaixo, você encontrará uma visão geral dos principais conceitos do Discovery.js. Você pode aprender todo o código do manual no repositório no GitHub , ou pode tentar como ele funciona online .
Condições iniciais
Primeiro de tudo, precisamos escolher um projeto para análise. Pode ser um projeto recém-criado ou um projeto existente, o principal é que ele contém node_modules (o objeto de nossa análise).
Primeiro, instale o pacote principal do discoveryjs e suas ferramentas de console:
npm install @discoveryjs/discovery @discoveryjs/cli
Em seguida, inicie o servidor Discovery.js:
> npx discovery No config is used Models are not defined (model free mode is enabled) Init common routes ... OK Server listen on http://localhost:8123
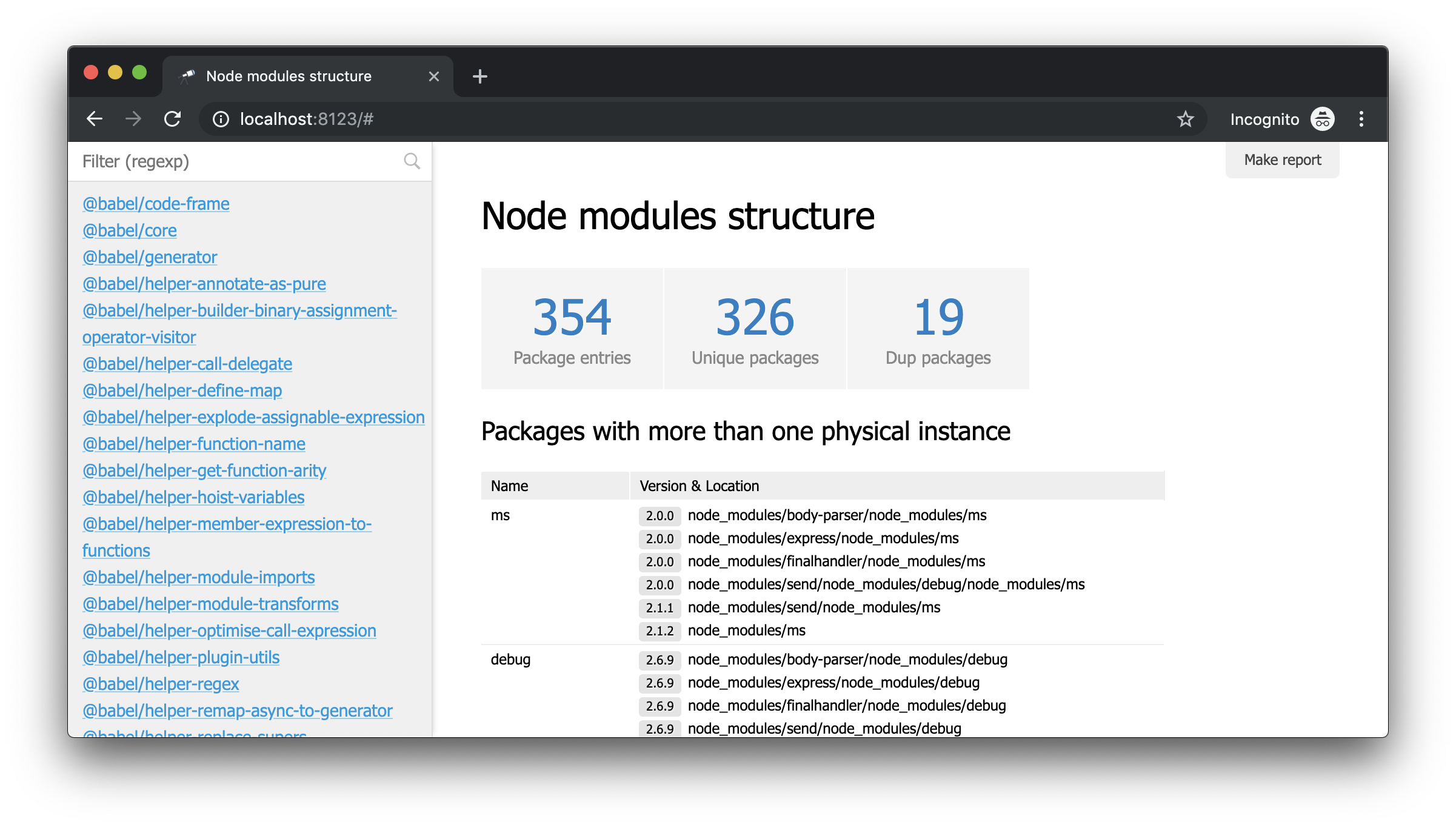
Se você abrir http://localhost:8123 no navegador, poderá ver o seguinte:

Este é um modo sem modelo, ou seja, quando nada está configurado. Mas agora, usando o botão "Carregar dados", você pode selecionar qualquer arquivo JSON ou simplesmente arrastá-lo para a página e iniciar a análise.
No entanto, precisamos de algo específico. Em particular, precisamos obter uma visão da estrutura node_modules . Para fazer isso, adicione a configuração.
Adicionar configuração
Como você deve ter notado, a mensagem No config is used exibida quando o servidor foi iniciado. Vamos criar um arquivo de configuração .discoveryrc.js com o seguinte conteúdo:
module.exports = { name: 'Node modules structure', data() { return { hello: 'world' }; } };
Nota: se você criar um arquivo no diretório de trabalho atual (ou seja, na raiz do projeto), nada mais será necessário. Caso contrário, você precisará passar o caminho para o arquivo de configuração usando a opção --config ou defina o caminho no package.json :
{ ... "discovery": "path/to/discovery/config.js", ... }
Reinicie o servidor para que a configuração seja aplicada:
> npx discovery Load config from .discoveryrc.js Init single model default Define default routes ... OK Cache: DISABLED Init common routes ... OK Server listen on http://localhost:8123
Como você pode ver, agora o arquivo que criamos é usado. E o modelo padrão descrito por nós é aplicado (o Discovery pode funcionar no modo de muitos modelos, falaremos sobre esse recurso nos manuais a seguir). Vamos ver o que mudou no navegador:
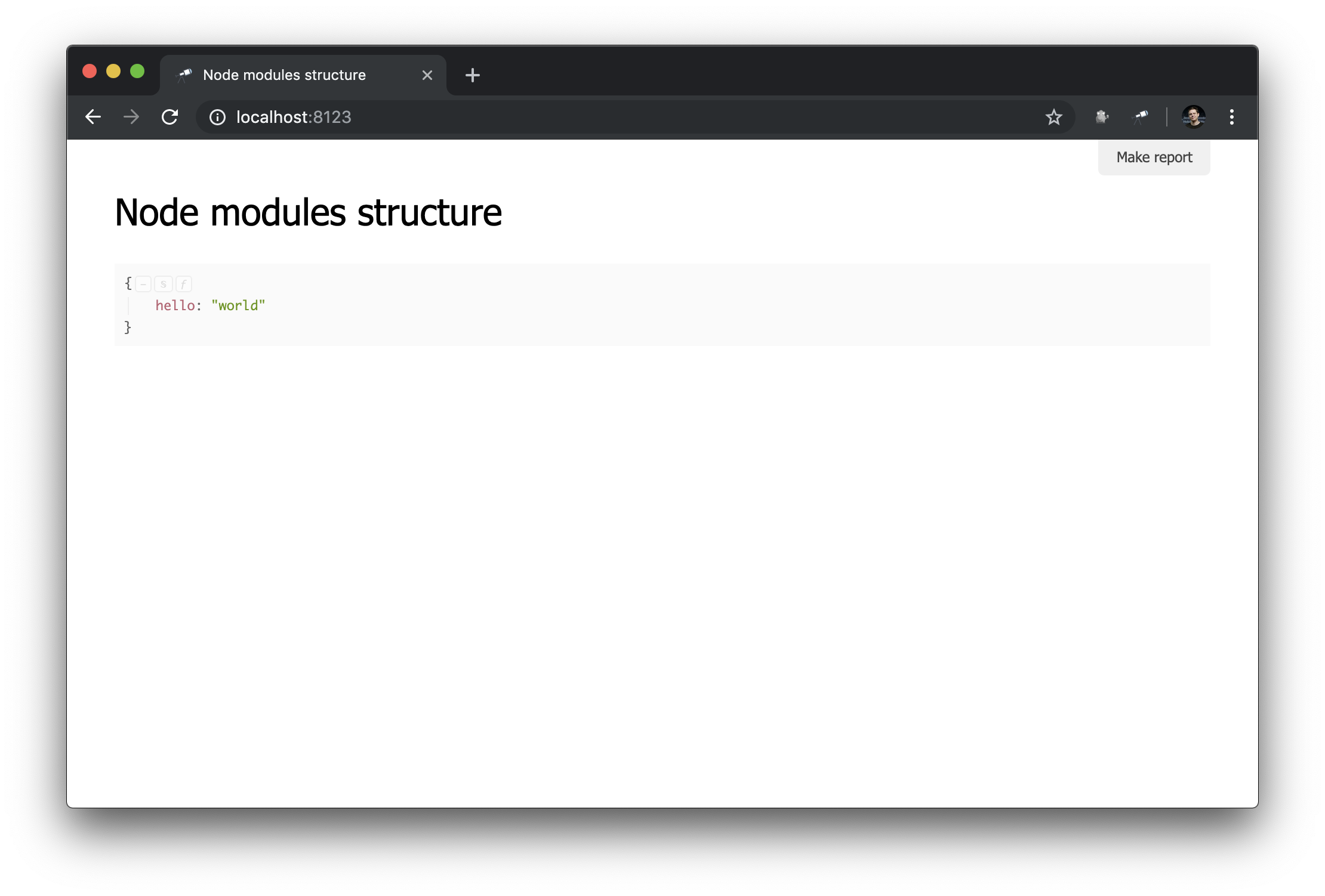
O que pode ser visto aqui:
name usado como o título da página;- o resultado da chamada do método de
data é exibido como o conteúdo principal da página.
Nota: o método data deve retornar dados ou Promise, que são resolvidos.
As configurações básicas são feitas, você pode seguir em frente.
Contexto
Vejamos a página do relatório personalizado (clique em Make report ):
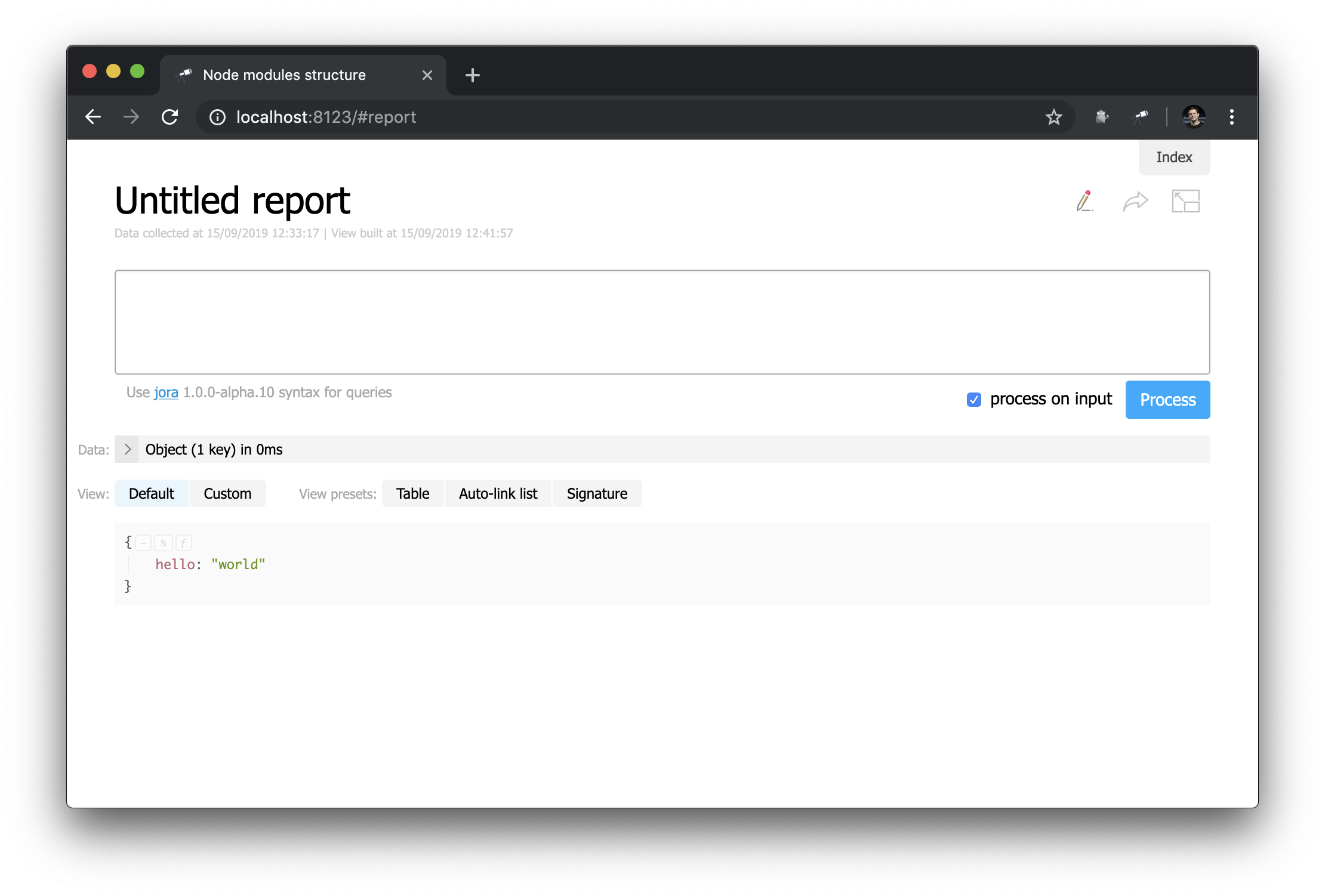
À primeira vista, isso não é muito diferente da página inicial ... Mas aqui você pode mudar tudo! Por exemplo, podemos recriar facilmente a aparência da página inicial:
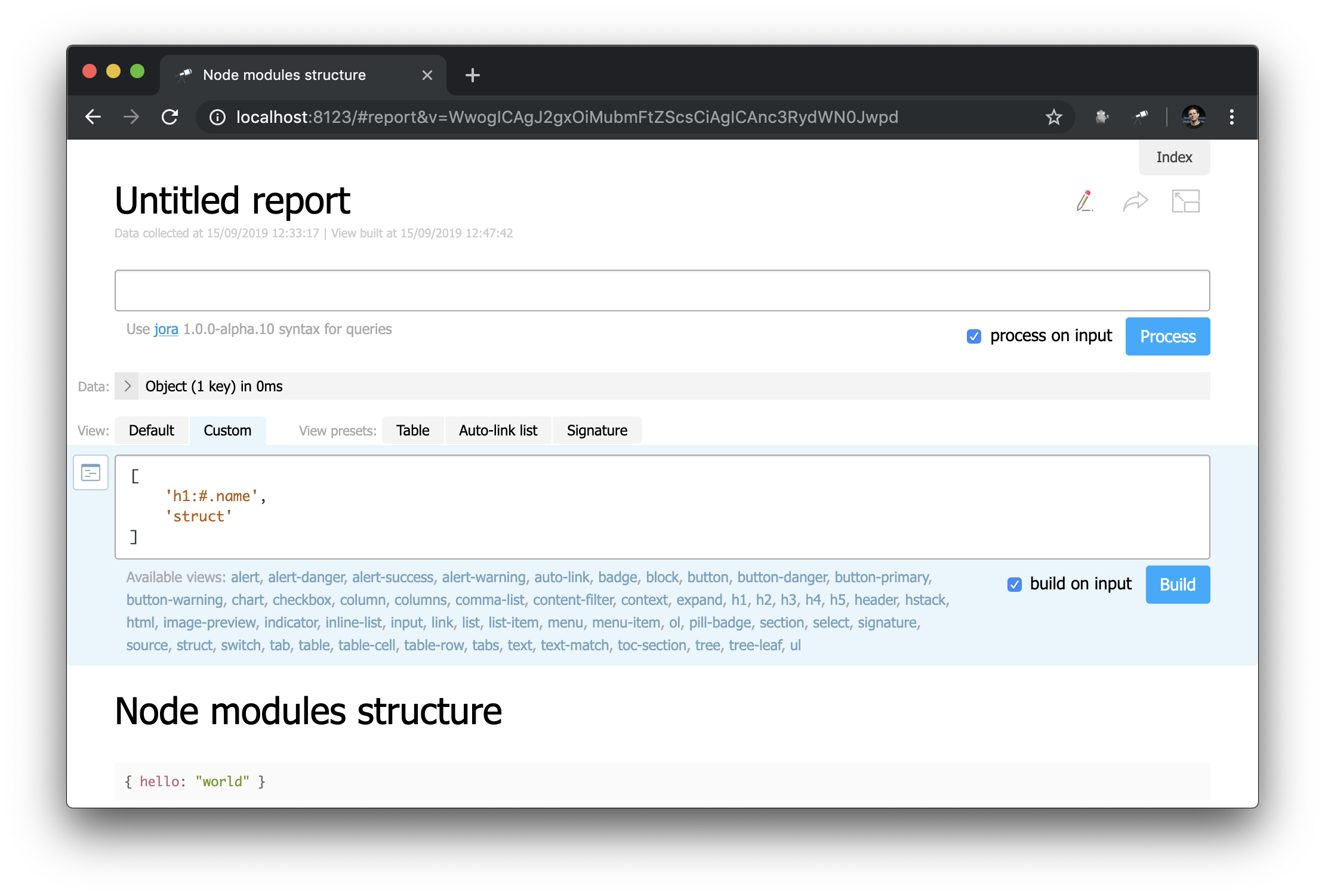
Observe como o cabeçalho está definido: "h1:#.name" . Este é o cabeçalho de primeiro nível com o conteúdo de #.name , que é uma solicitação Jora . # refere-se ao contexto da solicitação. Para visualizar seu conteúdo, basta digitar # no editor de consultas e usar a exibição padrão:
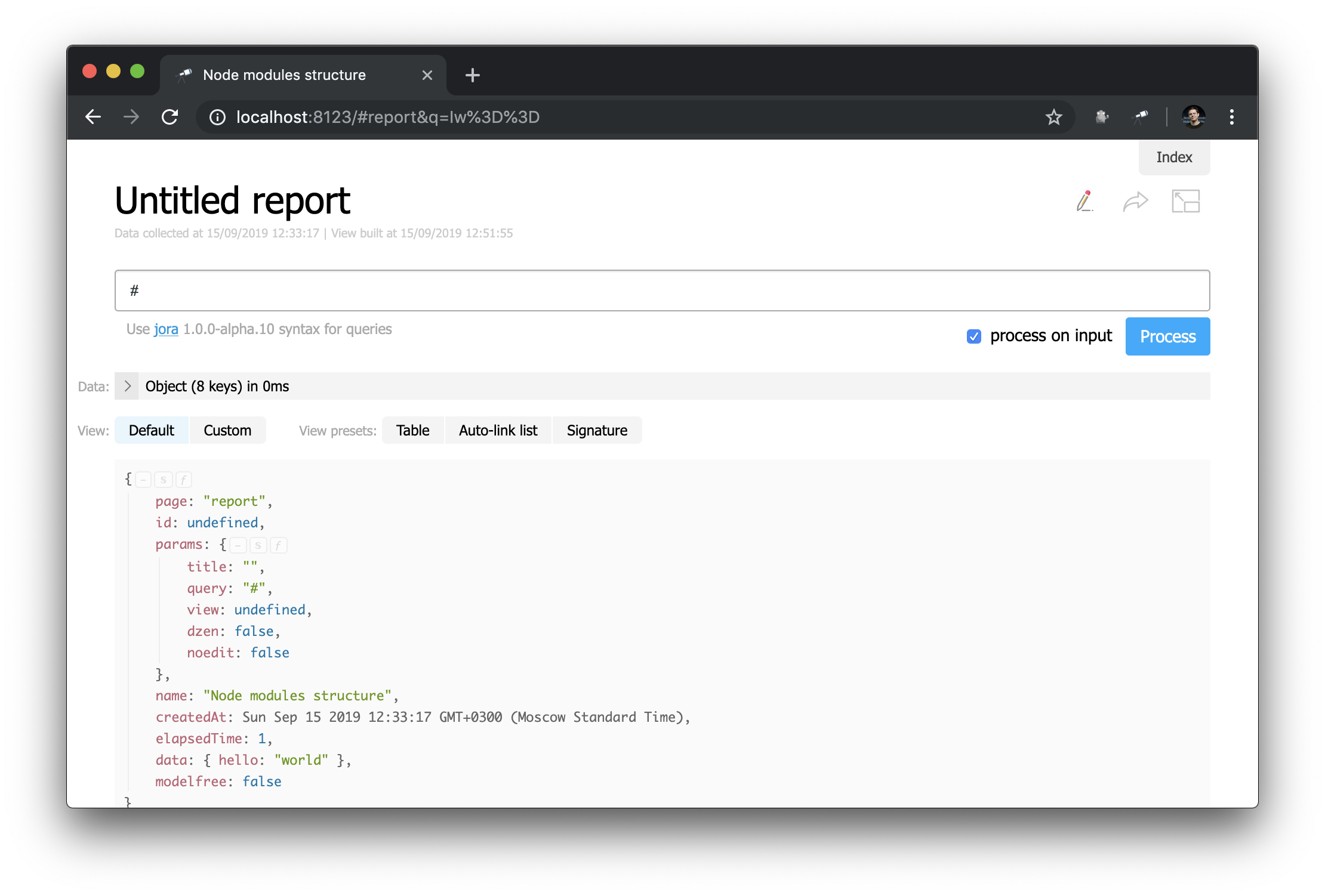
Agora você sabe como obter o ID da página atual, seus parâmetros e outros valores úteis.
Coleta de dados
Agora usamos um esboço no projeto em vez de dados reais, mas precisamos de dados reais. Para fazer isso, crie um módulo e altere o valor dos data na configuração (a propósito, após essas alterações, não é necessário reiniciar o servidor):
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data') };
O conteúdo de collect-node-modules-data.js :
const path = require('path'); const scanFs = require('@discoveryjs/scan-fs'); module.exports = function() { const packages = []; return scanFs({ include: ['node_modules'], rules: [{ test: /\/package.json$/, extract: (file, content) => { const pkg = JSON.parse(content); if (pkg.name && pkg.version) { packages.push({ name: pkg.name, version: pkg.version, path: path.dirname(file.filename), dependencies: pkg.dependencies }); } } }] }).then(() => packages); };
Usei o pacote @discoveryjs/scan-fs , que simplifica a verificação do sistema de arquivos. Um exemplo de uso do pacote é descrito em seu leia-me, tomei este exemplo como base e finalizei conforme necessário. Agora, temos algumas informações sobre o conteúdo de node_modules :
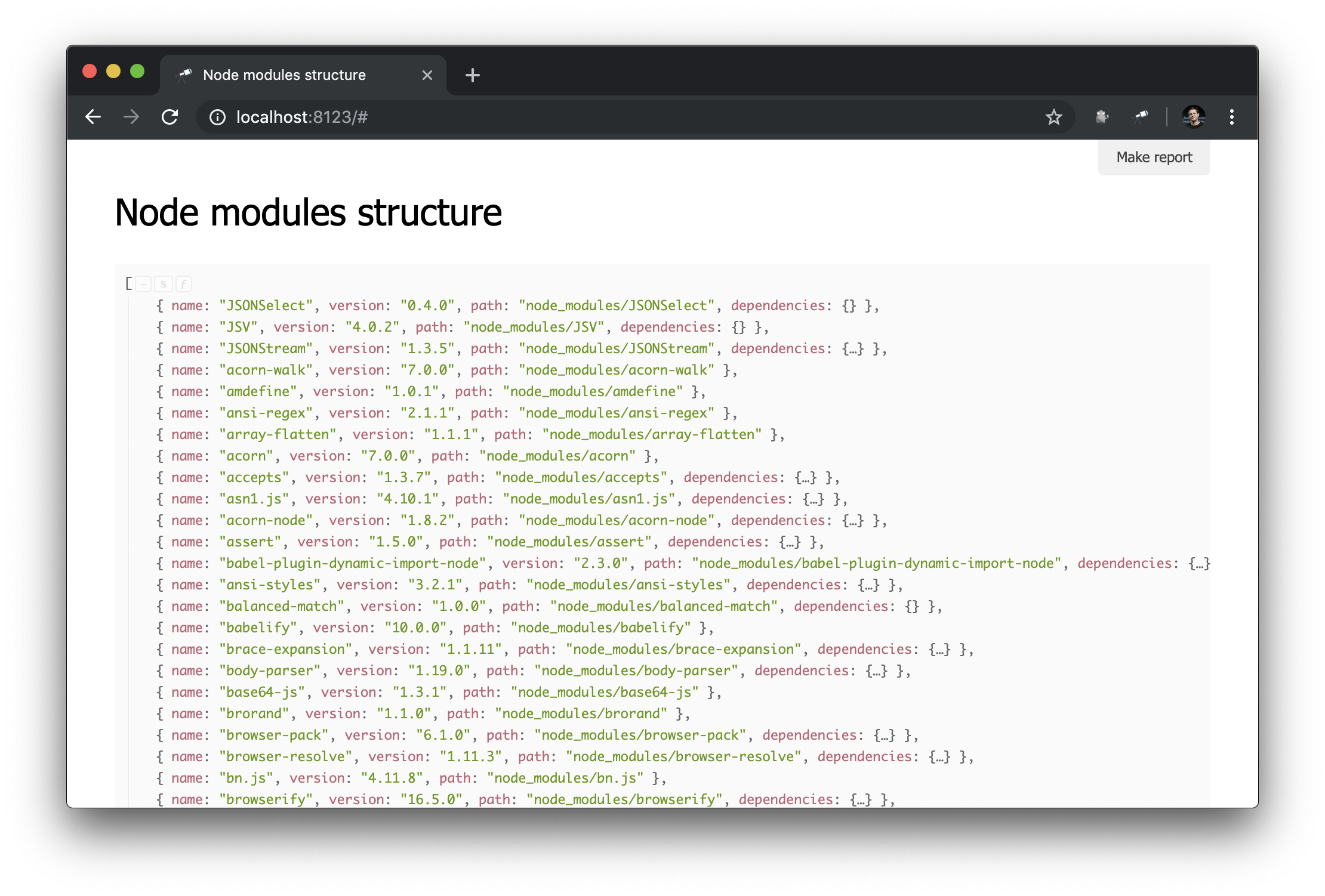
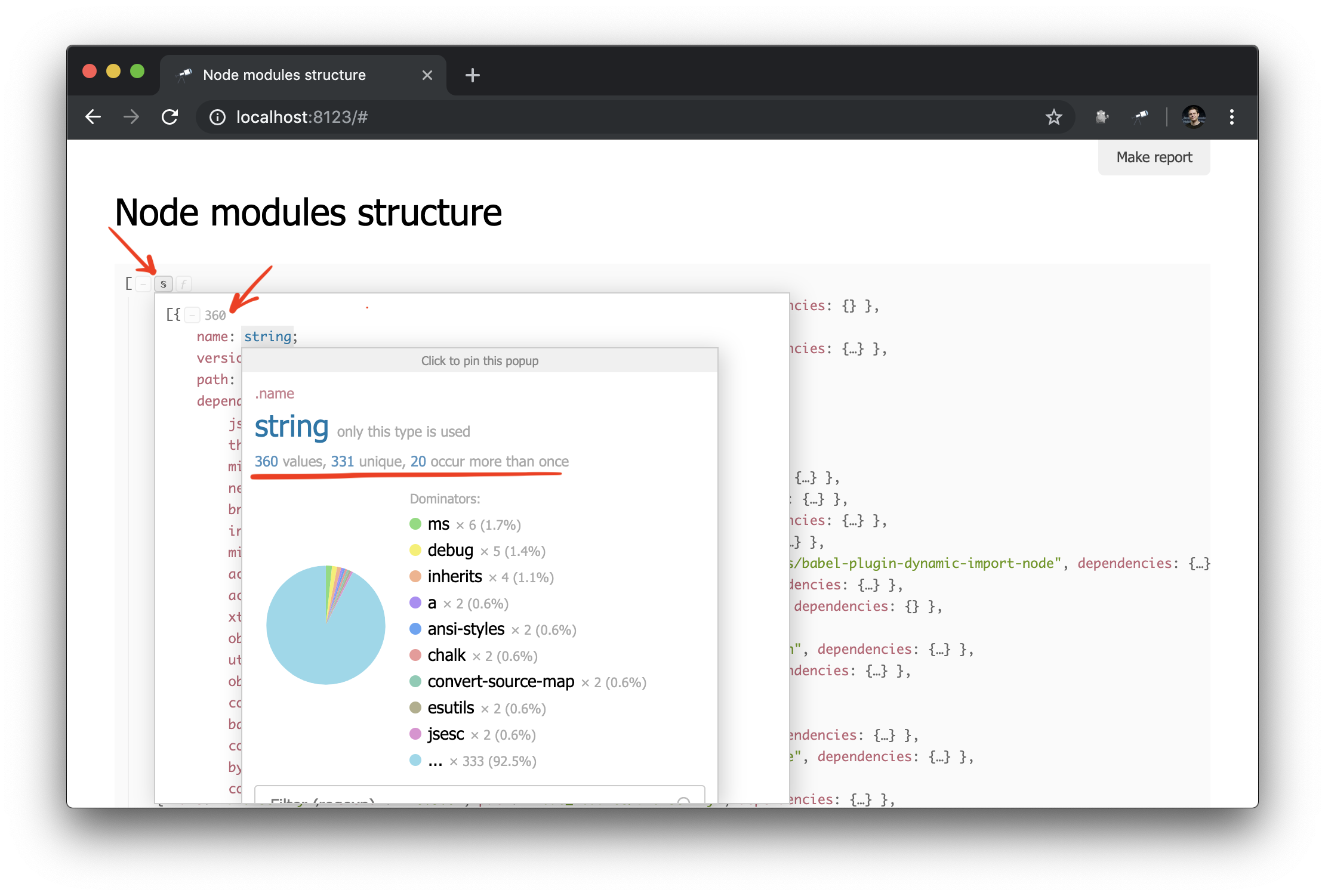
O que você precisa! E, apesar do JSON comum, já podemos analisá-lo e tirar algumas conclusões. Por exemplo, usando o pop-up da estrutura de dados, você pode descobrir o número de pacotes e descobrir quantos deles têm mais de uma instância física (devido à diferença nas versões ou nos problemas com a deduplicação).
Apesar de já termos alguns dados, precisamos de mais detalhes. Por exemplo, seria bom saber qual instância física resolve cada uma das dependências declaradas de um módulo específico. No entanto, o trabalho para melhorar a extração de dados está além do escopo deste guia. Portanto, iremos substituí-lo pelo pacote @discoveryjs/node-modules (que também é baseado em @discoveryjs/scan-fs ) para recuperar os dados e obter os detalhes necessários sobre os pacotes. Como resultado, o collect-node-modules-data.js bastante simplificado:
const fetchNodeModules = require('@discoveryjs/node-modules'); module.exports = function() { return fetchNodeModules(); };
Agora, as informações sobre o node_modules assim:
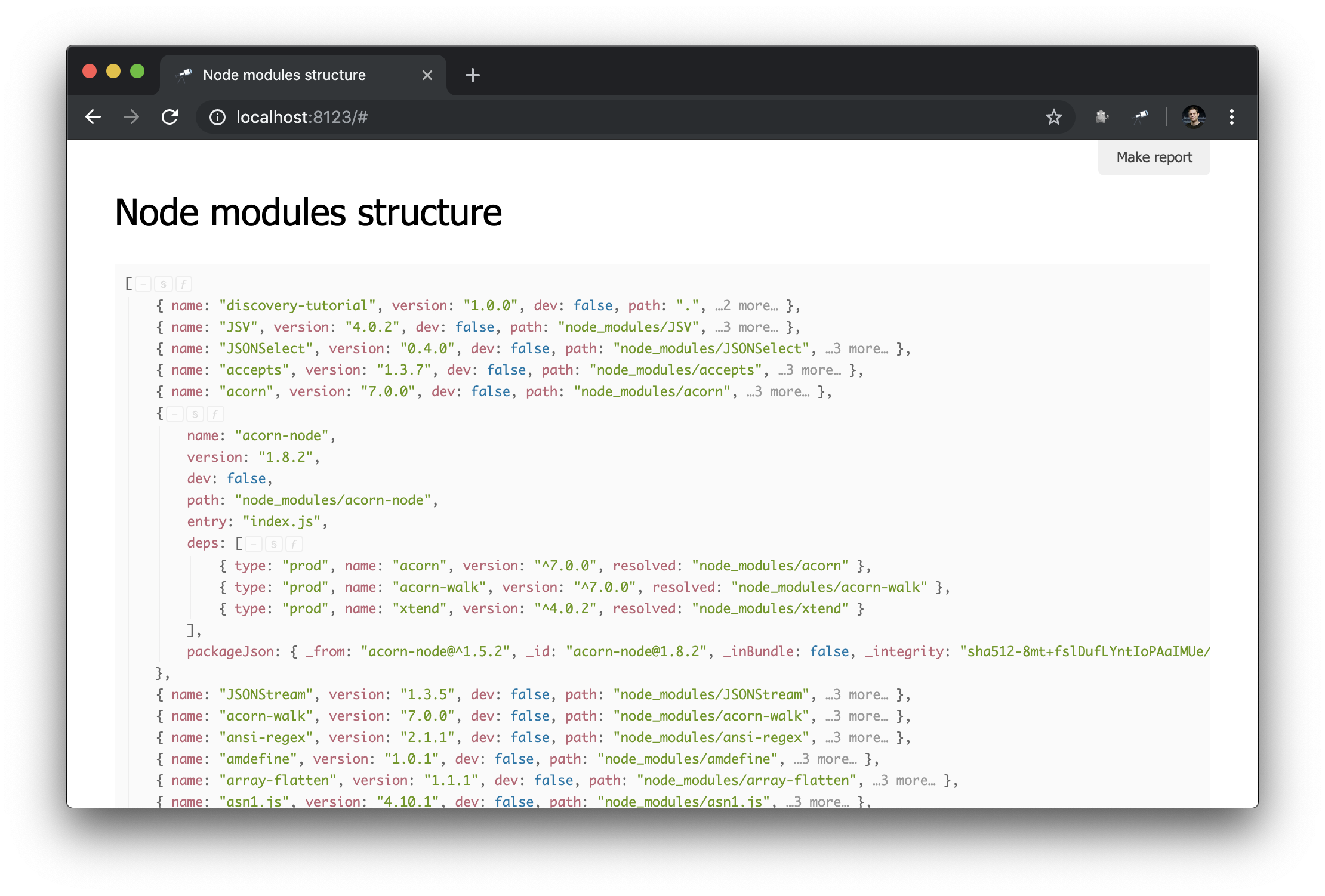
Script de preparação
Como você deve ter notado, alguns objetos que descrevem pacotes contêm deps - uma lista de dependências. Cada dependência possui um campo resolved cujo valor é uma referência a uma instância física do pacote. Esse link é o valor do path de um dos pacotes, é único. Para resolver o link para o pacote, você precisa usar código adicional (por exemplo, #.data.pick(<path=resolved>) ). E, é claro, seria muito mais conveniente se esses links já fossem resolvidos em referências a objetos.
Infelizmente, no estágio de coleta de dados, não podemos resolver os links, pois isso levará a conexões circulares, o que criará o problema de transferir esses dados na forma de JSON. No entanto, existe uma solução: este é um script de prepare especial. É definido na configuração e chamado sempre que um novo dado é atribuído à instância do Discovery. Vamos começar com a configuração:
module.exports = { ... prepare: __dirname + '/prepare.js',
Defina prepare.js :
discovery.setPrepare(function(data) {
Neste módulo, definimos a função de prepare para a instância Discovery. Essa função é chamada sempre antes de aplicar dados à instância do Discovery. Este é um bom lugar para permitir valores nas referências de objetos:
discovery.setPrepare(function(data) { const packageIndex = data.reduce((map, pkg) => map.set(pkg.path, pkg), new Map()); data.forEach(pkg => pkg.deps.forEach(dep => dep.resolved = packageIndex.get(dep.resolved) ) ); });
Aqui, criamos um índice de pacote no qual a chave é o valor do path do pacote (exclusivo). Depois, examinamos todos os pacotes e suas dependências e, nas dependências, substituímos o valor resolved por uma referência ao objeto do pacote. Resultado:
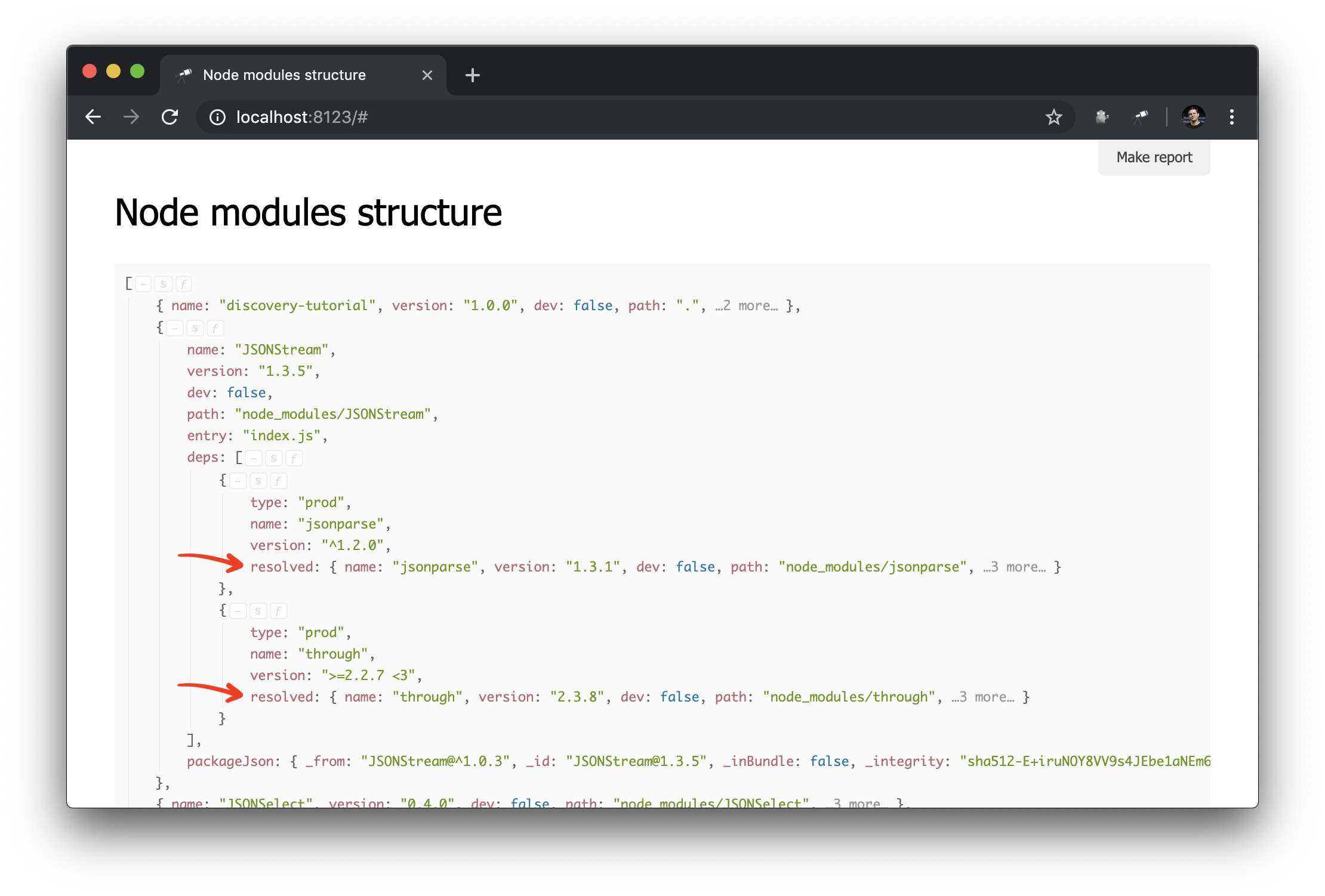
Agora é muito mais fácil fazer consultas ao gráfico de dependência. É assim que você pode obter um cluster de dependências (ou seja, dependências, dependências, etc.) para um pacote específico:
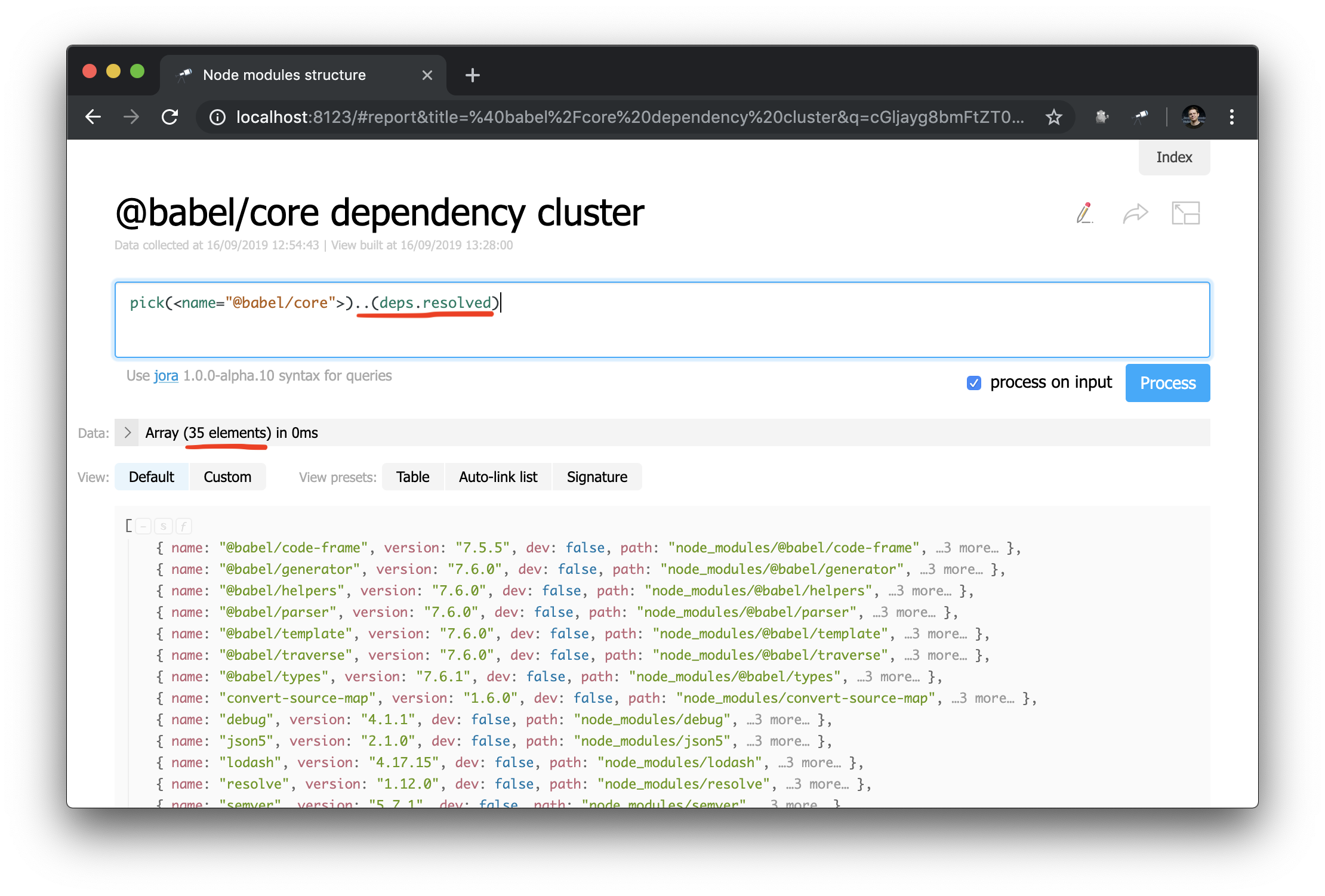
Uma história de sucesso inesperada: enquanto estudava os dados durante a redação do manual, descobri um problema no @discoveryjs/cli (usando a consulta .[deps.[not resolved]] ), que tinha um erro de digitação nas dependências de pares. O problema foi corrigido imediatamente. O caso é um bom exemplo de como essas ferramentas ajudam.
Talvez tenha chegado a hora de mostrar na página inicial vários números e pacotes com takes.
Personalizar página inicial
Primeiro, precisamos criar um módulo de página, por exemplo, pages/default.js . Usamos o default , porque esse é o identificador da página inicial, que podemos substituir (no Discovery.js, você pode substituir muito). Vamos começar com algo simples, por exemplo:
discovery.page.define('default', [ 'h1:#.name', 'text:"Hello world!"' ]);
Agora, na configuração, você precisa conectar o módulo de página:
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data'), view: { assets: [ 'pages/default.js'
Verifique no navegador:
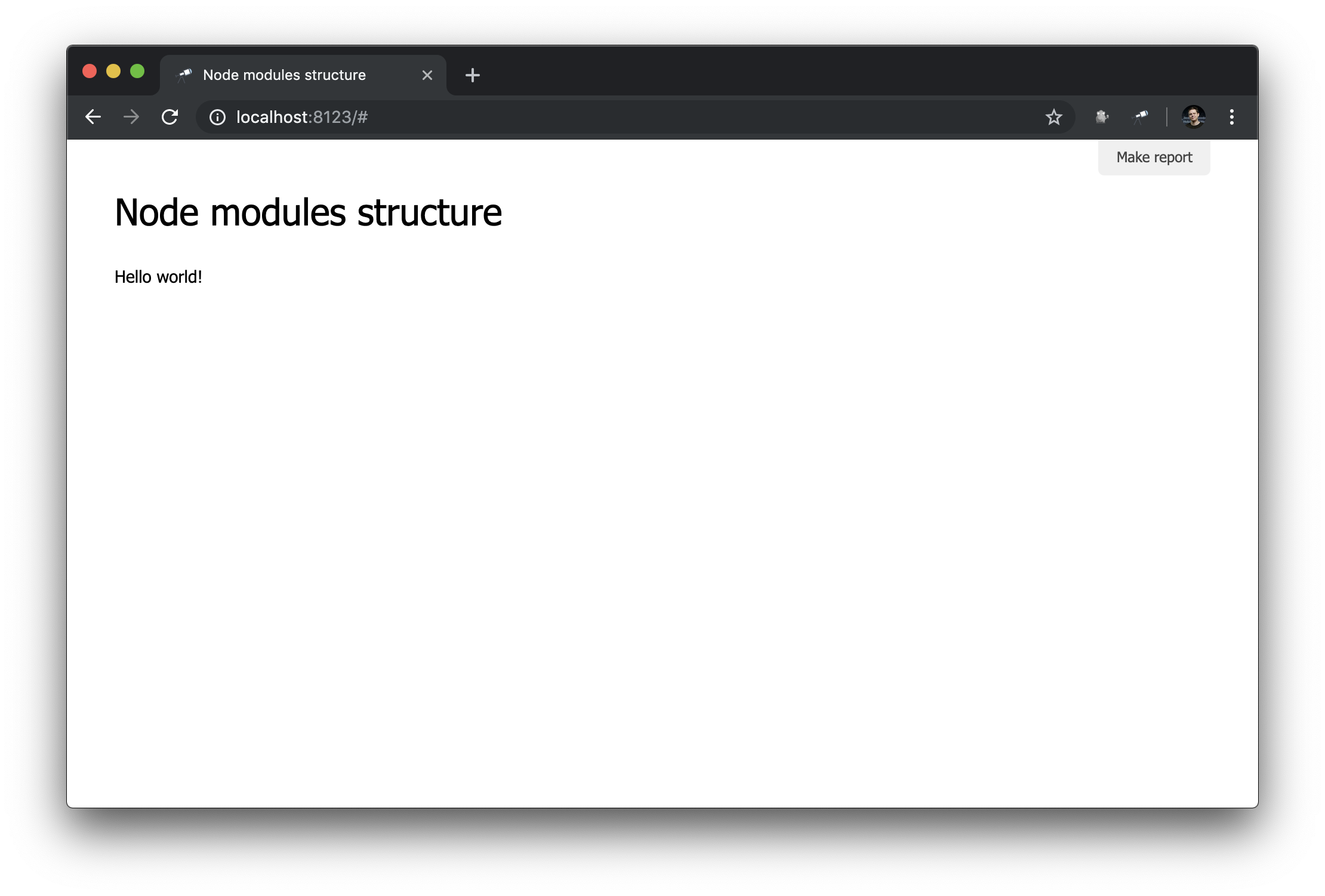
Isso funciona!
Agora vamos pegar alguns contadores. Para fazer isso, faça alterações em pages/default.js :
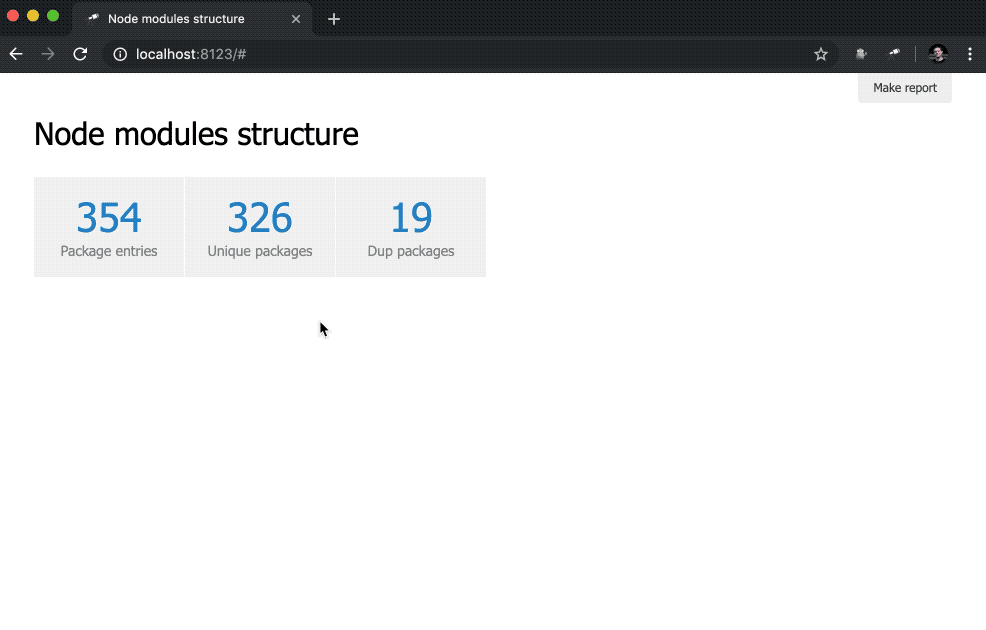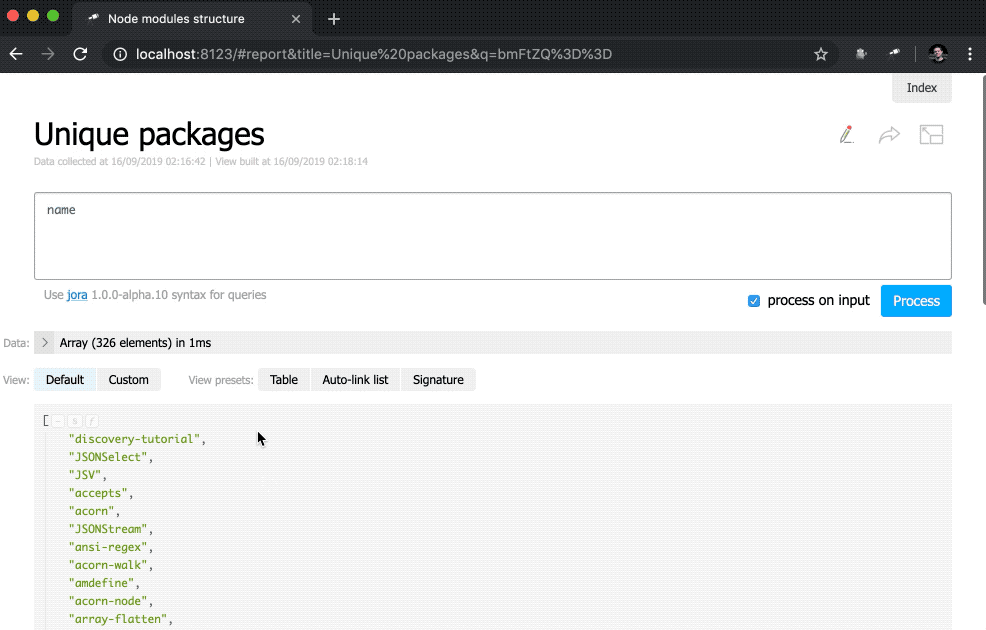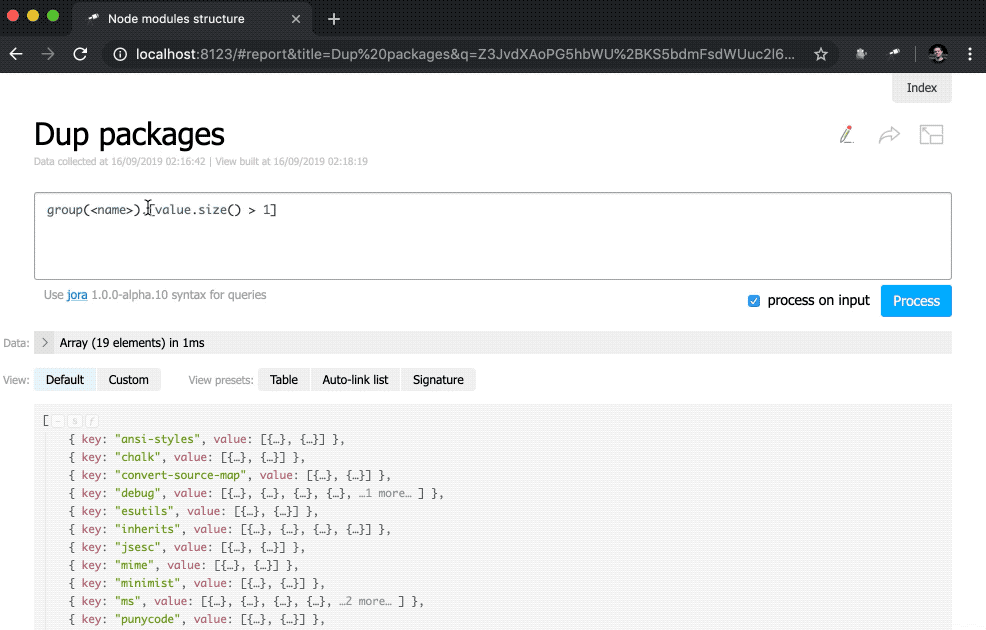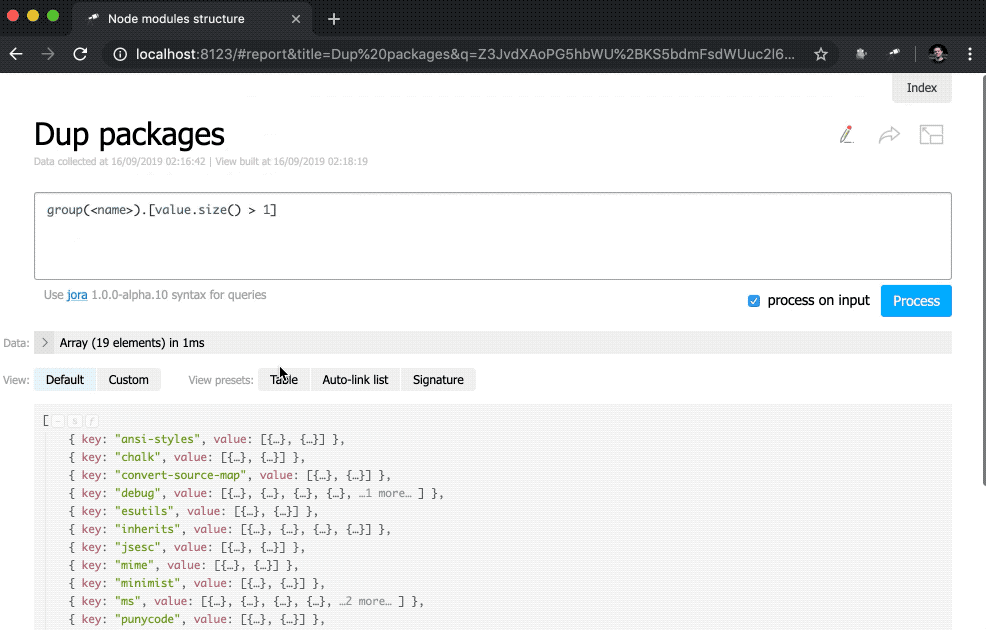
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', item: 'indicator', data: `[ { label: 'Package entries', value: size() }, { label: 'Unique packages', value: name.size() }, { label: 'Dup packages', value: group(<name>).[value.size() > 1].size() } ]` } ]);
Aqui, definimos uma lista embutida de indicadores. O valor dos data é uma consulta Jora que cria uma matriz de registros. A lista de pacotes (raiz de dados) é usada como base para as consultas; portanto, obtemos o tamanho da lista ( size() ), o número de nomes de pacotes exclusivos ( name.size() ) e o número de nomes de pacotes duplicados ( group(<name>).[value.size() > 1].size() ).
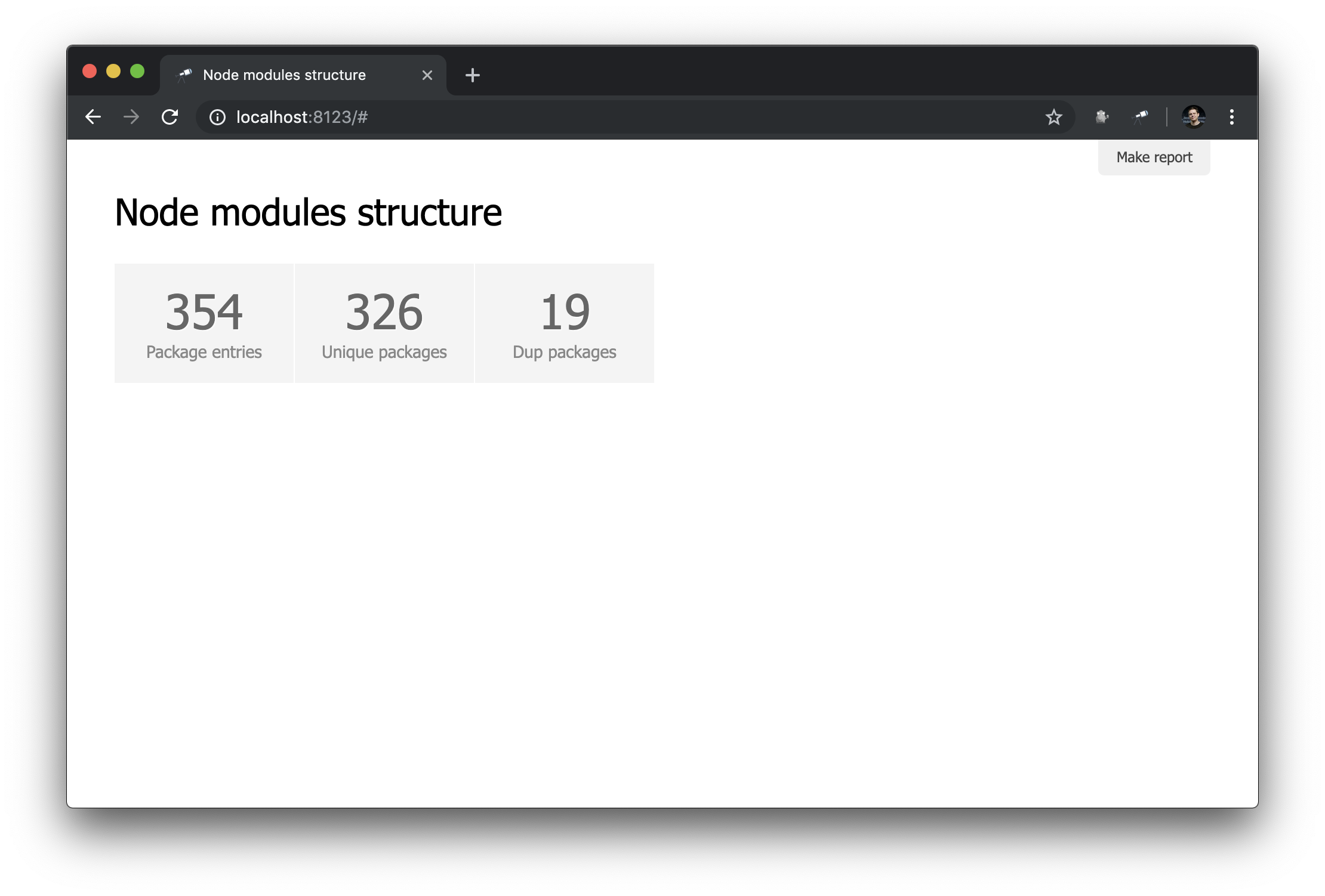
Nada mal. No entanto, seria melhor ter, além de números, links para as amostras correspondentes:
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', data: [ { label: 'Package entries', value: '' }, { label: 'Unique packages', value: 'name' }, { label: 'Dup packages', value: 'group(<name>).[value.size() > 1]' } ], item: `indicator:{ label, value: value.query(#.data, #).size(), href: pageLink('report', { query: value, title: label }) }` } ]);
Primeiro, alteramos o valor dos data , agora é uma matriz regular com alguns objetos. Além disso, o método size() foi removido das solicitações de valor.
Além disso, uma subconsulta foi adicionada à exibição do indicator . Esses tipos de consultas criam um novo objeto para cada elemento no qual o value e href são calculados. Para value , uma consulta é executada usando o método query() , para o qual os dados são transferidos do contexto e, em seguida, o método size() é aplicado ao resultado da consulta. Para href , é usado o método pageLink() , que gera um link para a página do relatório com uma solicitação e cabeçalho específicos. Após todas essas alterações, os indicadores se tornaram clicáveis (observe que seus valores se tornaram azuis) e mais funcionais.
Para tornar a página inicial mais útil, adicione uma tabela com pacotes com duplicatas.
discovery.page.define('default', [
A tabela usa os mesmos dados que o indicador de Dup packages . A lista de pacotes foi classificada por tamanho de grupo na ordem inversa. O restante da configuração está relacionado às colunas (a propósito, geralmente elas não precisam ser ajustadas). Para a coluna Version & Location , definimos uma lista aninhada (classificada por versão), na qual cada elemento é um par do número da versão e o caminho para a instância.
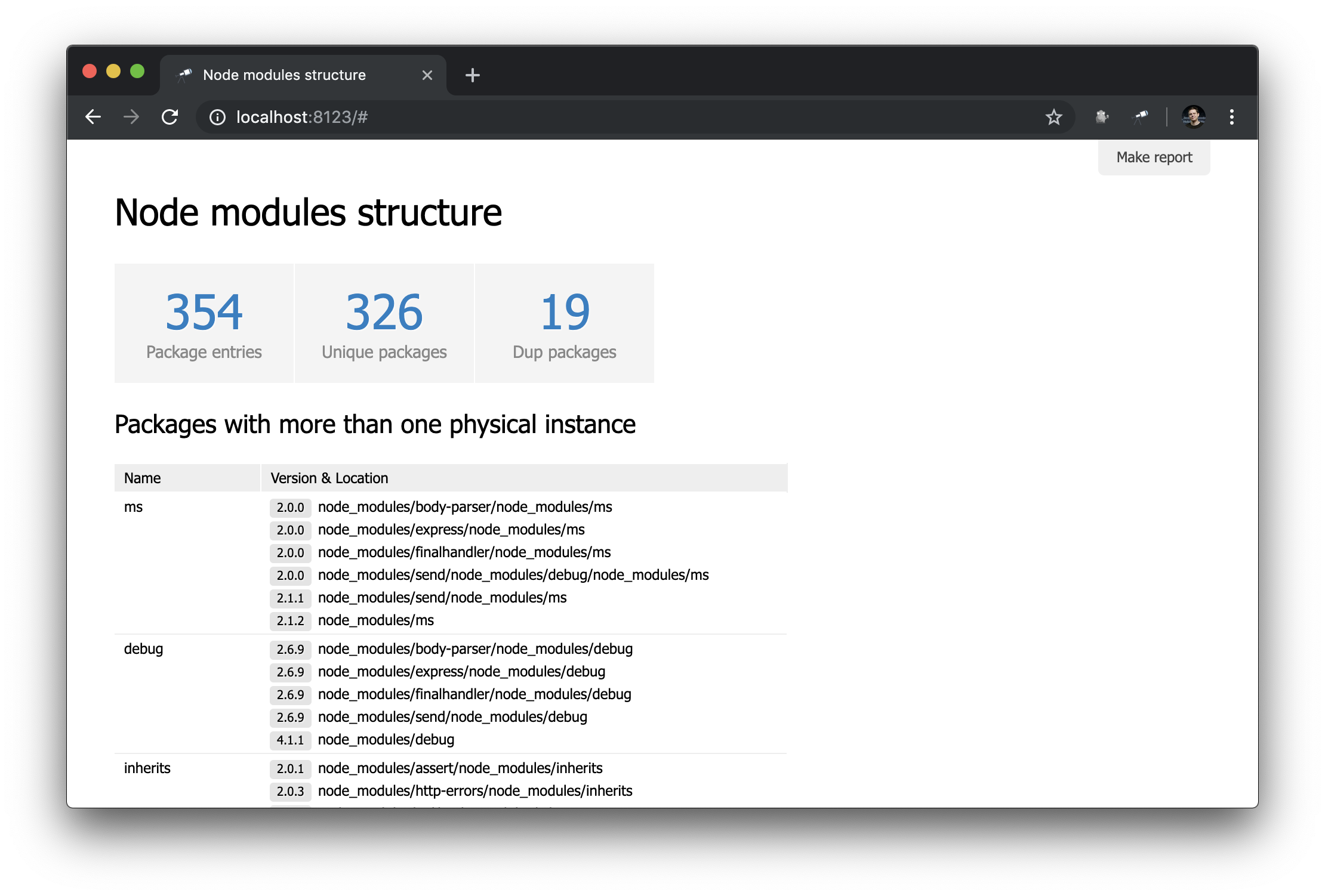
Página do pacote
Agora temos apenas uma visão geral dos pacotes. Mas seria útil ter uma página com detalhes sobre um pacote específico. Para fazer isso, crie um novo módulo pages/package.js e defina uma nova página:
discovery.page.define('package', { view: 'context', data: `{ name: #.id, instances: .[name = #.id] }`, content: [ 'h1:name', 'table:instances' ] });
Neste módulo, definimos a página com o package identificador. O componente de context foi utilizado como representação inicial. Este é um componente não visual que ajuda a definir dados para mapeamentos aninhados. Observe que usamos #.id para obter o nome do pacote, que é recuperado de uma URL como esta http://localhost:8123/#package:{id} .
Não esqueça de incluir o novo módulo na configuração:
module.exports = { ... view: { assets: [ 'pages/default.js', 'pages/package.js'
Resultado no navegador:
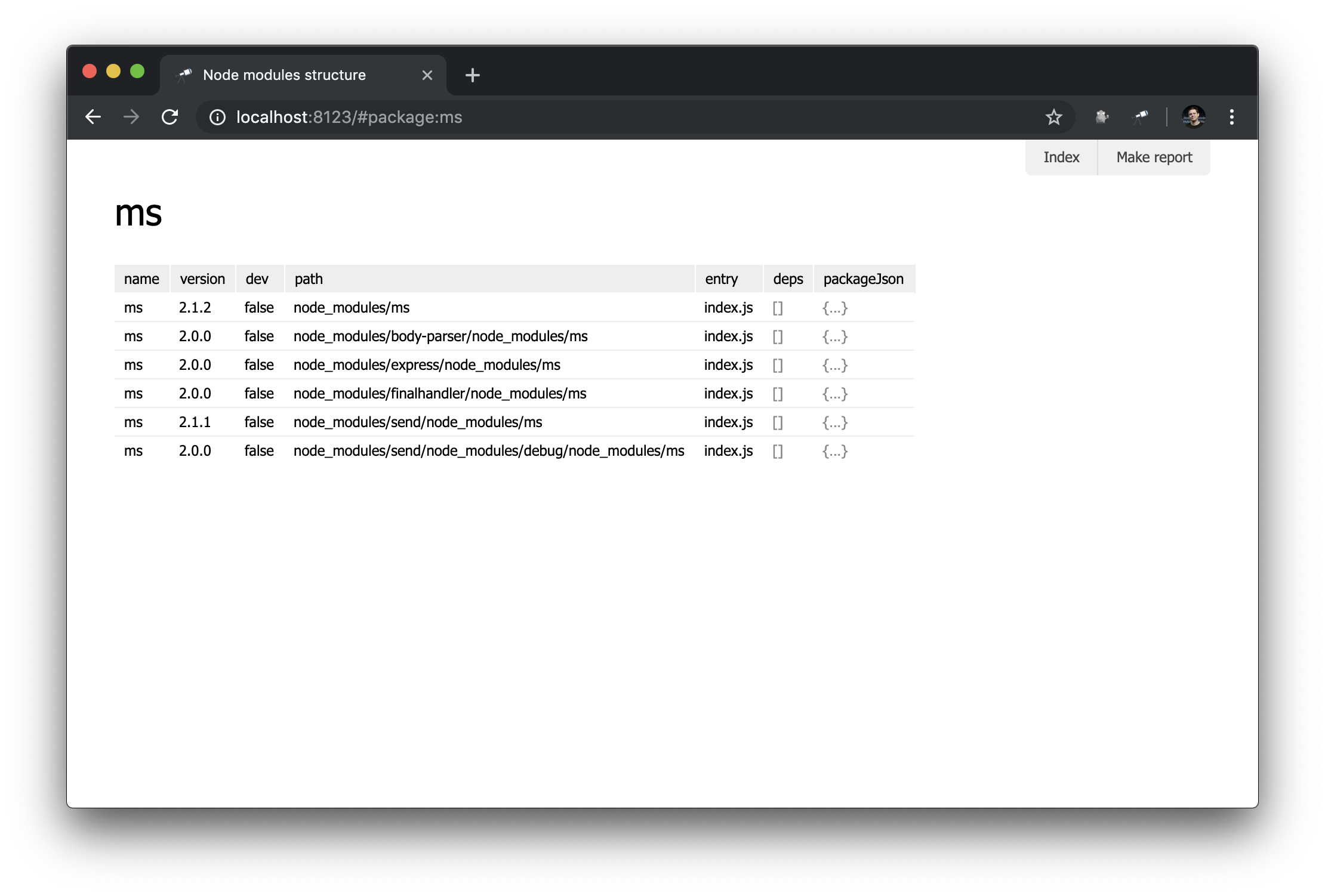
Não é muito impressionante, mas por enquanto. Criaremos mapeamentos mais complexos nos manuais subseqüentes.
Painel lateral
Como já temos uma página de pacote, seria bom ter uma lista de todos os pacotes. Para fazer isso, você pode definir uma vista especial - sidebar , que será exibida se estiver definida (não definida por padrão). Crie um novo módulo views/sidebar.js :
discovery.view.define('sidebar', { view: 'list', data: 'name.sort()', item: 'link:{ text: $, href: pageLink("package") }' });
Agora temos uma lista de todos os pacotes:
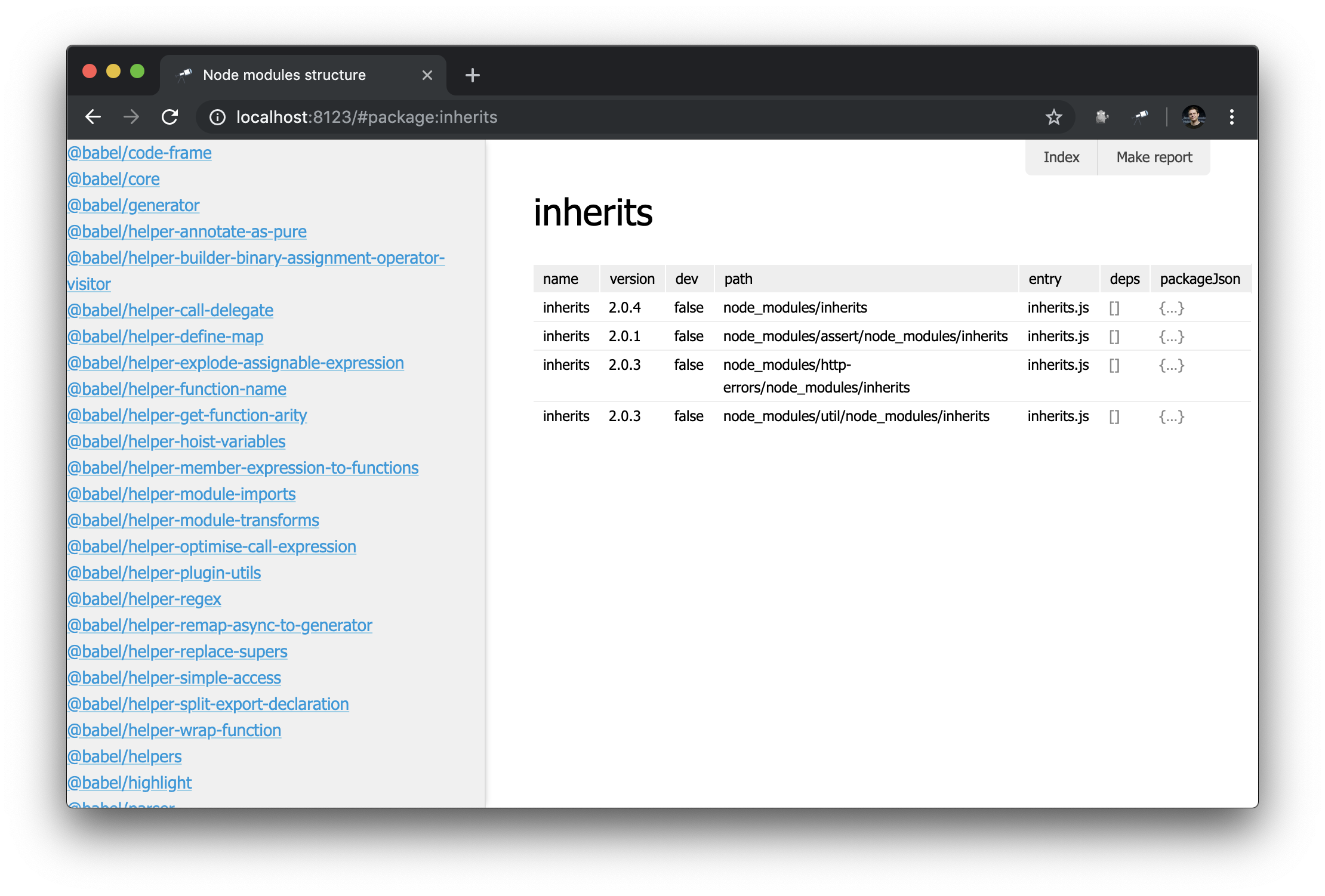
Parece bom. Mas com um filtro seria ainda melhor. Expandimos a definição de sidebar :
discovery.view.define('sidebar', { view: 'content-filter', content: { view: 'list', data: 'name.[no #.filter or $~=#.filter].sort()', item: { view: 'link', data: '{ text: $, href: pageLink("package"), match: #.filter }', content: 'text-match' } } });
Aqui, agrupamos a lista em um componente de content-filter que converte o valor de entrada no campo de entrada em expressões regulares (ou null se o campo estiver vazio) e o salva como um valor de filter no contexto (o nome pode ser alterado com a opção de name ). Além disso, para filtrar os dados da lista, usamos #.filter . Por fim, aplicamos o mapeamento de links para destacar partes correspondentes com correspondência de text-match . Resultado:

Caso não goste do design padrão, você pode personalizar os estilos como desejar. Digamos que você queira alterar a largura da barra lateral. Para isso, é necessário criar um arquivo de estilo (por exemplo, views/sidebar.css ):
.discovery-sidebar { width: 300px; }
E adicione um link a este arquivo na configuração, bem como aos módulos JavaScript:
module.exports = { ... view: { assets: [ ... 'views/sidebar.css',
AutoLinks
O capítulo final deste guia é dedicado aos links. Anteriormente, usando o método pageLink() , criamos um link para a página do pacote. Mas, além do link, você também deve definir o texto do link. Mas como facilitamos?
Para simplificar o trabalho dos links, precisamos definir uma regra para gerar links. É melhor fazer isso no script de prepare :
discovery.setPrepare(function(data) { ... const packageIndex = data.reduce( (map, item) => map .set(item, item)
Adicionamos um novo mapa (índice) de pacotes e o usamos para resolver entidades. O resolvedor de entidades tenta, se possível, converter o valor passado a ele em um descritor de entidade. O descritor contém:
type - tipo de entidadeid - uma referência exclusiva a uma instância de entidade usada em links como um IDname - usado como texto do link
Finalmente, você precisa atribuir esse tipo a uma página específica (o link deve levar a algum lugar, certo?).
discovery.page.define('package', { ... }, { resolveLink: 'package'
A primeira conseqüência dessas alterações é que alguns valores na visualização struct agora estão marcados com um link para a página do pacote:
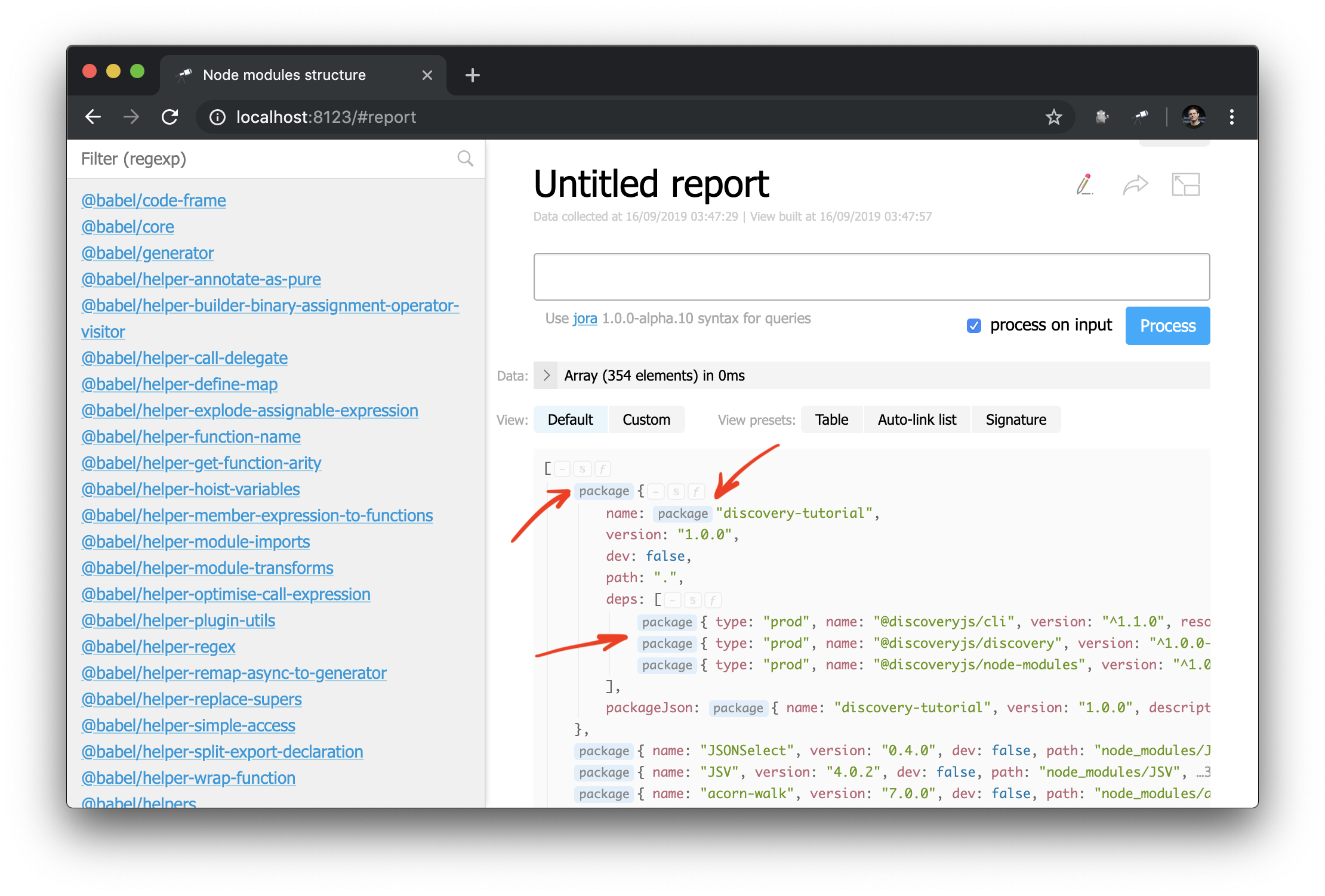
E agora você também pode aplicar o componente de auto-link a um nome de objeto ou pacote:
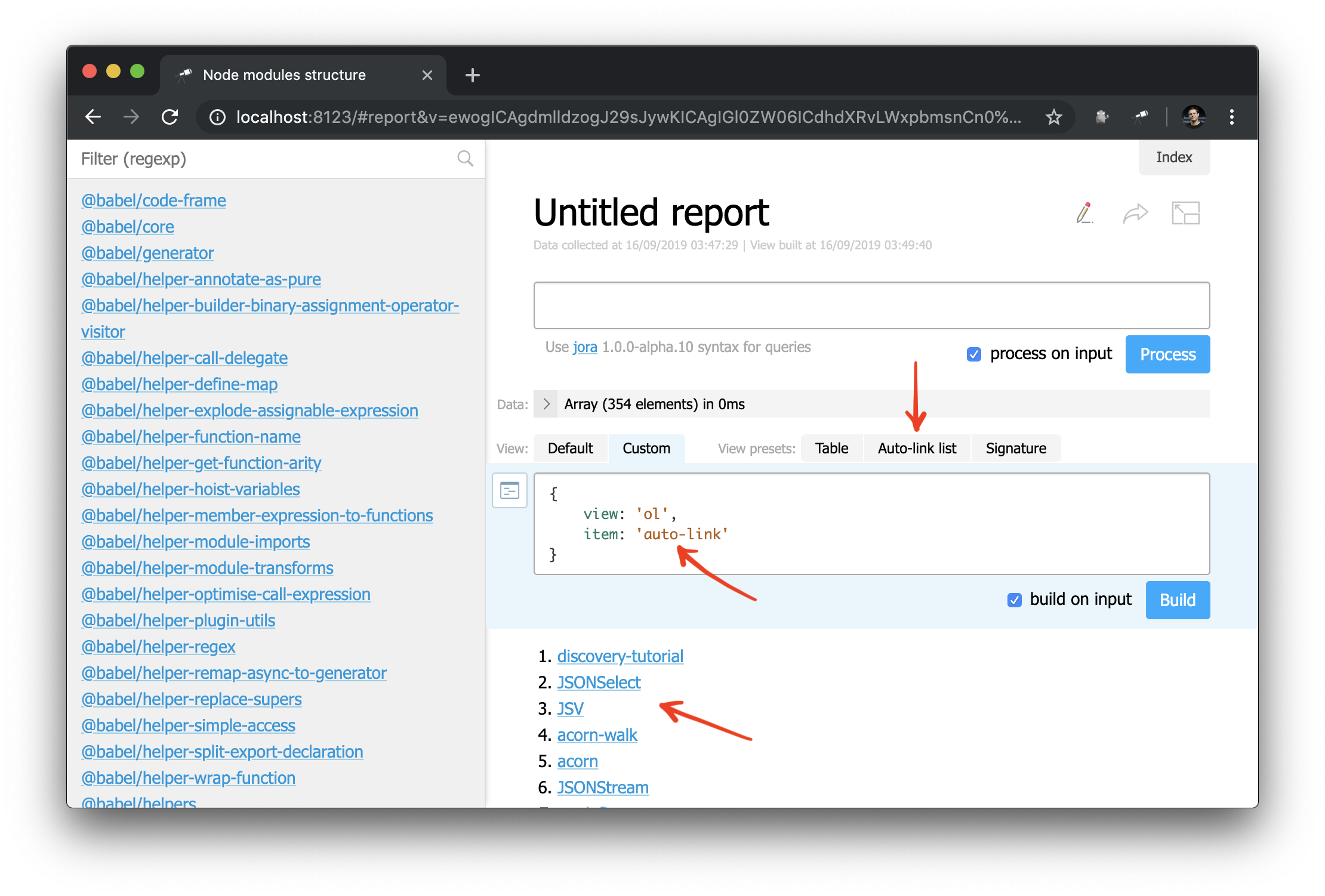
E, como exemplo, você pode refazer um pouco a barra lateral:
Conclusão
Agora você tem um entendimento básico dos principais conceitos do Discovery.js . Nos seguintes guias, examinaremos mais de perto os tópicos abordados.
Você pode ver o código-fonte inteiro do guia no repositório no GitHub ou tentar como ele funciona online .
Siga @js_discovery no Twitter para acompanhar as últimas notícias!